文本数据分析:文本挖掘还是自然语言处理?
数据分析师Seth Grimes曾指出“80%的商业信息来自非结构化数据,主要是文本数据”,这一表述可能夸大了文本数据在商业数据中的占比,但是文本数据的蕴含的信息价值毋庸置疑。KDnuggets的编辑、机器学习研究者和数据科学家Matthew Mayo就在网站上写了一个有关文本数据分析的文章系列。本文是该系列的第一篇,主要讲述了文本数据分析的大致步骤和框架。以下是论智对原文的编译。
虽然NLP和文本挖掘不是一回事儿,但它们仍是紧密相关的:它们处理同样的原始数据类型、在使用时还有很多交叉。下面我们就来描述一下这些任务的处理步骤。
如今的文本数据量非常之大,许多都是从日常生活中产生的,其中既有结构化的,也有半结构化甚至混乱的数据。我们对此能做什么?事实上,能做的有很多,这取决于你的目标是什么。
文本挖掘还是自然语言处理?
自然语言处理(NLP)关注的是人类的自然语言与计算机设备之间的相互关系。NLP是计算机语言学的重要方面之一,它同样也属于计算机科学和人工智能领域。而文本挖掘和NLP的存在领域类似,它关注的是识别文本数据中有趣并且重要的模式。
但是,这二者仍有不同。首先,这两个概念并没有明确的界定(就像“数据挖掘”和“数据科学”一样),并且在不同程度上二者相互交叉,具体要看与你交谈的对象是谁。我认为通过洞见级别来区分是最容易的。如果原始文本是数据,那么文本挖掘就是信息,NLP就是知识,也就是语法和语义的关系。下面的金字塔表示了这种关系:
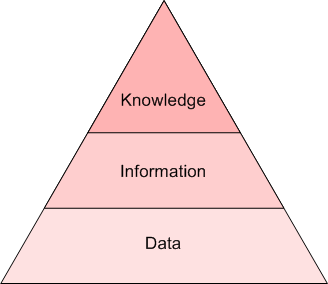
另一种区分这两个概念的方法是用下方的韦恩图区分,其中也涉及其他相关概念,从而能更好地表示它们之间重叠的关系。
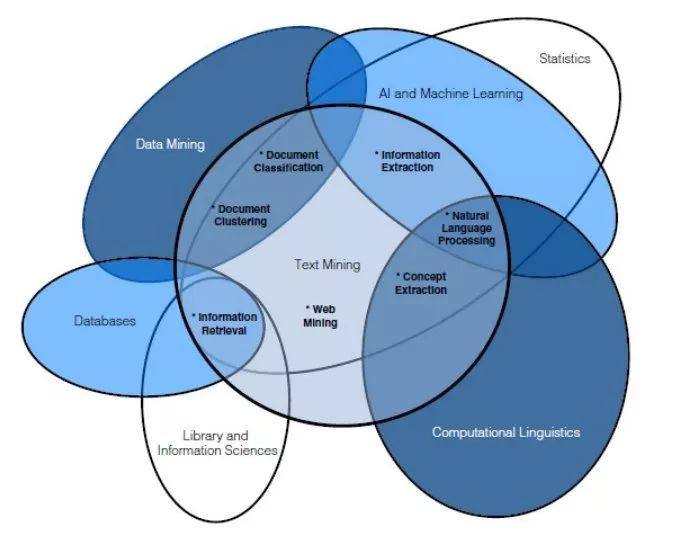
我们的目的并不是二者绝对或相对的定义,重要的是要认识到,这两种任务下对数据的预处理是相同的。
努力消除歧义是文本预处理很重要的一个方面,我们希望保留原本的含义,同时消除噪音。为此,我们需要了解:
关于语言的知识
关于世界的知识
结合知识来源的方法
除此之外,下图所示的六个因素也加大了文本数据处理的难度,包括非标准的语言表述、断句问题、习惯用语、新兴词汇、常识以及复杂的名词等等。

文本数据科学任务框架
我们能否为文本数据的处理制作一个高效并且通用的框架呢?我们发现,处理文本和处理其他非文本的任务很相似,可以查看我之前写的KDD Process作为参考。
以下就是处理文本任务的几大主要步骤:
1.数据收集
获取或创建语料库,来源可以是邮箱、英文维基百科文章或者公司财报,甚至是莎士比亚的作品等等任何资料。
2.数据预处理
在原始文本语料上进行预处理,为文本挖掘或NLP任务做准备
数据预处理分为好几步,其中有些步骤可能适用于给定的任务,也可能不适用。但通常都是标记化、归一化和替代的其中一种。
3.数据挖掘和可视化
无论我们的数据类型是什么,挖掘和可视化是探寻规律的重要步骤
常见任务可能包括可视化字数和分布,生成wordclouds并进行距离测量
4.模型搭建
这是文本挖掘和NLP任务进行的主要部分,包括训练和测试
在适当的时候还会进行特征选择和工程设计
语言模型:有限状态机、马尔可夫模型、词义的向量空间建模
机器学习分类器:朴素贝叶斯、逻辑回归、决策树、支持向量机、神经网络
序列模型:隐藏马尔可夫模型、循环神经网络(RNN)、长短期记忆神经网络(LSTMs)
5.模型评估
模型是否达到预期?
度量标准将随文本挖掘或NLP任务的类型而变化
即使不做聊天机器人或生成模型,某种形式的评估也是必要的
文本数据分析:文本挖掘还是自然语言处理?相关推荐
- 自然语言处理 文本预处理(下)(张量表示、文本数据分析、文本特征处理等)
文章目录 一.文本张量表示方法 1. 什么是文本张量表示 2. 文本张量表示的作用: 3. 文本张量表示的方法: 4. one-hot词向量 4.1 什么是one-hot词向量表示 4.2 one-h ...
- python爬虫与文本数据分析 系列课
在过去的两年间,Python一路高歌猛进,成功窜上"最火编程语言"的宝座.惊奇的是使用Python最多的人群其实不是程序员,而是数据科学家,尤其是社会科学家,涵盖的学科有经济学.管 ...
- 文本数据分析:删除停用词
停用词是指在信息检索中,为节省存储空间和提高搜索效率,在处理自然语言文本之前或之后会自动过滤掉某些没有具体意义的字或词,这些字或词即被称为停用词,比如英文单词"I""th ...
- Python 数据分析第六期--文本数据分析
Python 数据分析第六期–文本数据分析 1. Python 文本分析工具 NLTK NLTK (Natural Language Toolkit) NLP 领域最常用的一个 Python 库 , ...
- Python对某视频弹幕进行爬取,完成文本数据分析
本文主要使用jieba.requests.wordcloud.matplotlib.imageio等包完成数据爬取.文本数据分析.可视化. 弹幕数据: 目录 1.爬取弹幕数据.分词并统计高频词: 爬取 ...
- 2.文本预处理(分词,命名实体识别和词性标注,one-hot,word2vec,word embedding,文本数据分析,文本特征处理,文本数据增强)
文章目录 1.1 认识文本预处理 文本预处理及其作用 文本预处理中包含的主要环节 文本处理的基本方法 文本张量表示方法 文本语料的数据分析 文本特征处理 数据增强方法 重要说明 1.2 文本处理的基本 ...
- python网络爬虫实训报告-Python网络爬虫与文本数据分析
原标题:Python网络爬虫与文本数据分析 在过去的两年间,Python一路高歌猛进,成功窜上"最火编程语言"的宝座.惊奇的是使用Python最多的人群其实不是程序员,而是数据科学 ...
- R语言机器学习与大数据可视化暨Python文本挖掘与自然语言处理核心技术研修
中国通信工业协会通信和信息技术创新人才培养工程项目办公室 通人办[2017] 第45号 "R语言机器学习与大数据可视化"暨"Python文本挖掘与自然语言处理" ...
- “R语言机器学习与大数据可视化”暨“Python文本挖掘与自然语言处理”核心技术高级研修班的通知
中国通信工业协会通信和信息技术创新人才培养工程项目办公室 通人办[2017] 第45号 "R语言机器学习与大数据可视化"暨"Python文本挖掘与自然语言处理" ...
最新文章
- 从刚入职阿里的学弟那里薅来的面试题,速速领取~~~
- 智能车竞赛相关资料获取
- 把java 工程转为 maven 工程
- flowable 启动流程到完成所有任务之间的数据库变化
- php 打印 trace,php xdebug trace 调试的问题
- java怎么拦截数据库查询结果_关于mybatis拦截器,有谁知道怎么对结果集进行拦截,将指定字段查询结果进行格式化...
- 分享20佳移动应用程序开发框架
- 串口与定时器的重要关系_单片机串口必备基础知识
- 字典生成_数据字典文档自成工具,一键生成,效率倍增
- stm32的命名及选型介绍
- ubuntu java ide,在Ubuntu 18.04系统中下载与安装Eclipse IDE的方法
- gmail邮箱服务器被禁,Gmail邮箱失联:谷歌回应服务器没问题
- row_number()的使用
- elasticsearch 出现yellow 分片有unassigned现象原因
- [TODO]高维空间求近似最近邻
- Python 编程案例:谁没交论文?输出并生成电子表格
- python画平行坐标图_[宜配屋]听图阁
- 【I2C】I2C QA
- Androi移动开发基础
- 【车辆计数】基于matlab光流法行驶车辆检测计数【含Matlab源码 627期】
热门文章
- 国企,私企与外企利弊通观--关键时刻给应届毕业生及时点拨
- android studio黄油刀依赖,【Android】AndroidStudio 依赖 ButterKnife 出现的空指针异常
- ArcGIS提取栅格数据中的指定部分(可以是矢量数据也可时栅格数据)
- Photoshop学习(二):换色
- Hash破解神器-hashcat详细使用
- 代码提交到GitHub时出现的反复报错
- sudo apt update时 E: 仓库 “http://mirrors.ustc.edu.cn/ros/ubuntu jammy Release” 没有 Release
- eclipse鼠标变成十字架
- 携手合作伙伴,傲腾技术加速释放数据中心潜能
- 电容基础知识 之 钽电解电容