可视化 nlp_使用nlp可视化尤利西斯
可视化 nlp
My data science experience has, thus far, been focused on natural language processing (NLP), and the following post is neither the first nor last which will include the novel Ulysses, by James Joyce, as its primary target for NLP and literary elucidation. In this post I will explain why it’s such a perfect target, since Ulysses will likely be the focus of my next project. This will probably be a multi-part blog post.
到目前为止,我的数据科学经验一直集中在自然语言处理(NLP)上,以下文章既不是第一也不是最后一篇,其中包括James Joyce的小说《尤利西斯》(Ulysses),作为其NLP和文学阐释的主要目标。 在这篇文章中,我将解释为什么它是一个如此理想的目标,因为尤利西斯很可能成为我下一个项目的重点。 这可能是一个多部分的博客文章。
关于这本书 (About the Book)
First off, why this book?
首先,为什么要这本书?
Ulysses, by James Joyce, has elicited just about every kind of response from readers since its publication in 1922, ranging from claims that it’s the pinnacle of modernist literature to claims that it’s a filthy, decadent depiction of obscenity and pornography (nonetheless glittering with Shakespearean intertextuality on nearly every page) which should be, and was, banned until the famous Supreme Court case, United States v. One Book Called Ulysses in 1933 decidedly readmitted it into the United States. Moreover, this decision highlighted serious, longstanding philosophical questions about the role of art and the right to literary expression.
自1922年出版以来,詹姆斯·乔伊斯(James Joyce)撰写的《尤利西斯》(Ulysses)引起了读者的几乎所有回应,从声称这是现代主义文学的巅峰之作,到声称这是对淫秽和色情的肮脏,decade废的描写(尽管如此,莎士比亚还是闪闪发光的)。几乎在每页上都应保留互文性),直到著名的最高法院案件《美国诉一本名叫尤利西斯的书》 (1933年)被坚决重新纳入美国为止。 此外,这一决定突出了关于艺术的作用和文学表达权的严重的,长期的哲学问题。
I fall firmly into the former category, and I believe it’s an affirmative work of genius. The reasons for this include many of the reasons I use Ulysses for NLP: the intent of Joyce was to recreate the many different modes of human experience through language. Through the scintillating and narrowing confines of different languages, dialects, subdialects, profanities, connotations, grammars, and idioms, all of which cross different religious and cultural traditions from the Catholic Church to Irish nationalists, to the mundane domestic affairs of a house in Ireland in 1904, to the parallels of ordinary life found on one day in Dublin to the Odyssey, as well as Shakespeare’s Hamlet, through fixations on classical philosophy and human suffering expressed via a hallucinatory, drunken escapade in a brothel manifesting as both the climax of the novel and the resurrection of the dead, Joyce believed that dimensionality would emerge through the parallax of flowing between these different modes of language, or life.
我坚决属于前一类,并且我相信这是天才的肯定作品。 原因包括我将Ulysses用于NLP的许多原因:Joyce的目的是通过语言重现人类体验的许多不同模式。 通过各种语言,方言,次方言,亵渎,内涵,语法和成语的闪烁而狭窄的界限,所有这些跨越了不同的宗教和文化传统,从天主教到爱尔兰民族主义者,再到爱尔兰一所房子的平凡的内政在1904年,普通生活的相似之处在都柏林的第一天发现奥德赛 ,以及莎士比亚的哈姆雷特 ,通过对古典哲学,并通过表达人类痛苦的注视幻觉,在妓院醉酒越轨行为表现为两个高潮乔伊斯(Joece)认为小说和死者的复活是通过这些不同的语言或生活模式之间流动的视差而出现的维度 。
If the ostensible larger project of data science is to provide conceptual clarity via statistical analysis, as well as actionable insight through computing via machine learning, feature engineering, and deep understanding of data structures with the mindset of a scientist, then I can think of no greater interdisciplinary project, at least in the realm of NLP, than Ulysses for the sake of validating Joyce’s larger project. There are deeper parallels between data science and literary criticism than I initially realized when I entered the field, particularly in the importance of understanding the data through exploratory data analysis. And the more experience I’ve gained, the more I’ve realized this is a STEM way of saying ‘cultivate emotional alignment and clarity through conceptually rigorous inspection until dimensionality emerges in the data’.
如果说表面上较大的数据科学项目是通过统计分析来提供概念清晰性,以及通过机器学习,特征工程以及以科学家的思维方式对数据结构的深刻理解来通过计算提供可行的见解,那么我可以认为没有为了验证乔伊斯的更大项目,至少在NLP领域,这个更大的跨学科项目要比尤利西斯(Ulysses)好。 数据科学与文学批评之间的相似之处比我进入该领域时最初所意识到的要深得多,尤其是在通过探索性数据分析来理解数据的重要性方面。 而且我获得的经验越多,我就越意识到这是一种STEM方式,即“通过概念上严格的检查来培养情绪的一致性和清晰度,直到数据中出现维数为止”。
Hence, the following project will be an attempt to simply visualize Ulysses in a way inspired by a similar project.
因此,以下项目将尝试以类似项目的启发方式简单地可视化Ulysses 。
动机 (The Motivation)
I was initially inspired by this project. The project is presented in the form of an academic article on Thomas Pynchon’s V, another difficult English novel characterized by a fragmented plot and an unclear timeline, by Christos Iraklis Tsatsoulis, completed in 2013, and I remain continuously shocked that I haven’t found more projects like it. I presume this is due to a cultural gap between Data Science and Literary Criticism, for reasons most likely due to the ancient war between STEM and liberal arts.
最初,我受到这个项目的启发。 该项目以关于托马斯·平昌V的学术文章的形式呈现,该小说是克里斯托斯·伊拉克利斯·特萨苏里斯(Christos Iraklis Tsatsoulis)于2013年完成的另一本艰难的英语小说,其特点是剧情零散,时间表不明确,我一直为我没有发现而感到震惊更多类似的项目。 我认为这是由于数据科学与文学批评之间的文化鸿沟造成的,原因很可能是由于STEM与文科之间的古老战争 。
To start, Tsatsoulis presents an overview of the novel from a literary perspective, going over chapter summaries and the two primary ‘storylines’ in the book, the V. storyline and the Profane storyline. For the reader’s sake, I’ll be transparent by saying that I haven’t read V. by Thomas Pynchon, nor do you need to have read Ulysses to understand either project. For this post, I would only like to outline and emphasize the ingenuity behind the overarching project, which is to make a true interdisciplinary effort to use the brilliant tools of contemporary NLP to augment literary analysis through both visualization and deeper understanding of the semantic content.
首先,Tsatsoulis从文学的角度对小说进行了概述,介绍了章节摘要和本书中的两个主要“故事情节”,即V.故事情节和Profane故事情节。 为了读者的缘故,我会公开地说我没有读过Thomas Pynchon的V. ,也不需要读过Ulysses就能理解这两个项目。 对于本篇文章,我只想概述和强调总体项目背后的独创性, 即通过跨学科的努力,利用可视化和对语义内容的深入理解,利用当代NLP的出色工具来加强文学分析 。
So often have I seen the combative attitude between ‘machine learning’ and ‘art’, always descending into the same pit of claims that ‘a computer can never make real art’ versus claims that ‘real art is simply a set of fundamental patterns which can be learned and replicated’, whether in the context of AI-produced music, literature, or any number of films about AI-related romance and love. Without getting into the tangential complexities of that debate, I only mean to point out how little cooperation there is between these general poles, which seem to correspond, again, to STEM and liberal arts.
我经常看到“机器学习”与“艺术”之间的战斗态度,总是陷入“计算机永远不能创造真实艺术”的说法与“真实艺术只是一组基本模式,可以在AI产生的音乐,文学或任何与AI相关的爱情和爱情的电影中学习和复制。 在不讨论该辩论的切线复杂性的情况下,我只想指出这些普遍的极点之间几乎没有合作 ,而这些极点似乎又与STEM和文科相对应。
What Tsatsoulis accomplished shows just how useful the tools of NLP can be for healing this strange adversarial relationship.
Tsatsoulis取得的成就表明,NLP的工具对于治愈这种奇怪的对抗性关系有多么有用。
After presenting a literary overview of V., he then provides some exploratory data analysis, like any good data scientist, via a wordcloud and some of V.’s characterizing vocabulary. He explains his primary methodology for capturing the structure of semantic content throughout the novel, which involves TF-IDF and hierarchical clustering, as well as the interesting and original utilization of ‘distance thresholds’ between chapters, based on Euclidian, Manhattan, and Canberra distances, as well as an independent section on Normalized Compression Distance, a methodology based on Kolmogorov complexity. He uses these distance thresholds to create the bafflingly interesting visualizations for the novel:
在介绍了V.的文学概观之后,他随后通过词云和一些V.的特征性词汇,提供了一些探索性的数据分析,就像任何一位好的数据科学家一样。 他解释了他捕获整个小说中语义内容结构的主要方法,该方法涉及TF-IDF和分层聚类,以及基于欧几里得,曼哈顿和堪培拉距离的章节之间“距离阈值”的有趣和原始用法,以及关于标准化压缩距离的独立部分,该方法基于Kolmogorov复杂度。 他使用这些距离阈值为小说创建了令人困惑的有趣可视化效果:
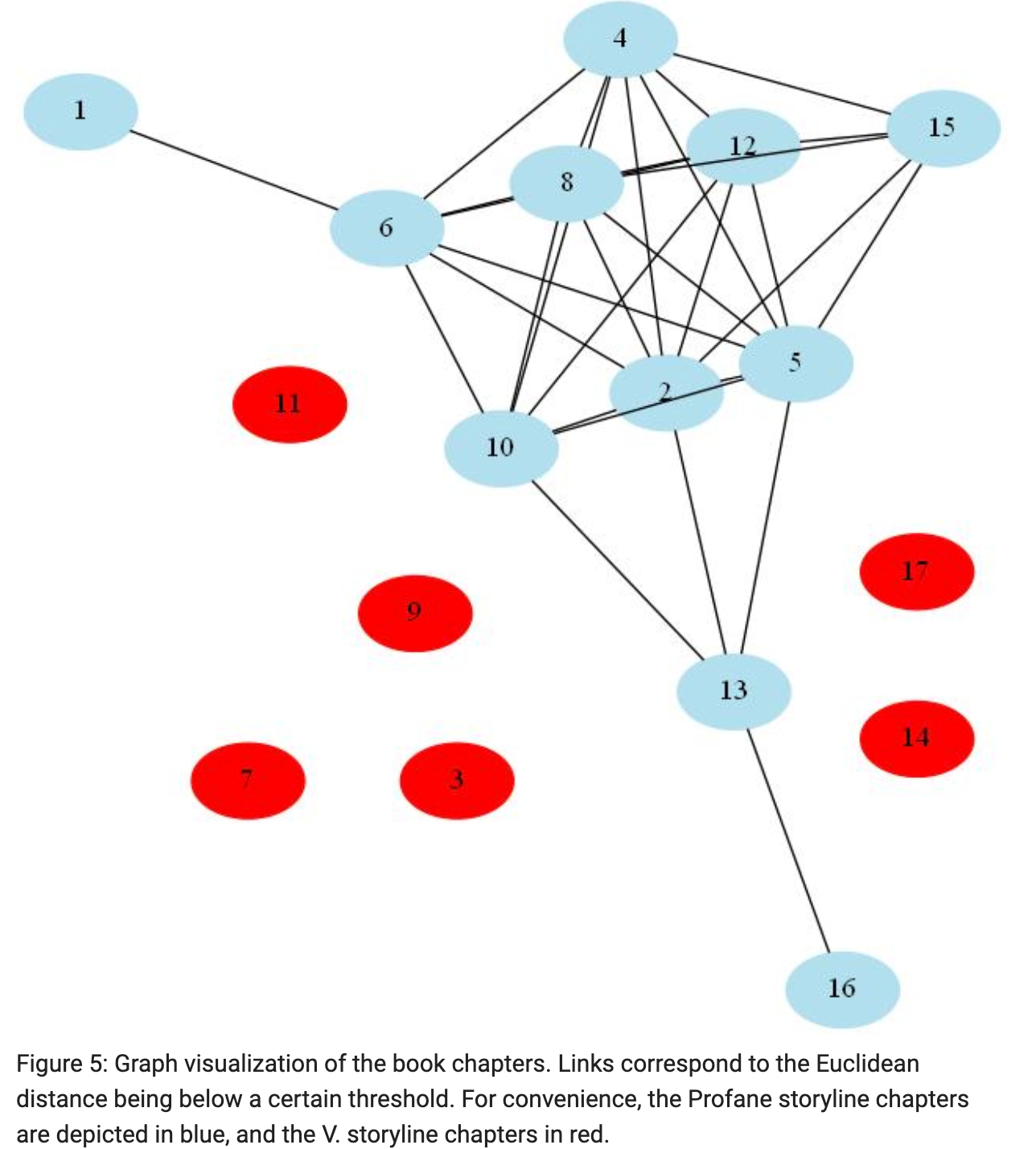
This is an incredible application of NLP to literary analysis. Tsatsoulis even mentions:
这是自然语言处理在文学分析中不可思议的应用。 Tsatsoulis甚至提到:
Somewhat to our surprise, despite this universal agreement regarding the existence of two different storylines in the novel, it seems that there has never been an attempt to exclusively map each chapter to one and only one storyline.
令我们感到惊讶的是,尽管就小说中存在两个不同的故事情节达成了普遍共识,但似乎从未尝试过将每一章专门映射到一个故事情节 。
Such a situation screams for the application of the tools of data science, and Tsatsoulis fantastically succeeded in applying them.
这种情况使数据科学工具的应用大为震惊,Tsatsoulis成功地应用了它们。
Why, then, given that this project was completed in 2013, has this methodology not caught on in the field of literary analysis? James Joyce himself is infamous for having said of Ulysses, to his French translator:
那么,既然这个项目于2013年完成,为什么在文学分析领域没有采用这种方法呢? 詹姆斯·乔伊斯(James Joyce)本人对他的法语翻译说过《尤利西斯》而臭名昭著:
I’ve put in so many enigmas and puzzles that it will keep the professors busy for centuries arguing over what I meant, and that’s the only way of insuring one’s immortality.
我已经提出了许多谜题和困惑,这将使教授们忙于几个世纪来一直在争论我的意思,而这是确保人们永生的唯一方法。
And indeed, professors remain busy arguing over Ulysses. I will not even discuss — for now — the ultimate enigma that is Finnegans Wake for the potential application of NLP, though it may indeed be the telos project of NLP and literature.
确实,教授们仍然忙于争论尤利西斯。 就目前而言,我什至不会讨论Finnegans Wake的终极谜团 对于NLP的潜在应用,虽然它可能确实是终极目的项目NLP和文学。
Hence, my motivation for applying a similar methodology to Ulysses is inspired by the utter success of Tsatsoulis’s project with Thomas Pynchon’s V., not just because of the literary merit provided by such an analysis, but because it demonstrates that productive cooperation between data science, or the field of precision and rigorous statistical dominance, and literary criticism, the refuge of obscurantism and impenetrable vocabulary, is possible.
因此,我之所以将类似的方法学应用于尤利西斯(Ulysses )的动机,是受Tsatsoulis与Thomas Pynchon的V.的项目的巨大成功的启发,这不仅是因为这种分析提供了文学上的价值,而且还因为它证明了数据科学之间的富有成效的合作,或在精确和严格的统计控制领域,以及文学批评领域,躲避晦涩难懂的词汇是可能的。
Look out for Part Two of this post, where I’ll actually attempt similar visualizations with the plot of Ulysses, which will hopefully align with standard interpretations of the novel.
请注意本文的第二部分,在这里我实际上将尝试用《 尤利西斯》的情节进行类似的可视化,这有望与小说的标准解释保持一致。
翻译自: https://medium.com/swlh/using-nlp-to-visualize-ulysses-8a953c27aca
可视化 nlp
http://www.taodudu.cc/news/show-995336.html
相关文章:
- python的power bi转换基础
- 自定义按钮动态变化_新闻价值的变化定义
- 算法 从 数中选出_算法可以选出胜出的nba幻想选秀吗
- 插入脚注把脚注标注删掉_地狱司机不应该只是英国电影历史数据中的脚注,这说明了为什么...
- 贝叶斯统计 传统统计_统计贝叶斯如何补充常客
- 因为你的电脑安装了即点即用_即你所爱
- 团队管理新思考_需要一个新的空间来思考讨论和行动
- bigquery 教程_bigquery挑战实验室教程从数据中获取见解
- java职业技能了解精通_如何通过精通数字分析来提升职业生涯的发展,第8部分...
- kfc流程管理炸薯条几秒_炸薯条成为数据科学的最后前沿
- bigquery_到Google bigquery的sql查询模板,它将您的报告提升到另一个层次
- 数据科学学习心得_学习数据科学时如何保持动力
- python多项式回归_在python中实现多项式回归
- pd种知道每个数据的类型_每个数据科学家都应该知道的5个概念
- xgboost keras_用catboost lgbm xgboost和keras预测财务交易
- 走出囚徒困境的方法_囚徒困境的一种计算方法
- 平台api对数据收集的影响_收集您的数据不是那么怪异的api
- 逻辑回归 概率回归_概率规划的多逻辑回归
- ajax不利于seo_利于探索移动选项的界面
- 数据探索性分析_探索性数据分析
- stata中心化处理_带有stata第2部分自定义配色方案的covid 19可视化
- python 插补数据_python 2020中缺少数据插补技术的快速指南
- ab 模拟_Ab测试第二部分的直观模拟
- 亚洲国家互联网渗透率_发展中亚洲国家如何回应covid 19
- 墨刀原型制作 位置选择_原型制作不再是可选的
- 使用协同过滤推荐电影
- 数据暑假实习面试_面试数据科学实习如何准备
- 谷歌 colab_如何在Google Colab上使用熊猫分析
- 边际概率条件概率_数据科学家解释的边际联合和条件概率
- 袋装决策树_袋装树是每个数据科学家需要的机器学习算法
可视化 nlp_使用nlp可视化尤利西斯相关推荐
- 鲜活数据数据可视化指南_数据可视化实用指南
鲜活数据数据可视化指南 Exploratory data analysis (EDA) is an essential part of the data science or the machine ...
- python数据图表可视化GUI,python做可视化数据图表
Python中数据可视化的两个库! 1. Matplotlib:是Python中众多数据可视化库的鼻祖,其设计风格与20世纪80年代的商业化程序语言MATLAB十分相似,具有很多强大且复杂的可视化功能 ...
- python使用matplotlib可视化、使用matplotlib可视化scipy.misc图像、自定义使用grey灰色映射、将不同亮度映射到不同的色彩、并添加颜色标尺
python使用matplotlib可视化.使用matplotlib可视化scipy.misc图像.自定义使用grey灰色映射.将不同亮度映射到不同的色彩.并添加颜色标尺 目录
- R语言ggplot2可视化:使用热力图可视化dataframe数据
R语言ggplot2可视化:使用热力图可视化dataframe数据 目录 R语言ggplot2可视化:使用热力图可视化dataframe数据
- python使用matplotlib可视化间断条形图、使用broken_barh函数可视化间断条形图、可视化定性数据的相同指标在时间维度上的差异
python使用matplotlib可视化间断条形图.使用broken_barh函数可视化间断条形图.可视化定性数据的相同指标在时间维度上的差异 目录 python使用matplotlib可视化间断条 ...
- python使用matplotlib可视化阶梯图、使用step函数可视化阶梯图、可视化时间序列数据的波动周期和规律
python使用matplotlib可视化阶梯图.使用step函数可视化阶梯图.可视化时间序列数据的波动周期和规律 目录
- R语言ggplot2可视化:使用热力图可视化dataframe数据、自定义设置热力图的颜色、自定添加标题、轴标签、热力图线框等
R语言ggplot2可视化:使用热力图可视化dataframe数据.自定义设置热力图的颜色.自定添加标题.轴标签.热力图线框等 目录
- python使用matplotlib可视化、查看matplotlib可视化中不同字体形式、不同字号、斜体可视化的效果对比
python使用matplotlib可视化.查看matplotlib可视化中不同字体形式.不同字号.斜体可视化的效果对比 目录
- python使用matplotlib可视化、使用matplotlib可视化scipy.misc图像、自定义使用RdYIBu色彩映射、将不同亮度映射到不同的色彩
python使用matplotlib可视化.使用matplotlib可视化scipy.misc图像.自定义使用RdYIBu色彩映射.将不同亮度映射到不同的色彩 目录
最新文章
- Paxos Made Simple(译)
- 使用Fabric自动化你的任务
- 每天一道LeetCode-----根据中序遍历和后序遍历重构二叉树
- Sql Server 在数据库中所有表所有栏位 找出匹配某个值的脚本(转)
- imap服务器appleimap.163.com没有响应,163smtp
- java ltp4j_43、哈工大NLP自然语言处理,LTP4j的测试+还是测试
- golang 将对象转换成string_Golang 匿名 struct 解码数据技巧
- python模块之codecs: 自然语言编码转换
- 计算机硬件基础电路参数测量,硬件电路设计基础知识.doc
- 白板推导系列Pytorch-线性判别分析(LDA)
- LSTM 手动实现车牌识别 Pytorch代码
- 新能源行业SCM供应链管理平台构建一站式新能源供应链交易闭环
- (转)iOS及Mac开源项目和学习资料【超级全面】
- stm32低功耗解决方案-(外部时钟芯片RX8025T)
- 玩转GD32F3x0开发板 (二)
- 卷皮网aso优化数据分析报告
- Parity(奇偶校验)和ECC(错误检查和纠正)
- 早安!新春快乐!兔年大吉!
- ps和php有什么关系,lr和ps有什么区别
- IOT-OS之RT-Thread(六)--- 线程间同步与线程间通信