datax参数设置_DataX-操作HDFS
DataX操作HDFS
读取HDFS
1 快速介绍
HdfsReader提供了读取分布式文件系统数据存储的能力。在底层实现上,HdfsReader获取分布式文件系统上文件的数据,并转换为DataX传输协议传递给Writer。
目前HdfsReader支持的文件格式有textfile(text)、orcfile(orc)、rcfile(rc)、sequence file(seq)和普通逻辑二维表(csv)类型格式的文件,且文件内容存放的必须是一张逻辑意义上的二维表。
HdfsReader需要Jdk1.7及以上版本的支持。
2 功能与限制
HdfsReader实现了从Hadoop分布式文件系统Hdfs中读取文件数据并转为DataX协议的功能。textfile是Hive建表时默认使用的存储格式,数据不做压缩,本质上textfile就是以文本的形式将数据存放在hdfs中,对于DataX而言,HdfsReader实现上类比TxtFileReader,有诸多相似之处。orcfile,它的全名是Optimized Row Columnar file,是对RCFile做了优化。据官方文档介绍,这种文件格式可以提供一种高效的方法来存储Hive数据。HdfsReader利用Hive提供的OrcSerde类,读取解析orcfile文件的数据。目前HdfsReader支持的功能如下:
1.支持textfile、orcfile、rcfile、sequence file和csv格式的文件,且要求文件内容存放的是一张逻辑意义上的二维表。
2.支持多种类型数据读取(使用String表示),支持列裁剪,支持列常量
3.支持递归读取、支持正则表达式("*"和"?")。
4.支持orcfile数据压缩,目前支持SNAPPY,ZLIB两种压缩方式。
5.多个File可以支持并发读取。
6.支持sequence file数据压缩,目前支持lzo压缩方式。
7.csv类型支持压缩格式有:gzip、bz2、zip、lzo、lzo_deflate、snappy。
8.目前插件中Hive版本为1.1.1,Hadoop版本为2.7.1(Apache[为适配JDK1.7],在Hadoop 2.5.0, Hadoop 2.6.0 和Hive 1.2.0测试环境中写入正常;其它版本需后期进一步测试;
9.支持kerberos认证(注意:如果用户需要进行kerberos认证,那么用户使用的Hadoop集群版本需要和hdfsreader的Hadoop版本保持一致,如果高于hdfsreader的Hadoop版本,不保证kerberos认证有效)
暂时不能做到:
1.单个File支持多线程并发读取,这里涉及到单个File内部切分算法。二期考虑支持。
2.目前还不支持hdfs HA;
实例
读取HDFS控制台输出
json如下
{"job": {"setting": {"speed": {"channel": 3}
},"content": [{"reader": {"name": "hdfsreader","parameter": {"path": "/user/hive/warehouse/test/*","defaultFS": "hdfs://192.168.1.121:8020","column": [{"index": 0,"type": "long"},
{"index": 1,"type": "string"},
{"type": "string","value": "hello"}
],"fileType": "text","encoding": "UTF-8","fieldDelimiter": ","}
},"writer": {"name": "streamwriter","parameter": {"print": true}
}
}]
}
}
执行
FengZhendeMacBook-Pro:bin FengZhen$ ./datax.py /Users/FengZhen/Desktop/Hadoop/dataX/json/HDFS/1.reader_all.json
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !Copyright (C)2010-2017, Alibaba Group. All Rights Reserved.2018-11-18 17:28:30.540 [main] INFO VMInfo - VMInfo# operatingSystem class =>sun.management.OperatingSystemImpl2018-11-18 17:28:30.551 [main] INFO Engine - the machine info =>osInfo: Oracle Corporation1.8 25.162-b12
jvmInfo: Mac OS X x86_6410.13.4cpu num:4totalPhysicalMemory:-0.00G
freePhysicalMemory:-0.00G
maxFileDescriptorCount:-1currentOpenFileDescriptorCount:-1GC Names [PS MarkSweep, PS Scavenge]
MEMORY_NAME| allocation_size |init_size
PS Eden Space| 256.00MB | 256.00MB
Code Cache| 240.00MB | 2.44MB
Compressed Class Space| 1,024.00MB | 0.00MB
PS Survivor Space| 42.50MB | 42.50MB
PS Old Gen| 683.00MB | 683.00MB
Metaspace| -0.00MB | 0.00MB2018-11-18 17:28:30.572 [main] INFO Engine -{"content":[
{"reader":{"name":"hdfsreader","parameter":{"column":[
{"index":0,"type":"long"},
{"index":1,"type":"string"},
{"type":"string","value":"hello"}
],"defaultFS":"hdfs://192.168.1.121:8020","encoding":"UTF-8","fieldDelimiter":",","fileType":"text","path":"/user/hive/warehouse/test/*"}
},"writer":{"name":"streamwriter","parameter":{"print":true}
}
}
],"setting":{"speed":{"channel":3}
}
}2018-11-18 17:28:30.601 [main] WARN Engine - prioriy set to 0, because NumberFormatException, the value is: null
2018-11-18 17:28:30.605 [main] INFO PerfTrace - PerfTrace traceId=job_-1, isEnable=false, priority=0
2018-11-18 17:28:30.605 [main] INFO JobContainer -DataX jobContainer starts job.2018-11-18 17:28:30.609 [main] INFO JobContainer - Set jobId = 0
2018-11-18 17:28:30.650 [job-0] INFO HdfsReader$Job -init() begin...2018-11-18 17:28:31.318 [job-0] INFO HdfsReader$Job - hadoopConfig details:{"finalParameters":[]}2018-11-18 17:28:31.318 [job-0] INFO HdfsReader$Job -init() ok and end...2018-11-18 17:28:31.326 [job-0] INFO JobContainer - jobContainer starts to doprepare ...2018-11-18 17:28:31.327 [job-0] INFO JobContainer - DataX Reader.Job [hdfsreader] doprepare work .2018-11-18 17:28:31.327 [job-0] INFO HdfsReader$Job -prepare(), start to getAllFiles...2018-11-18 17:28:31.327 [job-0] INFO HdfsReader$Job - get HDFS all files in path = [/user/hive/warehouse/test/*]
Nov 18, 2018 5:28:31 PM org.apache.hadoop.util.NativeCodeLoader
警告: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2018-11-18 17:28:33.323 [job-0] INFO HdfsReader$Job - [hdfs://192.168.1.121:8020/user/hive/warehouse/test/data]是[text]类型的文件, 将该文件加入source files列表
2018-11-18 17:28:33.327 [job-0] INFO HdfsReader$Job - 您即将读取的文件数为: [1], 列表为: [hdfs://192.168.1.121:8020/user/hive/warehouse/test/data]
2018-11-18 17:28:33.328 [job-0] INFO JobContainer - DataX Writer.Job [streamwriter] do prepare work .
2018-11-18 17:28:33.328 [job-0] INFO JobContainer - jobContainer starts to do split ...
2018-11-18 17:28:33.329 [job-0] INFO JobContainer - Job set Channel-Number to 3 channels.
2018-11-18 17:28:33.329 [job-0] INFO HdfsReader$Job - split() begin...
2018-11-18 17:28:33.330 [job-0] INFO JobContainer - DataX Reader.Job [hdfsreader] splits to [1] tasks.
2018-11-18 17:28:33.331 [job-0] INFO JobContainer - DataX Writer.Job [streamwriter] splits to [1] tasks.
2018-11-18 17:28:33.347 [job-0] INFO JobContainer - jobContainer starts to do schedule ...
2018-11-18 17:28:33.356 [job-0] INFO JobContainer - Scheduler starts [1] taskGroups.
2018-11-18 17:28:33.359 [job-0] INFO JobContainer - Running by standalone Mode.
2018-11-18 17:28:33.388 [taskGroup-0] INFO TaskGroupContainer - taskGroupId=[0] start [1] channels for [1] tasks.
2018-11-18 17:28:33.396 [taskGroup-0] INFO Channel - Channel set byte_speed_limit to -1, No bps activated.
2018-11-18 17:28:33.397 [taskGroup-0] INFO Channel - Channel set record_speed_limit to -1, No tps activated.
2018-11-18 17:28:33.419 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] attemptCount[1] is started
2018-11-18 17:28:33.516 [0-0-0-reader] INFO HdfsReader$Job - hadoopConfig details:{"finalParameters":["mapreduce.job.end-notification.max.retry.interval","mapreduce.job.end-notification.max.attempts"]}
2018-11-18 17:28:33.517 [0-0-0-reader] INFO Reader$Task - read start
2018-11-18 17:28:33.518 [0-0-0-reader] INFO Reader$Task - reading file : [hdfs://192.168.1.121:8020/user/hive/warehouse/test/data]
2018-11-18 17:28:33.790 [0-0-0-reader] INFO UnstructuredStorageReaderUtil - CsvReader使用默认值[{"captureRawRecord":true,"columnCount":0,"comment":"#","currentRecord":-1,"delimiter":",","escapeMode":1,"headerCount":0,"rawRecord":"","recordDelimiter":"\u0000","safetySwitch":false,"skipEmptyRecords":true,"textQualifier":"\"","trimWhitespace":true,"useComments":false,"useTextQualifier":true,"values":[]}],csvReaderConfig值为[null]
2018-11-18 17:28:33.845 [0-0-0-reader] INFO Reader$Task - end read source files...
1 张三 hello
2 李四 hello
2018-11-18 17:28:34.134 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] is successed, used[715]ms
2018-11-18 17:28:34.137 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] completed it‘s tasks.
2018-11-18 17:28:43.434 [job-0] INFO StandAloneJobContainerCommunicator - Total 2 records, 16 bytes | Speed 1B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.425s | Percentage 100.00%
2018-11-18 17:28:43.435 [job-0] INFO AbstractScheduler - Scheduler accomplished all tasks.
2018-11-18 17:28:43.436 [job-0] INFO JobContainer - DataX Writer.Job [streamwriter] do post work.
2018-11-18 17:28:43.436 [job-0] INFO JobContainer - DataX Reader.Job [hdfsreader] do post work.
2018-11-18 17:28:43.437 [job-0] INFO JobContainer - DataX jobId [0] completed successfully.
2018-11-18 17:28:43.438 [job-0] INFO HookInvoker - No hook invoked, because base dir not exists or is a file: /Users/FengZhen/Desktop/Hadoop/dataX/datax/hook
2018-11-18 17:28:43.446 [job-0] INFO JobContainer -
[total cpu info] =>
averageCpu | maxDeltaCpu | minDeltaCpu
-1.00% | -1.00% | -1.00%
[total gc info] =>
NAME | totalGCCount | maxDeltaGCCount | minDeltaGCCount | totalGCTime | maxDeltaGCTime | minDeltaGCTime
PS MarkSweep | 1 | 1 | 1 | 0.038s | 0.038s | 0.038s
PS Scavenge | 1 | 1 | 1 | 0.020s | 0.020s | 0.020s
2018-11-18 17:28:43.446 [job-0] INFO JobContainer - PerfTrace not enable!
2018-11-18 17:28:43.447 [job-0] INFO StandAloneJobContainerCommunicator - Total 2 records, 16 bytes | Speed 1B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.425s | Percentage 100.00%
2018-11-18 17:28:43.448 [job-0] INFO JobContainer -
任务启动时刻 : 2018-11-18 17:28:30
任务结束时刻 : 2018-11-18 17:28:43
任务总计耗时 : 12s
任务平均流量 : 1B/s
记录写入速度 : 0rec/s
读出记录总数 : 2
读写失败总数 : 0
参数说明(各个配置项值前后不允许有空格)
--path
描述:要读取的文件路径,如果要读取多个文件,可以使用正则表达式"*",注意这里可以支持填写多个路径。。
当指定单个Hdfs文件,HdfsReader暂时只能使用单线程进行数据抽取。二期考虑在非压缩文件情况下针对单个File可以进行多线程并发读取。
当指定多个Hdfs文件,HdfsReader支持使用多线程进行数据抽取。线程并发数通过通道数指定。
当指定通配符,HdfsReader尝试遍历出多个文件信息。例如: 指定/代表读取/目录下所有的文件,指定/bazhen/*代表读取bazhen目录下游所有的文件。HdfsReader目前只支持""和"?"作为文件通配符。
特别需要注意的是,DataX会将一个作业下同步的所有的文件视作同一张数据表。用户必须自己保证所有的File能够适配同一套schema信息。并且提供给DataX权限可读。
必选:是
默认值:无
--defaultFS
描述:Hadoop hdfs文件系统namenode节点地址。
目前HdfsReader已经支持Kerberos认证,如果需要权限认证,则需要用户配置kerberos参数,见下面
必选:是
默认值:无
--fileType
描述:文件的类型,目前只支持用户配置为"text"、"orc"、"rc"、"seq"、"csv"。
text表示textfile文件格式
orc表示orcfile文件格式
rc表示rcfile文件格式
seq表示sequence file文件格式
csv表示普通hdfs文件格式(逻辑二维表)
特别需要注意的是,HdfsReader能够自动识别文件是orcfile、textfile或者还是其它类型的文件,但该项是必填项,HdfsReader则会只读取用户配置的类型的文件,忽略路径下其他格式的文件
另外需要注意的是,由于textfile和orcfile是两种完全不同的文件格式,所以HdfsReader对这两种文件的解析方式也存在差异,这种差异导致hive支持的复杂复合类型(比如map,array,struct,union)在转换为DataX支持的String类型时,转换的结果格式略有差异,比如以map类型为例:
orcfile map类型经hdfsreader解析转换成datax支持的string类型后,结果为"{job=80, team=60, person=70}"
textfile map类型经hdfsreader解析转换成datax支持的string类型后,结果为"job:80,team:60,person:70"
从上面的转换结果可以看出,数据本身没有变化,但是表示的格式略有差异,所以如果用户配置的文件路径中要同步的字段在Hive中是复合类型的话,建议配置统一的文件格式。
如果需要统一复合类型解析出来的格式,我们建议用户在hive客户端将textfile格式的表导成orcfile格式的表
必选:是
默认值:无
--column
描述:读取字段列表,type指定源数据的类型,index指定当前列来自于文本第几列(以0开始),value指定当前类型为常量,不从源头文件读取数据,而是根据value值自动生成对应的列。
默认情况下,用户可以全部按照String类型读取数据,配置如下:
"column": ["*"]
用户可以指定Column字段信息,配置如下:
{ "type": "long", "index": 0 //从本地文件文本第一列获取int字段 }, { "type": "string", "value": "alibaba" //HdfsReader内部生成alibaba的字符串字段作为当前字段 } ```
对于用户指定Column信息,type必须填写,index/value必须选择其一。
* 必选:是
* 默认值:全部按照string类型读取
--fieldDelimiter
描述:读取的字段分隔符
另外需要注意的是,HdfsReader在读取textfile数据时,需要指定字段分割符,如果不指定默认为‘,‘,HdfsReader在读取orcfile时,用户无需指定字段分割符
必选:否
默认值:,
--encoding
描述:读取文件的编码配置。
必选:否
默认值:utf-8
--nullFormat
描述:文本文件中无法使用标准字符串定义null(空指针),DataX提供nullFormat定义哪些字符串可以表示为null。
例如如果用户配置: nullFormat:"\N",那么如果源头数据是"\N",DataX视作null字段。
必选:否
默认值:无
--haveKerberos
描述:是否有Kerberos认证,默认false
例如如果用户配置true,则配置项kerberosKeytabFilePath,kerberosPrincipal为必填。
必选:haveKerberos 为true必选
默认值:false
--kerberosKeytabFilePath
描述:Kerberos认证 keytab文件路径,绝对路径
必选:否
默认值:无
--kerberosPrincipal
描述:Kerberos认证Principal名,如xxxx/hadoopclient@xxx.xxx
必选:haveKerberos 为true必选
默认值:无
--compress
描述:当fileType(文件类型)为csv下的文件压缩方式,目前仅支持 gzip、bz2、zip、lzo、lzo_deflate、hadoop-snappy、framing-snappy压缩;值得注意的是,lzo存在两种压缩格式:lzo和lzo_deflate,用户在配置的时候需要留心,不要配错了;另外,由于snappy目前没有统一的stream format,datax目前只支持最主流的两种:hadoop-snappy(hadoop上的snappy stream format)和framing-snappy(google建议的snappy stream format);orc文件类型下无需填写。
必选:否
默认值:无
--hadoopConfig
描述:hadoopConfig里可以配置与Hadoop相关的一些高级参数,比如HA的配置。
"hadoopConfig":{
"dfs.nameservices": "testDfs",
"dfs.ha.namenodes.testDfs": "namenode1,namenode2",
"dfs.namenode.rpc-address.aliDfs.namenode1": "",
"dfs.namenode.rpc-address.aliDfs.namenode2": "",
"dfs.client.failover.proxy.provider.testDfs": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
}
必选:否
默认值:无
--csvReaderConfig
描述:读取CSV类型文件参数配置,Map类型。读取CSV类型文件使用的CsvReader进行读取,会有很多配置,不配置则使用默认值。
必选:否
默认值:无
常见配置:
"csvReaderConfig":{
"safetySwitch": false,
"skipEmptyRecords": false,
"useTextQualifier": false
}
所有配置项及默认值,配置时 csvReaderConfig 的map中请严格按照以下字段名字进行配置:
boolean caseSensitive = true;
char textQualifier = 34;
boolean trimWhitespace = true;
boolean useTextQualifier = true;//是否使用csv转义字符
char delimiter = 44;//分隔符
char recordDelimiter = 0;
char comment = 35;
boolean useComments = false;
int escapeMode = 1;
boolean safetySwitch = true;//单列长度是否限制100000字符
boolean skipEmptyRecords = true;//是否跳过空行
boolean captureRawRecord = true;
类型转换
由于textfile和orcfile文件表的元数据信息由Hive维护并存放在Hive自己维护的数据库(如mysql)中,目前HdfsReader不支持对Hive元数
据数据库进行访问查询,因此用户在进行类型转换的时候,必须指定数据类型,如果用户配置的column为"*",则所有column默认转换为
string类型。HdfsReader提供了类型转换的建议表如下:

其中:
--Long是指Hdfs文件文本中使用整形的字符串表示形式,例如"123456789"。
--Double是指Hdfs文件文本中使用Double的字符串表示形式,例如"3.1415"。
--Boolean是指Hdfs文件文本中使用Boolean的字符串表示形式,例如"true"、"false"。不区分大小写。
--Date是指Hdfs文件文本中使用Date的字符串表示形式,例如"2014-12-31"。
特别提醒:
--Hive支持的数据类型TIMESTAMP可以精确到纳秒级别,所以textfile、orcfile中TIMESTAMP存放的数据类似于"2015-08-21 22:40:47.397898389",如果转换的类型配置为DataX的Date,转换之后会导致纳秒部分丢失,所以如果需要保留纳秒部分的数据,请配置转换类型为DataX的String类型。
按分区读取
Hive在建表的时候,可以指定分区partition,例如创建分区partition(day="20150820",hour="09"),对应的hdfs文件系统中,相应的表的目录下则会多出/20150820和/09两个目录,且/20150820是/09的父目录。了解了分区都会列成相应的目录结构,在按照某个分区读取某个表所有数据时,则只需配置好json中path的值即可。
比如需要读取表名叫mytable01下分区day为20150820这一天的所有数据,则配置如下:
"path": "/user/hive/warehouse/mytable01/20150820/*"
写入HDFS
1 快速介绍
HdfsWriter提供向HDFS文件系统指定路径中写入TEXTFile文件和ORCFile文件,文件内容可与hive中表关联。
2 功能与限制
(1)、目前HdfsWriter仅支持textfile和orcfile两种格式的文件,且文件内容存放的必须是一张逻辑意义上的二维表;
(2)、由于HDFS是文件系统,不存在schema的概念,因此不支持对部分列写入;
(3)、目前仅支持与以下Hive数据类型: 数值型:TINYINT,SMALLINT,INT,BIGINT,FLOAT,DOUBLE 字符串类型:STRING,VARCHAR,CHAR 布尔类型:BOOLEAN 时间类型:DATE,TIMESTAMP 目前不支持:decimal、binary、arrays、maps、structs、union类型;
(4)、对于Hive分区表目前仅支持一次写入单个分区;
(5)、对于textfile需用户保证写入hdfs文件的分隔符与在Hive上创建表时的分隔符一致,从而实现写入hdfs数据与Hive表字段关联;
(6)、HdfsWriter实现过程是:首先根据用户指定的path,创建一个hdfs文件系统上不存在的临时目录,创建规则:path_随机;然后将读取的文件写入这个临时目录;全部写入后再将这个临时目录下的文件移动到用户指定目录(在创建文件时保证文件名不重复); 最后删除临时目录。如果在中间过程发生网络中断等情况造成无法与hdfs建立连接,需要用户手动删除已经写入的文件和临时目录。
(7)、目前插件中Hive版本为1.1.1,Hadoop版本为2.7.1(Apache[为适配JDK1.7],在Hadoop 2.5.0, Hadoop 2.6.0 和Hive 1.2.0测试环境中写入正常;其它版本需后期进一步测试;
(8)、目前HdfsWriter支持Kerberos认证(注意:如果用户需要进行kerberos认证,那么用户使用的Hadoop集群版本需要和hdfsreader的Hadoop版本保持一致,如果高于hdfsreader的Hadoop版本,不保证kerberos认证有效)
json如下
{"setting": {},"job": {"setting": {"speed": {"channel": 2}
},"content": [{"reader": {"name": "txtfilereader","parameter": {"path": ["/Users/FengZhen/Desktop/Hadoop/dataX/json/HDFS/data.txt"],"encoding": "UTF-8","column": [{"index": 0,"type": "long"},
{"index": 1,"type": "long"},
{"index": 2,"type": "long"},
{"index": 3,"type": "long"},
{"index": 4,"type": "DOUBLE"},
{"index": 5,"type": "DOUBLE"},
{"index": 6,"type": "STRING"},
{"index": 7,"type": "STRING"},
{"index": 8,"type": "STRING"},
{"index": 9,"type": "BOOLEAN"},
{"index": 10,"type": "date"},
{"index": 11,"type": "date"}
],"fieldDelimiter": "`"}
},"writer": {"name": "hdfswriter","parameter": {"defaultFS": "hdfs://192.168.1.121:8020","fileType": "orc","path": "/user/hive/warehouse/hdfswriter.db/orc_table","fileName": "hdfswriter","column": [{"name": "col1","type": "TINYINT"},
{"name": "col2","type": "SMALLINT"},
{"name": "col3","type": "INT"},
{"name": "col4","type": "BIGINT"},
{"name": "col5","type": "FLOAT"},
{"name": "col6","type": "DOUBLE"},
{"name": "col7","type": "STRING"},
{"name": "col8","type": "VARCHAR"},
{"name": "col9","type": "CHAR"},
{"name": "col10","type": "BOOLEAN"},
{"name": "col11","type": "date"},
{"name": "col12","type": "TIMESTAMP"}
],"writeMode": "append","fieldDelimiter": "`","compress": "NONE"}
}
}]
}
}
参数说明
--defaultFS
描述:Hadoop hdfs文件系统namenode节点地址。格式:hdfs://ip:端口;例如:hdfs://127.0.0.1:9000
必选:是
默认值:无
--fileType
描述:文件的类型,目前只支持用户配置为"text"或"orc"。
text表示textfile文件格式
orc表示orcfile文件格式
必选:是
默认值:无
--path
描述:存储到Hadoop hdfs文件系统的路径信息,HdfsWriter会根据并发配置在Path目录下写入多个文件。为与hive表关联,请填写hive表在hdfs上的存储路径。例:Hive上设置的数据仓库的存储路径为:/user/hive/warehouse/ ,已建立数据库:test,表:hello;则对应的存储路径为:/user/hive/warehouse/test.db/hello
必选:是
默认值:无
--fileName
描述:HdfsWriter写入时的文件名,实际执行时会在该文件名后添加随机的后缀作为每个线程写入实际文件名。
必选:是
默认值:无
--column
描述:写入数据的字段,不支持对部分列写入。为与hive中表关联,需要指定表中所有字段名和字段类型,其中:name指定字段名,type指定字段类型。
用户可以指定Column字段信息,配置如下:
"column":
[
{
"name": "userName",
"type": "string"
},
{
"name": "age",
"type": "long"
}
]
必选:是
默认值:无
--writeMode
描述:hdfswriter写入前数据清理处理模式:
?append,写入前不做任何处理,DataX hdfswriter直接使用filename写入,并保证文件名不冲突。
?nonConflict,如果目录下有fileName前缀的文件,直接报错。
必选:是
默认值:无
--fieldDelimiter
描述:hdfswriter写入时的字段分隔符,需要用户保证与创建的Hive表的字段分隔符一致,否则无法在Hive表中查到数据
必选:是
默认值:无
--compress
描述:hdfs文件压缩类型,默认不填写意味着没有压缩。其中:text类型文件支持压缩类型有gzip、bzip2;orc类型文件支持的压缩类型有NONE、SNAPPY(需要用户安装SnappyCodec)。
a必选:否
默认值:无压缩
--hadoopConfig
描述:hadoopConfig里可以配置与Hadoop相关的一些高级参数,比如HA的配置。
"hadoopConfig":{
"dfs.nameservices": "testDfs",
"dfs.ha.namenodes.testDfs": "namenode1,namenode2",
"dfs.namenode.rpc-address.aliDfs.namenode1": "",
"dfs.namenode.rpc-address.aliDfs.namenode2": "",
"dfs.client.failover.proxy.provider.testDfs": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
}
必选:否
默认值:无
--encoding
描述:写文件的编码配置。
必选:否
默认值:utf-8,慎重修改
--haveKerberos
描述:是否有Kerberos认证,默认false
例如如果用户配置true,则配置项kerberosKeytabFilePath,kerberosPrincipal为必填。
必选:haveKerberos 为true必选
默认值:false
--kerberosKeytabFilePath
描述:Kerberos认证 keytab文件路径,绝对路径
必选:否
默认值:无
--kerberosPrincipal
描述:Kerberos认证Principal名,如xxxx/hadoopclient@xxx.xxx
必选:haveKerberos 为true必选
默认值:无
类型转换
目前 HdfsWriter 支持大部分 Hive 类型,请注意检查你的类型。
下面列出 HdfsWriter 针对 Hive 数据类型转换列表:
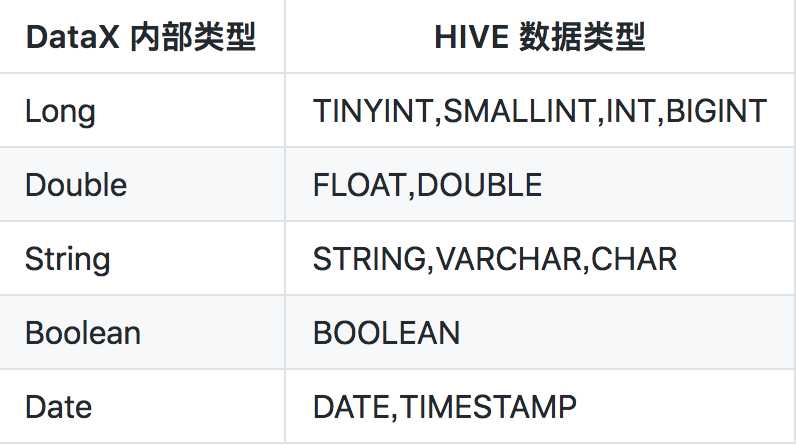
数据准备
data.txt
1`2`3`4`5`6`7`8`9`true`2018-11-18 09:15:30`2018-11-18 09:15:30
13`14`15`16`17`18`19`20`21`false`2018-11-18 09:16:30`2018-11-18 09:15:30
建表(text格式的)
create database IF NOT EXISTS hdfswriter;
use hdfswriter;
create table text_table(
col1 TINYINT,
col2 SMALLINT,
col3 INT,
col4 BIGINT,
col5 FLOAT,
col6 DOUBLE,
col7 STRING,
col8 VARCHAR(10),
col9 CHAR(10),
col10 BOOLEAN,
col11 date,
col12 TIMESTAMP
)
row format delimited
fields terminated by"`"STORED AS TEXTFILE;
Orc格式的
create database IF NOT EXISTS hdfswriter;
use hdfswriter;
create table orc_table(
col1 TINYINT,
col2 SMALLINT,
col3 INT,
col4 BIGINT,
col5 FLOAT,
col6 DOUBLE,
col7 STRING,
col8 VARCHAR(10),
col9 CHAR(10),
col10 BOOLEAN,
col11 date,
col12 TIMESTAMP
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY‘`‘STORED AS ORC;
执行json文件
FengZhendeMacBook-Pro:bin FengZhen$ ./datax.py /Users/FengZhen/Desktop/Hadoop/dataX/json/HDFS/2.writer.json
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !Copyright (C)2010-2017, Alibaba Group. All Rights Reserved.2018-11-18 21:08:16.212 [main] INFO VMInfo - VMInfo# operatingSystem class =>sun.management.OperatingSystemImpl2018-11-18 21:08:16.232 [main] INFO Engine - the machine info =>osInfo: Oracle Corporation1.8 25.162-b12
jvmInfo: Mac OS X x86_6410.13.4cpu num:4totalPhysicalMemory:-0.00G
freePhysicalMemory:-0.00G
maxFileDescriptorCount:-1currentOpenFileDescriptorCount:-1GC Names [PS MarkSweep, PS Scavenge]
MEMORY_NAME| allocation_size |init_size
PS Eden Space| 256.00MB | 256.00MB
Code Cache| 240.00MB | 2.44MB
Compressed Class Space| 1,024.00MB | 0.00MB
PS Survivor Space| 42.50MB | 42.50MB
PS Old Gen| 683.00MB | 683.00MB
Metaspace| -0.00MB | 0.00MB2018-11-18 21:08:16.287 [main] INFO Engine -{"content":[
{"reader":{"name":"txtfilereader","parameter":{"column":[
{"index":0,"type":"long"},
{"index":1,"type":"long"},
{"index":2,"type":"long"},
{"index":3,"type":"long"},
{"index":4,"type":"DOUBLE"},
{"index":5,"type":"DOUBLE"},
{"index":6,"type":"STRING"},
{"index":7,"type":"STRING"},
{"index":8,"type":"STRING"},
{"index":9,"type":"BOOLEAN"},
{"index":10,"type":"date"},
{"index":11,"type":"date"}
],"encoding":"UTF-8","fieldDelimiter":"`","path":["/Users/FengZhen/Desktop/Hadoop/dataX/json/HDFS/data.txt"]
}
},"writer":{"name":"hdfswriter","parameter":{"column":[
{"name":"col1","type":"TINYINT"},
{"name":"col2","type":"SMALLINT"},
{"name":"col3","type":"INT"},
{"name":"col4","type":"BIGINT"},
{"name":"col5","type":"FLOAT"},
{"name":"col6","type":"DOUBLE"},
{"name":"col7","type":"STRING"},
{"name":"col8","type":"VARCHAR"},
{"name":"col9","type":"CHAR"},
{"name":"col10","type":"BOOLEAN"},
{"name":"col11","type":"date"},
{"name":"col12","type":"TIMESTAMP"}
],"compress":"NONE","defaultFS":"hdfs://192.168.1.121:8020","fieldDelimiter":"`","fileName":"hdfswriter","fileType":"orc","path":"/user/hive/warehouse/hdfswriter.db/orc_table","writeMode":"append"}
}
}
],"setting":{"speed":{"channel":2}
}
}2018-11-18 21:08:16.456 [main] WARN Engine - prioriy set to 0, because NumberFormatException, the value is: null
2018-11-18 21:08:16.460 [main] INFO PerfTrace - PerfTrace traceId=job_-1, isEnable=false, priority=0
2018-11-18 21:08:16.460 [main] INFO JobContainer -DataX jobContainer starts job.2018-11-18 21:08:16.464 [main] INFO JobContainer - Set jobId = 0Nov18, 2018 9:08:17 PM org.apache.hadoop.util.NativeCodeLoader 警告: Unable to load native-hadoop library for your platform... using builtin-java classes whereapplicable2018-11-18 21:08:18.679 [job-0] INFO JobContainer - jobContainer starts to doprepare ...2018-11-18 21:08:18.680 [job-0] INFO JobContainer - DataX Reader.Job [txtfilereader] doprepare work .2018-11-18 21:08:18.682 [job-0] INFO TxtFileReader$Job - add file [/Users/FengZhen/Desktop/Hadoop/dataX/json/HDFS/data.txt] asa candidate to be read.2018-11-18 21:08:18.682 [job-0] INFO TxtFileReader$Job - 您即将读取的文件数为: [1]2018-11-18 21:08:18.683 [job-0] INFO JobContainer - DataX Writer.Job [hdfswriter] doprepare work .2018-11-18 21:08:18.933 [job-0] INFO HdfsWriter$Job - 由于您配置了writeMode append, 写入前不做清理工作, [/user/hive/warehouse/hdfswriter.db/orc_table] 目录下写入相应文件名前缀 [hdfswriter] 的文件2018-11-18 21:08:18.934 [job-0] INFO JobContainer - jobContainer starts to dosplit ...2018-11-18 21:08:18.934 [job-0] INFO JobContainer - Job set Channel-Number to 2channels.2018-11-18 21:08:18.937 [job-0] INFO JobContainer - DataX Reader.Job [txtfilereader] splits to [1] tasks.2018-11-18 21:08:18.938 [job-0] INFO HdfsWriter$Job - begin dosplit...2018-11-18 21:08:18.995 [job-0] INFO HdfsWriter$Job - splited write file name:[hdfs://192.168.1.121:8020/user/hive/warehouse/hdfswriter.db/orc_table__015cbc4e_94e7_4693_a543_6290deb25115/hdfswriter__0c580bd3_2265_4be7_8def_e6e024066c68]
2018-11-18 21:08:18.995 [job-0] INFO HdfsWriter$Job - end dosplit.2018-11-18 21:08:18.995 [job-0] INFO JobContainer - DataX Writer.Job [hdfswriter] splits to [1] tasks.2018-11-18 21:08:19.026 [job-0] INFO JobContainer - jobContainer starts to doschedule ...2018-11-18 21:08:19.050 [job-0] INFO JobContainer - Scheduler starts [1] taskGroups.2018-11-18 21:08:19.064 [job-0] INFO JobContainer -Running by standalone Mode.2018-11-18 21:08:19.076 [taskGroup-0] INFO TaskGroupContainer - taskGroupId=[0] start [1] channels for [1] tasks.2018-11-18 21:08:19.112 [taskGroup-0] INFO Channel - Channel set byte_speed_limit to -1, No bps activated.2018-11-18 21:08:19.113 [taskGroup-0] INFO Channel - Channel set record_speed_limit to -1, No tps activated.2018-11-18 21:08:19.133 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] attemptCount[1] isstarted2018-11-18 21:08:19.133 [0-0-0-reader] INFO TxtFileReader$Task - reading file : [/Users/FengZhen/Desktop/Hadoop/dataX/json/HDFS/data.txt]2018-11-18 21:08:19.199 [0-0-0-writer] INFO HdfsWriter$Task - begin dowrite...2018-11-18 21:08:19.200 [0-0-0-writer] INFO HdfsWriter$Task - write to file : [hdfs://192.168.1.121:8020/user/hive/warehouse/hdfswriter.db/orc_table__015cbc4e_94e7_4693_a543_6290deb25115/hdfswriter__0c580bd3_2265_4be7_8def_e6e024066c68]
2018-11-18 21:08:19.342 [0-0-0-reader] INFO UnstructuredStorageReaderUtil - CsvReader使用默认值[{"captureRawRecord":true,"columnCount":0,"comment":"#","currentRecord":-1,"delimiter":"`","escapeMode":1,"headerCount":0,"rawRecord":"","recordDelimiter":"\u0000","safetySwitch":false,"skipEmptyRecords":true,"textQualifier":"\"","trimWhitespace":true,"useComments":false,"useTextQualifier":true,"values":[]}],csvReaderConfig值为[null]2018-11-18 21:08:19.355 [0-0-0-reader] ERROR StdoutPluginCollector -脏数据:
{"message":"类型转换错误, 无法将[10] 转换为[BOOLEAN]","record":[{"byteSize":1,"index":0,"rawData":1,"type":"LONG"},{"byteSize":1,"index":1,"rawData":2,"type":"LONG"},{"byteSize":1,"index":2,"rawData":3,"type":"LONG"},{"byteSize":1,"index":3,"rawData":4,"type":"LONG"},{"byteSize":1,"index":4,"rawData":"5","type":"DOUBLE"},{"byteSize":1,"index":5,"rawData":"6","type":"DOUBLE"},{"byteSize":1,"index":6,"rawData":"7","type":"STRING"},{"byteSize":1,"index":7,"rawData":"8","type":"STRING"},{"byteSize":1,"index":8,"rawData":"9","type":"STRING"}],"type":"reader"}2018-11-18 21:08:19.358 [0-0-0-reader] ERROR StdoutPluginCollector -脏数据:
{"message":"类型转换错误, 无法将[22] 转换为[BOOLEAN]","record":[{"byteSize":2,"index":0,"rawData":13,"type":"LONG"},{"byteSize":2,"index":1,"rawData":14,"type":"LONG"},{"byteSize":2,"index":2,"rawData":15,"type":"LONG"},{"byteSize":2,"index":3,"rawData":16,"type":"LONG"},{"byteSize":2,"index":4,"rawData":"17","type":"DOUBLE"},{"byteSize":2,"index":5,"rawData":"18","type":"DOUBLE"},{"byteSize":2,"index":6,"rawData":"19","type":"STRING"},{"byteSize":2,"index":7,"rawData":"20","type":"STRING"},{"byteSize":2,"index":8,"rawData":"21","type":"STRING"}],"type":"reader"}2018-11-18 21:08:22.031 [0-0-0-writer] INFO HdfsWriter$Task - end dowrite2018-11-18 21:08:22.115 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] is successed, used[2987]ms2018-11-18 21:08:22.116 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] completed it‘s tasks.
2018-11-18 21:08:29.150 [job-0] INFO StandAloneJobContainerCommunicator - Total 2 records, 27 bytes | Speed 2B/s, 0 records/s | Error 2 records, 27 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 100.00%
2018-11-18 21:08:29.151 [job-0] INFO AbstractScheduler -Scheduler accomplished all tasks.2018-11-18 21:08:29.152 [job-0] INFO JobContainer - DataX Writer.Job [hdfswriter] dopost work.2018-11-18 21:08:29.152 [job-0] INFO HdfsWriter$Job - start rename file [hdfs://192.168.1.121:8020/user/hive/warehouse/hdfswriter.db/orc_table__015cbc4e_94e7_4693_a543_6290deb25115/hdfswriter__0c580bd3_2265_4be7_8def_e6e024066c68] to file [hdfs://192.168.1.121:8020/user/hive/warehouse/hdfswriter.db/orc_table/hdfswriter__0c580bd3_2265_4be7_8def_e6e024066c68].
2018-11-18 21:08:29.184 [job-0] INFO HdfsWriter$Job - finish rename file [hdfs://192.168.1.121:8020/user/hive/warehouse/hdfswriter.db/orc_table__015cbc4e_94e7_4693_a543_6290deb25115/hdfswriter__0c580bd3_2265_4be7_8def_e6e024066c68] to file [hdfs://192.168.1.121:8020/user/hive/warehouse/hdfswriter.db/orc_table/hdfswriter__0c580bd3_2265_4be7_8def_e6e024066c68].
2018-11-18 21:08:29.184 [job-0] INFO HdfsWriter$Job - start delete tmp dir [hdfs://192.168.1.121:8020/user/hive/warehouse/hdfswriter.db/orc_table__015cbc4e_94e7_4693_a543_6290deb25115] .
2018-11-18 21:08:29.217 [job-0] INFO HdfsWriter$Job - finish delete tmp dir [hdfs://192.168.1.121:8020/user/hive/warehouse/hdfswriter.db/orc_table__015cbc4e_94e7_4693_a543_6290deb25115] .
2018-11-18 21:08:29.218 [job-0] INFO JobContainer - DataX Reader.Job [txtfilereader] dopost work.2018-11-18 21:08:29.218 [job-0] INFO JobContainer - DataX jobId [0] completed successfully.2018-11-18 21:08:29.219 [job-0] INFO HookInvoker - No hook invoked, because base dir not exists or is a file: /Users/FengZhen/Desktop/Hadoop/dataX/datax/hook2018-11-18 21:08:29.330 [job-0] INFO JobContainer -[total cpu info]=>averageCpu| maxDeltaCpu |minDeltaCpu-1.00% | -1.00% | -1.00%[total gc info]=>NAME| totalGCCount | maxDeltaGCCount | minDeltaGCCount | totalGCTime | maxDeltaGCTime |minDeltaGCTime
PS MarkSweep| 1 | 1 | 1 | 0.042s | 0.042s | 0.042s
PS Scavenge| 1 | 1 | 1 | 0.020s | 0.020s | 0.020s2018-11-18 21:08:29.330 [job-0] INFO JobContainer - PerfTrace not enable!
2018-11-18 21:08:29.330 [job-0] INFO StandAloneJobContainerCommunicator - Total 2 records, 27 bytes | Speed 0B/s, 0 records/s | Error 2 records, 27 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 100.00%
2018-11-18 21:08:29.331 [job-0] INFO JobContainer -任务启动时刻 :2018-11-18 21:08:16任务结束时刻 :2018-11-18 21:08:29任务总计耗时 : 12s
任务平均流量 : 0B/s
记录写入速度 : 0rec/s
读出记录总数 :2读写失败总数 :2
因为有类型不匹配的数据,将格式修改正确后重新执行
FengZhendeMacBook-Pro:bin FengZhen$ ./datax.py /Users/FengZhen/Desktop/Hadoop/dataX/json/HDFS/2.writer_orc.json
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !Copyright (C)2010-2017, Alibaba Group. All Rights Reserved.2018-11-18 21:16:18.386 [main] INFO VMInfo - VMInfo# operatingSystem class =>sun.management.OperatingSystemImpl2018-11-18 21:16:18.401 [main] INFO Engine - the machine info =>osInfo: Oracle Corporation1.8 25.162-b12
jvmInfo: Mac OS X x86_6410.13.4cpu num:4totalPhysicalMemory:-0.00G
freePhysicalMemory:-0.00G
maxFileDescriptorCount:-1currentOpenFileDescriptorCount:-1GC Names [PS MarkSweep, PS Scavenge]
MEMORY_NAME| allocation_size |init_size
PS Eden Space| 256.00MB | 256.00MB
Code Cache| 240.00MB | 2.44MB
Compressed Class Space| 1,024.00MB | 0.00MB
PS Survivor Space| 42.50MB | 42.50MB
PS Old Gen| 683.00MB | 683.00MB
Metaspace| -0.00MB | 0.00MB2018-11-18 21:16:18.452 [main] INFO Engine -{"content":[
{"reader":{"name":"txtfilereader","parameter":{"column":[
{"index":0,"type":"long"},
{"index":1,"type":"long"},
{"index":2,"type":"long"},
{"index":3,"type":"long"},
{"index":4,"type":"DOUBLE"},
{"index":5,"type":"DOUBLE"},
{"index":6,"type":"STRING"},
{"index":7,"type":"STRING"},
{"index":8,"type":"STRING"},
{"index":9,"type":"BOOLEAN"},
{"index":10,"type":"date"},
{"index":11,"type":"date"}
],"encoding":"UTF-8","fieldDelimiter":"`","path":["/Users/FengZhen/Desktop/Hadoop/dataX/json/HDFS/data.txt"]
}
},"writer":{"name":"hdfswriter","parameter":{"column":[
{"name":"col1","type":"TINYINT"},
{"name":"col2","type":"SMALLINT"},
{"name":"col3","type":"INT"},
{"name":"col4","type":"BIGINT"},
{"name":"col5","type":"FLOAT"},
{"name":"col6","type":"DOUBLE"},
{"name":"col7","type":"STRING"},
{"name":"col8","type":"VARCHAR"},
{"name":"col9","type":"CHAR"},
{"name":"col10","type":"BOOLEAN"},
{"name":"col11","type":"date"},
{"name":"col12","type":"TIMESTAMP"}
],"compress":"NONE","defaultFS":"hdfs://192.168.1.121:8020","fieldDelimiter":"`","fileName":"hdfswriter","fileType":"orc","path":"/user/hive/warehouse/hdfswriter.db/orc_table","writeMode":"append"}
}
}
],"setting":{"speed":{"channel":2}
}
}2018-11-18 21:16:18.521 [main] WARN Engine - prioriy set to 0, because NumberFormatException, the value is: null
2018-11-18 21:16:18.540 [main] INFO PerfTrace - PerfTrace traceId=job_-1, isEnable=false, priority=0
2018-11-18 21:16:18.541 [main] INFO JobContainer -DataX jobContainer starts job.2018-11-18 21:16:18.577 [main] INFO JobContainer - Set jobId = 0Nov18, 2018 9:16:19 PM org.apache.hadoop.util.NativeCodeLoader 警告: Unable to load native-hadoop library for your platform... using builtin-java classes whereapplicable2018-11-18 21:16:20.377 [job-0] INFO JobContainer - jobContainer starts to doprepare ...2018-11-18 21:16:20.378 [job-0] INFO JobContainer - DataX Reader.Job [txtfilereader] doprepare work .2018-11-18 21:16:20.379 [job-0] INFO TxtFileReader$Job - add file [/Users/FengZhen/Desktop/Hadoop/dataX/json/HDFS/data.txt] asa candidate to be read.2018-11-18 21:16:20.379 [job-0] INFO TxtFileReader$Job - 您即将读取的文件数为: [1]2018-11-18 21:16:20.380 [job-0] INFO JobContainer - DataX Writer.Job [hdfswriter] doprepare work .2018-11-18 21:16:21.428 [job-0] INFO HdfsWriter$Job - 由于您配置了writeMode append, 写入前不做清理工作, [/user/hive/warehouse/hdfswriter.db/orc_table] 目录下写入相应文件名前缀 [hdfswriter] 的文件2018-11-18 21:16:21.428 [job-0] INFO JobContainer - jobContainer starts to dosplit ...2018-11-18 21:16:21.429 [job-0] INFO JobContainer - Job set Channel-Number to 2channels.2018-11-18 21:16:21.430 [job-0] INFO JobContainer - DataX Reader.Job [txtfilereader] splits to [1] tasks.2018-11-18 21:16:21.430 [job-0] INFO HdfsWriter$Job - begin dosplit...2018-11-18 21:16:21.454 [job-0] INFO HdfsWriter$Job - splited write file name:[hdfs://192.168.1.121:8020/user/hive/warehouse/hdfswriter.db/orc_table__c122e384_c22a_467a_b392_4e1042b2d033/hdfswriter__f55b962f_b945_401a_88fa_c1970d374dd1]
2018-11-18 21:16:21.454 [job-0] INFO HdfsWriter$Job - end dosplit.2018-11-18 21:16:21.454 [job-0] INFO JobContainer - DataX Writer.Job [hdfswriter] splits to [1] tasks.2018-11-18 21:16:21.488 [job-0] INFO JobContainer - jobContainer starts to doschedule ...2018-11-18 21:16:21.497 [job-0] INFO JobContainer - Scheduler starts [1] taskGroups.2018-11-18 21:16:21.505 [job-0] INFO JobContainer -Running by standalone Mode.2018-11-18 21:16:21.519 [taskGroup-0] INFO TaskGroupContainer - taskGroupId=[0] start [1] channels for [1] tasks.2018-11-18 21:16:21.533 [taskGroup-0] INFO Channel - Channel set byte_speed_limit to -1, No bps activated.2018-11-18 21:16:21.534 [taskGroup-0] INFO Channel - Channel set record_speed_limit to -1, No tps activated.2018-11-18 21:16:21.554 [0-0-0-reader] INFO TxtFileReader$Task - reading file : [/Users/FengZhen/Desktop/Hadoop/dataX/json/HDFS/data.txt]2018-11-18 21:16:21.559 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] attemptCount[1] isstarted2018-11-18 21:16:21.621 [0-0-0-writer] INFO HdfsWriter$Task - begin dowrite...2018-11-18 21:16:21.622 [0-0-0-writer] INFO HdfsWriter$Task - write to file : [hdfs://192.168.1.121:8020/user/hive/warehouse/hdfswriter.db/orc_table__c122e384_c22a_467a_b392_4e1042b2d033/hdfswriter__f55b962f_b945_401a_88fa_c1970d374dd1]
2018-11-18 21:16:21.747 [0-0-0-reader] INFO UnstructuredStorageReaderUtil - CsvReader使用默认值[{"captureRawRecord":true,"columnCount":0,"comment":"#","currentRecord":-1,"delimiter":"`","escapeMode":1,"headerCount":0,"rawRecord":"","recordDelimiter":"\u0000","safetySwitch":false,"skipEmptyRecords":true,"textQualifier":"\"","trimWhitespace":true,"useComments":false,"useTextQualifier":true,"values":[]}],csvReaderConfig值为[null]2018-11-18 21:16:22.444 [0-0-0-writer] INFO HdfsWriter$Task - end dowrite2018-11-18 21:16:22.476 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] is successed, used[926]ms2018-11-18 21:16:22.477 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] completed it‘s tasks.
2018-11-18 21:16:31.572 [job-0] INFO StandAloneJobContainerCommunicator - Total 2 records, 61 bytes | Speed 6B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 100.00%
2018-11-18 21:16:31.573 [job-0] INFO AbstractScheduler -Scheduler accomplished all tasks.2018-11-18 21:16:31.573 [job-0] INFO JobContainer - DataX Writer.Job [hdfswriter] dopost work.2018-11-18 21:16:31.576 [job-0] INFO HdfsWriter$Job - start rename file [hdfs://192.168.1.121:8020/user/hive/warehouse/hdfswriter.db/orc_table__c122e384_c22a_467a_b392_4e1042b2d033/hdfswriter__f55b962f_b945_401a_88fa_c1970d374dd1] to file [hdfs://192.168.1.121:8020/user/hive/warehouse/hdfswriter.db/orc_table/hdfswriter__f55b962f_b945_401a_88fa_c1970d374dd1].
2018-11-18 21:16:31.626 [job-0] INFO HdfsWriter$Job - finish rename file [hdfs://192.168.1.121:8020/user/hive/warehouse/hdfswriter.db/orc_table__c122e384_c22a_467a_b392_4e1042b2d033/hdfswriter__f55b962f_b945_401a_88fa_c1970d374dd1] to file [hdfs://192.168.1.121:8020/user/hive/warehouse/hdfswriter.db/orc_table/hdfswriter__f55b962f_b945_401a_88fa_c1970d374dd1].
2018-11-18 21:16:31.627 [job-0] INFO HdfsWriter$Job - start delete tmp dir [hdfs://192.168.1.121:8020/user/hive/warehouse/hdfswriter.db/orc_table__c122e384_c22a_467a_b392_4e1042b2d033] .
2018-11-18 21:16:31.648 [job-0] INFO HdfsWriter$Job - finish delete tmp dir [hdfs://192.168.1.121:8020/user/hive/warehouse/hdfswriter.db/orc_table__c122e384_c22a_467a_b392_4e1042b2d033] .
2018-11-18 21:16:31.649 [job-0] INFO JobContainer - DataX Reader.Job [txtfilereader] dopost work.2018-11-18 21:16:31.649 [job-0] INFO JobContainer - DataX jobId [0] completed successfully.2018-11-18 21:16:31.653 [job-0] INFO HookInvoker - No hook invoked, because base dir not exists or is a file: /Users/FengZhen/Desktop/Hadoop/dataX/datax/hook2018-11-18 21:16:31.766 [job-0] INFO JobContainer -[total cpu info]=>averageCpu| maxDeltaCpu |minDeltaCpu-1.00% | -1.00% | -1.00%[total gc info]=>NAME| totalGCCount | maxDeltaGCCount | minDeltaGCCount | totalGCTime | maxDeltaGCTime |minDeltaGCTime
PS MarkSweep| 1 | 1 | 1 | 0.051s | 0.051s | 0.051s
PS Scavenge| 1 | 1 | 1 | 0.023s | 0.023s | 0.023s2018-11-18 21:16:31.766 [job-0] INFO JobContainer - PerfTrace not enable!
2018-11-18 21:16:31.766 [job-0] INFO StandAloneJobContainerCommunicator - Total 2 records, 61 bytes | Speed 6B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 100.00%
2018-11-18 21:16:31.773 [job-0] INFO JobContainer -任务启动时刻 :2018-11-18 21:16:18任务结束时刻 :2018-11-18 21:16:31任务总计耗时 : 13s
任务平均流量 : 6B/s
记录写入速度 : 0rec/s
读出记录总数 :2读写失败总数 :0
datax参数设置_DataX-操作HDFS相关推荐
- datax参数设置_DataX Web数据增量同步配置说明
一.根据日期进行增量数据抽取 1.页面任务配置 打开菜单任务管理页面,选择添加任务 按下图中5个步骤进行配置 1.任务类型选DataX任务 2.辅助参数选择时间自增 3.增量开始时间选择,即sql中查 ...
- datax参数设置_DataX使用
解决问题? DataX简介? DataX使用? DataX配置文件? 1. DataX简介? DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL.Oracle.Sql ...
- HXU1861系列超高频RFID读写器|读卡器|一体机的串口网口及相关参数设置操作说明与指南
超高频读写器参数设置界面操作 1.打开串口 在打开端口之前,请将读写器与串口.天线正确连接,再接通电源.选择 (1)自动打开可用端口: 读写器地址等于FF时,为广播方式,与该串口连接的读写器均会响应. ...
- Linux中高斯分布的参数设置,华为openGauss 配置操作系统参数
openGauss要求各主机上的操作系统参数设置成一定的值,以满足系统运行的性能要求等. 这些参数有些会在openGauss安装环境准备阶段完成设置,且这些参数将直接影响openGauss的运行状态, ...
- 三菱mr服务器如何显示脉冲数,MR-JE-200A参数设置三菱MR-JE-200A操作手册(故障排除篇) - 广州正凌...
类型:MR-C型. 符号10A适用电机型号:HC-PQ23. 电源电压:单相AC220V. 驱动器方面:伺服驱动器在发展了变频技术的前提下, 在驱动器内部的电流环, 速度环和位置环(变频器没有该环)都 ...
- 会声会影2020 2021 2022 基础操作和参数设置图文教程
我们使用会声会影软件要想提高打开速度不仅要进行禁网和入站规则(新建规则)的设置,第一次打开软件后的很多设置和操作也至关重要,会声会影软件的确越来越臃肿,不断添加的插件更是不堪重负,所以建议各位量力而行 ...
- Midjourney指令操作、promt框架、参数设置教程
引言:基于Chatgpt的应用如雨后春笋,这波浪潮正当时.最近在摸索图片生成有价值的应用场景,使用过程中整理了一些指令秘籍,一同分享出来. 1.原理 Midjourney的人工智能绘画技术基于GPT- ...
- 系统常用参数的推荐设置(操作同样适合于其他AD版本,操作方法一致)
大家好,我是刘士铭,一名初级的电子爱好者,今天继续分享下AD软件的一些设置. 操作页面如下: 打开软件默认重启最近打开的工程(操作同样适合于其他AD版本,操作方法一致) 操作步骤:Setup syst ...
- 2021年大数据Hadoop(二十九):关于YARN常用参数设置
全网最详细的Hadoop文章系列,强烈建议收藏加关注! 后面更新文章都会列出历史文章目录,帮助大家回顾知识重点. 目录 本系列历史文章 前言 关于yarn常用参数设置 设置container分配最小内 ...
- DATAX工具同步数据从hdfs到drds性能优化
问题描述 在客户现场运维过程中,使用datax同步数据从hdfs到drds速度极其缓慢,因此希望进行datax的json文件进行优化,提升速度,同步缓慢及报错如下: 问题分析 对于datax的使用问题 ...
最新文章
- Spring基础专题——引言
- 用户界面设计的技巧与技术 (作者Scott W.Ambler)
- linux驱动模块开机自动加载,以及应用程序开机自启动
- 岩板铺地好吗_别人都说岩板好,我笑他人乐太早
- 草稿pyqt控件简单了解
- MySQl Search JSON Values
- String及其常用API
- 3月21日阿里云北京峰会的注册二维码
- C语言 指针访问数组,C语言通过指针引用数组
- hdoj2602 0/1背包 动态规划 模版题( Java版)
- 舒老师的hu测(日常吐槽)
- Python 学习笔记 - 函数
- RecyclerView系列:GridLayoutManager的构造函数中的orientation理解
- CleanMyMac4.12最新版mac系统内存空间清理教程
- 软件测试真的是吃青春饭的吗?有哪些建议可以给刚入职的测试员?(全是干货)
- 软件项目如何进行任务分配,减少冲突?
- 建模大佬都不会外传的角色手办制作流程
- MES系统多少钱?企业需要什么样的MES系统?
- PostgreSQL数据库锁机制——SpinLock
- Squid ----反向代理模式