文本生成评价指标串串烧
1. 前言
语言与图像,作为当前AI领域的两大热门方向,吸引了无数研究人员的目光。相比于图像,语言有简单易得,数据易于收取,存储空间低等优点,不过,由于语言本身的特性,他还有时序复杂,句式多变等缺点,带来的后果就是相比于CV领域的迅猛发展,nlp的发展好像差了点意思。不过,随之近年来以transformer为开端的技术的发展,nlp也迎来了自己的大发展,尤其是随着1700亿参数的GPT-3的开源,其生成的文本的质量达到了惊人的地步(缺陷就是,该模型太大了,远非一般公司所能承受)。这就引出了我们想讨论的内容,即如何判定文本生成的质量呢?毕竟,一个好的评价指标(或者设置合理的损失函数)不仅能够高效的指导模型拟合数据分布,还能够客观的让人评估文本生成模型的质量,从而进一步推动text generation 商业化能力。
接下来,让我们走进文本生成评价指标的世界,看看哪些指标可以有效反映文本生成的质量。
2. 指标分类
2.1 基于词重叠的方法
该类方法基于词汇的级别计算模型的生成文本和人工的参考文本之间的相似性,其中,最具影响力的的便是BLEU、METEOR和ROUGE,前两者常用于机器翻译任务,后者则常用于自动文本摘要。
2.1.1 BLEU
BLEU (Bilingual Evaluation Understudy,双语评估辅助工具),来源于IBM,它可以说是所有评价指标的鼻祖,其核心思想是比较候选译文和参考译文里的 n-gram 的重合程度,重合程度越高就认为译文质量越高。unigram用于衡量单词翻译的准确性,而其他 n-gram 表示翻译的流畅性。实践中,通常是取N=1~4,然后对进行加权平均,其计算公式为:

公式Pn指n-gram的精确率
Wn为n-gram的权重,一般设为1/N,即均匀权重
BP为惩罚因子,公式表明,针对翻译出来的短句子,BP会小于1,从而起到对短句子的惩罚作用
改进的多元精度(n-gram precision)
上面BLEU是改进后的,其原始形式只考虑1-gram,这会导致***常用词干扰***问题,如on,the这类词,如下面的例子
| 常用词干扰句子 | cat a on is the table |
|---|---|
| candidate | a cat is on the table |
| ref | there is a cat on the table |
表1 原句与翻译
计算其n-gram:
| N | 精度 |
|---|---|
| 1 | 1-gram为6.即candidate的每个单词,均在ref中,因而P1=1;同理可得干扰句子的P1也为1 |
| 2 | candidate:(a cat, 在),(cat is, 不在),(is on,不在),(on the,在),(the table,在),因而其P2=3/5; 同理得干扰句子为2/3 |
| 3 | candidate:(a cat is,不在),(cat is on,不在),(is on the,不在),(one the table,在),因而其P3=1/4;同理得干扰句子为0 |
显然,只使用1-gram的话,两个翻译结果都为1,而这显然是不正确的;使用改进的多元精度(n-gram precision)后,candidate为1.85,干扰句子为1.66,从而得到candidate更好的结论。
上面的Pn我们采用了直接计数的方式,其实这种方式还是有问题,比如上面的干扰句子,其内部有两个on和the,而ref中只有1个,所以实际使用时对Pn计数使用如下公式:

这样处理以后,干扰句子的P1就降为了1/2,也起到了削弱干扰句子的作用。
惩罚因子
使用改进的多元精度以后,问题并没有完全消除,考虑下面的句子:
| 类型 | 内容 |
|---|---|
| candidate | a cat |
| Ref | there is a cat on the table |
这个句子的P1=1,P2=1,显然其得分会很高,而实际上,该句子是不正确的,其原因便是candidate句子过短,n-gram较少,而交集高,这个翻译是存在很多信息丢失的,这种情况下,就到了惩罚因子发挥作用的时候了,在惩罚因子作用下,其得分变为原来的exp(1-7/2)倍,说明其与原文的相似度得到了降低。
上面说了那么多,总结一下BLEU,优点很明显:方便、快速,(毕竟只要计数就行了)结果有参考价值;而其缺点也很 明显:
- 不考虑语言表达(语法)上的准确性;
2. 不能很好地处理形态丰富的语句(BLEU原文建议大家配备4条翻译参考译文); - 短译句的测评精度有时会较高(惩罚因子表示臣妾已经尽力了 …);
- 没有考虑同义词或相似表达的情况,可能会导致合理翻译被否定;
2.1.2 ROUGE
ROUGE(Recall-Oriented Understudy for Gisting Evaluation),可以看做是BLEU 的改进版,专注于召回率而非精度。换句话说,它会查看有多少个参考译句中的 n 元词组出现在了输出之中,从其特点可以看出,这个指标适用的场景为NMT,因为它并不关系流畅度,而传统的SMT则需要同时考虑准确度和流畅度。
从使用上来说,目前的ROUGE可以大致分为4类:
ROUGE-N (将BLEU的精确率优化为召回率)
后缀N指的是N-gram,计算形式类似于BLEU,不同之处在于ROUGE关注召回率而不是精确率,它召回的对象便是N-gram。
计算公式如下:

公式的分母是统计在参考译文中 N-gram 的个数,而分子是统计参考译文与机器译文共有的 N-gram 个数。
仍以表1说明其计算方法:
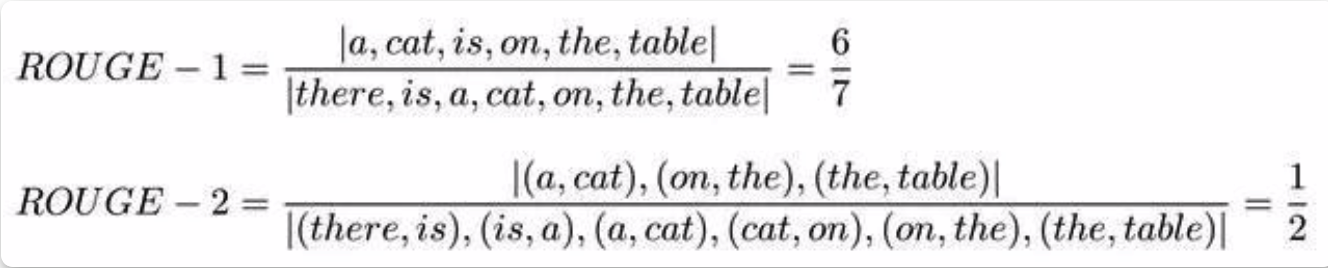
针对多个参考译文,最终的ROUGE分数为计算机译文和这些参考译文的 ROUGE-N 分数的最大值,计算方式为:
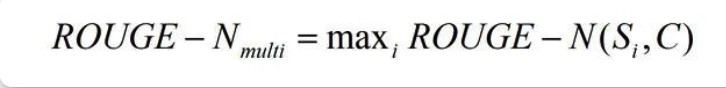
ROUGE-L (将BLEU的n-gram优化为公共子序列)
后缀L代表最长公共子序列(longest common subsequence, LCS),见名知义,它统计的是机器译文C和参考译文S的最长公共子序列,计算公式为:
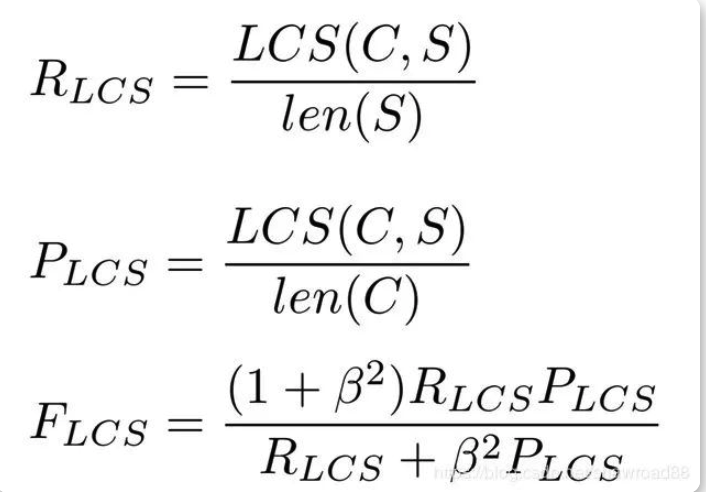
公式中的 RLCS 表示召回率,而 PLCS 表示精确率,FLCS 就是 ROUGE-L。一般 beta 会设置为很大的数,因此 FLCS 几乎只考虑了 RLCS (即召回率)。注意这里 beta 大,则 F 会更加关注 R,而不是 P,可以看下面的公式。如果 beta 很大,则 PLCS 那一项可以忽略不计。这个指标其实参照了F-score的思想。
ROUGE-W (将ROUGE-L的连续匹配给予更高的奖励)
从括号中解释便可以看出,该指标是ROUGE-L的改进版,其思想来源于下面的事实:

对上面的参考译文X,Y1和Y2的ROUGE-L是一样的,而从连续性角度来说,明显Y1的翻译质量更高,合理的做法是给予Y1更高的分数。
ROUGE-S (允许n-gram出现跳词(skip))
该指标针对的对象也是N-gram,不过其特点是采用的 N-gram 允许"跳词 (Skip)",即跳跃二元组(skip bigram)。例如句子 “I have a cat” 的 Skip 2-gram 包括 (I, have),(I, a),(I, cat),(have, a),(have, cat),(a, cat)。
跳跃二元组是句子中有序的单词对,和LCS类似,在单词对之间,单词可能被跳过。比如一句有4个单词的句子,按照排列组合就可能有6种跳跃二元组。
再次使用精度和召回率来计算F,将句子Sij中跳跃二元组的个数记为:
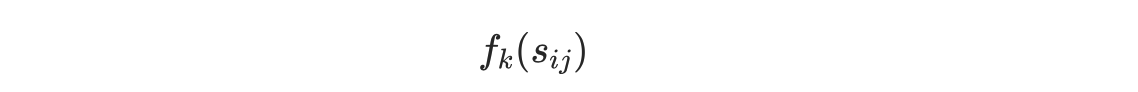
则计算公式为:
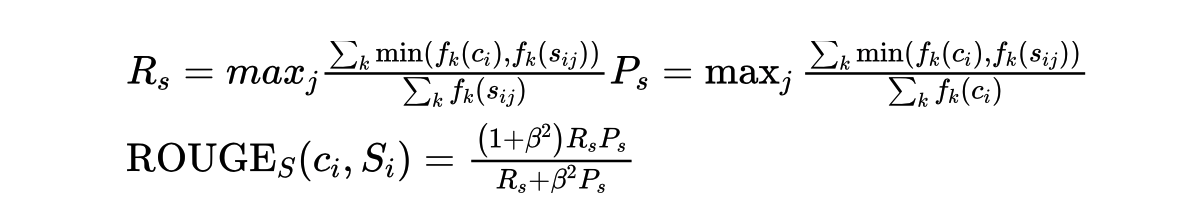
2.1.3 NIST
NIST(National Institute of standards and Technology),该方法也是针对BLEU的一个改进,它最大的特点就是引入了每个N-gram的信息量(information)概念,不同于BLEU简单对N-gram的计数,NIST是信息量之和与译文N-gram数目之商,它起到的作用就是将一些出现少的重点的词权重就给的大了。
计算公式:
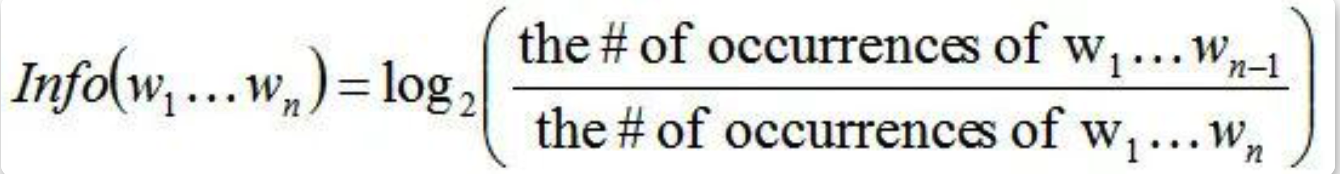
分母是n元词在参考译文中出现的次数,分子是对应的n-1元词在参考译文中的出现次数。对于一元词汇,分子的取值就是整个参考译文的长度。这里之所以这样算,应该是考虑到出现次数少的就是重点词这样的一个思路。
计算信息量之后,就可以对每一个共现n元词乘以它的信息量权重,再进行加权求平均得出最后的评分结果:
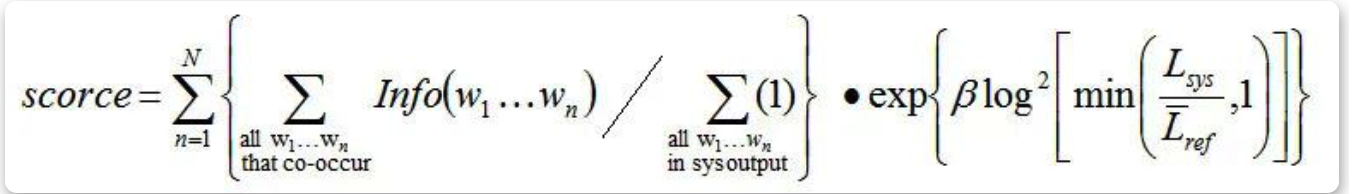
注意:
N一般取5
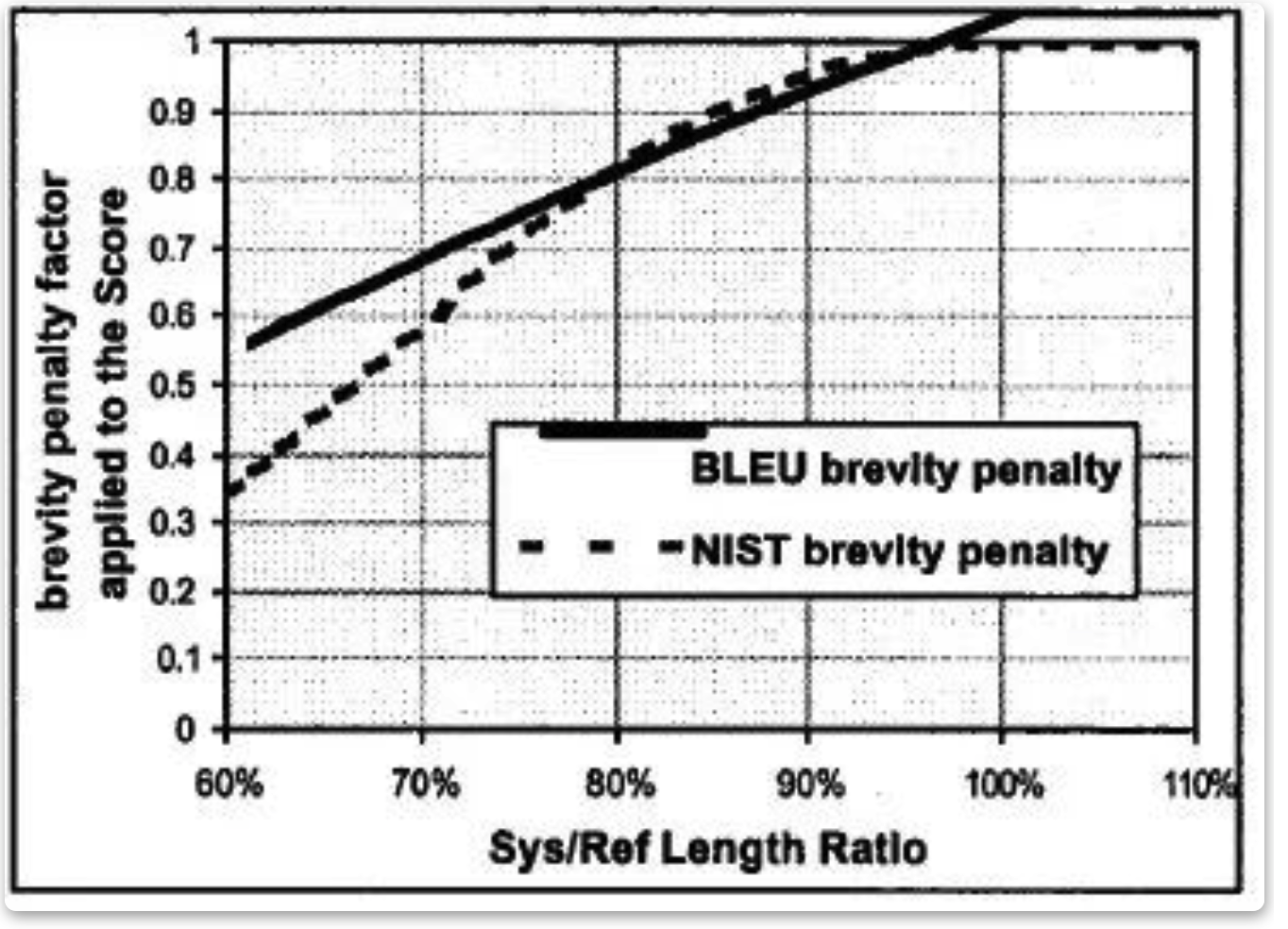
β是一个常数,在Lsys/Lref=2/3 时,β使得长度罚分率为0.5,它是个经验值,大概的曲线是:
Lref 是参考答案的平均长度(注意L的上方有一个平均符号)
Lsys是译文的长度
2.1.4 METEOR
METEOR于2004年由Lavir发现在评价指标中召回率的意义后提出,他们的研究表明,召回率基础上的标准相比于那些单纯基于精度的标准(如BLEU),其结果和人工判断的结果有较高相关性。METEOR测度基于单精度的加权调和平均数和单字召回率,其目的是解决一些BLEU标准中固有的缺陷。
METEOR也包括其他指标没有发现一些其他功能,如同义词匹配等。METEOR用 WordNet 等知识源扩充了一下同义词集,同时考虑了单词的词形(词干相同的词也认为是部分匹配的,也应该给予一定的奖励,比如说把 likes 翻译成了 like 总比翻译成别的乱七八糟的词要好吧?)
在评价句子流畅性的时候,用了 chunk 的概念(候选译文和参考译文能够对齐的、空间排列上连续的单词形成一个 chunk,这个对齐算法是一个有点复杂的启发式 beam serach),chunk 的数目越少意味着每个 chunk 的平均长度越长,也就是说候选译文和参考译文的语序越一致。
计算公式:
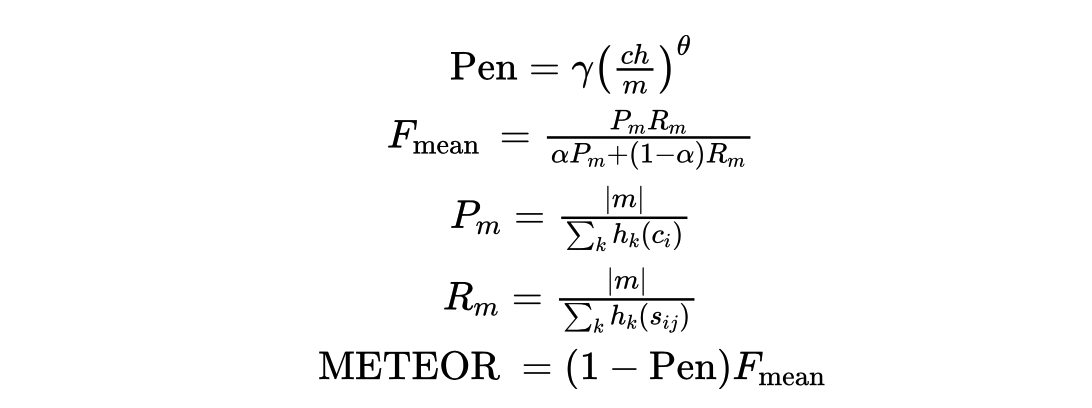
这个指标的计算非常复杂,所以我基本不用…
2.1.5 TER
TER(Translation Edit Rate), 也就是大名鼎鼎的编辑距离,刷题的小伙伴应该对此很熟悉,它是一种基于距离的评价方法,用来评定机器翻译结果的译后编辑的工作量。
这里,距离被定义为将一个序列转换成另一个序列所需要的最少编辑操作次数。操作次数越多,距离越大,序列之间的相似性越低;相反距离越小,表示一个句子越容易改写成另一个句子,序列之间的相似性越高。
TER 使用的编辑操作包括:增加、删除、替换和移位。其中增加、删除、替换操作计算得到的距离被称为编辑距离,并根据错误率的形式给出评分:
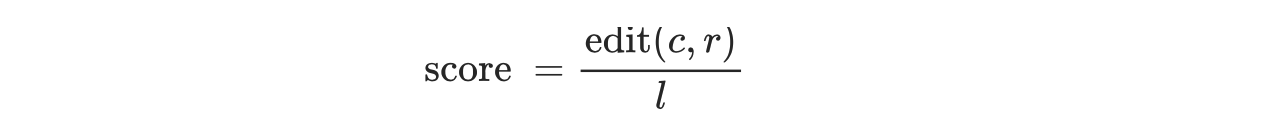
其中 edit(c,r) 是指机器翻译生成的候选译文 c 和参考译文 r 之间的距离,l 是归一化因子,通常为参考译文的长度。在距离计算中所有的操作的代价都为 1。在计算距离时,优先考虑移位操作,再计算编辑距离,也就是增加、删除和替换操作的次数。直到移位操作(参考文献中还有个增加操作,感觉是笔误了)无法减少编辑距离时,将编辑距离和移位操作的次数累加得到TER 计算的距离。
举个栗子:
candidate:cat is standing in the ground
ref:The cat is standing on the ground
将 Candidate 转换为 Reference,需要进行一次增加操作,在句首增加 “The”;一次替换操作,将 “in” 替换为 “on”。所以 edit(c, r) = 2,归一化因子 l 为 Reference 的长度 7,所以该参考译文的 TER 错误率为 2/7。
与 BLEU 不同,基于距离的评价方法是一种典型的 “错误率” 的度量,类似的思想也广泛应用于语音识别等领域。在机器翻译中,除了 TER 外,还有 WER,PER 等十分相似的方法,只是在 “错误” 的定义上略有不同。需要注意的是,很多时候,研究者并不会单独使用 BLEU 或者 TER,而是将两种方法融合,比如,使用 BLEU 与TER 相减后的值作为评价指标。
2.2 Image Caption常用指标
2.2.1 CIDEr
CIDEr 是专门设计出来用于图像标注问题的。这个指标将每个句子都看作“文档”,将其表示成 Term Frequency Inverse Document Frequency(tf-idf)向量的形式,通过对每个n元组进行(TF-IDF) 权重计算,计算参考 caption 与模型生成的 caption 的余弦相似度,来衡量图像标注的一致性的。
计算公式:

举例:
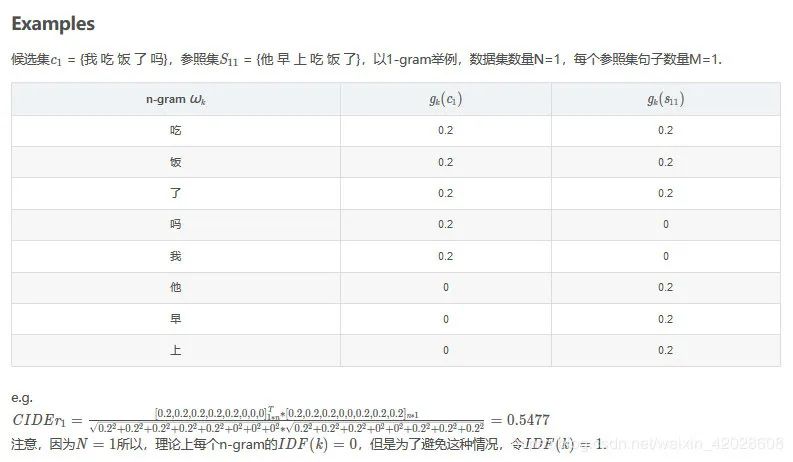
该指标是一种加权的评价指标,他更关注你是否说到了重点,而常见的词权重则没有那么高。在 Kaustav_slides image caption的综述里,也提到这个评价指标和人类的评价相关性更高一些。
2.2.2 SPICE
SPICE 也是专门设计出来用于 image caption 问题的。全称是 Semantic Propositional Image Caption Evaluation。
对如下图片:

你很快会发现尽管生成的句子与参考句极为相似(只有basketball一词不一样),但我们仍认为这是一个糟糕的生成。原因在于考虑了语义的情况下,模型把网球场错误的识别成了篮球场。这个时候BLEU或者其他指标就不能很好的评价生成效果了。
SPICE 使用基于图的语义表示来编码 caption 中的 objects, attributes 和 relationships。它先将待评价 caption 和参考 captions 用 Probabilistic Context-Free Grammar (PCFG) dependency parser parse 成 syntactic dependencies trees,然后用基于规则的方法把 dependency tree 映射成 scene graphs。最后计算待评价的 caption 中 objects, attributes 和 relationships 的 F-score 值。
还是已上图为例,a young girl standing on top of a tennis court (参考句) 可以被SPICE做如下处理:
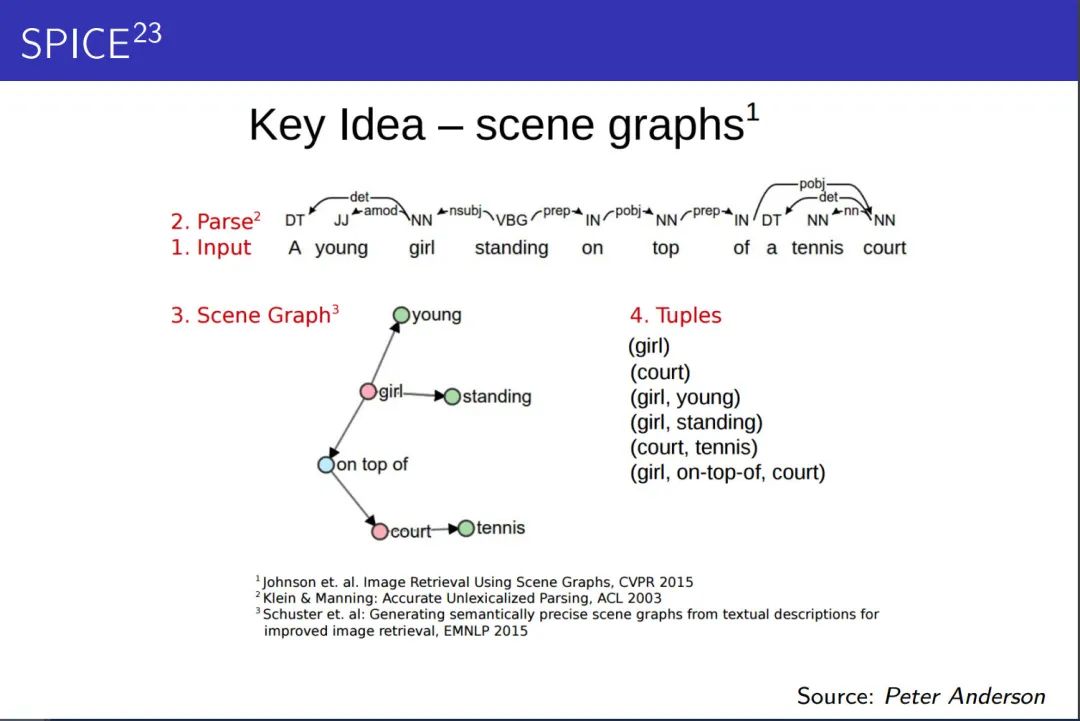
得到了若干个三元组之后,我们通过下面的公式来计算候选句c和参考句(或集合)S的得分:
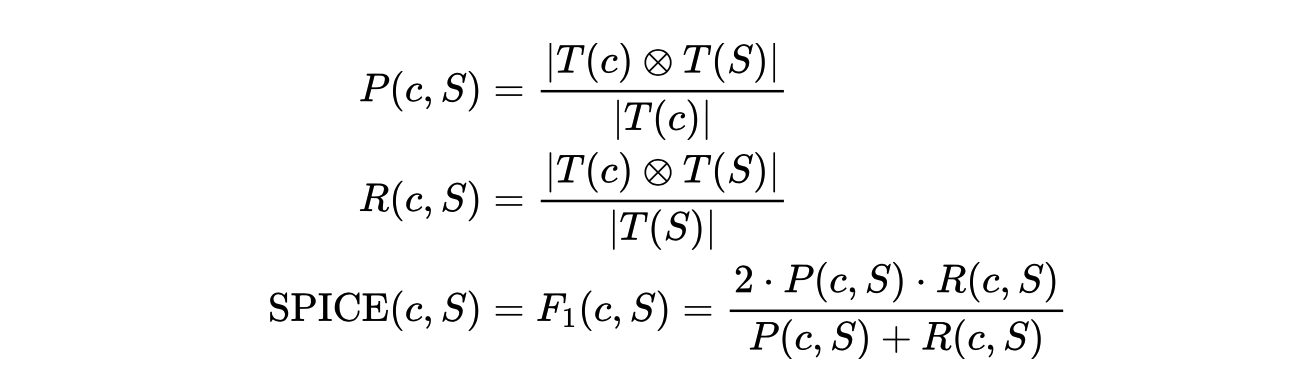
另一个栗子:

好处
- 对目标,属性,关系有更多的考虑;
- 和基于n-gram的评价模式相比,有更高的和人类评价的相关性
缺点
- 不考虑语法问题
- 依赖于semantic parsers , 但是他不总是对的
- 每个目标,属性,关系的权重都是一样的(一幅画的物体显然有主次之分)
2.3 词向量评价指标
上面的词重叠评价指标基本上都是n-gram方式,去计算生成响应和真是响应之间的重合程度,共现程度等指标。而词向量则是通过Word2Vec、Sent2Vec等方法将句子转换为向量表示,这样一个句子就被映射到一个低维空间,句向量在一定程度上表征了其含义,在通过余弦相似度等方法就可以计算两个句子之间的相似程度。
使用词向量的好处是,可以一定程度上增加答案的多样性,因为这里大多采用词语相似度进行表征,相比词重叠中要求出现完全相同的词语,限制降低了很多。
这种指标看起来挺美好,不是现实中很少见到有人用该指标来评价模型好坏,更多的人则是直接使用预训练词向量做初始化。
2.3.1 Greedy Matching
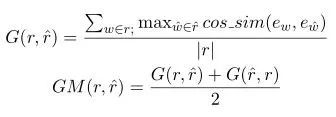
如上图所示,对于真实响应的每个词,寻找其在生成响应中相似度最高的词,并将其余弦相似度相加并求平均。同样再对生成响应再做一遍,并取二者的平均值。上面的相似度计算都是基于词向量进行的,可以看出本方法主要关注两句话之间最相似的那些词语,即关键词。
2.3.2 Embedding Average
这种方法直接使用句向量计算真实响应和生成响应之间的相似度,而句向量则是每个词向量加权平均而来,如下图所示。然后使用余弦相似度来计算两个句向量之间的相似度。
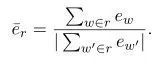
2.3.3 Vector Extrema
跟上面的方法类似,也是先通过词向量计算出句向量,在使用句向量之间的余弦相似度表示二者的相似度。不过句向量的计算方法略有不同,这里采用向量极值法进行计算。
2.4 基于语言模型的方法
2.4.1 PPL
PPL,也即perplexity困惑度,是语言模型中的指标,用于评价语言模型的好坏,其实质是根据每个词来估计一句话出现的概率,看一句话是否通顺。也经常会在对话系统中出现评价生成的响应是否符合语言规则,低困惑度的概率分布模型或概率模型能更好地预测样本。(
计算公式如下图所示:
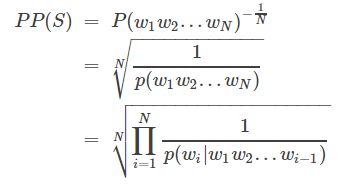
S代表sentence,N是句子长度,p(wi)是第i个词的概率。第一个词就是 p(w1|w0),而w0是START,表示句子的起始,是个占位符。这个式子可以这样理解,PPL越小,p(wi)则越大,一句我们期望的sentence出现的概率就越高。
Perplexity可以认为是average branch factor(平均分支系数),即预测下一个词时可以有多少种选择。可选词数越少,我们大致认为模型越准确。这样也能解释,为什么PPL越小,模型越好。
PPL受多种因素影响:
(1) 训练数据集越大,PPL会下降得更低,1billion dataset和10万dataset训练效果是很不一样的;
(2) 数据中的标点会对模型的PPL产生很大影响,一个句号能让PPL波动几十,标点的预测总是不稳定;
(3) 预测语句中的“的,了”等词也对PPL有很大影响,可能“我借你的书”比“我借你书”的指标值小几十,但从语义上分析有没有这些停用词并不能完全代表句子生成的好坏。
对上面的计算公式取log,可以发现其效果等效于pytorch中的cross entropyloss,因而,可以直接用math.exp(cross entropy loss)来计算PPL。
2.4.2 基于bert的评分指标
基于N-gram重叠的度量标准只对词汇变化敏感,不能识别句子语义或语法的变化。因此,它们被反复证明与人工评估差距较大。
近年来Bert为代表的的plm红红火火,于是有人提出使用句子上下文表示(bert全家桶)和人工设计的计算逻辑对句子相似度进行计算。这样的评价指标鲁棒性较好,在缺乏训练数据的情况下也具有较好表现。
BERTSCORE
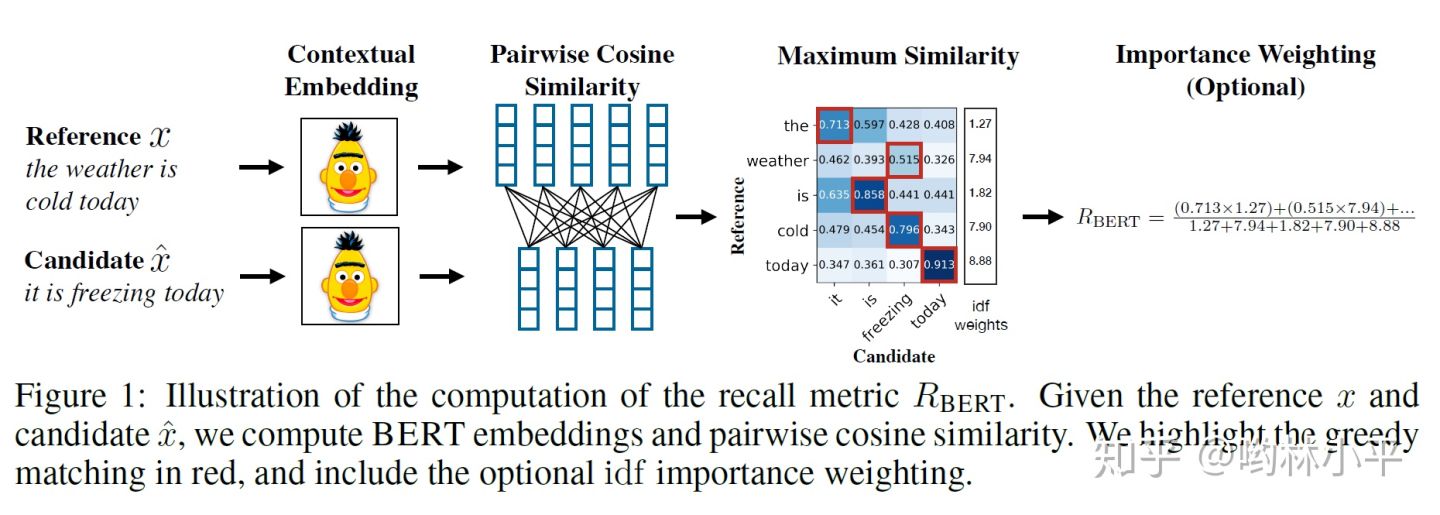
Importance Weighting
还可以考虑给不同的词以权重。作者使用idf函数,即给定M个参考句,词w的idf为:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BlO3FD0P-1632883484540)(https://www.zhihu.com/equation?tex=%5Coperatorname%7Bidf%7D%28w%29%3D-%5Clog+%5Cfrac%7B1%7D%7BM%7D+%5Csum_%7Bi%3D1%7D%5E%7BM%7D+%5Cmathbb%7BI%7D%5Cleft%5Bw+%5Cin+x%5E%7B%28i%29%7D%5Cright%5D)]
用此式更新上述评分,例如recall:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nZiaos2J-1632883484541)(https://www.zhihu.com/equation?tex=R_%7B%5Cmathrm%7BBERT%7D%7D%3D%5Cfrac%7B%5Csum_%7Bx_%7Bi%7D+%5Cin+x%7D+%5Ctext+%7B+idf+%7D%5Cleft%28x_%7Bi%7D%5Cright%29+%5Cmax+%7B%5Chat%7Bx%7D%7Bj%7D+%5Cin+%5Chat%7Bx%7D%7D+%5Cmathbf%7Bx%7D_%7Bi%7D%5E%7B%5Ctop%7D+%5Chat%7B%5Cmathbf%7Bx%7D%7D_%7Bj%7D%7D%7B%5Csum_%7Bx_%7Bi%7D+%5Cin+x%7D+%5Ctext+%7B+idf+%7D%5Cleft%28x_%7Bi%7D%5Cright%29%7D)]
Baseline Rescaling
为了保证一个可读性(即不好的生成值为0,好的生成值为1)需要做一个Rescaling。作者的做法是随机的组合候选句和参考句(we create 1M candidate-reference pairs by grouping two random sentences.)从而计算一个b的平均值。b会被用于以下的式子:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UMAgaPro-1632883484543)(https://www.zhihu.com/equation?tex=%5Chat%7BR%7D_%7B%5Cmathrm%7BBERT%7D%7D%3D%5Cfrac%7BR_%7B%5Cmathrm%7BBERT%7D%7D-b%7D%7B1-b%7D)]
若如此做,R_BERT会被映射到0和1(typically),precision和F1也可以做相似的操作。
此外,还有一些其他的指标,如MoverScore,BLEURT等等,具体可参考对应的论文。
3. 总结
文本生成的指标多种多样,其适用也需结合具体的业务,目前的状况为:
- BLEU,ROUGE等评价指标依然是主流的评价方式
- 从短句惩罚、重复、重要信息缺失、多样化等方面,衍生出例如METEOR、SPICE、Distinct等评价指标
- 以bertscore为代表的评价指标近年来受到广泛的关注,与人工评价的相关性也越来越高
文本生成评价指标串串烧相关推荐
- 【NLG】(六)文本生成评价指标—— ROUGE原理及代码示例
前奏: [NLG](一)文本生成评价指标--BLEU原理及代码示例 [NLG](二)文本生成评价指标-- METEOR原理及代码示例 [NLG](三)文本生成评价指标-- ENTROPY原理及代码示例 ...
- 【NLG】(二)文本生成评价指标—— METEOR原理及代码示例
前奏: [NLG](一)文本生成评价指标--BLEU原理及代码示例 1.METEOR原理 2004年,卡内基梅隆大学的Lavir提出评价指标中召回率的意义,基于此研究,Banerjee和Lavie(B ...
- 肝了1W字!文本生成评价指标的进化与推翻
一只小狐狸带你解锁 炼丹术&NLP 秘籍 作者:林镇坤(中山大学研一,对文本生成和猫感兴趣) 前言 文本生成目前的一大瓶颈是如何客观,准确的评价机器生成文本的质量.一个好的评价指标(或者设置合 ...
- 最全面的文本生成评价指标大盘点
点击下面卡片,关注我呀,每天给你送来AI技术干货! 来自:NLP情报局 文本生成是自然语言处理最基础的任务之一,应用广泛,包括闲聊.写诗.作曲.讲故事等等,如图是清华大学"九歌"机 ...
- 文本生成评价指标-A Survey
文本生成是自然语言处理最基础的任务之一,应用广泛,包括闲聊.写诗.作曲.讲故事等等,如图是清华大学"九歌"机器人生成的五言绝句. 本文聚焦于文本生成的评价方式,通过综述论文解读,介 ...
- NLP文本生成的评价指标有什么?
文章目录 NLP文本生成的评价指标有什么? 1. BLEU 2. ROUGE 2.1 ROUGE-N (将BLEU的精确率优化为召回率) 2.2 ROUGE-L (将BLEU的n-gram优化为公共子 ...
- 文本生成客观评价指标总结(附Pytorch代码实现)
前言:最近在做文本生成的工作,调研发现针对不同的文本生成场景(机器翻译.对话生成.图像描述.data-to-text 等),客观评价指标也不尽相同.虽然网络上已经有很多关于文本生成评价指标的文章,本博 ...
- huggingface transformers实战系列-05_文本生成
# hide from utils import * setup_chapter() Using transformers v4.11.3 Using datasets v1.13.0 Using a ...
- 文本摘要生成评价指标——rouge
文本摘要生成评价指标--rouge rouge的作用: rouge的内容: rouge的类别: rouge的使用: rouge-N的理解: Rouge-L的理解 rouge的作用: -Rouge的全名 ...
最新文章
- 基于WinCE的I2C驱动程序设计
- 优雅的使用 ThreadLocal
- python读取mtcars数据集并实现以下操作_Python可视化43 | plotnine≈R语言ggplot2,43plotnineR...
- 《软件需求分析(第二版)》第 14 章——需求管理的原则和实践 重点部分总结
- sqlserver聚合索引(clustered index) / 非聚合索引(nonclustered index)的理解
- MFC编程入门之十(对话框:设置对话框控件的Tab顺序)
- 常见排序算法整理2(C++实现)
- 朋友圈加粗字体数字_可爱搞笑的女生朋友圈文案
- Windows系统通过cmd查找结束进程
- echarts中的自定义tooltip浮层展示
- 达梦数据库update关联更新改造
- IDEA启动tomcat控制台出现中文乱码问题完美解决方案(亲测有效)
- 取向性完全不同 骐达英朗底盘对比解析
- Perl下载和安装Python下载和安装
- Oracle数据库:子查询、单行子查询,多行子查询,in,any,all语句,子查询的练习案例
- 在线考试系统的倒计时
- win10定时任务报错:操作员或系统管理员拒绝了请求
- 第三章 项目立项管理
- 全网最全精析破解 Springboot+Jpa 对数据库增删改查
- Python的IDE:基于Eclipse/MyEclipse软件的PyDev插件配置python的开发环境(不同python项目加载不同版本的python)—从而实现Python编程图文教程之详细攻略