GPU的硬件结构中与CUDA相关的几个概念:thread block grid warp sp sm
streaming processor(sp): 最基本的处理单元,streaming processor 最后具体的指令和任务都是在sp上处理的。GPU进行并行计算,也就是很多个sp同时做处理。现在SP的术语已经有点弱化了,而是直接使用thread来代替。一个SP对应一个thread。
Warp:warp是SM调度和执行的基础概念,同时也是一个硬件概念,注意到Warp实际上是一个和硬件相关的概念,通常一个SM中的SP(thread)会分成几个warp(也就是SP在SM中是进行分组的,物理上进行的分组),每一个WARP中在Tegra中是32个thread.这个WARP中的32个thread(sp)是一起工作的,执行相同的指令,如果没有这么多thread需要工作,那么这个WARP中的一些thread(sp)是不工作的。
每一个线程都有自己的寄存器内存和local memory,一个warp中的线程是同时执行的,也就是当进行并行计算时,线程数尽量为32的倍数,如果线程数不上32的倍数的话;假如是1,则warp会生成一个掩码,当一个指令控制器对一个warp单位的线程发送指令时,32个线程中只有一个线程在真正执行,其他31个 进程会进入静默状态。
streaming multiprocessor(sm):多个sp加上其他的一些资源组成一个sm, streaming multiprocessor. 其他资源也就是存储资源,共享内存,寄储器等。可见,一个SM中的所有SP是先分成warp的,是共享同一个memory和instruction unit。
每个SM通过使用两个特殊函数(Special Function Unit,SFU)单元进行超越函数和属性插值函数(根据顶点属性来对像素进行插值)计算。SFU用来执行超越函数、插值以及其他特殊运算
在 G80/G92 的架构下,总共会有 128 个 SP,以 8 个 SP 为一组,组成 16 个 SM,再以两个 SM 为一个 TPC,共分成 8 个 TPC 来运作。而在新一代的 GT200 里,SP 则是增加到 240 个,还是以 8 个 SP 组成一个 SM,但是改成以 3 个 SM 组成一个 TPC,共 10 组 TPC。
在Tegra系列中,一个GPU中通常只有2个SM,每一个SM中包含4个WARP,每一个warp中有32个thread(SP),因此,一个SM中有128个SP。
Stream:流(Stream)是一系列顺序执行的命令,流之间相对无序或并发的执行他们的命令。
软件概念:
thread-->block-->grid:在利用cuda进行编程时,一个grid分为多个block,而一个block分为多个thread。其中任务划分到是否影响最后的执行效果。划分的依据是任务特性和GPU本身的硬件特性。GRID,BLOCK,THREAD是软件概念,而非硬件的概念。
从硬件角度讲,一个GPU由多个SM组成(当然还有其他部分),一个SM包含有多个SP(以及还有寄存器资源,shared memory资源,L1cache,scheduler,SPU,LD/ST单元等等),1.x硬件,一个SM包含8个SP,2.0是32个,2.1是48个,3.0和3.5是192个。以及SP目前也称为CUDA CORE,而SM目前也称为MP,在KEPLER架构(SM3.0和3.5)下也称为SMX。
从软件角度讲,CUDA因为是SIMT的形式,GRID,block,thread是thread的组织形式。最小的逻辑单位是一个thread,最小的硬件执行单位是thread warp(简称warp),若干个thread(典型值是128~512个)组成一个block,block被加载到SM上运行,多个block组成整体的GRID。
这里为什么要有一个中间的层次block呢?这是因为CUDA通过这个概念,提供了细粒度的通信手段,因为block是加载在SM上运行的,所以可以利用SM提供的shared memory和__syncthreads()功能实现线程同步和通信,这带来了很多好处。而block之间,除了结束kernel之外是无法同步的,一般也不保证运行先后顺序,这是因为CUDA程序要保证在不同规模(不同SM数量)的GPU上都可以运行,必须具备规模的可扩展性,因此block之间不能有依赖。
从上面的表述中可以总结:
在GPU中最小的硬件单元是SP(这个术语通常使用thread来代替),而硬件上一个SM中的所有SP在物理上是分成了几个WARP(每一个warp包含一些thread),warp中的SP是可以同时工作的,但是执行相同的指令,也就是说取指令单元取一条指令同时发射给WARP中的所有的SP(假设SP都需要工作,否则有些是idle的).可见,在硬件上一个SM->WARPS->threads(sp).
对于软件thread组织来看,因为一个SM中是分WARP的,而一个WARP包含一定数目(比如Tegra 32个)的sp(thread),因此最好按照这个数目来组织thread,否则硬件该warp上有些SP是不工作的。
这就是CUDA的两级并行结构。
总而言之,一个kernel对应一个GRID,该GRID又包含若干个block,block内包含若干个thread。GRID跑在GPU上的时候,可能是独占一个GPU的,也可能是多个kernel并发占用一个GPU的(需要fermi及更新的GPU架构支持)。
block是resident在SM上的,一个SM可能有一个或多个resident blocks,需要具体根据资源占用分析。
thread以warp为单位被SM的scheduler 发射到SP或者其他单元,如SFU,LD/ST unit执行相关操作,需要等待的warp会被切出(依然是resident 状态),以空出执行单元给其他warps。
GPU中的几种memory及其在系统中的位置:
还有几个概念:
SIMT:SIMT中文译为单指令多线程,英文全称为Single Instruction Multiple Threads。如同CPU中的SIMD。GPU中的SIMT体系结构相对于CPU的SIMD中的概念。为了有效地管理和执行多个单线程,多处理器采用了SIMT架构。此架构在第一个unified computing GPU中由NVIDIA公司生产的GPU引入。不同于CPU中通过SIMD(单指令多数据)来处理矢量数据;GPU则使用SIMT,SIMT的好处是无需开发者费力把数据凑成合适的矢量长度,并且SIMT允许每个线程有不同的分支。 纯粹使用SIMD不能并行的执行有条件跳转的函数,很显然条件跳转会根据输入数据不同在不同的线程中有不同表现,这个只有利用SIMT才能做到。
下面几张硬件结构简图 便于理解(图片来源于网上)


以上两图可以清晰地表示出sm与sp的关系。
http://space.itpub.net/23057064/viewspace-629236
目前市场上的NVIDIA显卡都是基于Tesla架构的,分为G80、G92、GT200三个系列。Tesla体系架构是一块具有可扩展处器数量的处理器阵列。每个GT200 GPU包含240个流处理器(streaming processor,SP),每8个流处理器又组成了一个流多处理器(streaming multiprocessor,SM),因此共有30个流多处理器。GPU在工作时,工作负载由PCI-E总线从CPU传入GPU显存,按照体系架构的层次自顶向下分发。PCI-E 2.0规范中,每个通道上下行的数据传输速度达到了5.0Gbit/s,这样PCI-E2.0×16插槽能够为上下行数据各提供了5.0*16Gbit/s=10GB/s的带宽,故有效带宽为8GB/s,而PCI-E 3.0规范的上下行数据带宽各为20GB/s。但是由于PCI-E数据封包的影响,实际可用的带宽大约在5-6GB/s(PCI-E 2.0 ×16)。
在GT200架构中,每3个SM组成一个TPC(Thread Processing Cluster,线程处理器集群),而在G80架构中,是两个SM组成一个TPC,G80里面有8个TPC,因为G80有128(2*8*8)个流处理器,而GT200中TPC增加到了10(3*10*8)个,其中,每个TPC内部还有一个纹理流水线。
大多数时候,称呼streaming processor为流处理器,其实并不太正确,因为如果称streaming processor为流处理器的话,自然是隐式的与CPU相对,但是CPU有独立的一套输入输出机构,而streaming processor并没有,不能在GPU编程中使用printf就是一个例证。将SM与CPU的核相比更加合适。和现在的CPU的核一样,SM也拥有完整前端。
GT200和G80的每个SM包含8个流处理器。流处理器也有其他的名称,如线程处理器,“核”等,而最新的Fermi架构中,给了它一个新的名称:CUDA Core。SP并不是独立的处理器核,它有独立的寄存器和程序计数器(PC),但没有取指和调度单元来构成完整的前端(由SM提供)。因此,SP更加类似于当代的多线程CPU中的一条流水线。SM每发射一条指令,8个SP将各执行4遍。因此由32个线程组成的线程束(warp)是Tesla架构的最小执行单位。由于GPU中SP的频率略高于SM中其他单元的两倍,因此每两个SP周期SP才能对片内存储器进行一次访问,所以一个warp中的32个线程又可以分为两个half-warp,这也是为什么取数会成为运算的瓶颈原因。Warp的大小对操作延迟和访存延迟会产生影响,取Warp大小为32是NVIDIA综合权衡的结果。
SM最主要的执行资源是8个32bit ALU和MAD(multiply-add units,乘加器)。它们能够对符合IEEE标准的单精度浮点数(对应float型)和32-bit整数(对应int型,或者unsigned int型)进行运算。每次运算需要4个时钟周期(SP周期,并非核心周期)。因为使用了四级流水线,因此在每个时钟周期,ALU或MAD都能取出一个warp的32个线程中的8个操作数,在随后的3个时钟周期内进行运算并写回结果。
每个SM中,还有一个共享存储器(Shared memory),共享存储器用于通用并行计算时的共享数据和块内线程通信,但是由于它采用的是片上存储器,其速度极快,因此也被用于优化程序性能。
每个SM通过使用两个特殊函数(Special Function Unit,SFU)单元进行超越函数和属性插值函数(根据顶点属性来对像素进行插值)计算。SFU用来执行超越函数、插值以及其他特殊运算。SFU执行的指令大多数有16个时钟周期的延迟,而一些由多个指令构成的复杂运算,如平方根或者指数运算则需要32甚至更多的时钟周期。SFU中用于插值的部分拥有若干个32-bit浮点乘法单元,可以用来进行独立于浮点处理单元(Float Processing Unit,FPU)的乘法运算。SFU实际上有两个执行单元,每个执行单元为SM中8条流水线中的4条服务。向SFU发射的乘法指令也只需要4个时钟周期。
在GT200中,每个SM还有一个双精度单元,用于双精度计算,但是其计算能力不到单精度的1/8。
控制流指令(CMP,比较指令)是由分支单元执行的。GPU没有分支预测机制,因此在分支得到机会执行之前,它将被挂起,直到所有的分支路径都执行完成,这会极大的降低性能。
GPU中的软件概念:kernel->grid->block->warp->thread
Grid、Block和Thread的关系
http://www.cnblogs.com/qingsunny/p/3384779.html
Thread :并行运算的基本单位(轻量级的线程)
Block :由相互合作的一组线程组成。一个block中的thread可以彼此同步,快速交换数据,最多可以同时512个线程。
Grid :一组Block,有共享全局内存
Kernel :在GPU上执行的程序,一个Kernel对应一个Grid。
http://www.cnblogs.com/dubing/archive/2011/10/10/2085742.html
CUDA在执行的时候是让host里面的一个一个的kernel按照线程网格(Grid)的概念在显卡硬件(GPU)上执行。每一个线程网格又可以包含多个线程块(block),每一个线程块中又可以包含多个线程(thread)。每一个kernel交给每一个Grid来完成。当要执行这些任务的时候,每一个Grid又把任务分成一部分一部分的block,block再分线程来完成。每个Grid中的任务是一定的。二维线程块的索引关系为如下:
unsigned int xIndex = blockDim.x * blockIdx.x + threadIdx.x;
unsigned int yIndex = blockDim.y * blockIdx.y + threadIdx.y;
block中的每个线程都有自己的寄存器和local memory,block中的所有线程共享一个shared memory,一个grid共享一个global memory。每一个时钟周期内,warp(一个block里面一起运行的thread)包含的thread数量是有限的,现在的规定是32个。一个block中含有16个warp。所以一个block中最多含有512个线程.每次Device(就是显卡)只处理一个grid。
其结构如下图所示:
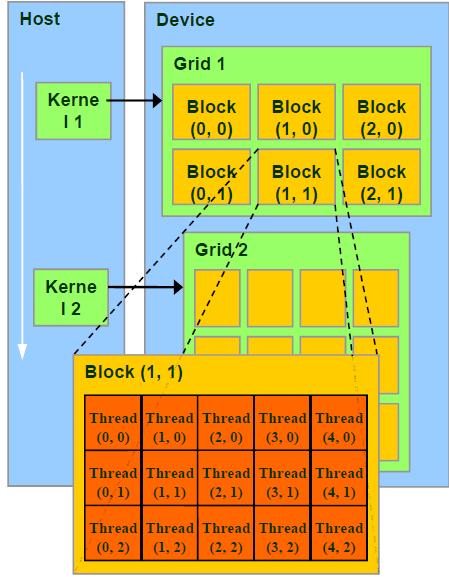

此图反应了warp作为调度单位的作用,每次GPU调度一个warp里的32个线程执行同一条指令,其中各
个线程对应的数据资源不同(指令相同但是数据不同)。

此图是一个warp排程的例子。
一个sm只会执行一个block里的warp,当该block里warp执行完才会执行其他block里的warp。
进行划分时,最好保证每个block里的warp比较合理,那样可以一个sm可以交替执行里面的warp,从而提高
效率,此外,在分配block时,要根据GPU的sm个数,分配出合理的block数,让GPU的sm都利用起来,提
利用率。分配时,也要考虑到同一个线程block的资源问题,不要出现对应的资源不够。
软件的概念: thread->warp(32 thread,执行相同的指令但是数据不同,是GPU基本的调度单位)->block->grid
GPU的硬件结构中与CUDA相关的几个概念:thread block grid warp sp sm相关推荐
- CUDA学习----sp, sm, thread, block, grid, warp概念
CUDA学习----sp, sm, thread, block, grid, warp概念 2017-01-11 17:14:28| 分类: HPC&CUDA优化 | 标签:cuda g ...
- GPU中与CUDA相关的几个概念
GPU中与CUDA相关的几个概念 标签: cudathread任务编程存储 2012-06-04 12:42 2998人阅读 评论(0) 收藏 举报 分类: GPU(284) 计算机系统(78) 硬件 ...
- cuda笔记-初始化矩阵及thread,block,grid概念
thread:一个CUDA的并行程序会被许多threads来执行: block:多个threads组成一个block,同一个block中threads可以使用_syncthreads()同步,也可以通 ...
- GPU软件抽象与硬件映射的理解(Grid、Block、Warp、Thread与SM、SP)
GPU软件抽象与硬件映射的理解 1 从程序到软件抽象: 组成关系: GPU上运行函数kernel对应一个Grid,每个Grid内有多个Block,每个Block由多个Thread组成. 运行方式: B ...
- 显卡,GPU,显卡驱动,CUDA ,CUDA Toolkit之间的关系
相关知识收集于网络,主要来自 显卡,显卡驱动,nvcc, cuda driver,cudatoolkit,cudnn到底是什么? GPU 和显卡是什么关系? 显卡.显卡驱动.cuda 之间的关系是什么 ...
- GPU加速(一)CUDA C编程及GPU基本知识
前 言 笔记来自深蓝学院<CUDA入门与深度神经网络加速> 补充:线程与线程 线程是进程中执行运算(CPU调度)的最小单位.同一类线程共享代码和数据空间:进程是资源分配的最小单位.每个进程 ...
- CUDA下的GPU编程入门--第一个CUDA程序
CUDA是NVIDIA公司开发的一个用于GPU编程的开源框架,用于将GPU用于更广泛的数学计算,充当cpu的功能,所以只能在nvidia的GPU下实现,如果你的GPU不是nvidia的,赶紧去换一个吧 ...
- NVIDIA显卡驱动及CUDA相关安装流程(包括多版本cuda切换)
NVIDIA显卡驱动及CUDA相关安装流程 NVIDIA驱动安装 NVIDIA驱动官方下载地址: https://www.nvidia.cn/Download/index.aspx?lang=cn 第 ...
- 在keras中使用gpu加速训练模型;安装cuda;cudnn;cudnn_cnn_infer64_8.dll 不在path中;device_lib.list_local_devices无gpu;挂掉
在keras中使用gpu加速训练模型,如何安装cuda,cudnn,解决cudnn_cnn_infer64_8.dll 不在path中,解决device_lib.list_local_devices( ...
最新文章
- filebeat配置详解
- snort3安装教程
- python中pos的用法_Python:数组、队列及堆栈的使用(list用法)--转
- mysql5.718解压版安装_MySQL v5.7.18 版本解压安装
- 事实表和维度表是怎么造数据_从电商数据指标到电商数据中台
- java计算加减表达式_【Java】计算加减乘除数学公式(简单计算器)含小数
- P3327-[SDOI2015]约数个数和【莫比乌斯反演】
- python不同目录调用_python3 不同目录间模块调用
- 吴思涵国内首场肿瘤ecDNA学术报告|深度揭秘半个世纪ecDNA的研究成果及突破性进展...
- 统计字符数(信息学奥赛一本通-T1187)
- v-viewer图片打不开一直在刷新_python实现将一组图片转化成视频
- VScode Settings Sync同步功能设置
- 电源大师课笔记 1.5
- CAD迷你看图 for Mac(MiniCAD)
- 4600u黑苹果 r5_黑苹果配置 篇四:黑苹果硬件选购指南之m-ATX篇--2019年8月
- CUDA版本与显卡驱动匹配
- 欢度国庆⭐️共享爬虫之美⭐️基于 Python 实现微信公众号爬虫(Python无所不能爬)
- 性能测试工具loucst使用(最新版本)
- 从零开始操作系统-07:APIC
- Flutter实战开发(2)------实现条形码扫描获取商品信息