我说我了解集合类,面试官竟然问我为啥HashMap的负载因子不设置成1!?
在Java基础中,集合类是很关键的一块知识点,也是日常开发的时候经常会用到的。比如List、Map这些在代码中也是很常见的。
个人认为,关于HashMap的实现,JDK的工程师其实是做了很多优化的,要说所有的JDK源码中,哪个类埋的彩蛋最多,那我想HashMap至少可以排前五。
也正是因为如此,很多细节都容易被忽视,今天我们就来关注其中一个问题,那就是:
为什么HashMap的负载因子设置成0.75,而不是1也不是0.5?这背后到底有什么考虑?
大家千万不要小看这个问题,因为负载因子是HashMap中很重要的一个概念,也是高端面试的一个常考点。
另外,这个值得设置,有些人会用错的,比如前几天我的《阿里巴巴Java开发手册建议创建HashMap时设置初始化容量,但是多少合适呢?》这篇文章中,就有读者这样回复:


既然有人会尝试着去修改负载因子,那么到底改成1是不是合适呢?为什么HashMap不使用1作为负载因子的默认值呢?
什么是loadFactor
首先我们来介绍下什么是负载因子(loadFactor),如果读者对这部分已经有了解,那么可以直接跨过这一段。
我们知道,第一次创建HashMap的时候,就会指定其容量(如果未显示制定,默认是16,详见为啥HashMap的默认容量是16?),那随着我们不断的向HashMap中put元素的时候,就有可能会超过其容量,那么就需要有一个扩容机制。
所谓扩容,就是扩大HashMap的容量:
void addEntry(int hash, K key, V value, int bucketIndex) { if ((size >= threshold) && (null != table[bucketIndex])) { resize(2 * table.length); hash = (null != key) ? hash(key) : 0;bucketIndex = indexFor(hash, table.length); } createEntry(hash, key, value, bucketIndex);
}
从代码中我们可以看到,在向HashMap中添加元素过程中,如果 元素个数(size)超过临界值(threshold) 的时候,就会进行自动扩容(resize),并且,在扩容之后,还需要对HashMap中原有元素进行rehash,即将原来通中的元素重新分配到新的桶中。
在HashMap中,临界值(threshold) = 负载因子(loadFactor) * 容量(capacity)。
loadFactor是装载因子,表示HashMap满的程度,默认值为0.75f,也就是说默认情况下,当HashMap中元素个数达到了容量的3/4的时候就会进行自动扩容。(相见HashMap中傻傻分不清楚的那些概念)
为什么要扩容
还记得前面我们说过,HashMap在扩容到过程中不仅要对其容量进行扩充,还需要进行rehash!所以,这个过程其实是很耗时的,并且Map中元素越多越耗时。
rehash的过程相当于对其中所有的元素重新做一遍hash,重新计算要分配到那个桶中。
那么,有没有人想过一个问题,既然这么麻烦,为啥要扩容?HashMap不是一个数组链表吗?不扩容的话,也是可以无限存储的呀。为啥要扩容?
这其实和哈希碰撞有关。
哈希碰撞
我们知道,HashMap其实是底层基于哈希函数实现的,但是哈希函数都有如下一个基本特性:根据同一哈希函数计算出的散列值如果不同,那么输入值肯定也不同。但是,根据同一散列函数计算出的散列值如果相同,输入值不一定相同。
两个不同的输入值,根据同一散列函数计算出的散列值相同的现象叫做碰撞。
衡量一个哈希函数的好坏的重要指标就是发生碰撞的概率以及发生碰撞的解决方案。
而为了解决哈希碰撞,有很多办法,其中比较常见的就是链地址法,这也是HashMap采用的方法。详见全网把Map中的hash()分析的最透彻的文章,别无二家。
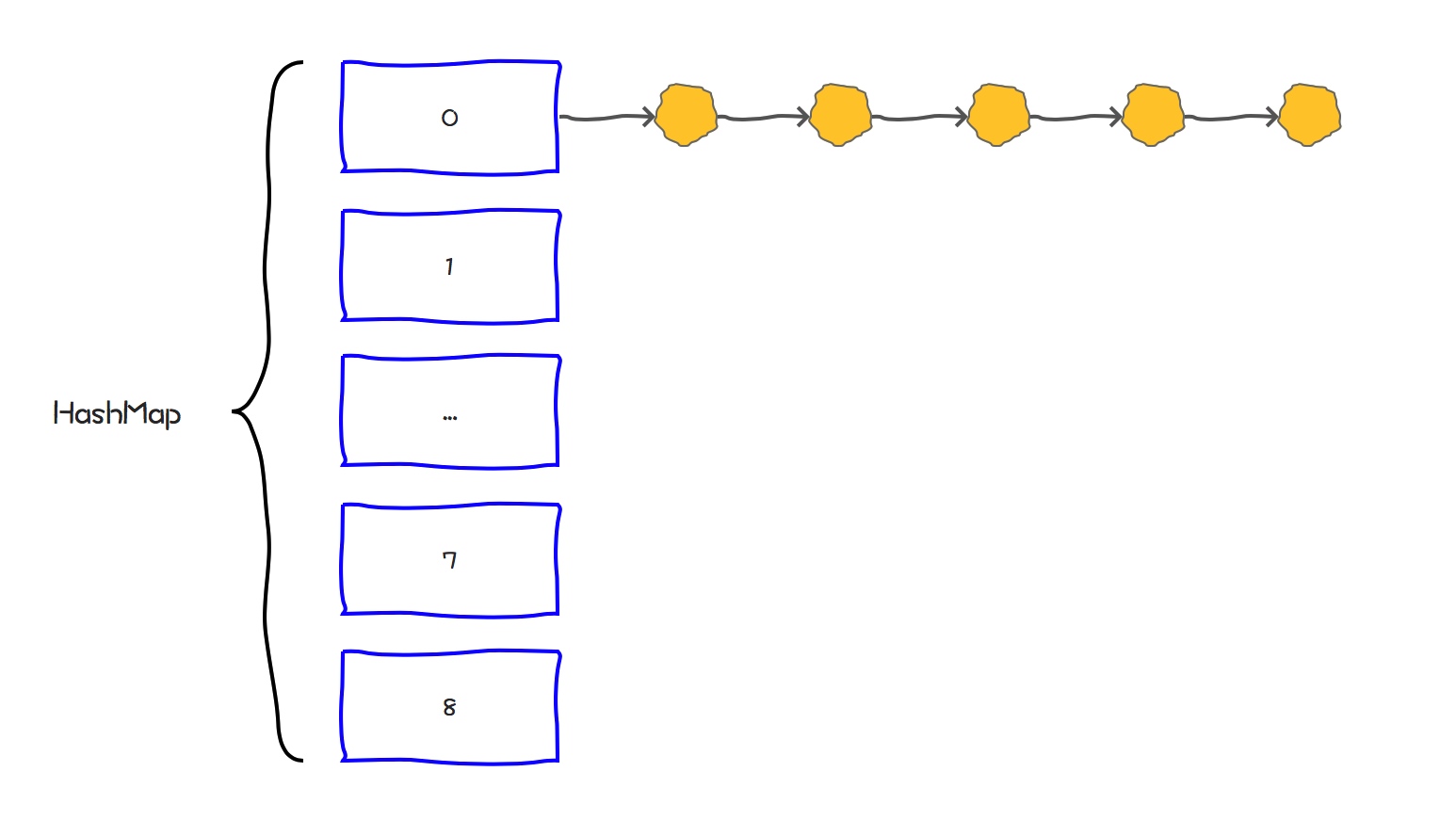
HashMap将数组和链表组合在一起,发挥了两者的优势,我们可以将其理解为链表的数组。
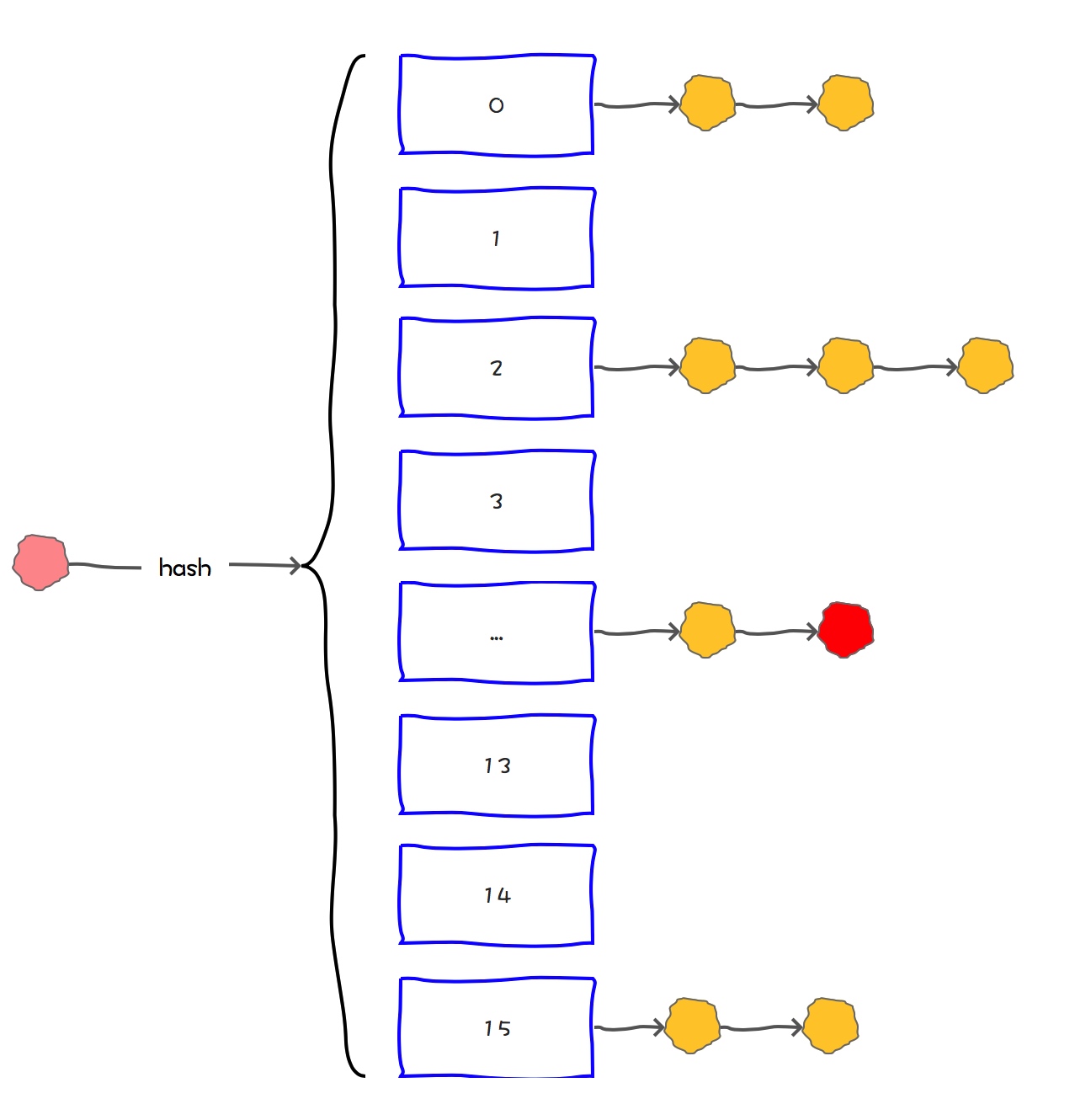 

HashMap基于链表的数组的数据结构实现的
我们在向HashMap中put元素的时候,就需要先定外到是数组中的哪条链表,然后把这个元素挂在这个链表的后面。
当我们从HashMap中get元素的时候,也是需要定位到是数组中的哪条链表,然后再逐一遍历链表中的元素,直到查找到需要的元素为止。
可见,HashMap通过链表的数组这种结构,解决了hash冲突的问题。
但是,如果一个HashMap中冲突太高,那么数组的链表就会退化为链表。这时候查询速度会大大降低。

所以,为了保证HashMap的读取的速度,我们需要想办法尽量保证HashMap的冲突不要太高。
扩容避免哈希碰撞
那么如何能有效的避免哈希碰撞呢?
我们先反向思维一下,你认为什么情况会导致HashMap的哈希碰撞比较多?
无外乎两种情况:
1、容量太小。容量小,碰撞的概率就高了。狼多肉少,就会发生争强。
2、hash算法不够好。算法不合理,就可能都分到同一个或几个桶中。分配不均,也会发生争强。
所以,解决HashMap中的哈希碰撞也是从这两方面入手。
这两点在HashMap中都有很好的提现。两种方法相结合,在合适的时候扩大数组容量,再通过一个合适的hash算法计算元素分配到哪个数组中,就可以大大的减少冲突的概率。就能避免查询效率低下的问题。
为什么默认loadFactor是0.75
至此,我们知道了loadFactor是HashMap中的一个重要概念,他表示这个HashMap最大的满的程度。
为了避免哈希碰撞,HashMap需要在合适的时候进行扩容。那就是当其中的元素个数达到临界值的时候,而这个临界值前面说过和loadFactor有关,换句话说,设置一个合理的loadFactor,可以有效的避免哈希冲突。
那么,到底loadFactor设置成多少算合适呢?
这个值现在在JDK的源码中是0.75:
/*** The load factor used when none specified in constructor.*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
那么,为什么选择0.75呢?背后有什么考虑?为什么不是1,不是0.8?不是0.5,而是0.75呢?
在JDK的官方文档中,有这样一段描述描述:
As a general rule, the default load factor (.75) offers a good tradeoff between time and space costs. Higher values decrease the space overhead but increase the lookup cost (reflected in most of the operations of the HashMap class, including get and put).
大概意思是:一般来说,默认的负载因子(0.75)在时间和空间成本之间提供了很好的权衡。更高的值减少了空间开销,但增加了查找成本(反映在HashMap类的大多数操作中,包括get和put)。
试想一下,如果我们把负载因子设置成1,容量使用默认初始值16,那么表示一个HashMap需要在"满了"之后才会进行扩容。
那么在HashMap中,最好的情况是这16个元素通过hash算法之后分别落到了16个不同的桶中,否则就必然发生哈希碰撞。而且随着元素越多,哈希碰撞的概率越大,查找速度也会越低。
0.75的数学依据
另外,我们可以通过一种数学思维来计算下这个值是多少合适。
我们假设一个bucket空和非空的概率为0.5,我们用s表示容量,n表示已添加元素个数。
用s表示添加的键的大小和n个键的数目。根据二项式定理,桶为空的概率为:
P(0) = C(n, 0) * (1/s)^0 * (1 - 1/s)^(n - 0)
因此,如果桶中元素个数小于以下数值,则桶可能是空的:
log(2)/log(s/(s - 1))
当s趋于无穷大时,如果增加的键的数量使P(0) = 0.5,那么n/s很快趋近于log(2):
log(2) ~ 0.693...
所以,合理值大概在0.7左右。
当然,这个数学计算方法,并不是在Java的官方文档中提现的,我们也无从考察到底有没有这层考虑,就像我们根本不知道鲁迅写文章时候怎么想的一样,只能推测。这个推测来源于Stack Overflor(https://stackoverflow.com/questions/10901752/what-is-the-significance-of-load-factor-in-hashmap)
0.75的必然因素
理论上我们认为负载因子不能太大,不然会导致大量的哈希冲突,也不能太小,那样会浪费空间。
通过一个数学推理,测算出这个数值在0.7左右是比较合理的。
那么,为什么最终选定了0.75呢?
还记得前面我们提到过一个公式吗,就是临界值(threshold) = 负载因子(loadFactor) * 容量(capacity)。
我们在《为啥HashMap的默认容量是16?》中介绍过,根据HashMap的扩容机制,他会保证capacity的值永远都是2的幂。
那么,为了保证负载因子(loadFactor) * 容量(capacity)的结果是一个整数,这个值是0.75(3/4)比较合理,因为这个数和任何2的幂乘积结果都是整数。
总结
HashMap是一种K-V结构,为了提升其查询及插入的速度,底层采用了链表的数组这种数据结构实现的。
但是因为在计算元素所在的位置的时候,需要使用hash算法,而HashMap采用的hash算法就是链地址法。这种方法有两个极端。
如果HashMap中哈希冲突概率高,那么HashMap就会退化成链表(不是真的退化,而是操作上像是直接操作链表),而我们知道,链表最大的缺点就是查询速度比较慢,他需要从表头开始逐一遍历。
所以,为了避免HashMap发生大量的哈希冲突,所以需要在适当的时候对其进行扩容。
而扩容的条件是元素个数达到临界值时。HashMap中临界值的计算方法:
临界值(threshold) = 负载因子(loadFactor) * 容量(capacity)
其中负载因子表示一个数组可以达到的最大的满的程度。这个值不宜太大,也不宜太小。
loadFactor太大,比如等于1,那么就会有很高的哈希冲突的概率,会大大降低查询速度。
loadFactor太小,比如等于0.5,那么频繁扩容没,就会大大浪费空间。
所以,这个值需要介于0.5和1之间。根据数学公式推算。这个值在log(2)的时候比较合理。
另外,为了提升扩容效率,HashMap的容量(capacity)有一个固定的要求,那就是一定是2的幂。
所以,如果loadFactor是3/4的话,那么和capacity的乘积结果就可以是一个整数。
所以,一般情况下,我们不建议修改loadFactor的值,除非特殊原因。
比如我明确的知道我的Map只存5个kv,并且永远不会改变,那么可以考虑指定loadFactor。
但是其实我也不建议这样用。我们完全可以通过指定capacity达到这样的目的。详见为啥HashMap的默认容量是16?
参考资料:
https://stackoverflow.com/questions/10901752/what-is-the-significance-of-load-factor-in-hashmap
https://docs.oracle.com/javase/6/docs/api/java/util/HashMap.html
https://preshing.com/20110504/hash-collision-probabilities/
我说我了解集合类,面试官竟然问我为啥HashMap的负载因子不设置成1!?相关推荐
- 原创 | 我说我了解集合类,面试官竟然问我为啥HashMap的负载因子不设置成1!?...
△Hollis, 一个对Coding有着独特追求的人△ 这是Hollis的第 254篇原创分享 作者 l Hollis 来源 l Hollis(ID:hollischuang) 在Java基础中,集合 ...
- 【Nginx】面试官竟然问我Nginx如何生成缩略图,还好我看了这篇文章!!
写在前面 今天想写一篇使用Nginx如何生成缩略图的文章,想了半天题目也没想好,这个题目还是一名读者帮我起的.起因就是这位读者最近出去面试,面试官正好问了一个Nginx如何生成缩略图的问题.还别说,就 ...
- 我说我精通字符串,面试官竟然问我Java中的String有没有长度限制!?|附视频讲解
关于String有没有长度限制的问题,我之前单独写过一篇文章分析过,最近我又抽空回顾了一下这个问题,发现又有了一些新的认识.于是准备重新整理下这个内容. 这次在之前那篇文章的基础上除了增加了一些验证过 ...
- 我说我精通字符串,面试官竟然问我Java中的String有没有长度限制!?
String是Java中很重要的一个数据类型,除了基本数据类型以外,String是被使用的最广泛的了,但是,关于String,其实还是有很多东西容易被忽略的. 就如本文我们要讨论的问题:Java中的S ...
- 今日头条面试官竟然问我new一个对象背后发生了什么?这太难了...
来源:https://url.cn/5V55xBu 一. 前言 Java在new一个对象的时候,会先查看对象所属的类有没有被加载到内存,如果没有的话,就会先通过类的全限定名来加载. 加载并初始化类完 ...
- 【建议收藏】面试官会问的位运算奇淫技巧
往期热门文章: 1.到底可不可以用 kill -9 关闭程序?2.IDEA 2021首个大版本发布,新增了这几个超实用功能!3.Optional 是个好东西,你真的会用么?4.Java 8 Concu ...
- 之前遇到一位老面试官,问我的问题真的有点东西
这篇文章其实源于一次我的面试经历. 那次我面对是一位老面试官,真的很有东西. 那次面试我和他叨叨了两小时....我滴妈我嘴巴都干了真的. 他的提问都很有深度,可以说对我的学习之路有很大的帮助. 我记得 ...
- 面试官再问我如何保证 RocketMQ 不丢失消息,这回我笑了!
0x00. 消息的发送流程 一条消息从生产到被消费,将会经历三个阶段: 生产阶段,Producer 新建消息,然后通过网络将消息投递给 MQ Broker 存储阶段,消息将会存储在 Broker 端磁 ...
- 面试官都会问的Mybatis面试题,你会这样回答吗?
一.概述 面试,难还是不难?取决于面试者的底蕴(气场+技能).心态和认知及沟通技巧.面试其实可以理解为一场聊天和谈判,在这过程中有心理.思想上的碰撞和博弈.其实你只需要搞清楚一个逻辑:"面试 ...
最新文章
- 邮件报文格式和MIME
- Flink从入门到放弃之源码解析系列-第1章 Flink组件和逻辑计划
- oracle恢复RAC到单机
- Python--上下文管理器学习(11.3)
- call and apply
- oracle awr报告生成_[ORACLE],SQL性能报告(AWR)导出,扶你走上调优大神之路
- 记录下ES6踩过的坑
- 理解Python中的with…as…语法
- u9系统的使用方法仓库_用友ERP系统,U9操作流程图
- 从零开始学习Android Framework
- Super odometry:以IMU为核心的激光雷达视觉惯性融合框架(ICRA2021)
- 测评两款升压稳压芯片
- 微信朋友圈python广告演员_Python制作微信好友背景墙教程(附完整代码)
- PHP数据加密的几种方式
- [Filecoin]协议实验室关于SNARK竞赛的公告
- 八、CSS基础选择器
- 「Python条件结构」显示学号及提示信息
- java中的package_JAVA中的PACKAGE机制——(好文转帖)
- 爬取王者荣耀高清皮肤
- java与C/C++的比较