tensorflow强化学习之打乒乓球(Reinforcement Learning)
2019独角兽企业重金招聘Python工程师标准>>> 
深度学习大部分是监督学习,而且需要海量,高质量的数据对。这在现实世界,是非常难的事情。人类的学习过程里,不可能让一个孩子,看一亿张图片,才学会识别一只猫。
强化学习则更像人类的学习过程,这次3天达到世界顶尖高手水平的alpha zero也是基于强化学习的算法,从0开始。连接主义学习里,有监督学习,非监督学习,还有强化学习,强化学习靠环境提供的强化信号对动作的优劣做评价。
下面这篇文章对RL做了很好的总结:
http://karpathy.github.io/2016/05/31/rl/
OpenAI gym提供一个很好的强化学习的工具箱:
https://github.com/openai/gym
我们看看强化学习能做什么有意思的事情。
Atari是一个古老的打乒乓球的游戏。
再看一个MDP决策:

我们就让RL做类似的事情,本文先介绍让计算机从像素开始学会打乒乓球。
乒乓球的游戏规则就不多介绍,直接看系统如何实现,我们不只针对这个游戏做系统设计,我们设计尽量通过的系统,能完成更多任务,看如下的策略网络。
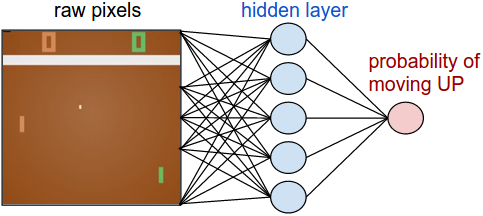
pip install gym,这个强化学习的开发包是需要的。atari_py这个包也是需要的。
t_states = tf.placeholder(tf.float32, shape=[None,80,80]) # policy network network = InputLayer(t_states, name='input') network = DenseLayer(network, n_units=H, act=tf.nn.relu, name='hidden') network = DenseLayer(network, n_units=3, name='output') probs = network.outputs sampling_prob = tf.nn.softmax(probs)t_actions = tf.placeholder(tf.int32, shape=[None]) t_discount_rewards = tf.placeholder(tf.float32, shape=[None]) loss = tl.rein.cross_entropy_reward_loss(probs, t_actions, t_discount_rewards) train_op = tf.train.RMSPropOptimizer(learning_rate, decay_rate).minimize(loss)
这里损失函数,我们仍然使用交叉熵损失:
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, targets=actions)
但在这个基础上,乘以环境反馈的回报reward:
loss = tf.reduce_sum(tf.multiply(cross_entropy, rewards))
action = tl.rein.choice_action_by_probs(prob.flatten(), [1,2,3]) observation, reward, done, _ = env.step(action)
每一次行动,系统会给出一个reward,奖励或惩罚,然后训练最优的行动方案。
强化还可以做很多很酷的事情,后续继续更新。
关于作者:魏佳斌,互联网产品/技术总监,北京大学光华管理学院(MBA),特许金融分析师(CFA),资深产品经理/码农。偏爱python,深度关注互联网趋势,人工智能,AI金融量化。致力于使用最前沿的认知技术去理解这个复杂的世界。
扫描下方二维码,关注:AI量化实验室(ailabx),了解AI量化最前沿技术、资讯。
转载于:https://my.oschina.net/u/1996852/blog/1560494
tensorflow强化学习之打乒乓球(Reinforcement Learning)相关推荐
- 强化学习 最前沿之Hierarchical reinforcement learning(一)
强化学习-最前沿系列 深度强化学习作为当前发展最快的方向,可以说是百家争鸣的时代.针对特定问题,针对特定环境的文章也层出不穷.对于这么多的文章和方向,如果能撇一隅,往往也能够带来较多的启发. 本系列文 ...
- 【论文笔记】分层强化学习鼻祖:Feudal Reinforcement Learning 1993
1993年的分层强化学习:Feudal Reinforcement Learning 概括 1992年没有深度学习,人们研究RL的思路与现在并不相同.但不可否认,提出"分层强化学习" ...
- 分层强化学习综述:Hierarchical reinforcement learning: A comprehensive survey
论文名称:Hierarchical reinforcement learning: A comprehensive survey 论文发表期刊:ACM Computing Surveys 期刊影响因子 ...
- 深度强化学习:入门(Deep Reinforcement Learning: Scratching the surface)
原文链接:https://blog.csdn.net/qq_32690999/article/details/78594220 本博客是对学习李宏毅教授在youtube上传的课程视频<Deep ...
- 【强化学习-14】Multi-agent reinforcement learning: centralized vs. decentralized
Multi-agent reinforcement learning 第3种架构 本笔记整理自 (作者: Shusen Wang): https://www.bilibili.com/video/BV ...
- TensorFlow 强化学习:1~5
原文:Reinforcement Learning With TensorFlow 协议:CC BY-NC-SA 4.0 译者:飞龙 本文来自[ApacheCN 深度学习 译文集],采用译后编辑(MT ...
- TensorFlow 强化学习:6~10
原文:Reinforcement Learning With TensorFlow 协议:CC BY-NC-SA 4.0 译者:飞龙 本文来自[ApacheCN 深度学习 译文集],采用译后编辑(MT ...
- 强化学习入门 : 一文入门强化学习 (Sarsa、Q learning、Monte-carlo learning、Deep-Q-Network等)
最近博主在看强化学习的资料,找到这两个觉得特别适合入门,一个是"一文入门深度学习",一个是"莫烦PYTHON". 建议:看资料的时候可以多种资料一起参考,一边调 ...
- 深度强化学习之模仿学习(Imitation Learning)
上一部分研究的是奖励稀疏的情况,本节的问题在于如果连奖励都没有应该怎么办,没有奖励的原因是,一方面在某些任务中很难定量的评价动作的好坏,如自动驾驶,撞死人和撞死动物的奖励肯定不同,但分别为多少却并 ...
最新文章
- 常见荧光定量 PCR 检测方法比较
- C++与QML逻辑分离
- GitLab 安装配置指南
- 七:Java之封装、抽象、多态和继承
- JAVA学习 02Day
- 【Swift】iOS UICollectionView 计算 Cell 大小的陷阱
- 微软和火眼又分别发现SolarWinds 供应链攻击的新后门
- 常见基本题型:进制的转换
- 推荐一些2021年整理的PHP毕业设计、毕设参考作品案例
- S32K144 S32K148 UDS诊断 BOOTLOADER开发 ISO14229 15765 软件定 基于UDS协议的CAN总线Bootloader设计 具体价格以咨询为主 UDS 诊断
- opendds简单入门(二)
- als算法参数_推荐算法之ALS
- linux开启cups服务,Linux中cups打印服务实战设置
- 新型城镇化提质扩容 打造民村智慧城市
- nodejs批量ping
- 163邮箱注册,163邮箱申请方法
- 浅谈几种网络攻击及攻防原理
- C/C++ —— 什么是定义?什么是声明?
- 论文阅读——Image Inpainting for Irregular Holes Using Partial Convolutions
- 相机3D坐标到机械臂坐标的转换