hadoop rpc客户端初始化和调用过程详解
为什么80%的码农都做不了架构师?>>> 
本文主要记录hadoop rpc的客户端部分的初始化和调用的过程,下面的介绍中主要通过DFSClient来说明,为什么用DFSClient呢?DFSClient作为namenode的客户端,通过rpc来操作hdfs。限于篇幅,本文对下文引用到的类,做了较大的剪裁,只给出了关键的部分,如有疑问,可以一起交流。
DFSClient的初始化
DFSClient的初始化主要看其构造函数,其中rpc部分我们主要关注属性final ClientProtocol namenode,DFSClient的文件系统操作都是由他代理完成,构造函数中的关键代码如下:
public DFSClient(URI nameNodeUri, ClientProtocol rpcNamenode,Configuration conf, FileSystem.Statistics stats)throws IOException {proxyInfo = NameNodeProxies.createProxy(conf, nameNodeUri,ClientProtocol.class);this.dtService = proxyInfo.getDelegationTokenService();this.namenode = proxyInfo.getProxy();
}显然,DFSClient中的namenode是一个代理类。
接着NameNodeProxies类的createProxy方法,下面给出了NameNodeProxies中需要用到的一些方法:
public class NameNodeProxies {
public static <T> ProxyAndInfo<T> createProxy(Configuration conf,URI nameNodeUri, Class<T> xface) throws IOException {return createNonHAProxy(conf, NameNode.getAddress(nameNodeUri), xface,UserGroupInformation.getCurrentUser(), true);
}public static <T> ProxyAndInfo<T> createNonHAProxy(Configuration conf, InetSocketAddress nnAddr, Class<T> xface,UserGroupInformation ugi, boolean withRetries) throws IOException {proxy = (T) createNNProxyWithClientProtocol(nnAddr, conf, ugi,withRetries);return new ProxyAndInfo<T>(proxy, dtService);
}/**这部分是重点
*/
private static ClientProtocol createNNProxyWithClientProtocol(InetSocketAddress address, Configuration conf, UserGroupInformation ugi,boolean withRetries) throws IOException {ClientNamenodeProtocolPB proxy = RPC.getProtocolProxy(ClientNamenodeProtocolPB.class, version, address, ugi, conf,NetUtils.getDefaultSocketFactory(conf),org.apache.hadoop.ipc.Client.getTimeout(conf), defaultPolicy).getProxy();proxy = (ClientNamenodeProtocolPB) RetryProxy.create(ClientNamenodeProtocolPB.class,new DefaultFailoverProxyProvider<ClientNamenodeProtocolPB>(ClientNamenodeProtocolPB.class, proxy),methodNameToPolicyMap,defaultPolicy);return new ClientNamenodeProtocolTranslatorPB(proxy);
}
}该类中前面两个方法做跳转用,直接看createNNProxyWithClientProtocol方法,这里两行很关键的代码,proxy实例的初始化,这里先提示注意前一行中的getProxy() 对于这个方法是需要注意的,这样也保证了类型的一致。
这时候就不得不调出RPC这个类来看看他是怎么生成proxy的实例的了,看代码:ProtobufRpcEngineProtobufRpcEngineProtobufRpcEngineProtobufRpcEngine
public class RPC {
public static <T> ProtocolProxy<T> getProtocolProxy(Class<T> protocol,long clientVersion,InetSocketAddress addr,UserGroupInformation ticket,Configuration conf,SocketFactory factory,int rpcTimeout,RetryPolicy connectionRetryPolicy) throws IOException { if (UserGroupInformation.isSecurityEnabled()) {SaslRpcServer.init(conf);}return getProtocolEngine(protocol,conf).getProxy(protocol, clientVersion,addr, ticket, conf, factory, rpcTimeout, connectionRetryPolicy);}
}RPC中还是需要进一步的跳转,但是这里需要注意,getProtocolEngine这个方法,这里做一个说明,查看
RpcEngine的依赖,看图: 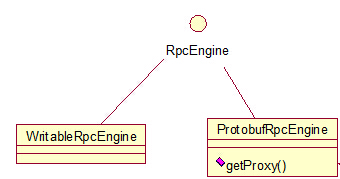 在我的2.4.1的hadoop的版本中,hadoop的序列化框架已经用了Protobuf,所以getProtocolEngine方法得到的是ProtobufRpcEngine类的一个实例,那好,我们进一步跟踪ProtobufRpcEngine类的getProxy方法,看代码:
在我的2.4.1的hadoop的版本中,hadoop的序列化框架已经用了Protobuf,所以getProtocolEngine方法得到的是ProtobufRpcEngine类的一个实例,那好,我们进一步跟踪ProtobufRpcEngine类的getProxy方法,看代码:
public class ProtobufRpcEngine implements RpcEngine {public <T> ProtocolProxy<T> getProxy(Class<T> protocol, long clientVersion,InetSocketAddress addr, UserGroupInformation ticket, Configuration conf,SocketFactory factory, int rpcTimeout, RetryPolicy connectionRetryPolicy) throws IOException {final Invoker invoker = new Invoker(protocol, addr, ticket, conf, factory,rpcTimeout, connectionRetryPolicy);return new ProtocolProxy<T>(protocol, (T) Proxy.newProxyInstance(protocol.getClassLoader(), new Class[]{protocol}, invoker), false);}
}对java的动态代理有点了解的人看到Proxy.newProxyInstance这个方法应该都很清楚这就是生成一个远程代理类实例(特别注意:在NameNodeProxies类的createNNProxyWithClientProtocol方法中getProxy方法拿到的对象也就是这个对象),其中的invoker参数,确实我们不能忽略的,因为他暗藏玄机,java的动态代理中,invoker的类需要实现InvocationHandler接口,该接口只听过一个方法invoke,共代理类使用,及通过Proxy.newProxyInstance生成的代理类,在使用的时候是通过InvocationHandler的invoke方法来起作用的。好吧,现在我们可以顺便看看在ProtobufRpcEngine类的getProxy方法中invoker局部变量的类依赖图: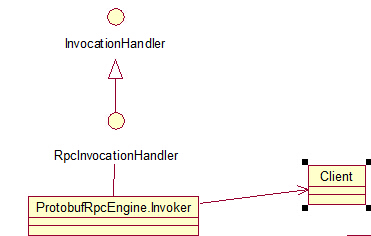 ,显然有刚才提到的实现关系,现在再让我们看看Invoker的内部,包括构造函数和invoke方法:
,显然有刚才提到的实现关系,现在再让我们看看Invoker的内部,包括构造函数和invoke方法:
private Invoker(Class<?> protocol, Client.ConnectionId connId,Configuration conf, SocketFactory factory) {this.remoteId = connId;this.client = CLIENTS.getClient(conf, factory, RpcResponseWrapper.class);this.protocolName = RPC.getProtocolName(protocol);this.clientProtocolVersion = RPC.getProtocolVersion(protocol);}public Object invoke(Object proxy, Method method, Object[] args)throws ServiceException {val = (RpcResponseWrapper) client.call(RPC.RpcKind.RPC_PROTOCOL_BUFFER,new RpcRequestWrapper(rpcRequestHeader, theRequest), remoteId);
}在构造函数请注意一个属性client,他的类型正式 org.apache.hadoop.ipc.Client,而且在invoke方法中发起远程调用的正是这个client属性,能够读到这里的同学,相信应该比较清楚了,在DFSClient中发起远程访问的就是这个Client类的实例。
关于DFSClient的初始化阶段中关于rpc的部分,总结一句,就是创建一个namenode的代理对象,供后续的文件系统操作调用。
DFSClient的getFileLinkInfo方法
DFSClient提供了相当丰富的API供客户端操作hadoop的文件系统,这里以 getFileLinkInfo为例,讲解rpc客户端的调用过程。注意:如果是FileSystem类的话,请使用方法getFileLinkStatus,他对DFSClient提供的getFileLinkInfo做了一层包装,仅此而已。
直接看DFSClient中的代码:
public HdfsFileStatus getFileLinkInfo(String src) throws IOException {checkOpen();try {return namenode.getFileLinkInfo(src);} catch(RemoteException re) {throw re.unwrapRemoteException(AccessControlException.class,UnresolvedPathException.class);}}很简答的一行代码,通过namenode属性的调用操作完成,看了DFSClient的初始化过程,我们很容易知道namenode的实例化类是ClientNamenodeProtocolTranslatorPB,继续看调用过程,代码转到了ClientNamenodeProtocolTranslatorPB中:
@Overridepublic HdfsFileStatus getFileLinkInfo(String src)throws AccessControlException, UnresolvedLinkException, IOException {GetFileLinkInfoRequestProto req = GetFileLinkInfoRequestProto.newBuilder().setSrc(src).build();try {GetFileLinkInfoResponseProto result = rpcProxy.getFileLinkInfo(null, req);return result.hasFs() ? PBHelper.convert(rpcProxy.getFileLinkInfo(null, req).getFs()) : null;} catch (ServiceException e) {throw ProtobufHelper.getRemoteException(e);}}这时候我们会发现一个属性rpcProxy,再回过头看看NameNodeProxies类的createProxy方法,我们就可以很清楚的知道,rpcProxy就是那个能发起远程调用的代理类,它封装了Invoker对象,当然就也有了使用Client类的能力,很好,这里我们稍微总结下,在DFSClient类中,调用getFileLinkInfo方法,最终就是通过Client的call方法,发起远程访问,获取数据。
这时候,我们可以进一步来探讨下Hadoop中RPC的Client类了,下面我把Client类主要的部分抽取出来了,看下面的代码:
public class Client {
Call createCall(RPC.RpcKind rpcKind, Writable rpcRequest) {return new Call(rpcKind, rpcRequest);}public Writable call(RPC.RpcKind rpcKind, Writable rpcRequest,ConnectionId remoteId, int serviceClass) throws IOException {final Call call = createCall(rpcKind, rpcRequest);Connection connection = getConnection(remoteId, call, serviceClass);connection.sendRpcRequest(call); // send the rpc requestreturn call.getRpcResponse();
}private class Connection extends Thread {private void receiveRpcResponse() {}public void sendRpcRequest(final Call call)throws InterruptedException, IOException {}
}
}看了DFSclient的初始化部分,我们就可以知道,DFSClient的远程调用,是通过Client的call方法起作用的。其实Client的call方法已经很能够说明问题了,先封装一个call,然后获取连接,再得到结果。简单的说Client就是这样了。可以在稍微复杂一点,在Client的call方法中,封装了call后,getConnection的方法不仅是获取一个连接,同时会启动连接代表的线程,这个线程的作用就是等待请求的完成,完成后,将结果写到call中(该过程天内各国Connection的receiveRpcRespoce方法完成),在call方法中获取连接后,会发送请求的参数到namenode的服务端,等待namenode处理完毕,Connection的receiveRpcRespoce方法写返回结果,最后call方法中返回结果。大概的过程就是这个样子了。
好像整个过程也不太复杂,只是不熟悉的情况下跟踪代码会比较累点。
转载于:https://my.oschina.net/psuyun/blog/372492
hadoop rpc客户端初始化和调用过程详解相关推荐
- 启动go服务_go微服务框架go-micro深度学习 rpc方法调用过程详解
摘要: 上一篇帖子go微服务框架go-micro深度学习(三) Registry服务的注册和发现详细解释了go-micro是如何做服务注册和发现在,服务端注册server信息,client获取serv ...
- go微服务框架go-micro深度学习(五) stream 调用过程详解
上一篇写了一下rpc调用过程的实现方式,简单来说就是服务端把实现了接口的结构体对象进行反射,抽取方法,签名,保存,客户端调用的时候go-micro封请求数据,服务端接收到请求时,找到需要调用调 ...
- JVM类加载、验证、准备、解析、初始化、卸载过程详解
目录 0 使用类的准备工作 初始化(Init) 1 加载(Load) 1.1 详细过程 1.1.1 通过类全限定名获取该类的二进制字节流 1.1.2 静态存储结构=>运行时数据结构 1.1.3 ...
- 简述python函数调用过程_python函数定义和调用过程详解
我们可以创建一个函数来列出费氏数列 >>> def fib(n): # write Fibonacci series up to n ... """Pr ...
- Spring源码分析之Bean的创建过程详解
前文传送门: Spring源码分析之预启动流程 Spring源码分析之BeanFactory体系结构 Spring源码分析之BeanFactoryPostProcessor调用过程详解 本文内容: 在 ...
- hadoop作业初始化过程详解(源码分析第三篇)
(一)概述 我们在上一篇blog已经详细的分析了一个作业从用户输入提交命令到到达JobTracker之前的各个过程.在作业到达JobTracker之后初始化之前,JobTracker会通过submit ...
- Hadoop学习之Mapreduce执行过程详解
一.MapReduce执行过程 MapReduce运行时,首先通过Map读取HDFS中的数据,然后经过拆分,将每个文件中的每行数据分拆成键值对,最后输出作为Reduce的输入,大体执行流程如下图所示: ...
- Spring生命周期Bean初始化过程详解
Spring生命周期Bean初始化过程详解 Spring 容器初始化 Spring Bean初始化 BeanFactory和FactoryBean 源码分析 Bean的实例化 preInstantia ...
- 简历项目描述过程详解
简历项目描述过程详解 一.项目分点 1.1 集群规模 1.2 框架结构,画出来 1.3 框架 1.3.1 第一个Flume 1.3.1.1 碰到的问题 1.3.2 kafka 1.3.2.1 框架介绍 ...
最新文章
- springboot集成kafka及kafka web UI的使用
- VTK:相互作用之RubberBand2DObserver
- 2019ICPC(沈阳) - Fish eating fruit(树形dp+树根转移)
- 工厂设计模式案例研究
- Oracle存储过程快速入门
- 伦敦帝国学院M+T实验室,全奖博士招生
- Git fatal: write error: Broken pipe
- python 获取当前路径_Python获取当前路径实现代码
- 杭电acm 1205 吃糖果
- java并发包是谁编写的_0.Java并发包系列开篇
- 如何使用Visio 2007制作流程图
- [经典好文] 谈笑色影间,人生本无忌 (转于色影无忌)
- 沉思录(MEDITATIONS)1-12卷
- wps如何对比两列数据找出不同
- 【wav音频解析】之wavread函数的C++实现
- 人工智能应该用在这个地方!
- 求解TSP问题(python)(穷举、最近邻居法、opt-2法、动态规划、插入法)
- mysql积累--索引
- js实现小游戏 贪吃蛇
- 密码学系列 - 国密算法