带你玩转Logview: MaxCompute Logview参数详解和问题排查
Logview是MaxCompute Job提交后查看和Debug任务的工具。通过Logview可看到一个Job的运行状态、运行结果以及运行细节和每个步骤的进度。当Job提交到MaxCompute后,会生成Logview的链接,用户可以直接在浏览器上打开Logview链接,进入查看Job的信息,而对于Logview上的诸多参数信息,究竟应该怎么“拨开云雾”,发现问题所在呢?又如何通过Logview了解每个instance、task运行状态及资源占用情况,如何分析执行计划,分析query存在问题,找到Long-Tails task,让数据分析业务高效又省钱呢?本文中,阿里巴巴计算平台产品专家云花将为大家揭晓答案。
直播视频回看,戳这里!https://yq.aliyun.com/webinar/play/484
分享资料下载,戳这里!https://yq.aliyun.com/download/2953
更多精彩内容传送门:大数据计算技术共享计划 — MaxCompute技术公开课第二季
以下内容根据演讲视频及PPT整理而成。
本文将主要围绕以下4个方面进行分享:
- 什么是Logview
- 相关概念和原理
- Logview参数详解
- 使用Logview排查问题
很多用户在使用MaxCompute的时候会遇到一些问题,但是却苦于不知道如何去定位这些问题,也不知道应该如何进行优化。因此,本文整理了一些Logview参数以及问题定位的相关知识与大家分享。
一、什么是Logview?
Logview是一个在MaxCompute上提交任务之后用来查看和Debug任务的工具,大家可以通过Logview看到任务的运行状态,包括任务的排队情况以及资源的使用情况,甚至在每个节点上Instance运行的细节及其进度。当提交的任务出错了或者运行时间过长,就可以借助Logview分析具体的原因,进而对任务进行精准优化。
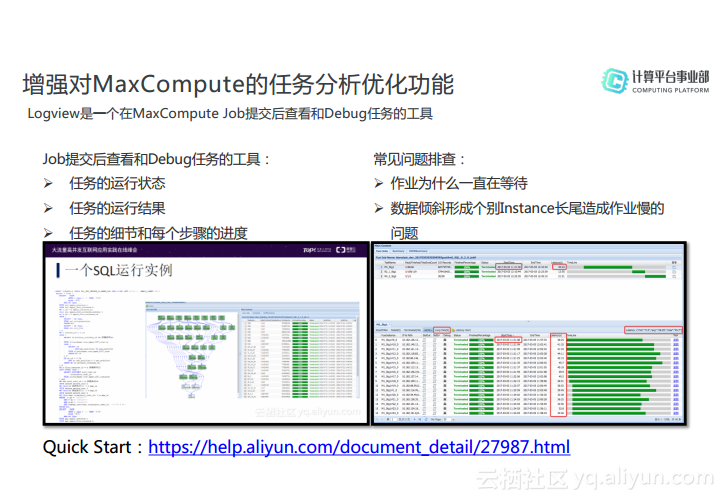
二、相关概念和原理
在使用Logview的时候可能会遇到很多名词,这些名词都是MaxCompute特有的,因此在本部分中也进行简单介绍,帮助大家更好地理解Logview的运行原理。
MaxCompute系统架构
如下图所示的是MaxCompute的系统架构。从上往下看,首先最上层就是数据源和客户端接入的部分,各种外部数据源都可以通过外部传输的工具如Tunnel以及DataHub将数据同步到分布式文件存储系统盘古中。在客户端,用户可以使用命令行工具、MaxCompute Studio以及DataWorks等开发完任务提交之后,以Restful API形式提交到HTTP服务,当HTTP服务接收到请求之后,先向用户中心做身份鉴权,因此整个接入层其实承载了数据上传下载、用户鉴权以及负载均衡等工作。接入层之下就是管理层,这也是MaxCompute最为核心的部分,这部分负责对用户空间和对象的管理、命令的解析与执行、对象的访问控制以及授权等功能,其主要有三种角色,即Workers、Scheduler以及Executor。MaxCompute的元数据其实是存储在阿里云开放服务——分布式元数据服务上。
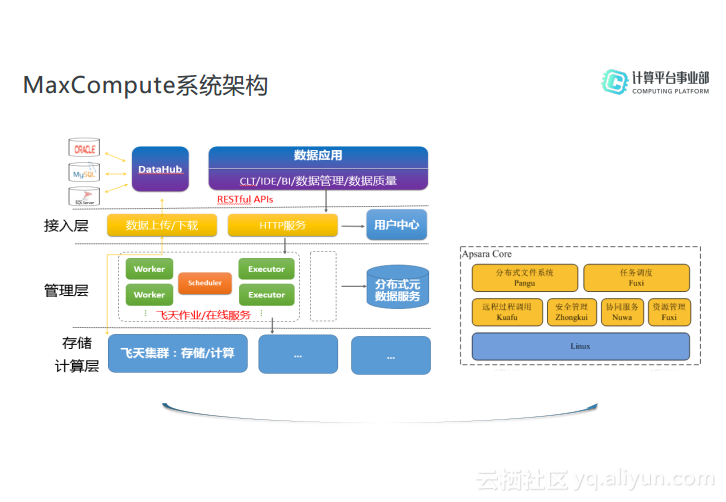
MaxCompute的计算集群就是架构在飞天系统之上的,而飞天系统的核心模块包括了分布式文件存储系统盘古、分布式资源调度系统伏羲、分布式协同服务女娲以及分布式监控系统神农、远程过程调用系统夸父、以及安全管理系统钟馗等。以上就是MaxCompute的基础架构,其最核心和复杂的逻辑就在管理层与伏羲之间的任务调度和管理。
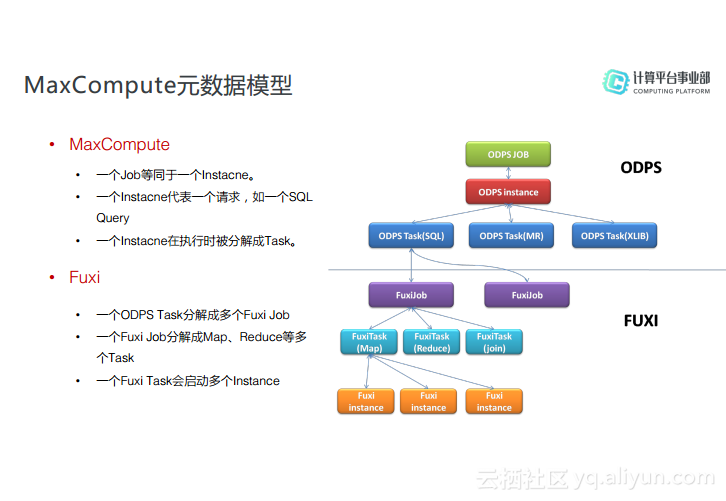
MaxCompute元数据模型
其实MaxCompute以前还有个名字叫做ODPS,从2016年开始ODPS正式改名为MaxCompute,所以其实在Logview中出现的ODPS字样其实就是指MaxCompute。MaxCompute最常见的两种对象就是Job,也就是Instance,另外一个就是ODPS Task。比如当提交一个SQL Query的请求,系统就会创建一个Instance,而当这个Instance在MaxCompute上执行的时候就会被分解成多个Task,但是多数情况下Instance与Task是一一对应的。这个Task有SQL类型的、有MR类型的,还有机器学习的。而在底层的分布式系统Fuxi上面也有Job和Task和Instance的概念,而这些需要和MaxCompute上的Task以及Instance的概念区分清楚。当ODPS Task提交到服务器上之后,每个Task会被分解成为多个Fuxi Job,而每个Fuxi Job会根据执行计划分解成不同的执行阶段,比如Map、Reduce以及Join等。而每个Task又会启动多个Instance来执行,相当于启动多个节点。
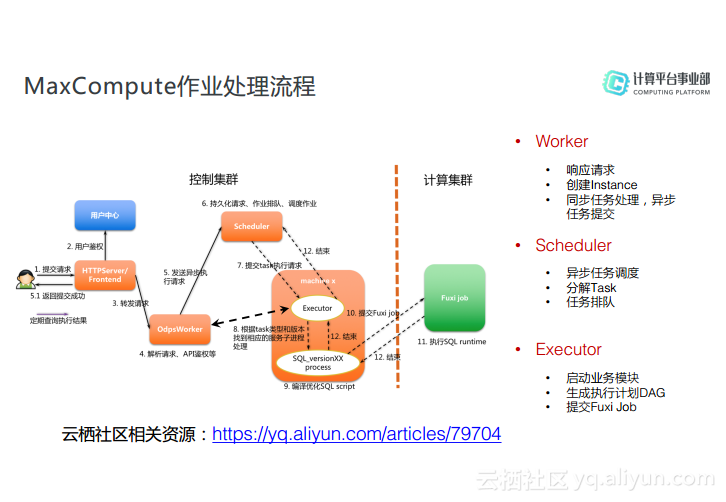
MaxCompute作业处理流程
首先,用户会在客户端提交一个SQL语句,客户端会通过Restful API形式提交到HTTP服务,HTTP服务的前端接收到这个请求之后会先去用户中心做鉴权,通过鉴权之后会根据所在集群信息转交给MaxCompute相应的Worker去执行。Worker则会解析这个请求,首先做API的鉴权,有了权限之后才会响应请求。Worker会判断作业类型,一种是同步任务,也就是说当Worker自己执行完就可以返回,比如SQL DDL以及Job的查询状态等,Worker会访问OTS获取元数据信息,然后交给Executor执行,执行完成之后就直接返回给客户端。另外一种是异步任务,所谓异步任务就是对后续节点进行处理,需要提交到Fuxi去处理的任务,比如SQL的DML或者MR这类的任务请求。Worker会创建一个Instance然后交给Scheduler去执行,Scheduler负责对所有异步任务的调度,它会把Instance分解为Task并做全局的计算调度。当所有资源以及条件都满足Scheduler就会将Task交给Executor进行执行,Executor上其实封装了各种业务逻辑,比如SQL以及算法模块,Executor会根据不同的作业类型拉取不同的作业模块。当Executor空闲的时候会向Scheduler进行心跳上报并请求任务,当其拿到任务之后会根据任务类型启动一个相应的业务模块来执行。Executor会生成一个任务的执行计划,并将任务以及执行计划一起交给Fuxi进行执行。有时候提交到Fuxi的任务会出现回退的情况,比如第一次是按照Online Job的作业类型来提交的,到Fuxi之后可能会提交失败并回退到Scheduler,然后按照Offline的方式再提交一次,这样就会在Logview看到对应的情况。当Executor将Task提交给Fuxi之后,还会去监控Task的执行状态,当执行完成之后则会更新OTS里面的Task信息并汇报给Scheduler,Scheduler则会判断整个Instance是否执行完毕,如果执行完毕也会去更新OTS中的Instance信息,将其设置为Terminated,以上这些就是完整的作业处理流程。
三、Logview参数详解
分享完基本概念和理论之后就可以介绍Logview的参数了。主要的信息包括ODPS Instance,其涵盖了队列信息以及子状态信息,另外一部分包括Fuxi Job,这可以进一步拆解成Task信息和Fuxi Instance信息。在整个任务结束之后可以看到其Summary以及Diagnosis诊断信息,此外还有上传下载的小功能。
ODPS Instance信息
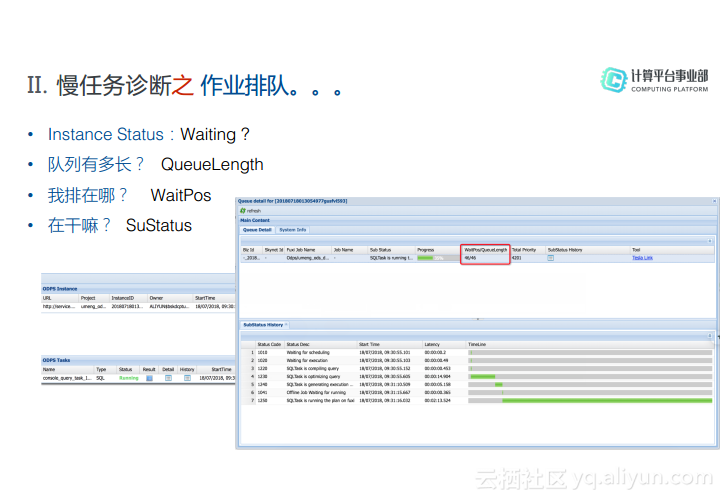
下图中最上面的表中有这样的几个字段:URL、Project、InstanceID、Owner、StartTime、EndTime、Latency、Status以及Process等。URL是Endpoint的地址,Project存放项目的名称,InstanceID其实是时间戳跟着随机字符串,这个时间戳是精确到毫秒的,而这个时间是UTC时间,与电脑提交任务的时间是不一致的。StartTime和EndTime分别是任务开始和结束的时间,Latency则是任务运行所消耗的时间。而对于Status而言,则有四种状态:Waiting状态代表任务正在ODPS中处理,还没提交到Fuxi中运行;Waiting List代表任务已经到了Fuxi,并且在Fuxi中排队,N代表排队的位置;Running代表在Fuxi中运行;Terminated代表运行已经结束了。在表格里面,只要Status不是Terminated的状态,只要双击就能打开Queue Detail和SubStatus History详细信息。
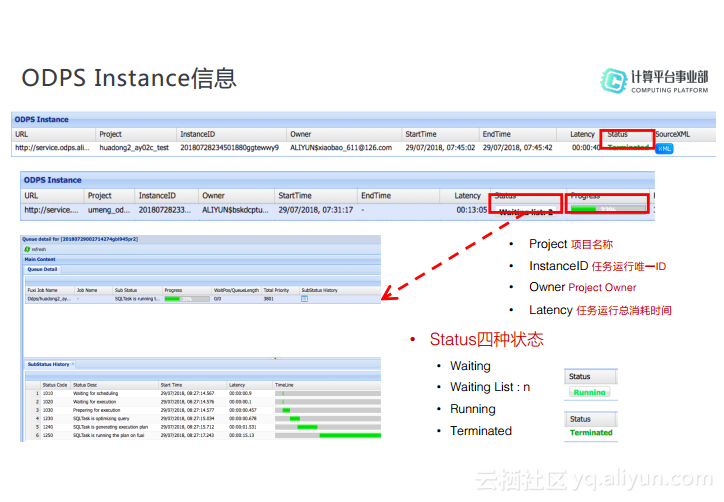
Queue Detail&SubStatus History信息
如下图所示最上面的Table是关于队列的信息,首先是Fuxi Job的name,SubStatus则是目前Job的运行状态,Progress是目前的执行进度。红框里面有两个字段,分别是WaitPOS和QueueLength,前者是目前排队的位置,后者是队列长度,根据这两个字段就能看到整个队列里面有多少任务在排队,这个任务排在第几位。Total Priority是其优先级,点击SubStatus History的图标可以打开下图中下侧的Table。对于SubStatus History而言着重介绍一下SubStatus Code以及其含义,在下图中列出了一些常见的SubStatus Code以及其对应含义。
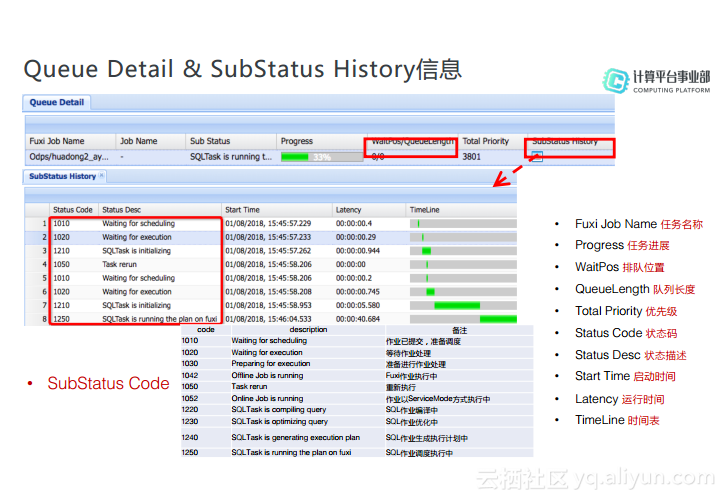
Fuxi Job的两种作业类型
前面也提到了Fuxi Job有两种作业类型,分别是Online Job和Offline Job,这两种Job到底有什么区别呢?首先,对于Offline的作业而言,当每次提交作业时在Fuxi上都会有一个环境准备的时间,对于大数据量并且不需要返回查询结果的作业比较合适。而对于小数据量并且实时作业要求比较高的作业是不合适的。所以Fuxi提供了Service Mode这种准实时的作业形式,首先会有一个服务去预先申请计算一些资源并加载出来,比如会预先分配一万个Instance,当有作业提交过来的时候会根据作业规模分配一些Instance进行执行,这样就省去环境准备的时间,所以就会比较快,这就是两种类型作业的主要差异。
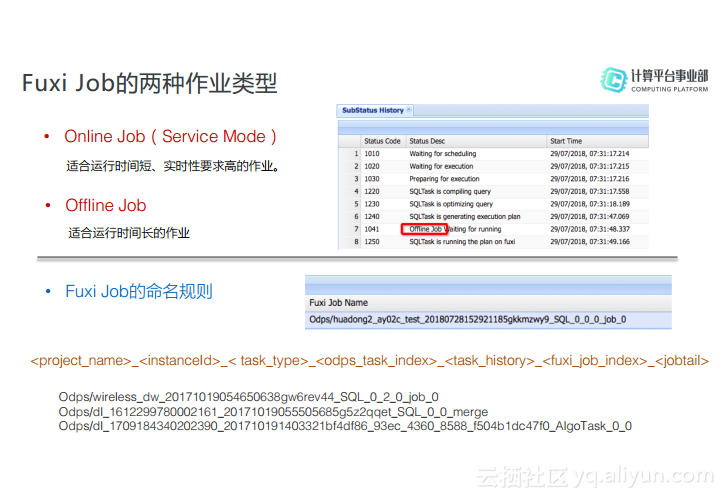
对于FuxiJob的命名规则而言,如上图所示“odps/”后面的部分就是:
<project_name>_<instanceId>_<task_type>_<odps_task_index>_<task_history>_<fuxi_job_index>_<jobtail>。
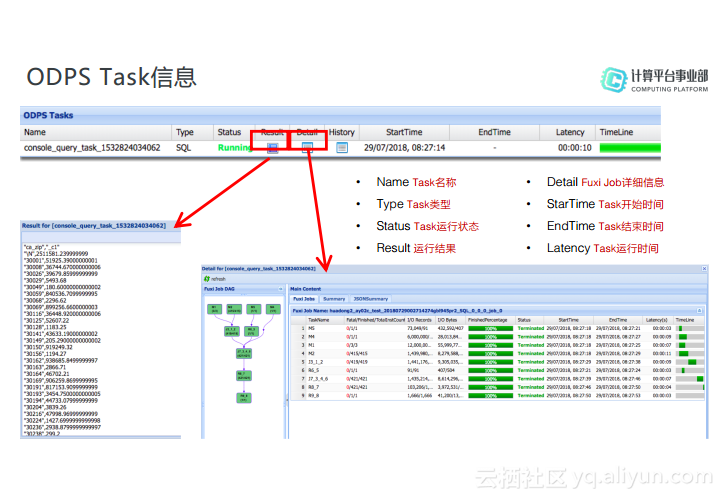
ODPS Task信息
如下图所示的是ODPS Task信息,上面的表格的第一个字段是TaskName,Type指的是作业类型,Status指的是运行状态,双击Rusult会输出作业的整个结果集,双击Detail信息则会打开整个Fuxi Job的详细Table。
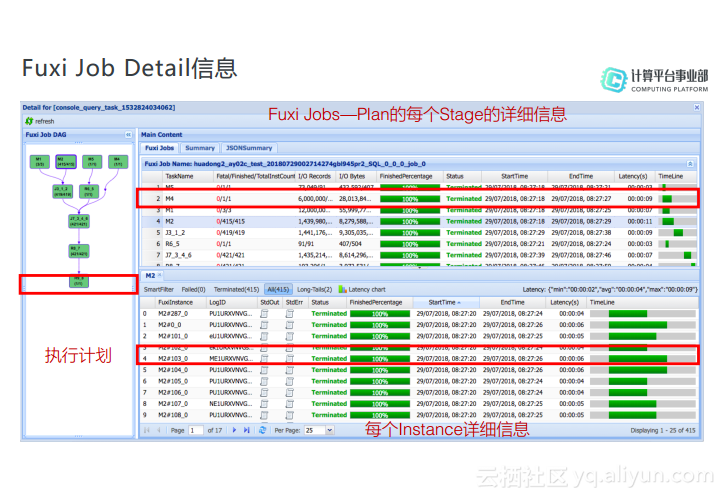
Fuxi Job Detail信息
Fuxi Job详细信息主要分为三个部分,最左侧是任务的执行计划,这个执行计划是在Executor里面生成的,执行计划就是将一个任务分成不同的Stage来执行,每个Stage的都可以看做一个图上的点,而Stage之间的依赖关系就可以看做图的边,这样就构成一个有向无环图。在下图例子中,将Fuxi Job分解成了四个Map的Task,两个Join的Task,还有3个Reduce的Task。举例而言,对于J3_1_2这个Task而言,需要在M1和M2执行完成之后才会执行,也就是说M1和M2的输出就是J3_1_2的输入,并且在名字上也可以体现其依赖关系,也就是说命名其实是和执行计划相关的。下图中右上方这部分就是每个Task的详细信息,也是每个Stage的详细信息。图中下面部分则是每个Instance的详细信息。
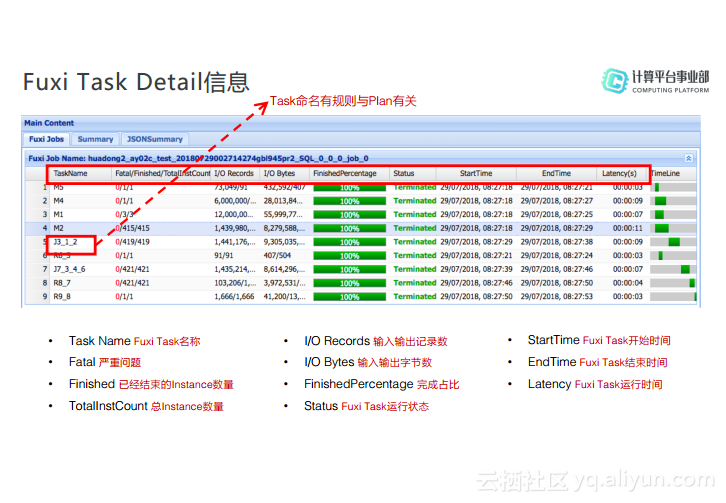
Fuxi Task Detail信息
对于Fuxi Job Detail信息而言,又有哪些需要关注呢?第一个字段就是TaskName,其和执行计划的生成是相关的。后面的字段Fatal/Finished/TotalInstCount,在表格里面Fatal表示严重错误个数,因此被标红了;Finished表示已经结束的Instance的个数,后面的TotalInstCount指的是为每个Task启动的总Task数量。下一个字段I/O Records指的是输入和输出的记录的个数,I/O Bytes指的是输入和输出的字节数。FinishedPercentage指的是进度条,Status则指的是每个Task的运行状态。
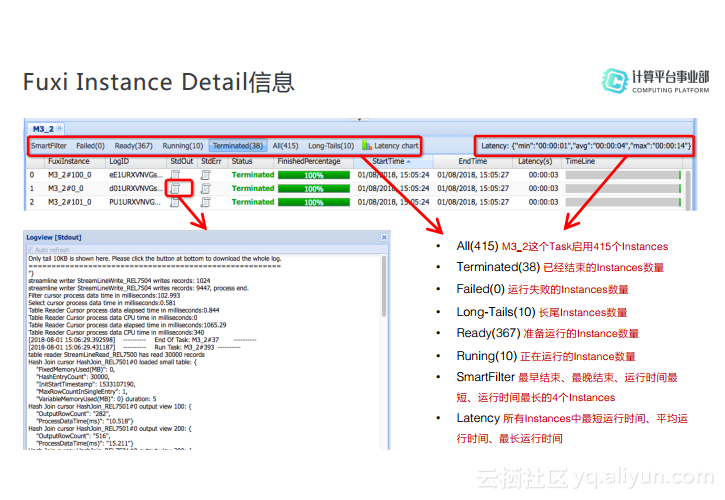
Fuxi Instance Detail信息
Fuxi Instance是整个作业流中最小的颗粒,在如下图所示的Demo中是一个Map的作业详细信息。首先看All字段,这个字段后面有一个数字415,这说明为M3_2这个Task启动了415个Instance,其左侧的Terminated、Running、Ready以及Failed分别是相应状态的实例个数。而SmartFilter则会给出最早结束、最晚结束、运行时间最短和运行时间最长的四个Instance,将其筛选处理方便观察。Latency Chart则是以图表的形式展示所有的Instance的运行时长分布,而在Latency里面则是最长运行时间和最短运行时间以及平均运行时长,其实这三个时间对于分析长尾任务是非常有用的。在每个Instance的表格里面详细信息里面有一个StdOut,这是每个Instance在执行过程中打印的信息,而StuErr则是当Instance失败的时候可以用来查看出错原因的。
Fuxi Job Detail信息 之 Summary信息
FuxiJob的Summary是在整个Job运行完之后才能查看的信息,主要包括Job消耗的CPU、内存、Job输入的表名以及记录数和字节数。此外,Job的运行时间单位是秒。Fuxi Task的Summary信息则主要包括Instance数量、Task运行时间、所有Instance里面的最大、最小和平均运行时间。

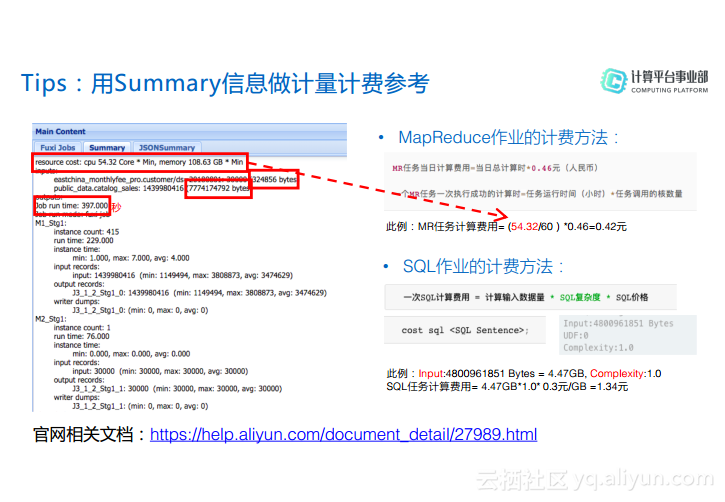
Tips:用Summary信息做计量计费参考
这里与大家分享一个Tips,就是如何用Summary信息做计量计费参考,比如在这里执行的是一个MapReduce作业,其计费方法是MR任务当日计算费用=当日总计算时*0.46元(RMB),则任务的计算时=任务运行时间(小时)*任务调用的核数量。而在Summary信息里面就能够直接拿到CPU的计算时,而不需要用公式计算了。而对于SQL计算而言,计算公式为:一次SQL计算费用 = 计算输入数据量 * SQL复杂度 * SQL价格。而输入数据量与SQL复杂度都能够通过cost sql <SQL Sentence>这个命令来计算。对于计量计算而言,更多的内容请参考官网上的信息。
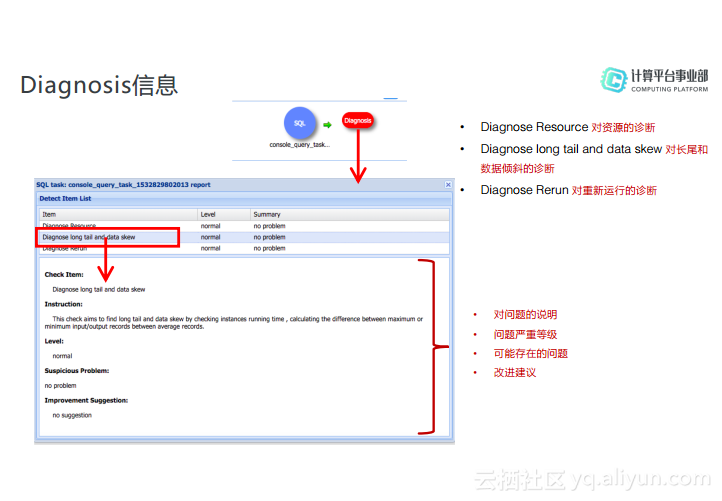
Diagnosis信息
Diagnosis是诊断信息,其是在作业执行完成之后可以点击小红点进而打开如下图所示的表格。Diagnosis主要会诊断三类信息,分别是对资源的诊断、对数据倾斜的诊断以及对重新运行的诊断,每类信息会给出对于问题的说明和问题严重等级,并且会给出改进意见。
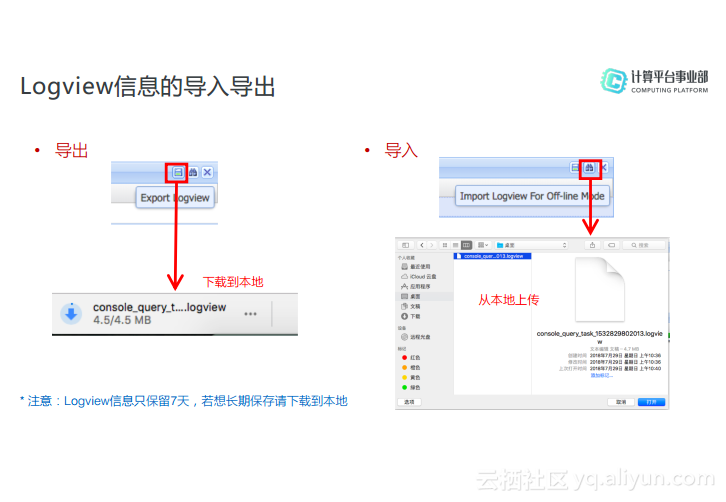
Logview信息的导入导出
Logview的信息可以导入和导出,因为其信息只能在系统中保留7天,如果想要长期保存就需要导出信息。大家可以点击Logview右上角的小图标将Logview信息保存到本地,当需要分析的时候再点击“望远镜”小图标,从本地将Logview信息上传上去就可以还原出Logview的信息。
四、使用Logview排查问题
常见的问题有这样几种,首先就是任务一直在排队等待或者任务直接运行失败了,而最常见的情况就是任务执行时间太长了,一直跑不完。其实大多数慢任务的原因都是因为长尾,而大多数长尾都是因为数据倾斜带来的。这不仅将会影响数据分析结果的产出,还会拉高数据资源的消费,因此对于这种情况必须要进行优化。
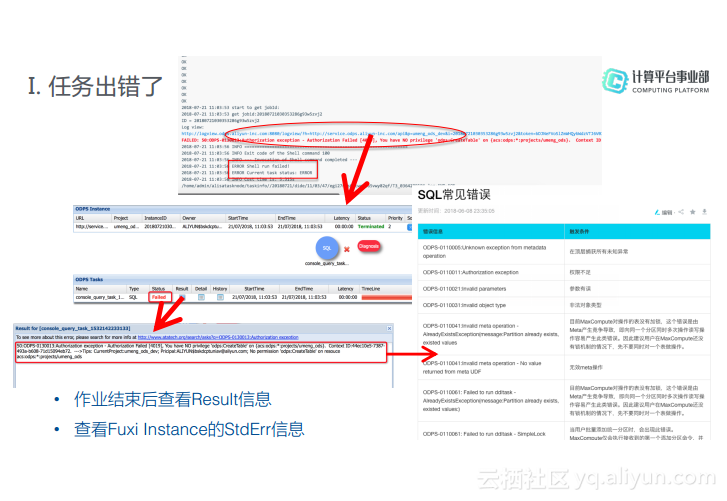
1. 任务出错了
对于出错任务而言,从控制台输出就可以看到出错的原因,如果想要查看更加详细的信息,则可以打开Logview去查看ODPS的Result信息,如果失败了可以看到Status变成红色了。当双击Result之后就可以看到报错输出的整体信息。在出错信息里面会有错误码,而错误码与详细错误的对照表可以在官网找到。所以查看出错任务的方式有两种,一种是在作业结束之后查看其Result信息,另外一种方式则是去查看Instance的StdErr信息。
2. 慢任务诊断
(1) 作业排队
对于慢任务诊断而言,可能看到一种现象就是作业一直在排队或者在控制台看到Fuxi Job一直在Waiting。进一步在Logview里面查看,发现Status到底是Waiting还是Waiting List,这样就可以发现其到底在哪里排队,如果状态是Waiting List则可以进一步地看其详细队列长度到底是多少,排到了第几位。还可以在SubStatus里面看到其子状态的信息。
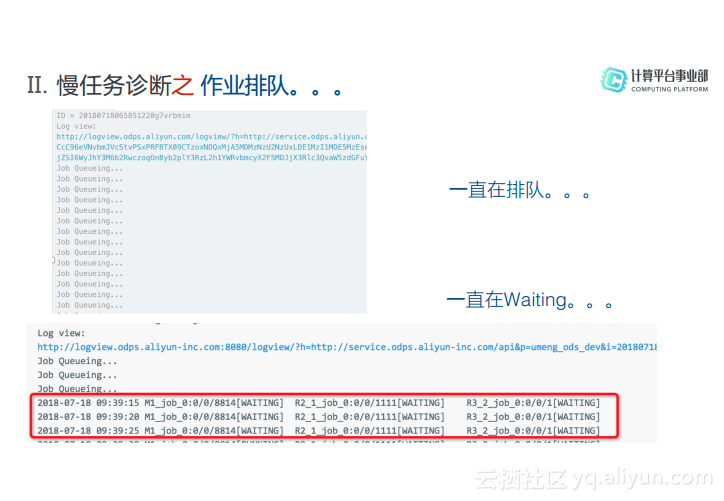
对于慢任务而言,很多用户反映不能够知道到底是哪一个作业是慢任务,因此在这里为大家介绍两种查看慢任务的方法:一种是“show p”,可以查看所有示例信息;而“top instance”可以查看当前正在执行的作业,而运行时间最长的作业可能就是阻塞队列导致其他任务排队的任务。对于由于资源抢占所导致的问题,可以做如下的优化:
- 对于后付费用户而言,可以根据作业特性把相对稳定的周期性常规任务放到预付费资源组去执行,可以保证资源不被抢占。
- 对于预付费用户而言,如果并行执行多个作业,最好合理安排作业执行时间,让作业错峰执行,临时任务则建议在后付费资源组执行。而关于作业排队的原因分析,可以参照云栖社区的一些相关资源文档。
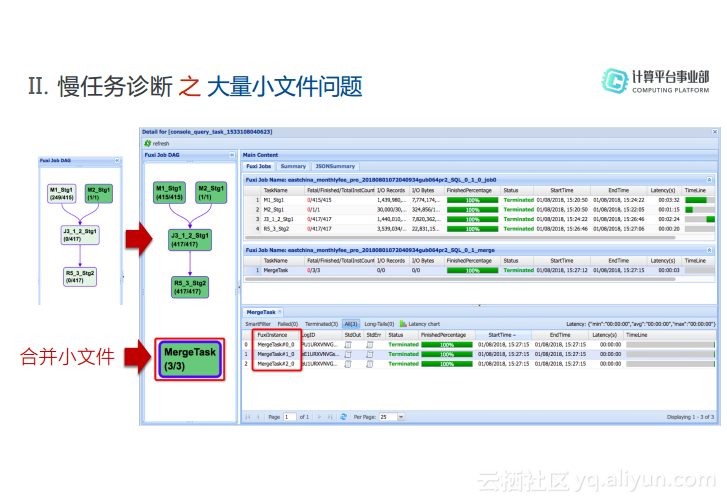
(2) 大量小文件问题
大量小文件的存在也会导致任务执行很慢,比如在作业开始执行的时候,执行计划可能如下图中第一张所示,有两个Map以及一个Join还有一个Reduce,当Reduce的Task执行之后,发现系统自动增加一个MergeTask,这就是因为系统在做合并小文件的操作。
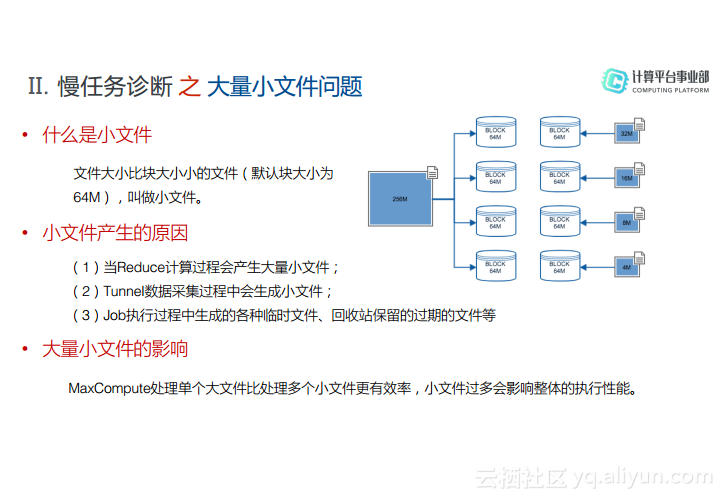
其实,分布式文件系统的数据文件是按照块来存储的,盘古的块大小就是64M,所以如果文件小于64M就可以称为小文件。小文件的产生主要有这样的3种原因:(1)当Reduce计算过程中会产生大量小文件;(2)Tunnel数据采集过程中会生成小文件;(2)Job执行过程中生成的各种临时文件、回收站保留的过期文件等。而因为小文件过多,就会导致在Map阶段读取的数据出现分布不均匀的情况,进而引起长尾。如果存在大量的小文件,除了会浪费资源并降低磁盘空间利用率之外,还会影响整体的执行性能,因此从存储和性能两方面考虑都需要将计算过程中的小文件都合并。其实MaxCompute系统已经做了很多的优化,系统会自动分配一个Fuxi的MergeTask来做小文件的合并,但是其实还有很多情况下产生的小文件没有被合并。因此,MaxCompute提供了一些参数帮助用户进行小文件的合并。
首先可以查看小文件的数量,也就是判断自己的表里面是否存在很多小文件。可以用“desc extended TableName”命令就可以输出小文件数量。如果小文件数量很多就可以通过如图中下面的SQL来整合小文件。
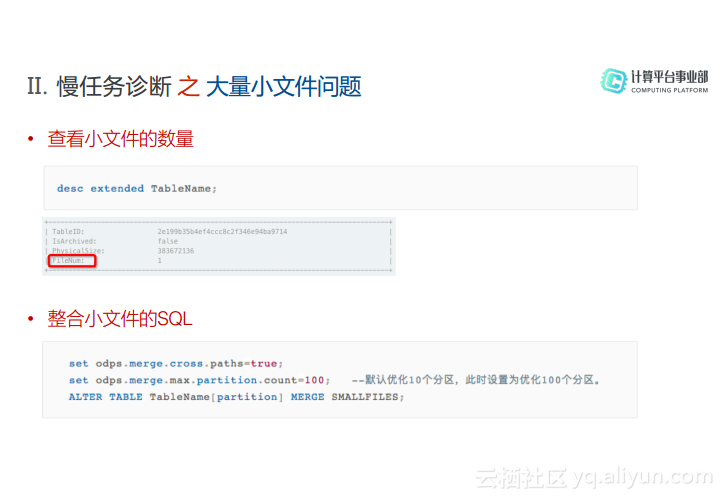
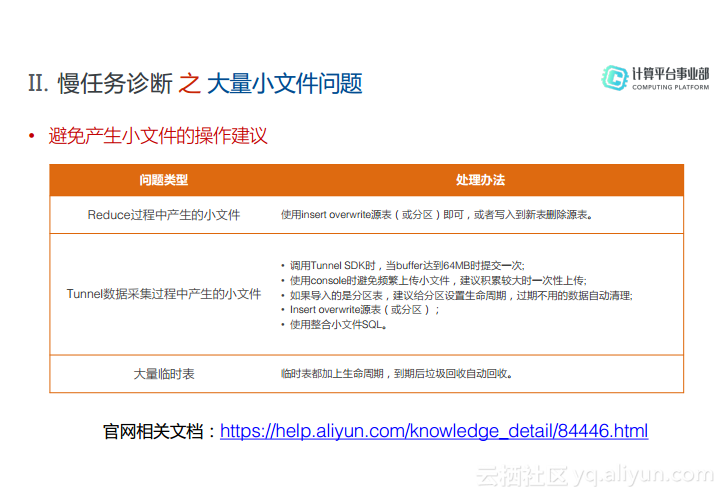
为了避免小文件的操作,可以给出一些相关建议。比如在Reduce过程中产生的小文件建议可以使用insert overwrite向原表写入数据,或者把数据写入新表之后,将原表删除。其次,为了避免在Tunnel的数据采集过程中产生小文件,可以调用Tunnel SDK。也就是在上传数据的时候最好等到Buffer达到64M的时候再进行提交,不要过于频繁地进行提交。在导入分区表的时候建议为表设置生命周期,对于过期的数据可以进行自动清理。而针对大量临时表的情况,也可以加上生命周期,到期之后进行自动回收。对于小文件的优化,在官网文档中也有更加详细的介绍。
(3)数据倾斜导致长尾任务
数据倾斜导致长尾任务也会导致慢作业。其实数据倾斜就是因为数据分布不均匀,少数的Fuxi Instance处理的数据量远远超过其他的Instance,因此导致长尾任务。在MaxCompute的Logview里面,将鼠标放在Longtails标签上面就可以看到提示“Latency is more than twice average”,也就是说运行时间超过平均的两倍,就将其定义为长尾任务。
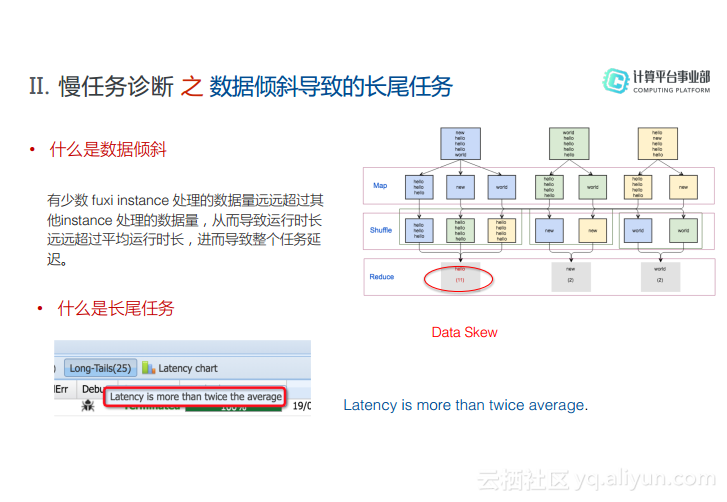
通过Logview有两种方式查看其是否属于长尾任务,第一种方法就是查看Long-Tails的Fuxi Instances的Max Lantency。如果括号里面的数量大于0,那就说明已经出现了长尾,点击标签之后就会将所有长尾Instance列出来,并且可以查看其各种信息。另外一种查看长尾任务的方法就是查看Fuxi Job的Summary信息以及Diagnosis信息,通过分析Summary可以查看长尾分布在哪个阶段。如果instance time的max和avg两个值相差很大就说明出现了长尾;而对于input records而言,如果输入数据量的max和avg相差也很大就说明发生了数据倾斜。在Diagnosis信息里面专门有一项是检查数据倾斜和长尾的,所以通过系统所给出的信息就能够查看出是否出现了长尾还是数据倾斜,也同时给出了一些改进意见。
最后与大家分享对于不同种类的数据倾斜分别可以做哪些优化。在Join阶段出现的数据倾斜是因为Join Key分布不均匀,导致某一个Key的值数据量特别大,会被分配到同一个Instance上进行处理,这个Instance处理时间就会比较长,因此造成长尾。比如用一个大表来join一个小表或者在key中有大量的空值都会造成Join阶段的数据倾斜,对于这种情况可以使用Map Join进行优化,其原理是将Join操作提前到Join阶段进行,其实就是将小表里的数据加载到执行Join操作的程序内存中,所以就加速了Join的执行,而Map Join比普通Join性能要好很多,对于有空值的情况,建议先过滤掉空值然后补上随机数,相当于对Key做重新分配,然后再进行Join。第二种则是由于Group By导致的数据倾斜,其产生原因也是由于Group By后面的Key分布不均匀导致的,这里有两种优化方法,一种是设置方倾斜的参数,另外一种则是对Key加上随机数进行重新分配。第三种是由于使用Distinct造成的数据倾斜,由于Distinct是对于字段做去重的操作,那么这样就没办法在Map的Shuffle阶段就根据GroupBy做一次聚合操作来减少数据传输,它只能将所有的数据全都传入到Reduce端来处理,所以当Key的数据发生了不均匀的时候就会导致Reduce端出现长尾,针对这种情况可以用Count + GroupBy代替Distinct。最后一种就是由于动态分区带来的长尾,如果动态分区过多的时候就可能造成小文件过多,而为了整理小文件,系统会在启动一个Reduce的Task对数据进行整理,如果动态分区写入数据有倾斜就会产生长尾,在这种情况下就尽量不要使用动态分区,在insert的时候最好指定相应的分区。对于优化这部分,大家也可以在官网上找到更加详细的链接。

原文链接
本文为云栖社区原创内容,未经允许不得转载。
带你玩转Logview: MaxCompute Logview参数详解和问题排查相关推荐
- Linux系统内核介绍及Linux系统运行级别,uname,vmstat,top命令参数详解 和一些排查案例
Linux系统内核:内核是操作系统的核心,有很多基本功能,负责管理系统的进程 内存设备驱动程序 文件和网络系统,决定着系统的性能和稳定性 Linux内核相关介绍: 内存管理(Linux采用虚拟内存) ...
- python传入参数加星号_Python 带星号(* 或 **)的函数参数详解
1. 带默认值的参数 在了解带星号(*)的参数之前,先看下带有默认值的参数,函数定义如下: >> def defaultValueArgs(common, defaultStr = &qu ...
- VS自带工具:dumpbin的参数详解
VS自带工具:dumpbin的参数详解 参考链接: 1.微软技术文档 2.微软官方文档描述](https://docs.microsoft.com/zh-cn/cpp/build/reference/ ...
- 至强cpu型号列表_装机必看——CPU型号参数详解
装机必看--CPU型号参数详解 --装机个人练习生-海 在初步解了电脑构成后,我们DIY装机首先要看的就是如何选CPU,今天就带大家详细学习CPU的各类数据. 说到CPU,我们先来介绍下生产CPU的两 ...
- Nginx内置变量以及日志格式变量参数详解
Nginx内置变量以及日志格式变量参数详解 $args #请求中的参数值 $query_string #同 $args $arg_NAME #GET请求中NAME的值 $is_args #如果请求中有 ...
- C语言 printf格式化输出,参数详解
有关输出对齐 int main(int argc, char* argv[]) { char insertTime[20] = {"1234567890"}; double i ...
- Lesson 8.1Lesson 8.2 决策树的核心思想与建模流程CART分类树的建模流程与sklearn评估器参数详解
Lesson 8.1 决策树的核心思想与建模流程 从本节课开始,我们将介绍经典机器学习领域中最重要的一类有监督学习算法--树模型(决策树). 可此前的聚类算法类似,树模型也同样不是一个模型,而是一类模 ...
- 系列 《使用sklearn进行集成学习——理论》 《使用sklearn进行集成学习——实践》 目录 1 Random Forest和Gradient Tree Boosting参数详解 2 如何调参?
系列 <使用sklearn进行集成学习--理论> <使用sklearn进行集成学习--实践> 目录 1 Random Forest和Gradient Tree Boosting ...
- 【Nginx】Nginx配置文件参数/启动参数详解;启动/停止/重新加载配置命令
nginx配置文件 nginx及其模块的工作方式是由配置文件指定,默认情况下配置文件被命名为nginx.conf并且存放在/usr/local/nginx/conf或者 /etc/nginx或者 /u ...
最新文章
- Digital Imaging Processing 数字图像处理
- 神策数据丨九大行业数字化经营指南集锦,值 100% 收藏
- Redis的事务:相关命令 watch 与mysql事务的区别
- PHP的JSON封装
- Spring整合Quartz定时任务 在集群、分布式系统中的应用
- SSO单点登录系列1:cas客户端源码分析cas-client-java-2.1.1.jar
- linux基础(二)——linux各文件夹含义和作用
- 职场 | 算法是怎样决定你的职业生涯的
- 9.ansible变量之fact
- UserWarning: findfont: Font family [‘sans-serif‘] not found. Falling back to DejaVu Sans
- 新浪微博批量登录获取cookie
- 基于Cesium搭建单体化平台全流程简单记录
- SlideShow Pro(幻灯片制作)v5.0.0.10绿色中文版
- 1628 Pizza Delivery
- pandas 根据筛选条件对指定excel列进行筛选
- 【计算机组成原理】IEEE 754
- 9、Vue自定义指令
- 史上最接地气的国外穷游攻略
- 电脑网易我的世界进服务器未响应,我的世界网易版进不去解决方法 MC网易电脑端进不去原因...
- windows 查找目录下文件中包含某个字符的文件
热门文章
- java密码框提示_[Java教程]如何实现在密码框如出现提示语
- 【LeetCode笔记】剑指 Offer 56 . 数组中数字出现的次数(Java、位运算)
- c语言中把各位上为奇数的数取出,下列给定程序中函数fun()的功能是:将长整型数中每一位上为奇数的数依次取出,构成一个新数放在冲。 - 赏学吧...
- go struct 静态函数_Go语言学习笔记(四)结构体struct 接口Interface 反射reflect...
- bat循环执行带参数_wxappUnpacker的bingo.bat脚本逐行解读
- 隐藏鼠标指针_Mac鼠标光标消失怎么办?苹果电脑鼠标指针不显示的解决方法
- c 子类对象 访问父类对象受保护成员_java面向对象总结
- 十年积累,5.4万GitHub Star一朝清零:开源史上最大意外损失
- 国际空间站20年花掉超千亿美金,一些人开始觉得它“没啥用”了
- 双11又来了,网友:比数学考试都难