【深度学习】— 各框架分布式训练简介+测评
1.各框架分布式简介
1.Pytorch
从官方文档上我们可以看到,pytorch的分布式训练,主要是torch.distributed包所提供,主要包含以下组件:
- Distributed Data-Parallel Training (DDP)
- RPC-Based Distributed Training (RPC)
- Collective Communication (c10d)
其中,DDP提供了数据并行相关的分布式训练接口;RPC提供了数据并行之外,其他类型的分布式训练如参数服务器模式、pipeline并行模式,使用的是P2P点对点通信;而c10d是一个用于集合通信的库,作为DDP的组件为其提供服务。由于我们大多数的分布式训练需求,是基于DDP的,故下面内容不涉及RPC相关的训练。
接口
单机多GPU可以使用torch.nn.DataParallel接口或torch.nn.parallel.DistributedDataParallel接口。不过官方更推荐使用DistributedDataParallel(DDP);分布式多机情况下,则只能使用DDP接口。
DistributedDataParallel和 之间的区别DataParallel是:DistributedDataParallel使用multiprocessing,即为每个GPU创建一个进程,而DataParallel使用多线程。通过使用multiprocessing,每个GPU都有其专用的进程,这避免了Python解释器的GIL导致的性能开销。如果您使用DistributedDataParallel,则可以使用 torch.distributed.launch实用程序来启动程序
参考:Use nn.parallel.DistributedDataParallel instead of multiprocessing or nn.DataParallel
底层依赖
Pytorch在1.6版本中,可以通过torch.nn.parallel.DistributedDataParallel来实现数据并行的分布式训练,DistributedDateParallel,简称DDP。
DDP的上层调用是通过dispatch.py实现的,即dispatch.py是DDP的python入口,它实现了 调用C ++库forward的nn.parallel.DistributedDataParallel模块的初始化步骤和功能;DDP的底层依赖c10d库的ProcessGroup进行通信,可以在ProcessGroup中找到3种开箱即用的实现,即 ProcessGroupGloo,ProcessGroupNCCL和ProcessGroupMPI。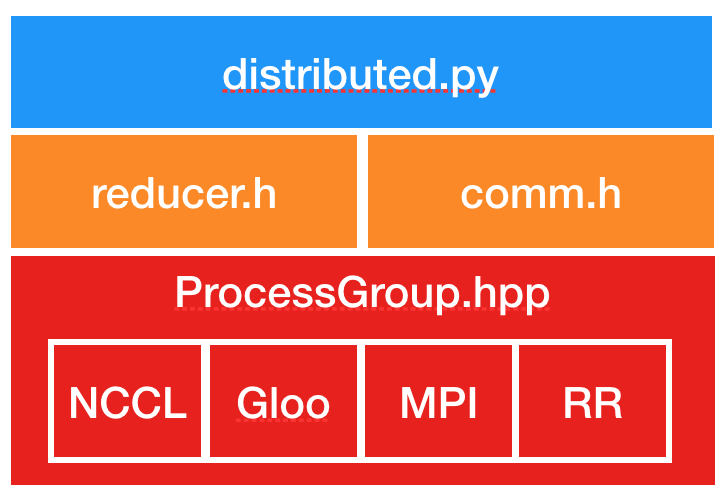
ProcessGroupGloo,ProcessGroupNCCL和ProcessGroupMPI这3种分布式通讯实现分别对应:
- Gloo
- NCCL
- MPI
即本质上,pytorch的分布式多机训练,依赖于以上这3种通信库。
参考:Distributed Data Parallel
分布式示例
我们以Pytorch官方仓库里的分布式训练源码为例,简单讲解下pytorch分布式训练相关方法和参数。
相关参数
分布式训练的入口是main.py,我们首先看下分布式设置相关的参数。
源码第59行:
parser.add_argument('--world-size', default=-1, type=int,help='number of nodes for distributed training')
parser.add_argument('--rank', default=-1, type=int,help='node rank for distributed training')
parser.add_argument('--dist-url', default='tcp://224.66.41.62:23456', type=str,help='url used to set up distributed training')
parser.add_argument('--dist-backend', default='nccl', type=str,help='distributed backend')
parser.add_argument('--seed', default=None, type=int,help='seed for initializing training. ')
parser.add_argument('--gpu', default=None, type=int,help='GPU id to use.')
parser.add_argument('--multiprocessing-distributed', action='store_true',help='Use multi-processing distributed training to launch ''N processes per node, which has N GPUs. This is the ''fastest way to use PyTorch for either single node or ''multi node data parallel training')
- –world-size 表示分布式训练中,机器节点总数
- –rank 表示节点编号(n台节点即:0,1,2,…,n-1)
- –multiprocessing-distributed 是否开启多进程模式(单机、多机都可开启)
- –dist-url 本机的ip,端口号,用于多机通信
- –dist-backend 多机通信后端,默认使用nccl
初始化进程组
分布式训练的第一步是需要设置分布式进程组,设置多机通信后端、本机ip端口号、节点总数、本机编号等信息。
源码129行:
dist.init_process_group(backend=args.dist_backend, init_method=args.dist_url,world_size=args.world_size, rank=args.rank)
将上述分布式相关参数,传递到torch.distributed.init_process_group并初始化用于训练的线程组;
**
创建模型
分布式训练时,模型需要用DDP进行包装。
源码153行:
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.gpu])
通过DDP接口创建一个多机model实例。
**
数据切分和DataLoader
多机的Dataloader和普通dataloader也有所区别,需要用DistributedSampler包装后再通过torch.utils.data.DataLoader实例化成Dataloader。
源码217行:
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
通过DistributedSampler创建一个wapper,将数据集放入其中,再通过 torch.utils.data.DataLoader
创建可用于多机的Dataloader;
if args.distributed:train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)else:train_sampler = Nonetrain_loader = torch.utils.data.DataLoader(train_dataset, batch_size=args.batch_size, shuffle=(train_sampler is None),num_workers=args.workers, pin_memory=True, sampler=train_sampler)
其余部分,和正常的单机版训练差异不大,此处就不赘述了。
- 完整的利用ResNet50训练ImageNet的示例可参考:Pytorch官方仓库
- 分布式训练速度测评及结果,可以参考DLPerf:PyTorch ResNet50 v1.5测评
2.PaddlePaddle
接口
从Paddle Fluid Release 1.5.1 开始,官方推荐使用Fleet API进行分布式训练,关于Fleet API的介绍可以参考 Fleet Design Doc。
Fluid支持数据并行的分布式训练,API使用 DistributeTranspiler 将单机网络配置转换成可以多机执行的 pserver 端程序和 trainer 端程序。用户在不同的节点执行相同的一段代码,根据环境变量或启动参数, 可以执行对应的 pserver 或 trainer 角色。Fluid分布式同步训练同时支持pserver模式和NCCL2模式, 在API使用上有差别,需要注意。参考:Paddle:分布式同步训练
**pserver模式即参数服务器模式;NCCL2模式,即集合通信模式(利用NCCL进行通信并更新梯度的模型);**通常,在分布式多GPU的环境下,我们使用NCCL模式的分布式训练。在Paddle中使用NCCL进行数据并行的分布式训练时,除了需要预先为每台节点安装相应版本的NCCL外,还需要在代码中设置如下参数:
- trainer_id trainer节点的id,从0到n-1,n为当前训练任务中trainer节点的个数
- trainers 字符串类型,指定当前任务所有trainer的IP和端口号,仅用于NCCL2初始化
- current_endpoint 当前任务的当前节点的IP和端口号
参考:https://www.paddlepaddle.org.cn/tutorials/projectdetail/487871
分布式示例
- 基于paddle.fluid接口,利用ResNet50网络训练ImageNet的示例可参考:PaddlePaddle官方仓库
- 分布式训练速度测评及结果,可以参考DLPerf:PaddlePaddle-ResNet50V1.5测评
- 基于Paddle分布式Fleet API,将单机的训练代码改造成分布式,可以参考:多机多卡训练
3.MXNet
https://github.com/apache/incubator-mxnet/
可通过ps-lite,Horovod和BytePS通过自动并行扩展到多GPU和分布式设置。
概念
Worker Server Scheduler
MXNet支持数据并行和模型并行的分布式训练。在MXNet的分布式训练中有3个比较重要的角色:
- Worker
- Server
- Scheduler
worker,server,scheduler三者共同协作,完成模型的分布式训练过程。其中,worker是分布式训练的执行单元,在分布式训练处理每个batch前,worker会从server处拉取最新的权重,其次worker还可以在每个batch训练结束后将梯度发送至server处;server顾名思义是服务器单元,用于存储模型参数并和各个worker进行通信;scheduler的作用是建立集群,管理节点和端口监听。
MXNet中还用到了key-value store(KVStore)即键值存储的概念。在分布式训练过程中,一个或多个server通过KVStore存储了worker训练过程中产生的参数,其中模型网络中,每个参数数组分配一个key,而value则存储了其权重,worker通过pull和push来更新参数的权重。在编译MXNet时,需添加build flag:USE_DIST_KVSTORE=1
以使MXNet支持分布式训练。
KVStore
KVStore服务器支持两种工作模式:
- 1.聚合梯度但不应用更新
- 2.聚合梯度且更新权重
模式1表示server仅聚合各个worker的梯度,但是并不应用更新梯度;模式2表示聚合各worker的梯度且应用这些梯度进行权重更新。创建gluon.Trainer时,可以通过参数update_on_kvstore=False或True来分别开启这两种工作模式。
NCCL+CUDA支持
为了在NVIDIA显卡设备上获得更好的性能,需要在源码构建MXNet时添加CUDA支持,build时需要添加USE_CUDA构建项;同样,为了使用NVIDIA集合通信库NCCL,需要添加USE_NCCL构建项
参考:
https://mxnet.cdn.apache.org/versions/1.7.0/api/faq/distributed_training
https://mxnet.apache.org/get_started/build_from_source
分布式示例
下面,我们以MXNet官方仓库里的ResNet50分布式训练为例,简单讲解下MXNet分布式训练相关方法和参数。
初始化horovod
分布式训练是通过train_horovod.py 完成。训练前,需要先初始化horovod,初始化后可以通过hvd.size()、hvd.rank()、hvd.local_rank()等查看horovod协调的计算资源。train_horovod.py
源码141行:
# Horovod: initialize Horovod
hvd.init()
num_workers = hvd.size()
rank = hvd.rank()
local_rank = hvd.local_rank()
- num_workers,即当前节点上horovod工作进程数量,通常等于GPU数量;
- rank = hvd.rank(),是一个全局GPU资源列表;
- local_rank = hvd.local_rank()是当前节点上的GPU资源列表;
譬如有4台节点,每台节点上4块GPU,则num_workers的范围为015,local_rank为03
同步模型参数
分布式的模型创建和多机类似,区别在于,使用horovod时,需要通过hvd.broadcast_parameters 将当前节点模型参数“广播”出去,即将模型权重同步至各个节点。
源码374行:
# Fetch and broadcast parameters
params = model.collect_params()
if params is not None:hvd.broadcast_parameters(params, root_rank=0)
**
切分数据集
分布式训练时,和单机训练一样,都是通过gluon.data.DataLoader来完成数据加载,区别在于分布式情况下,需要提前用SplitSampler来对train_data、val_data的数据进行切分。
源码241行:
train_sampler = SplitSampler(len(train_set), num_parts=num_workers, part_index=rank)train_data = gluon.data.DataLoader(train_set, batch_size=batch_size,# shuffle=True,last_batch='discard', num_workers=data_nthreads,sampler=train_sampler)
**
分布式Trainer
分布式训练时,需要使用hvd.DistributedTrainer创建trainer,此trainer是gluon.Trainer的子类
源码389行:
# Horovod: create DistributedTrainer, a subclass of gluon.Trainertrainer = hvd.DistributedTrainer(params, opt)if args.resume_states != '':trainer.load_states(args.resume_states)
完整的利用ResNet50训练ImageNet的示例可参考:官方仓库,仓库里也提供了正常(非分布式)情况下的imagenet训练代码:train_imagenet.py,可以用于和分布式训练代码train_horovod.py做比较;
分布式训练速度测评及结果,可以参考DLPerf:MXNet ResNet50 测评
4.Tensorflow
接口
在Tensorflow中,需要通过tf.distribute.Strategy接口来定义分布式策略,并通过这些不同的策略,来进行模型的分布式训练。tf.distribute.Strategy 旨在实现以下目标:
- 易于使用,支持多种用户(包括研究人员和 ML 工程师等)。
- 提供开箱即用的良好性能。
- 轻松切换策略。
从Tensorflow官方文档中,我们可以看到主要有以下策略:
- MirroredStrategy
- TPUStrategy
- MultiWorkerMirroredStrategy
- CentralStorageStrategy
- ParameterServerStrategy
当然,需要注意的是:从单机训练切换到使用这些策略进行分布式训练时,是需要改动代码的(并非无缝一键切换),而且tf提供的模型训练API并不是对这些策略都完全支持,详见官方文档—策略类型:
| 训练 API | MirroredStrategy | TPUStrategy | MultiWorkerMirroredStrategy | CentralStorageStrategy | ParameterServerStrategy |
|---|---|---|---|---|---|
| Keras API | 支持 | 支持 | 实验性支持 | 实验性支持 | 计划于 2.3 后支持 |
| 自定义训练循环 | 支持 | 支持 | 实验性支持 | 实验性支持 | 计划于 2.3 后支持 |
| Estimator API | 有限支持 | 不支持 | 有限支持 | 有限支持 | 有限支持 |
下面,简单介绍下各个策略的模式:
MirroredStrategy
支持单机多gpu同步的分布式训练,默认使用 NVIDIA NCCL 作为all reduce实现。
TPUStrategy
支持谷歌TPU设备的策略(TPU 是 Google 的专用 ASIC,旨在显著加速机器学习工作负载)
MultiWorkerMirroredStrategy
与 MirroredStrategy 非常相似。它实现了跨多个工作进程的同步分布式训练,而每个工作进程可能有多个 GPU。简单来说,多机分布式通常使用的就是这个策略。该策略支持3种不同的collective communication模式:
CollectiveCommunication.RINGCollectiveCommunication.NCCLCollectiveCommunication.AUTO
RING模式将使用gRPC用于基于环的collective通信;而NCCL模式则是使用基于NVIDIA 的 NCCL来实现;AUTO模式则是在运行时自动选择。
CentralStorageStrategy
执行同步训练,参数变量不会被镜像,而是放在 CPU 上,且运算会复制到所有本地 GPU 。如果只有一个 GPU,则所有变量和运算都将被放在该 GPU 上。
ParameterServerStrategy
在多台机器上进行参数服务器训练,和MultiWorkerMirroredStrategy类似,可用于多机分布式训练。改策略下,一些机器被指定作为工作节点,一些机器被指定为参数服务器,模型的每个变量都会被放在参数服务器上。计算会被复制到所有工作进程的所有 GPU 中。注:该策略仅适用于 Estimator API。
分布式示例
下面,我们以TensorFlow官方仓库里的ResNet50的分布式训练为例,简单讲解下TensorFlow分布式训练相关方法和参数。
分布式策略
首先,分布式训练的入口为classifier_trainer.py,我们在classifier_trainer.py第301行看到定义了分布式策略strategy。
第301行:
strategy = strategy_override or distribution_utils.get_distribution_strategy(distribution_strategy=params.runtime.distribution_strategy,all_reduce_alg=params.runtime.all_reduce_alg,num_gpus=params.runtime.num_gpus,tpu_address=params.runtime.tpu)
分布式策略相关的参数如num_gpus、distribution_strategy等会传递到get_distribution_strategy(),该方法内部(distribution_utils.py第127行)生成各种策略实例,如:
- tf.distribute.experimental.TPUStrategy
- tf.distribute.OneDeviceStrategy
- tf.distribute.experimental.MultiWorkerMirroredStrategy
- tf.distribute.MirroredStrategy
- tf.distribute.experimental.ParameterServerStrategy
第127行:
if distribution_strategy == "tpu":# When tpu_address is an empty string, we communicate with local TPUs.cluster_resolver = tpu_lib.tpu_initialize(tpu_address)return tf.distribute.experimental.TPUStrategy(cluster_resolver)if distribution_strategy == "multi_worker_mirrored":return tf.distribute.experimental.MultiWorkerMirroredStrategy(communication=_collective_communication(all_reduce_alg))if distribution_strategy == "one_device":if num_gpus == 0:return tf.distribute.OneDeviceStrategy("device:CPU:0")if num_gpus > 1:raise ValueError("`OneDeviceStrategy` can not be used for more than ""one device.")return tf.distribute.OneDeviceStrategy("device:GPU:0")if distribution_strategy == "mirrored":if num_gpus == 0:devices = ["device:CPU:0"]else:devices = ["device:GPU:%d" % i for i in range(num_gpus)]return tf.distribute.MirroredStrategy(devices=devices,cross_device_ops=_mirrored_cross_device_ops(all_reduce_alg, num_packs))if distribution_strategy == "parameter_server":return tf.distribute.experimental.ParameterServerStrategy()raise ValueError("Unrecognized Distribution Strategy: %r" % distribution_strategy)
之后,在classifier_trainer.py第301行处,将生成的策略传递给变量strategy
数据加载
首先,在117行处,使用官方dataset_factory.DatasetBuilder接口构建出用于数据加载的训练集和验证集的builder,然后在第316行处builder根据分布式策略对数据进行切分,生成分布式训练可用数据集。
第316行:
datasets = [builder.build(strategy)if builder else None for builder in builders]
之后,通过model.compile(353行)将optimizer等参数编译到keras定义的resnet50-model上;加上训练集dataset、callback(回调函数)等一系列参数后,通过model.fit执行模型训练(386行)。
- 完整的利用ResNet50训练ImageNet的示例可参考:TensorFlow官方仓库
- 分布式训练速度测评及结果,可以参考DLPerf:【DLPerf】TensorFlow 2.x-ResNet50V1.5测评
5.OneFlow
概念
和以上主流深度学习框架不同,OneFlow作为一个新颖的深度学习框架,对性能和分布式训练有着执着的追求。OneFlow支持数据并行和模型并行,与其他框架的不同之处在于其架构设计并非传统的master/worker架构,而是一种去中心化的流式架构,而这种架构带来的优势也比较明显:
- 采用去中心化的流式架构,而非
maste/worker架构,最大程度优化节点网络通信效率 - 提供
consistent view,整个节点网络中只需要逻辑上唯一的输入与输出 - 提供兼容其它框架的
mirrored view,熟悉其它框架分布式训练的用户可直接上手 - 极简配置,由单一节点的训练程序转变为分布式训练程序,只需要几行配置代码
OneFlow的去中心化是由Actor机制实现,Actor机制和SBP的设计加上对设备ConsistentView的抽象,使得OneFlow中的分布式训练实现起来异常高效,在几大主流框架中几个经典模型的测试中,实现了单卡速度最快、多机多卡加速比最高。但对于上层用户,使用oneflow进行分布式进行却异常简单,实际上,在oneflow中无需改动原有代码,只需要简单的几行配置,即可完美支持分布式训练:
#每个节点的gpu使用数目
flow.config.gpu_device_num(8)
#通信端口
flow.env.ctrl_port(9988)
#节点配置
nodes = [{"addr":"192.168.1.12"}, {"addr":"192.168.1.11"}]
flow.env.machine(nodes)
此外,在多机的网络通信部分,OneFlow 底层的网络通信库原生支持 RDMA 的高性能通信,也有一套基于 epoll 的高效通信设计,且OneFlow编译时自带nccl(静态编译),用户无需手动下载设置,安装oneflow后可直接支持分布式。
更多OneFlow相关的系统概念和设计请参考:
- OneFlow官方文档—分布式训练
- OneFlow官方文档—系统设计
分布式示例
在对比多个框架的分布式用法后,我们发现OneFlow的分布式最简单易用,因为其设计的出发点就是追求分布式性能及易用性。所以,在OneFlow中,无论是单机单卡、单机多卡、还是多机多卡,都是一套统一的代码(无需额外的分布式接口、无需修改原有的模型训练相关代码)。话不多说,示例如下:
1.单机
只需要在开头,加入单机需使用的GPU数即可。如:
单机1卡:
flow.config.gpu_device_num(1)
单机8卡:
flow.config.gpu_device_num(8)
2.分布式
分布式几乎和单机配置一样,无需操心多机情况下的数据切分,optimizer设置、权重同步等问题,只需额外增加3行代码用于配置多机的ip信息、通信端口号即可:
#每个节点的 gpu 使用数目
flow.config.gpu_device_num(8)
# 通信节点ip
nodes = [{"addr":"192.168.1.12"}, {"addr":"192.168.1.11"}]
flow.env.machine(nodes)
#通信端口
flow.env.ctrl_port(9988)
以下,是完整的分布式训练代码示例:
# see : http://docs.oneflow.org/basics_topics/distributed_train.html#_5
import oneflow as flow
import oneflow.typing as tpBATCH_SIZE = 100def mlp(data):initializer = flow.truncated_normal(0.1)reshape = flow.reshape(data, [data.shape[0], -1])hidden = flow.layers.dense(reshape,512,activation=flow.nn.relu,kernel_initializer=initializer,name="hidden",)return flow.layers.dense(hidden, 10, kernel_initializer=initializer, name="output-weight")def config_distributed():print("distributed config")# 每个节点的gpu使用数目flow.config.gpu_device_num(8)# 通信端口flow.env.ctrl_port(9988)# 节点配置nodes = [{"addr": "192.168.1.12"}, {"addr": "192.168.1.11"}]flow.env.machine(nodes)@flow.global_function(type="train")
def train_job(images: tp.Numpy.Placeholder((BATCH_SIZE, 1, 28, 28), dtype=flow.float),labels: tp.Numpy.Placeholder((BATCH_SIZE,), dtype=flow.int32),
) -> tp.Numpy:logits = mlp(images)loss = flow.nn.sparse_softmax_cross_entropy_with_logits(labels, logits, name="softmax_loss")lr_scheduler = flow.optimizer.PiecewiseConstantScheduler([], [0.1])flow.optimizer.SGD(lr_scheduler, momentum=0).minimize(loss)return lossif __name__ == "__main__":config_distributed()flow.config.enable_debug_mode(True)check_point = flow.train.CheckPoint()check_point.init()(train_images, train_labels), (test_images, test_labels) = flow.data.load_mnist(BATCH_SIZE, BATCH_SIZE)for epoch in range(1):for i, (images, labels) in enumerate(zip(train_images, train_labels)):loss = train_job(images, labels)if i % 20 == 0:print(loss.mean())
- 完整的利用ResNet50训练ImageNet的示例可参考:OneFlow官方Benchmark仓库
- 分布式训练速度测评及结果,可以参考DLPerf:【DLPerf】OneFlow Benchmark评测
2.DLPerf踩坑经验汇总
2.1 精确到commit
首先,各个框架存在不同版本;其次,项目代码也在不断维护和更新,我们需要复现一个项目,首先需要熟读项目的readme,然后精确地匹配到对应的commit,保证代码版本和框架版本相匹配,才能将由于代码/框架版本不匹配导致各种问题的概率降至最低。
2.2 多机问题
多机情况下常见的问题:
2.2.1 horovod/mpi多机运行失败
无论是在物理机还是nvidia-ngc容器中,要运行horovod/mpi,都需要提前在节点之间配置ssh免密登录,保证用于通信的端口可以互相连通。
如:
# export PORT=10001
horovodrun -np ${gpu_num} \
-H ${node_ip} -p ${PORT} \
--start-timeout 600 \
python3 train.py ${CMD} 2>&1 | tee ${log_file}# 或者:
mpirun --allow-run-as-root -oversubscribe -np ${gpu_num} -H ${node_ip} \-bind-to none -map-by slot \-x LD_LIBRARY_PATH -x PATH \-mca pml ob1 -mca btl ^openib \-mca plm_rsh_args "-p ${PORT} -q -o StrictHostKeyChecking=no" \-mca btl_tcp_if_include ib0 \python3 train.py ${CMD} 2>&1 | tee ${log_file}
需要保证节点间ssh可以通过端口10001互相连通
2.2.2 docker容器连通问题
如果是在docker容器中进行多机训练,需要保证docker容器间可以通过指定端口互相ssh免密登录。(如:在10.11.0.2节点的docker容器内可以通过ssh root@10.11.0.3 -p 10001可以直接登录10.11.0.3节点的docker容器)
而在docker容器里,有两种实现方式:
- docker的host模式
- docker的bridge模式
docker的host模式
host模式,需要通过docker run时添加参数 --net=host 指定,该模式下表示容器和物理机共用端口(没有隔离),需要修改容器内ssh服务的通信端口号(vim /etc/ssh/sshd_config),用于docker容器多机通讯,具体方式见:README—SSH配置
docker的bridge模式
即docker的默认模式。该模式下,容器内部和物理机的端口是隔离的,可以通过docker run时增加参数如:-v 9000:9000进行端口映射,表明物理机9000端口映射到容器内9000端口,docker容器多机时即可指定9000端口进行通信。
两种方式都可以,只要保证docker容器间能通过指定端口互相ssh免密登录即可。
2.2.3 多机没连通/长时间卡住没反应
- 通信库没有正确安装
- 存在虚拟网卡,nccl需指定网卡类型
通信库没有正确安装
通常是没有正确地安装多机依赖的通信库(openmpi、nccl)所导致。譬如paddle、tensorflow2.x等框架依赖nccl,则需要在每个机器节点上安装版本一致的nccl,多机训练时,可以通过export NCCL_DEBUG=INFO来查看nccl的日志输出。
openmpi安装
官网:https://www.open-mpi.org/software/ompi/v4.0/
wget https://download.open-mpi.org/release/open-mpi/v4.0/openmpi-4.0.0.tar.gz
gunzip -c openmpi-4.0.0.tar.gz | tar xf -
cd openmpi-4.0.0
sudo ./configure --prefix=/usr/local/openmpi --with-cuda=/usr/local/cuda-10.2 --enable-orterun-prefix-by-default
sudo make && make install
make时,若报错numa相关的.so找不到:
sudo apt-get install libnuma-dev
添加到环境变量
vim ~/.bashrc
export PATH=$PATH:/usr/local/openmpi/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/openmpi/lib
source ~/.bashrc
horovod安装
官网:https://github.com/horovod/horovod
HOROVOD_GPU_OPERATIONS=NCCL python -m pip install --no-cache-dir horovod
存在虚拟网卡,nccl需指定网卡类型
有时,nccl已经正常安装,且节点间可以正常ssh免密登录,且都能互相ping通,不过还是遭遇多机训练长时间卡住的问题,可能是虚拟网卡的问题,当存在虚拟网卡时,如果不指定nccl变量,则多机通信时可能会走虚拟网卡,而导致多机不通的问题。
如下图:
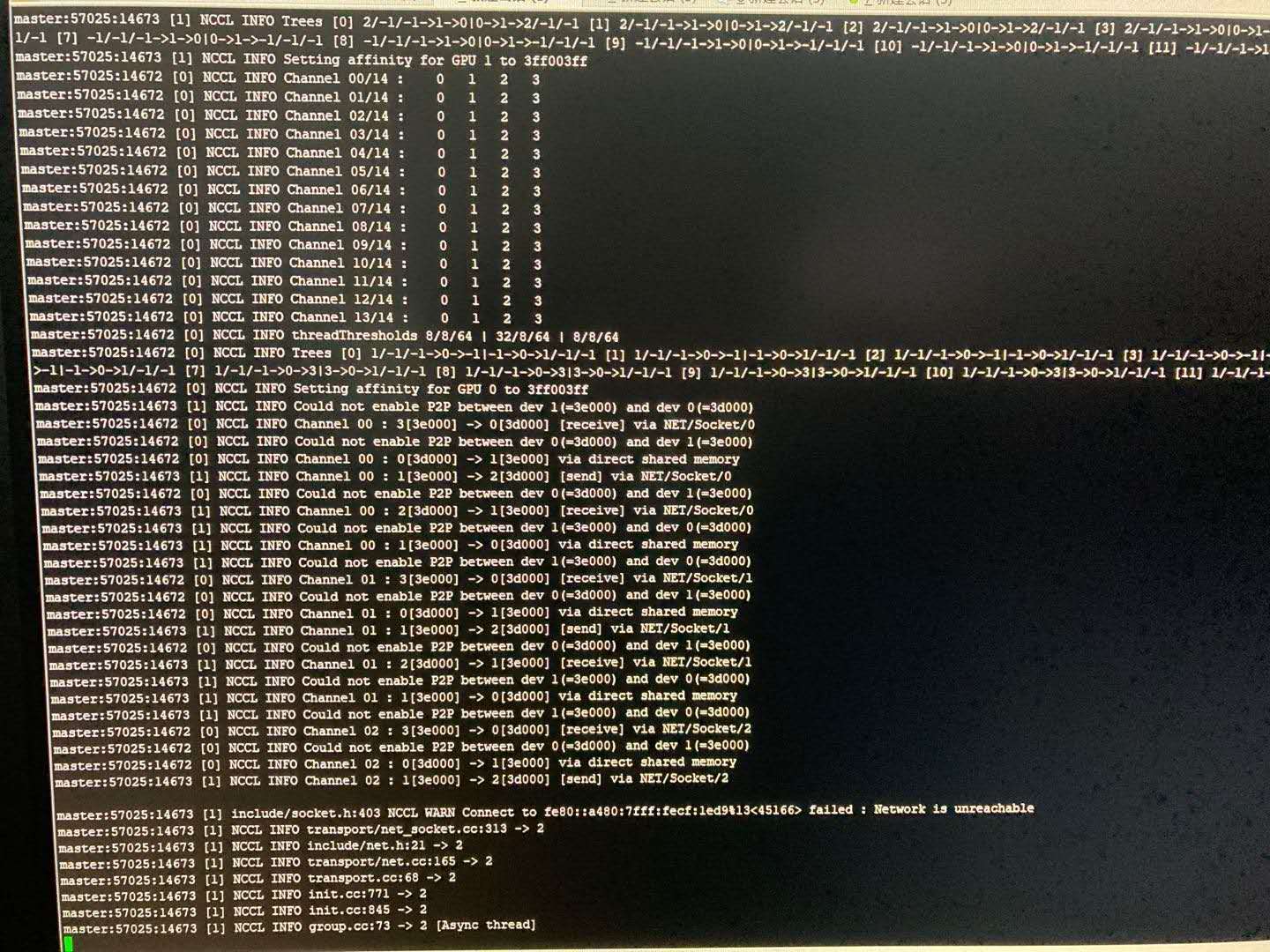
NCCL WARN Connect to fe80::a480:7fff:fecf:1ed9%13<45166> failed : Network is unreachable表明多机下遭遇了网络不能连通的问题。具体地,是经过网卡:fe80::a480:7fff:fecf…通信时不能连通。
我们排查时,通过在发送端ping一个较大的数据包(如ping -s 10240 10.11.0.4),接收端通过bwm-ng命令查看每个网卡的流量波动情况(找出ping相应ip时,各个网卡的流量情况),发现可以正常连通,且流量走的是enp类型的网卡。
通过ifconfig查看当前节点中的所有网卡类型:

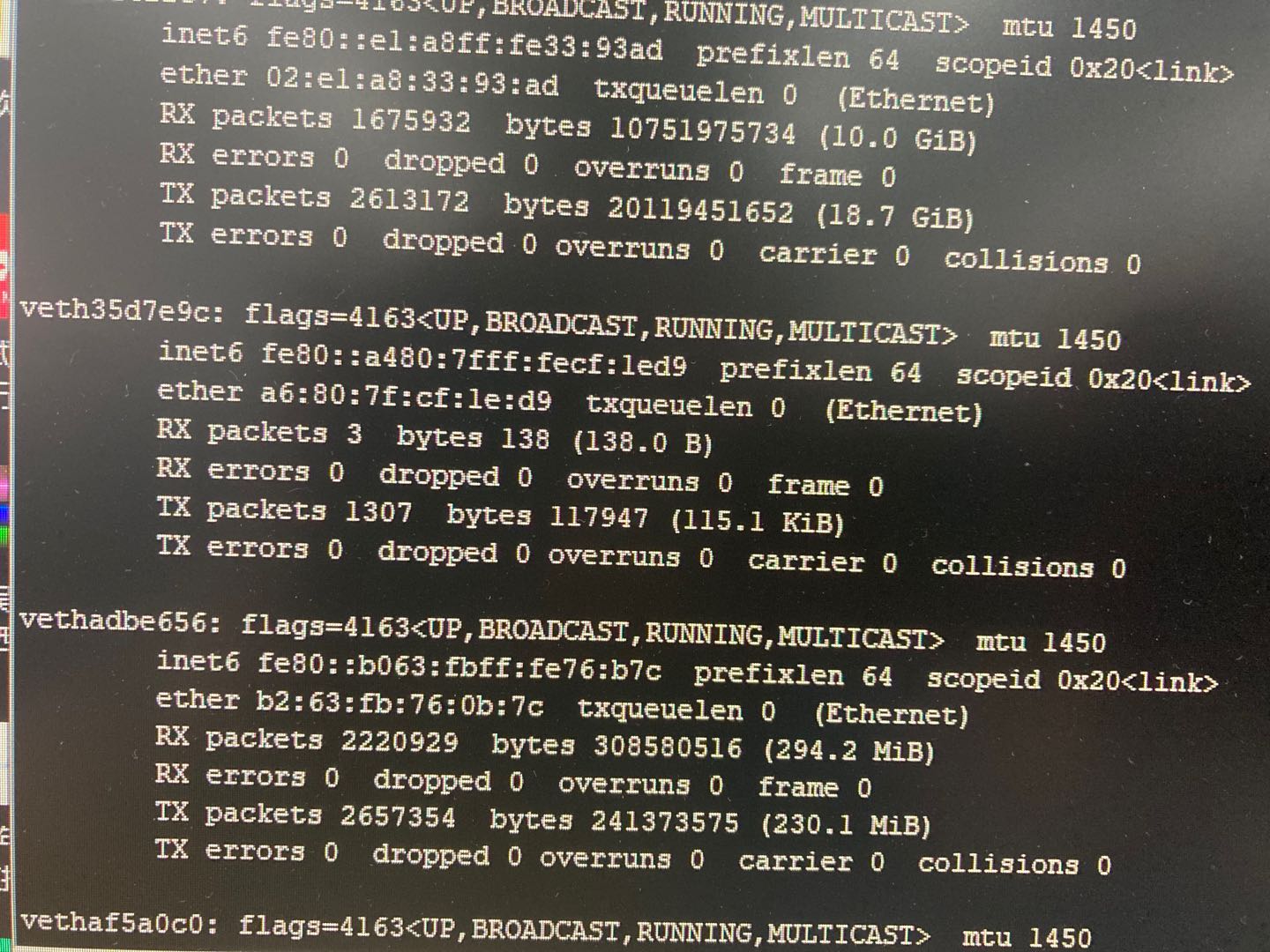
可以发现有很多enp开头的网卡,也有很多veth开头的虚拟网卡,而nccl日志输出中的:fe80::a480:7fff:fecf:1ed9是veth虚拟网卡。
通过查看nccl官网文档发现,我们可以通过指定nccl变量来设定nccl通信使用的网卡类型:
export NCCL_SOCKET_IFNAME=enp
2.3加速比低
- 没安装IB驱动
- horovod参数设置
- 没有使用dali
- 数据读取线程数设置不合理
3.其他分享
3.1 查看GPU拓扑
nvidia-smi topo -m
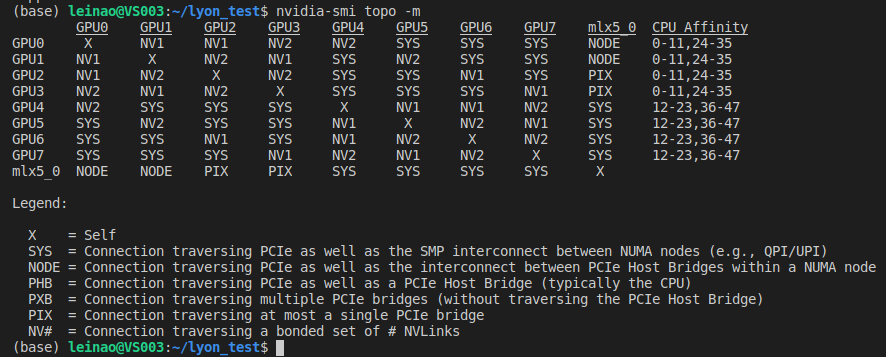
可以看出,此台机器包含8块GPU(GPU0~7),mlx5_0是Mellanox ConnectX-4 PCIe网卡设备(10/25/40/50千兆以太网适配器,另外该公司是IBA芯片的主要厂商)。图的上半部分表示GPU间的连接方式,如gpu1和gpu0通过NV1互联,gpu4和gpu1通过SYS互联;图的下半部分为连接方式的具体说明,如NV表示通过nvlink互联,PIX通过至多一个PCIe网桥互联。
在图的下半部分,理论上GPU间的连接速度从上到下依次加快,最底层的NV表示通过nvlink互联,速度最快;最上层SYS表示通过pcie以及穿过NUMA节点间的SMP互联(即走了PCie又走了QPI总线),速度最慢。
- NV表示通过nvidia-nvlink互联,速度最快;
- PIX表示GPU间至多通过一个PCIe网桥连接;
- PHB表示通过PCIe和PCIe主网桥连接(通常PCIe 主网桥是存在于cpu之中,所以PHB可以理解为通过PCIe和cpu相连);
- NODE表示通过PCIe以及NUMA节点内PCIe主网桥之间的互连(通常NUMA节点内,包含多个cpu节点,每个cpu节点都包含一个PCIe主网桥,所以NODE可以理解为在一个NUMA节点内,通过PCIe和多个CPU相连);
- SYS表示通过PCIe以及NUMA节点之间的SMP互连(例如,QPI/UPI),这个可以理解为通过PCIe,且跨过多个NUMA节点及其内部的SMP(多个cpu节点)进行互联。
- X表示gpu节点自身;
关于NUMA,SMP等服务器结构的简单介绍可参考:服务器体系(SMP, NUMA, MPP)与共享存储器架构(UMA和NUMA)
3.2 NCCL
- 知乎:如何理解Nvidia英伟达的Multi-GPU多卡通信框架NCCL?
- 知乎:使用NCCL进行NVIDIA GPU卡之间的通信
- NCCL官方文档——故障排除
- NCCL官方文档——环境变量
【深度学习】— 各框架分布式训练简介+测评相关推荐
- AI学习笔记(九)从零开始训练神经网络、深度学习开源框架
AI学习笔记之从零开始训练神经网络.深度学习开源框架 从零开始训练神经网络 构建网络的基本框架 启动训练网络并测试数据 深度学习开源框架 深度学习框架 组件--张量 组件--基于张量的各种操作 组件- ...
- 【github干货】主流深度学习开源框架从入门到熟练
文章首发于微信公众号<有三AI> [github干货]主流深度学习开源框架从入门到熟练 今天送上有三AI学院第一个github项目 01项目背景 目前深度学习框架呈百家争鸣之态势,光是为人 ...
- 斯坦福CS231n 2017最新课程:李飞飞详解深度学习的框架实现与对比
斯坦福CS231n 2017最新课程:李飞飞详解深度学习的框架实现与对比 By ZhuZhiboSmith2017年6月19日 13:37 斯坦福大学的课程 CS231n (Convolutio ...
- 【完结】12大深度学习开源框架(caffe,tf,pytorch,mxnet等)快速入门项目
这是一篇总结文,给大家来捋清楚12大深度学习开源框架的快速入门,这是有三AI的GitHub项目,欢迎大家star/fork. https://github.com/longpeng2008/yousa ...
- 【完结】给新手的12大深度学习开源框架快速入门项目
文/编辑 | 言有三 这是一篇总结文,给大家来捋清楚12大深度学习开源框架的快速入门,这是有三AI的GitHub项目,欢迎大家star/fork. https://github.com/longpen ...
- Euler 今日问世!国内首个工业级的图深度学习开源框架,阿里妈妈造
千呼万唤始出来!阿里妈妈正式公布重磅开源项目--图深度学习框架Euler.这是国内首个在核心业务大规模应用后开源的图深度学习框架.此次开源,Euler内置了大量的算法供用户直接使用,相关代码已经可在G ...
- 12大深度学习开源框架(caffe,tensorflow,pytorch,mxnet等)汇总详解
这是一篇总结文,给大家来捋清楚12大深度学习开源框架的快速入门,这是有三AI的GitHub项目,欢迎大家star/fork. https://github.com/longpeng2008/yousa ...
- TIP 2021 | 重访CV经典!首个无监督深度学习图像拼接框架
点击下方卡片,关注"CVer"公众号 AI/CV重磅干货,第一时间送达 作者:廖康 | 已授权转载(源:知乎) https://zhuanlan.zhihu.com/p/386 ...
- 人机交互系统(2.1)——深度学习分布式计算框架
1 为什么需要分布式计算? 在这个数据爆炸的时代,产生的数据量不断地在攀升,从GB,TB,PB到ZB.挖掘其中数据的价值也是企业在不断地追求的终极目标.但是要想对海量的数据进行挖掘,首先要考虑的就是海 ...
最新文章
- 策略模式——Strategy
- Linux cached过高问题
- 每天一道LeetCode-----摩尔投票法寻找给定数组中出现个数大于n/2或n/3的元素
- Python脚本监控线上AMQ Number of Pending Messages数量
- Angular里的style property binding的一个例子
- Spring Cloud Alibaba —— Seata 分布式事务框架
- Java实现学生管理系统(完整代码)
- 调用http_【学习充电】直观讲解一下 RPC 调用和 HTTP 调用的区别!
- 9.linux ntp服务器搭建
- 简单帅气的折纸机器人_新型电磁喷雾可将任何物体变成机器人,有望在生物学领域应用...
- IntelliJ IDEA中使用sonar插件,忽略规则和重启规则
- floodlight路由机制分析
- redis如何设置密码
- android launcher启动过程,Android应用启动过程-Launcher源码浅析
- 爬虫技术(04)神箭手爬虫field的属性
- spring boot 运行提示:Process finished with exit code 1
- 服务器如何通过域共享文件夹,如何在域中共享文件夹
- 【逆向】Android App soul api-sign算法分析
- Pytorch混合精度训练
- 安装好kali后必做的5件事