敏感词过滤之——自定义构建查询词库与快速查询实现
关于敏感词过滤的一点思考与实践
- 业务场景
- 思考与研究
- 逻辑分析
- 代码实现(php)
- 构建敏感词树
- 分割字符串
- 敏感词树长分支的递归实现
- 读取敏感词库
- 敏感词树的查询
- 查询实现
- 调用
- 测试、分析与总结
业务场景
最近在公司维护的小程序上,遇到一个需要用到敏感词过滤功能的业务模块,虽然有微信提供的敏感词过滤的api可供使用,但是如果我们想加入自定义的敏感词库,或者我们想要知道是什么违规词汇,后对他和谐处理,那要如何实现呢?
思考与研究
我们知道,如果要查询某段文本中的敏感词汇,马上能想到的有如下几种:
1.用正则匹配的方式去实现,简单粗暴地对每一个敏感词库中的敏感词在文本中进行匹配。
2.转变成某种格式,利用开发语言内置的某些“值是否存在的”方法实现
3.将数据存入数据库中利用数据库查询
4.其它的方法欢迎评论区补充。
但是以上的方法都有着或多或少的问题,例如正则匹配,如果输入文本很大、敏感词库很大,那么全部查一遍的时间复杂度显然会超出预期,又例如利用开发语言的内置方法,且不说不同的语言有没有内置这种方法,在算法设计上,我们也不能只考虑单一语言的实现,优秀的算法在不同语言中实现的效果都是出色的,而数据库查询基本类似于第一种,所以不考虑。
经过一番网络上对各种帖子的研究,发现敏感词过滤大多使用的是类DFA算法的思想实现,要了解DFA算法的原理和使用场景不在此篇讨论的范畴中,因此不予篇幅描述。
那么我们如何利用类DFA的思想实现呢?
逻辑分析
根据DFA算法的思想,我们可以将敏感词库设计成一个特殊的树形结构,称之为敏感词查询树。
基本逻辑是将敏感词拆分成单独的字,然后根据顺序构建一个树分支,如果有些敏感词是前几个字相同的,则构建成同一个分支下的小分支,以此类推:
例如将:乒乓球大赛、乒乓球冠军、乒乓大满贯、篮球冠军、篮联、足球、足力健等词语构建成树形结构,则抽象效果图如下:![]()
预估:由于将敏感词设计成了抽象的特殊树的分支结构(也可以说有点像hash,本文不对具体的定义做讨论),在查询时树的最大深度就是敏感词条的字符长度,这样一来时间复杂度降低了数个level,完全可以满足高效查询的需求。在消耗内存空间的问题上,我们还可以将该词库放入redis中使用hash结构保存,在频繁调用的时候只需要很小的内存空间就能高速完成查询。
有了清晰结构,下一步讨论 完成敏感词树的建立和查询的实现方法,这样我们的讨论才有意义。
代码实现(php)
准备:
考虑到需要自定义敏感词库,所以在实现算法时通过读取文本的方式建立敏感词库(提供敏感词库下载链接,直接打开中文乱码,建议网盘)
敏感词库.txt
博文中出现的敏感词,已用拼音代替过审
构建敏感词树
构建树的方法需要将敏感词分割成单个字符按照顺序建立分支,按照我们树的基本规则,每个字符为一个节点,相同字符长在同一个分支上,敏感词树分支按照顺序延伸。
分割字符串
/*** 分割字符串,将用户输入的字符去掉符号之后* * @param String $str 切割的字符串* @param int $split_len 切割后的长度* @return array|false*/
function utf8StrSplit($str, $split_len = 1)
{ if (!preg_match('/^[0-9]+$/', $split_len) || $split_len < 1) return FALSE; $len = mb_strlen($str, 'UTF-8'); if ($len <= $split_len) return array($str); preg_match_all('/.{'.$split_len.'}|[^x00]{1,'.$split_len.'}$/us', $str, $ar); return $ar[0];
}
敏感词树长分支的递归实现
/*** 敏感词入树* @param &$node 当前节点的引用* @param &$wordsArr 用户输入文本的字符数组引用* @return null*/function addTreeBranch(&$node, &$wordsArr){//弹出数组中的第一个字符$word = array_shift($wordsArr);if ($word == null){return;}if (isset($node[$word])){ //如果已存在这个字符节点,则节点引用转移到此节点$nextNode = &$node[$word];return $this->addTreeBranch($nextNode ,$wordsArr);}else{//如果不存在该字符节点,则长出该片叶子,赋值为空,再转移节引用到该字符节点$node[$word] = [];$nextNode = &$node[$word];return $this->addTreeBranch($nextNode ,$wordsArr);}}
读取敏感词库
调用上述两个方法生成敏感词库(以text文件为例)
function createSearchTree (){$sensitiveWordsTree = [];//敏感词树//读取敏感词库,生成查找树$sensitive = file( 'test.txt'); //按行读取内容foreach ( $sensitive as $line => $value ){//去除换行符$value = preg_replace("/[,!?:#%& *]/","",$value); //拆分每行内容 $tempArr = $this->utf8StrSplit($value);//树长分支$this->addTreeBranch($sensitiveWordsTree, $tempArr);}return json_encode($sensitiveWordsTree);}
我们来看一下生成的敏感词树的结构:
{"乒": {"乓": {"球": {"大": {"赛": []},"冠": {"军": []}},"大": {"满": {"贯": []}}}},"篮": {"球": {"大": {"赛": []}},"联": []},"足": {"球": [],"力": {"健": []}}
}
可以看到树的结构与我们的逻辑结构的概念图基本一致。那么敏感词的生成方法就完成了。
敏感词树的查询
有了结构之后,接下来要对某段文本进行敏感词匹配,这是我们过滤或者和谐它的基础。
匹配的方法和构造树的方法原理类似,都是通过数组键值的访问递归判断,不过查询比构建麻烦的地方在于匹配的关键词需要完全一致、匹配结束之后需要跳转回根节点继续查找、匹配成功的敏感词需要保存起来等。
来看如何实现
查询实现
/*** 敏感词匹配,递归匹配敏感词树,如匹配则保存敏感词信息* author Ray* create_time 2020-7-16 11:24* @param array $userInput 用户输入的内容拆分后的字符数组* @param array $sensitiveWordsInfo 用于保存匹配到的敏感词的数组,子数组为用户输入内容的敏感词语,子数组个数为匹配的敏感词个数* @param array $node 敏感词树查询定位节点* @param array $sensitiveWordsArr 保存敏感词的临时数组* @param int $index 查询树的深度* @return String 当未查询到的时候返回null,当查询到时返回匹配敏感词数组*/
private function searchTreeBranch(&$userInput, &$sensitiveWordsInfo, &$node, $sensitiveWordsArr, $index)
{//用户输入字符过滤完成,或者避免死循环出现,结束递归if (empty($userInput) || $index > 100){//搜索结束,返回匹配到的结果数组return $sensitiveWordsInfo;}//逐个字符匹配,取出当前判断的字符$word = array_shift($userInput);//若当前节点有该字符分支if (isset($node[$word])){ //若匹配的字符分支为叶子节点if (empty($node[$word])){//将当前敏感字保存进敏感词匹配数组中array_push($sensitiveWordsArr, $word);//保存匹配的敏感词array_push($sensitiveWordsInfo, implode('', $sensitiveWordsArr));//匹配完一个敏感词,继续查询下一个字符, 重新从根节点递归return $this->searchTreeBranch($userInput, $sensitiveWordsInfo, $this->sensitiveWordsTree, [], 0);}else{//当前字符有匹配,且下一个节点非空,则过渡到这个字符节点$nextNode = &$node[$word];//将当前敏感字保存array_push($sensitiveWordsArr,$word);return $this->searchTreeBranch($userInput, $sensitiveWordsInfo, $nextNode, $sensitiveWordsArr, $index++);}}else{ //没有匹配,查询下一个字符, 重新从根节点查询if (!empty($sensitiveWordsArr)){//匹配“fa lun gon”、“中国”时,类似“法轮中国”中,“fa lun gon”不能完全匹配,//但是“中”字会被跳过,所以类似此种情况回填“轮中”二字继续查询array_shift($sensitiveWordsArr);array_unshift($userInput,$word);$userInput = array_merge($sensitiveWordsArr,$userInput);}return $this->searchTreeBranch($userInput, $sensitiveWordsInfo, $this->sensitiveWordsTree, [], 0);}
}调用
过滤查询文本中的中文字符、英文字符、特殊字符,调用递归查询方法
/*** 用户敏感词判断方法* @param content 待判断的文本* @return boolen 是否是敏感词,true为是*/
private function inSensitive($content)
{$sensitiveWordsInfo = [];//敏感词在用户输入文本中的位置//去除英文字符$content = preg_replace("/[\s|\~|`|\!|\@|\#|\$|\%|\^|\&|\*|\(|\)|\-|\_|\+|\=|\||\|\[|\]|\{|\}|\;|\:|\"|\'|\,|\<|\>|\/|\?]/","",$content);//去除中文标点符号$content = urlencode($content);//将关键字编码$content = preg_replace("/(%7E|%60|%21|%40|%23|%24|%25|%5E|%26|%27|%2A|%28|%29|%2B|%7C|%5C|%3D|\-|_|%5B|%5D|%7D|%7B|%3B|%22|%3A|%3F|%3E|%3C|%2C|\.|%2F|%A3%BF|%A1%B7|%A1%B6|%A1%A2|%A1%A3|%A3%AC|%7D|%A1%B0|%A3%BA|%A3%BB|%A1%AE|%A1%AF|%A1%B1|%A3%FC|%A3%BD|%A1%AA|%A3%A9|%A3%A8|%A1%AD|%A3%A4|%A1%A4|%A3%A1|%E3%80%82|%EF%BC%81|%EF%BC%8C|%EF%BC%9B|%EF%BC%9F|%EF%BC%9A|%E3%80%81|%E2%80%A6%E2%80%A6|%E2%80%9D|%E2%80%9C|%E2%80%98|%E2%80%99)+/",'',$content);$content = urldecode($content);//将过滤后的关键字解码if (empty($content)){return [];}//拆分用户输入$userInput = $this->utf8_str_split($content);//匹配用户输入是否为敏感词$this->searchTreeBranch($userInput, $sensitiveWordsInfo, $this->sensitiveWordsTree, [], 0);return $sensitiveWordsInfo;
}
主要的难点在于查询实现中递归的结束 (输入文本检索完成)、继续递归 (敏感词成功匹配) 的跳转(匹配成功的跳转、未完全匹配需要回退的跳转)之间的状态转换,在方法中已做了详细的注释,本文不讨论具体查询方法,代码供参考。
正式运行完成之后测试的结果如:
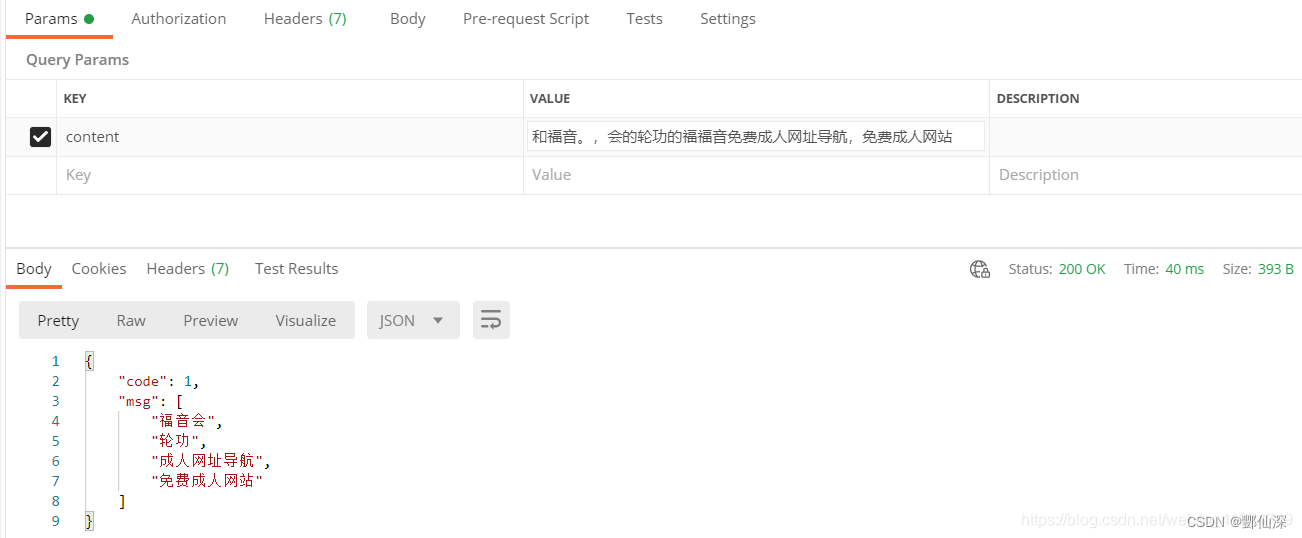,然后匹配成功“chen ren 网址导航”。
![]()
再者,我们一个完整的查询请求消耗的时间只有40ms,基本满足业务场景快速响应的需要。
测试、分析与总结
通过测试,在响应时间上基本可以满足要求,但是占用内存会比较多,如果后续通过redis建立hash类型的数据,建立快速读取的方式,应该对性能有一定提升。
另外如果要对一段文本中的敏感词进行替换处理(俗称*河蟹),可以用上面的方法将匹配的敏感词组再对文本进行替换处理,由于较为简单就不做演示了。
敏感词过滤之——自定义构建查询词库与快速查询实现相关推荐
- mysql怎样查表的模式_mysql常用基础操作语法(四)--对数据的简单无条件查询及库和表查询【命令行模式】...
1.mysql简单的查询:select 字段1,字段2... from tablename; 如果字段那里写一个*,代表查询所有的字段,等同于指定出所有的字段名,因此如果要查询所有字段的数据,一般都是 ...
- ansj 自定义 停用词_构造自定义停用词列表的快速提示
ansj 自定义 停用词 by Kavita Ganesan 通过Kavita Ganesan 构造自定义停用词列表的快速提示 (Quick tips for constructing custom ...
- mysql常用基础操作语法(四)--对数据的简单无条件查询及库和表查询【命令行模式】
1.mysql简单的查询:select 字段1,字段2... from tablename; 如果字段那里写一个*,代表查询所有的字段,等同于指定出所有的字段名,因此如果要查询所有字段的数据,一般都 ...
- 360权重查询 360权重如何快速查询呢?
随着360搜索以迅猛的步伐杀入搜索阵营,并成为国内搜索量第二大搜索引擎,推出了360权重查询工具,试用了一下,感觉与百度权重查询的原理基本类似,下面具体说说这个. 最近入职了一家SEO公司,接手管理了 ...
- SpringBoot使用SensitiveWord实现敏感词过滤
包含默认敏感词过滤和自定义敏感词过滤. 导入依赖 <dependency><groupId>com.github.houbb</groupId><artifa ...
- 5分钟Serverless实践 | 构建无服务器的敏感词过滤后端系统
前言 在上一篇"5分钟Serverless实践"系列文章中,我们介绍了什么是Serverless,以及如何构建一个无服务器的图片鉴黄Web应用,本文将延续这个话题,以敏感词过滤为例 ...
- python骂人的程序_Python实现敏感词过滤的4种方法
在我们生活中的一些场合经常会有一些不该出现的敏感词,我们通常会使用*去屏蔽它,例如:尼玛 -> **,一些骂人的敏感词和一些政治敏感词都不应该出现在一些公共场合中,这个时候我们就需要一定的手段去 ...
- python敏感词过滤代码简单_大型企业都在用,Python实现敏感词过滤
在我们生活中的一些场合经常会有一些不该出现的敏感词,我们通常会使用*去屏蔽它,例如:尼玛 -> **,一些骂人的敏感词和一些政治敏感词都不应该出现在一些公共场合中,这个时候我们就需要一定的手段去 ...
- AC自动机:多模式串匹配实现敏感词过滤
文章出处:极客时间<数据结构和算法之美>-作者:王争.该系列文章是本人的学习笔记. 1 敏感词过滤场景 在很多支持用户发表内容的网站,都有敏感词过滤替换的功能.例如将一些淫秽.反动内容过滤 ...
最新文章
- Python 学习博客
- 一个简单的生产消费者示例
- Nginx 之五: Nginx服务器的负载均衡、缓存与动静分离功能
- 如何利用css使PNG图片透明
- 删除win10自带的软件
- c语言变量为什么要定义,C语言为什么要规定对所用到的变量要“先定义,后使用”...
- c语言删除双向链表重复元素,求一个双向链表的建立,插入删除的c语言程序完整版的,借鉴一下思想,再多说一下就是能运行的那种...
- java中的Servlet
- 大家沉迷短视频无法自拔?Python爬虫进阶,带你玩转短视频
- mysql数据库原理与应用武洪萍第三张答案_MySQL数据库原理及应用(第2版)(微课版)...
- window的mysql开机自动启动
- 增大或者减小图片大小的方法
- 技能高考的计算机教室,2020湖北技能高考成绩查询时间
- 详谈利用系统漏洞及mysql提权
- OpenGL实验2:图形的旋转、平移、缩放
- WebGL开源框架列举概述
- altium designer利用向导画封装库详解
- 锦州市2021年高考成绩查询时间,2021年辽宁锦州中考考试时间及科目安排(已公布)...
- 截止目前,计算机考研调剂信息大全!
- 进入数据标注组后我干了什么