sql server 分区_使用分区归档SQL Server数据
sql server 分区
The Partition feature was introduced in the SQL Server 2005. This article is to cover how partitioning can be useful when it comes to archiving of SQL Server data in a database. Please note that this article does not cover how partitioning works and its configurations in detail.
SQL Server 2005中引入了分区功能。本文旨在介绍在数据库中归档SQL Server数据时如何使用分区。 请注意,本文没有详细介绍分区的工作方式及其配置。
Database administrators face quite a few challenges during data archiving tasks. One major challenge in archiving is the impact to the databases and other requests. For example, let’s assume that you need to archive the year 2012 data from orders table. Since this is order table, you will have billions of records and year 2012 may have few millions of rows. When deleting those records, obviously it takes considerable time to delete as each delete will be a physical operation on the table. During this operation, lock escalation will occur at the table level and there will be a table lock. This means that the table will be locked during the deletion of all the records. This results that the users will not be able to access the table during this time. Therefore, in most of the cases, database administrators need special approvals and off peak time to perform this so that impact to the system is limited.
在数据归档任务期间,数据库管理员面临许多挑战。 归档的主要挑战是对数据库和其他请求的影响。 例如,假设您需要从订单表中存档2012年的数据。 由于这是订单表,因此您将拥有数十亿条记录,而2012年可能有几百万行。 删除这些记录时,显然需要花费大量时间,因为每次删除都是对表的物理操作。 在此操作过程中,锁升级将在表级别发生,并且将有一个表锁。 这意味着该表将在删除所有记录期间被锁定。 这导致用户在这段时间内将无法访问该表。 因此,在大多数情况下,数据库管理员需要特殊的批准和非高峰时间来执行此操作,从而限制了对系统的影响。
什么是SQL Server中的分区? (What is Partitioning in SQL Server?)
To overcome this types of issues, the SQL Server partition feature will be helpful to perform data archiving in an effective manner. Typically, partitioning is used to improve reading performs. It will separate rows into different “buckets”. Actually, “partitioning” represents database operations where very large tables are divided into several parts. By dividing a large table into multiple tables, queries that access only a fraction of the data can run much faster than before, because there is fewer data to scan in one partition.
为了克服这类问题,SQL Server分区功能将有助于有效地执行数据归档。 通常,使用分区来提高读取性能。 它将行分成不同的“存储桶”。 实际上,“分区”表示将非常大的表分为几部分的数据库操作。 通过将一个大表划分为多个表,仅访问一小部分数据的查询可以比以前更快地运行,因为在一个分区中要扫描的数据较少。
The main of objective of partitioning is to aid in the maintenance of large tables and to reduce the overall time to read and load data for particular user operations.
分区的主要目的是帮助维护大型表并减少用于特定用户操作的读取和加载数据的总时间。
如何创建分区? (How partitions are created?)
Let’s create the partition first. As stated before, details of partition creation will not be discussed in detail and in the case of a need you can refer to the URLs stated in the references at the end of this article.
首先创建分区。 如前所述,将不详细讨论分区创建的详细信息,在需要的情况下,您可以参考本文结尾的参考中所述的URL。
First, you need to create the partition function. The partition function will decide on the range of the data for each partition:
首先,您需要创建分区功能。 分区功能将决定每个分区的数据范围:
CREATE PARTITION FUNCTION pf_FactInternetSales_Year (int)
AS RANGE RIGHT FOR VALUES (20090101,20100101, 20110101, 20120101,20130101,20140101,20150101); Next, the partition schema is created, referring to the partition function created before. In real world implementation, the partition schema will allocate to different file groups. For the purpose of this article, only PRIMARY file group will be used for the simplicity:
接下来,参考之前创建的分区功能创建分区架构。 在实际的实现中,分区架构将分配给不同的文件组。 出于本文的目的,为了简单起见,仅使用PRIMARY文件组:
CREATE PARTITION SCHEME ps_FactInternetSales
AS PARTITION pf_FactInternetSales_Year
TO ([PRIMARY], [PRIMARY], [PRIMARY], [PRIMARY], [PRIMARY], [PRIMARY], [PRIMARY], [PRIMARY]);Next, create a table specifying partition schema and partition column. In this example, OrderDateKey is the partition key:
接下来,创建一个指定分区模式和分区列的表。 在此示例中,OrderDateKey是分区键:
CREATE TABLE [dbo].[FactSales]([ProductKey] [int] NOT NULL,[OrderDateKey] [int] NOT NULL,[DueDateKey] [int] NOT NULL,[ShipDateKey] [int] NOT NULL,[CustomerKey] [int] NOT NULL,[PromotionKey] [int] NOT NULL,[CurrencyKey] [int] NOT NULL,[SalesAmount] [money] NOT NULL,) ON ps_FactInternetSales([OrderDateKey])If you take a close look at the above script, file group is the partition schema.
如果仔细看一下上面的脚本,文件组就是分区模式。
In the case of data warehousing, datekey is derived as a combination of year, month and day. Unlike other dimensions where surrogate keys are just incremental numbers, date dimension surrogate key has a logic. Main reason to have a logic to date key is so that partition can be incorporated into these tables.
对于数据仓库,datekey是由年,月和日的组合得出的。 与其他维替代键只是增量数字不同,日期维替代键具有逻辑。 拥有逻辑上最新的键的主要原因是可以将分区合并到这些表中。
Next, populate new table with data for the demonstration purposes.
接下来,出于演示目的,用数据填充新表。
After populating data, let us verify data population in the partitioned table using the following query:
填充数据后,让我们使用以下查询来验证分区表中的数据填充:
SELECT OBJECT_NAME(p.object_id) AS ObjectName,p.Partition_Number AS PartitionNumber,PRV.Value AS RangeValue,Rows AS RowCnt
FROM sys.partitions AS p
INNER JOIN sys.indexes AS i ON p.object_id = i.object_id AND p.index_id = i.index_id
INNER JOIN sys.partition_schemes ps ON i.data_space_id=ps.data_space_id
INNER JOIN sys.partition_functions PF ON PF.function_id = ps.Function_ID
INNER JOIN sys.partition_range_values PRV ON PRV.Function_ID = Ps.Function_IDAND CASE WHEN PF.boundary_value_on_right = 1 THEN boundary_id + 1ELSE boundary_id END = p.Partition_Number
WHEREOBJECT_NAME(p.object_id) = 'FactSales'
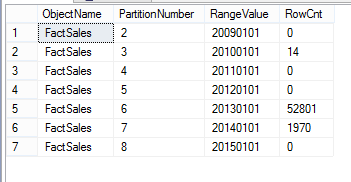
ORDER BY Partition_Number;Following is the output in which it shows a number of rows for each partition along with the range value for the partition.
以下是输出,其中显示了每个分区的行数以及该分区的范围值。
By examining above data set, let us assume that we need to archive data for the year 2011 which has around 2000 records. A traditional way of doing this is executing a delete statement where OrderDateKey is between 20110101 and 20111231. As discussed before, this will lead to various other issues thus it will not be a popular decision.
通过检查上述数据集,让我们假设我们需要存档2011年大约2000条记录的数据。 执行此操作的传统方法是执行Delete语句,其中OrderDateKey在20110101和20111231之间。如前所述,这将导致其他各种问题,因此这不是一个流行的决定。
存档SQL Server数据 (Archiving SQL Server data )
Another way of doing this is by using the SWITCH command in the partition.
另一种方法是通过在分区中使用SWITCH命令。
To archive data using the SWITCH command, you need to create same table structure in same file group as the partition that you are about to archive as shown below.
要使用SWITCH命令归档数据,需要在与要归档的分区相同的文件组中创建相同的表结构,如下所示。
CREATE TABLE [dbo].[FactSales_Archive]([ProductKey] [int] NOT NULL,[OrderDateKey] [int] NOT NULL,[DueDateKey] [int] NOT NULL,[ShipDateKey] [int] NOT NULL,[CustomerKey] [int] NOT NULL,[PromotionKey] [int] NOT NULL,[CurrencyKey] [int] NOT NULL,[SalesAmount] [money] NOT NULL,) ON [PRIMARY]Next is to switch data to newly created table.
接下来是将数据切换到新创建的表。
Let us examine the data distribution again as we did before using the same query.
让我们像在使用相同查询之前一样再次检查数据分布。
From the above image, it is clear that records for the year 2011 were deleted. With the SWITCH statement, there won’t be any table locks as there won’t be any physical data deletes. The SWITCH statement will be a meta-data change which will take less than one second to complete.
从上图可以明显看出,2011年的记录已被删除。 使用SWITCH语句,将不会有任何表锁,因为不会有任何物理数据删除。 SWITCH语句将是一个元数据更改,只需不到一秒钟即可完成。
In case you have a column store index for the partitioned table, which is quite normal in data warehouse, you need to disable the column store index before switching the partition. You need to enable the column store index until the partition switching is completed.
如果您有分区表的列存储索引(这在数据仓库中是很正常的),则需要在切换分区之前禁用列存储索引。 您需要启用列存储索引,直到分区切换完成。
Since this partition table data is moved to the newly created table, though the data is archived from the original table, the database still has the data. Some database administrators still favor this approach as it can be kept as temporary data store so that you can recover the data in case of a need.
由于此分区表数据已移至新创建的表,因此尽管该数据是从原始表中存档的,但数据库仍具有该数据。 一些数据库管理员仍然喜欢这种方法,因为它可以保存为临时数据存储,以便您可以在需要时恢复数据。
SQL Server 2016的新增功能 (What’s new in SQL Server 2016?)
In SQL Server 2016, in addition to the SWITCH command, there is an option of truncating a partition without using an additional table. In case of partition truncating, there is no requirement to disable or enable column store indexes.
在SQL Server 2016中,除了SWITCH命令之外,还可以选择不使用其他表就将分区截断。 如果分区被截断,则无需禁用或启用列存储索引。
TRUNCATE TABLE FactSales WITH ( PARTITIONS (5))With the above statement, the fifth partition will be truncated.
使用上面的语句,第五个分区将被截断。
Also, you have the luxury of truncating multiple adjacent partitions as shown in below statement.
另外,您可以将多个相邻分区截断,如下所示。
TRUNCATE TABLE FactSales WITH ( PARTITIONS ( 6 TO 7))However, you need to remember that there won’t be a backup of the archived data when you perform a partition truncation. Though there is no perform gain with the truncate statement with compared to switch statement, it is much simpler as no need for disabling column store indexes and much cleaner as you don’t need to create another temporary table.
但是,您需要记住,执行分区截断时不会备份存档数据。 尽管与switch语句相比,truncate语句没有执行收益,但是它更简单,因为不需要禁用列存储索引,并且更清洁,因为您不需要创建另一个临时表。
其他资讯 (Other Information)
In SQL Server Analysis Service (SSAS) cubes also has the partition option. If you can match the SSAS partitions to the database partitions, you can improve cube process as well.
在SQL Server Analysis Service(SSAS)中,多维数据集还具有分区选项。 如果可以将SSAS分区与数据库分区匹配,则还可以改善多维数据集处理。
翻译自: https://www.sqlshack.com/archiving-sql-server-data-using-partitions/
sql server 分区
sql server 分区_使用分区归档SQL Server数据相关推荐
- sql机器学习服务_机器学习服务–在SQL Server中配置R服务
sql机器学习服务 The R language is one of the most popular languages for data science, machine learning ser ...
- sql 2017 机器学习_使用R和SQL Server 2017进行机器学习
sql 2017 机器学习 The primitive Business Intelligence (BI) methodology has its primary focus on data sou ...
- sql azure 语法_什么是Azure SQL Cosmos DB?
sql azure 语法 介绍 (Introduction) In the Azure Portal, you will find the option to install Azure SQL Co ...
- sql初学者指南_使用tSQLt框架SQL单元测试面向初学者
sql初学者指南 tSQLt is a powerful, open source framework for SQL Server unit testing. In this article, we ...
- python中引入sql的优点_引用sql-和引用sql相关的内容-阿里云开发者社区
bboss持久层改进支持模块sql配置文件引用其它模块sql配置文件中sql语句 bboss持久层改进支持模块sql配置文件引用其它模块sql配置文件中sql语句. 具体使用方法如下: <pro ...
- sql delete删除列_现有表操作中SQL DELETE列概述
sql delete删除列 In this article, we will explore the process of SQL Delete column from an existing tab ...
- win10只有c盘怎么分区_磁盘分区:系统C盘空间不足怎么办?
一般来说,驱动器字母"C"就是我们所说的系统分区.该C盘空间不足将影响您的计算机系统的性能,程序和游戏的运行速度.因此,您必须学会如何增加C盘空间让其有更多的自由空间以优化系统程序 ...
- parted新建分区_扩展分区及文件系统(Linux)
操作场景 云硬盘是云上可扩展的存储设备,您可以在创建云硬盘后随时扩展其大小,以增加存储空间,同时不失去云硬盘上原有的数据. 云硬盘扩容 完成后,需要将扩容部分的容量划分至已有分区内,或者将扩容部分的容 ...
- 卡夫卡如何分区_通过分区在卡夫卡实现订单担保人
卡夫卡如何分区 Kafka最重要的功能之一是实现消息的负载平衡,并保证分布式集群中的排序,否则在传统队列中是不可能的. 首先让我们尝试了解问题陈述 让我们假设我们有一个主题,其中发送消息,并且有一个消 ...
最新文章
- 链表问题7——判断一个链表是否为回文结构
- centos6源码安装mysql5.6.29
- MyEclipse结合Git
- 使用vscode调试Nodejs
- caffe windows学习:第一个测试程序
- 转载:SendMessage()这个函数有很多奇妙的用途
- mysql 升级 openssl_升级openssl
- 前端学习(3121):react-hello-react的总结state
- linux mongo 服务器,如何用MongoDB在Linux服务器上创建大量连接和线程的记忆
- 7-11 分段计算居民水费 (10 分)
- 欧几里德算法(求最大公约数和最小公倍数)
- cadence17.2安装教程
- 计算机给文件重命名快捷键,计算机中文件重命名快捷键是什么
- 简析JavaScript 事件绑定、事件冒泡、事件捕获和事件执行顺序
- “全包”给装修公司,验收时发现甲醛超标,能要求重装或赔偿吗?
- logo制作软件 Ai怎么设计创意LOGO
- peerDependencies WARNING问题剖析
- 区块链主要的核心内容
- Linux伪文件系统proc
- java下载文件到服务器_java代码实现上传文件到文档服务器、下载文档服务器文件...
热门文章
- 与ea服务器连接中断770,测试ea出现 There has been a critical error 这是什么错误?如何解决? 谢谢!...
- jQuery - 获取内容和属性
- 查看windows所有exe的启动参数。
- 异常检测(Anomaly detection): 异常检测算法(应用高斯分布)
- 【软件分析与挖掘】Vision of Software Clone Management: Past, Present, and Future (Keynote Paper)...
- JS之模板技术(aui / artTemplate)
- linux编程之信号
- MDI窗体关闭问题解决一例
- 【零基础学Java】—类的定义(七)
- 小程序本地图片偶尔加载不出来_小程序优化的20中策略