基于PaddleX的化妆品识别
飞桨全流程开发工具-PaddleX
PaddleX是飞桨全流程开发工具,集飞桨核心框架、模型库、工具及组件等深度学习开发所需全部能力于一身,打通从数据接入到推理部署的深度学习开发全流程,简化各环节串联工作,大幅提升开发效率。
PaddleX提供API和可视化界面Demo两种使用模式,简明易懂的Python API,方便用户根据实际生产需求直接调用或二次开发,为开发者提供飞桨全流程开发的最佳实践,用户通过简单集成即可生产所在行业的专属AI工具。
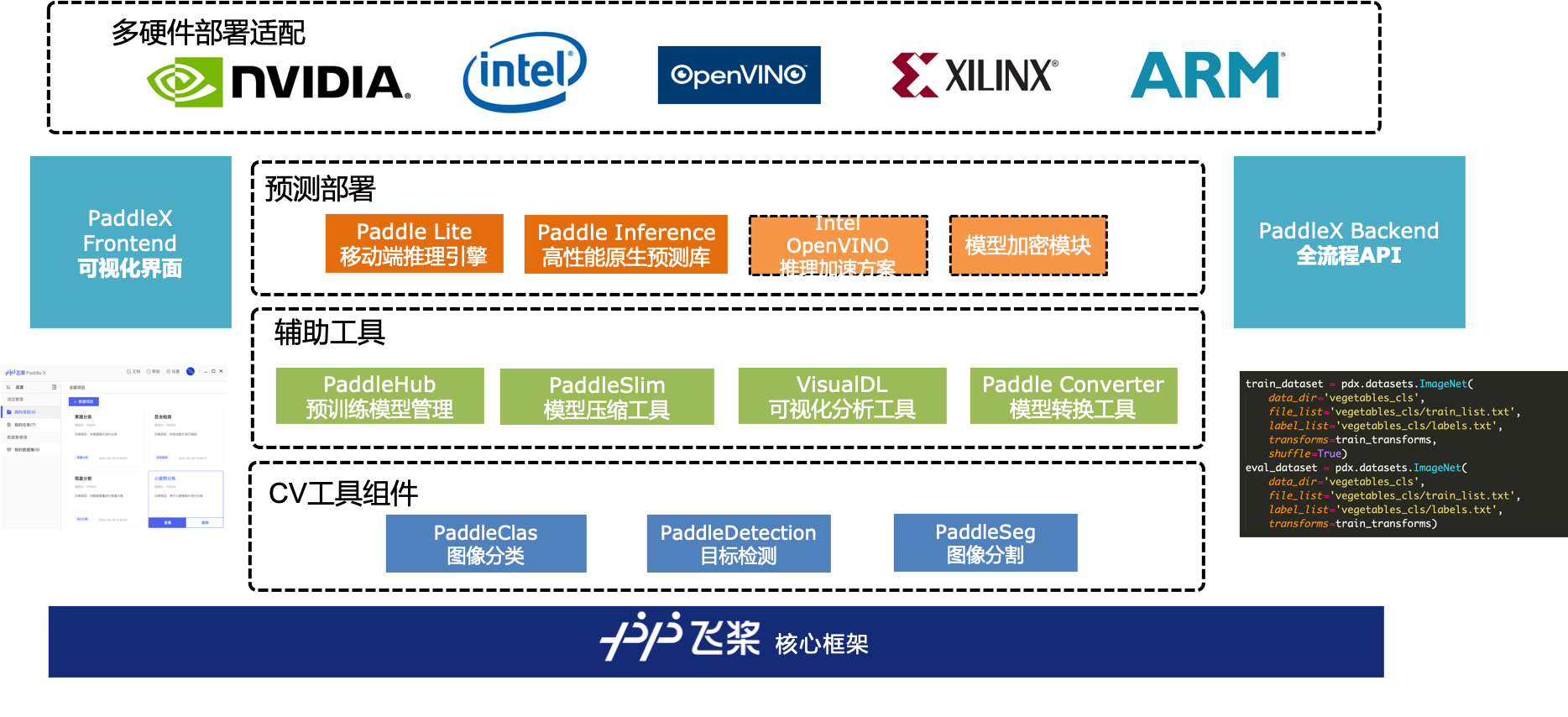
PaddleX具备以下特点:
- 全流程打通:打通从数据接入到推理部署的深度学习开发全流程,简化各环节串联工作,大幅提升开发效率。
- 开源技术内核:集成飞桨领先的视觉算法和工具组件,提供简明易懂的Python API,完全开源开放,易于集成和二次开发。
- 产业深度兼容:兼容Windows、Mac、Linux系统,支持GPU加速模型训练,并且是本地开发,可确保数据安全,符合产业应用的需求。
- 完善的教程与服务:丰富的全流程开发文档,高效的技术服务支持,提供多种方式方便用户与技术团队直接交流。
PaddleX 图形化开发界面
为了帮助开发者更好的了解飞桨的开发步骤以及所涉及的模块组件,进一步提升项目开发效率,飞桨为开发者提供了基于PaddleX实现的图形化开发界面示例,用户可以基于该界面示例进行改造,开发符合自己习惯的操作界面。开发者可以根据实际业务需求,直接调用或改造PaddleX后端技术内核来开发项目,或使用图形化开发界面快速体验飞桨模型开发全流程。

PaddleX 快速使用方法
下面以MobileNetV3_ssld完成化妆品分类为例,介绍PaddleX训练模型方式。
MobileNetV3_ssld是通过SSLD(简单的半监督标签知识蒸馏)方式得到的新模型。相对比原有的MobileNetV3预训练模型,在参数量不变的情况下,MobileNetV3_ssld预训练模型在ImageNet数据集上的精度提升3%。
在下文中,我们将介绍API和可视化界面Demo两种使用PaddleX的方法。
1. 安装paddleX
! pip install paddlex -i https://mirror.baidu.com/pypi/simple
2. 准备化妆品分类数据集
下载并解压数据集,数据形式如下,展示了图片样本和对应的分类标签:

! wget https://bj.bcebos.com/paddlex/datasets/makeup.tar.gz
! tar xzf makeup.tar.gz
3. 训练准备
3.1 配置训练环境,并导入PaddleX库
# jupyter中使用paddlex需要设置matplotlib
import matplotlib
matplotlib.use('Agg')
# 设置使用0号GPU卡(如无GPU,执行此代码后仍然会使用CPU训练模型)
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
import paddlex as pdx
3.2 定义图像处理流程transforms
定义训练和验证过程中的图像处理流程,其中训练过程包括了部分数据增强操作(验证时不需要),如在本示例中,训练过程使用了RandomCrop和RandomHorizontalFlip两种数据增强方式,更多图像预处理流程transforms的使用可参见paddlex.cls.transforms。
from paddlex.cls import transforms
train_transforms = transforms.Compose([transforms.RandomCrop(crop_size=224),transforms.RandomHorizontalFlip(),transforms.Normalize()
])
eval_transforms = transforms.Compose([transforms.ResizeByShort(short_size=256),transforms.CenterCrop(crop_size=224),transforms.Normalize()
])
3.3 定义数据集Dataset
使用PaddleX内置的数据集读取器读取训练和验证数据集,并应用上面配置的图像处理流程。本示例采用ImageNet数据集格式,因此这里采用pdx.datasets.ImageNet来加载数据集,该接口的介绍可参见文档paddlex.datasets.VOCDetection。
train_dataset = pdx.datasets.ImageNet(data_dir='makeup',file_list='makeup/train_list.txt',label_list='makeup/labels.txt',transforms=train_transforms,shuffle=True)
eval_dataset = pdx.datasets.ImageNet(data_dir='makeup',file_list='makeup/val_list.txt',label_list='makeup/labels.txt',transforms=eval_transforms)2020-05-11 10:17:47 [INFO] Starting to read file list from dataset...
2020-05-11 10:17:47 [INFO] 710 samples in file makeup/train_list.txt
2020-05-11 10:17:47 [INFO] Starting to read file list from dataset...
2020-05-11 10:17:47 [INFO] 132 samples in file makeup/val_list.txt
3.4 开始训练模型
在定义好数据集后,即可选择分类模型(这里使用了MobileNetV3_large_ssld模型)开始训练。MobileNetV3_large是面向移动端应用场景的模型,而MobileNetV3_large_ssld是百度通过SSLD蒸馏策略所得的模型,具有更高的精度表现。
关于分类模型训练,更多参数介绍可参见文档paddlex.cls.MobileNetV3_large_ssld。在如下代码中,模型训练过程每间隔save_interval_epochs轮次,会保存一次模型在save_dir目录下,同时在保存的过程中也会在验证数据集上计算相关指标,模型训练过程中相关日志的含义可参见文档。
注:本数据集在P40 GPU上训练MobileNetV3_large_ssld,模型的训练过程预估为10分钟左右;如无GPU,则预估为30分钟左右。
num_classes = len(train_dataset.labels)
model = pdx.cls.MobileNetV3_large_ssld(num_classes=num_classes)
model.train(num_epochs=10,train_dataset=train_dataset,train_batch_size=32,eval_dataset=eval_dataset,lr_decay_epochs=[4, 6, 8],save_interval_epochs=1,learning_rate=0.025,save_dir='output/mobilenetv3_large_ssld')
4. 模型预测
result = model.predict('makeup/mascara/27.jpeg', topk=1)
print("Predict Result:", result)
Predict Result: [{'category_id': 5, 'category': 'eyebrow', 'score': 0.86157554}]
当然,PaddleX的功能不止这么简单,这是一个极简功能的展示案例。实际上,PaddleX可以和PaddleSeg、PaddleClass、PaddleDec等开发套件一样,实现非常丰富的模型和训练配置。如果读者对这些功能感兴趣,欢迎继续查阅PaddleX的文档,或者可以通过PaddleX官方提供的图形化界面Demo了解。该Demo完整展示了基于PaddleX的API可以完成的功能,而且PaddleX的界面读者可以根据自己的需要重新设计。
PaddleX客户端使用方法
1. 下载PaddleX客户端。
您需要前往官网填写基本信息后下载试用PaddleX客户端。
2. 准备数据
在开始模型训练前,需要根据不同的任务类型,将数据标注为相应的格式。目前PaddleX支持图像分类、目标检测、语义分割、实例分割四种任务类型。不同类型任务的数据处理方式可查看数据集格式说明。
3. 导入数据集
(1)数据标注完成后,您需要根据不同的任务,将数据和标注文件,按照客户端提示更名并保存到正确的文件中。
(2)在客户端新建数据集,选择与数据集匹配的任务类型,并选择数据集对应的路径,将数据集导入。

如果想用自己的数据集,可以上传自己的数据集,这里我们以化妆品分类为例,上传化妆品的数据集。

上传成功后,会出现如下界面,如果需要重新划分训练集、验证集、测试集时,可以选择重新划分:
- 训练集:用来训练模型
- 验证集:中间小测验,用于进行模型评估,找到最优模型
- 测试集:最终测试模型在现实场景的泛化误差,避免过拟合

4.创建项目
(1)在完成数据导入后,可点击“新建项目”创建一个项目。
(2)可根据实际任务需求选择项目的任务类型,需要注意项目所采用的数据集也带有任务类型属性,两者需要进行匹配。

5.项目开发
(1)选择数据:项目创建完成后,需要选择已载入客户端并校验后的数据集,并点击“下一步”,进入参数配置页面。

(2)配置参数:主要分为模型参数、训练参数、优化策略三部分。可根据实际需求选择模型结构及对应的训练参数、优化策略,使得任务效果最佳。

另外,可以在客户端中选择不同的数据增强方式:

参数配置完成后,点击“启动训练”,模型开始训练并进行效果评估。
(3)训练可视化:在训练过程中,可通过VisualDL查看模型训练过程时的参数变化、日志详情,及当前最优的训练集和验证集训练指标。模型在训练过程中通过点击“终止训练”随时终止训练过程。

PaddleX集成了飞桨可视化分析工具VisualDL,可以很方便地查看训练过程的指标数据。

模型训练结束后,点击”下一步“,从客户端中,也可以看到训练的完成进度和验证集精度。
(4)模型发布:当模型效果满意后,可根据实际的生产环境需求,将模型发布为需要的版本。

注意:这个带可视化界面的AI研发软件仅仅是基于PaddleX API做出来的一个Demo。受此启发,欢迎读者使用PaddleX API研发一款适合自己所在企业或行业使用的AI研发工具,整个软件的功能可以根据场景的需要来灵活定制。
---------------------华丽的分割线-------------------------
我自己的基于PaddleX的化妆品识别
- 增加香水类的数据集
增加一类数据集
通过爬虫爬取香水的图片,增加perfume(香水)一类的数据集
- 香水数据集的图片

- 8类图片数据文件夹
PaddleX新建数据集
建立自己的数据集
![]()
![]()
PaddleX数据选择
添加需要学习的数据
![]()
![]()
PaddleX参数配置
设置合适的参数
![]()
PaddleX训练可视化
开启训练,同时可视化
![]()
![]()
![]()
PaddleX模型评估
对模型进行评估
![]()
![]()
PaddleX模型发布
发布训练好的模型
![]()
最终模型效果
模型整体指标:
![]()
模型测试结果:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
# 本地导出模型上传work文件夹
# 适当修改predict.py
!cd /home/aistudio/work
!python work/predict.py# 运行可以看到[{'category_id': 0, 'category': 'blush', 'score': 0.99619496}],运行成功
总结
联系作者
- 作者GitHub:点击here
- 作者博客:点击here
- AI Studio链接:点击here
在本节中,简单的介绍了PaddleX的训练模型的使用方式,更多的使用请参考官方文档和PaddleX的Github。
基于PaddleX的化妆品识别相关推荐
- 基于PaddleX的智能零售柜商品识别
摘 要 在传统的零售柜中,实现自动识别的方法主要有:硬件分隔.根据重量判断.识别顾客的行为.射频识别标记等.本文基于深度学习在图像分类领域的优异性能,研究基于PaddleX的智能零售柜商品识别,相比于 ...
- 基于PaddleX实现的安全帽检测
安全帽检测 基于PaddleX 2.0开发 1.项目说明 在该项目中,主要向大家介绍如何使用目标检测来实现对安全帽的检测,涉及代码以及优化过程亦可用于其它目标检测任务等. 在施工现场,对于来往人员,以 ...
- 基于Python的验证码识别技术
基于Python的验证码识别技术 作者:强哥 概述 前言 准备工作 识别原理 图像处理 切割图像 人工标注 训练数据 检测结果 搞笑一刻 福利一刻 推荐阅读 前言 很多网站登录都需要输入验证码,如果要 ...
- 基matlab的水果识别的应用,基于MATLAB的水果识别的数字图像处理
基于MATLAB的水果识别的数字图像处理 图像处理 ( 报告 ) 题目 基于 MATLAB 的 水果识别的数字图像处理 指导教师 职称 教授 学生姓名 学号 专 业 院(系) 完成时间 2016 年 ...
- python人脸识别毕业设计-Python基于Dlib的人脸识别系统的实现
之前已经介绍过人脸识别的基础概念,以及基于opencv的实现方式,今天,我们使用dlib来提取128维的人脸嵌入,并使用k临近值方法来实现人脸识别. 人脸识别系统的实现流程与之前是一样的,只是这里我们 ...
- 图像处理之基于NCC模板匹配识别
图像处理之基于NCC模板匹配识别 一:基本原理 NCC是一种基于统计学计算两组样本数据相关性的算法,其取值范围为[-1, 1]之间,而对图像来说,每个像素点都可以看出是RGB数值,这样整幅图像就可以看 ...
- 基于matlab的人脸五官边缘检测方法,基于MATLAB的人脸识别系统的设计
基于MATLAB的人脸识别系统的设计(论文12000字,外文翻译,参考程序) 摘要:本文基于MATLAB平台设计了一款简单的人脸识别系统,通过USB摄像头来采集图像,经过肤色方法进行人脸检测与定位,然 ...
- 数字图像处理:基于MATLAB的车牌识别项目
学过了数字图像处理,就进行一个综合性强的小项目来巩固一下知识吧.前阵子编写调试了一套基于MATLAB的车牌识别的项目的代码.今天又重新改进了一下代码,识别的效果好一点了,也精简了一些代码.这里没有使用 ...
- 『森林火灾检测』基于PaddleX实现森林火灾检测
效果预览 B站链接 AIStudio链接 项目背景 2019年3月30日17时 ,凉山州木里县境内发生森林火灾,30名扑火人员牺牲. 2020年3月30日15时35分,凉山州西昌市经久乡和安哈 ...
最新文章
- 图片转字符 android,转字符图app下载-转字符图 安卓版v2.4-PC6安卓网
- CSS3---8.盒模型
- 卷积Groups Group Convolutions
- 160个Crackme013之投机取巧
- jakarta ee_MicroProfile在Jakarta EE时代的作用
- 集群服务负载均衡------LVS
- Java SSM1——Maven
- lan pci 联想开机_微软承认KB4568831导致部分联想ThinkPad笔记本崩溃和蓝屏
- if条件的默认转换规则:
- 使用Vitamio打造自己的Android万能播放器(4)——本地播放(快捷搜索、数据存储)...
- 数据库相关概念与编程使用方式
- bad response Not Found 404
- uniapp 二维码生成器 uQRCode
- struct.error: short format requires (-32768) <= number <= 32767
- 论文总结之任务型对话NLU
- 【转】使用cocosbuilder在cocos2d-…
- Instruments 之 Energy Log
- css3的弹性盒子模型,css3弹性盒子模型——回顾。
- 抖音二面:为什么模块循环依赖不会死循环?CommonJS和ES Module的处理不同?
- mysql技术之innodb存储引擎