OpenTSDB 造成 Hbase 整点压力过大问题的排查和解决
业务背景
OpenTSDB 是一款非常适合存储海量时间序列数据的开源软件,使用 HBase 作为存储让它变的非常容易扩展。我们在建设美团性能监控平台的过程中,每天需要处理数以亿计的数据,经过几番探索和调研,最终选取了 OpenTSDB 作为数据存储层的重要组件。OpenTSDB 的安装和配置过程都比较简单,但是在实际的业务应用中,还是会出现这样那样的问题,本文详细介绍我们在OpenTSDB 实际使用过程中遇到的 HBase 整点压力过大的问题,期望对大家有些参考意义。
问题的出现
性能监控平台使用 OpenTSDB 负责存储之后不久(创建的表名称是 tsdb-perf),数据平台组的同事发现,tsdb-perf 这个表在最近这段时间每天上午 10 点左右有大量的读操作,造成 HBase 集群压力过大,但是想去分析问题的时候发现读操作又降为 0 了,为了避免类似情况未来突然发生,需要我来排查下原因。
于是我就想:性能监控平台目前只是个内部系统,用户使用量不大,并且只有在用户需要查看数据时去查询,数据读取量不应该造成 HBase 的压力过大。
重现问题
如果要解决这个问题,稳定重现是个必要条件,根据数据平台组同事的反馈,我们做了更详细的监控,每隔两分钟采集性能监控平台所用的 HBase 集群的读操作数量,发现是下面的变化趋势:
13:00:05 0
13:02:01 66372
13:04:01 96746
13:06:02 101784
13:08:01 99254
13:10:02 2814
13:12:01 93668
13:14:02 93224
13:16:02 90118
13:18:02 11376
13:20:01 85134
13:22:01 81880
13:24:01 80916
13:26:01 77694
13:28:02 76312
13:30:01 73310
13:32:02 0
13:34:01 0
13:36:01 0
13:38:02 0
13:40:01 0
13:42:02 0
13:44:01 0
13:46:02 0
13:48:01 0
13:50:02 0
13:52:01 0
13:54:02 0
13:56:01 0
13:58:02 0
14:00:01 0
14:02:01 36487
14:04:01 43946
14:06:01 53002
14:08:02 51598
14:10:01 54914
14:12:02 95784
14:14:04 53866
14:16:02 54868
14:18:01 54122
14:20:04 0
14:22:01 0
14:24:02 0
14:26:01 0
14:28:01 0
14:30:01 0
14:32:02 0
14:34:01 0
从图上不难看出,每到整点开始 tsdb-perf 这个表的读操作飚的很高,大约持续半个小时,之后恢复到 0 。到下个整点又出现类似的问题,并没有像数据平台组同事观察到的突然回复正常了,可能他们连续两次观察的时间点刚好错开了。
于是,真正的问题就变成了:OpenTSDB 到 HBase 的读操作每到整点开始飚的很高,持续大约半小时后回复正常,这种类脉冲式的流量冲击会给 HBase 集群的稳定性带来负面影响。
定位问题所在
事出反常必有妖,OpenTSDB 到 HBase 的大量读操作肯定伴随很大的网络流量,因为两者用 HTTP 通信,我们得仔细梳理下可能造成这种情况的几种原因。性能监控平台的架构图如下:
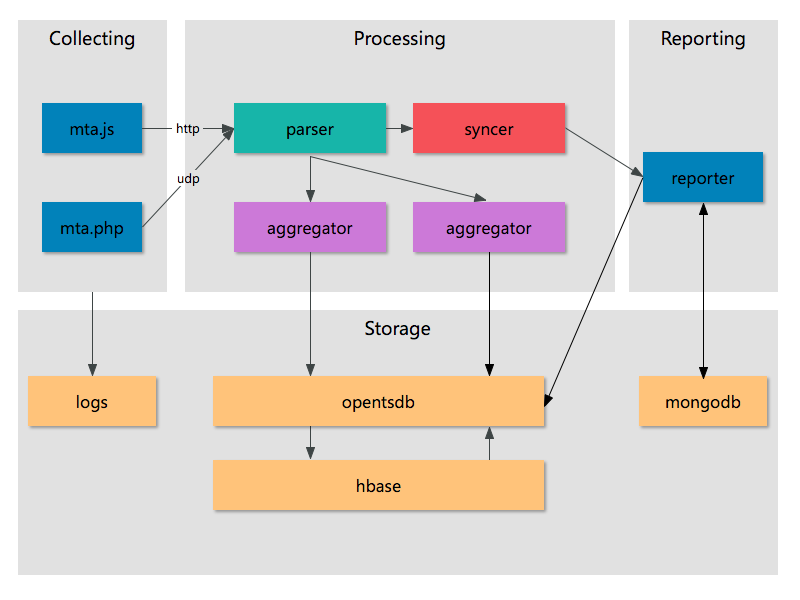
从架构图可以看出,只有数据聚合服务和报表系统会和 OpenTSDB 交互,聚合服务向里面写数据,报表系统从里面读数据。然后 OpenTSDB 负责把数据发送到 HBase 中。从数据流动的方向来讲,有可能是报表系统导致了大量的读操作,也有可能是聚合服务里面存在不合理的读请求,也有可能是 OpenTSDB 本身存在缺陷。
首先排除的是报表系统导致的大量读操作,因为只会在用户查看某些报表时才会从 OpenTSDB 读取数据,目前报表系统每天的访问量也才几百,不足以造成如此大的影响。
其次,如何确认是否是聚合服务导致了大量的读请求呢?可以从网络流量的视角来分析,如果聚合服务到 OpenTSDB 的流量过大,完全有可能导致 OpenTSDB 到 HBase 的过大流量,但是由于目前聚合服务和 TSDB 写实例是部署在相同的机器上,无法方便的统计到网络流量的大小,于是我们把聚合服务和 TSDB 写实例分开部署,得到下面的流量统计图:
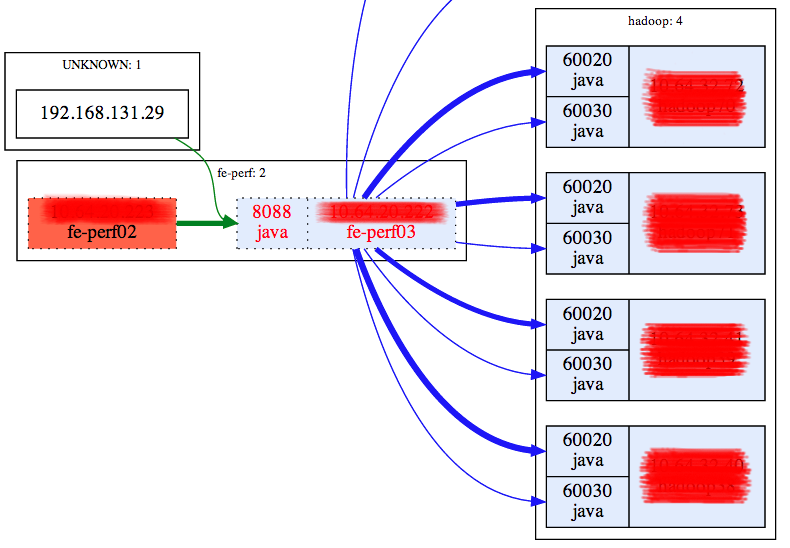
聚合服务只接收来自解析服务的数据包计算完毕之后发送给 TSDB,其网络流量如下图:
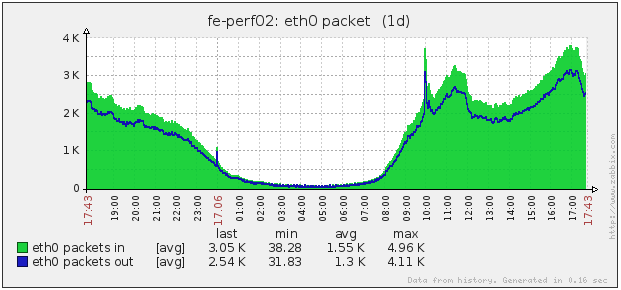
TSDB 服务只接收来自聚合服务的数据,然后发送到 HBase,却出现了脉冲式的冲高回落,网络流量如下图:
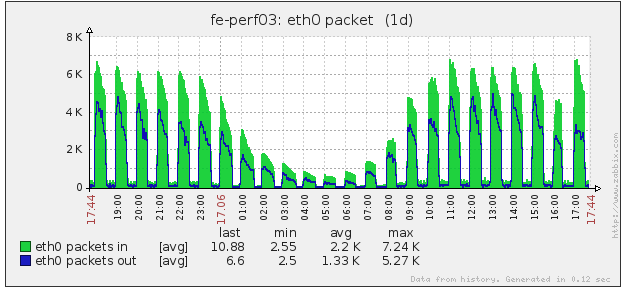
这样,就可以排除聚合服务造成的问题,出问题的地方就在 OpenTSDB 和 HBase 集群之间,其他业务线并没有造成 HBase 的压力过大,看来问题应该出在 OpenTSDB 里面,如果这个问题是 OpenTSDB 内部存在的,那么其他使用了 OpenTSDB 的系统肯定也存在类似的问题,下面是另外一个组部署的 OpenTSDB 的机器的网络流量图(注意,这台机器上只部署了 OpenTSDB 服务):
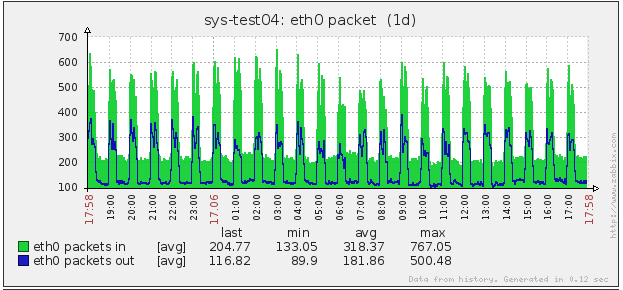
这让我更加确信问题是在 OpenTSDB 内部,也就是它的工作机制导致了这种问题。
查找问题原因
于是我先后查阅了 OpenTSDB 的官方文档和 Google Group 讨论组里的大部分帖子,还下载来了 OpenTSDB 的源代码,探个究竟,另外在从读操作从 0 到暴涨的过程中仔细盯着 OpenTSDB 的 stat 页面特别关注下面红色方框中的几个指标:

让我感觉比较诡异的是,与大量读操作同时发生的还有大量的删除操作,官方文档上的这段话很好的解释了我的疑惑:
If compactions have been enabled for a TSD, a row may be compacted after it’s base hour has passed or a query has run over the row. Compacted columns simply squash all of the data points together to reduce the amount of overhead consumed by disparate data points. Data is initially written to individual columns for speed, then compacted later for storage efficiency. Once a row is compacted, the individual data points are deleted. Data may be written back to the row and compacted again later.
这段话很好的解释了 OpenTSDB 的 Compaction 机制的工作原理,OpenTSDB 内部的工作原理比这个更复杂,下面我说下我通俗的理解:
- 为了节省存储空间和提高数据读取速度,OpenTSDB 内部有个数据压缩(即 Compaction)的机制,将设定的某个时间段内某个指标的所有数据压缩成单行,重新写到 HBase;
- OpenTSDB 运行时默认把收到的数据(原始数据点)每秒1次的速度批量写到 HBase 上,然后会周期性的触发上面提到的数据压缩机制,把原始数据点拿出来,压缩后重新写回HBase,然后把原始数据点删除,这就虽然我们只往 OpenTSDB 写数据但大量的读和删操作还是会发生的原因;
- OpenTSDB 默认的配置是以 3600 秒为区间压缩,实际运行时就是整点触发,这样整点发生的大量读、删操作就可以解释了;
至此,线上 OpenTSDB 实例整点大量读操作造成 HBase 集群压力过大的问题原因基本明了。
如何解决问题
找到问题的原因之后,我们想到了以下 2 种解决方案:
- 禁用 OpenTSDB 的 Compaction 机制,这样 OpenTSDB 就变成了 1 个纯粹的写实例,数据读取速度会有牺牲,因为每次读取需要扫描更多的数据,这个对于业务数据量很大的系统来说可能并不合适;
- 想办法让 OpenTSDB 的数据压缩过程缓慢进行,这样到 HBase 的流量压力就会平缓很多,但是这样做还是有风险,因为如果从业务系统到 OpenTSDB 的流量暴涨仍然有可能会 HBase 压力过大,不过这就是另外1个问题了,HBase 需要扩容;
实际操作过程中,我们使用了第 2 种方案,修改 OpenTSDB 的源代码中 src/core/CompactionQueue.java 中的 FLUSH_SPEED 常量为 1,重新编译即可。这样改动的实际影响是:默认压缩速度是 2 倍速,即最多半个小时内完成前 1 个小时数据的压缩,重新写回到 HBase,可以把这个调成 1 倍速,给它 1 个小时的时间来完成前 1 个小时数据的 Compaction,这样到 HBase 的流量会平缓很多。
经验和教训
几经辗转,终于找到问题原因所在(离解决问题还有距离),下面是我的几点感受:
- 解决问题之前,要能够稳定重现,找到真正的问题所在,不能停留在表面,如果不进行几个小时的 HBase 读操作监控,不会发现整点暴涨持续半小时然后回落的问题;
- 系统的运行环境很复杂,必要的时候要想办法把问题隔离到影响因素更少的环境中,更容易发现问题,比如性能监控平台各组件的混合部署给机器间的流量分析造成了困难;
- 使用开源软件,最好能深入了解下运行机制,用起来才得心应手,不然出了问题就很麻烦,这次的排查过程让我更加详细的了解了 OpenTSDB 的运行机制;
至此,本文完~
OpenTSDB 造成 Hbase 整点压力过大问题的排查和解决相关推荐
- window电脑C盘占用过大问题的几种解决方法
文章目录 C盘占用过大问题的俩种解决方法 原因一.临时文件过大: 原因二.(我自己用的pycharm软件缓存过大): 原因三.新增的其他博客方法: 方法四.删除window更新文件(这个一旦删除,无法 ...
- OpenTSDB存储Hbase原理
OpenTSDB在部署的时候会执行create_table.sh这个初始化脚本,这个脚本的作用是在Hbase中创建4张表 这4张表,OpenTSDB主要使用其中的2张表 tsdb:存储插入数据的时间戳 ...
- 安装Hbase(分布式)遇到一些问题及解决方法
问题一:安装完成后在Hbase shell 命令行执行list命令时,爆出如下错误: hbase(main):001:0> list TABLE SLF4J: Class path contai ...
- [解决] HiveServer2中使用jdbc访问hbase时导致ZooKeeper连接持续增加的解决
最近在监控中发现HiveServer2连接到zookeeper里的连接持续上涨,很奇怪,虽然知道HiveServer2支持并发连接,使用ZooKeeper来管理Hive表的读写锁,但我们的环境并不需要 ...
- hbase 做陌陌数据处理(问题及解决 一 )
目录 问题一 Failure to find org.glassfish:javax.el:pom:3.0.1-b06-SNAPSHOT in https://rep..... 问题二. 创建命名空间 ...
- HBase报错server is not running yet解决方法
问题描述 尝试安装Hadoop 3.3.1与HBase 2.3.5,安装并配置完成后,Hadoop正常运行,HBase启动Shell后运行list指令测试,出现如下错误 ERROR: org.apac ...
- Hadoop-HBASE案例分析-Hadoop学习笔记二
之前有幸在MOOC学院抽中小象学院hadoop体验课. 这是小象学院hadoop2.X概述第八章的笔记 主要介绍HBase,一个分布式数据库的应用案例. 案例概况: 1)时间序列数据库(OpenT ...
- Redis中AKF原则的应用
Redis 单机 .单节点.单实例 缺点:1. 单点故障(一台服务如果挂了,整个系统不可用了)2. 容量有限3. 压力 过大 为了解决 单机的 问题 ,引入了AKF 原则 AKF X轴:直接水平复制应 ...
- OpenTSDB介绍——基于Hbase的分布式的,可伸缩的时间序列数据库,而Hbase本质是列存储...
原文链接:http://www.jianshu.com/p/0bafd0168647 OpenTSDB介绍 1.1.OpenTSDB是什么?主要用途是什么? 官方文档这样描述:OpenTSDB is ...
最新文章
- 使用Java和JSF构建一个简单的CRUD应用
- select选中的值_selenium下拉框处理(select)
- VC2008下使用OpenSSL 1 0 0g 免编译
- Codeforces 1163A - Eating Soup
- http status code —— http 状态码
- linux ios文件是否存在,技术|如何在 Linux 中验证 ISO 镜像
- vue之vue-cookies
- 如何让 Mac 加入网络帐户服务器?
- Redis基本命令及相关用法
- App_Code 目录
- CentOS 6.7安装gcc4.8.2
- 别花时间抠图了,赶紧试试这几个免抠图的PNG图片网站!
- 【实战 01】心脏病二分类数据集
- 计算机中安装音乐软件是一种,电脑必装的八款软件,你装了吗?
- ios获取本地音乐库音乐很详细
- 计算机安装xp蓝屏怎么办,xp蓝屏,详细教您教你怎么修复xp蓝屏问题
- python爬虫爬取深交所数据
- 播布客教学视频_C学习笔记_8.2_统计1到100中9的个数(函数)
- 阿里云高主频通用型hfg7云服务器磁盘I/O性能表详解
- Unity3D-VR《静夜诗》5-李白吟诗
热门文章
- Azure SQL 数据库:服务级别与性能问答
- C#快速导入海量XML数据至SQL Server数据库
- GARFIELD@10-07-2004
- Linux平台gcc和动态共享库的基础知识
- UDT源码剖析(五):UDT::cleanup()过程代码注释
- 2019 高考填报志愿建议
- .net的label的背景如何设置成为透明_css如何设置背景图片?background属性添加背景图片...
- jstl 获取 javascript 定义的变量_前端开发大牛完整总结出了JavaScript 难点 +最新web前端开发教程...
- bp神经网络预测_股指期货价格变动趋势往往反映的是股票价格的走势,因此BP神经网络对股指期货价格的准确预测就是对股票价格的准确预测。...
- LeetCode MySQL 1581. 进店却未进行过交易的顾客