爬虫技术做到哪些很酷很有趣很有用的事情
能利用爬虫技术做到哪些很酷很有趣很有用的事情?
今天突然想玩玩爬虫,就提了这个问题。跟着YouTube上的一个tutor写了个简单的程序,爬了一点豆瓣的数据。主要用到request和bs4(BeautifulSoup)模块。虽然简陋,毕竟是人生中的第一只爬虫啊……以示纪念,代码写在博客里了:我的第一只爬虫:爬取豆瓣读书
374 个回答
 Emily L,Buy Side Equity Research / HFT
Emily L,Buy Side Equity Research / HFT
2011年夏天我在google实习的时候做了一些Twitter数据相关的开发,之后我看到了一片关于利用twitter上人的心情来预测股市的论文(http://battleofthequants.net/wp-content/uploads/2013/03/2010-10-15_JOCS_Twitter_Mood.pdf)。实习结束后我跟几个朋友聊了聊,我就想能不能自己做一点twitter的数据挖掘,当时只是想先写个爬虫玩玩,没想最后开发了两年多,抓取了一千多万用户的400亿条tweet。
上分析篇
先给大家看一些分析结果吧。大家几点睡觉呢? 我们来统计一下sleep这个词在twitter上出现的频率。
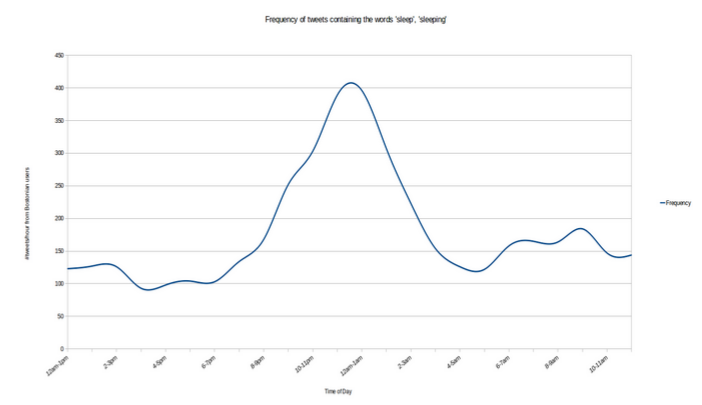
看来很多人喜欢在睡前会说一声我睡了。那我们再看一个更有意思的 :"Thursday"这个词的每天出现的频率。
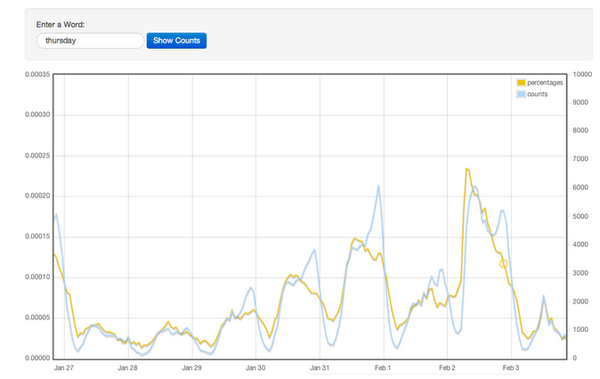
这里2月2号是周四,不出意料,这一天提到周四的频率最高。而且好像离周四越近这个频率越高。可是,为什么2月1号的频率反而低了呢?是因为2月1号大家不说周四而说明天了(有的人会说2月2号也可以说是今天,但是因为在2月2号提到当天的次数太高,因此还是有很多人用周四这个词)。
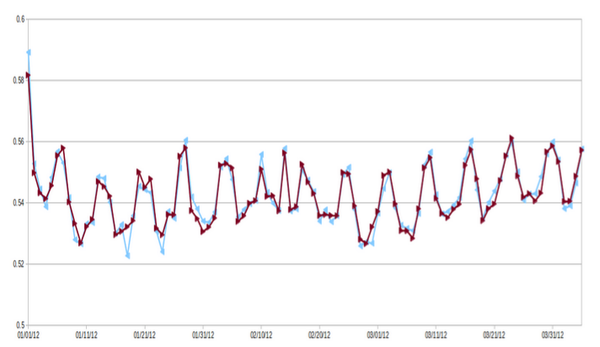
做了词频统计我们还可以做一些语义分析。我们可以利用unsupervised learning来分析一条tweet的感情色彩。我们对每一条tweet的高兴程度在0至1之间打分,并对每天做平均值,就得到了下面这张图。这里最明显的特征恐怕就是周期性了。是的,大家普遍周末比较高兴。不过这张图的开始和中间有两个点与周期不吻合。如果我告诉你这两天是1月1日和2月14日,那你肯定会想到为什么了,元旦和情人节很多人是很高兴的(不排除slient majority存在的可能)。
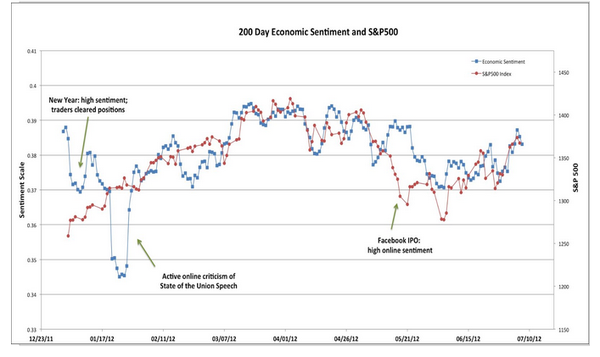
这很有意思,但似乎没什么用啊。那我们来看下面这张图,还是2012年的情感分析,不过这里对用户进行了过滤,只保留了来自投资人和交易员的tweet (根据用户的tweet我们可以估计他/她的职业)。蓝线是这些用户的感情色彩,红线是S&P 500指数。看来行情好的时候大家都高兴啊。
最后我们再来看两个统计图吧。2012年是美国大选年,这里统计了在所有和奥巴马相关的tweet里跟提到经济的tweet占的比例。红线是这个比例,黑线是S&P 500
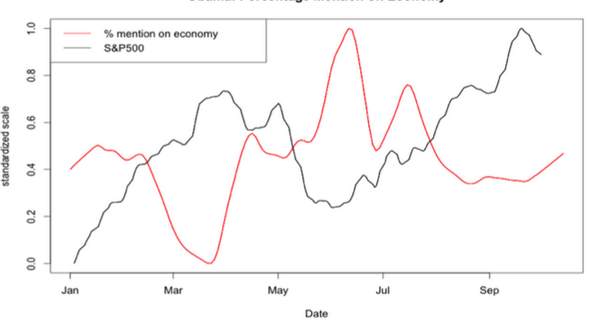
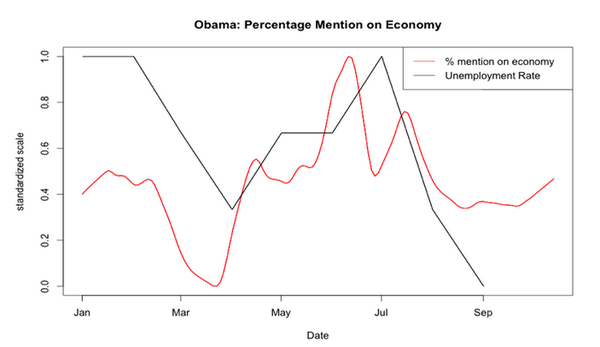
貌似和美国经济有负相关性啊!为什么呢,我们看下面的图就明白了。这个比例和美国失业率正相关,而经济和失业率又是负相关的。换句话说,美国人(尤其是共和党的)找不到工作了就开始埋怨奥巴马了。
除了上面的分析外我做了很多其他的研究,比如如何判断一个用户的职业,验证六度分隔理论, 以及网络扩张速度的建模,不过这里就先不赘述了。
最后要说的是以上的分析在统计上都是不严谨的,twitter上的信息杂音非常大,又有很强的demographic bias,有很多因素都没有考虑。我们只能希望大数定律能过弥补一些误差。写在这里只是抛砖引玉,给大家看一下爬虫可以做什么。大家感兴趣的话之后我可以补充一下这两个话题:
1. 怎样判断一条tweet的感情色彩
2. 怎样估计一个twitter用户的职业
下技术篇
当时Twitter用户大概已经有上亿了,每天新的tweet也有几千万甚至上亿。能不能把这些数据全部抓取下来呢?这是可能的。Twitter是有API的,不过每个IP地址每小时可以抓取150个用户最近的tweet,以这个速度要把几亿个用户抓取一遍需要近一百年。但是,大部分Twitter用户是不活跃甚至从来不发tweet的,还有很多用户是印尼等国家(不是他们不重要,我真的看不懂他们发的tweet),如果我们把不说英语,不发tweet以及follow人数不超过5个(好像注册twitter后用户会被要求follow 5个人)的用户过滤掉,我们就剩下了大约10,000,000个用户,十年就可以搞定了。
十年好像还是太长了。。。不过twitter的访问限制是基于IP地址的,只要我从多个IP访问twitter不久好了(我真的没有DDOS twitter的意思啊)?那么下一步就是搜集大量代理服务器来访问twitter api。为了做twitter的爬虫我专门做了一个爬虫去搜集免费代理服务器。免费的东西总是有代价的,这些服务器非常不稳定。因此我又建立了一套代理服务器管理系统,定期更新IP地址,删除不能用的服务器。最后这套系统平均每天有几百个可用的服务器,大约半个月就可以把一千万个用户抓取一遍了。
此外我又做了一些动态优化,根据twitter用户的follower数量决定他们的抓取频率,以提高重要用户tweet的实时性。
在一年半的时间里,这套系统一共抓取了400亿条tweet,加起来得有10TB,估计占来自美国tweet数量的一半左右。那么问题来了,怎么存贮这些tweet呢?如果要做分析的话恐怕把数据读一遍就要好几天了。很多人马上会说hadoop, cassandra, spark等等。不过作为一个穷学生我哪里有钱去做一个cluster呢?这些数据存在AWS上就得每月1000刀了。
自己动手,丰衣足食。解决方案就是自己组装一个服务器,买了8块3T硬盘做了一个12TB的磁盘矩阵放在寝室里。

软件使用了最为传统的MySQL,这是一个存了400亿条数据的MySQL数据库。我花了大量时间去做优化,尝试了各种各样的partition, ordering, indexing。最后可以实现一天之内对100-200亿条数据进行线型搜索或过滤,或者几秒钟内调取某一天的或某一条tweet。
这台服务器现在留在了MIT,毕业后我把它提供给了一位教授做研究。
PS:
这个项目在2013年停止了,因为social media已经不在火,而且twitter于2013年中关闭了相关的API接口。
这个项目的初衷是学术性质的,我不想违反twitter的服务条款,因此这些数据没有被出售或者用来谋求商业价值,而是留给了MIT做研究。
在这期间与几个朋友进行了很愉快的合作,未征得他们允许就不在此提名了。
暂时没有开源的打算,因为当时水平有限,代码写得太丑了(用java写的)。
PS2:
很多人问怎么找代理服务器,请大家google一下吧。当然如果不能翻墙的话有代理服务器恐怕也不能用。
谢绝转载。
收藏 • 没有帮助 •
• 禁止转载
 刘飞,想当作家的工科男
刘飞,想当作家的工科男
1. 建立机器翻译的语料库。
这是我研究生期间的核心课题,我先来介绍下背景。
大家其实都用过谷歌翻译、百度翻译,虽然确实槽点很多,但不妨碍机器翻译相较过去已经达到基本可用的程度了。
我大概说下机器翻译的原理。
在几十年前,计算机学家们的思路是,既然是人工智能的范畴,就让计算机懂得语法规则、知道词语含义,跟小孩子上学时学习的语言课程一样去做训练,就应该可以了。
但结果是,基于语义和语法规则的机器翻译效果糟糕得一塌糊涂。
究其原因,还是每个词语的含义实在太多、每句话的语境不同意思也会不同,更别说不同语言中要表达清楚同一个意思的方式也完全不同。
比如下图这个,你觉得英语国家的人能看懂吗:

其实,当时也有另一派,叫做统计派。他们认为,就跟当年战胜国际象棋世界冠军的“深蓝(深蓝(美国国际象棋电脑))”一样,应当用统计的方式去做。大家知道,“深蓝”并没有领会象棋的下法,而只是熟悉几百万的棋局,懂得怎样走从概率上看起来是最正确的。
机器翻译也是这样,完全可以输入人工翻译的大量语料,然后做出统计模型,让计算机尽可能地熟悉别人是怎么翻译的,从而耳濡目染,也能“假装”可以翻译了。
但那个年代并没有条件收集大量语料信息。后来很多年后,谷歌出现了,随之出现的还有它的超大数据规模和超强的计算能力,于是谷歌的统计机器翻译系统也就是全球正确率最高的系统之一了。而目前你所用过的、见到的机器翻译工具,全都是用的统计方法。
故事大概就是这样。目前学术界的机器翻译方法中,统计机器翻译基本是垄断的地位。而效果的好坏,则基本就看语料库的规模。(想了解更多,推荐阅读 数学之美 (豆瓣) 的第2章“‘自然语言处理 — 从规则到统计”及第3章“统计语言模型”)
所以你知道了,我的任务就是跟同学做一个爬虫和简易的分析系统,从而建立一个大规模的语料库。
网上双语的资源还是挺多的,大都像这种:

我们的爬取步骤大概是:
1. 对当前网页进行简易判断,如果有双语嫌疑,则收录整理出来双语的正文;如果没有,弃用;
2. 将正文内容进行详细判断,确定是双语文本,则进行段落对齐和句子对齐,整理到语料库;如果没有,弃用;
3. 对当前网页的所有链接网页,重复步骤 1
有详细介绍的我们申请的专利在这里:http://www.soopat.com/Patent/201210442487
其实我们当时的双语判断算法和对齐算法这些都不是难点,难点在机器配置、爬虫设计和服务器维护上。我们几乎天天流窜在机房(配置机器、接线、装机)、实验室(编写、运行代码)、网络中心(跪求带宽)、学校物业(空调他妈又坏了)这几个地方,总是没法消停。
最痛苦的是,假期里回家远程访问下爬虫,发现 down 机了... 整个假期的宝贵时间就浪费了。
这是我们当时在又闷又热又吵的机房的照片:

好在最后我们终于爬到了要求的语料规模,并且通过了国家项目的验收。现在这些包括中英俄日的庞大语料正在百度翻译中起到重要的作用,如果你用过百度翻译,不妨给我点个感谢 ^_^
如果你对机器翻译感兴趣,也可以自己爬点双语语料,做个翻译器玩玩。这是一个极其简易的搭建教程:机器翻译系统的搭建。可以用它介绍的 1500 句对,也可以自己多爬一些。搭建好之后,你输入一句话,看到机器像模像样地回一句半生不熟的翻译,还是有可能会被萌到的。
当然,要是你希望像我们一样搭建千万级甚至亿级的语料库,并且做一个翻译器,那你需要有特别强大计算能力和存储能力的服务器、非常宽的带宽,以及强大的耐心和毅力...
2. 社会计算方面的统计和预测
很多朋友已经提到了可以通过爬虫得到的数据做一些社会计算的分析。我们实验室爬取了大规模的新浪微博内容数据(可能是非商用机构中最多的),并针对这些数据做了很多有趣的尝试。
2.1 情绪地图
@Emily L 提到了著名的根据情绪预测股市的论文:http://battleofthequants.net/wp-content/uploads/2013/03/2010-10-15_JOCS_Twitter_Mood.pdf 。其实我们也仿照做了国内的,不过没有预测,只是监测目前微博上大家的情绪,也是极有趣的。
我们把情绪类型分为“喜悦”“愤怒”“悲伤”“恐惧”“惊奇”,并且对能体现情绪的词语进行权重的标记,从而给每天每个省份都计算出一个情绪指数。
界面大概是这样:
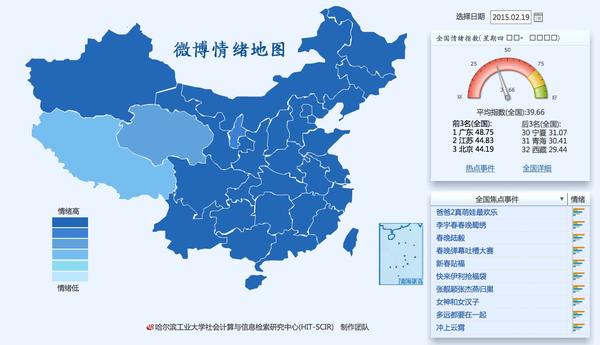
可以直观看到全国各省份的情绪。不过实际上我感觉省份的区别不明显,最明显的是每天全国情绪指数的变动。
比如春节是 2 月 18 日,那天的情绪指数是 41.27,前一天是 33.04,后一天则是 39.66。跟除夕夜都在吐槽和抱怨春晚,而大年初一则都在拜年情绪高涨,初二有所回落这样的状况预估是一致的。
比如今年 1 月 2 日,上海踩踏事故开始登上各大媒体头条,成了热点话题,整个微博的情绪指数就骤降到 33.99 。
再比如 5 月份情绪指数最高的是 5·20,因为今年开始流行示爱和表白;其次就是五一假期那几天。同样跟现实状况的预估是一致的。
访问地址:http://123.126.42.100:5929/flexweb/index.html
2.2 饮食地图
我们抽取出所有美食相关词语,然后基于大家提到的美食次数,做了这么一份饮食地图。你可以查看不同省份、不同性别的用户、不同的时间段对不同类别食物的关注程度。
比如你可以看到广东整体的美食关注:

还可以把男的排除掉,只看女的:
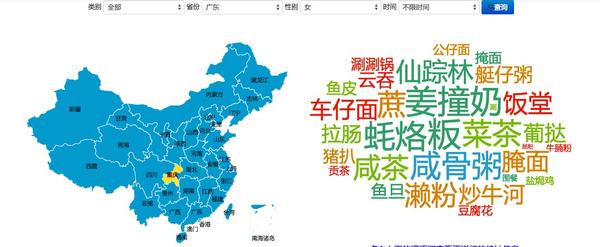
还可以具体到,看广东女性每天早上会提到什么喝的:
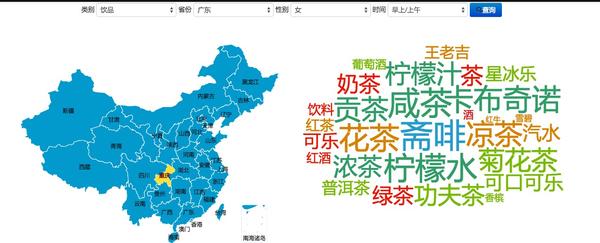
访问地址:微博用户饮食习惯分析
2.3 票房预测
这是我们实验室最大胆的尝试,希望利用微博上大家表现出来的,对某部电影的期待值和关注度,来预测其票房。
细节就不介绍了,目前对某些电影的预测比较准,某些则差很多。因为显然,很多电影是大家不用说也会默默买票,而很多电影是大家乐于讨论但不愿出钱到电影院去看的。
界面是这样的:
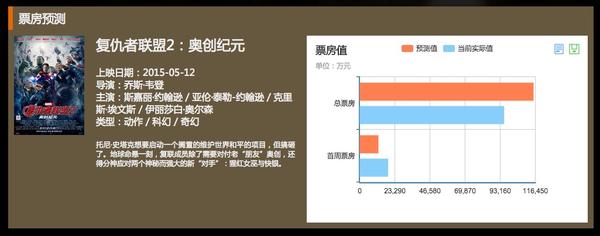
访问地址:电影票房预测-SCIR
最后贴上我们实验室的官方网站:哈尔滨工业大学社会计算与信息检索研究中心
3. 写在后面
现在国内的社交平台(微博、豆瓣、知乎)已经积累了很多信息,在上面可分析的事情太多啦。大到政府部门需要的舆情监控,小到可以看看喜欢的姑娘最近情绪如何。
其中有些会特别有价值,比如一些重要的预测(股市预测、票房预测),真的做成了的话商业价值根本不可估量;还有些会特别有趣,比如看看 5·20 的时候大家最爱说的情话是什么,看看我跟李开复之间最近的关系链是什么。
说到这,我突然很想做个知乎的分析。
在内容方面,比如看看全知乎的文字里最常出现的人名到底是 @张佳玮还是 @梁边妖;比如看看政治或者历史话题下,以表达情绪的词作为依据,大家的正能量多还是负能量多;比如看看当大家提到哪些东西时,情绪会最激动(中医?老罗?穆斯林?)。
在关系方面,比如看看我的朋友、传说中认识所有知乎女 V 的谁谁谁到底还有哪个女 V 没有关注;比如看看知乎有哪些社交达人,虽然没多少赞但关系链却在大 V 们中间;比如看看有没有关注了我同时还被 @朱炫 关注的,这样我可以托他给我介绍大师兄。
有没有人一起来嗨?让我看到你的手!

收藏 • 没有帮助 •
• 作者保留权利
 夏狗冬孙子
夏狗冬孙子
dung_beetle/get_tieba.py at master · ZhangHang-z/dung_beetle · GitHub
然后尝试着更复杂一点的匹配,抓取豆瓣电影上新片榜, 口碑榜, 票房榜,也没有涉及到登录,复杂了全用正则就好像有点麻烦,也许我的水平不够,这时我发现了BeautifulSoup这个库。
dung_beetle/get_doubant.py at master · ZhangHang-z/dung_beetle · GitHub
我想试试登录,就参考别人的代码登录豆瓣,但是urllib,urllib2不是那么好用。。
dung_beetle/login_douban1.py at master · ZhangHang-z/dung_beetle · GitHub
所以我就用requests,简直是一键安装的效果。
dung_beetle/login_douban.py at master · ZhangHang-z/dung_beetle · GitHub
我作为新手一直喜欢用for循环一路走到底,但是循环的效率不怎么样,这时就开始尝试学习多线程库的使用了,一开始我想爬XX的,但是一直连接失败,无奈随便找了个论坛。原本如果用for循环需要100s, 多线程10s就好了。
dung_beetle/forum_crawler1.py at master · ZhangHang-z/dung_beetle · GitHub
这几天我考虑写稍大一点的东西,毕竟掌握一门语言的语法,库的使用要靠不断的写,碰到各种问题,才知道怎么解决。所以准备写个爬取知乎的爬虫,但是目前不尽人意。
ZhangHang-z/gzhihu · GitHub
效果:可把问题答案写入文件,但除了文本外,无法处理图片。

收藏 • 没有帮助 •
• 作者保留权利
 张航,LivePay.my
张航,LivePay.my
App有iOS版和Android版,可以下载并查看教学文档和习题文件,老师有新的通告也会发推送给同学们,还可以查看成绩,课程表,考试时间,个人财务,校园新闻,出勤率等。
目前基本全校都在使用。 一个人开发了两个月。App名字叫MMUBee
开发这个App,我一毛钱都没赚,每年还赔进去四百多美元的开发者注册费和VPS租用费。两个月里也基本上起早贪黑的做。没太多原因,就是喜欢做东西。
我不经常去上课,不过去的时候都可以看见大家在用MMUbee,有一次一个同学打开MMUbee然后对着我说,你快来下载MMUbee,It's awesome!,我说这是我开发的,他没反应过来,过了5秒钟,一脸兴奋的问我Are u kidding me?类似的事情还有很多,比如在上课的时候老师会说,大家不许把考试答案发在MMUbee里。
MMUbee的校友圈里,前两个月90%的Post都是好评。Twitter和Facebook上也都是同学们的一片叫好声,校内论坛更是沸沸扬扬了一段时间。虽然MMUbee本身没有盈利,却给我带来了很多机遇,通过这些机遇做了一个上市公司的项目,赚了一大笔。
MMUbee Android: MMUbee - Android Apps on Google Play
MMUbee iOS: MMUbee on the App Store on iTunes
在我做了这件事情之后 , 她觉得我越来越懂她了 , 嘻嘻
有一天 , 我发现我心仪已久的妹纸在朋友圈里分享了知乎专栏的文章 , 就知道她也刷知乎 . 如果在知乎上关注她 , 我就能知道 , 她最近关注什么 , 心里想些什么 , 了解了解她喜欢的方面 , 还能作为谈资 , 简直太赞了(*^^)v .
但是输入她的名字...... 在知乎上根本找不到好吗 (๑`灬´๑)
我们两个聊天的时候 , 刚好说到了她分享的那篇文章 ,
我很自然的说: "知乎上你用的不是真名呀, 就我这么天真用了真名.."
她笑着说:"那个可以改呀" ,
"凭什么知乎团队不让我改啊!!! ",我答道," 不如我们互粉吧^_- "
哎 , 于是她打开zhihu , 看了看我的主页 , 并没有关注我...... 可能是赞太少了吧... 达不到她的要求 , 或者她不想让我知道她在看什么吧 , 也许她希望自己的知乎是交浅言深 , 不希望被身边人看见... (๑-﹏-๑) 失望.
我回去想了想 , 她说名字可以改 , 那她可能以前也用的是真名 , 找到破绽了!
知乎的名字可以改 , 但是id是改不了的 !
(ps: 谢知友 @黑白异象@嘿嘿我在这儿@也之 纠正错误 这个id我记得以前是不能改的 , 现在叫做个性域名是默认的 , 但是可以改. 详见 2015-6-22更)
每个人的主页地址 , people后面那个就是TA的id,
http://www.zhihu.com/people/zhang-san-12-45
例如张三同名很多 , 后面就会加上数字. 她的名字拼音相同的较多 , 我试了一下 , 这个数字是不超过100的. 它的组合方式有 zhang-san , zhang-san-1 zhang-san-12-43 依次类推.
好 , 现在我就可以开始寻找她的账号了! 既然她改名了 , 那她名字满足的条件一定是: 昵称的拼音不是真名. 这个用pypinyin模块可以解决 , 这样子 , 需要我人工查看的主页就少很多了.
1. 在github上 下载 @egrcc 的zhihu-python
2. 寻找她了ing
# coding: utf-8from zhihu import User
from pypinyin import pinyin, lazy_pinyin
import pypinyinuser_url = ''
user_id = ''
l = [u'bu', u'xu', u'kan']#这里是她名字的拼音, 还是不要暴露她的好, (*/ω\*)
for num in range(100): #先在 -100以内搜索try:user_url = 'http://www.zhihu.com/people/bu-xu-kan-' + str(num)user = User(user_url)user_id = user.get_user_id()if l != lazy_pinyin(user_id.decode('gbk')): #看看她有没有用原名print user_id, ' ', numexcept:passfor i in range(100): for j in range(100): #在 -100-100以内搜索try:user_url = 'http://www.zhihu.com/people/bu-xu-kan-' + str(i) + '-' + str(j)user = User(user_url)user_id = user.get_user_id()print user_id, ' ', i, '-', jexcept:pass
爬了好久 , 结果出来了 , 这些昵称不多 , 我翻翻他们的主页就幸运地找到了我心仪的妹纸:
XXXXXXXX 26
XXXXXXXX 27
XXXXXXXX 42
XXXXXXXX 72
XXXXXXXX 94
she is here! 6 - 36
XXXXXXXX 6 - 76
XXXXXXXX 7 - 86
XXXXXXXX 10 - 35
XXXXXXXX 28 - 67
XXXXXXXX 32 - 28
XXXXXXXX 32 - 66
XXXXXXXX 34 - 75
从那之后 , 我每天都可以看她的主页啦~ 至于我有没有追到她呢....
--------------------------2015-06-17更--------------------------------------------------------------------
我匿名的原因是因为我正在追她 , 如果我追到 , 或者没追到她 , 我就不匿了.
在我打开她的主页之后 , 我发现她喜欢科幻 , 也对推理小说感兴趣 , 关注穿衣打扮方面 , 符合我的胃口呀 . 最近呢 , 她关注情感方面的问题变多了 , 我不知道是不是因为最近我和她联系变频繁了 , 激起了她一些感觉 , (*/ω\*)
我会加油哒~
--------------------------2015-06-22更--------------------------------------------------------------------
知友 @黑白异象@嘿嘿我在这儿@也之 纠正错误 . 这个id我记得以前是不能改的 , 现在叫做个性域名是默认的 , 大部分人没有注意 , 但是可以改. 具体修改在这里知乎 - 与世界分享你的知识、经验和见解 , 不想被相同方法发现的人赶紧修改哦~
嘿 , 上周约她出来吃饭看电影啦 , 我会继续努力哟~
--------------2015-6-24-----------------
今天,我和她 @viview 快乐地在一起辣~
收藏•没有帮助•
•作者保留权利 收起
 林骏翔,金融投资/PS/Python
林骏翔,金融投资/PS/Python
 我当初是看到这个帖子才知道Python这门语言的功能,才开始去学的,现在也学了一小段时间。不得不说,Python爬虫对于我来说真是个神器。之前在分析一些经济数据的时候,需要从网上抓取一些数据下来,想了很多方法,一开始是通过Excel,但是Excel只能爬下表格…显示全部
我当初是看到这个帖子才知道Python这门语言的功能,才开始去学的,现在也学了一小段时间。不得不说,Python爬虫对于我来说真是个神器。之前在分析一些经济数据的时候,需要从网上抓取一些数据下来,想了很多方法,一开始是通过Excel,但是Excel只能爬下表格…显示全部
废话说多了,说说自己的学习经历吧。也给想学Python,想写爬虫的人一个参考。
一开始我是在网易云课堂上自己找了个基础的视频来学,Python是真是门简单的语言,之前懂一点Visual Basic,感觉Python也很适合给无编程基础的人学习。
入门视频到最后,就做出了我的第一个爬虫——百度贴吧图片爬虫(相信很多的教程都是以百度贴吧爬虫为经典例子来说的。)
一开始代码很简单,只能爬取第一页的数据,于是我加了一个循环,就能够爬取制定页数的图片了。并且图片是有按顺序排列的,非常方便。在筛选网址的时候用正则表达式就好了。正则表达式使用:[精华] 正则表达式30分钟入门教程
<img src="https://pic3.zhimg.com/c3d851cf4625bcf3ef1781935930068a_b.png" data-rawwidth="821" data-rawheight="405" class="origin_image zh-lightbox-thumb" width="821" data-original="https://pic3.zhimg.com/c3d851cf4625bcf3ef1781935930068a_r.png">
可是我不经常混贴吧啊,也很少有要下载贴吧图片的需求。回归初衷吧。我对投资有兴趣,学编程有一个原因也是为了投资服务。在7月股灾进行时的时候,我错过了一个明显的“捡钱”的机会,并非自身专业知识不够,而是当时在准备考试,很少去看股市,这让我心有不甘:要是有个东西能够帮我自动爬取数据分析并推送就好了,于是有了以下学习轨迹:
一、爬取数据
在此顺便贴上一个Python系列教程http://www.jikexueyuan.com/path/python/,极客学院,里面有些教程还是挺不错的。从里面我知道了两个可以替代Python里urllib和re正则表达式的库,它们分别叫做requests和lxml。
第一个库挺不错的,现在在获取网页源代码时,我都用这个库,大家如果有不懂的可以看看那个网站。第二个库由于我是用3.4版本的Python,折腾了很久没折腾进去,于是我发现了另一个不错的库BeautifulSoup,详细教程参考:Python爬虫入门八之Beautiful Soup的用法
有了requests和Beautifulsoup,基本上可以实现我想要的很多功能了。我便做了一个抓取分级基金数据的爬虫: <img src="https://pic2.zhimg.com/0f4e91f08f610a489d270de3ca0dbfe5_b.png" data-rawwidth="135" data-rawheight="147" class="content_image" width="135">
二、分析并推送
其实在此分析其实还谈不上,顶多算是筛选。(不过我相信随着我数学能力提升会能有进一步的分析的,美好的祝愿。。。)筛选很简单,就是涨幅或收益率等等满足一定条件就保留下来,保留下来干嘛?推送啊!!!
将保存下来的数据通过邮件发送到自己的邮箱,手机上下载个软件,一切就大功告成了!
至此当时学习Python的目的就达到了,当时鸡冻地要炸了!!!
不过……那么好玩的东西,怎么能这么快就结束了?再折腾吧!于是
<img src="https://pic3.zhimg.com/7df5f981bfd355e714cf62f8879a5ac6_b.png" data-rawwidth="247" data-rawheight="167" class="content_image" width="247"> <img src="https://pic2.zhimg.com/d78838f147284aa31be394ca4200cd71_b.png" data-rawwidth="119" data-rawheight="151" class="content_image" width="119">
<img src="https://pic2.zhimg.com/d78838f147284aa31be394ca4200cd71_b.png" data-rawwidth="119" data-rawheight="151" class="content_image" width="119">
三、简单的界面
等等!Python好像不能直接弄成exe可执行文件,不能每次运行都开Python的窗口啊!强迫症怎么能忍!上网搜搜发现有诸如py2exe的包可以转换,可是老子是3.4版本啊!折腾半天没搞定,算了!我不是会点VB吗,用那个吧。于是连界面都有了
<img src="https://pic4.zhimg.com/d0de98a3c5da1ab129d314c93d8e846f_b.png" data-rawwidth="742" data-rawheight="158" class="origin_image zh-lightbox-thumb" width="742" data-original="https://pic4.zhimg.com/d0de98a3c5da1ab129d314c93d8e846f_r.png">
刚好会点PS,做做低级的界面也不错。
四、云服务器
做完界面我以为就结束了,我还是too young啊。用了几天发现,我总不能天天开着电脑让它就运行那么几个程序吧?总得有个地方能让我24小时运行这些程序。本来想跟朋友的电脑轮流运行,还是太麻烦。偶然的机会我发现了云服务器这个东西。了解后砸下重金买下服务器(其实一个月30而已……)
<img src="https://pic2.zhimg.com/02bf5699867aac2f128f1afc80b5bae9_b.png" data-rawwidth="966" data-rawheight="444" class="origin_image zh-lightbox-thumb" width="966" data-original="https://pic2.zhimg.com/02bf5699867aac2f128f1afc80b5bae9_r.png"> 折腾一番linux系统的操作,实现了24小时的实时推送。 折腾一番linux系统的操作,实现了24小时的实时推送。
折腾一番linux系统的操作,实现了24小时的实时推送。
而到这里,我已经深陷到Python里了,我觉得我应该继续学习这门强大简单的语言,在知乎上看到了一个问题:Quant 应该学习哪些 Python 知识? - 薛昆Kelvin 的回答,虽然说的是Quant但也为我指引了一些方向。目前正准备学习numpy,pandas,matplotlib这些库,以实现未来对金融、经济数据的可视化和分析。相关的内容有一本书写得还不错,叫《利用Python进行数据分析》,有兴趣学习可以读一读。
共勉。
—————————2015.9.23更新—————————
好多人问是什么服务器,我用的是阿里云。有些人反应价格很高,其实把配置调到最低,可以满足基本需求,价格只要30左右。
正好刚刚收到一封邮件,学生党有福利了
<img src="https://pic2.zhimg.com/824422a2ae7b3c6a907c74fef088f769_b.png" data-rawwidth="798" data-rawheight="162" class="origin_image zh-lightbox-thumb" width="798" data-original="https://pic2.zhimg.com/824422a2ae7b3c6a907c74fef088f769_r.png">
(我真的不是在打广告啊……)
—————————2015.10.2更新—————————
快破千赞了,有点出乎意料,补充几点吧。
1.我用阿里云发现最低的也要100/80/40(各种价格),答主你不是在骗我吧?
<img src="https://pic4.zhimg.com/43a9f2e31c6496e6492505b7eb1f2107_b.png" data-rawwidth="1280" data-rawheight="510" class="origin_image zh-lightbox-thumb" width="1280" data-original="https://pic4.zhimg.com/43a9f2e31c6496e6492505b7eb1f2107_r.png">直接上图,32元左右。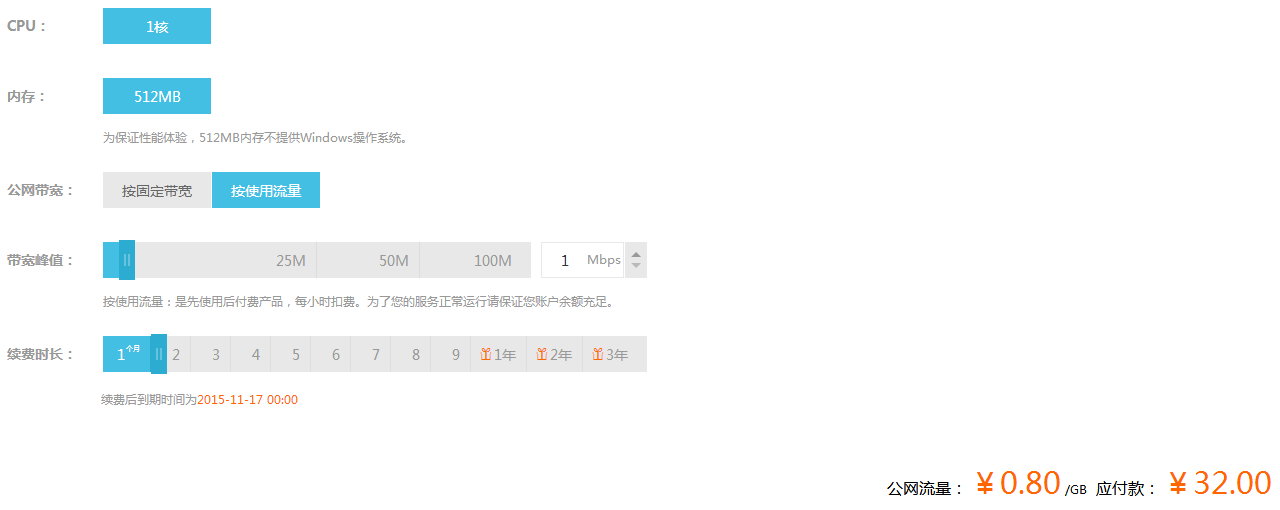 直接上图,32元左右。
直接上图,32元左右。
其实国内的服务器有挺多的,一个月三四十的低配很多地方都买得到。不过评论区有人提到一些外国个人的云服务器价格有些在30~50/年,很便宜。答主暂时还没去看,因为买的服务器还没过期,有需要的可以翻翻评论区看看。
(另外,亚马逊好像有免费一年的云服务器试用。)
2.Python3也可以转成exe
我只是按照自己的学习轨迹写的回答,当初是在不知道云服务器的情况下才有转化成exe的需求,并且当时了解得不多,屡屡碰壁没能完成。现在已经不需要了,不过还是谢谢大家的提醒。
这里顺便提醒一下,各位初学Python务必装入pip,不要像我一样怕麻烦,结果导致一些库花了好长时间才折腾进去,其实只要“pip install XXX”就很轻松搞定了。
3.从哪里爬来的数据?
见另一个回答:
有哪些网站用爬虫爬取能得到很有价值的数据? - 林骏翔的回答
收藏•没有帮助•
•禁止转载 收起
 SameOl,我是来搞笑的
SameOl,我是来搞笑的
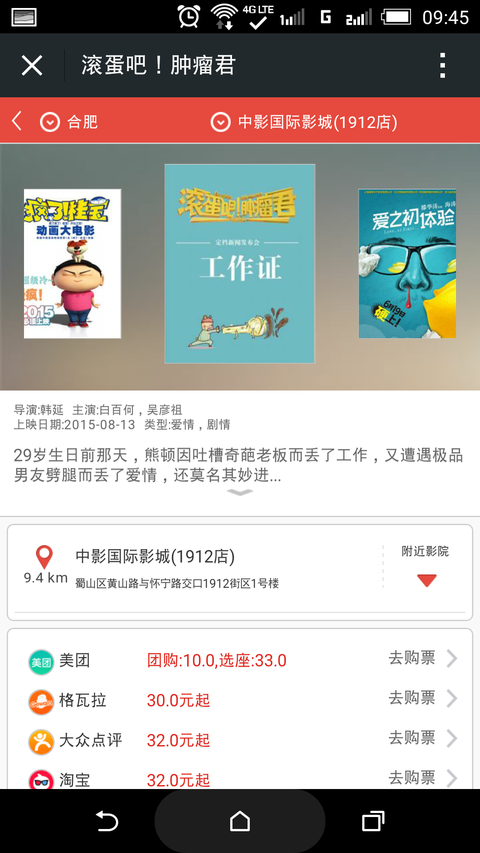 现放出下载地址,选电影稍后会有微信号公布-----------------------------------------------------------------------------------------------------------------------------------------利用爬虫抓取猫眼,大众点评,淘宝,糯米四个平台的电影院,排片…显示全部
现放出下载地址,选电影稍后会有微信号公布-----------------------------------------------------------------------------------------------------------------------------------------利用爬虫抓取猫眼,大众点评,淘宝,糯米四个平台的电影院,排片…显示全部
稍后会有微信号公布
-----------------------------------------------------------------------------------------------------------------------------------------
利用爬虫抓取猫眼,大众点评,淘宝,糯米四个平台的电影院,排片以及电影票票价数据,现已集成到微信公众号中,进入微信公众号中获取当前位置,选中某一部电影根据当前位置获取附近影院以及每个影院各个票价的对比,然后根据数据去最便宜的平台买票!先占个坑,明天上图,上数据。
各位同学不要着急,由于外网服务器爬虫已经停了一段时间数据不是最新的,这两天我在优化爬虫程序,猫眼的接口这两天对票价字段进行了混淆!明天一定上数据
---------------------------------------------------------2015-08-20更新---------------------------------------------------------
先上图吧。
<img src="https://pic3.zhimg.com/61c0956690d2e33a93612eafe9f42516_b.jpg" data-rawwidth="1080" data-rawheight="1920" class="origin_image zh-lightbox-thumb" width="1080" data-original="https://pic3.zhimg.com/61c0956690d2e33a93612eafe9f42516_r.jpg">这张是微信里的截图(信号和电量图标不知道会不会逼死处女座的)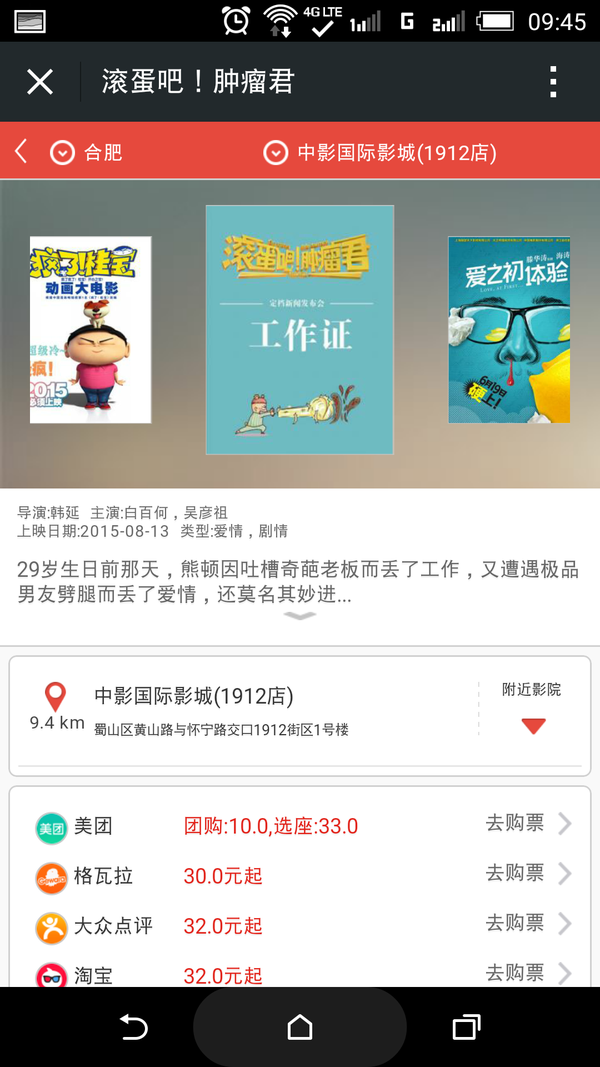 这张是微信里的截图(信号和电量图标不知道会不会逼死处女座的)
这张是微信里的截图(信号和电量图标不知道会不会逼死处女座的)
再来张数据库里的字段
<img src="https://pic2.zhimg.com/49fbd7be345a69a76bea5be4c4a7be05_b.jpg" data-rawwidth="925" data-rawheight="236" class="origin_image zh-lightbox-thumb" width="925" data-original="https://pic2.zhimg.com/49fbd7be345a69a76bea5be4c4a7be05_r.jpg">除了美团其他数据基本都是准确的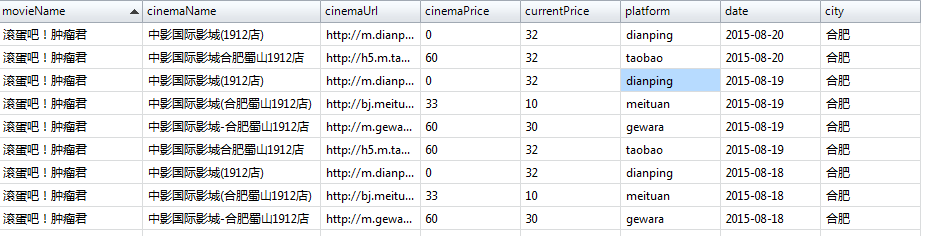 除了美团其他数据基本都是准确的
除了美团其他数据基本都是准确的
点评的
<img src="https://pic1.zhimg.com/a393ebedfad7784821871b14d4913f48_b.jpg" data-rawwidth="757" data-rawheight="552" class="origin_image zh-lightbox-thumb" width="757" data-original="https://pic1.zhimg.com/a393ebedfad7784821871b14d4913f48_r.jpg">淘宝电影的]格瓦拉的(上海的同学可能用格瓦拉的可能比较多)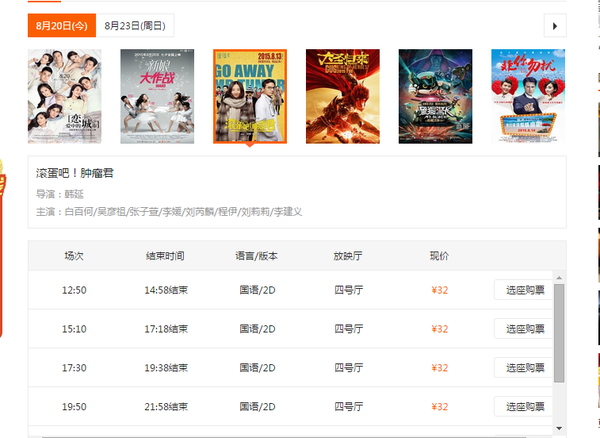 淘宝电影的]格瓦拉的(上海的同学可能用格瓦拉的可能比较多)
淘宝电影的]格瓦拉的(上海的同学可能用格瓦拉的可能比较多)
<img src="https://pic3.zhimg.com/e03b4a50a73badc598297accf44f7a52_b.jpg" data-rawwidth="953" data-rawheight="737" class="origin_image zh-lightbox-thumb" width="953" data-original="https://pic3.zhimg.com/e03b4a50a73badc598297accf44f7a52_r.jpg">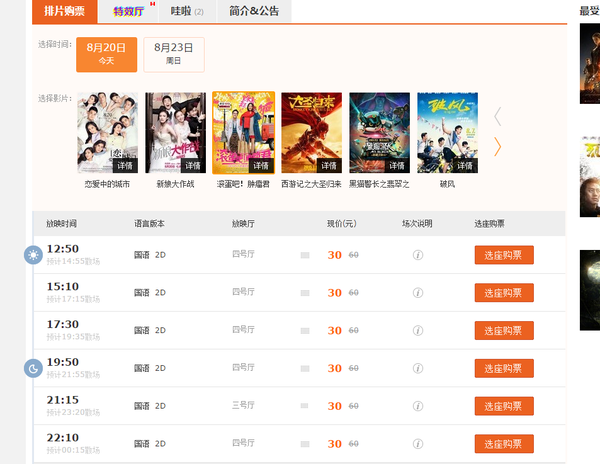
这个爬虫是5月份写的,偶尔在跑,爬的数据比较粗糙,爬的时间也比较长,除了美团,其他的平台基本都没多大问题,美团上个周末对票价数据进行了混淆,导致爬出的数据有问题,这个星期开始重构这个爬虫,以后可能会上线个更精细的版本,也会增加其他平台的票价数据!
微信号就先不上了,等重构后的版本上线,我再放出微信号。
------------------------------10.9更新------------------------------
先上个图吧,糯米这6.6的票实在太狠了,从美团和点评合并来看,糯米200亿的补贴已经有了成效。
后台代码基本重构完成,近期我会放出地址,请大家再等一等
<img src="https://pic4.zhimg.com/d8d0572c856afd1c44030e053cd5c727_b.jpg" data-rawheight="960" data-rawwidth="540" class="origin_image zh-lightbox-thumb" width="540" data-original="https://pic4.zhimg.com/d8d0572c856afd1c44030e053cd5c727_r.jpg">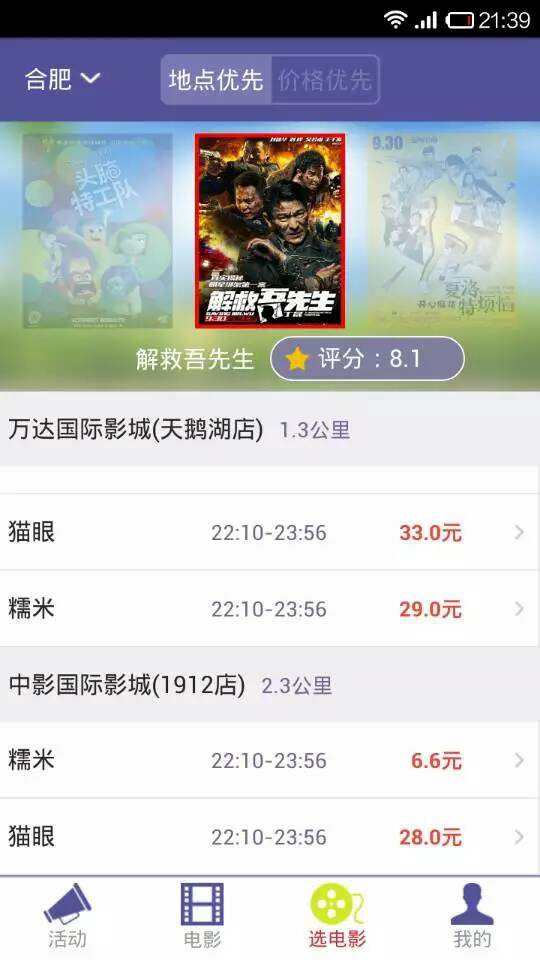
---------------------------------------------------10.10更新---------------------------------------------------------------------
让大家久等了,下载地址在最上面,app很毛糙,欢迎来喷,大家请只关注选电影模块就行了,其他的请无视。微信号稍后会更新,如果核心比价模块有问题欢迎来反馈!
收藏•没有帮助•
•作者保留权利 收起
 grapeot,人生苦短 我用Python
grapeot,人生苦短 我用Python
 可以带逛呀!爬了知乎12万用户的头像,把长得像的头像放在一起,方便浏览:http://lab.grapeot.me/zhihu/touxiang/bai-yuan-yuan-73.html然后搜集了知友们的点击,预测出来这是你们(平均)最喜欢的人长的样子:然后根据点击数据训练出来了一个带逛机器人,可以自动识别美女:http://lab.grapeot.me/zhihu/autoface…显示全部
可以带逛呀!爬了知乎12万用户的头像,把长得像的头像放在一起,方便浏览:http://lab.grapeot.me/zhihu/touxiang/bai-yuan-yuan-73.html然后搜集了知友们的点击,预测出来这是你们(平均)最喜欢的人长的样子:然后根据点击数据训练出来了一个带逛机器人,可以自动识别美女:http://lab.grapeot.me/zhihu/autoface…显示全部
爬了知乎12万用户的头像,把长得像的头像放在一起,方便浏览:http://lab.grapeot.me/zhihu/touxiang/bai-yuan-yuan-73.html
然后搜集了知友们的点击,预测出来这是你们(平均)最喜欢的人长的样子:
<img src="https://pic3.zhimg.com/92278c2f4a284bafb01d939e4fc4f6fa_b.png" data-rawwidth="320" data-rawheight="320" class="content_image" width="320">
然后根据点击数据训练出来了一个带逛机器人,可以自动识别美女:
<img src="https://pic2.zhimg.com/db6a06ea0ea3c0cdf6aefb7207ea19e9_b.png" data-rawwidth="600" data-rawheight="311" class="origin_image zh-lightbox-thumb" width="600" data-original="https://pic2.zhimg.com/db6a06ea0ea3c0cdf6aefb7207ea19e9_r.png"> http://lab.grapeot.me/zhihu/autoface
http://lab.grapeot.me/zhihu/autoface
更详细的信息可以参见我的专栏文章:
带逛传万世 因有我参与 - 挖掘知乎里有趣的东西 - 知乎专栏
你们最爱的知乎头像 - 挖掘知乎里有趣的东西 - 知乎专栏
头像带逛 - 挖掘知乎里有趣的东西 - 知乎专栏
收藏•没有帮助•
•作者保留权利 收起
 何明科,喜欢用爬虫抓数据
何明科,喜欢用爬虫抓数据
 用爬虫最大的好处是批量且自动化得获取和处理信息。对于宏观或者微观的情况都可以多一个侧面去了解(不知道能不能帮统计局一些忙)。以下是我们自己用爬虫获得的信息然后做的呈现。(多图预警)1、获得各个机场的实时流量2、获得热点城市的火车票情况3、各…显示全部
用爬虫最大的好处是批量且自动化得获取和处理信息。对于宏观或者微观的情况都可以多一个侧面去了解(不知道能不能帮统计局一些忙)。以下是我们自己用爬虫获得的信息然后做的呈现。(多图预警)1、获得各个机场的实时流量2、获得热点城市的火车票情况3、各…显示全部
(多图预警)
1、获得各个机场的实时流量
<img src="https://pic3.zhimg.com/adbee8589f03b1f4edd58e6c80a82fe6_b.jpg" data-rawwidth="1190" data-rawheight="744" class="origin_image zh-lightbox-thumb" width="1190" data-original="https://pic3.zhimg.com/adbee8589f03b1f4edd58e6c80a82fe6_r.jpg">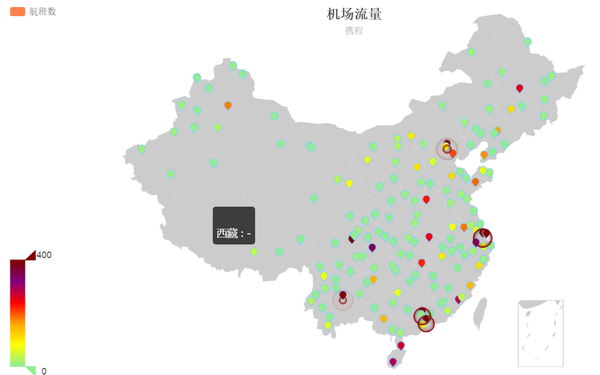
2、获得热点城市的火车票情况
<img src="https://pic1.zhimg.com/47e2545e510ccce3d6a31827f1755c34_b.jpg" data-rawwidth="705" data-rawheight="653" class="origin_image zh-lightbox-thumb" width="705" data-original="https://pic1.zhimg.com/47e2545e510ccce3d6a31827f1755c34_r.jpg">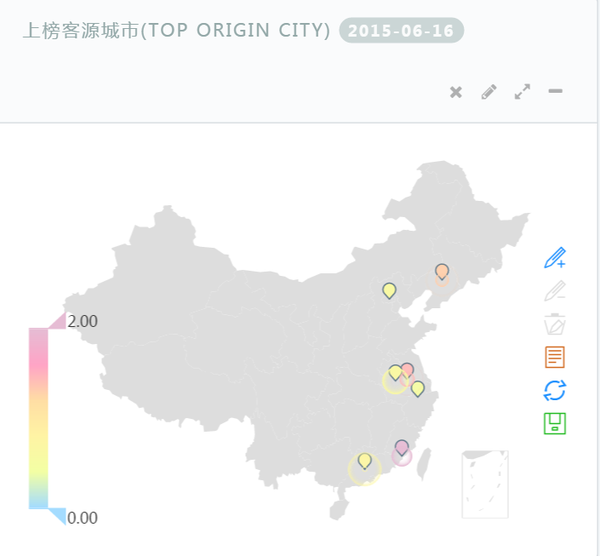
3、各种热门公司招聘中的职位数及月薪分布
<img src="https://pic3.zhimg.com/8aa8fc1babe66f6a89e603a9ed7f60aa_b.jpg" data-rawwidth="707" data-rawheight="591" class="origin_image zh-lightbox-thumb" width="707" data-original="https://pic3.zhimg.com/8aa8fc1babe66f6a89e603a9ed7f60aa_r.jpg">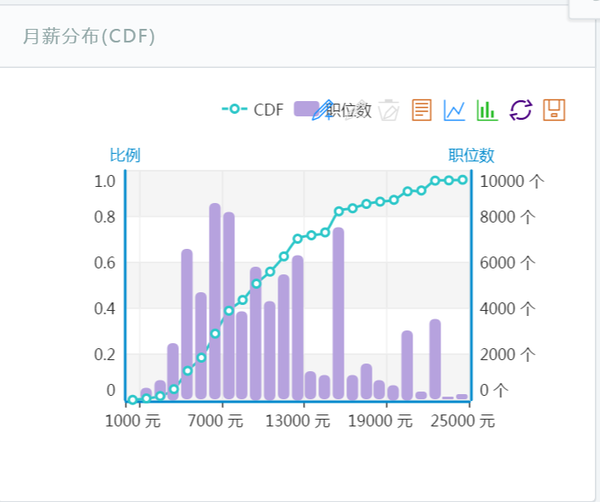
4、某公司的门店变化情况
<img src="https://pic2.zhimg.com/cb19bace7864b680b325203ebe5ce71d_b.jpg" data-rawwidth="1409" data-rawheight="799" class="origin_image zh-lightbox-thumb" width="1409" data-original="https://pic2.zhimg.com/cb19bace7864b680b325203ebe5ce71d_r.jpg">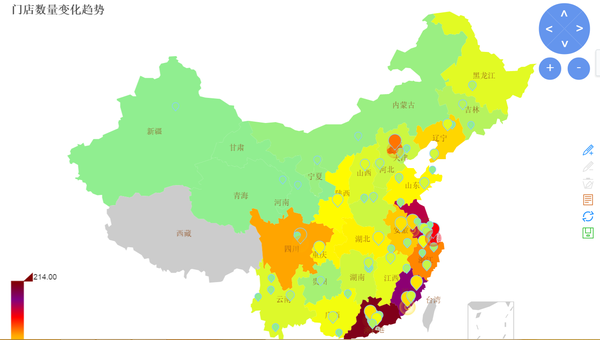
5、对某一类金融产品的检测和跟踪
<img src="https://pic2.zhimg.com/49d24f9303436a786074734e23d1a3f9_b.jpg" data-rawwidth="697" data-rawheight="809" class="origin_image zh-lightbox-thumb" width="697" data-original="https://pic2.zhimg.com/49d24f9303436a786074734e23d1a3f9_r.jpg">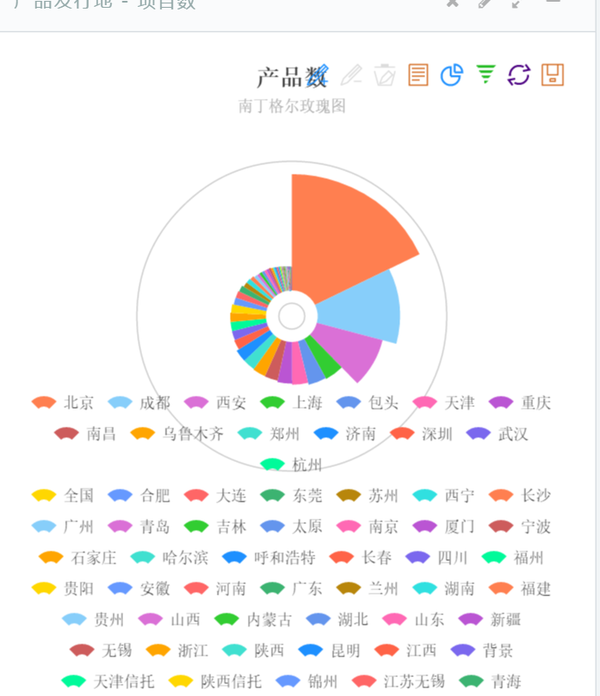
6、对某车型用户数变化情况的跟踪
<img src="https://pic3.zhimg.com/9c0eb28f3b5321578a9efa2cea7d49a2_b.jpg" data-rawwidth="1447" data-rawheight="563" class="origin_image zh-lightbox-thumb" width="1447" data-original="https://pic3.zhimg.com/9c0eb28f3b5321578a9efa2cea7d49a2_r.jpg">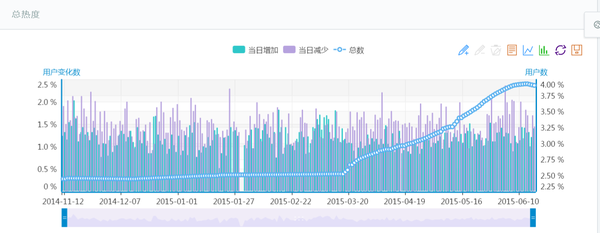
7、对某个App的下载量跟踪
<img src="https://pic1.zhimg.com/ace11806119acbe204b9193dfce2c378_b.jpg" data-rawwidth="679" data-rawheight="595" class="origin_image zh-lightbox-thumb" width="679" data-original="https://pic1.zhimg.com/ace11806119acbe204b9193dfce2c378_r.jpg">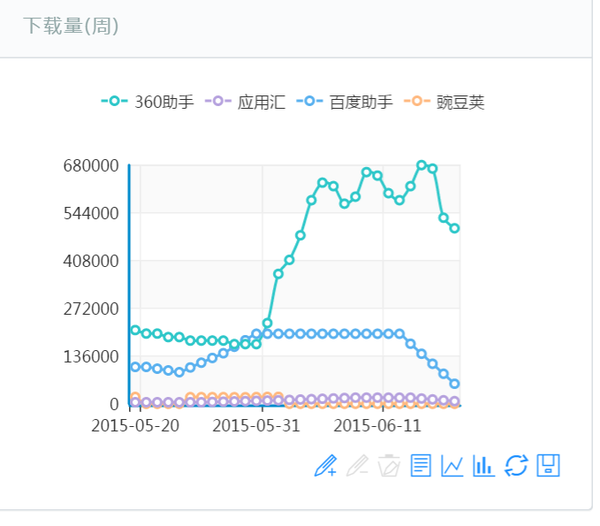
收藏•没有帮助•
•作者保留权利 收起
 知乎用户,汪
知乎用户,汪
 彩蛋:彩蛋已关闭,人太多,已经发不过来了- -本机和VPS不管频率间隔多慢,仍然不断被屏蔽,粗略算了一下多出的3000人如果发完可能要到下周了,所以停掉了骚瑞为后来的同学解释一下彩蛋怎么回事,顺便对昨晚12点之后收不到彩蛋的同学抱歉(鞠躬),由于人…显示全部
彩蛋:彩蛋已关闭,人太多,已经发不过来了- -本机和VPS不管频率间隔多慢,仍然不断被屏蔽,粗略算了一下多出的3000人如果发完可能要到下周了,所以停掉了骚瑞为后来的同学解释一下彩蛋怎么回事,顺便对昨晚12点之后收不到彩蛋的同学抱歉(鞠躬),由于人…显示全部
彩蛋:
彩蛋已关闭,人太多,已经发不过来了- -
本机和VPS不管频率间隔多慢,仍然不断被屏蔽,粗略算了一下多出的3000人如果发完可能要到下周了,所以停掉了
骚瑞
为后来的同学解释一下彩蛋怎么回事,顺便对昨晚12点之后收不到彩蛋的同学抱歉(鞠躬),由于人太多,已经发不出去了- -
- 彩蛋是如果赞了这条答案会自动收到一条随机的私信,里面是一则短笑话
- 笑话是在某网站上爬下来的,一共几十条随机发送
起因是昨天写完原答案,突然想到如果加上彩蛋会不会很多人点赞(说我不是骗赞自己也不信)
于是写了个小脚本,跑了起来试了一下
第一次高潮出现在回答完30分钟后,突然多了一两百的赞,由于私信发送时间间隔太短,挂掉了
修复后坚持到了晚上十二点,本机和VPS都不能再持续发送私信,于是停掉了
今早起来发现赞又多了3000,崩溃的我决定还是不接着发了。。。
代码和逻辑如下:
// 代码不全,只有主要的逻辑
// 用到的库如下:var request = require('superagent');
var cheerio = require('cheerio');
var fs = require('fs');// 首先是这样的一个接口,可以取到某个答案所有赞同的人数
// 每次取会返回10条数据,是编译好的HTML模版,还有下一组数据的地址
// 遍历这10条数据并取到所有人的ID即可
// config 是Cookie、Host、Referer等配置var sourceLink = 'https://www.zhihu.com/answer/' + code + '/voters_profile';function getVoterList(link, fn) {var next = '';if (postListLength && !sleepIng) {console.log('waiting');sleepIng = true;return setTimeout(function () {sleepIng = false;sleep = 1;getVoterList(link, fn);}, 1000 * 60);}request.get(link).set(config).end(function (err, res) {if (err || !res.ok) {return console.log(err);}var result = JSON.parse(res.text), voterList = '', $;if (result.paging && result.paging.next) {next = result.paging.next;}if (result.payload && result.payload.length) {voterList = result.payload.join('');$ = cheerio.load(voterList);$('.zm-rich-follow-btn').each(function () {var id = $(this).attr('data-id');if (voterIdList.indexOf(id) === -1 && oldIdList.indexOf(id) === -1) {console.log('new id: ', id);voterIdList.push(id);} else {dupIdLen += 1;}});}if (next && dupIdLen < 20) {setTimeout(function () {getVoterList('https://www.zhihu.com' + next, fn);}, 3000);} else {dupIdLen = 0;fn();}});
}// 在爬取完该接口后,新的点赞人数会暂存在数组中,遍历该数组,并发送请求
// 如请求发送成功,将各ID保存在某一个文件中,如发送失败,等几分钟后重试function sendPost() {var hasError = false;var tempArr = [];postListLength = voterIdList.length;console.log('send post');if (voterIdList.length) {voterIdList.forEach(function (id, i) {if (hasError) {// 处理发送失败的情况,等待5分钟重试if (!sleepIng) {console.log('waiting');sleepIng = true;return setTimeout(function () {sleepIng = false;sleep = 1;sendPost();}, 1000 * 60 * 5);}return console.log('has error');}var index = (function () {return i;})(i);var postIndex = index > postList.length ? index % postList.length : index;setTimeout(function () {// 一波发送完成之前不会启动下一波私信发送postListLength--;request.post('https://www.zhihu.com/inbox/post').send({member_id: id,content: postList[postIndex],token: '',_xsrf: '' // 这里是发送者的Cookie}).set(config).set({"Accept": "*/*"}).set({"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8"}).end(function (err, res) {console.log('hasError: ', hasError);console.log(new Date());console.log(res.text);var resObj = {};try {resObj = JSON.parse(res.text);} catch (e) {console.log(e);if (!sleepIng) {hasError = true;sleep = 5;console.log('waiting');sleepIng = true;return setTimeout(function () {sleepIng = false;sleep = 1;sendPost();}, 1000 * 60 * 5);}}if (err || !res.ok || resObj.r !== 0) {console.log(err);hasError = true;sleep = 5;tempArr = voterIdList.slice(0, index);oldIdList = oldIdList.concat(tempArr);fs.writeFile('./idlist.json', oldIdList, function (err) {if (err) console.log(err);});}});}, 20 * 1000 * index * sleep);if (index === voterIdList.length - 1) {console.log('last');oldIdList = oldIdList.concat(voterIdList);voterIdList = [];setTimeout(function () {console.log('run again');getVoterList(sourceLink, sendPost);}, 1000 * 60 * 15);fs.writeFile('./idlist.json', oldIdList, function (err) {if (err) console.log(err);});console.log('done ');}});} else {setTimeout(function () {console.log('run again');getVoterList(sourceLink, sendPost);}, 1000 * 60);}
}
代码花了半个小时写的,比较糙,不过跑了一下确实能用,既然已经不发了就不改了,有同学要求就发上来了
PS 知乎的策略应该有变化,昨晚12点之前只要对同一个人两条私信不重复,把握好发送时间间隔就没问题,12点之后我的VPS已经不能用了,时间间隔再久也会返回500错误,1点后我的本机也不行了,不断的返回500和403,Cookie也有更新,索性就停掉了
这是昨晚爬到的ID
&lt;img src="https://pic3.zhimg.com/c5b1bfc4f8fc2788d4fd7d5aad081a0e_b.png" data-rawwidth="1270" data-rawheight="906" class="origin_image zh-lightbox-thumb" width="1270" data-original="https://pic3.zhimg.com/c5b1bfc4f8fc2788d4fd7d5aad081a0e_r.png"&gt;
还有我的视角所看的我的私信列表= =
&lt;img src="https://pic3.zhimg.com/e77934b2365659981ca660990d0d9b66_b.png" data-rawwidth="730" data-rawheight="905" class="origin_image zh-lightbox-thumb" width="730" data-original="https://pic3.zhimg.com/e77934b2365659981ca660990d0d9b66_r.png"&gt;
就酱
==============================
某人有一天书荒了,想要看豆瓣上的高分书,然而豆瓣并没有提供按评分的检索,于是拜托我写一个小东西,要求是能按现有标签来分类检索豆瓣图书,并按分数从高到低排序
需求不难,就是数据没有,于是写了个爬虫按标签爬下来豆瓣所有的书
爬的时候只爬了分类的列表,这样有书籍的名称,链接,评分,分类,够用了,而且一次请求可以拿到较多的数据,并发不高的情况下能较快的爬完豆瓣所有的书
爬数据的时间大概两个多小时左右,每次请求间隔3秒,倒是没被屏蔽
代码用node写的,包括外网访问的服务器,基本满足了某人的需要,现在跑在我自己的VPS上,有域名可以直接访问
爬完知道豆瓣热门标签下大概有6万多本书,是会不断更新的,所以还要定期爬一下更新一下数据
下面是预览,时间所限页面写的糙了点,反正用户就一个- -
&lt;img src="https://pic3.zhimg.com/8f321ad177b7f820d98aa71c3c0f9aca_b.png" data-rawwidth="1661" data-rawheight="964" class="origin_image zh-lightbox-thumb" width="1661" data-original="https://pic3.zhimg.com/8f321ad177b7f820d98aa71c3c0f9aca_r.png"&gt;
&lt;img src="https://pic4.zhimg.com/9c6b853653c8247f316393a3fccb5053_b.png" data-rawwidth="1663" data-rawheight="964" class="origin_image zh-lightbox-thumb" width="1663" data-original="https://pic4.zhimg.com/9c6b853653c8247f316393a3fccb5053_r.png"&gt;
&lt;img src="https://pic2.zhimg.com/fcf79abbadc896c6874fe2309a91503d_b.png" data-rawwidth="434" data-rawheight="777" class="origin_image zh-lightbox-thumb" width="434" data-original="https://pic2.zhimg.com/fcf79abbadc896c6874fe2309a91503d_r.png"&gt;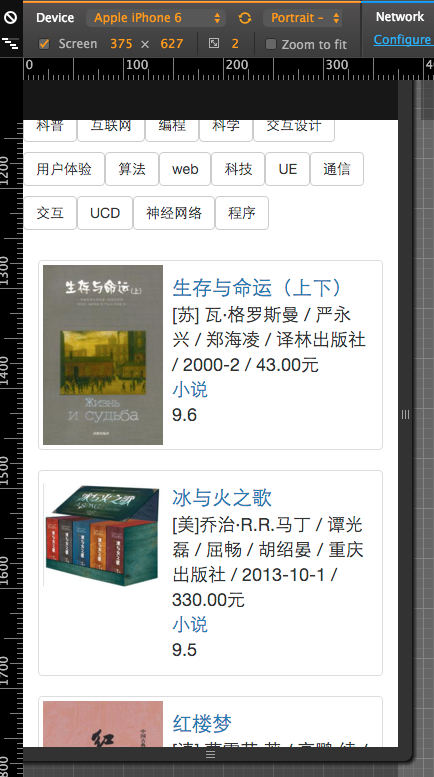
收藏•没有帮助•
•作者保留权利 收起
 余弦,在知道创宇黑客不神秘
余弦,在知道创宇黑客不神秘
 我们用爬虫爬遍整个网络空间,爬那些主流端口,这背后是各种服务,其中 Web 服务最为复杂。我们把这些服务的响应内容尽可能存储下来,加上大量指纹规则去识别它们都是什么。于是我们得到了「全球网络设备」情况:http://www.zoomeye.org/statistic/device由于 Web 服务的特殊性…显示全部
我们用爬虫爬遍整个网络空间,爬那些主流端口,这背后是各种服务,其中 Web 服务最为复杂。我们把这些服务的响应内容尽可能存储下来,加上大量指纹规则去识别它们都是什么。于是我们得到了「全球网络设备」情况:http://www.zoomeye.org/statistic/device由于 Web 服务的特殊性…显示全部
我们把这些服务的响应内容尽可能存储下来,加上大量指纹规则去识别它们都是什么。
于是我们得到了「全球网络设备」情况:
http://www.zoomeye.org/statistic/device
由于 Web 服务的特殊性,我们还得到了「全球 Web 服务」情况:
http://www.zoomeye.org/statistic/web
当我们看到这个时,对整个网络空间充满敬畏,于是内部的项目在 2013 年初考虑对外开放,首先开放了搜索:
http://zoomeye.org
&lt;img data-rawheight="1136" data-rawwidth="640" src="https://pic3.zhimg.com/53ae3b653de6e4ad3f59438d3c688e9e_b.jpg" class="origin_image zh-lightbox-thumb" width="640" data-original="https://pic3.zhimg.com/53ae3b653de6e4ad3f59438d3c688e9e_r.jpg"&gt;
取了个非常酷的名字:ZoomEye,中文叫:钟馗之眼,定位为:网络空间搜索引擎。当前已经是第三版。
由于这种搜索方式非常专业(并非面向普通大众),我们在首页上提供了「用户手册」,还有「搜索 Dork」,用户可以借助这两样快速入门。
我们做这个的目的是什么?
其实,我们是安全研究者(说通俗点:黑客),我们想解决一个问题:
一个漏洞爆发后,我们如何感知全球影响面?
这个问题背后的逻辑就是我们做这个搜索引擎的奥秘。
在黑客世界,攻击者与防御者,他们对抗的单元都可以细分到一个个「组件」,我们认为组件是构成网络空间的最小单元,比如你搭建一个网站,你要用 Ubuntu/PHP/MySQL/WordPress(附带各种插件)/jQuery 等等等,这些玩意就是一个个组件,你不需要重复劳动去创造它们,而是选择搭积木方式,这是整个网络空间进化的必然结果。正因为如此,如果一个组件出漏洞(这是必然的),那将影响一大批使用它的那些目标。
攻击者喜欢这样,因为一个组件出漏洞,攻击者可以大规模黑掉目标,然后做各种坏事(庞大地下产业链的一个关键环节)。
对我们来说,其实我们是防御者,我们可以站在攻击者角度去评估这种影响面,然后发出预警。
我们最成功的案例是,2014/4/8 心脏出血漏洞爆发时,我们是最快搞定整个权威预警的团队。可以看当时我们基于 ZoomEye 做出的心脏出血全球统计与一年后的相关解读:
http://www.zoomeye.org/lab/heartbleed
http://www.zoomeye.org/lab/heartbleed/2015
&lt;img data-rawheight="1136" data-rawwidth="640" src="https://pic3.zhimg.com/acc180e8b5ac6bb0a93ab054327d7446_b.jpg" class="origin_image zh-lightbox-thumb" width="640" data-original="https://pic3.zhimg.com/acc180e8b5ac6bb0a93ab054327d7446_r.jpg"&gt;
当时,我们的结论覆盖了央视、新华社、许多科技媒体、很多报刊杂志,还有国家相关监管机构,2014 年底时,入选极客公园评审的 2014 年互联网产品 50 强。这给了我们团队极大的信心,从一个内部实验性小项目逐渐成为安全圈/黑客圈炙手可热的平台。
这是一件大工程,如果你仔细体验这个平台,你会认可我的看法。
这是一个充满争议的平台,有人说我们通过 ZoomEye 就可以黑遍全世界。我们有能力做这事,但我们不会这样做,黑遍有什么好玩的,好玩在对抗,在促进整个网络空间的良性进化。
Google 爬了全球网站,他们说「不作恶」,对我们来说,全球网站只是我们面对庞大网络空间的一个子集(Google 的爬虫复杂度比我们只面对组件的爬虫的复杂度要高 N 个量级,这里不展开),为了把这个平台做好,我们还需要大量的人才与服务器、带宽、钱。
这是我这么多年带队做的最酷的爬虫项目,如果你也是 Python 工程师,对黑客这个领域充满好奇,可以私信我^_^
收藏•没有帮助•
•作者保留权利 收起
 萝莉控夫斯基,http://Chnyoo.cn高级工程师
萝莉控夫斯基,http://Chnyoo.cn高级工程师
于是乎利用采集脚本抓一坨一坨的资料给她用,
而她的同事天天自己搜资料整理到半夜,
大概就是这样。
==============
收到感谢是因为有码农要靠这个技能去把妹么23333
收藏•没有帮助•
•作者保留权利
 张方舟,http://ZhihuHot.sinaapp.com 知乎会火问题精选…
张方舟,http://ZhihuHot.sinaapp.com 知乎会火问题精选…
 最新更新:本爬虫已开源,路过的帮我点个Star/Fork就最好了https://github.com/MorganZhang100/zhihu-spiderUpdate 2015.1.21自己使用了8天,算了一下,得赞效率是之前的21倍,大概还是有些用的。Update 2015.1.19今天把筛选算法更新了一下,给出的推荐更有参考意义了,大家有兴趣的…显示全部
最新更新:本爬虫已开源,路过的帮我点个Star/Fork就最好了https://github.com/MorganZhang100/zhihu-spiderUpdate 2015.1.21自己使用了8天,算了一下,得赞效率是之前的21倍,大概还是有些用的。Update 2015.1.19今天把筛选算法更新了一下,给出的推荐更有参考意义了,大家有兴趣的…显示全部
&lt;img src="https://pic2.zhimg.com/a35ee6262651b3177a86e00fee76f399_b.jpg" data-rawwidth="1596" data-rawheight="706" class="origin_image zh-lightbox-thumb" width="1596" data-original="https://pic2.zhimg.com/a35ee6262651b3177a86e00fee76f399_r.jpg"&gt;
Update 2015.1.21
自己使用了8天,算了一下,得赞效率是之前的21倍,大概还是有些用的。
Update 2015.1.19
今天把筛选算法更新了一下,给出的推荐更有参考意义了,大家有兴趣的可以去试一下~
评论中有人问筛选会火的问题的依据是什么。目前我只考虑了如下几个变量:
关注人数(决定了答案的曝光量)
已有答案数(决定了竞争强度)
已有答案的最高票答案票数(决定了竞争强度)
根据这三个变量,我可以找出曝光量大的,竞争强度低的问题来回答,从而更容易得赞。
如果大家有更好的点子,请不吝赐教~~~
----------------
前几天边学python边写了一个爬虫用来爬知乎问题,从中筛选出可能会火的问题,目前爬了一百多万个问题了,从中选了500个可能会火的放在了知乎Hot上,网址是http://ZhihuHot.sinaapp.com。
自己试用了下,感觉还是有一点意思的,目前的算法没考虑太多细节,如果除了我还有人喜欢的话我就再改进好了。话说知乎的问题真多啊,我的数据库大小正在以肉眼可见的速度不断上涨。本来还想给爬虫加上多线程功能的,后来想想如果加了的话没两天我就没有硬盘空间可用了。
收藏•没有帮助•
•作者保留权利 收起
Waiting,php程序员
 爬知乎的收藏夹里的所有图片……只要配置一个收藏夹的链接地址,然后运行时输入想获取的起始和结束页,不输入默认抓取第一页然后……恩,图片名是按作者的名字保存的,里面那个info文件夹保存了这些作者的知乎首页地址也可以按赞同数过滤低赞同的答案,目前…显示全部
爬知乎的收藏夹里的所有图片……只要配置一个收藏夹的链接地址,然后运行时输入想获取的起始和结束页,不输入默认抓取第一页然后……恩,图片名是按作者的名字保存的,里面那个info文件夹保存了这些作者的知乎首页地址也可以按赞同数过滤低赞同的答案,目前…显示全部
只要配置一个收藏夹的链接地址,然后运行时输入想获取的起始和结束页,不输入默认抓取第一页
然后……
&lt;img src="https://pic4.zhimg.com/d3bda5a2c67700ec89c0172defc2ac57_b.png" data-rawwidth="669" data-rawheight="882" class="origin_image zh-lightbox-thumb" width="669" data-original="https://pic4.zhimg.com/d3bda5a2c67700ec89c0172defc2ac57_r.png"&gt; &lt;img src="https://pic3.zhimg.com/12eb0cb9bd9261004e41c4bd6a97fcfa_b.png" data-rawwidth="479" data-rawheight="732" class="origin_image zh-lightbox-thumb" width="479" data-original="https://pic3.zhimg.com/12eb0cb9bd9261004e41c4bd6a97fcfa_r.png"&gt;
&lt;img src="https://pic3.zhimg.com/12eb0cb9bd9261004e41c4bd6a97fcfa_b.png" data-rawwidth="479" data-rawheight="732" class="origin_image zh-lightbox-thumb" width="479" data-original="https://pic3.zhimg.com/12eb0cb9bd9261004e41c4bd6a97fcfa_r.png"&gt; &lt;img src="https://pic3.zhimg.com/90672d14befe36be60aa597d9a2a9ace_b.png" data-rawwidth="1113" data-rawheight="696" class="origin_image zh-lightbox-thumb" width="1113" data-original="https://pic3.zhimg.com/90672d14befe36be60aa597d9a2a9ace_r.png"&gt;
&lt;img src="https://pic3.zhimg.com/90672d14befe36be60aa597d9a2a9ace_b.png" data-rawwidth="1113" data-rawheight="696" class="origin_image zh-lightbox-thumb" width="1113" data-original="https://pic3.zhimg.com/90672d14befe36be60aa597d9a2a9ace_r.png"&gt; &lt;img src="https://pic3.zhimg.com/024999577861c90f21f4e32bc8adecea_b.png" data-rawwidth="1142" data-rawheight="809" class="origin_image zh-lightbox-thumb" width="1142" data-original="https://pic3.zhimg.com/024999577861c90f21f4e32bc8adecea_r.png"&gt;
&lt;img src="https://pic3.zhimg.com/024999577861c90f21f4e32bc8adecea_b.png" data-rawwidth="1142" data-rawheight="809" class="origin_image zh-lightbox-thumb" width="1142" data-original="https://pic3.zhimg.com/024999577861c90f21f4e32bc8adecea_r.png"&gt;
恩,图片名是按作者的名字保存的,里面那个info文件夹保存了这些作者的知乎首页地址
也可以按赞同数过滤低赞同的答案,目前还没用这个功能,全抓下来了
====================
感谢大家的点赞,另外一个练手的爬虫一块上传了。抓取淘宝模特图片的爬虫
&lt;img src="https://pic2.zhimg.com/b9cda7736004afa5d6d0c35c1d143c29_b.png" data-rawwidth="501" data-rawheight="219" class="origin_image zh-lightbox-thumb" width="501" data-original="https://pic2.zhimg.com/b9cda7736004afa5d6d0c35c1d143c29_r.png"&gt; &lt;img src="https://pic4.zhimg.com/9087eb8588735ec74e28fa3e90afe873_b.png" data-rawwidth="820" data-rawheight="783" class="origin_image zh-lightbox-thumb" width="820" data-original="https://pic4.zhimg.com/9087eb8588735ec74e28fa3e90afe873_r.png"&gt;
&lt;img src="https://pic4.zhimg.com/9087eb8588735ec74e28fa3e90afe873_b.png" data-rawwidth="820" data-rawheight="783" class="origin_image zh-lightbox-thumb" width="820" data-original="https://pic4.zhimg.com/9087eb8588735ec74e28fa3e90afe873_r.png"&gt;
==============
评论里@鬼觉神知 修改了脚本为 OSX,python2.7可用 ,链接:bigstupidx/Pythonspider: 一个简单的python爬虫,原生py...
收藏•没有帮助•
•禁止转载 收起
 李德,环保部门科研人员
李德,环保部门科研人员
------------------------------------------------正常分割线----------------------------------------------------
2011年,我还在学校读书,写了个软件注册了几十万个新浪微博账号。(那时候还不要求实名制,真怀念)。然后就要养账号,写了几个爬虫软件从搜狐微博上爬昵称用来更新我新浪微博上的昵称,从大V的粉丝中爬他们的头像用来更新自己的微博头像(我对不起大家!),从笑话微博中爬微博内容来发到自己微博中。用这这几十万个微博账号去参与抽奖,一年获利了七万多块钱。读书那几年我承包了我们宿舍所有的水电费和我们班男生宵夜啤酒鸭霸王的费用。
------------------------------------------问题回答--------------------------------------------------------------
1、是不是用Python写的,用别的语言可以实现不啦?
答:是用C#写的,Python没有学过,毕竟专业不是计算机,毕业后所从事的工作也不是程序员,所以没有学习这个的动力。别的语言肯定也是可以实现的,计算机语言之间都有相似性,只是实现起来的难易程度不一样。上学时学习C#完全是出于爱好,在学习、工作上能够解决自己的问题即可。我不适合专职做程序员,去理解别人的需求很痛苦,其实曾经尝试着去当一名伟大的软件程序员来着,可惜北漂未遂。
2、怎么知道你的帐号中奖了?
答:我自己的帐号我一眼就能认得出来。我一般用一个大号去参加抽奖(大号一般不会被封),然后用软件去监测我的大号参与抽奖。这样我的小号转发的有奖活动跟我的大号之间就几乎相同了(为什么说几乎,因为有部分会失败)。活动开奖后,我只要从我的大号中进入抽奖页面查看中奖帐号即可。我自己的帐号全部申请了10个左右的勋章,有昵称、有头像、有学校、有年龄、有标签,最重要的是从所转发的微博和抽奖活动来看,一个有奖活动中间夹杂几个正常微博,正常微博的内容我是从谁的微博中抓取的我也都能认识。只要疑似自己的帐号,把它的UID或者nickname放入数据中中检索便知结果。
3、新浪微博不封号?
答:肯定封,而且经常好几千上万那样封。所以我一次性都是用一万个左右的帐号去参加抽奖,封掉了就用下一批。此外换IP是常识,之前十个左右换一个IP,后来严格了,基本上三五个就换一次IP。封号和反封号跟新浪也是斗智斗勇,每次帐号被封之后我都会把同一批使用但幸存的那么几百个帐号来进行分析。同批次参与活动为什么大部分帐号被封,但是还有几百个幸存的呢,他们之间肯定是有差异的,找到这种差异去猜测新浪技术然后改进我的软件。
4、现在还做不做这方面的软件了,不做可惜了,能不能帮我写个某某软件,批量生成一些知乎点赞帐号和点赞软件?
答:现在不做,从来都没有想过把这个当作所谓的事业。现在有了正经工作,而且收入也比做这个要多,为什么还要去做这种边缘性的东西。
5、鸭霸王是什么?
答:下酒菜,湖南特色,辣的够滋味,毕业了怀念。
6、碉堡?
答:会很疼,还是不要。
收藏•没有帮助•
•作者保留权利 收起
 孔庆勋,创业猫CEO/首席段子手
孔庆勋,创业猫CEO/首席段子手
 作为一只一向自诩“不懂技术”的创业喵,我也要来强答了!虽然不懂技术,但是简单的代码还是会几行的(没错,仅限于几行!)。所以,接下来我要讲的这件事情,也不过就是几行代码的事情。还是一年前的事情,当时由于高考录入信息,统一通过省招办的微信平台…显示全部
作为一只一向自诩“不懂技术”的创业喵,我也要来强答了!虽然不懂技术,但是简单的代码还是会几行的(没错,仅限于几行!)。所以,接下来我要讲的这件事情,也不过就是几行代码的事情。还是一年前的事情,当时由于高考录入信息,统一通过省招办的微信平台…显示全部
虽然不懂技术,但是简单的代码还是会几行的(没错,仅限于几行!)。所以,接下来我要讲的这件事情,也不过就是几行代码的事情。
还是一年前的事情,当时由于高考录入信息,统一通过省招办的微信平台确认信息。
然后,我在确认自己的信息时,居然发现——所有的信息都是明文保存!
而且,免冠照片的文件名就是——身份证号!!!
当时我的第一个反应是——黑客可以拖一个库了啊!
然而我怎么证明自己的判断呢?我特喵不会写代码啊!!!
当时高三,时间还是挺宝贵的。我看了一下,这一天大约有3个小时去弄这个事。
于是,对于编程几乎没有了解的我,用3个小时入门了PHP,搭建了环境,然后从代码库上找到了壳,反复改了算法,用了几个语句,然后写出来了一个爬虫!!!
说是爬虫,其实还不过是一个小循环。大概,就是这样的,没错就是大神们最不屑一顾的入门语句,而且这几行代码里还有很多的不良习惯……
<?phpfor($i1=0000;$i1<=9999;$i1++){if($i1<1000){ $u="http://100.123.1.2/sy_wpt/bin/studentPic/210701199701230$i1.jpg";copy($u,"210701199701230$i1.jpg");}else{ $u="http://100.123.1.2/sy_wpt/bin/studentPic/21070119970123$i1.jpg";copy($u,"21070119970123$i1.jpg");}}?>
注意,代码中体现的域名并非真实域名,所有涉及个人信息的内容,也已经全部屏蔽掉了……这个是最基本的代码,略微高级一点的,可以脱库那种我也不放出来了。
总之,最后的效果大概就是我的浏览器飞速地刷屏,然后文件夹里多了无数张全省同届高中生的免冠照片。
当然,我只是做了一个实验,不过是不到2000张的量而已,而且在实验过后全部删掉。
顺便留了一张女神的,免冠照也好看(花痴脸)。
言归正传,按照这个办法,全省十几万考生的照片,我可以在一天内搞到手,还有对应的身份证号。
最后的效果,大概是这样的……(图为示例)
&lt;img src="https://pic4.zhimg.com/1bd12565f24fc2bea9b249705bb0af1b_b.png" data-rawwidth="1404" data-rawheight="475" class="origin_image zh-lightbox-thumb" width="1404" data-original="https://pic4.zhimg.com/1bd12565f24fc2bea9b249705bb0af1b_r.png"&gt;
做完这一切后,我选择提交了乌云……然而,至今这个漏洞还存在着。
后来我又联系了媒体,甚至我做白帽子的朋友亲自去教育厅举报了这个漏洞。然而,并没有什么卵用。我们的个人信息就这么暴露在了外面。免冠照+身份证号码能做多少事情,大家就自行去想象吧~~~
说到我自己。在写完这些代码后,我就再没碰过PHP……
以上。
收藏•没有帮助•
•作者保留权利 收起
 xlzd,http://xlzd.me - 技术宅,专栏作…
xlzd,http://xlzd.me - 技术宅,专栏作…
爬了知乎100万用户,做的一个知乎用户浅析:
一个知乎重度用户眼中的知乎
-------------------------------------------------------------
20150616新更:
知乎上有很多高质量的妹子~~~
写了一个爬虫, 从一个用户( @OnlySwan )开始, 按照一个规则判断每个人是否是美女(头像检测 / 回答问题中的图片内容 / 赞.感谢.收藏等的次数 ......), 若是则存下她,然后从她的关注列表开始爬下去(美女关注美女的概率更大).
爬虫跑在我的VPS上,然后在SAE建了一个应用展示(后一步暂时没有做完)~~~
-----------------------------------------------------------------
20150523新更:
妹子图(妹子图 - 清纯美女,可爱美女,美女图片)是个不错的网站,但是有很多广告, 于是爬下妹子图的所有图片, 挂到了我的VPS上~~~(Blog of xlzd)
-----------------------------------------------------------------
以前的一篇博客,Python爬黄色网站图片。http://duxu.info/2015/03/06/python-beautiful-soup-qbcr/
﹉﹉﹉﹉﹉﹉﹉﹉﹉﹉﹉﹉﹉﹉﹉﹉﹉﹉﹉﹉﹉﹉
以下内容文不对题,请随意忽略。
一个用Python但不是爬虫的应用,个人最爱。
有一个树莓派和继电器,然后接上网络后继电器连着电热毯,当快去睡觉的时候留给我的一个小号邮箱发一个邮件,树莓派跑一段Python程序,收到后就会回复一封邮件并给电热毯通电制热。
我是一个懒人。
150119->
评论中有人说到WiFi和蓝牙等技术控制。我的思路是这样的,继电器可以控制电热毯,在保证安全的前提下下一步打算控制空调和出门前放好米和水的电压力锅,可能这时候还在外面,所以WiFi和蓝牙的思路不够通用,没有采用。
另外对于评论中APP的想法不错,打算给老爸老妈做一个(他们都是Android手机),暂时还是发送邮件的思路,他们并不懂什么邮件,所以做成一键发送某个命令,开或者关一样东西,收到树莓派的反馈邮件后弹一个Toast或者AlertDialog提示下。
收藏•没有帮助•
•作者保留权利 收起
 LIKE,Software Engineer
LIKE,Software Engineer
 这是我们跟某大数据公司的合作的一个研究...(由于暂时没有征求对方的同意,所以暂时不方便披露)并且代码和数据都可以在我们的云端产品使用:【滚雪球】雪球滚起来吧,到底我们是否能靠舆情事件赚钱呢?有一天聊到他们爬了很多很多的数据,而我们是专注在…显示全部
这是我们跟某大数据公司的合作的一个研究...(由于暂时没有征求对方的同意,所以暂时不方便披露)并且代码和数据都可以在我们的云端产品使用:【滚雪球】雪球滚起来吧,到底我们是否能靠舆情事件赚钱呢?有一天聊到他们爬了很多很多的数据,而我们是专注在…显示全部
有一天聊到他们爬了很多很多的数据,而我们是专注在看二级市场的量化研究和交易,提供了回测和模拟交易,那么爬下来的大数据如何可以在二级市场变现呢?我们不就是一个很好的合作吗?拿到数据,理清思路,进行结构化将无规则的数据进行量化 - 规则化,提供易用的Python API,好,策略研究员们可以尝试了 - 只需要证明收益、风险都相对客观,经过模拟实盘、小部分投入资金验证即可了。
废话少说,开讲故事...
最早是这家拿到了很多很多的乱七八糟的股票相关的舆情数据,那么到底哪些是比较重要的呢?因为拿到的文本数据是非常非常大的...
一个符合逻辑的思路是:我们根据关注者数据进行每日选股,一方面考虑新增的关注者数量,同时也考虑关注者的增长率,即新增关注者与总关注者的比例,对这一数值进行排序,进行每日的选股调仓。然后测试这一次选出的10个股票,看看他们这一周的表现,结果比较一般,证明舆情数据对于当日表现的作用明显,应当每日调仓。
因此从中构建了几组数据,包括:
1. 某股票昨日新增评论
2. 某股票总评论
3. 某股票昨日新增关注者
4. 某股票总关注者数目
5. 某股票卖出行为(不太准优化中)
6. 某股票买入行为(不太准优化中)
那么对于5,6的构建,我们考虑到兴许应该只考虑大V效应,即社区前5%的大V的调仓记录 - 剔除掉非大V用户即剔除了更多的噪音。这也是雪球100 paper中的选择标准:
&lt;img src="https://pic4.zhimg.com/960bb95683f6d69d55bb65f66c6aaaf3_b.png" data-rawwidth="721" data-rawheight="286" class="origin_image zh-lightbox-thumb" width="721" data-original="https://pic4.zhimg.com/960bb95683f6d69d55bb65f66c6aaaf3_r.png"&gt;
OK,经过了一系列的洗洗刷刷以后数据clean ready,根据上面的逻辑思想进行尝试运行策略。
-------------------最初的结果-----------------------
曾经我们以为我们在做的一个量化策略发现了真正的交易圣杯...
&lt;img src="https://pic1.zhimg.com/48edb547d702b6a857ebba0ac2c841b4_b.png" data-rawwidth="797" data-rawheight="681" class="origin_image zh-lightbox-thumb" width="797" data-original="https://pic1.zhimg.com/48edb547d702b6a857ebba0ac2c841b4_r.png"&gt;
团队非常开心:也不用在给大家发工资了,年初的时候给大家发第一个月的工资,然后这一年让大家早上九点半开始交易半小时,根据我们这个策略的信号机械执行就行了...然后就能获得下图的1500%的年化收益率,有着12的Sharpe的一个策略...这意味着什么呢?如果年初我们给一个员工1万的工资,年尾他这一万块就变成了15万,比平均每个月工资还多,那我们就不发工资了呗...
&lt;img src="https://pic3.zhimg.com/1e7a952b7e8745d9f343c1c39c301872_b.png" data-rawwidth="1601" data-rawheight="481" class="origin_image zh-lightbox-thumb" width="1601" data-original="https://pic3.zhimg.com/1e7a952b7e8745d9f343c1c39c301872_r.png"&gt;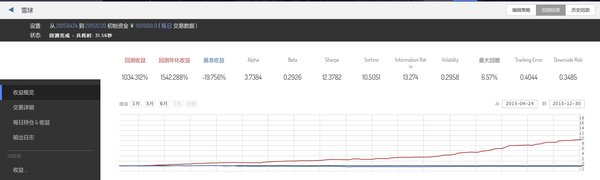
初始的10万资金在回测的结尾不到一年时间变成了118万+
当时我们真的很开心,团队大家都觉得“嗯,老板你发一个月工资给我们+这个策略我们就可以今年不要工资啦!”
雪球就可以滚起来啦...
&lt;img src="https://pic4.zhimg.com/ec17837cd7ae93c871c18f5b23e21b13_b.png" data-rawwidth="745" data-rawheight="591" class="origin_image zh-lightbox-thumb" width="745" data-original="https://pic4.zhimg.com/ec17837cd7ae93c871c18f5b23e21b13_r.png"&gt;
涨停、跌停的问题
虽然该策略没有考虑到停牌股票的操作(Ricequant已经处理了),不过再深入研究以后我们发现,有些股票舆情热门那么往往也不容易买入、卖出啊 - 因为受到了涨、跌停影响,随后我们改进了策略,剔除掉了这些涨跌停无法买入的股票,结果就变成了这样...
&lt;img src="https://pic2.zhimg.com/c8ce25908d6d49a94ce6369f22242965_b.png" data-rawwidth="1585" data-rawheight="537" class="origin_image zh-lightbox-thumb" width="1585" data-original="https://pic2.zhimg.com/c8ce25908d6d49a94ce6369f22242965_r.png"&gt;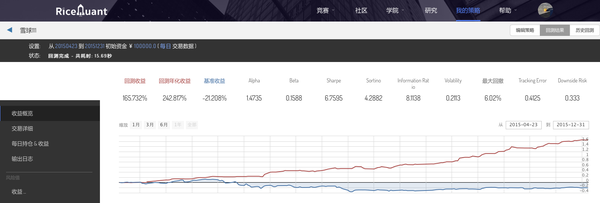
这样子“改良”之后,仔细验证了落单的股票都不存在当天涨停、跌停或者交易量不够的情况,但是收益急剧下降到了242%的年化收益率。不过至少还是有6.7的Sharpe,well,虽然不能财务自由了,但是投入点钱每年这么赚还是能做高富帅的,想想也还开心。。。
未来数据?
接着有一天我们内部在讨论,假如一个并不难的“大数据爬虫”策略可以获得如此显著的Sharpe,那么为什么不会有很多基金base on舆情策略直接赚钱不就好了,来钱不是很容易吗?我们也觉得想继续深挖,那么问题来了...
后来发现,我们在回测当天调用的股票舆情数据其实是第二天早上7点才生成的,那么意味着在当天早上我们就知道了随后这一整天的股票舆情走向了!
神马?!∑q|゚Д゚|p 当时的表情是这样的...莫非注定屌丝依然是屌丝了吗!
战战兢兢地修改完代码,让舆情数据调用的API只能调用到昨天的数据,结果出来了...
&lt;img src="https://pic2.zhimg.com/dce81b191f0ba5333d2361d9809715b5_b.png" data-rawwidth="1316" data-rawheight="528" class="origin_image zh-lightbox-thumb" width="1316" data-original="https://pic2.zhimg.com/dce81b191f0ba5333d2361d9809715b5_r.png"&gt;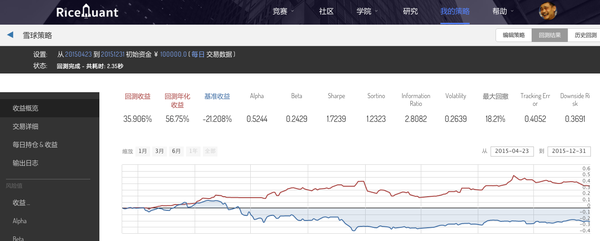
年化收益率现在变成了56.7%,伴随着18%的最大回撤,只能说还行吧,虽然依然大幅度战胜了大盘!
well...还是继续回头老老实实写代码挖矿吧...可见一个圣杯不会这么容易地出现的...
巴菲特你好,巴菲特再见!
数据是非常有意思的,从中可以发现的确舆情是和股票有正相关的,而让我们设想数据爬取的速度如果达到了秒甚至毫秒级别一次更新,那么会让这个收益更加提高(我们测试了每天和几天甚至一个月的调仓效果都会比较差),是的。。。爬虫也需要更快更强
而我们想要做的更有趣的事情包括看京东、淘宝等销售数据是提前于财报发布的,并且更加真实,上面更有超过100家的上市公司在做生意,还有诸如好评的增加减少也是一个因子,敬请期待。
当大数据配合合适的工具,我们相信会有更有意思的事情发生,不过还是要提示:
股市有风险,入市需谨慎
股市有风险,入市需谨慎
股市有风险,入市需谨慎
重要的话说三遍...仅代表本人的测试看法,不代表Ricequant也不建议不理解的情况下跟随投资。
也欢迎大家关注专栏 : Money Code - http://zhuanlan.zhihu.com/ricequant
也会时不时更新有趣的策略和想法
所有的提到的数据都可以在 http://www.ricequant.com 上自己尝试,是完全免费的云端工具
收藏•没有帮助•
•作者保留权利 收起
 egrcc
egrcc
相比于大家,我并没有做出什么很酷,很有趣的事情。我用爬虫做的第一个东西,是批量下载壁纸的工具: https://github.com/egrcc/small-python/tree/master/download-zol-pictures-wallpaper。现在看起来虽然没什么,不过它让我感受到到我也可以用计算机技术做一些有意义的东西,而不是整天面对一个黑框框。让我有动力和兴趣去做下一个更酷的东西。
第二个东西是一个android上的搜索工具,可以搜索网盘资源。也是开源的,egrcc/xunmi_android · GitHub。豌豆荚可以下载,「寻觅」安卓版免费下载。实际上就是爬了gfsoso的搜索结果数据(实际是google),然后用android包装了一下。当然我征得了gfsoso开发者的同意。由于最近gfsoso变更域名,而我没有及时更新,只能搜索微盘的资源了。要知道,google可不只是能搜索网盘资源哦,剩下的就要发挥你自己的想象力了。
第三个东西是爬知乎的工具,egrcc/zhihu-python · GitHub。这也算是目前做得最成功的一个项目了。我曾经在如何入门 Python 爬虫? - egrcc 的回答中讲述过写的过程中遇到的一些坑。
另一件事情是,曾经有一位知友在毕业论文中需要用到某个网站一些数据,但她自己不知道怎么取到大量的数据,于是找到了我,我就帮忙写了个小程序帮她爬了10万条数据。能帮助别人完成毕业论文难道不是一件很酷的事情吗?
现在大数据这么火,什么专业都要跟它扯点边,所以,多学点技术吧,说不定哪一天你的毕业论文也能用上 。
收藏•没有帮助•
•作者保留权利
知乎用户
我发现红包图片居然是静态的地址,而且固定页面投放的。于是手写爬虫,抓淘宝商品页面,分析下有没有红包图就行了。
几个小时赚了2000多吧,100的较少,红包折现麻烦,要自己开店自己购买。
收藏•没有帮助•
•作者保留权利
更多
写回答…
作者:何宜晖
链接:http://www.zhihu.com/question/27621722/answer/51648885
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
爬虫技术做到哪些很酷很有趣很有用的事情相关推荐
- 用python自动化办公_知乎1800赞 | 用Python自动化办公能做到哪些有趣或有用的事情?...
原标题:知乎1800赞 | 用Python自动化办公能做到哪些有趣或有用的事情? 知友:陈廷聿(1800+ 赞同) 利益相关:Python办公自动化课程的讲师 我想介绍一下我是如何从每天工作8小时,进 ...
- python爬虫技术可以干什么-利用爬虫技术能做到哪些很酷很有趣很有用的事情?...
很久之前就看到老爬虫 @何明科 的回答,在后续的几年里面,一致在思考和践行爬虫赋能业务运营的结合点和场景.爬虫是虾米东东?真的是盗取数据的不法之徒吗? 真相却恰恰相反,而且很多场景下都能极大的赋能业务 ...
- python爬虫可以做哪些好玩的_利用爬虫技术能做到哪些很酷很有趣很有用的事情?...
可以批量下载抖音小姐姐的视频啊!!!https://www.zhihu.com/video/1007643517610475520 可以查看微信好友撤回了什么消息啊!!!Python查看微信撤回消息 ...
- 爬虫python能做什么外国人-利用爬虫技术能做到哪些很酷很有趣很有用的事情?...
知乎十二小时内发布最受关注话题 ') cl_list = [' ', ' ', ' ', ' '] for i in listss: number = random.choice(cl_list) f ...
- python能用来做什么有意思的事情-用 Python 自动化办公能做到哪些有趣或有用的事情?...
首先,很感谢党,感谢政府,感谢麻瓜编程,能在有幸之年认识一帮让我膜拜的大佬(咳咳,有点跑题)................... 学习初衷:作为一名财务打杂工,对财务岗位大多数繁冗低效无意义的工作深 ...
- python自动化办公都能做什么-用 Python 自动化办公能做到哪些有趣或有用的事情?...
首先,很感谢党,感谢政府,感谢麻瓜编程,能在有幸之年认识一帮让我膜拜的大佬(咳咳,有点跑题)................... 学习初衷:作为一名财务打杂工,对财务岗位大多数繁冗低效无意义的工作深 ...
- 日常办公会用到的python模块-用 Python 自动化办公能做到哪些有趣或有用的事情?...
所有需要重复做两次的事情,都可以用程序代替我来完成. 场景1: 微信上处理的事情有很多都是重复的,又经常容易被这些琐事打断.于是我在 Python 程序里设定了一些关键词和相应的自动回复: /> ...
- python智能办公系统_用 Python 自动化办公能做到哪些有趣或有用的事情?
Python的学习资料,网上随便搜都是大把的 不过那些基本上没什么干货 好的学习资料是系统的,全面的 从实战例子,到工具到源码,都全面的很 片面的学习,你肯定是学不好的 而且,大多数资料都是一堆理论的 ...
- python标准词匹配_用 Python 自动化办公能做到哪些有趣或有用的事情?
我想介绍一下我是如何从每天工作8小时,进化成每天工作10分钟的. 不涉及太多的技术细节,毕竟知乎是一个分(现)享(编)知(故)识(事)的地方 0.先自我介绍一下: 我不是程序员,大学学的也不是IT专业 ...
最新文章
- java 多条件比较_Java 多条件复杂排序小结
- VS2008 Tips #004 – 您可以通过“浏览方式…”添加浏览器到 Visual Web Developer
- sed原理的一些感悟
- stl 基于哈希的map c++_关于哈希表,你该了解这些!
- 【jQuery笔记Part4】01-jQuery-节点操作-添加节点-删除节点-复制节点
- 沫沫金::jqGrid插件-弹窗返回值
- pthread_detach()与pthread_join的区别?
- 车载前视摄像头学习笔记 ———— 摄像头输出数据格式(YUV)
- STM32CubeMX驱动4脚OLED模块
- php html block,html blockquote怎么用?blockquote标签的用法介绍
- linux嵌入式reboot不生效,Embeded linux之reboot
- 九校联考-绵阳东辰国际NOIP模拟总结
- 如何修改品牌电脑logo,让你电脑开机更个性
- Axure8.0-制作图片验证码
- Zephyr 3.2 弃用devicetree 中node 里的label property
- 通俗易懂解释IP段192.168.1.0/24和192.168.0.0/16
- AIX小型机安装JAVA JDK的方法
- ffmpeg如何进行高清图片转码
- C++ MATLAB 混合编程——VS项目调用MATLAB函数
- Oracle数据库习题整理