Tesseract-OCR 字符识别---样本训练 [转]
Tesseract是一个开源的OCR(Optical Character Recognition,光学字符识别)引擎,可以识别多种格式的图像文件并将其转换成文本,目前已支持60多种语言(包括中文)。 Tesseract最初由HP公司开发,后来由Google维护,目前发布在Googel Project上。地址为http://code.google.com/p/tesseract-ocr/。
使用默认的语言库识别
1.安装Tesseract
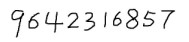
3. 打开命令行,定位到Tesseract-OCR目录,输入命令:
- tesseract.exe number.jpg result -l eng
tesseract.exe number.jpg result -l eng其中result表示输出结果文件txt名称,eng表示用以识别的语言文件为英文。
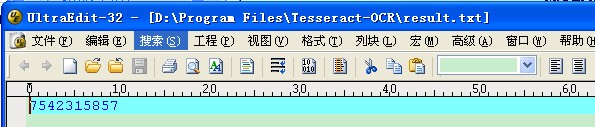
3. 打开Tesseract-OCR目录下的result.txt文件,看到识别的结果为7542315857,有3个字符识别错误,识别率还不是很高,那有没有什么方法来提供识别率呢?Tesseract提供了一套训练样本的方法,用以生成自己所需的识别语言库。下面介绍一下具体训练样本的方法。
训练样本
1.下载工具jTessBoxEditor. http://sourceforge.net/projects/vietocr/files/jTessBoxEditor/,这个工具是用来训练样本用的,由于该工具是用JAVA开发的,需要安装JAVA虚拟机才能运行。
2. 获取样本图像。用画图工具绘制了5张0-9的文样本图像(当然样本越多越好),如下图所示:
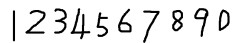
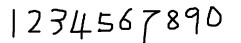
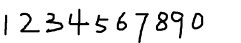
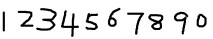
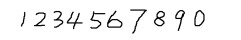
3.合并样本图像。运行jTessBoxEditor工具,在点击菜单栏中Tools--->Merge TIFF。在弹出的对话框中选择样本图像(按Shift选择多张),合并成num.font.exp0.tif文件。4.生成Box File文件。打开命令行,执行命令:
- tesseract.exe num.font.exp0.tif num.font.exp0 batch.nochop makebox
tesseract.exe num.font.exp0.tif num.font.exp0 batch.nochop makebox生成的BOX文件为num.font.exp0.box,BOX文件为Tessercat识别出的文字和其坐标。
注:Make Box File的命令格式为:
- tesseract [lang].[fontname].exp[num].tif [lang].[fontname].exp[num] batch.nochop makebox
tesseract [lang].[fontname].exp[num].tif [lang].[fontname].exp[num] batch.nochop makebox其中lang为语言名称,fontname为字体名称,num为序号,可以随便定义。
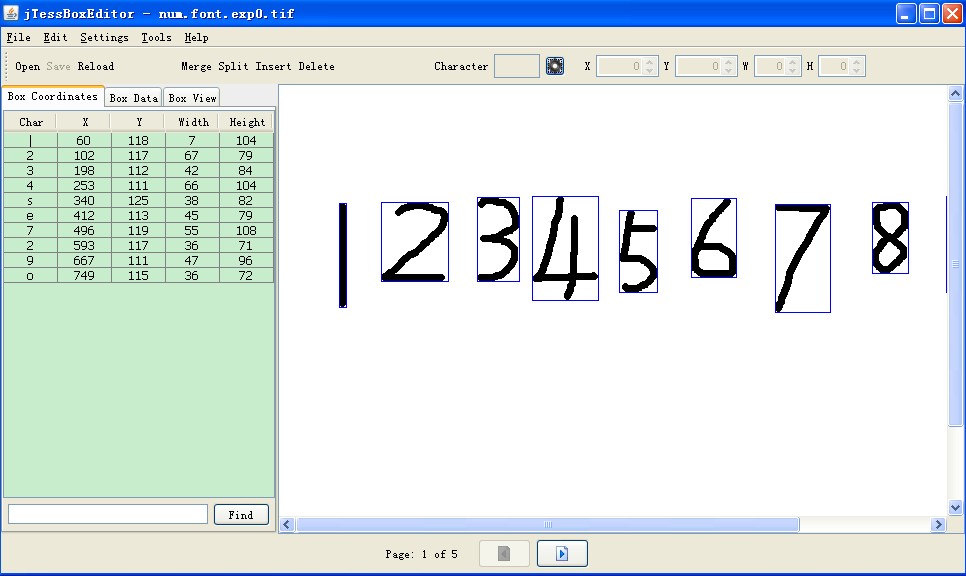
5.文字校正。运行jTessBoxEditor工具,打开num.font.exp0.tif文件(必须将上一步生成的.box和.tif样本文件放在同一目录),如下图所示。可以看出有些字符识别的不正确,可以通过该工具手动对每张图片中识别错误的字符进行校正。校正完成后保存即可。
6.定义字体特征文件。Tesseract-OCR3.01以上的版本在训练之前需要创建一个名称为font_properties的字体特征文件。
font_properties不含有BOM头,文件内容格式如下:
- <fontname> <italic> <bold> <fixed> <serif> <fraktur>
<fontname> <italic> <bold> <fixed> <serif> <fraktur>其中fontname为字体名称,必须与[lang].[fontname].exp[num].box中的名称保持一致。<italic> 、<bold> 、<fixed> 、<serif>、 <fraktur>的取值为1或0,表示字体是否具有这些属性。
这里在样本图片所在目录下创建一个名称为font_properties的文件,用记事本打开,输入以下下内容:
- font 0 0 0 0 0
font 0 0 0 0 0这里全取值为0,表示字体不是粗体、斜体等等。 7.生成语言文件。在样本图片所在目录下创建一个批处理文件,输入如下内容。
- rem 执行改批处理前先要目录下创建font_properties文件
- echo Run Tesseract for Training..
- tesseract.exe num.font.exp0.tif num.font.exp0 nobatch box.train
- echo Compute the Character Set..
- unicharset_extractor.exe num.font.exp0.box
- mftraining -F font_properties -U unicharset -O num.unicharset num.font.exp0.tr
- echo Clustering..
- cntraining.exe num.font.exp0.tr
- echo Rename Files..
- rename normproto num.normproto
- rename inttemp num.inttemp
- rename pffmtable num.pffmtable
- rename shapetable num.shapetable
- echo Create Tessdata..
- combine_tessdata.exe num.
rem 执行改批处理前先要目录下创建font_properties文件echo Run Tesseract for Training..
tesseract.exe num.font.exp0.tif num.font.exp0 nobatch box.trainecho Compute the Character Set..
unicharset_extractor.exe num.font.exp0.box
mftraining -F font_properties -U unicharset -O num.unicharset num.font.exp0.trecho Clustering..
cntraining.exe num.font.exp0.trecho Rename Files..
rename normproto num.normproto
rename inttemp num.inttemp
rename pffmtable num.pffmtable
rename shapetable num.shapetable echo Create Tessdata..
combine_tessdata.exe num.将批处理通过命令行执行。执行后的结果如下:
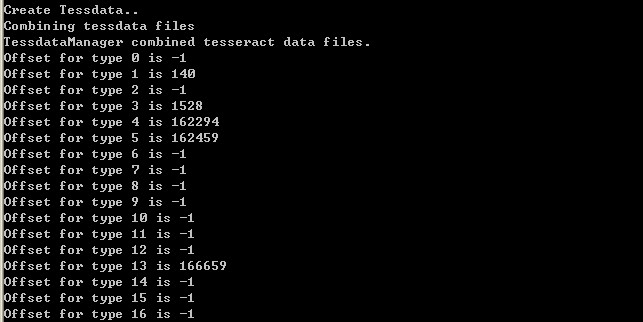
需确认打印结果中的Offset 1、3、4、5、13这些项不是-1。这样,一个新的语言文件就生成了。
num.traineddata便是最终生成的语言文件,将生成的num.traineddata拷贝到Tesseract-OCR-->tessdata目录下。可以用它来进行字符识别了。
使用训练后的语言库识别
用训练后的语言库识别number.jpg文件, 打开命令行,定位到Tesseract-OCR目录,输入命令:
- tesseract.exe number.jpg result -l eng
tesseract.exe number.jpg result -l eng识别结果如如图所示,可以看到识别率提高了不少。通过自定义训练样本,可以进行图形验证码、车牌号码识别等。感兴趣的朋友可以研究研究。

转载于:https://www.cnblogs.com/samlin/p/Tesseract-OCR.html
Tesseract-OCR 字符识别---样本训练 [转]相关推荐
- Tesseract OCR手写数字的样本训练
Tesseract OCR样本训练除需要安装Tesseract OCR软件外,还需要下载Tesseract OCR样本训练工具jTessBoxEditorFX,下载地址: http://dl.pcon ...
- Tesseract OCR 训练字库
Tesseract OCR是一款由HP实验室开发由Google维护的开源OCR引擎,在字符识别领域发挥着举足轻重的作用.除了使用软件自带的中英文识别库,我们可以使用Tesseract OCR训练属于自 ...
- tesseract OCR的多语言,多字体字符识别
识别多种字体.多种语言的字符,在实际应用中是很常见的问题. 经过测试,及查看tesseract3.01的源码,tesseract 3.01版本是不支持多语言.多种字体OCR识别的. tesseract ...
- tesseract ocr训练样本库以及样本库使用
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言 一.tesseract ocr训练样本库 二.样本库的使用 总结 前言 这篇报告主要介绍两个内容: 1.tessera ...
- 关于Tesseract OCR 中文训练识别小试(java调用Tess4j)
2017.9.20日小结 最近接到是关于消防系统协议解析仪器的项目,目的是从协议解析仪器获取有效数据,并解析数据(目的是不希望消防主机的数据信息再传给主机厂商而是最后能给自己收集调用).由于各个消防器 ...
- [转]tesseract OCR Engine overview字符识别学习
原文地址:http://blog.csdn.net/viewcode/article/details/7790065 正文: 原文: An Overview of the Tesseract OCR ...
- 应用OpenCV进行OCR字符识别
opencv自带一个字符识别的例子,它的重点不是OCR字符识别,而主要是演示机器学习的应用.它应用的是UCI提供的字符数据(特征数据). DAMILES在网上发布了一个应用OpenCV进行OCR的例子 ...
- An Overview of the Tesseract OCR Engine译文
An Overview of the Tesseract OCR Engine译文 Abstract Tesseract OCR引擎以及UNLV OCR精度第四次年度测试中的HP Research P ...
- tesseract简单介绍和训练
Python--图片文字识别--Tesseract 1.tesseract介绍 Tesseract,一款由HP实验室开发由Google维护的开源OCR(Optical Character Recogn ...
最新文章
- 【HDU】1305 Immediate Decodability(字典树:结构体数组,二维数组,链表/指针)
- 淘金尖端领域:全球量子技术最新投资趋势
- Linux——文件管理之inode
- 万达放弃A股上市,数据揭秘王思聪投资为何频繁跳水?
- java代码同时下载_java代码实现打包多个文件下载功能
- 在一台服务器上搭建多个项目的SVN
- 3D远方纯动态白云页面源码
- Java的简单了解。
- “数”驰天下,华为云DRS 高效支撑T3出行平稳迁移
- solr与zookeeper搭建solrcloud分布式索引服务实例
- [转载] strtol() -- 将字符串转换成长整型数(转载)
- 【高德LBS开源组件大赛】iOS版地图选中Overlay功能组件
- java每日学习回忆录
- 蓝鸽集团云计算机,App Store 上的“蓝鸽教育云”
- word2016添加题注|图注文献标号的交叉引用及引用的更新|添加不同类型的页码|文献自动编号|文献编号的自动引用|删除空白页
- 诗歌九 声律启蒙(云对雨,雪对风,晚照对晴空)
- github不小心同步覆盖了本地文件
- 美军回应网传UFO:视频为真 现有人类技术无法达到
- c语言浮点数和0比较大小,C-浮点数为什么不能和0比较?
- “仅三天可见” 的朋友圈有方法破解啦!