从数据仓库系统对比看Hive发展前景
虽然MapReduce(Hadoop)的应用非常广泛,但这类框架暴露出来的编程接口仍然比较低级,编写复杂处理程序或Ad-hoc查询仍然 十分耗时,并且代码很难复用。目前,Google、Facebook和微软等公司都在底层分布式计算框架之上又提供更高层次的编程模型,将开发者不关心的 细节封装起来,提供了更简洁的编程接口。
目前应用最广泛的当属Facebook开源贡献的Hive。Hive是一个基于Hadoop的数据仓库平台,通过Hive,可以方便地进行数据 提取转化加载(ETL)的工作。Hive定义了一个类似于SQL的查询语言HQL,能够将用户编写的SQL转化为相应的MapReduce程序。当然,用 户也可以自定义Mapper和Reducer来完成复杂的分析工作。从2010年下半年开始,Hive成为Apache顶级项目。
基于MapReduce的Hive具有良好的扩展性和容错性。不过由于MapReduce缺乏结构化数据分析中有价值的特性,以及Hive缺乏 对执行计划的充分优化,导致Hive在很多场景下比并行数据仓库慢(在几十台机器的小规模下可能相差更大),Hive的架构如图1所示。
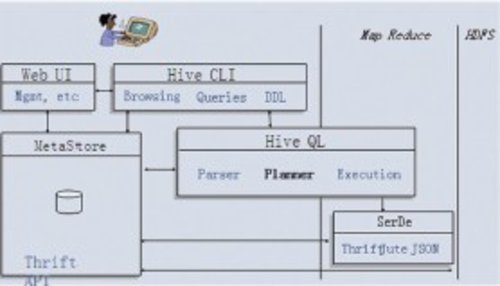
|
强大的数据仓库和数据分析平台至少需要具备以下几点特性。
·灵活的存储引擎
·高效的执行引擎
·良好的可扩展性
·强大的容错机制
·多样化的可视化
本文将简要阐述Hive是否完全具备了以上几点,以及与传统的并行数据仓库对比优劣如何。
存储引擎
Hive没有自己专门的数据存储格式,也没有为数据建立索引,用户可以非常自由地组织Hive中的表,只要在创建表时告诉Hive数据中的列分 隔符和行分隔符,Hive就可以解析数据。Hive的元数据存储在RDBMS中,所有数据都基于HDFS存储。Hive包含Table、External Table、Partition和Bucket等数据模型。
并行数据仓库需要先把数据装载到数据库中,按特定的格式存储,然后才能执行查询。每天需要花费几个小时来将数据导入并行数据库中,而且随着数据量的增长和新的数据源加入,导入时间会越来越长。导入时大量的写I/O与用户查询的读I/O产生竞争,会导致查询的性能很差。
Hive执行查询前无需导入数据,执行计划直接执行。Hive支持默认的多种文件格式,同时也可以通过实现MapReduce的 InputFormat或OutputFormat类,由用户定制格式。因为公司的数据种类很多,存储于不同的数据源系统,可能是MySQL、HDFS或 者Hypertable等,很多时候Hive的分析过程会用到各种数据源的数据。当然使用多个存储数据源,除了功能上要能够支持导入/导出之外,如何根据 各种存储源的能力和执行流获得最优执行计划也是件麻烦事儿。
执行引擎
并行数据仓库使用优化器。在生成执行计划时,利用元数据信息估算执行流上各个算子要处理的数据量和处理开销,进而选取最优的执行计划。并行数据 仓库实现了各种执行算子(Sort、GroupBy、Union和Filter等),它的执行优化器可以灵活地选择这多个算子的不同实现。此外,并行数据 仓库还拥有完备的索引机制,包括磁盘布局、缓存管理和I/O管理等多个层面的优化,这些都对查询性能至关重要。而这恰恰是Hive的不足之处。
Hive的编译器负责编译源代码并生成最终的执行计划,包括语法分析、语义分析、目标代码生成,所做的优化并不多。Hive基于 MapReduce,Hive的Sort和GroupBy都依赖MapReduce。而MapReduce相当于固化了执行算子,Map的 MergeSort必须执行,GroupBy算子也只有一种模式,Reduce的Merge-Sort也必须可选。另外Hive对Join算子的支持也较 少。另外,内存拷贝和数据预处理也会影响Hive的执行效率。当然,数据预处理可能会影响数据的导入效率,这需要根据应用特点进行权衡。
扩展性
并行数据仓库可以很好地扩展到几十或上百个节点的集群,并且达到接近线性的加速比。然而,今天的大数据分析需要的可扩展性远远超过这个数量,经 常需要达到数百甚至上千节点。目前,几乎没有哪个并行数据仓库运行在这么大规模的集群上,这涉及多个方面的原因。并行数据仓库假设底层集群节点完全同构; 并行数据仓库认为节点故障是很少出现的;并行数据仓库设计和实现基于的数据量并未达到PB级或者EB级。
与并行数据仓库不同的是,Hive更加关注水平扩展性。简单来讲,水平扩展性指系统可以通过简单的增加资源来支持更大的数据量和负载。
Hive处理的数据量是PB级的,而且每小时每天都在增长,这就使得水平扩展性成为一个非常重要的指标。Hadoop系统的水平扩展性是非常好的,而Hive基MapReduce框架,因此能够很自然地利用这点。
容错性
Hive有较好的容错性。Hive的执行计划在MapReduce框架上以作业的方式执行,每个作业的中间结果文件写到本地磁盘,最终输出文件 写到HDFS文件系统,利用HDFS的多副本机制来保证数据的可靠性,从而达到作业的容错性。如果在作业执行过程中某节点出现故障,那么Hive执行计划 基本不会受到影响。因此,基于Hive实现的数据仓库可以部署在由普通机器构建的分布式集群之上。
如果当某个执行计划在并行数据仓库上运行时,某节点发生故障,那么必须重新执行该计划。所以,当集群中的单点故障(可能是磁盘故障等)发生率较 高时,并行数据仓库的性能就会下降。在实际生产环境中,假设每个节点故障发生率是0.01%,那么1000个节点的集群中,单点故障发生率则为10%。这 个数字并不是耸人听闻的,处理海量数据的I/O密集型应用集群,平均每月的机器故障率达到1%~10%。当然这些机器可能是2~3万元的普通机型。
可视化
Hive的可视化界面基本属于字符终端,用户的技术水平一般比较高。面向不同的应用和用户,提供个性化的可视化展现,是Hive改进的一个重要 方向。个性化的可视化也可以理解为用户群体的分层,例如,图形界面方式提供初级用户,简单语言方式提供中级用户,复杂程序方式提供高级用户。
相关系统
除了Hive,近年来业界系统也诞生了其他各种类型的数据仓库,像Google的Tenzing、Dremel、微软的DryadLINQ、 Hadapt的HadoopDB等。Tenzing和DryadLINQ在框架分层上类似于Hive,Dremel除了语言层还实现了计算执行层,而 HadoopDB的目标是结合并行数据仓库和Hadoop的优点。
Tenzing的目标是支持Google对数据的Ad-hoc分析,当然之前的分析都是基于传统的关系数据库的。Tenzing在性能方面做了 大量优化,包括编译优化以及对MapReduce本身的增强等,这些都使得Tenzing的性能在很多方面接近甚至超过了并行数据仓库。另外,基于 LLVM的Tenzing执行引擎可以将单点执行性能提升10倍左右。
DryadLINQ的目标是对并行程序的开发进行抽象,使其和单机开发一样。与Hive不同的是,DryadLINQ并不是一种全新的语言,它 将特定语法直接集成到宿主语言(C#等高级语言),充分利用宿主语言的抽象和组合等编程语言机制。与Tenzing类似,DryadLINQ的扩展性和可 用性都依赖于底层的执行系统Dryad。
Dremel是Google用于满足交互式查询的系统,主要目标是执行一次性的、结果数据较小的聚合运算,不支持join、update等复杂 算子。与Tenzing和DryadLINQ不同,Dremel没有基于MapReduce或Dryad之类的底层计算框架,它实现了一个树状的执行层, 这个执行层管理节点的失效或竞争,包括优先级等,与MapReduce的实现机制相似。Dremel的底层存储系统是GFS,基本概念是按列分割数据,把 树形结构的数据按列分割。
HadoopDB希望整合并行数据仓库和Hadoop用于大数据分析,这既能保证高性能,又能提供可扩展和高可用能力。HadoopDB的基本 思想是在节点上运行并行数据库实例,MapReduce作为这些节点的执行层,尽可能地将执行计划放到并行数据库中完成,利用其已有的优化技术。当然,这 会牺牲一部分导入数据的性能,导入数据时会执行一部分表的布局和重组。
总结
作为互联网领域应用最为广泛的开源数据仓库,Hive是份免费的午餐,尤其它在扩展性和容错性方面有强大的优势,其前景被大家一致看好。不过对 比传统并行数据仓库,Hive在存储引擎支持、执行引擎高效化以及多样化接口等方面,还有很多工作要做。此外,业界的其他数据仓库,像新兴的 Tenzing、DryadLINQ、Dremel或HadoopDB等,都有Hive值得借鉴的地方,Hive原有的实现也还有很大的优化空间。
Hive的诞生带动了Hadoop开源栈系统的进一步发展,也使得很多公司能够从零开始快速搭建数据仓库系统,推动了整个产业链的进步。真心地希望Hive能够继续成长,不断演进,成为全面而强大的通用数据仓库标准。
作者杨栋,百度分布式高级研发工程师,从事Hypertable、Hadoop及流式计算的研究和开发。
本文选自《程序员》杂志2012年05期
转载于:https://www.cnblogs.com/end/archive/2012/08/17/2644249.html
从数据仓库系统对比看Hive发展前景相关推荐
- hive olap 数据仓库_数据仓库系统的实现和使用(含OLAP重点讲解)
前言 完整的数据仓库系统会涉及其他一些组件的开发,其中最主要的是ETL工程,在线分析处理工具(OLAP)和商务智能(BI)应用等. 本文将对这些方面做一个总体性的介绍(尤其是OLAP),旨在让读者对数 ...
- 大数据学习之路-Hive
Hive 1. Hive基本概念 1.1 什么是Hive 1.2 Hive的优缺点 1.2.1 优点 1.2.2 缺点 1.3 Hive架构原理 1.4 Hive和 数据库比较 1.4.1 查询语言 ...
- 大数据时代的技术hive:hive介绍
转自:http://www.cnblogs.com/sharpxiajun/archive/2013/06/02/3114180.html 我最近研究了hive的相关技术,有点心得,这里和大家分享下. ...
- hive遍历_从Hive中的stored as file_foramt看hive调优
一.行式数据库和列式数据库的对比 1.存储比较 行式数据库存储在hdfs上式按行进行存储的,一个block存储一或多行数据.而列式数据库在hdfs上则是按照列进行存储,一个block可能有一列或多列数 ...
- track_info分区表的创建并将ETL的数据加载到Hive表
文章目录 track_info分区表的创建 将ETL的数据加载到Hive表 track_info分区表的创建 分区表 因为日志是一天一个分区 create external table track_i ...
- hive hql文档_大数据学习路线分享hive的运行方式
大数据学习路线分享hive的运行方式,hive的属性设置: 1.在cli端设置 (只针对当前的session) 3.在java代码中设置 (当前连接) 2.在配置文件中设置 (所有session有效) ...
- 从云数据迁移服务看MySQL大表抽取模式
摘要:MySQL JDBC抽取到底应该采用什么样的方式,且听小编给你娓娓道来. 小编最近在云上的一个迁移项目中被MySQL抽取模式折磨的很惨.一开始爆内存被客户怼,再后来迁移效率低下再被怼.MySQL ...
- 90年代中国人一个月挣多少钱?一组数据带你看懂90年代消费情况
转载/挖数 最近几天,无意中在网上找到这本1999年的旧杂志 里边以杭州作为城市样本,调研了90年代杭州市的家庭收入及支出,读着读着我仿佛走进岁月时光机,穿越回23年前,以下摘取部分数据. 以1995 ...
- mysql大表数据抽取_从云数据迁移服务看MySQL大表抽取模式
摘要:MySQL JDBC抽取到底应该采用什么样的方式,且听小编给你娓娓道来. 小编最近在云上的一个迁移项目中被MySQL抽取模式折磨的很惨.一开始爆内存被客户怼,再后来迁移效率低下再被怼.MySQL ...
最新文章
- 还在重复造轮子?Java开发人员必知必会的20种常用类库和API
- python环境准备_python开发环境准备
- android html邮件 messagecompose,android email 转发附件丢失问题
- tomcat的安装及配置
- 企业为什么要做SEO,它的重要性有哪些?
- 如何创建隐藏用户帐号
- x-admin发异步把数据提交给php,role-add.html
- IAR8.4.2安装方法
- 在线计算机性能测试,电脑性能检测
- cadence SPB17.4 - 更换已有原理图的标题栏
- Docker创建私有仓库
- gee批量下载数据Google Drive下载大文件
- 如何查看MySQL版本号
- 2021河南科技大学计算机考研科目,2021河南科技大学考研参考书目
- 从X Fold+折叠屏手机再议vivo的用户导向创新思维
- 【ROS学习】- tf学习 - tf中重要函数解析 (陆续更新....)
- 〖经典怀念〗新白娘子传奇MV之青姐17部完整原版下载
- 文献合集 | 超扫描之fNIRS / fMRI / EEG / MEG
- PHP 帕斯卡(Pascal)三角形
- cookie获取和钓鱼攻击演示
热门文章
- java部署到服务器乱码_java web项目发布到linux服务器上运行出现乱码
- python处理csv文件将id相同的行合并到同一行并用符号将其隔开_Python探索性数据分析,这样才容易掌握...
- java 关于集合的笔试题_Java集合面试题(一)
- 5-14卷积神经网添加正则化
- linux lockf文件锁存在,进程停止,Linux文件锁学习-flock, lockf, fcntl
- 未能卸载该设备.启动计算机,未能卸载该设备。启动计算机时可能需要该设备...
- audio标签的controls属性_HTML5 新增标签和属性
- 基于参考点的非支配遗传算法-NSGA-III(一)
- Net平台下的B/S开发框架
- android checkbox 选中事件_挖穿Android第四十九天