NUMA架构和Java
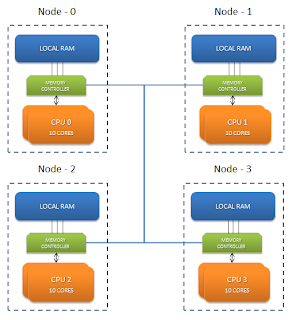
这些具有巨大内核的盒子带有非统一内存访问(NUMA)架构。 NUMA是一种可提高本地节点的内存访问性能的体系结构。 这些新的硬件盒分为称为节点的不同区域。 这些节点具有一定数量的核心,并分配有一部分内存。 因此,对于具有1 TB RAM和80个核心的机箱,我们有4个节点,每个节点具有20个核心和256 GB的内存分配。
您可以使用命令numactl --hardware
>numactl --hardware
available: 4 nodes (0-3)
node 0 size: 258508 MB
node 0 free: 186566 MB
node 1 size: 258560 MB
node 1 free: 237408 MB
node 2 size: 258560 MB
node 2 free: 234198 MB
node 3 size: 256540 MB
node 3 free: 237182 MB
node distances:
node 0 1 2 3 0: 10 20 20 20 1: 20 10 20 20 2: 20 20 10 20 3: 20 20 20 10JVM启动时,它将启动线程,这些线程是在某些随机节点的内核上调度的。 每个线程都尽可能快地使用其本地内存。 线程可能在某个时候处于WAITING状态,并在CPU上重新调度。 这次不能保证它将在同一节点上。 现在这一次,它必须访问一个远程存储位置,这会增加延迟。 远程存储器访问速度较慢,因为指令必须遍历互连链路,从而引入额外的跃点。
Linux命令numactl提供了一种仅将进程绑定到某些节点的方法。 它将进程锁定到特定节点,以执行和分配内存。 如果将JVM实例锁定到单个节点,则将删除节点间的流量,并且所有内存访问都将在快速本地内存上进行。
numactl --cpunodebind=nodes, -c nodes
Only execute process on the CPUs of nodes.创建了一个小型测试,该测试试图序列化一个大对象并计算每秒的事务和延迟。
要执行绑定到一个节点的Java进程,请执行
numactl --cpunodebind=0 java -Dthreads=10 -jar serializationTest.jar将此测试运行在两个不同的盒子上。
盒子A
4个CPU x 10核x 2(超线程)=总共80核
节点:0,1,2,3
方块B
2个CPU x 10个内核x 2个(超线程)=总共40个内核
节点:0,1
CPU速度:两者均为2.4 GHz。
默认设置也使用框中可用的所有节点。
| 框 | NUMA政策 | TPS | 延迟 (平均) | 延迟 (分钟) |
| 一个 | 默认 | 261 | 37 | 18岁 |
| 乙 | 默认 | 387 | 25 | 5 |
| 一个 | –cpunodebind = 0,1 | 405 | 23 | 3 |
| 乙 | –cpunodebind = 0 | 1,613 | 5 | 3 |
| 一个 | –cpunodebind = 0 | 1,619 | 5 | 3 |
因此,我们可以推断出,与“ 2个节点” Box B上的默认设置相比,“节点较多”的Box A上的默认设置在“ CPU密集型”测试中的性能较低。更好。 可能是因为它的节点跳数更少,并且线程被重新调度的概率增加到50%。
当--cpunodebind=0 ,它的表现要优于所有情况。
注意:以上测试是在10个内核上使用10个线程运行的。
测试罐: 下载
测试源: 下载
参考:来自我们的JCG合作伙伴 Himadri Singh的NUMA和Java ,在Billions&Terabytes博客上。
翻译自: https://www.javacodegeeks.com/2012/09/numa-architecture-and-java.html
NUMA架构和Java相关推荐
- smp架构与numa架构_NUMA架构和Java
smp架构与numa架构 是时候部署您的应用程序了,期待着采购最适合负载要求的硬件. 如今,具有40核或80核的包装盒非常普遍. 总体概念是更多的内核,更多的处理能力,更多的吞吐量. 但是我看到了一些 ...
- NUMA架构的CPU
本文从NUMA的介绍引出常见的NUMA使用中的陷阱,继而讨论对于NUMA系统的优化方法和一些值得关注的方向. 文章欢迎转载,但转载时请保留本段文字,并置于文章的顶部 作者:卢钧轶(cenalulu) ...
- NUMA架构的CPU -- 你真的用好了么?
本文从NUMA的介绍引出常见的NUMA使用中的陷阱,继而讨论对于NUMA系统的优化方法和一些值得关注的方向. 文章欢迎转载,但转载时请保留本段文字,并置于文章的顶部 作者:卢钧轶(cenalulu) ...
- Linux NUMA 架构 :基础软件工程师需要知道一些知识
文章目录 前言 从物理CPU.core到HT(hyper-threading) UMA(Uniform memory access) NUMA架构 NUMA下的内存分配策略 1. MPOL_DEFAU ...
- Percona5.6增加了对NUMA架构的支持
目前主流服务器都支持NUMA架构,我们可以通过命令numactl --hardware查看,如图: 在这里,NUMA架构把CPU逻辑上划分为两个节点node0和node1,每个节点上分配4核CPU.1 ...
- 【Android架构师java原理详解】二;反射原理及动态代理模式
前言: 本篇为Android架构师java原理专题二:反射原理及动态代理模式 大公司面试都要求我们有扎实的Java语言基础.而很多Android开发朋友这一块并不是很熟练,甚至半路初级底子很薄,这给我 ...
- 六、CPU优化(4)NUMA架构
一.服务器系统架构 从系统架构来看,目前的商用服务器大体可以分为以下三类 1. 即对称多处理器结构(SMP:Symmetric Multi-Processor),, 在SMP架构中,每个CPU对称工作 ...
- jug java_架构大型企业Java项目–我的虚拟JUG会话
jug java 昨天我很荣幸被邀请参加虚拟JUG . 这是一个很大的荣誉,其原因有很多:首先,我是vJUG董事会的一员,其次,因为这是我第二次向这个对Java感兴趣的伟大团队做演讲. 受到邀请总是很 ...
- 架构大型企业Java项目–我的虚拟JUG会话
昨天我很荣幸被邀请参加虚拟JUG . 这是一个很大的荣誉,其原因有很多:首先,我是vJUG董事会的一员,其次,因为这是我第二次向这个对Java感兴趣的伟大团队做演讲. 被邀请回来总是很高兴的. 架构大 ...
最新文章
- kernel和filter这两个概念在CNN中的区别以及卷积核与卷积层的关系
- 查询缓存---Mybatis学习笔记(十)
- 考虑用Task.WhenAll
- 信息学奥赛一本通 1189:Pell数列 | 1202:Pell数列 | OpenJudge NOI 2.3 1788:Pell数列 | 2.3 1788:Pell数列
- Linux.ProxyM僵尸网络再次发起疯狂攻击,感染过万台设备
- js 程序执行与顺序实现详解
- 怎么修改asp文件上传大小限制?
- ECshop新手入门模板制作教程[转载]
- IDEA 修改文件编码
- vs2019,C#,MySQL创建图书管理系统2(登录功能实现)
- 笔记本外接显示器教程级后续使用技巧
- 请你讲讲分布式系统中的限流器一般如何实现?
- linux如何扫描网络漏洞,在Linux系统上用nmap扫描SSL漏洞的方法
- RaspberryPi 3B 之初体验笔记(续一)
- Linux 下播放音乐和视频
- 封闭式基金折价排行表20060929(ZT)
- 用C++设计一个简单的学籍管理系统
- 利用QGIS和点数据进行等值线插值分析
- Go 语言 IDE 之 VSCode 配置使用
- 【机械】基于matlab实现直齿圆柱齿轮应力计算附matlab代码
热门文章
- 转:Kafka事务使用和编程示例/实例
- java国际化——消息格式化+文本文件和字符集
- final 实例域+final类+final方法(阻止继承)
- os如何处理键盘的所有按键,显示or不显示,显示是如何显示
- cuba开发_使用CUBA进行开发–与Spring相比有很大的转变?
- java 集成开发工具_最好的Java开发人员测试和集成工具
- ssl/tls服务器瞬时_SSL / TLS REST服务器–带有Spring和TomEE的客户端
- 实现函数克隆_哪个更好的选择:克隆或复制构造函数?
- 使用AWS Lambda在Go中构建RESTful API
- mongodb插入速度每秒_MongoDB事实:商品硬件上每秒插入80000次以上