python3 爬虫实例_【实战练习】Python3网络爬虫快速入门实战解析(上)
原标题:【实战练习】Python3网络爬虫快速入门实战解析(上)
摘要
使用python3学习网络爬虫,快速入门静态网站爬取和动态网站爬取
[
前言
]
强烈建议:请在电脑的陪同下,阅读本文。本文以实战为主,阅读过程如稍有不适,还望多加练习。
本文的实战内容有:
网络小说下载(静态网站)
优美壁纸下载(动态网站)
爱奇艺VIP视频下载
[
网络爬虫简介
]
网络爬虫,也叫网络蜘蛛(Web Spider)。它根据网页地址(URL)爬取网页内容,而网页地址(URL)就是我们在浏览器中输入的网站链接。比如:https://www.baidu.com/,它就是一个URL。
在讲解爬虫内容之前,我们需要先学习一项写爬虫的必备技能:审查元素(如果已掌握,可跳过此部分内容)。
1、审查元素
在浏览器的地址栏输入URL地址,在网页处右键单击,找到检查。(不同浏览器的叫法不同,Chrome浏览器叫做检查,Firefox浏览器叫做查看元素,但是功能都是相同的)

我们可以看到,右侧出现了一大推代码,这些代码就叫做HTML。什么是HTML?举个容易理解的例子:我们的基因决定了我们的原始容貌,服务器返回的HTML决定了网站的原始容貌。
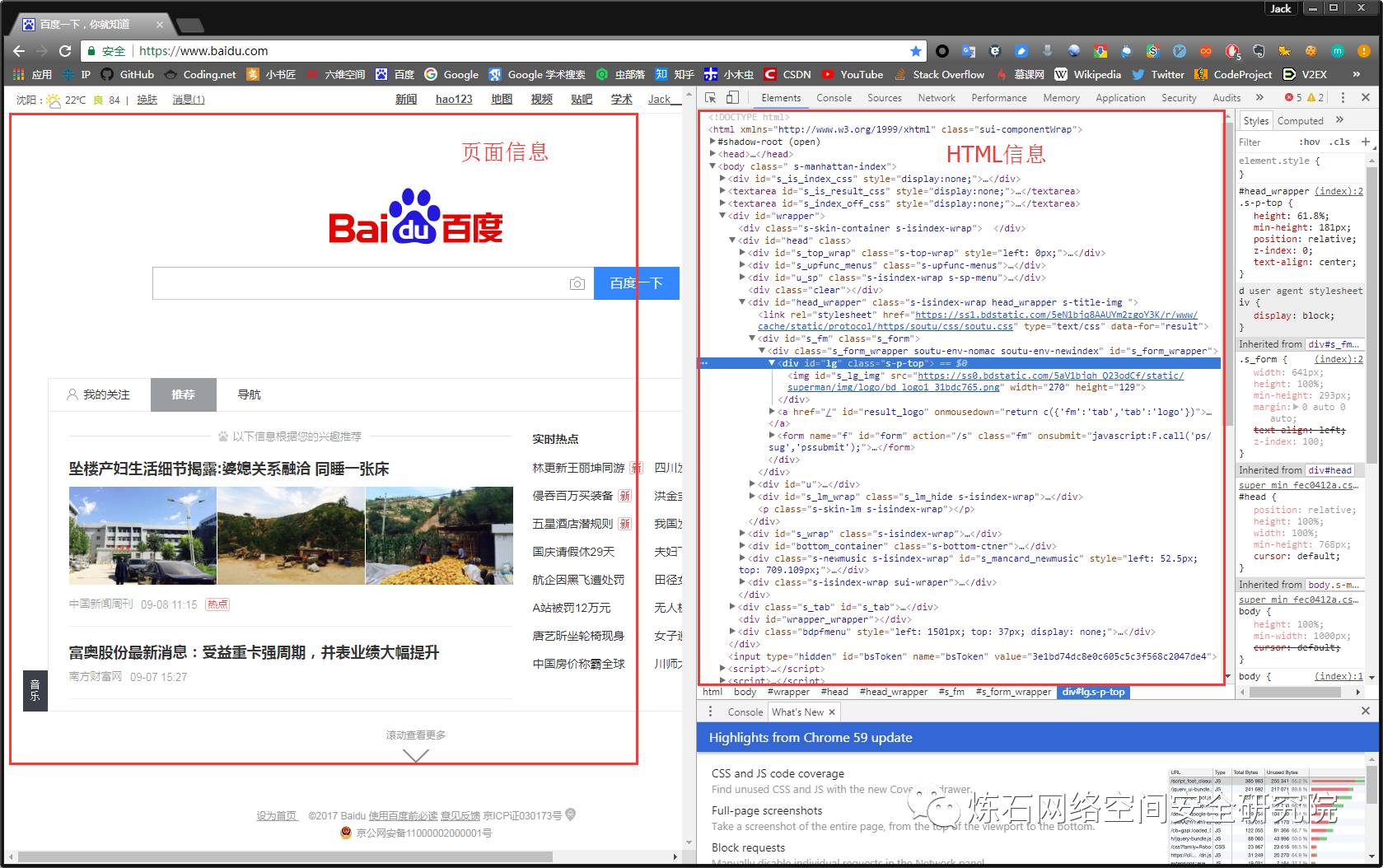
为啥说是原始容貌呢?因为人可以整容啊!扎心了,有木有?那网站也可以"整容"吗?可以!请看下图:

我能有这么多钱吗?显然不可能。我是怎么给网站"整容"的呢?就是通过修改服务器返回的HTML信息。我们每个人都是"整容大师",可以修改页面信息。我们在页面的哪个位置点击审查元素,浏览器就会为我们定位到相应的HTML位置,进而就可以在本地更改HTML信息。
再举个小例子:我们都知道,使用浏览器"记住密码"的功能,密码会变成一堆小黑点,是不可见的。可以让密码显示出来吗?可以,只需给页面"动个小手术"!以淘宝为例,在输入密码框处右键,点击检查。

可以看到,浏览器为我们自动定位到了相应的HTML位置。将下图中的password属性值改为text属性值(直接在右侧代码处修改):

我们让浏览器记住的密码就这样显现出来了:

说这么多,什么意思呢?浏览器就是作为客户端从服务器端获取信息,然后将信息解析,并展示给我们的。我们可以在本地修改HTML信息,为网页"整容",但是我们修改的信息不会回传到服务器,服务器存储的HTML信息不会改变。刷新一下界面,页面还会回到原本的样子。这就跟人整容一样,我们能改变一些表面的东西,但是不能改变我们的基因。
2、简单实例
网络爬虫的第一步就是根据URL,获取网页的HTML信息。在Python3中,可以使用urllib.request和requests进行网页爬取。
1.urllib库是python内置的,无需我们额外安装,只要安装了Python就可以使用这个库。
2.requests库是第三方库,需要我们自己安装。
requests库强大好用,所以本文使用requests库获取网页的HTML信息。requests库的github地址:https://github.com/requests/requests
(1)requests安装
在cmd中,使用如下指令安装requests:
或者:
(2)简单实例
requests库的基础方法如下:

官方中文教程地址:http://docs.python-requests.org/zh_CN/latest/user/quickstart.htmlrequests库的开发者为我们提供了详细的中文教程,查询起来很方便。本文不会对其所有内容进行讲解,摘取其部分使用到的内容,进行实战说明。
首先,让我们看下requests.get()方法,它用于向服务器发起GET请求,不了解GET请求没有关系。我们可以这样理解:get的中文意思是得到、抓住,那这个requests.get()方法就是从服务器得到、抓住数据,也就是获取数据。让我们看一个例子(以 www.gitbook.cn为例)来加深理解:

requests.get()方法必须设置的一个参数就是url,因为我们得告诉GET请求,我们的目标是谁,我们要获取谁的信息。运行程序看下结果:

左侧是我们程序获得的结果,右侧是我们在www.gitbook.cn网站审查元素获得的信息。我们可以看到,我们已经顺利获得了该网页的HTML信息。这就是一个最简单的爬虫实例,可能你会问,我只是爬取了这个网页的HTML信息,有什么用呢?客官稍安勿躁,接下来进入我们的实战正文。
[
爬虫实战
]
1、小说下载
(1)实战背景
小说网站-笔趣看:
URL:http://www.biqukan.com/
笔趣看是一个盗版小说网站,这里有很多起点中文网的小说,该网站小说的更新速度稍滞后于起点中文网正版小说的更新速度。并且该网站只支持在线浏览,不支持小说打包下载。因此,本次实战就是从该网站爬取并保存一本名为《一念永恒》的小说,该小说是耳根正在连载中的一部玄幻小说。PS:本实例仅为交流学习,支持耳根大大,请上起点中文网订阅。
(2)小试牛刀
我们先看下《一念永恒》小说的第一章内容,URL:http://www.biqukan.com/1_1094/5403177.html

我们先用已经学到的知识获取HTML信息试一试,编写代码如下:

运行代码,可以看到如下结果:

可以看到,我们很轻松地获取了HTML信息。但是,很显然,很多信息是我们不想看到的,我们只想获得如右侧所示的正文内容,我们不关心div、br这些html标签。如何把正文内容从这些众多的html标签中提取出来呢?这就是本次实战的主要内容。
(3)Beautiful Soup
爬虫的第一步,获取整个网页的HTML信息,我们已经完成。接下来就是爬虫的第二步,解析HTML信息,提取我们感兴趣的内容。对于本小节的实战,我们感兴趣的内容就是文章的正文。提取的方法有很多,例如使用正则表达式、Xpath、Beautiful Soup等。对于初学者而言,最容易理解,并且使用简单的方法就是使用Beautiful Soup提取感兴趣内容。
Beautiful Soup的安装方法和requests一样,使用如下指令安装(也是二选一):
1.pip install beautifulsoup4
2.easy_install beautifulsoup4
一个强大的第三方库,都会有一个详细的官方文档。我们很幸运,Beautiful Soup也是有中文的官方文档。URL:
http://beautifulsoup.readthedocs.io/zh_CN/latest/
同理,我会根据实战需求,讲解Beautiful Soup库的部分使用方法,更详细的内容,请查看官方文档。
现在,我们使用已经掌握的审查元素方法,查看一下我们的目标页面,你会看到如下内容:

不难发现,文章的所有内容都放在了一个名为div的“东西下面”,这个"东西"就是html标签。HTML标签是HTML语言中最基本的单位,HTML标签是HTML最重要的组成部分。不理解,没关系,我们再举个简单的例子:
一个女人的包包里,会有很多东西,她们会根据自己的习惯将自己的东西进行分类放好。镜子和口红这些会经常用到的东西,会归放到容易拿到的外侧口袋里。那些不经常用到,需要注意安全存放的证件会放到不容易拿到的里侧口袋里。
html标签就像一个个“口袋”,每个“口袋”都有自己的特定功能,负责存放不同的内容。显然,上述例子中的div标签下存放了我们关心的正文内容。这个div标签是这样的:
细心的朋友可能已经发现,除了div字样外,还有id和class。id和class就是div标签的属性,content和showtxt是属性值,一个属性对应一个属性值。这东西有什么用?它是用来区分不同的div标签的,因为div标签可以有很多,我们怎么加以区分不同的div标签呢?就是通过不同的属性值。
仔细观察目标网站一番,我们会发现这样一个事实:class属性为showtxt的div标签,独一份!这个标签里面存放的内容,是我们关心的正文部分。
知道这个信息,我们就可以使用Beautiful Soup提取我们想要的内容了,编写代码如下:

在解析html之前,我们需要创建一个Beautiful Soup对象。BeautifulSoup函数里的参数就是我们已经获得的html信息。然后我们使用find_all方法,获得html信息中所有class属性为showtxt的div标签。find_all方法的第一个参数是获取的标签名,第二个参数class_是标签的属性,为什么不是class,而带了一个下划线呢?因为python中class是关键字,为了防止冲突,这里使用class_表示标签的class属性,class_后面跟着的showtxt就是属性值了。看下我们要匹配的标签格式:
这样对应的看一下,是不是就懂了?可能有人会问了,为什么不是find_all('div', id = 'content', class_ = 'showtxt')?这样其实也是可以的,属性是作为查询时候的约束条件,添加一个class_='showtxt'条件,我们就已经能够准确匹配到我们想要的标签了,所以我们就不必再添加id这个属性了。运行代码查看我们匹配的结果:
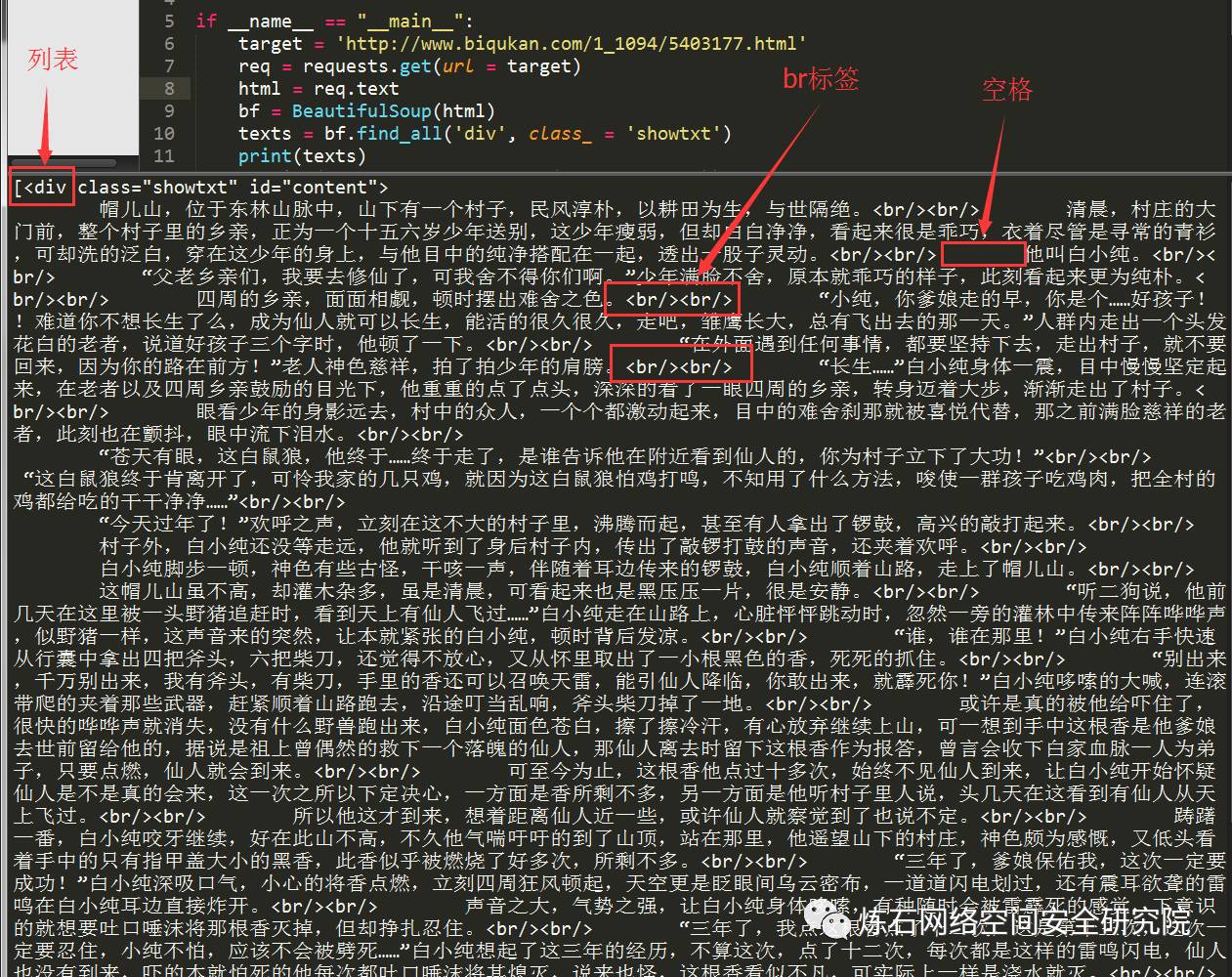
我们可以看到,我们已经顺利匹配到我们关心的正文内容,但是还有一些我们不想要的东西。比如div标签名,br标签,以及各种空格。怎么去除这些东西呢?我们继续编写代码:

find_all匹配的返回的结果是一个列表。提取匹配结果后,使用text属性,提取文本内容,滤除br标签。随后使用replace方法,剔除空格,替换为回车进行分段。 在html中是用来表示空格的。replace('xa0'*8,'nn')就是去掉下图的八个空格符号,并用回车代替:

程序运行结果如下:

可以看到,我们很自然的匹配到了所有正文内容,并进行了分段。我们已经顺利获得了一个章节的内容,要想下载正本小说,我们就要获取每个章节的链接。我们先分析下小说目录:
URL:http://www.biqukan.com/1_1094/

通过审查元素,我们发现可以发现,这些章节都存放在了class属性为listmain的div标签下,选取部分html代码如下:

在分析之前,让我们先介绍一个概念:父节点、子节点、孙节点。
限定了
- 标签和
- 标签,那么
- 标签和
-
标签就是
标签的孙节点。有点绕?那你记住这句话:谁包含谁,谁就是谁儿子!
他们之间的关系都是相对的。比如对于
-
标签,它的子节点是标签,它的父节点是标签。这跟我们人是一样的,上有老下有小。
看到这里可能有人会问,这有好多
- 标签和
python3 爬虫实例_【实战练习】Python3网络爬虫快速入门实战解析(上)相关推荐
- 【Socket网络编程进阶与实战】------ Socket网络编程快速入门
前言 本篇博客主要是分享,socket网络编程进阶与实践☞socket网络编程快速入门 一.聊一聊Socket 学习目标与收获
- 基于python的网络爬虫编程_基于Python的网络爬虫程序设计
程序设计 ●Program Design 基于 Python的网络爬虫程序设计 网络 信 息量 的迅 猛 增 长,对 如何从海量的信息中准确的搜索 到用户需要的信息提 出了极大的 挑战.网络爬 虫具有 ...
- 基于python的网络爬虫技术_基于python的网络爬虫技术的研究
龙源期刊网 http://www.qikan.com.cn 基于 python 的网络爬虫技术的研究 作者:刘文辉 李丽
- 基于python的网络爬虫系统_基于Python对网络爬虫系统的设计与实现.pdf
基于Python对网络爬虫系统的设计与实现.pdf 日期: 2020-08-02 01:17:51 人气: - 基于Python对网络爬虫系统的设计与实现软件研发与应用SOFTWARE DEVELOP ...
- python3界面实例_程序人生——python3下tkinter的界面示例
# written by wangluojisuan import tkinter from tkinter import messagebox global main_form global lbl ...
- Python3网络爬虫快速入门实战解析
Python3网络爬虫快速入门实战解析 标签: python网络爬虫 2017-09-28 14:48 6266人阅读 评论(34) 收藏 举报 分类: Python(26) 作者同类文章X 版权声明 ...
- Python3 网络爬虫快速入门实战解析
点击上方"Python高校",关注 文末干货立马到手 作者:Jack Cui http://cuijiahua.com/blog/2017/10/spider_tutorial_1 ...
- Python3网络爬虫快速入门实战解析(一小时入门 Python 3 网络爬虫)
Python3网络爬虫快速入门实战解析(一小时入门 Python 3 网络爬虫) https://blog.csdn.net/u012662731/article/details/78537432 出 ...
- python爬取公交车站数据_Python爬虫实例_城市公交网络站点数据的爬取方法
爬取的站点:http://beijing.8684.cn/ (1)环境配置,直接上代码: # -*- coding: utf-8 -*- import requests ##导入requests fr ...
最新文章
- 创业者周鸿祎前传(西安交大时期)
- pythonrequests下载大文件_Python3 使用requests模块显示下载大文件显示进度
- iOS - Frame 项目架构
- notepad++ tcl_TCL科技前三季度净利20亿元,投资并购超200亿元
- 正则控制可以输两位小数、负数,整数
- linux 架设J2EE网站过程分享之二 —— JDK安装
- Apache Shiro 使用手册(五)Shiro 配置说明
- 3年出货5000万颗!国内老牌芯片商用平头哥玄铁处理器研发新芯片
- BZOJ 1041 圆上的整点 数学
- Linux搜寻文件或目录命令解析
- 知识竞赛软件/答题系统/答题小程序
- 单龙芯3A3000-7A1000PMON研究学习-(10)撸起袖子干-pmoncfg Bonito 干了什么?(这是make cfg的部分)
- Word:退出即关机(转)
- [About Design] 各类素材网站
- java中lastmodified_Java File lastModified()用法及代码示例
- Spring Boot 2.x 基础案例:整合Dubbo 2.7.3+Nacos1.1.3(配置中心)
- html用360打不开,win7系统使用360安全卫士解决浏览器打不开的方法
- 敷衍的面试|记录问题仅供参考,不代表最终答案
- 计算机两个硬盘的作用,固态硬盘时代谈谈双硬盘(固态+机械硬盘)的好处
- 捕获iOS模拟器视频以进行App预览
热门文章
- 算法的时间复杂度(python版容易理解)+常用的时间复杂度、python代码--数据结构
- Connected to the target VM, address: ‘127.0.0.1:0‘, transport: ‘socket‘ Disconnected from the target
- JAVA-WEB开发环境和搭建
- anaconda下安装新包一直报错(‘parse() got an unexpected keyword argument 'transport_encoding'’)...
- C# File类的操作
- jquery 通过submit()方法 提交表单示例
- Atitit. 数据约束 校验 原理理论与 架构设计 理念模式java php c#.net js javascript mysql oracle...
- (None resource)-Binary system
- 【leetcode】Integer to Roman
- linux基础应用和常用技巧