阿里大数据运维新成员——24小时待命!有求必应!能说会做!...
序言
阿里大数据计算平台包含了广泛的数据计算相关产品与服务,包括MaxCompute通用计算、StreamCompute实时流计算、PAI机器学习、Flash图计算及其上的一站式开发平台Dataworks。同时计算平台拥有着多个全球机房、十万多机器的部署规模,在这样的体量下,线上的作业故障分析与用户咨询变成了日常工作,在高峰期我们的值班小二一天需对外服务数百次,不停响起的钉钉声,也变成了办公室的一种背景噪音。
这样的人肉运维显然不是我们技术人应有的工作状态,所以我们推出了智能机器人来作为我们值班一线,它帮助平台外部用户解惑排障,也帮助平台内部运维高效工作:
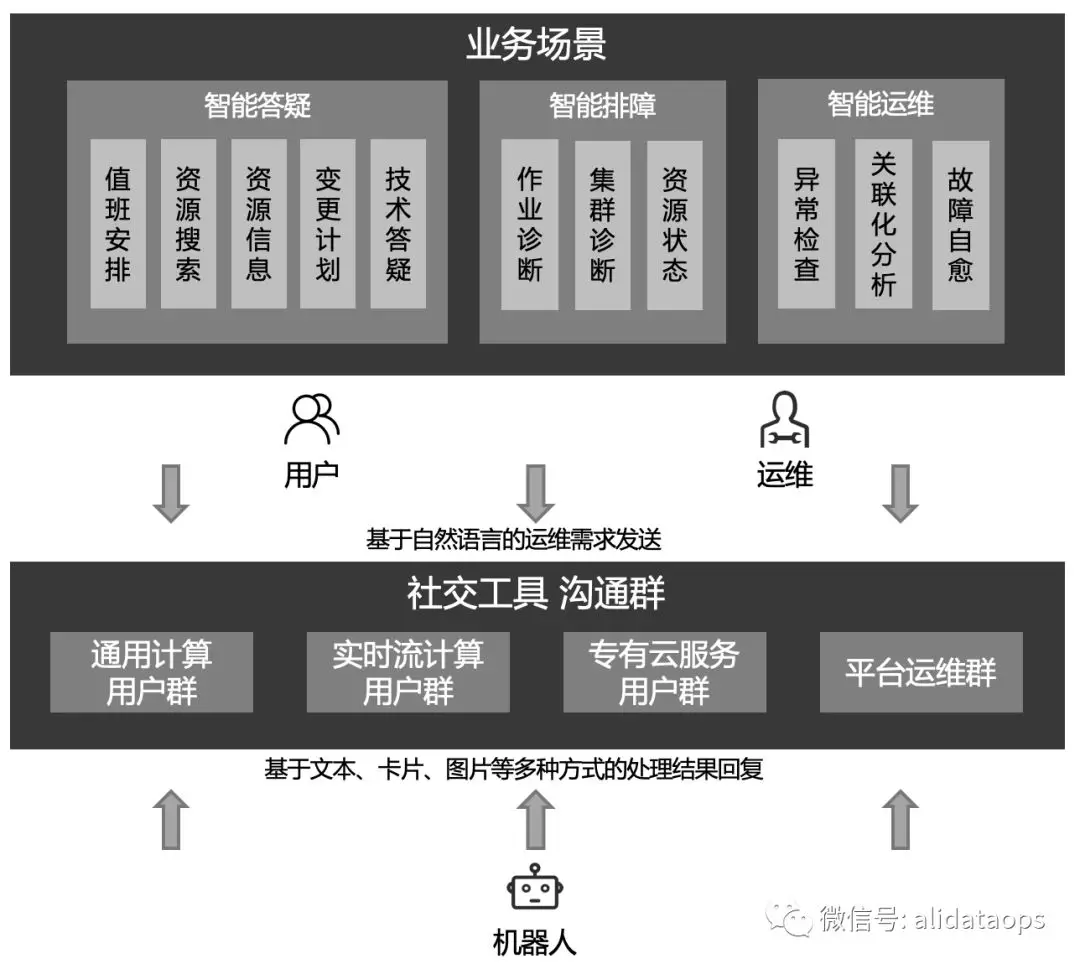
本文选择其中的智能排障与智能答疑两个场景来展开介绍。
1智能排障
大数据计算平台底层都是分布式系统,从纵向看,软件栈上涉及自下而上有硬件、操作系统、分布式存储、分布式调度、分布式锁、Runtime、API Server等极其复杂的模型;从横向上看,数据的采集、传输、在线计算、离线计算、存储等,数据的整个生命周期涉及系统很多。这就导致了问题的定位非常复杂,比如流计算Blink业务场景的智能诊断而言,一个流计算作业运行过程要面临以下复杂的问题:
- 作业所处分布式环境的机器数量多(横向),一个复杂的Blink作业可能涉及上千个Container资源运行在上千台机器上,一个Container中运行几十个blink subtask并发线程
- 作业相关组件数量多,各组件指标多(纵向),blink层本身每个subtask有delay、tps、latency、checkpoint相关等几十指标,Container有队列cpu资源、mem资源等指标、操作系统有CPU、磁盘、网络等相关指标。
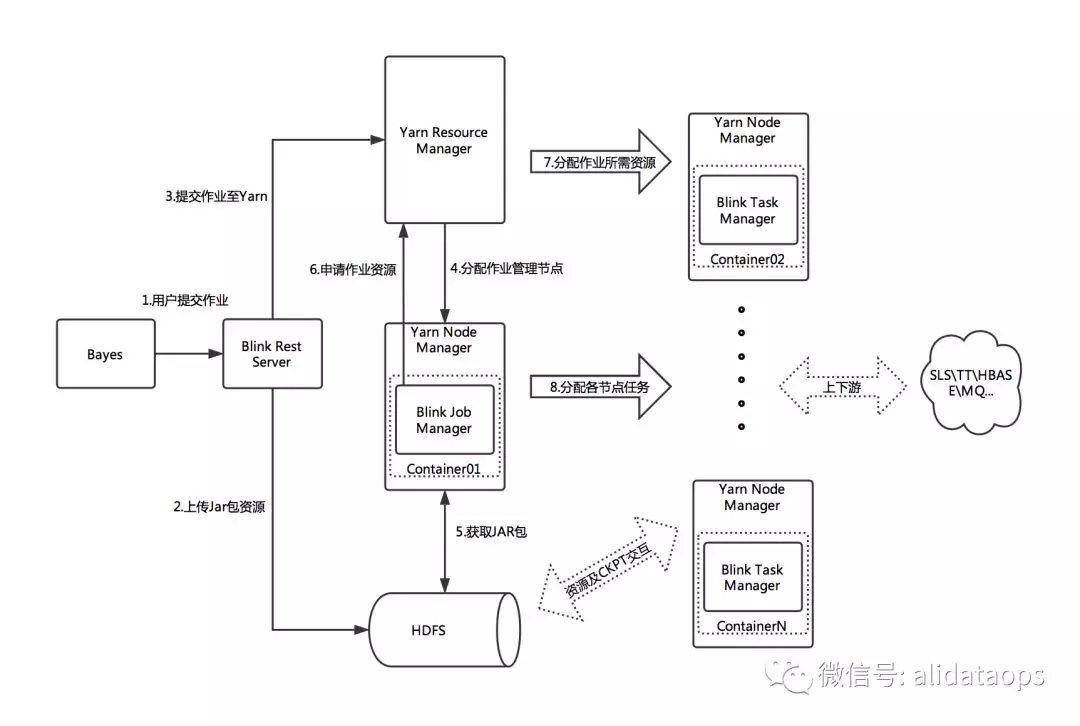
基于以上问题,结合帮助用户解决问题和提高平台稳定性的角度出发,结合数据驱动运维的思路,机器人诊断推出了一键诊断的功能,从众多机器、指标中找出异常节点指标,帮助用户快速定位作业问题。主要包括以下几大类:
应用场景举例
智能答疑机器人有一个核心功能就是对接各个大数据平台的智能诊断,拿流计算平台而言,用户可以便捷的at机器人+作业/集群/机器对运维实体进行基本信息查看和作业诊断。
1、作业诊断
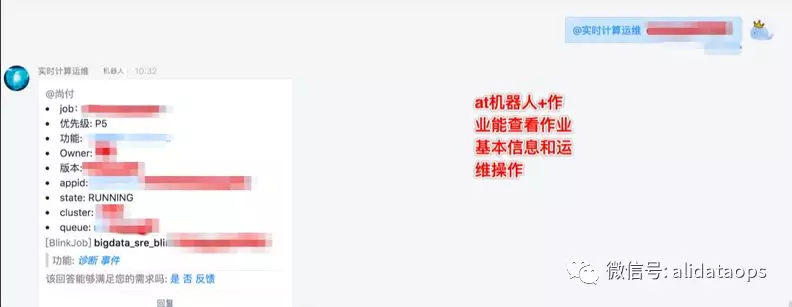
- 作业信息
通过机器人能快捷查看作业的基础信息,包括优先级、版本、集群、用户等,还能有对该作业的运维操作。
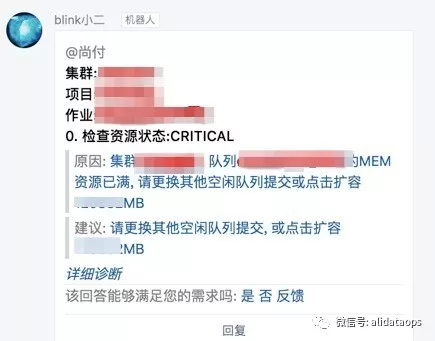
- 资源不足
每个用户都有自己的预算和可用资源,一旦资源不够会导致用户作业无法提交,通过诊断功能可以给用户清晰的告诉用户现在是哪个队列异常,资源不够,具体还差多少,并且有闭环扩容功能提示用户一键扩容。
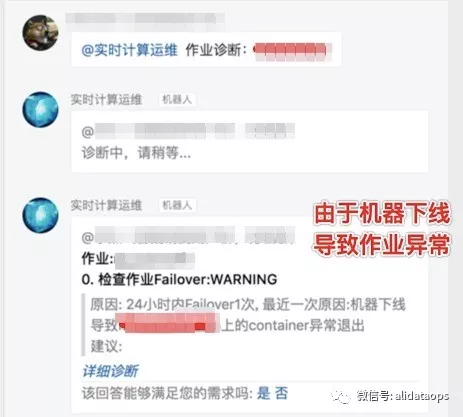
- 机器硬件故障
集群有几万台机器,每天由于硬件故障导致上下线机器是非常频繁的,机器硬件故障会到作业触发FailOver,用户会咨询作业重启原因,智能诊断可以给出“时光机”般的快照:
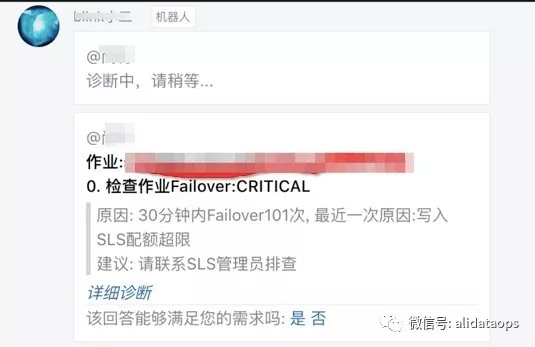
- 数据上下游问题
一个流计算作业会从上游读取数据,消费完成后写到下游,涉及到多个系统交互。有时候并不是Blink系统本身的问题,而是数据上下游系统出问题了,类似被限流、没数据等场景,机器人诊断打通上下游系统的诊断数据,会给出诊断建议:
二、集群/机器诊断
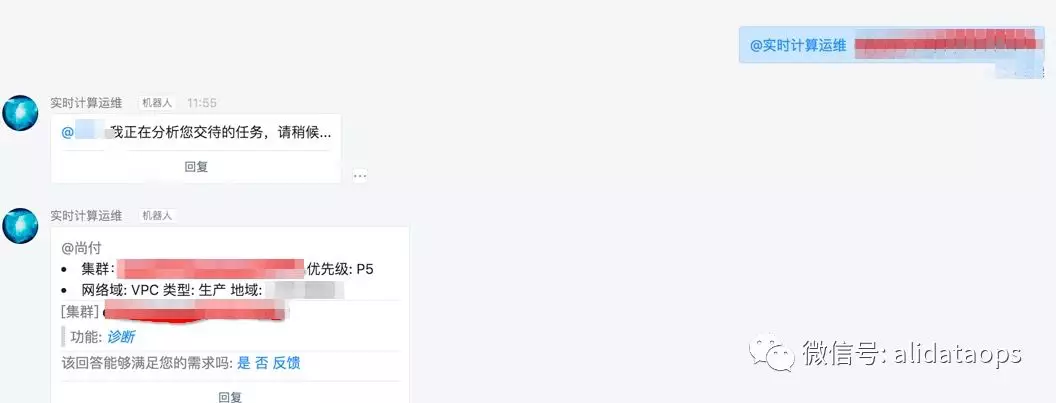
- 集群诊断
一个集群由上万台机器组成,上面部署了分布式系统,各个复杂的模块协同工作,彼此互相依赖。一旦集群出问题,基本上都是大故障,如果在故障时候第一时间定位到具体是哪个服务模块有问题,从而进行详细诊断:
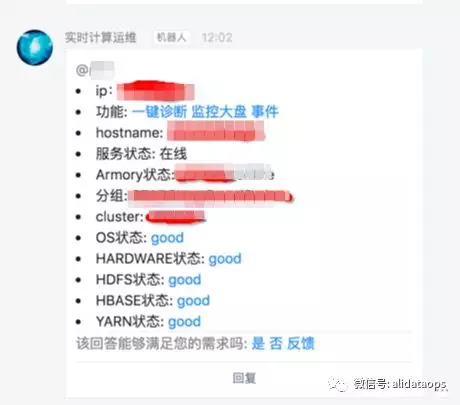
- 机器诊断
机器诊断能快速定位机器上所有模块是否正常,比如Load过高,可以通过详细诊断具体是哪个作业导致的;通用的逻辑还适用于Cpu过高、线程数过高、IO Util打满,从而迅速定位业务作业,并进行相应的自愈
智能答疑
平台用户在开发与运行作业过程中,经常会碰到各种疑惑,包括:
- 资源不够怎么扩容?怎么追加预算?
- 我的作业FailOver是什么原因?
- 集群是不是有变更?机器是不是硬件有问题?
- 各种SQL语法、参数、配置问题?
- ...
此类问题的解答场景,其数量之多、知识面之广,使技术小二答疑难度堪比参加高考。
虽然平台具备完整的用户文档,但我们发现用户依然喜欢在工作群中向小二直接提出问题,原因是:
- 用户希望立即得到准确的答案,而不是需要在关键字匹配的文档中进行翻阅
- 群里可以形成讨论,有类似经验的人员可以帮助解决问题
如今大家在碰到问题时,都非常喜欢使用搜索引擎,因此我们只需要将搜索能力引入到机器人中,配合适当的自然语言分词技术,就可以让机器人起到答疑一线的作用,解决大部份常见问题。
同时,为了让答疑能有更好的效果,需要在以下环节下功夫,提高数据与回复质量:
- 答疑知识库的丰富性:足够丰富的知识内容,才能满足各类关键字的检索,这点下文会介绍知识图谱;
- 答疑知识的关键字标注:对已有的知识提供适当的标签与关键字列表来提高匹配效果,减少不同领域的知识噪音;
- 用户提问的分词领域化:提供各领域的分词优化,去除人类语言中的无意义单词,保留关键字;
- 答案的排名优化:当搜索到多个结果时,需使用匹配度与历史点击率,来优化知识列表,提高首页知识命中率;
应用场景举例
在日常值班过程中,答疑占据了一大部分精力,值班同学要面对小白用户、资深用户、开发运维等各种答疑问题,智能答疑机器人上线后可以自助答疑,后面对接了业务的知识库,解决了这一大痛点。
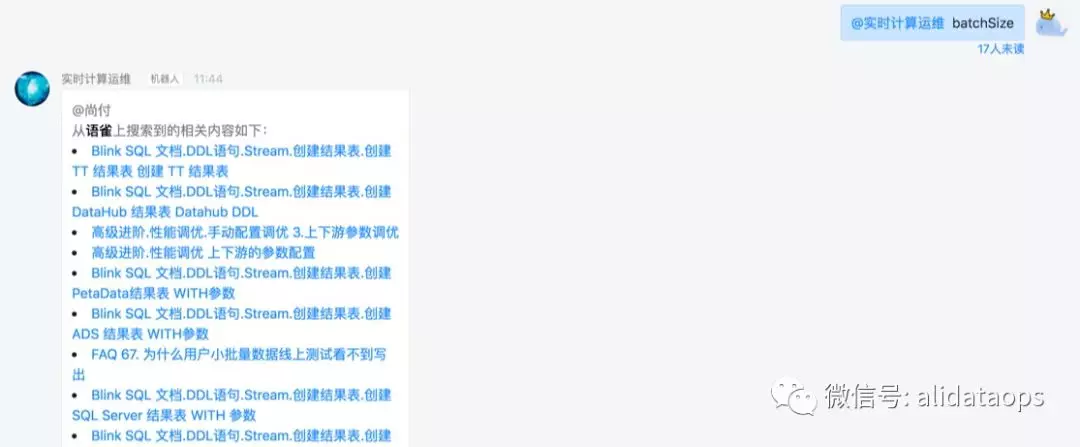
- SQL语法类
用户在日常写SQL过程中,针对语法类的使用可以直接通过机器人搜索,定位到知识库,大大提升写代码的效率。
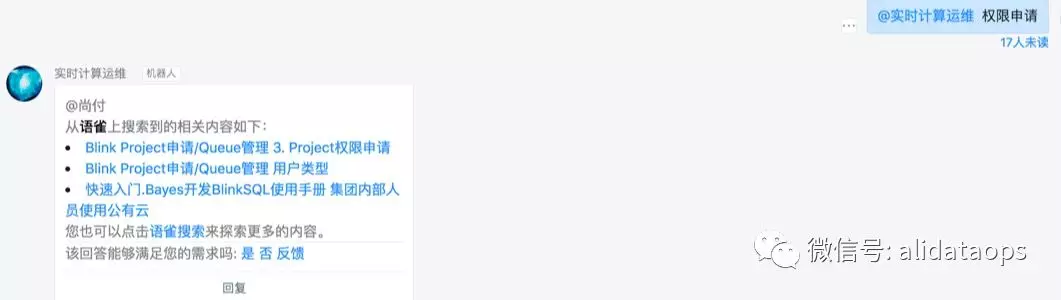
- 运维操作类
对于常规的运维操作,比如:权限申请、资源扩容等可以通过机器人二次交互直达功能:
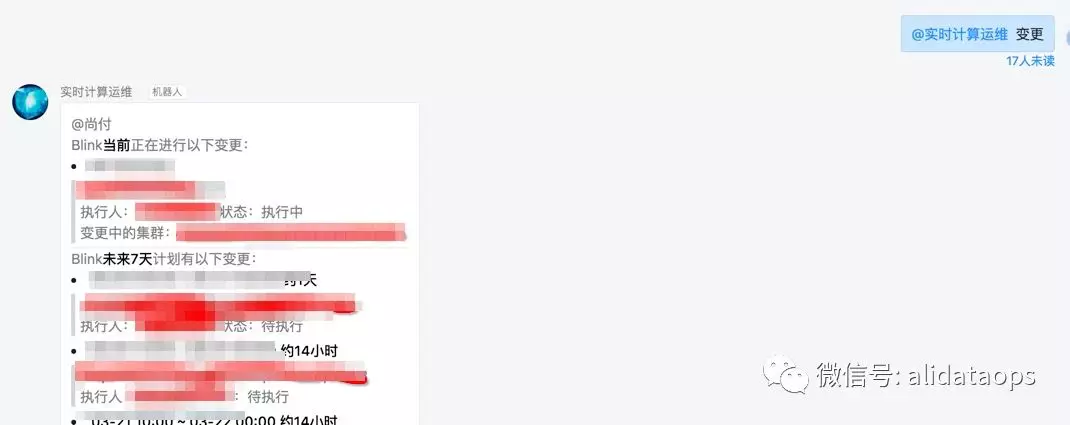
- 信息查询:
日常答疑过程中的针对“热点”问题做了“定制化”回复,比如想知道集群此刻是否有变更?过去、未来一段时间是否有变更,集团封网和熔断的时间点。
机器人技术
目前在社交平台上中增加机器人是一件很容易的事,以下就是一段号称价值百万的机器人代码:
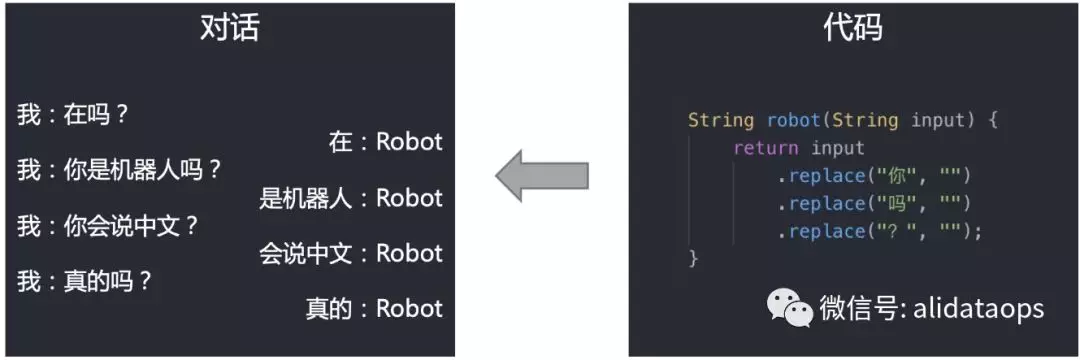
开个玩笑:),实际上大家都知道自然语言处理(NLP)是非常难的领域,但因为NLP难而不做机器人是一个误区。
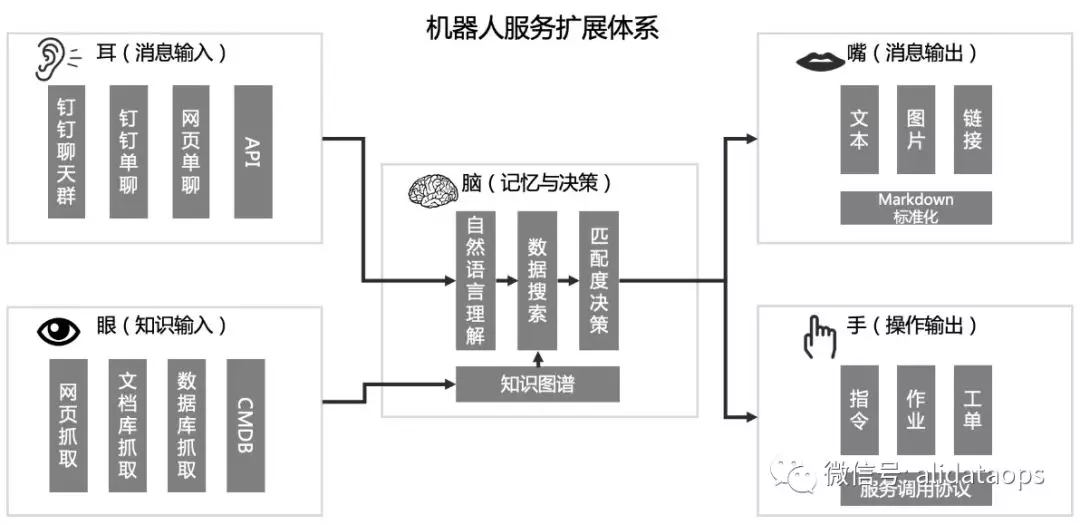
在我们工作中可以起到帮助的机器人,并不需要在NLP上有多大的投入,而关键是提供足够的知识与服务支撑,来满足特定领域的业务需求,机器人只是起到一个门户效果,也可以理解它是一个存在于社交平台上的搜索入口。下图是我们的机器人服务生态架构:
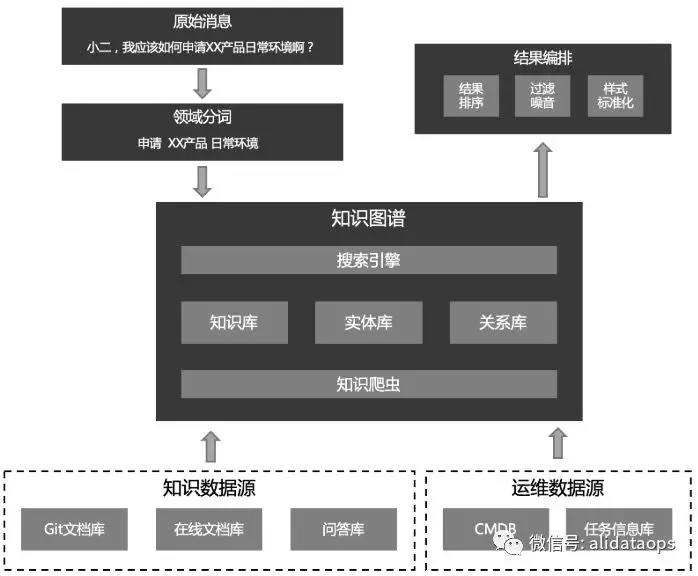
知识图谱
可以看出,在问答领域,知识图谱起到了机器人的大脑记忆库的核心作用,其的知识丰富性与检索质量,是提高答复效率的关键。同时,由于运维领域还存在海量的实体数据(主机、作业、应用等等),知识图谱并不能简单的使用问答库来进行建设。因此我们提出知识图谱概述,采用ElasticSearch作为核心数据库,结合数据联邦、同步、爬虫实现各类运维内容的统一与检索入口:
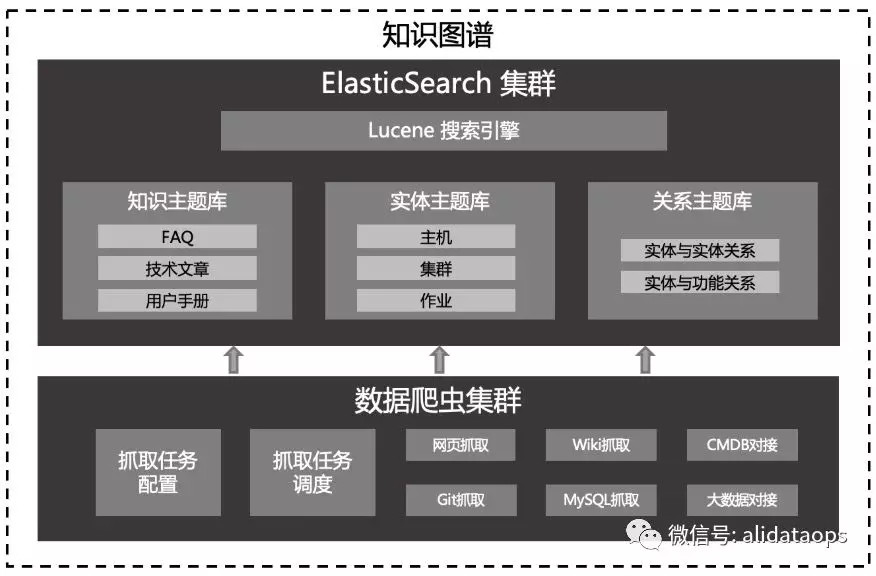
随着知识图谱接入内容的增加,它很快也变成了一个庞大的怪物。初期发展可能还能够采用统一的存储,但是随着业务的发展,我们将越来越难通过统一的存储完成完整的知识图谱的构建,而且由于历史原因,我们本来就有大量结构化的数据存储在不同的产品上,我们应该借助于这些产品已有的存储计算能力来统一构建知识图谱,而不是抛弃他们,这样可以以最小的代价拿到最好的结果。
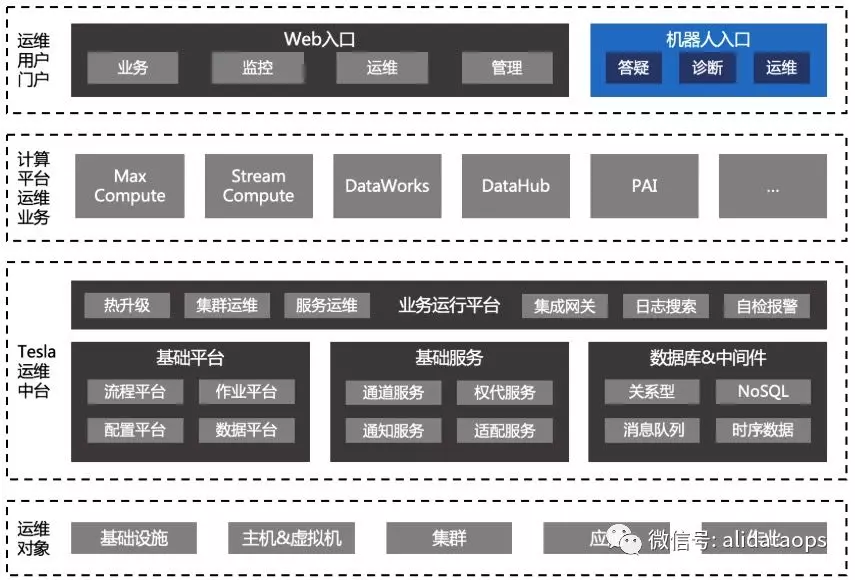
5运维平台
而计算平台的自动化运维系统Tesla,则为机器人提供了强大的能力支持。通过机器人的服务插件体系,将运维系统的答疑、诊断、运维等服务,都集成到机器人中。使机器人成为一个来自社交平台的服务与流量入口,用户可以从机器人处直接到到一些功能的结果(如诊断),也可以点击链接进入平台使用具体的功能。
小结
我们的新成员已经投入工作一年多,独当一面能完成具体的服务引导与排障答疑等场景。我们后续还将继续在以下方面进行改进:
- 增加知识的阅读理解能力,以便根据长篇的文档形成简短的问题答案,加快现有知识文档的转换;
- 提高自然语言理解能力,如通过提问的相似度计算,来解答同一个问题的多种不同提法;
- 增加个性化服务,针对用户形成个性化结果推荐与相关信息主动通知。
原文发布时间为:2019-03-27
本文作者: 王华/蒋君伟
本文来自云栖社区合作伙伴“AliDataOps”,了解相关信息可以关注“ AliDataOps”。
阿里大数据运维新成员——24小时待命!有求必应!能说会做!...相关推荐
- 大数据运维实战第一课 大话 Hadoop 生态圈
你好,欢迎来到<大数据运维实战>专栏. 入行以来,我从事大数据运维也有十多年了,期间我做过系统运维.DBA,也做过大数据分析师,最后选择了大数据运维方向,曾设计并管理超过千台.PB 级的数 ...
- 大数据开发、大数据分析、大数据运维主要工作各是什么?哪个好?
本文转自https://blog.csdn.net/weixin_34318956/article/details/87302823 首先,工作本身没有好坏之分,只有门槛高低之别.大数据开发.大数据分 ...
- 大数据开发、大数据分析、大数据运维主要工作各是什么?哪个好?谢谢?
首先,工作本身没有好坏之分,只有门槛高低之别.大数据开发.大数据分析.大数据运维都围绕着大数据展开.如果我们把大数据去掉,就只剩下,开发,分析,运维.当然还有其它的工作,例如运营,产品,讲师,测试等. ...
- 魅族大数据运维平台实践
一.大数据平台介绍 1.1大数据平台架构演变 如图所示魅族大数据平台架构演变历程: 2013年底,我们开始实践大数据,并部署了测试集群.当时只有三个节点,因为我们起步比较晚,没有赶上Hadoop1.0 ...
- 阿里大数据技术如何进化?资深技术专家带你回顾
阿里妹导读:很多童鞋在后台留言,希望看到大数据相关的文章.因此,今天带来一篇阿里资深专家观滔在2017年云栖大会的精彩分享,为大家展示阿里大数据计算服务的进化演进.以及MaxCompute解读. 一. ...
- 详解:从Greenplum、Hadoop到现在的阿里大数据技术
对于企业来说,但是到底云计算是什么呢?相信很多企业都有这样的困惑,让我们一起回到这个原始的起点探讨究竟什么是云计算?云计算对于企业而言到底意味什么? 云计算的三条发展路径及三种落地形态 当回到最初的起 ...
- 阿里大数据部门真实工作场景,和你想象的一样吗?
BI工程师.数据仓库工程师.ETL工程师.数据开发工程师(大数据开发工程师) 有什么区别? 一味的解释数据仓库概念可能没意思,我们从不同角色出发吧 老板 :我是一家手机公司的老板,今天要向去董事局汇报 ...
- 大数据运维工作(Linux,OGG,链路监控,Hadoop运维等)
大数据运维工程师工作内容 Linux运维手册 1. 启动/关闭集群组件 1.1 负载均衡 1)Nginx 运维命令 Copy to clipboard cd /usr/nginx/sbin #进入 s ...
- 第一章 阿里大数据产品体系
1.大数据基础知识 什么是数据分析? 数据分析是基于商业目的,有目的的进行收集.整理.加工和分析数据,提炼有价值信息的过程. 数据分析流程:需求分析明确目标➡️数据收集加工处理➡️数据分析数据展现➡️ ...
- 【赵渝强老师】阿里云大数据ACP认证之阿里大数据产品体系
阿里大数据产品体系是基于阿里云飞天平台上的数据处理服务.主要分为阿里云大数据基础产品和阿里云数加平台,其产品架构图如下所示: 一.阿里云大数据基础产品 1.云数据库--RDS(ApsaraDB for ...
最新文章
- asp自动解析网页中的图片地址,并将其保存到本地服务器
- K-Means ++ 和 kmeans 区别
- k8s minikube管理镜像相关命令:minikube image list/pull/load
- set trans 必须是事务处理的第一个语句_MySQL中特别实用的几种SQL语句送给大家
- double operator[](int i)_java中double类型精度丢失问题及解决方法
- [Ubuntu] Your Firefox profile cannot be loaded. It may be missing or inaccessible
- 问题十八:怎么对ray tracing图形进行消锯齿
- 常量 变量 赋值 c
- 矩阵分析与应用(四)——逆矩阵、广义逆矩阵和Moore-Penrose逆矩阵
- 外壳IK防护等级测试
- 【软件工程师学硬件】之 接口
- 支配树学习思路/模板
- 解决Java应用的后台错误:“操作符不存在: character varying = bytea“
- 互联网公司对Android,iOS开发工程师的职位要求
- 【乐通达】微信永不缺席!连发三大重磅更新,视频号终于成了视频号
- 【机器学习 深度学习】通俗讲解集成学习算法
- Android开发常见面试
- 力扣(39.40)补9.20
- 第九章:项目资源管理 - (9.4 建设团队)
- 美国知名科技公司入门级软件工程师的薪水排名