【算法】skiplist——调表,一种随机化的类平衡二叉树
参考文章:http://wenku.baidu.com/link?url=nk9uFfTZuwVIU-yldWkOaiv4qFVAb8QZK2wV7JYzAxot2bCSn-nV9emUX8B2depBnOh66vRy28zQxZ5khGp6U7SQuS4qcuw0vVGmoDxUSiC
参考文章:http://dsqiu.iteye.com/blog/1705530
参考文章:http://www.cnblogs.com/xuqiang/archive/2011/05/22/2053516.html
参考文章:http://deepfuture.iteye.com/blog/954342
跳跃表(Skip List)是1987年才诞生的一种崭新的数据结构,它在进行查找、插入、删除等操作时的期望时间复杂度均为O(logn),有着近乎替代平衡树的本领。而且最重要的一点,就是它的编程复杂度较同类的AVL树,红黑树等要低得多,这使得其无论是在理解还是在推广性上,都有着十分明显的优势。
首先,我们来看一下跳跃表的结构
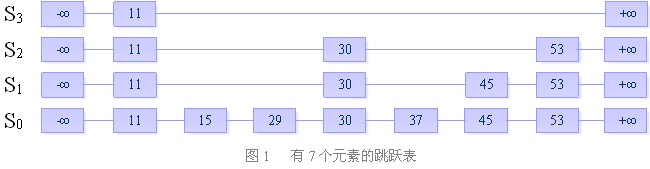
跳跃表由多条链构成(S0,S1,S2 ……,Sh),且满足如下三个条件:
每条链必须包含两个特殊元素:+∞ 和 -∞(其实不需要)
S0包含所有的元素,并且所有链中的元素按照升序排列。
每条链中的元素集合必须包含于序数较小的链的元素集合。
操作
一、查找
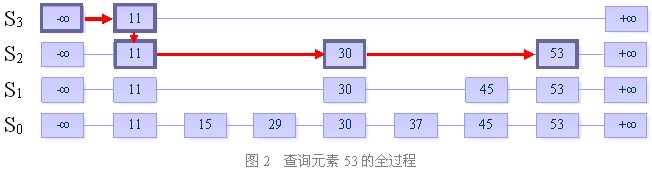
目的:在跳跃表中查找一个元素x
在跳跃表中查找一个元素x,按照如下几个步骤进行:
1. 从最上层的链(Sh)的开头开始
2. 假设当前位置为p,它向右指向的节点为q(p与q不一定相邻),且q的值为y。将y与x作比较
(1) x=y 输出查询成功及相关信息
(2) x>y 从p向右移动到q的位置
(3) x<y 从p向下移动一格
3. 如果当前位置在最底层的链中(S0),且还要往下移动的话,则输出查询失败
二、插入
目的:向跳跃表中插入一个元素x
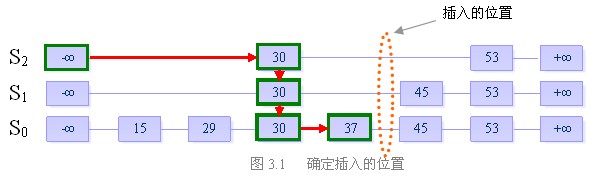
首先明确,向跳跃表中插入一个元素,相当于在表中插入一列从S0中某一位置出发向上的连续一段元素。有两个参数需要确定,即插入列的位置以及它的“高度”。
关于插入的位置,我们先利用跳跃表的查找功能,找到比x小的最大的数y。根据跳跃表中所有链均是递增序列的原则,x必然就插在y的后面。
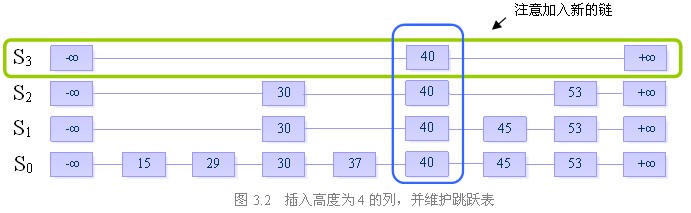
而插入列的“高度”较前者来说显得更加重要,也更加难以确定。由于它的不确定性,使得不同的决策可能会导致截然不同的算法效率。为了使插入数据之后,保持该数据结构进行各种操作均为O(logn)复杂度的性质,我们引入随机化算法(Randomized Algorithms)。
我们定义一个随机决策模块,它的大致内容如下:
产生一个0到1的随机数r r ← random()
如果r小于一个常数p,则执行方案A, if r<p then do A
否则,执行方案B else do B
初始时列高为1。插入元素时,不停地执行随机决策模块。如果要求执行的是A操作,则将列的高度加1,并且继续反复执行随机决策模块。直到第i次,模块要求执行的是B操作,我们结束决策,并向跳跃表中插入一个高度为i的列。
我们来看一个例子:
假设当前我们要插入元素“40”,且在执行了随机决策模块后得到高度为4
步骤一:找到表中比40小的最大的数,确定插入位置
步骤二:插入高度为4的列,并维护跳跃表的结构
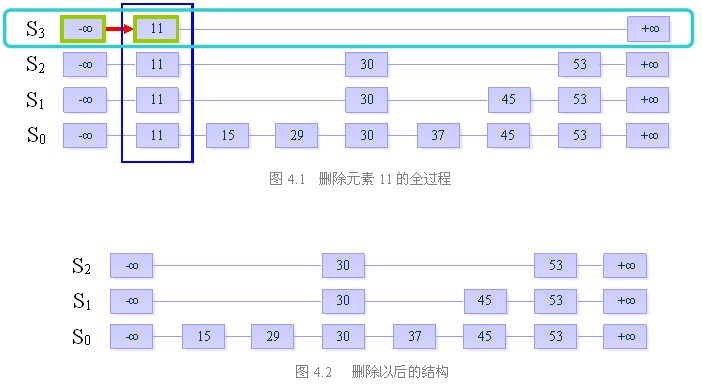
三、删除
目的:从跳跃表中删除一个元素x
删除操作分为以下三个步骤:
在跳跃表中查找到这个元素的位置,如果未找到,则退出
将该元素所在整列从表中删除
将多余的“空链”删除
我们来看一下跳跃表的相关复杂度:
空间复杂度: O(n) (期望)
跳跃表高度: O(logn) (期望)
相关操作的时间复杂度:
查找: O(logn) (期望)
插入: O(logn) (期望)
删除: O(logn) (期望)
之所以在每一项后面都加一个“期望”,是因为跳跃表的复杂度分析是基于概率论的。有可能会产生最坏情况,不过这种概率极其微小。
1.聊一聊跳表作者的其人其事
2. 言归正传,跳表简介
3. 跳表数据存储模型
4. 跳表的代码实现分析
5. 论文,代码下载及参考资料
<1>. 聊一聊作者的其人其事
跳表是由William Pugh发明。他在 Communications of the ACM June 1990, 33(6) 668-676 发表了Skip lists: a probabilistic alternative to balanced trees,在该论文中详细解释了跳表的数据结构和插入删除操作。
William Pugh同时还是FindBug(没有使用过,这是一款java的静态代码分析工具,直接对java 的字节码进行分析,能够找出java字节码中潜在很多错误。)作者之一。现在是University of Maryland, College Park(马里兰大学伯克分校,位于马里兰州,全美大学排名在五六十名左右的样子)大学的一名教授。他和他的学生所作的研究深入的影响了java语言中内存池实现。
又是一个计算机的天才!
<2>. 言归正传,跳表简介
这是跳表的作者,上面介绍的William Pugh给出的解释:
Skip lists are a data structure that can be used in place of balanced trees. Skip lists use probabilistic balancing rather than strictly enforced balancing and as a result the algorithms for insertion and deletion in skip lists are much simpler and significantly faster than equivalent algorithms for balanced trees.
跳表是平衡树的一种替代的数据结构,但是和红黑树不相同的是,跳表对于树的平衡的实现是基于一种随机化的算法的,这样也就是说跳表的插入和删除的工作是比较简单的。
下面来研究一下跳表的核心思想:
先从链表开始,如果是一个简单的链表,那么我们知道在链表中查找一个元素I的话,需要将整个链表遍历一次。
![]()
如果是说链表是排序的,并且节点中还存储了指向前面第二个节点的指针的话,那么在查找一个节点时,仅仅需要遍历N/2个节点即可。
![]()
这基本上就是跳表的核心思想,其实也是一种通过“空间来换取时间”的一个算法,通过在每个节点中增加了向前的指针,从而提升查找的效率。
<3>.跳表的数据存储模型
我们定义:
如果一个基点存在k个向前的指针的话,那么陈该节点是k层的节点。
一个跳表的层MaxLevel义为跳表中所有节点中最大的层数。
下面给出一个完整的跳表的图示:
![]()
那么我们该如何将该数据结构使用二进制存储呢?通过上面的跳表的很容易设计这样的数据结构:
定义每个节点类型:
typedef struct nodeStructure
![]()
上面的每个结构体对应着图中的每个节点,如果一个节点是一层的节点的话(如7,12等节点),那么对应的forward将指向一个只含一个元素的数组,以此类推。
定义跳表数据类型:
} * list;
跳表数据类型中包含了维护跳表的必要信息,level表明跳表的层数,header如下所示:
![]()
定义辅助变量:
定义上图中的NIL变量:node NIL;
#define MaxLevel (MaxNumberOfLevels-1)
定义辅助方法:
好的基本的数据结构定义已经完成,接下来来分析对于跳表的一个操作。
<4>. 跳表的代码实现分析
4.1 初始化
初始化的过程很简单,仅仅是生成下图中红线区域内的部分,也就是跳表的基础结构:
![]()
};
4.2 插入操作
由于跳表数据结构整体上是有序的,所以在插入时,需要首先查找到合适的位置,然后就是修改指针(和链表中操作类似),然后更新跳表的level变量。
![]()
}
4.3 删除某个节点
和插入是相同的,首先查找需要删除的节点,如果找到了该节点的话,那么只需要更新指针域,如果跳表的level需要更新的话,进行更新。
![]()
}
4.4 查找
查找操作其实已经在插入和删除过程中包含,比较简单,可以参考源代码。
<5>. 论文,代码下载及参考资料
SkipList论文
/Files/xuqiang/skipLists.rar
//--------------------------------------------------------------------------------
增加跳表c#实现代码 2011-5-29下午
上面给出的数据结构的模型是直接按照跳表的模型得到的,另外还有一种数据结构的模型:
跳表节点类型,每个跳表类型中仅仅存储了左侧的节点和下面的节点:
![]()
我们现在来看对于这种模型的操作代码:
1. 初始化完成了如下的操作:
![]()
2. 插入操作:和上面介绍的插入操作是类似的,首先查找到插入的位置,生成update数组,然后随机生成一个level,然后修改指针。
3. 删除操作:和上面介绍的删除操作是类似的,查找到需要删除的节点,如果查找不到,抛出异常,如果查找到的需要删除的节点的话,修改指针,释放删除节点的内存。
Skip List(跳跃表)原理详解与实现
本文内容框架:
§1 Skip List 介绍
§2 Skip List 定义以及构造步骤
§3 Skip List 完整实现
§4 Skip List 概率分析
§5 小结
§1 Skip List 介绍
Skip List是一种随机化的数据结构,基于并联的链表,其效率可比拟于二叉查找树(对于大多数操作需要O(log n)平均时间)。基本上,跳跃列表是对有序的链表增加上附加的前进链接,增加是以随机化的方式进行的,所以在列表中的查找可以快速的跳过部分列表(因此得名)。所有操作都以对数随机化的时间进行。Skip List可以很好解决有序链表查找特定值的困难。
§2 Skip List 定义以及构造步骤
Skip List定义
像下面这样(初中物理经常这样用,这里我也盗用下):
一个跳表,应该具有以下特征:
- 一个跳表应该有几个层(level)组成;
- 跳表的第一层包含所有的元素;
- 每一层都是一个有序的链表;
- 如果元素x出现在第i层,则所有比i小的层都包含x;
- 第i层的元素通过一个down指针指向下一层拥有相同值的元素;
- 在每一层中,-1和1两个元素都出现(分别表示INT_MIN和INT_MAX);
- Top指针指向最高层的第一个元素。
构建有序链表

的一个跳跃表如下:

Skip List构造步骤:
1、给定一个有序的链表。
2、选择连表中最大和最小的元素,然后从其他元素中按照一定算法(随机)随即选出一些元素,将这些元素组成有序链表。这个新的链表称为一层,原链表称为其下一层。
3、为刚选出的每个元素添加一个指针域,这个指针指向下一层中值同自己相等的元素。Top指针指向该层首元素
4、重复2、3步,直到不再能选择出除最大最小元素以外的元素。
§3 Skip List 完整实现
下面来定义跳表的数据结构(基于C)
首先是每个节点的数据结构
- typedef struct nodeStructure
- {
- int key;
- int value;
- struct nodeStructure *forward[1];
- }nodeStructure;
跳表的结构如下
- typedef struct skiplist
- {
- int level;
- nodeStructure *header;
- }skiplist;
下面是跳表的基本操作
首先是节点的创建
- nodeStructure* createNode(int level,int key,int value)
- {
- nodeStructure *ns=(nodeStructure *)malloc(sizeof(nodeStructure)+level*sizeof(nodeStructure*));
- ns->key=key;
- ns->value=value;
- return ns;
- }
列表的初始化
列表的初始化需要初始化头部,并使头部每层(根据事先定义的MAX_LEVEL)指向末尾(NULL)。
- skiplist* createSkiplist()
- {
- skiplist *sl=(skiplist *)malloc(sizeof(skiplist));
- sl->level=0;
- sl->header=createNode(MAX_LEVEL-1,0,0);
- for(int i=0;i<MAX_LEVEL;i++)
- {
- sl->header->forward[i]=NULL;
- }
- return sl;
- }
插入元素
插入元素的时候元素所占有的层数完全是随机的,通过随机算法产生
- int randomLevel()
- {
- int k=1;
- while (rand()%2)
- k++;
- k=(k<MAX_LEVEL)?k:MAX_LEVEL;
- return k;
- }
跳表的插入需要三个步骤,第一步需要查找到在每层待插入位置,然后需要随机产生一个层数,最后就是从高层至下插入,插入时算法和普通链表的插入完全相同。

- bool insert(skiplist *sl,int key,int value)
- {
- nodeStructure *update[MAX_LEVEL];
- nodeStructure *p, *q = NULL;
- p=sl->header;
- int k=sl->level;
- //从最高层往下查找需要插入的位置
- //填充update
- for(int i=k-1; i >= 0; i--){
- while((q=p->forward[i])&&(q->key<key))
- {
- p=q;
- }
- update[i]=p;
- }
- //不能插入相同的key
- if(q&&q->key==key)
- {
- return false;
- }
- //产生一个随机层数K
- //新建一个待插入节点q
- //一层一层插入
- k=randomLevel();
- //更新跳表的level
- if(k>(sl->level))
- {
- for(int i=sl->level; i < k; i++){
- update[i] = sl->header;
- }
- sl->level=k;
- }
- q=createNode(k,key,value);
- //逐层更新节点的指针,和普通列表插入一样
- for(int i=0;i<k;i++)
- {
- q->forward[i]=update[i]->forward[i];
- update[i]->forward[i]=q;
- }
- return true;
- }
红色区域为辅助数组update的内容
删除节点
删除节点操作和插入差不多,找到每层需要删除的位置,删除时和操作普通链表完全一样。不过需要注意的是,如果该节点的level是最大的,则需要更新跳表的level。
- bool deleteSL(skiplist *sl,int key)
- {
- nodeStructure *update[MAX_LEVEL];
- nodeStructure *p,*q=NULL;
- p=sl->header;
- //从最高层开始搜
- int k=sl->level;
- for(int i=k-1; i >= 0; i--){
- while((q=p->forward[i])&&(q->key<key))
- {
- p=q;
- }
- update[i]=p;
- }
- if(q&&q->key==key)
- {
- //逐层删除,和普通列表删除一样
- for(int i=0; i<sl->level; i++){
- if(update[i]->forward[i]==q){
- update[i]->forward[i]=q->forward[i];
- }
- }
- free(q);
- //如果删除的是最大层的节点,那么需要重新维护跳表的
- for(int i=sl->level-1; i >= 0; i--){
- if(sl->header->forward[i]==NULL){
- sl->level--;
- }
- }
- return true;
- }
- else
- return false;
- }
查找
跳表的优点就是查找比普通链表快,当然查找操作已经包含在在插入和删除过程,实现起来比较简单。

搜索key=14的示意图
- int search(skiplist *sl,int key)
- {
- nodeStructure *p,*q=NULL;
- p=sl->header;
- //从最高层开始搜
- int k=sl->level;
- for(int i=k-1; i >= 0; i--){
- while((q=p->forward[i])&&(q->key<=key))
- {
- if(q->key==key)
- {
- return q->value;
- }
- p=q;
- }
- }
- return NULL;
- }
完整代码如下:
- #include<stdio.h>
- #include<stdlib.h>
- #define MAX_LEVEL 10 //最大层数
- //节点
- typedef struct nodeStructure
- {
- int key;
- int value;
- struct nodeStructure *forward[1];
- }nodeStructure;
- //跳表
- typedef struct skiplist
- {
- int level;
- nodeStructure *header;
- }skiplist;
- //创建节点
- nodeStructure* createNode(int level,int key,int value)
- {
- nodeStructure *ns=(nodeStructure *)malloc(sizeof(nodeStructure)+level*sizeof(nodeStructure*));
- ns->key=key;
- ns->value=value;
- return ns;
- }
- //初始化跳表
- skiplist* createSkiplist()
- {
- skiplist *sl=(skiplist *)malloc(sizeof(skiplist));
- sl->level=0;
- sl->header=createNode(MAX_LEVEL-1,0,0);
- for(int i=0;i<MAX_LEVEL;i++)
- {
- sl->header->forward[i]=NULL;
- }
- return sl;
- }
- //随机产生层数
- int randomLevel()
- {
- int k=1;
- while (rand()%2)
- k++;
- k=(k<MAX_LEVEL)?k:MAX_LEVEL;
- return k;
- }
- //插入节点
- bool insert(skiplist *sl,int key,int value)
- {
- nodeStructure *update[MAX_LEVEL];
- nodeStructure *p, *q = NULL;
- p=sl->header;
- int k=sl->level;
- //从最高层往下查找需要插入的位置
- //填充update
- for(int i=k-1; i >= 0; i--){
- while((q=p->forward[i])&&(q->key<key))
- {
- p=q;
- }
- update[i]=p;
- }
- //不能插入相同的key
- if(q&&q->key==key)
- {
- return false;
- }
- //产生一个随机层数K
- //新建一个待插入节点q
- //一层一层插入
- k=randomLevel();
- //更新跳表的level
- if(k>(sl->level))
- {
- for(int i=sl->level; i < k; i++){
- update[i] = sl->header;
- }
- sl->level=k;
- }
- q=createNode(k,key,value);
- //逐层更新节点的指针,和普通列表插入一样
- for(int i=0;i<k;i++)
- {
- q->forward[i]=update[i]->forward[i];
- update[i]->forward[i]=q;
- }
- return true;
- }
- //搜索指定key的value
- int search(skiplist *sl,int key)
- {
- nodeStructure *p,*q=NULL;
- p=sl->header;
- //从最高层开始搜
- int k=sl->level;
- for(int i=k-1; i >= 0; i--){
- while((q=p->forward[i])&&(q->key<=key))
- {
- if(q->key == key)
- {
- return q->value;
- }
- p=q;
- }
- }
- return NULL;
- }
- //删除指定的key
- bool deleteSL(skiplist *sl,int key)
- {
- nodeStructure *update[MAX_LEVEL];
- nodeStructure *p,*q=NULL;
- p=sl->header;
- //从最高层开始搜
- int k=sl->level;
- for(int i=k-1; i >= 0; i--){
- while((q=p->forward[i])&&(q->key<key))
- {
- p=q;
- }
- update[i]=p;
- }
- if(q&&q->key==key)
- {
- //逐层删除,和普通列表删除一样
- for(int i=0; i<sl->level; i++){
- if(update[i]->forward[i]==q){
- update[i]->forward[i]=q->forward[i];
- }
- }
- free(q);
- //如果删除的是最大层的节点,那么需要重新维护跳表的
- for(int i=sl->level - 1; i >= 0; i--){
- if(sl->header->forward[i]==NULL){
- sl->level--;
- }
- }
- return true;
- }
- else
- return false;
- }
- void printSL(skiplist *sl)
- {
- //从最高层开始打印
- nodeStructure *p,*q=NULL;
- //从最高层开始搜
- int k=sl->level;
- for(int i=k-1; i >= 0; i--)
- {
- p=sl->header;
- while(q=p->forward[i])
- {
- printf("%d -> ",p->value);
- p=q;
- }
- printf("\n");
- }
- printf("\n");
- }
- int main()
- {
- skiplist *sl=createSkiplist();
- for(int i=1;i<=19;i++)
- {
- insert(sl,i,i*2);
- }
- printSL(sl);
- //搜索
- int i=search(sl,4);
- printf("i=%d\n",i);
- //删除
- bool b=deleteSL(sl,4);
- if(b)
- printf("删除成功\n");
- printSL(sl);
- system("pause");
- return 0;
- }
§4 Skip List 概率分析



§5 小结
本篇博文已经详细讲解了Skip List数据结构的所有内容,应该可以有一个深入的了解。如果你有任何建议或者批评和补充,请留言指出,不胜感激,更多参考请移步互联网。
参考:
①Skip List: http://www.cs.auckland.ac.nz/software/AlgAnim/niemann/s_skl.htm
②Songeliu: http://www.spongeliu.com/63.html
③Shi Kai Lun :http://yilee.info/skip-list.html
④Michael T. Goodrich Roberto Tamassia Algorithm Design Foundations, Analysis, and Internet Examples
⑤http://epaperpress.com/sortsearch/skl.html
【算法】skiplist——调表,一种随机化的类平衡二叉树相关推荐
- 跳跃表 skipList 跳表的原理以及golang实现
跳跃表 skipList 调表的原理以及golang实现 调表skiplist 是一个特殊的链表,相比一般的链表有更高的查找效率,跳跃表的查找,插入,删除的时间复杂度O(logN) Redis中的有序 ...
- ML之R:通过数据预处理利用LiR/XGBoost等(特征重要性/交叉训练曲线可视化/线性和非线性算法对比/三种模型调参/三种模型融合)实现二手汽车产品交易价格回归预测之详细攻略
ML之R:通过数据预处理利用LiR/XGBoost等(特征重要性/交叉训练曲线可视化/线性和非线性算法对比/三种模型调参/三种模型融合)实现二手汽车产品交易价格回归预测之详细攻略 目录 三.模型训练 ...
- skiplist 跳表(1)
最近学习中遇到一种新的数据结构,很实用,搬过来学习. 原文地址:skiplist 跳表 为什么选择跳表 目前经常使用的平衡数据结构有:B树,红黑树,AVL树,Splay Tree, Treep等. ...
- SkipList 跳表
转载:https://blog.csdn.net/fw0124/article/details/42780679 为什么选择跳表 说起跳表,我们还是要从二分查找开始. 二分查找的关键要求有两个, 1 ...
- SkipList 跳跃表
http://blog.csdn.net/likun_tech/article/details/7354306 http://www.cnblogs.com/zhuangli/articles/127 ...
- 初学者如何选择合适的机器学习算法(附算法速查表)
来源:机器之心 参与:黄小天.蒋思源.吴攀 校对:谭佳瑶 本文长度为4000字,建议阅读6分钟 本文针对算法的选择为你提供一些参考意见. 本文主要的目标读者是机器学习爱好者或数据科学的初学者,以及对学 ...
- skiplist 跳表(2)-----细心学习
快速了解skiplist请看:skiplist 跳表(1) http://blog.sina.com.cn/s/blog_693f08470101n2lv.html 本周我要介绍的数据结构,是我非常非 ...
- CG100---13年金牛星 调表 型号HA48
CG100 曾欢 13年 名爵MG3 仪表MC9S12HZ128 BCM-24C16 CG100具体的功能和特点 1.仪表调校 单片机仪表,9s12仪表,八脚码片仪表集成在一起,这是其它设备不具备的. ...
- 性能优化专题 - JVM 性能优化 - 04 - GC算法与调优
目录导航 前言 Garbage Collect(垃圾回收) 如何确定一个对象是垃圾? 引用计数法 可达性分析 垃圾收集算法 标记-清除(Mark-Sweep) 复制(Copying) 标记-整理(Ma ...
最新文章
- 自建28核树莓派集群,顺便学学docker,这里有一个500美元的搭建方案
- 浅玩JavaScript的数据类型判断
- springboot 压测 50并发 线程等待_Spring Boot中三款内嵌容器的使用
- mysql 数据趋势,2019年8月全球数据库流行度排行--oracle、mysql增长趋势明显
- Qt文档阅读笔记-QWindow的进一步认识
- 关于PHP的错误机制总结
- mysql启动日志指令_简单整理MySQL的日志操作命令
- bzoj4152 [AMPPZ2014]The Captain
- 自定义标签之使用struts的valueStack取值
- bc8-android导航,路畅A6导航刷机固件 4.09 CN-A6-GBDS-BC8-VIN-256-V1.51
- 【解析】.NET中代理服务器WebProxy的各种用法
- 计算机用户名显示TEMP,windows7登陆创建TEMP临时个人配置文件夹解决方法-系统操作与应用 -亦是美网络...
- kindeditor用法简介
- [Protues]protues8使用示波器制作李沙育图形
- HDOJ题目分类大全
- Redis缓存击穿、雪崩、穿透!(超详细)
- 12.5米分辨率DEM
- clickhouse 生产集群部署之坑坑洼洼(三)
- tp5.1对接阿里云短信实例
- CorelDRAW VBA - 打开文件(另存为)对话框
热门文章
- 你是外包,麻烦不要偷吃零食。。。网友:...
- No thread-bound request found: Are you referring to request attributes outside of an actual web
- datax(二)datax on azkaban架构设计之datax as a service
- [ECCV2022]3D face reconstruction with dense landmarks
- python判断是否为中文、中文符号、英文、英文符号
- 中国拳手徐灿将战世界拳王:有信心把金腰带带回祖国
- 阿里easyexcel读取excel流程初探
- 关于MERGE JOIN CARTESIAN
- 编写一个程序,完成字符大小写的转换。
- vue+element实现天翼云oos上传文件