python葡萄酒数据_用python进行葡萄酒质量预测
python葡萄酒数据
Warning: This is long article for those who seek only machine learning code, please just go right to the the last section, but for those who actually come to learn something from the data please carefully read the whole process and prepare a question for me.
警告:对于那些只寻求机器学习代码的人来说,这是一篇长篇文章,请直接转到最后一节,而对于那些真正从数据中学习到一些东西的人,请仔细阅读整个过程并为我准备一个问题。
First, let’s call the elephant in the room, “Why we have to detect the quality of wine?” And “Can quality be predictable?”. These latter question arises from the subjective perspective of person toward a preference of wine testing, in acquiring the quality of the wine, we will focus only on the objective part which is the actual quality such as balance, aroma, not the flavors. The former question arises from the person who has not enter to the realm of wine drinking before, the quality of the wine cannot simply be classified as good or bad as same as other food, it needs many metrics to consider.
开始步骤,让我们把大象在房间里,“为什么我们要检测酒的品质?” 还有“质量可以预测吗?”。 后一个问题是从人们对葡萄酒测试偏爱的主观角度提出的,在获取葡萄酒的质量时,我们将只关注客观部分,即平衡,香气而不是风味等实际质量。 前一个问题来自以前没有进入葡萄酒饮用领域的人,葡萄酒的质量不能像其他食物一样简单地分为好或坏,它需要许多指标来考虑。
现在是这个统计数据获取中的真正问题 (Now is the real question in this statistics acquisition)
“Can quality of wine be determined without using wine testing techniques, in other words, can we used predictive technique of machine learning to quantify the wine quality with scale and lesser expertise?”
“是否可以在不使用葡萄酒测试技术的情况下确定葡萄酒的质量,换句话说,我们可以使用机器学习的预测技术来量化具有较少规模的专业知识的葡萄酒质量吗?”
The question whether statistical techniques can be used to determine the quality of wine without the need for individual inspection of wine tester will be carry out in this article.
本文将讨论是否可以使用统计技术来确定葡萄酒的质量而无需对葡萄酒测试仪进行单独检查的问题。
数据 (DATA)
This dataset is common in Kaggle open sources however, you might actually find articles in medium that used the cool and advance machine learning algorithm for solving this problem like Random Forest, Neural network and Support Vector machine and telling you what is the accuracy, precision, recall and f-1 score of the model without actually doing the proper knowledge acquisition of where quality of wine derived from. Of course, the power of machine learning do not require the one who implement it to actually know the input and give a great result. But it sure will help the machine learns better if the one who supervised the machine understand what are the relationships of inputs to output.
该数据集在Kaggle开源软件中很常见,但是,您实际上可能会在媒体上找到使用凉爽且先进的机器学习算法来解决此问题的文章,例如随机森林,神经网络和支持向量机,并告诉您准确度,精确度,召回和模型的f-1分数,而实际上并未对葡萄酒质量的来源进行适当的知识获取。 当然,机器学习的力量不需要实施它的人真正知道输入并给出出色的结果。 但是,如果监督机器的人了解输入与输出之间的关系,那肯定会帮助机器学习得更好。
Let’s do the machine learning in the proper way like statistics, now our data is the red and white wine data with their physio-chemical properties. The grape that used in the wine is the Portuguese varietal of Vinho Verde and the document for data mining study can be found here. First, let explore the overview of physio-chemical feature.
让我们以诸如统计之类的适当方式进行机器学习,现在我们的数据是具有物理化学特性的红葡萄酒和白葡萄酒数据。 葡萄酒中使用的葡萄是葡萄牙的Vinho Verde品种,有关数据挖掘研究的文件可以在这里找到。 首先,让我们探索理化特征的概述。
了解数据 (Understanding data)
Fixed acidity: The non-volatile acid found in wine whihc are tartaric, malic, citric, and succinic. All of these acids originate in grapes with the exception of succinic acid, which is produced by yeast during the fermentation process.
固定的酸度:在葡萄酒中发现的非挥发性酸为酒石酸,苹果酸,柠檬酸和琥珀酸。 除琥珀酸外,所有这些酸都起源于葡萄,而琥珀酸是在发酵过程中由酵母产生的。
Volatile acidity: the acidic elements of a wine that are gaseous, rather than liquid, and therefore can be sensed as a smell, showing an aroma, rather than found on the palate.
挥发性酸度:葡萄酒中的酸性元素,是气态而不是液态,因此可以感觉到是一种气味,显示出一种香气,而不是在味蕾上发现。
citric acid: a weak organic acid, which is often used as a natural preservative or additive to food or drink to add a sour taste and freshness to food.
柠檬酸:一种弱有机酸,通常用作食品或饮料的天然防腐剂或添加剂,以增加食品的酸味和新鲜度。
residual sugar: the amount of sugar remaining after fermentation stops, it’s rare to find wines with less than 1 gram/liter and wines with greater than 45 grams/liter are considered sweet.
残留糖:发酵停止后残留的糖量,很少发现少于1克/升的葡萄酒,而超过45克/升的葡萄酒被认为是甜的。
chlorides: the amount of salt in the wine
氯化物:酒中盐的含量
free sulfur dioxide(SO2): SO2 is used throughout all stages of the wine-making process to prevent oxidation and microbial growth. Excessive amounts of SO2 can inhibit fermentation and cause undesirable sensory effects.
游离二氧化硫(SO2) :在酿酒过程的所有阶段都使用SO2,以防止氧化和微生物生长。 过量的SO2会抑制发酵并引起不良的感官效果。
total sulfur dioxide: amount of free and bound forms of S02S02; in low concentrations, SO2SO2 is mostly undetectable in wine, but at free SO2SO2 concentrations over 50 ppm, SO2SO2 becomes evident in the nose and taste of wine
二氧化硫总量:SO 2 SO 2的游离形式和结合形式; 在低浓度下,葡萄酒中几乎检测不到SO2SO2,但是当游离SO2SO2浓度超过50 ppm时,葡萄酒的香气和口感中会明显出现SO2SO2。
density: the density of water is close to that of water depending on the percent alcohol and sugar content
密度:取决于酒精和糖的含量百分比,水的密度接近于水的密度
pH: Winemakers use pH as a way to measure ripeness in relation to acidity. Low pH wines will taste tart and crisp, while higher pH wines are more susceptible to bacterial growth. Most wine pH’s fall around 3 or 4.
pH值:酿酒师使用pH值来衡量相对于酸度的成熟度。 低pH值的酒会发出酸和松脆的味道,而高pH值的酒更容易受到细菌的滋生。 大多数葡萄酒的pH值约为3或4。
Sulphates: a wine additive which can contribute to sulfur dioxide gas (S02S02) levels, which acts as an antimicrobial and antioxidant.
硫酸盐:一种葡萄酒添加剂,可提高二氧化硫气体(SO2SO2)的含量,起抗菌剂和抗氧化剂的作用。
alcohol: the percent alcohol content of the wine.
酒精度:葡萄酒中酒精度的百分比。
Now we have a rough understanding of our features, let’s look at the our dataset.
现在,我们对功能有了一个大致的了解,让我们看一下我们的数据集。
红VS。 白色 (RED VS. WHITE)
In the world of wine, the difference between red and white wine is not just its color, but the ingredient, the method of wine-making and aging. Because of these differences, the physio-chemicals will be different determinant when it comes to quantify the quality of wine.
在葡萄酒世界中,红葡萄酒和白葡萄酒的区别不仅在于其颜色,还在于其成分,酿酒方法和陈酿方法。 由于存在这些差异,因此在量化葡萄酒质量时,物理化学因素将是不同的决定因素。
In white and red wine dataset, we have 4898 and 1599 data points respectively. They all contains same. Luckily, the data collection is well-defined with no missing data and prepare for analyst right away.
在白葡萄酒和红葡萄酒数据集中,我们分别有4898和1599个数据点。 它们都包含相同的内容。 幸运的是,数据收集的定义明确,没有丢失的数据,可以立即为分析师做好准备。
条形图显示白色和红色的质量等级 (Bar Chart to show the quality rating of white and red)
The picture below show the white and red wine quality rating. The top picture illustrates the white wine quality and the bottom illustrates the red wine quality. As you can see both have similar distribution, it is rare to see the wine have higher quality than 7 and lower quality than 5. This makes sense, in the world of wine making it require a lot of process, technique and class. To create such a bad wine is seemingly as hard as great wine. But to make a fine wine (5, 6 quality) is acceptable and common. At first, we might think making bad wine is hard or people are hardly make bad wine, but it is more likely that many people made bad wine. A lot of bad wine maker just went bankrupt and those who still have enough revenue stays in the business. In the other hand, the high quality wine maker might be rare or it is the capital intensity wine making process that those who have money can only produce wine. If we want to find out we need more inspection on wine making process by backward engineer on the chemical to reach the conclusion that capital is required to make great wine. Unfortunately, I would not like to drag the article to those wine making process.
下图显示了白葡萄酒和红葡萄酒的质量等级。 上图显示白葡萄酒的质量,下图显示白葡萄酒的质量。 正如您所看到的,两者的分布相似,很少见到葡萄酒的质量高于7,质量低于5。这在葡萄酒世界中是很有意义的,它需要大量的过程,技术和等级。 创造如此糟糕的葡萄酒似乎和伟大的葡萄酒一样艰难。 但是酿造上等葡萄酒(5、6质量)是可以接受的并且是普遍的。 起初,我们可能会认为酿造不好的酒很难,或者人们几乎不会酿造不好的酒,但是很多人酿造不好的酒的可能性更大。 许多劣质葡萄酒制造商刚刚破产,那些仍然有足够收入的人留在企业中。 另一方面,高质量的酿酒师可能很少见,或者有钱人只能生产葡萄酒是资本密集型的酿酒过程。 如果我们想找出答案,就需要对葡萄酒的制造过程进行更多的检查,由后进工程师对该化学品进行检查,以得出结论:制造优质葡萄酒需要资金。 不幸的是,我不想将本文拖到那些酿酒过程中。
现在看看与我们目标最相关的功能 (Now look at the most correlated features with our target)
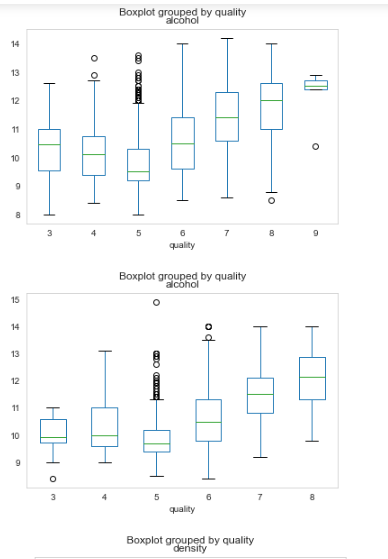
The boxplot tells us the average(mean) of alcohol by each quality of both white(top) and red(bottom) wine, from this boxplot we can assume some relationship between quality and alcohol to be positive correlation and non-linearity. As you can see the alcohol seem to exhibit the negative relationship on wine quality 3, 4 ,and 5 while exhibits positive relation on 5,6,7, and 8. This give us the intuition that alcohol does a pretty job for prediction but will have a confusing threshold and overlapping of data around quality 3, 4, 5,and 6.
箱线图告诉我们白(顶)酒和红(底)酒每种品质的酒精平均(均值),从该箱图中我们可以假定品质和酒精之间的某种关系是正相关和非线性的。 如您所见,酒精似乎对葡萄酒品质3、4和5表现出负相关关系,而对5、6、7和8则表现出正相关关系。这给我们的直觉是,酒精在预测方面做得很好,但会阈值令人困惑,并且质量3、4、5和6周围的数据重叠。
With this knowledge of the co-occurrence between the data, we know at least that machine learning will able to use this information as predictive power. However, the good predictive model should be able to perform at least better than null prediction( use most frequent class as predicted value for all data) or random prediction( use the probability distribution to randomly assign the predicted value). So let’s say our accuracy benchmark to whether the classifier is good or not should be more than 44.87 percent. This number tells the probability of someone with no knowledge about wine and give the most frequent quality that he/she found to any given wine.
有了数据之间共存的知识,我们至少知道机器学习将能够使用此信息作为预测能力。 但是,良好的预测模型应该至少比空预测(使用最频繁的类作为所有数据的预测值)或随机预测(使用概率分布随机分配预测值)更好。 因此,假设我们对分类器是否良好的准确性基准应高于44.87%。 该数字表明某人对葡萄酒一无所知的可能性,并给出给定葡萄酒中他/她发现的最频繁的质量。
The randomly assign predictor should have mean around the same as most-frequent predictor however, the randomness can exhibit some range of uncertainty to the prediction and giving a range of variation around mean accuracy instead of a single value.
随机分配的预测变量的均值应与最频繁的预测变量的均值大致相同,但是,随机性可能会给预测值带来一定范围的不确定性,并给出均值精度附近的变化范围,而不是单个值。
模型 (Model)
So the model just need to be better than 44 percent and that is the threshold that we can said model is done a pretty good job at prediction. I perform two model: Decision tree classifier and multinomial logistic regression.
因此,该模型只需要优于44%,这就是我们可以说模型在预测方面做得很好的阈值。 我执行两个模型:决策树分类器和多项逻辑回归。
The logistic regression gives us the accuracy of 52.34 which is 8 percent more than most-frequent predictor and Decision tree accuracy of 61.43 percent which is 17 percent more than most-frequent prediction.
逻辑回归的准确度为52.34,比最常用的预测值高8%;决策树的准确度为61.43%,比最常用的预测值高17%。
With the feature importances of decision tree, the most influence variable is the alcohol at 16 percent followed by volatile acidity and free sulfur dioxide at 11 percent.
考虑到决策树的重要性,影响最大的变量是酒精含量为16%,其次是挥发性酸度和游离二氧化硫为11%。
These are pretty good model however, it should be able to explain the phenomena which is needed to make better wine quality. And that will be explained in next week for other model and data.
这些都是很好的模型,但是,它应该能够解释提高葡萄酒质量所需要的现象。 下周将针对其他模型和数据进行说明。
CODE
码
翻译自: https://medium.com/analytics-vidhya/wine-quality-prediction-with-python-695939d34d87
python葡萄酒数据
http://www.taodudu.cc/news/show-3112437.html
相关文章:
- c语言红酒编程题,葡萄酒基础知识试题解析一
- 基于K均值聚类的葡萄酒品种判别
- 2021年中国葡萄酒行业发展现状分析,产业技术不断升级,需求量有望持续增长「图」
- LIBSVM (三) 葡萄酒种类识别
- AJAX葡萄酒价位,智利葡萄酒品牌
- 葡萄酒评论数据集
- 【云计算小知识】什么是云计算?云计算特点是什么?
- 云计算机特点的是什么意思,云计算是什么?有哪些特点?
- 云计算是什么意思?新手怎么学云计算开发入门课程
- 云计算的云指的是什么?通俗解释云计算能做什么
- 【云计算】什么是云计算
- 云计算到底是什么?我这样看待云计算
- 云计算是什么意思?3张图看懂云计算架构
- 云计算是什么意思?
- 云计算是什么意思?云计算管理平台有哪些?
- 云计算具有什么平台_云计算?通俗易懂点讲云计算是什么意思?
- 计算机的云是什么意思_什么是云计算云计算是什么意思
- python云计算是什么意思_云计算是什么意思 什么是云计算
- 云计算的概念及介绍(通俗解释)
- 计算机专业概况,计算机专业概况介绍
- 程序员高效率工作工具推荐(必备工具)
- sublime简要笔记
- 那些年啊,那些事——一个程序员的奋斗史 ——114
- 学习Python的代码记录
- 两周!从入门到第15到第3!小白和你一起入门NLP
- 在宇宙中心五道口上班,是怎样一种体验
- git pull 是到工作区还是暂存区_我把git想简单了
- 智课雅思词汇---二十一、名词性后缀acity是什么意思
- AccelStepper库
- 【STM32】STM32之DRV8834电机驱动(IO方式)
python葡萄酒数据_用python进行葡萄酒质量预测相关推荐
- python表格数据_用python读取表格数据
我有一堆表格数据的文本文件.看起来像这样:1. BRISTOL CITY 42 16 4 1 43 13 8 7 6 23 27 59 2. Plymouth Argyle 42 18 3 0 47 ...
- python 共享数据_用Python共享全局数据
a在GlobalDataBase的声明中分配了一个列表. GlobalDataBase的每个实例都以对同一列表的引用开始,我们将其称为"原始"列表. 当您在第一个示例中执行self ...
- python集群_使用Python集群文档
python集群 Natural Language Processing has made huge advancements in the last years. Currently, variou ...
- python 概率分布模型_使用python的概率模型进行公司估值
python 概率分布模型 Note from Towards Data Science's editors: While we allow independent authors to publis ...
- Python金融数据三:Python程序计算看涨期权
Python金融数据三:Python程序计算看涨期权 计算看涨期权价格的代码 Black-Scholes-Merton期权定价模型(Black-Scholes-Merton Option Pricin ...
- 利用python从网页查找数据_利用Python模拟淘宝的搜索过程并对数据进行可视化分析...
数据挖掘入门与实战 公众号: datadw 本文讲述如何利用Python模拟淘宝的搜索过程并对搜索结果进行初步的数据可视化分析. 搜索过程的模拟:淘宝的搜索页面有两种形式, 一种形式是, 2019/2 ...
- python 免费空间_用python做大数据
不学Python迟早会被淘汰?Python真有这么好的前景? 最近几年Python编程语言在国内引起不小的轰动,有超越Java之势,本来在美国这个编程语言就是最火的,应用的非常非常的广泛,而Pytho ...
- df python 增加数据_【Note】关于玩转数据处理R语言120题的注解(P1-P50)
前言: 这是关于张敬信老师@张敬信的专栏R&Python数据科学中的文章:玩转数据处理120题(R语言tidyverse版本)的个人自学笔记.敬信老师是我本科期间的恩师之一,非常感谢他提供的学 ...
- python 金融可视化_用 Python 进行金融数据可视化
Python量化的关键是金融数据可视化,不管是传统的K线图,仍是如今的策略分析,都须要大量的可视化图表.具体到编程代码,就是使用Python绘图模块库绘图,好比传统的Python绘图模块库有Matpl ...
最新文章
- 使用MYCAT作为Mysql HA的中间件(转)
- 乐乐茶签约帆软软件,打造新式茶饮数字化管理新标杆
- 某位程序猿柬埔寨开发offer到手,薪资翻倍,去吗?网友:面向阎王编程...
- javascript 类的创建1
- MPLS在ATM技术上实现的研究
- C# 执行文件的根目录 (转)
- Python绘制数码管(系统时间)
- 给定一个数组,寻找次大的数 (1)
- 最详细的Mysql操作手册(一)
- python 数组去重_python数组去重
- 职能型、矩阵型、项目型组织结构的优缺点
- CentOS 7 配置Ruby语言开发环境
- 阿里云 mysql 创建数据库 账户密码 外网连接等
- java 写服务器向客户端发送消息,java服务器向客户端发送消息
- 简明理解 行列式和秩
- Photoshop | 快速抠头发(调整边缘/选择并遮住)
- Origin双Y轴图形画法,添加图例,合并图例
- html5 图片处理 开源,AlloyImage 基于 HTML5 的专业级图像处理开源引擎 - 文章教程...
- 基于3D边界特征的视觉定位技术
- S7-200SMART PLC如何使用MicroSD存储卡来进行程序传输和固件更新?
热门文章
- 《计算机网络》信道划分介质访问控制
- matlab计算图片基频,复倒频谱 - 基频估计
- npm报错 This is probably not a problem with npm,there is likely additional logging output above可能的原因
- 个人博客图片(ElasticSearch)
- Qt 5.15 安装步骤
- python定义一个学生类姓名、年龄、性别、成绩、你成绩评价_.定义一个学生类Student,包含三个属性姓名、年龄、性别,创建三个学生对象存入ArrayList集合中。...
- 2020-2021中科院陈玉福算法设计与分析期末考试
- php开源商城 yii,Yii2开源电商商城Fecshop
- 【学习笔记】大数据技术之HBase
- 【Win8系统:速度快 启动快 关机慢】