扩展CUDA SDK 2.3 の convolutionSeparable
SDK2.3的convolutionSeparable示例,纯代码,零注释,忒血汗。。汗了半小时才o掉,帖出来供大家参考。
离散数据的二维卷积:
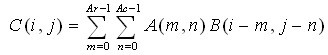
其中,Ar、Ac分别是A的行数与列数。应用很多,比如对图像做高斯平滑(去噪),拿高斯核与输入图像做卷积。
convolutionSeparable之所以”Separable”,是因为它在row、col两个维上分别做了卷积操作。在此先奉上CPU代码,无敌明了<本帖只讲述row方向上的,col上的太类似了,自己看咯>
|
// Reference row convolution filter extern "C" void convolutionRowCPU( float *h_Dst, float *h_Src, float *h_Kernel, int imageW, int imageH, int kernelR//-8 ){ for(int y = 0; y < imageH; y++) for(int x = 0; x < imageW; x++){ float sum = 0; for(int k = -kernelR; k <= kernelR; k++){ int d = x + k;//即左右各8个,外加自己本位上的,共17个元素做邻域加权 if(d >= 0 && d < imageW) sum += h_Src[y * imageW + d] * h_Kernel[kernelR - k];//h_src视为上式中B阵,h_kernel视为A阵(本例中h_kernel为随机给出的核,用户可以自己写高斯核玩) } h_Dst[y * imageW + x] = sum; } } |
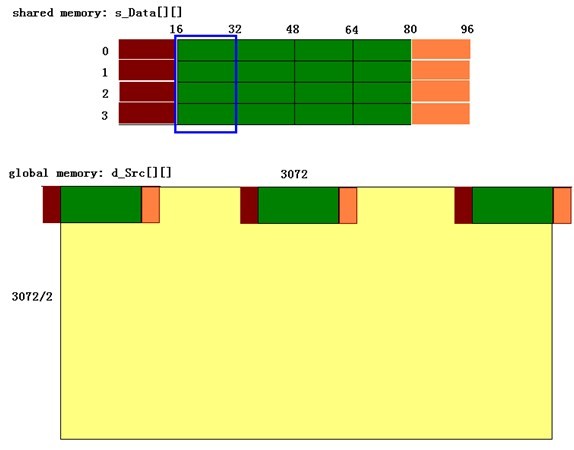
好了,下面想想CUDA怎么实现,每个block完成什么样的任务,每个thread又负责完成怎样的任务。下图分别是每个block的共享存储体数组s_Data[4][96]、全局存储器里的输入数组d_Src[3072/2][3072]。线程组织结构是这样的:grid( imagW/(ROWS_RESULT_STEPS*ROWS_BLOCKDIM_X), imagH/ROWS_BLOCKDIM_Y ), block(ROWS_BLOCKDIM_X, ROWS_BLOCKDIM_Y)。其中ROWS_BLOCKDIM_X为16,ROWS_BLOCKDIM_Y为4,表明block内线程组织结构是16*4;ROWS_RESULT_STEPS 为4,表明一个block每次做4轮操作,看图中s_Data的绿色部分,每次一个block即16*4个线程对应计算一个蓝色框框标注的部分,一个线程负责计算一个位置上的数据,做4轮于是就有了4列绿矩嘛。注意,最左边的一列红阵和最右边的一列橙阵特别标出,这是在进行一些“越界处理”,例如计算d_src[][]最左边的元素时,它们的“左边8个元素”(事实上已经不能再左了),这时红色阵置0,同理理解橙阵。
下面再来看这段kernel代码,顺风顺水了是不是。。
|
// Row convolution filter #define ROWS_BLOCKDIM_X 16 #define ROWS_BLOCKDIM_Y 4 #define ROWS_RESULT_STEPS 4 #define ROWS_HALO_STEPS 1 __global__ void convolutionRowsKernel( float *d_Dst, float *d_Src, int imageW, int imageH, int pitch ){ __shared__ float s_Data[ROWS_BLOCKDIM_Y][(ROWS_RESULT_STEPS + 2 * ROWS_HALO_STEPS) * ROWS_BLOCKDIM_X]; //Offset to the left halo edge const int baseX = (blockIdx.x * ROWS_RESULT_STEPS - ROWS_HALO_STEPS) * ROWS_BLOCKDIM_X + threadIdx.x; const int baseY = blockIdx.y * ROWS_BLOCKDIM_Y + threadIdx.y; d_Src += baseY * pitch + baseX; d_Dst += baseY * pitch + baseX; //Main data #pragma unroll for(int i = ROWS_HALO_STEPS; i < ROWS_HALO_STEPS + ROWS_RESULT_STEPS; i++)//i=1,i<5 s_Data[threadIdx.y][threadIdx.x + i * ROWS_BLOCKDIM_X] = d_Src[i * ROWS_BLOCKDIM_X]; //Left halo for(int i = 0; i < ROWS_HALO_STEPS; i++){//i=0,i<1 s_Data[threadIdx.y][threadIdx.x + i * ROWS_BLOCKDIM_X] = (baseX >= -i * ROWS_BLOCKDIM_X ) ? d_Src[i * ROWS_BLOCKDIM_X] : 0; } //Right halo for(int i = ROWS_HALO_STEPS + ROWS_RESULT_STEPS; i < ROWS_HALO_STEPS + ROWS_RESULT_STEPS + ROWS_HALO_STEPS; i++){ s_Data[threadIdx.y][threadIdx.x + i * ROWS_BLOCKDIM_X] = (imageW - baseX > i * ROWS_BLOCKDIM_X) ? d_Src[i * ROWS_BLOCKDIM_X] : 0; } //Compute and store results __syncthreads(); #pragma unroll for(int i = ROWS_HALO_STEPS; i < ROWS_HALO_STEPS + ROWS_RESULT_STEPS; i++){ float sum = 0; #pragma unroll for(int j = -KERNEL_RADIUS; j <= KERNEL_RADIUS; j++) sum += c_Kernel[KERNEL_RADIUS - j] * s_Data[threadIdx.y][threadIdx.x + i * ROWS_BLOCKDIM_X + j]; d_Dst[i * ROWS_BLOCKDIM_X] = sum; } } extern "C" void convolutionRowsGPU( float *d_Dst, float *d_Src, int imageW, int imageH ){ assert( ROWS_BLOCKDIM_X * ROWS_HALO_STEPS >= KERNEL_RADIUS ); assert( imageW % (ROWS_RESULT_STEPS * ROWS_BLOCKDIM_X) == 0 ); assert( imageH % ROWS_BLOCKDIM_Y == 0 ); dim3 blocks(imageW / (ROWS_RESULT_STEPS * ROWS_BLOCKDIM_X), imageH / ROWS_BLOCKDIM_Y); dim3 threads(ROWS_BLOCKDIM_X, ROWS_BLOCKDIM_Y); convolutionRowsKernel<<<blocks, threads>>>( d_Dst, d_Src, imageW, imageH, imageW ); cutilCheckMsg("convolutionRowsKernel() execution failed/n"); } |
另外,偶稀饭这张照片,也要帖出来。。不要拦偶。。

另外,我对程序进行了一些改进,使其可以处理任意宽*任意高的大小,不一定非要是16或64或什么什么的整数倍,而且对边界做了clamp处理,SDK的程序边界处理不好(越界的填充0,模糊两下边界就白白了),我是将越界的都填充为它最临近的那个像素点的值,这样模糊下来,边界效果几乎不变。具体程序可以参见我上传的这份源码,需要的朋友直接调用就好。
扩展CUDA SDK 2.3 の convolutionSeparable相关推荐
- 使用CUDA显卡加速SDK实现 H264编码
CUDA(Compute Unified Device Architecture),显卡厂商NVIDIA推出的运算平台.CUDA™是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂 ...
- 【并行计算-CUDA开发】从零开始学习OpenCL开发(一)架构
多谢大家关注 转载本文请注明:http://blog.csdn.net/leonwei/article/details/8880012 本文将作为我<从零开始做OpenCL开发>系列文章的 ...
- CUDA安装及配置:Windows 7 64位环境
最近又有新的项目要做了,这次是关于CUDA---多核高性能计算的问题,所以最近一直在学习CUDA的编程问题,昨天安装软件完毕,运行第一个程序的时候还是遇到很多问题.所以这里给大家一起分享一下, 有和我 ...
- CUDA在Windows下的软件开发环境搭建
http://www.cnblogs.com/yaoyuanzhi/archive/2010/11/13/1876215.html CUDA在Windows下的软件开发环境搭建 本文我们以Visual ...
- CUDA初探—环境配置
在开始学习之前,首先要做的就是找到一本好的教材,要知道一本好的教材可以让我们更加轻松地入门.在看了一些个CUDA编程相关的教材之后,我向大家推荐的一本教材叫做<GPU高性能编程CUDA实战> ...
- 深入浅出说CUDA程序设计(一)
第一章 为什么需要并行程序 CUDA,全称是Compute Unified Device Architecture,一般翻译成中文为计算统一设备架构.笔者以为这样的名字会让人对CUDA感到很迷惑,CU ...
- 深入浅出说CUDA程序设计(二)
1.1 并行算法的目标 计算需求是永无止境的,可以说高性能计算是计算机科学研究中的"日不落"课题.并行计算是其中最有效的手段.作为软件编程人员,设计编写并行算法是最为核心的工作任务 ...
- 摩尔的预言 唯有CUDA才是终极的CPU
作者:小熊在线-宁道奇 . 标题:一二三四五六七八九十一二三四五六七八九十 标题:摩尔的预言 唯有CUDA才是终极的CPU 作者:小熊在线-宁道奇 关键词:Intel AMD CPU GPU CUD ...
- OpenCV4.4 CUDA编译与加速全解析
点击上方"小白学视觉",选择加"星标"或"置顶" 重磅干货,第一时间送达本文转自|OpenCV学堂 OpenCV4.4 + CUDA概述 O ...
最新文章
- Linux 黑话解释:什么是定时任务
- OCIEnvCreate failed with return code -1 but error message text was not available with ODP.net
- 组织敏捷之路上的七点体会
- 爬虫实战:批量爬取京东内衣图片(自动爬取多页,非一页)
- 数组中两数相加等于特定值,以字符串的形式输出两数角标
- 2018Alibaba数学竞赛-决赛试题
- perl6正则 4: before / after 代码断言: ?{} / !{}
- 使用C语言--编写人机猜数游戏
- mysql servlet登录验证_使用Servlet和jdbc创建用户登录验证
- 2020年30种最佳的免费网页爬虫软件
- 临沂大学 计算机学院,2018临沂大学首届计算机文化节组织动员大会
- 运维常说的 5个9、4个9、3个9 的可靠性,到底是什么鬼?
- EOS的侧链技术亮点是什么?
- switch商店显示服务器维护,国服switch eshop商城常见问题汇总 购买数字版问题答疑...
- 寄存器与移位寄存器(数字电路)
- wr703n 官方固件140120版本刷openwrt
- ag-grid-angular
- [附源码]java毕业设计校园二手交易平台的设计
- android 64位进程,简单科普一下,安卓下的64位和32位
- R+VIC模型融合实践技术应用及未来气候变化模型预测