Attention的梳理、随想与尝试
转自:https://zhuanlan.zhihu.com/p/38281113
(一)深度学习中的直觉
3 X 1 and 1 X 3 代替 3 X 3

LSTM中的门设计

Attention机制的本质来自于人类视觉注意力机制。人们视觉在感知东西的时候一般不会是一个场景从到头看到尾每次全部都看,而往往是根据需求观察注意特定的一部分。而且当人们发现一个场景经常在某部分出现自己想观察的东西时,人们会进行学习在将来再出现类似场景时把注意力放到该部分上:

将更多的注意力聚焦到有用的部分,Attention的本质就是加权。但值得注意的是,同一张图片,人在做不同任务的时候,注意力的权重分布应该是不同的。

基于以上的直觉,Attention可以用于:
- 学习权重分布:
- 这个加权可以是保留所有分量均做加权(即soft attention);也可以是在分布中以某种采样策略选取部分分量(即hard attention),此时常用RL来做;
- 这个加权可以作用在原图上,也可以作用在特征图上;
- 这个加权可以在时间维度、空间维度、mapping维度以及feature维度。
2. 任务聚焦、解耦(通过attention mask)
多任务模型,可以通过Attention对feature进行权重再分配,聚焦各自关键特征。
(二)发展历程
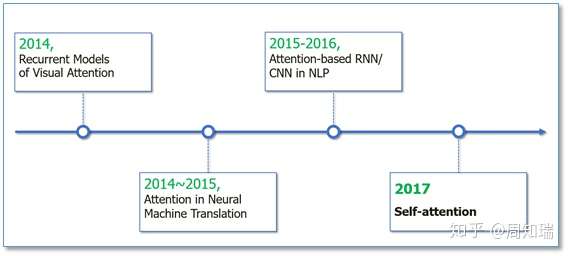
Attention机制最早是在视觉图像领域提出来的,应该是在九几年思想就提出来了,但是真正火起来应该算是2014年google mind团队的这篇论文《Recurrent Models of Visual Attention》,他们在RNN模型上使用了attention机制来进行图像分类。随后,Bahdanau等人在论文《Neural Machine Translation by Jointly Learning to Align and Translate》中,使用类似attention的机制在机器翻译任务上将翻译和对齐同时进行,他们的工作算是第一个将attention机制应用到NLP领域中。接着attention机制被广泛应用在基于RNN/CNN等神经网络模型的各种NLP任务中。2017年,google机器翻译团队发表的《Attention is all you need》中大量使用了自注意力(self-attention)机制来学习文本表示。自注意力机制也成为了大家近期的研究热点,并在各种NLP任务上进行探索。下图展示了attention研究进展的大概趋势:
(三)Attention设计
3.1 定义
Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V
Google 2017年论文Attention is All you need中,为Attention做了一个抽象定义:
An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key.
注意力是将一个查询和键值对映射到输出的方法,Q、K、V均为向量,输出通过对V进行加权求和得到,权重就是Q、K相似度。
计算Attention Weighted Value有三个步骤:
- 计算Q、K相似度得分
- 得分归一化(Attention Weight)
- 根据得分对V进行加权

3.2 分类
3.2.1 按输出分类
- Soft attention
- Hard attention
soft attention输出注意力分布的概率值,hard attention 输出onehot向量。
3.2.2 按关注的范围分类
Effective Approaches to Attention-based Neural Machine Translation
- Globle attention
全局注意力顾名思义对整个feature mapping进行注意力加权。

- Local attention
局部注意力有两种,第一种首先通过一个hard-globle-attention锁定位置,在位置上下某个local窗口进行注意力加权。

第二种是在某中业务场景下, 比如 对于一个问题"Where is the football?", "where"和"football’"在句子中起着总结性的作用。而这种attention只和句子中每个词自身相关。Location-based的意思就是,这里的attention没有其他额外所关注的对象,即attention的向量就是q本身,即Q=K,其attention score为:
$score(Q,K)=activation(W^TQ+b)$
3.2.3 按计算score的函数不同

(四)业务应用
- chatbot意图分类
采用:Self-attention + Dot-product-score
效果:

观察到:
- attention自动mask了<PAD>字符;
- 对于分类作用更大的关键词,给予了更高的attention weight;
(四)思考
- 多步负荷预测
多任务多输出模型,每步预测对于特征的关注点应该不一样,学习一个feature mapping 的mask attention。
- 异常数据mask负荷预测
在原始feature mapping 后接一个attention,自动mask 异常输入,提升模型的鲁棒性。
(六)Reference
Paper
- Hierarchical Attention Networks for Document Classification
- Attention Is All You Need
- Neural Machine Translation by Jointly Learning to Align and Translate
- Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
- Fully Convolutional Network with Task Partitioning for Inshore Ship Detection in Optical Remote Sensing Images
- Effective Approaches to Attention-based Neural Machine Translation
github
- pytorch-attention
- seq2seq
- PyTorch-Batch-Attention-Seq2seq
Blog
- 一文读懂「Attention is All You Need」| 附代码实现
- Attention Model(mechanism) 的 套路
- 【计算机视觉】深入理解Attention机制
- 自然语言处理中的自注意力机制
- Encoder-Decoder模型和Attention模型
Attention的梳理、随想与尝试相关推荐
- 遍地开花的 Attention ,你真的懂吗?
阿里妹导读:曾被 paper 中各种各样的 Attentioin 搞得晕晕乎乎,尽管零零散散地整理过一些关于Attention 的笔记,重点和线索依然比较凌乱.今天,阿里巴巴工程师楠易,将 Atten ...
- 深度学习与中文短文本分析总结与梳理
感谢原著,原文出处:https://www.cnblogs.com/wangyaning/p/7853879.html 1.绪论 过去几年,深度神经网络在模式识别中占绝对主流.它们在许多计算机视觉任务 ...
- Attention注意力机制学习(三)------->从Attention到Transformer再到BERT
关于提取特征向量这件事 视觉图像领域提特征向量的方式: 古典方式:SIFI/HOG算法 现代方式:VGG.ResNet.MobileNet等网络 自然语言处理文本领域提特征向量的方式: 较早时期:N- ...
- 阿士比亚:搜索团队智能内容生成实践
一.项目背景 1.1 什么是智能内容生成? 更准确的定义应该是智能文本内容生成,指的是训练机器模型,智能生成单品推荐理由.多商品清单文章一类的文本型内容,显然,与智能内容生成相对的概念 ...
- 怎么将一个数字高低位互换_多彩数字 多彩童年——东城幼儿园玩具研究教学案例...
玩具是儿童的天使,孩子在天使的陪伴下,创造性地进行着自己的游戏活动.在幼儿众多的玩具中怎样甄别一款好玩的玩具,挖掘出玩具的最大教育价值,让他们在和玩具的互动中快乐地学习呢?下面,我们来看看老师们是怎样 ...
- 孤读Paper——《ATSS:Adaptive Training Sample Selection》
<ATSS:Adaptive Training Sample Selection> 此论文一出感觉是在告诉像我们这样的小朋友根本没有深入理解目标检测.论文醍醐灌顶的指出了影响Ancho ...
- 淘宝总知道你要什么?万字讲述智能内容生成实践 | 技术头条
参加「CTA 核心技术及应用峰会·杭州」,请扫码报名 ↑↑↑ 作者 | 清淞 来源 | 清淞的知乎专栏 专栏地址: https://zhuanlan.zhihu.com/p/33956907 本文主要 ...
- 知识蒸馏论文读书笔记
突然觉得,我应该做一点笔记,梳理一下学过的东西,否则年一过,整个人就跟失忆了一样. 知识蒸馏这个名字非常高大上(不得不说大佬不仅想法清新脱俗,名字也起的情形脱俗啊).如果直白地说老师学生模型,那就不酷 ...
- 你关注过黑产、羊毛党吗?用户增长的另一面
文末可下载网易严选演讲PDF完整版~ 上至BAT,下到互联网初创公司,都面临羊毛党的威胁 产品总价值=活跃用户规模╳单个用户价值–异常用户损失 你知道吗,在你关注用户增长的同时,有一些黑产也在关注你. ...
最新文章
- 机器学习简单代码示例
- 成功解决 pypmml.base.PmmlError: (‘PmmlException‘, ‘Not a valid PMML‘)
- wps怎么投递简历发到boss直聘_央视新闻联合BOSS直聘带“岗”年薪超82亿元
- 使用Select.HtmlToPdf 把html内容生成pdf文件
- MongoDB文件操作(支持大于4M数据)
- php 用js 封装,JavaScript使用封装
- python 变成float32_python – Numpy将float32转换为float64
- zookeeper分布式锁原理及实现
- Jackson使用详解
- git完全cli指南之详细思维导图整理分享
- linux 如何查看fb中分辨率_西门子S71200,如何在FB块中使用操作定时器?
- 字典树 之 hdu 1247
- 详细解析RxAndroid的使用方式
- beforeunload中阻止提示关闭_React 系统中,在离开编辑页面前做提示
- 虚拟助手之争,智能音箱能否挑战智能手机?
- Playmaker节点工具使用(二)—Odin绘制支持
- SSIS 左边工具栏消失处理
- excel countifs 计算包含了空白单元格,结果错误,不对,特别大。
- DataFrame切片
- STM32 DFU下载与 DFU生成工具
热门文章
- 磁盘与文件系统管理( 认识磁盘,了解磁盘,文件系统的建立与自动挂载)
- centos下搭建网站服务器,Centos7搭建web服务器
- ajxs跨域 php_php设置header头允许ajax跨域请求
- php中的select case语句吗,VBS教程:VBScript 语句-Select Case 语句
- mysql 列目录_Linux ls命令:查看目录下文件
- 前端信息查询与显示_中国商标网查询显示的信息都是正确的吗
- 华为怎么安装服务器系统版本,服务器怎么安装操作系统版本
- java在dog中定义name变量,组合构造 冯跃峰 java中组合的应用(不相干的类共同完成一个功能)+构造器回顾...
- dncnn图像去噪_NeuNet2020:BRDNet(开源)使用深度CNN和批量归一化进行图像去噪
- mysql导出数据字典6_MySQL利用Navicat导出数据字典