【论文笔记】On Recognizing Texts of Arbitary Shapes with 2D Self-Attention(SATRN)
文章目录
- On Recognizing Texts of Arbitary Shapes with 2D Self-Attention(SATRN)
- 基本信息
- 摘要
- 模型结构
- 实验
- 总结
On Recognizing Texts of Arbitary Shapes with 2D Self-Attention(SATRN)
基本信息
- 论文链接
- 发表时间:2020
- 应用场景:自然场景场景文字识别
摘要
| 存在什么问题 | 解决了什么问题 |
|---|---|
|
1. 现有识别模型对于大曲率弯曲或者旋转文本识别效果不佳。 2. crnn - 默认文字是水平排列的。 |
1. 提出SATRN网络结构,利用self-attention机制对场景文字图片下所有字符的2d空间关系进行建模,在面对文字不同的布局方式以及字符间隔较大的情况下有天然的优势。 2. 对于大曲率弯曲、大角度旋转文本以及多行文字也具备足够的识别能力。 3. 在非规则文本(irregular text)数据集上超过先前模型5.7个点,达到SOTA。 |
模型结构
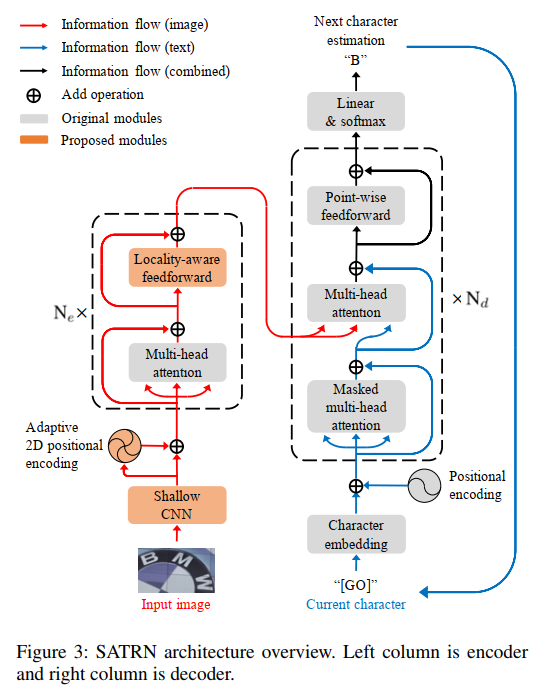
能够明显看出整体结构与标准的transformer几乎一致,整体上遵循CNN -> transformer encoder -> transformer decoder架构。
在encoder上相比于原始的transformer encoder,有已下3点优化:
出于计算量的考虑,先用一个CNN(文中叫Shallow CNN)处理输入图像,抽取视觉特征的同时进行降采样操作,降低feature map的大小,为后续transformer encoder建模像素间的关系减轻计算负担。Shallow CNN采用简单的两层conv->bn->relu->pool堆叠即可,实现高和宽的4倍降采样。
经过CNN后,就准备将feature map送入transformer encoder中了,但是此时feature map是2D的,并不是一个序列,像素间是存在空间位置关系的,因此一个优秀的position encoding模块是非常有必要的,作者这里提出了adaptive 2D positional encoding(A2DPE)模块。
对于featurep map上的每一个像素点,首先是一个x,y方向的传统正、余弦position encoding(下图只列了一个方向的公式):

最终的position encoding是两者的加权叠加:
而权重α(E)\alpha(E)α(E)和β(E)\beta(E)β(E)是可学习的变量(E是feature map),具体求法也比较简单:
g(E)g(E)g(E)代表全局平均池化层,W1h、W2hW_1^h、W_2^hW1h、W2h代表竖直方向的两个不改变通道数目的卷积核,同理,W1w和W2wW_1^w和W_2^wW1w和W2w代表水平方向的两个不改变通道数目的卷积核。max函数只是代表了一个relu层而已。经过两次卷积,最后接一个sigmoid层,得到竖直方向PE和水平方向PE的自适应学习权重,加权求和两方向的正、余弦PE后得到最终的adaptive 2D positional encoding值。注意这个过程有一些broadcasting操作,在纸上画一画就能分析出来,比较简单,这里不再赘述。另外加完PE后,会将feature map拉平变成序列,送入transformer encoder中。
encoder中的self-attention模块中的FFN层优化,作者认为self-attention对于长程注意力的捕捉能力很优秀,但是也要兼顾局部注意力的捕捉。而且每个字符大概率和其周边的字符有更强的相关性,因此作者这里将FFN中的全连接层换成了conv->depthConv->conv几个卷积层,让模型同时兼顾长程注意力和局部注意力,其模型结构比较简单,如下所示:
decoder和标准transformer一致,无优化。
实验
Regular和Irregular benchmark上的识别实验,可以看到SATRN在Irregular test dataset上吊打了先前的所有识别方法,取得了SOTA。
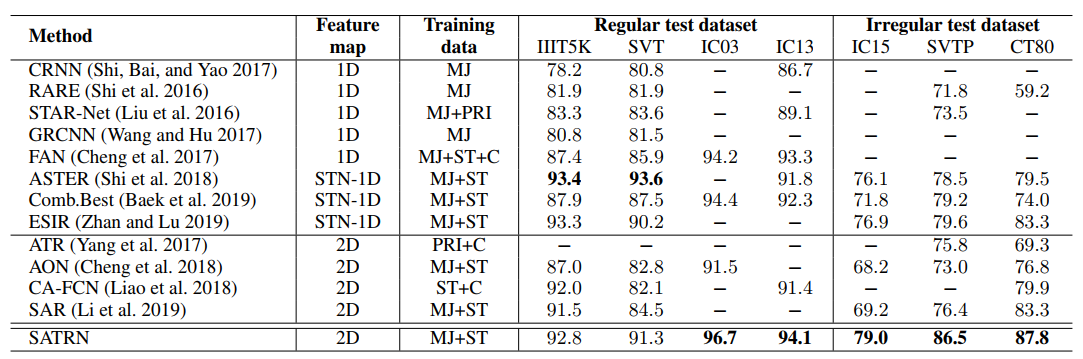
训练数据集:MJ+ST;resize: 32x100;self-attention dim: 512;encoder层数:12;decoder层数6;输出类别94+1(有1个时SOS/EOS token)。
A2DPE消融实验,可以看到作者提出的A2DPE位置编码方法效果是最好的。这种自适应位置编码方式能够更好的适应字符间各种版面布局方式,加强模型表达能力。
![]()
- Encoder中FFN层的消融实验,出于效果和性能间的双重考虑,采用了卷积+深度可分离卷积代替了原先的全连接结构。
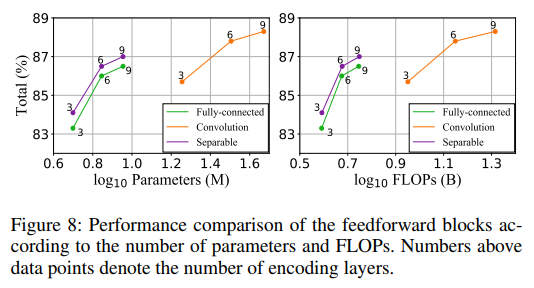
- shallow cnn降采样消融实验,降采样倍率越大,计算量就越小,但是识别效果也越差,在达到8倍降采样后,识别效果降低的就比较多了。作者最终采用的是4倍降采样。
![]()
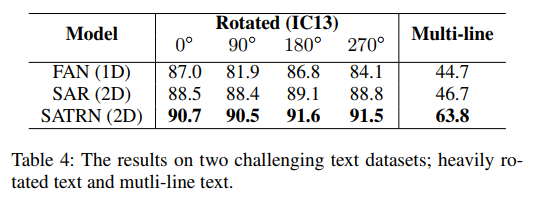
SATRN在旋转文本、多行文本数据集上的效果验证:
对于旋转文本场景,基于IC13改造了个旋转测试集,训练的时候训练集随机[0,360]旋转,图片resize改为[64,64]。
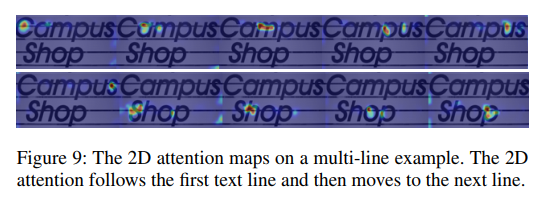
对于多行文本场景,基于SJ和MT数据集构造了多行文本训练集,基于IC13改造了多行测试集。从encoder-decoder attention map的可视化上证明了SATRN具备跨行识别的能力
可以看到在这两个场景下SATRN指标都是最好的。
总结
- 为了解决识别弯曲程度大、旋转文本难度大的问题,提出了SATRN模型,模型整体架构依托transformer,并在encoder上做了一些优化以更好的适配STR任务,并在多个irregular test set上指标取得了SOTA。
- SATRN模型可挖掘的潜力很大,对于文字的布局没有任何人为的假设偏见,这也使得SATRN具备在旋转文本、多行文本上的识别能力。
- 缺点:速度慢,解码仍然要遵循auto regression解码范式,能够像DETR那样一次并行解码出全部的识别字符呢?以此来提升识别性能。所以模型落地还有一段路要走。
【论文笔记】On Recognizing Texts of Arbitary Shapes with 2D Self-Attention(SATRN)相关推荐
- 论文翻译-On Recognizing Texts of Arbitrary Shapes with 2D Self-Attention
论文翻译-On Recognizing Texts of Arbitrary Shapes with 2D Self-Attention 原文地址:https://arxiv.org/pdf/1910 ...
- 论文笔记:A CNN Regression Approach for Real-Time 2D/3D Registration
REAL-TIME 2D/3D REGISTRATION VIA CNN REGRESSION 摘要 介绍 问题描述 通过分层学习进行姿态估计 摘要 提出了用于实时2-D / 3-D注册的卷积神经网络 ...
- 【论文笔记】Encoding cloth manipulations using a graph of states and transitions
[论文笔记]Encoding cloth manipulations using a graph of states and transitions Abstract 问题: Cloth manipu ...
- 最新图神经网络论文笔记汇总(附pdf下载)
点击上方,选择星标或置顶,不定期资源大放送! 阅读大概需要15分钟 Follow小博主,每天更新前沿干货 [导读]近年来,图神经网络变得非常火热,每年顶会在该领域内都会出现大量的研究论文,本文为大家提 ...
- 论文笔记 《Selective Search for Object Recognition》
论文笔记 <Selective Search for Object Recognition> 项目网址:http://koen.me/research/selectivesearch/ 一 ...
- GAN for NLP (论文笔记及解读
GAN 自从被提出以来,就广受大家的关注,尤其是在计算机视觉领域引起了很大的反响."深度解读:GAN模型及其在2016年度的进展"[1]一文对过去一年GAN的进展做了详细介绍,十分 ...
- 论文笔记【A Comprehensive Study of Deep Video Action Recognition】
论文链接:A Comprehensive Study of Deep Video Action Recognition 目录 A Comprehensive Study of Deep Video A ...
- ORB-SLAM3 论文笔记
ORB-SLAM3 论文笔记 这篇博客 ORB-SLAM3系统 相机模型的抽象(Camera Model) 重定位的问题 图片矫正的问题 视觉惯性SLAM的工作原理 相关公式 IMU初始化 跟踪和建图 ...
- 【论文笔记】 LSTM-BASED DEEP LEARNING MODELS FOR NONFACTOID ANSWER SELECTION
一.简介 这篇论文由IBM Watson发表在2016 ICLR,目前引用量92.这篇论文的研究主题是answer selection,作者在这篇论文基础上[Applying Deep Learnin ...
最新文章
- 自定义ActionSheetView
- 正则表达式全部符号详解
- VS 打包升成可自动升级的安装包
- NYOJ----776删除元素
- “病毒防治”页面中“社区热帖”版块不显示
- matlab错误:vl_feat工具箱问题
- 原型继承+原型链 + 对象继承发展
- 获取两个数据的交集_MySQL交集和差集的实现方法
- Python操作数据库(二)
- 几个常用的CSS3样式代码以及不兼容的解决办法
- kaggle房价预测特征意思_Kaggle初探--房价预测案例之数据分析
- 关于智能手机的基本知识
- 为什么家里pm25比外面高_夫妻感情很好,男人为什么还会找情人?这是我听过最好的答案...
- java认证,ocjp认证,jdk1.8,全流程介绍
- 在华为手机上查看连接过的wifi密码(不愁记性不好)
- 中学-综合素质【2】
- EI检索ISTP检索ICFMD 2011年制造与设计科学技术会议
- c实现 图像dither算法_Atitit (Sketch Filter)素描滤镜的实现 图像处理 attilax总结...
- C语言消消乐游戏代码
- 基于Linux+ARM的远程视频监控--系列开题