antlr 教程_ANTLR教程– Hello Word
antlr 教程
每当您需要评估编译时未知的表达式,或者解析奇怪的用户输入或文件时,这都是有用的。 当然,可以为任何这些任务创建定制的手工分析器。 但是,这通常需要更多的时间和精力。 对良好的解析器生成器的一点了解可能会将这些耗时的任务变成简单而又快速的练习。
这篇文章从ANTLR有用性的一个小例子开始。 然后,我们解释什么是ANTLR以及它如何工作。 最后,我们展示如何编译一个简单的“ Hello word!” 语言转换成抽象语法树。 该帖子还说明了如何添加错误处理以及如何测试语言。
下一篇文章展示了如何创建一种真实的表达语言。
实词示例
ANTLR在开源单词中似乎很流行。 其中, Apache Camel , Apache Lucene , Apache Hadoop , Groovy和Hibernate都使用它 。 他们都需要用于自定义语言的解析器。 例如,Hibernate使用ANTLR解析其查询语言HQL。
所有这些都是大型框架,因此与小型应用程序相比,它们更可能需要特定领域的语言。 使用ANTLR的较小项目的列表可在其展示列表中找到 。 我们还找到了关于该主题的一个stackoverflow讨论。
若要查看ANTLR在哪里有用以及如何节省时间,请尝试估算以下要求:
- 将公式计算器添加到会计系统中。 它将计算公式的值,例如
(10 + 80)*sales_tax。 - 将扩展的搜索字段添加到配方搜索引擎中。 它将搜索匹配表达式的收据,例如
(chicken and orange) or (no meat and carrot)。
我们的安全评估需要一天半的时间,其中包括文档,测试以及与项目的集成。 如果您面临类似的要求并且做出了更高的估计,那么ANTLR值得一看。
总览
ANTLR是代码生成器。 它以所谓的语法文件作为输入,并生成两个类:lexer和parser。
Lexer首先运行,然后将输入分成称为令牌的片段。 每个令牌代表或多或少有意义的输入。 标记流被传递到解析器,解析器完成所有必要的工作。 解析器负责构建抽象语法树,解释代码或将其转换为其他形式。
语法文件包含ANTLR生成正确的词法分析器和解析器所需的所有内容。 它是否应该生成Java或python类,解析器是否生成抽象语法树,汇编代码或直接解释代码等。 正如本教程显示如何构建抽象语法树一样,在以下说明中我们将忽略其他选项。
最重要的是,语法文件描述了如何将输入分为令牌以及如何从令牌构建树。 换句话说,语法文件包含词法分析器规则和解析器规则。
每个词法分析器规则描述一个令牌:
TokenName: regular expression;解析器规则更加复杂。 最基本的版本类似于lexer规则中的版本:
ParserRuleName: regular expression;它们可能包含修饰符,这些修饰符在结果抽象语法树中指定输入,根和子元素上的特殊转换,或在使用规则时执行的操作。 几乎所有工作通常都在解析器规则内完成。
基础设施
首先,我们展示使ANTLR开发更容易的工具。 当然,本章中所描述的内容都不是必需的。 所有示例仅适用于maven,文本编辑器和Internet连接。
ANTLR项目制作了独立的IDE , Eclipse插件和Idea插件 。 我们没有找到NetBeans插件。
ANTLRWorks
独立的想法称为ANTLRWorks 。 从项目下载页面下载它。 ANTLRWorks是单个jar文件,请使用java -jar antlrworks-1.4.3.jar命令运行它。
IDE具有更多功能,并且比Eclipse插件更稳定。
Eclipse插件
从ANTLR 下载页面下载并解压缩ANTLR v3。 然后,从Eclipse Marketplace安装ANTLR插件:

转到“首选项”并配置ANTLR v3安装目录:
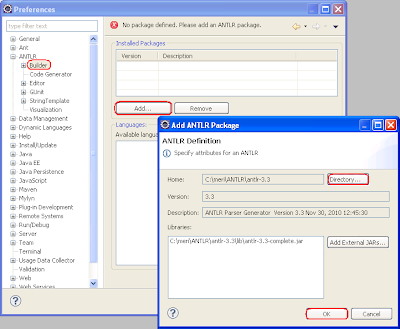
要测试配置,请下载示例语法文件并在eclipse中打开它。 它将在ANTLR编辑器中打开。 编辑器具有三个选项卡:
- 语法–具有语法突出显示,代码完成等功能的文本编辑器。
- 解释器–将测试表达式编译成语法树,可能会产生与生成的解析器不同的结果。 它倾向于在正确的表达式上抛出失败的谓词异常。
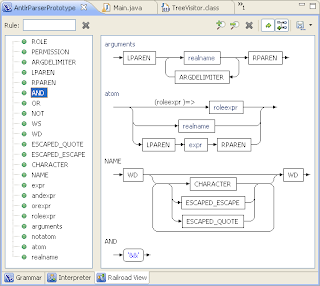
- 铁路视图–绘制您的词法分析器和解析器规则的漂亮图形。
空项目– Maven配置
本章说明如何将ANTLR添加到Maven项目中。 如果您使用Eclipse且尚未安装m2eclipse插件,请从http://download.eclipse.org/technology/m2e/releases更新站点进行安装。 这将使您的生活更加轻松。
建立专案
创建新的Maven项目,并在“选择原型”屏幕上指定maven-archetype-quickstart。 如果不使用Eclipse,则命令mvn archetype:generate可以达到相同的目的。
相依性
将ANTLR依赖项添加到pom.xml中 :
org.antlrantlr3.3jarcompile注意:由于ANTLR没有向后兼容的历史记录,因此最好指定所需的版本。
外挂程式
Antlr maven插件在generate-sources阶段运行,并从语法(.g)文件生成lexer和parser java类。 将其添加到pom.xml中 :
org.antlrantlr3-maven-plugin3.3run antlrgenerate-sourcesantlr创建src/main/antlr3文件夹。 该插件希望其中包含所有语法文件。
生成的文件放在target/generated-sources/antlr3目录中。 由于此目录不在默认的maven构建路径中,因此我们使用build-helper-maven-plugin将其添加到该目录中:
org.codehaus.mojobuild-helper-maven-pluginadd-sourcegenerate-sourcesadd-source${basedir}/target/generated-sources/antlr3如果使用eclipse,则必须更新项目配置:右键单击项目->'maven'->'更新项目配置'。
测试一下
调用maven以测试项目配置:右键单击项目->'Run As'->'Maven generate-sources'。 或者,使用mvn generate-sources命令。
构建应该成功。 控制台输出应包含antlr3-maven-plugin插件输出:
[INFO] --- antlr3-maven-plugin:3.3:antlr (run antlr) @ antlr-step-by-step ---
[INFO] ANTLR: Processing source directory C:\meri\ANTLR\workspace\antlr-step-by-step\src\main\antlr3
[INFO] No grammars to process
ANTLR Parser Generator Version 3.3 Nov 30, 2010 12:46:29它之后应该是build-helper-maven-plugin插件输出:
[INFO] --- build-helper-maven-plugin:1.7:add-source (add-source) @ antlr-step-by-step ---
[INFO] Source directory: C:\meri\ANTLR\workspace\antlr-step-by-step\target\generated-sources\antlr3 added.此阶段的结果位于github上,标记为001-configured_antlr 。
你好字
我们将创建最简单的语言解析器– hello word解析器。 它通过一个表达式构建一个小的抽象语法树:“ Hello word!”。
我们将使用它来显示如何创建语法文件并从中生成ANTLR类。 然后,我们将展示如何使用生成的文件并创建单元测试。
第一个语法文件
Antlr3-maven-plugin在src/main/antlr3目录中搜索语法文件。 它使用语法为每个子目录创建新程序包,并在其中生成解析器和词法分析器类。 由于我们希望将类生成到org.meri.antlr_step_by_step.parsers包中,因此我们必须创建src/main/antlr3/org/meri/antlr_step_by_step/parsers目录。
语法名称和文件名必须相同。 文件必须带有.g后缀。 此外,每个语法文件都以语法名称声明开头。 我们的S001HelloWord语法从以下几行开始:
grammar S001HelloWord;声明之后始终是生成器选项。 我们正在研究Java项目,希望将表达式编译成抽象语法树:
options {// antlr will generate java lexer and parserlanguage = Java;// generated parser should create abstract syntax treeoutput = AST;
}Antlr不会在生成的类之上生成包声明。 我们必须使用@parser::header和@lexer::header块来实施它。 标头必须遵循选项块:
@lexer::header {package org.meri.antlr_step_by_step.parsers;
}@parser::header {package org.meri.antlr_step_by_step.parsers;
}每个语法文件必须至少具有一个词法分析器规则。 每个词法分析器规则必须以大写字母开头。 我们有两个规则,第一个定义一个称呼令牌,第二个定义一个endsymbol令牌。 称呼必须为“ Hello word”,且结尾符号必须为“!”。
SALUTATION:'Hello word';
ENDSYMBOL:'!';同样,每个语法文件必须至少具有一个解析器规则。 每个解析器规则必须以小写字母开头。 我们只有一个解析器规则:我们语言中的任何表达式都必须由称呼后跟一个结尾符号组成。
expression : SALUTATION ENDSYMBOL;注意:语法文件元素的顺序是固定的。 如果更改它,则antlr插件将失败。
生成词法分析器和解析器
使用mvn generate-sources命令或从Eclipse从命令行生成词法分析器和解析器:
- 右键单击该项目。
- 点击“运行方式”。
- 单击“ Maven生成源”。
Antlr插件将创建target / generated-sources / antlr / org / meri / antlr_step_by_step / parsers文件夹,并将S001HelloWordLexer.java和S001HelloWordParser.java文件放入其中。
使用Lexer和Parser
最后,我们创建编译器类。 它只有一种公共方法,该方法:
- 调用生成的词法分析器将输入拆分为令牌,
- 调用生成的解析器以根据令牌构建AST,
- 将结果AST树打印到控制台中,
- 返回抽象语法树。
编译器位于S001HelloWordCompiler类中:
public CommonTree compile(String expression) {try {//lexer splits input into tokensANTLRStringStream input = new ANTLRStringStream(expression);TokenStream tokens = new CommonTokenStream( new S001HelloWordLexer( input ) );//parser generates abstract syntax treeS001HelloWordParser parser = new S001HelloWordParser(tokens);S001HelloWordParser.expression_return ret = parser.expression();//acquire parse resultCommonTree ast = (CommonTree) ret.tree;printTree(ast);return ast;} catch (RecognitionException e) {throw new IllegalStateException("Recognition exception is never thrown, only declared.");}注意:不必担心在S001HelloWordParser.expression()方法上声明的RecognitionException异常。 它永远不会被抛出。
测试它
在本章结束时,我们将使用一个针对新编译器的小测试用例。 创建S001HelloWordTest类:
public class S001HelloWordTest {/*** Abstract syntax tree generated from "Hello word!" should have an * unnamed root node with two children. First child corresponds to * salutation token and second child corresponds to end symbol token.* * Token type constants are defined in generated S001HelloWordParser * class.*/@Testpublic void testCorrectExpression() {//compile the expressionS001HelloWordCompiler compiler = new S001HelloWordCompiler();CommonTree ast = compiler.compile("Hello word!");CommonTree leftChild = ast.getChild(0);CommonTree rightChild = ast.getChild(1);//check ast structureassertEquals(S001HelloWordParser.SALUTATION, leftChild.getType());assertEquals(S001HelloWordParser.ENDSYMBOL, rightChild.getType());}}测试将成功通过。 它将抽象语法树打印到控制台:
0 null-- 4 Hello word-- 5 !IDE中的语法
在编辑器中打开S001HelloWord.g并进入解释器选项卡。
- 在左上方视图中突出显示表达式规则。
- 写下“你好字!” 进入右上方的视图。
- 按左上角的绿色箭头。
解释器将生成解析树:

复制语法
本教程中的每个新语法都基于先前的语法。 我们汇总了将旧语法复制到新语法所需的步骤列表。 使用它们将OldGrammar复制到NewGrammar:
- 将OldGrammar.g复制到同一目录中的NewGrammar.g 。
- 将语法声明更改为
grammar NewGrammar; - 生成解析器和词法分析器。
- 创建类似于先前的OldGrammarCompiler类的新类NewGrammarCompiler 。
- 创建类似于先前的OldGrammarTest类的新测试类NewGrammarTest 。
错误处理
没有适当的错误处理,没有任何任务真正完成。 生成的ANTLR类尽可能尝试从错误中恢复。 它们的确向控制台报告错误,但是没有现成的API可以以编程方式查找语法错误。
如果我们只构建命令行编译器,那可能很好。 但是,假设我们正在为我们的语言构建GUI,或将结果用作其他工具的输入。 在这种情况下,我们需要对所有生成的错误进行API访问。
在本章的开头,我们将尝试使用默认错误处理并为其创建测试用例。 然后,我们将添加一个简单的错误处理,只要发生第一个错误,该处理就会抛出异常。 最后,我们将转向“真实”解决方案。 它将在内部列表中收集所有错误并提供访问它们的方法。
作为副产品,本章介绍了如何:
- 在解析器规则中添加自定义catch子句 ,
- 向生成的类中添加新的方法和字段 ,
- 覆盖生成的方法 。
默认错误处理
首先,我们将尝试解析各种不正确的表达式。 目的是了解默认的ANTLR错误处理行为。 我们将根据每个实验创建测试用例。 所有测试用例都位于S001HelloWordExperimentsTest类中。
表达式1 : Hello word?
结果树与正确的树非常相似:
0 null-- 4 Hello word-- 5 ?<missing ENDSYMBOL>控制台输出包含错误:
line 1:10 no viable alternative at character '?'
line 1:11 missing ENDSYMBOL at '<eof>'测试用例 :以下测试用例通过均没有问题。 不会引发异常,并且抽象语法树节点类型与正确表达式中的相同。
@Testpublic void testSmallError() {//compile the expressionS001HelloWordCompiler compiler = new S001HelloWordCompiler();CommonTree ast = compiler.compile("Hello word?");//check AST structureassertEquals(S001HelloWordParser.SALUTATION, ast.getChild(0).getType());assertEquals(S001HelloWordParser.ENDSYMBOL, ast.getChild(1).getType());}表情2 : Bye!
结果树与正确的树非常相似:
0 null-- 4 <missing>-- 5 !</missing>控制台输出包含错误:
line 1:0 no viable alternative at character 'B'
line 1:1 no viable alternative at character 'y'
line 1:2 no viable alternative at character 'e'
line 1:3 missing SALUTATION at '!'测试用例 :以下测试用例通过均没有问题。 不会引发异常,并且抽象语法树节点类型与正确表达式中的相同。
@Testpublic void testBiggerError() {//compile the expressionS001HelloWordCompiler compiler = new S001HelloWordCompiler();CommonTree ast = compiler.compile("Bye!");//check AST structureassertEquals(S001HelloWordParser.SALUTATION, ast.getChild(0).getType());assertEquals(S001HelloWordParser.ENDSYMBOL, ast.getChild(1).getType());}表达式3 : Incorrect Expression
结果树只有根节点,没有子节点:
0控制台输出包含很多错误:
line 1:0 no viable alternative at character 'I'
line 1:1 no viable alternative at character 'n'
line 1:2 no viable alternative at character 'c'
line 1:3 no viable alternative at character 'o'
line 1:4 no viable alternative at character 'r'
line 1:5 no viable alternative at character 'r'
line 1:6 no viable alternative at character 'e'
line 1:7 no viable alternative at character 'c'
line 1:8 no viable alternative at character 't'
line 1:9 no viable alternative at character ' '
line 1:10 no viable alternative at character 'E'
line 1:11 no viable alternative at character 'x'
line 1:12 no viable alternative at character 'p'
line 1:13 no viable alternative at character 'r'
line 1:14 no viable alternative at character 'e'
line 1:15 no viable alternative at character 's'
line 1:16 no viable alternative at character 's'
line 1:17 no viable alternative at character 'i'
line 1:18 no viable alternative at character 'o'
line 1:19 no viable alternative at character 'n'
line 1:20 mismatched input '<EOF>' expecting SALUTATION测试用例 :我们终于找到了一个导致树结构不同的表达式。
@Testpublic void testCompletelyWrong() {//compile the expressionS001HelloWordCompiler compiler = new S001HelloWordCompiler();CommonTree ast = compiler.compile("Incorrect Expression");//check AST structureassertEquals(0, ast.getChildCount());}Lexer中的错误处理
每个词法分析器规则“ RULE”对应于生成的词法分析器中的“ mRULE”方法。 例如,我们的语法有两个规则:
SALUTATION:'Hello word';
ENDSYMBOL:'!';并且生成的词法分析器有两种相应的方法 :
public final void mSALUTATION() throws RecognitionException {// ...
}public final void mENDSYMBOL() throws RecognitionException {// ...
}根据抛出的异常,lexer可能会也可能不会尝试从中恢复。 但是,每个错误都以reportError(RecognitionException e)方法结尾。 生成的词法分析器继承它:
public void reportError(RecognitionException e) {displayRecognitionError(this.getTokenNames(), e);}结果:我们必须在lexer中更改reportError或displayRecognitionError方法。
解析器中的错误处理
我们的语法只有一个解析器规则“表达式”:
expression SALUTATION ENDSYMBOL;该表达式对应于生成的解析器中的expression()方法:
public final expression_return expression() throws RecognitionException {//initializationtry {//parsing}catch (RecognitionException re) {reportError(re);recover(input,re);retval.tree = (Object) adaptor.errorNode(input, retval.start, input.LT(-1), re);} finally {}//return result;
}如果发生错误,解析器将:
- 向控制台报告错误,
- 从错误中恢复
- 将错误节点(而不是普通节点)添加到抽象语法树。
解析器中的错误报告比lexer中的错误报告稍微复杂一些:
/** Report a recognition problem.** This method sets errorRecovery to indicate the parser is recovering* not parsing. Once in recovery mode, no errors are generated.* To get out of recovery mode, the parser must successfully match* a token (after a resync). So it will go:** 1. error occurs* 2. enter recovery mode, report error* 3. consume until token found in resynch set* 4. try to resume parsing* 5. next match() will reset errorRecovery mode** If you override, make sure to update syntaxErrors if you care about that.*/public void reportError(RecognitionException e) {// if we've already reported an error and have not matched a token// yet successfully, don't report any errors.if ( state.errorRecovery ) {return;}state.syntaxErrors++; // don't count spuriousstate.errorRecovery = true;displayRecognitionError(this.getTokenNames(), e);}这次我们有两个可能的选择:
- 通过自己的处理替换解析器规则方法中的catch子句,
- 覆盖解析器方法。
在解析器中更改捕获
Antlr提供了两种方法来更改解析器中生成的catch子句。 我们将创建两个新的语法,每个都演示一种方法。 在这两种情况下,我们都会使解析器在第一个错误时退出。
首先,我们可以将rulecatch添加到新S002HelloWordWithErrorHandling语法的解析器规则中:
expression : SALUTATION ENDSYMBOL;
catch [RecognitionException e] {//Custom handling of an exception. Any java code is allowed.throw new S002HelloWordError(":(", e);
}当然,我们必须将S002HelloWordError异常的导入添加到headers块中 :
@parser::header {package org.meri.antlr_step_by_step.parsers;//add imports (see full line on Github)import ... .S002HelloWordWithErrorHandlingCompiler.S002HelloWordError;
}编译器类与以前几乎相同。 它声明了新的异常:
public class S002HelloWordWithErrorHandlingCompiler extends AbstractCompiler {public CommonTree compile(String expression) {// no change here}@SuppressWarnings("serial")public static class S002HelloWordError extends RuntimeException {public S002HelloWordError(String arg0, Throwable arg1) {super(arg0, arg1);}}
}然后,ANTLR将用我们自己的处理方式替换表达式规则方法中的默认catch子句:
public final expression_return expression() throws RecognitionException {//initializationtry {//parsing}catch (RecognitionException re) {//Custom handling of an exception. Any java code is allowed.throw new S002HelloWordError(":(", e); } finally {}//return result;
}通常, 语法 , 编译器类和测试类在Github上可用。
或者,我们可以将rulecatch规则放在标题块和第一个lexer规则之间。 S003HelloWordWithErrorHandling语法演示了此方法:
//change error handling in all parser rules
@rulecatch {catch (RecognitionException e) {//Custom handling of an exception. Any java code is allowed.throw new S003HelloWordError(":(", e);}
}我们必须将S003HelloWordError异常的导入添加到标头块中:
@parser::header {package org.meri.antlr_step_by_step.parsers;//add imports (see full line on Github)import ... .S003HelloWordWithErrorHandlingCompiler.S003HelloWordError;
}编译器类与前面的情况完全相同。 ANTLR将替换所有解析器规则中的默认catch子句:
public final expression_return expression() throws RecognitionException {//initializationtry {//parsing}catch (RecognitionException re) {//Custom handling of an exception. Any java code is allowed.throw new S003HelloWordError(":(", e); } finally {}//return result;
}同样,Github上提供了语法 , 编译器类和测试类 。
不幸的是,这种方法有两个缺点。 首先,它仅在解析器中不适用于lexer。 其次,默认报告和恢复功能以合理的方式工作。 它尝试从错误中恢复。 一旦开始恢复,就不会产生新的错误。 仅当解析器未处于错误恢复模式时,才会生成错误消息。
我们喜欢此功能,因此我们决定仅更改错误报告的默认实现。
将方法和字段添加到生成的类
我们会将所有词法分析器/解析器错误存储在私有列表中。 此外,我们将在生成的类中添加两个方法:
- hasErrors –如果发生至少一个错误,则返回true,
- getErrors –返回所有生成的错误。
在@members块内添加了新的字段和方法:
@lexer::members {//everything you need to add to the lexer
}@parser::members {//everything you need to add to the parser
}成员块必须放置在标题块和第一个词法分析器规则之间。 该示例的语法为S004HelloWordWithErrorHandling :
//add new members to generated lexer
@lexer::members {//add new fieldprivate List<RecognitionException> errors = new ArrayList <RecognitionException> ();//add new methodpublic List<RecognitionException> getAllErrors() {return new ArrayList<RecognitionException>(errors);}//add new methodpublic boolean hasErrors() {return !errors.isEmpty();}
}//add new members to generated parser
@parser::members {//add new fieldprivate List<RecognitionException> errors = new ArrayList <RecognitionException> ();//add new methodpublic List<RecognitionException> getAllErrors() {return new ArrayList<RecognitionException>(errors);}//add new methodpublic boolean hasErrors() {return !errors.isEmpty();}
}生成的词法分析器和生成的解析器都包含用members块编写的所有字段和方法。
覆盖生成的方法
要覆盖生成的方法,请执行与要添加新方法相同的操作,例如,将其添加到@members块中:
//override generated method in lexer
@lexer::members {//override methodpublic void reportError(RecognitionException e) {errors.add(e);displayRecognitionError(this.getTokenNames(), e);}
}//override generated method in parser
@parser::members {//override methodpublic void reportError(RecognitionException e) {errors.add(e);displayRecognitionError(this.getTokenNames(), e);}
}现在,reportError方法将覆盖lexer和parser中的默认行为。
收集编译器中的错误
最后,我们必须更改编译器类。 新版本将在输入解析阶段之后收集所有错误:
private List<RecognitionException> errors = new ArrayList<RecognitionException>();public CommonTree compile(String expression) {try {... init lexer ...... init parser ...ret = parser.expression();//collect all errorsif (lexer.hasErrors())errors.addAll(lexer.getAllErrors());if (parser.hasErrors())errors.addAll(parser.getAllErrors());//acquire parse result... as usually ...} catch (RecognitionException e) {...}
}/**
* @return all errors found during last run
*/
public List<RecognitionException> getAllErrors() {return errors;
}解析器完成工作后,我们必须收集词法分析器错误。 从它调用词法分析器,之前没有任何错误。 像往常一样,我们将语法 , 编译器类和测试类放在Github上。
下载antlr分步项目的标记003-S002-to-S004HelloWordWithErrorHandling ,以查找同一java项目中的所有三种错误处理方法。
参考: ANTLR教程–我们的JCG合作伙伴 Maria Jurcovicova在This is Stuff博客上的问候语。
翻译自: https://www.javacodegeeks.com/2012/04/antlr-tutorial-hello-word.html
antlr 教程
antlr 教程_ANTLR教程– Hello Word相关推荐
- 计算机基础操作与应用实训教程,计算机应用基础实训教程の第 3 章 Word 2003 基本操作.pdf...
计算机应用基础实训教程の第 3 章 Word 2003 基本操作.pdf (37页) 本资源提供全文预览,点击全文预览即可全文预览,如果喜欢文档就下载吧,查找使用更方便哦! 19.9 积分 第 3 章 ...
- Apache POI(Word)教程_编程入门自学教程_菜鸟教程-免费教程分享
教程简介 IT宝库整理的Apache POI Word入门教程 - 从基本到高级概念的简单简单步骤学习Apache POI Word,其中包括概述,Apache POI安装,核心类,文档,段落,边框, ...
- Python 自动化教程(5) : 自动生成Word文件
系列教程: Python 自动化教程(1) 概述,第一篇 Excel自动化 Python 自动化教程(2) : Excel自动化:使用pandas库 Python 自动化教程(3) : 自动生成PPT ...
- word文档小方格怎么弄_如何在WORD文档中的小方格里打对勾,独家教程在这里,WORD中的小方框...
原标题:如何在WORD文档中的小方格里打对勾,独家教程在这里,WORD中的小方框 我们在做一些服务项目的协议或者代理委托时,通常会有一些项目需要我们在前面的小方框里打对勾,打印出来的纸质版只需要拿笔勾 ...
- 实用教程:如何在Word与EXCEL(WPS)中加入斜表头并加入文字详细教程
实用教程:如何在Word与EXCEL(WPS)中加入斜表头并加入文字详细教程 一. 效果 二. Word方法 1.首先加入空表格: 2. 写入想要的文字并按Enter(回车)键分开(特指:斜表头) 3 ...
- 好用到爆的Python自动化办公教程,Python × Excel × Word × PPT 一次解决
好用到爆的Python自动化办公教程,Python × Excel × Word × PPT 一次解决 大家好,我是黄伟
- ASP.NET Core 异常和错误处理 - ASP.NET Core 基础教程 - 简单教程,简单编程
原文:ASP.NET Core 异常和错误处理 - ASP.NET Core 基础教程 - 简单教程,简单编程 ASP.NET Core 异常和错误处理 上一章节中,我们学习了 ASP.NET Cor ...
- python菜鸟教程字典-python教程菜鸟教程学习路线
python教程菜鸟教程学习路线,需要学Python 环境搭建.Python 中文编码.Python 基础语法.Python 变量类型.Python 运算符.Python 条件语句.Python 循环 ...
- ASP.NET Core macOS 环境配置 - ASP.NET Core 基础教程 - 简单教程,简单编程
ASP.NET Core macOS 环境配置 - ASP.NET Core 基础教程 - 简单教程,简单编程 原文:ASP.NET Core macOS 环境配置 - ASP.NET Core 基础 ...
最新文章
- 机器学习(MACHINE LEARNING)MATLAB求解利润最大化问题【线性规划】
- 【Java】 剑指offer(28) 对称的二叉树
- 【数据使用】3问视觉项目中的数据整理,这点小事你是不是都掌握好了?
- [转]毕业5年决定你的命运 --------值得所有不甘平庸的人看看
- Linux 查看文件位置/查看文件路径的命令
- Composer更新慢的终极解决方案-转
- 超过4G的分区安装oracle,Red hat Linux AS4.0安装Oracle9.2.04详细步骤
- android只有域名打包封装成apk,一个Android Studio工程根据网址打包出不同的apk
- 竞价推广账户日常优化需要注意十大要点
- win7原版iso镜像下载 windows7官方原版全系列(正式版、专业版、企业版、家庭版)下载
- BAT自动IP地址切换脚本
- GPU架构与管线总结
- python正则表达式相关知识点记录
- jquerymobile-16 select menu
- 计算机组成原理alu_b什么意思,计算机组成原理实验三多功能ALU设计实验(5页)-原创力文档...
- 共模电感的原理、作用和使用示例
- 解析S2B2C模式的典型特征,应用S2B2C商城助力医疗器械企业快速发展
- FAQ:redis key/value 前面出现\xAC\xED\x00\x05t\x00\x05
- 代码优化大盘点:35 个 Java 代码优化魔鬼细节
- routeros 3322电信联通脚本