Cris 玩转大数据系列之日志收集神器 Flume
Cris 玩转大数据系列之日志收集神器 Flume
Author:Cris
文章目录
- Cris 玩转大数据系列之日志收集神器 Flume
- Author:Cris
- 1. Flume 概述
- 1.1 什么是 Flume?
- 1.2 Flume 的优点
- 1.3 Flume 组成架构
- ① Agent
- ② Source
- ③ Channel
- ④ Sink
- ⑤ Event
- 1.4 Flume 常见四种拓扑结构
- 1.5 Flume Agent 内部原理解析
- 2. Flume 快速上手
- 2.1 Flume 官方文档
- 2.2 安装部署
- 2.3 配置 Flume 的环境变量(推荐)
- 3. Flume 实战(重点)
- 3.1 监控端口数据官方案例
- ① 案例需求
- ② 需求分析
- ③ 实现步骤
- 3.2 实时读取本地文件到HDFS案例
- ① 案例需求
- ② 案例分析图
- ③ 实现步骤
- ④ 执行监控
- ⑤ 开启hadoop和hive并操作hive产生日志
- 3.3 实时读取目录文件到HDFS案例(重点)
- ① 案例需求
- ② 需求分析
- ③ 实现步骤
- ④ 开启监控测试
- 3.4 单数据源多出口案例(一)
- ① 架构图示
- ② 案例需求
- ③ 需求分析
- ④ 实现步骤
- ⑤ 启动测试
- 3.5 单数据源多出口案例(二)
- ① 架构图
- ② 需求
- ③ 需求分析
- ④ 实现步骤
- ⑤ 启动测试
- 3.6 多数据源汇总案例(重点)
- ① 架构图
- ② 案例需求
- ③ 案例分析
- ④ 实现步骤
- ⑤ 启动测试
- 4. Flume 监控之 Ganglia
- 4.1 Ganglia 介绍,安装与部署
- 4.2 操作 Flume 测试监控
- 4.3 Ganglia 图表参数说明
- 5. 自定义 Source 组件(深度)
- 5.1 定义 Source 组件的目的
- 5.2 自定义 Source 组件的图示
- 5.3 自定义MySQLSource步骤
- ① 创建 Maven 工程
- ② 自定义 Source 以及辅助类
- ③ 打包运行
- ④ 创建 MySQL 对应表
- ⑤ 测试(并使用 IDEA 远程 Debug)
- 5.4 总结
- 6. 简单的正则
1. Flume 概述
1.1 什么是 Flume?
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume基于流式架构,灵活简单
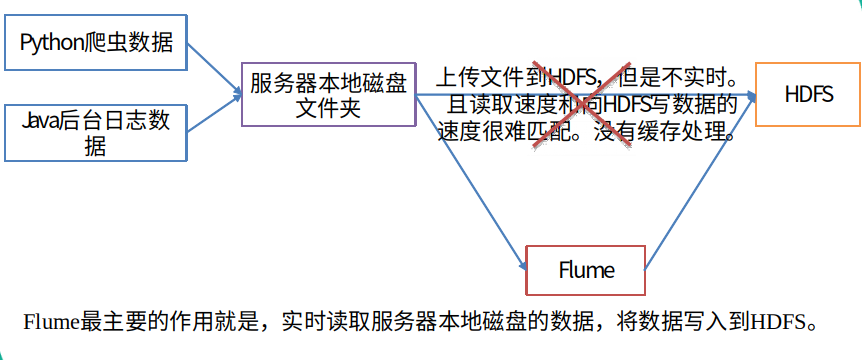
1.2 Flume 的优点
可以和任意集中式存储进程集成(例如
HDFS或者HBase)。输入的的数据速率大于写入目的存储的速率,
Flume会进行缓冲,减小HDFS的压力。flume中的事务基于
channel,使用了两个事务模型(sender + receiver),确保消息被可靠发送。
Flume使用两个独立的事务分别负责从soucrce到channel,以及从channel到sink的事件传递。一旦事务中所有的数据全部成功提交到channel,那么source才认为该数据读取完成。同理,只有成功被sink写出去的数据,才会从channel中移除
1.3 Flume 组成架构
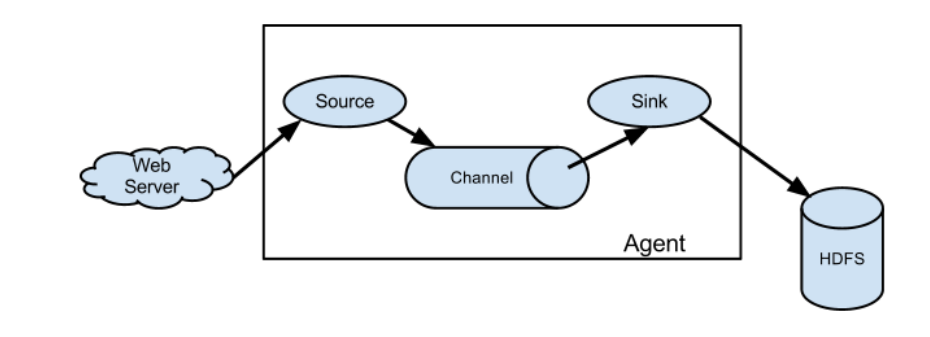
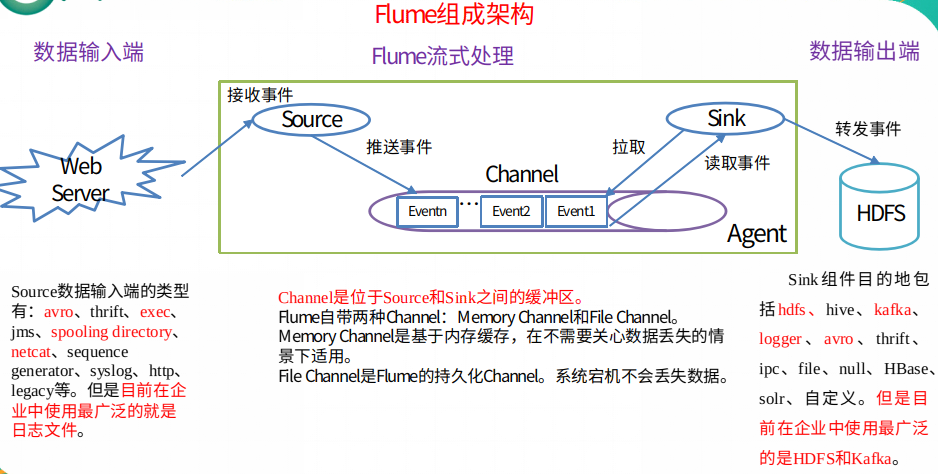
① Agent
Agent 是一个 JVM 进程,它以事件的形式将数据从源头送至目的,是 Flume 数据传输的基本单元
Agent 主要有3个部分组成,Source、Channel、Sink
② Source
Source 是负责接收数据,并将数据封装成 event,并将 events 批量的放到一个或多个Channel。Source 组件可以处理各种类型、各种格式的日志数据,包括 avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy
③ Channel
Channel 是位于 Source 和 Sink 之间的缓冲区。因此,Channel 允许 Source 和 Sink 运作在不同的速率上。Channel 是线程安全的,可以同时处理几个 Source 的写入操作和几个 Sink 的读取操作。
Flume 自带两种 Channel:Memory Channel 和 File Channel。
Memory Channel 是内存中的队列。Memory Channel 在不需要关心数据丢失的情景下适用。如果需要关心数据丢失,那么 Memory Channel 就不应该使用,因为程序死亡、机器宕机或者重启都会导致数据丢失。
File Channel 将所有事件写到磁盘。因此在程序关闭或机器宕机的情况下不会丢失数据。
④ Sink
Sink不断地轮询 Channel 中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个 Flume Agent。
Sink 是完全事务性的。在从 Channel 批量删除数据之前,每个 Sink 用 Channel 启动一个事务。批量事件一旦成功写出到存储系统或下一个 Flume Agent,Sink 就利用 Channel 提交事务。事务一旦被提交,该 Channel 从自己的内部缓冲区删除事件。
Sink 组件目的地包括hdfs、logger、avro、thrift、ipc、file、null、HBase、solr、自定义。
⑤ Event
传输单元,Flume 数据传输的基本单元,以事件的形式将数据从源头送至目的地。 Event 由可选的 header 和载有数据的一个 byte array 构成。Header 是容纳了 key-value 字符串对的 HashMap

1.4 Flume 常见四种拓扑结构
第一种结构
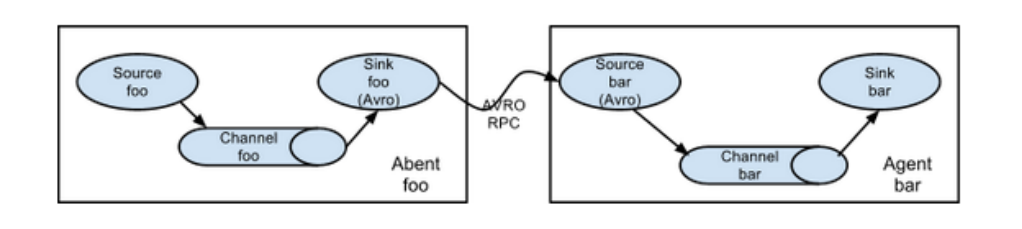
这种模式是将多个 Flume 给顺序连接起来了,从最初的 source 开始到最终 sink 传送的目的存储系统。此模式不建议桥接过多的 Flume 数量, Flume 数量过多不仅会影响传输速率,而且一旦传输过程中某个节点 Flume 宕机,会影响整个传输系统
第二种结构
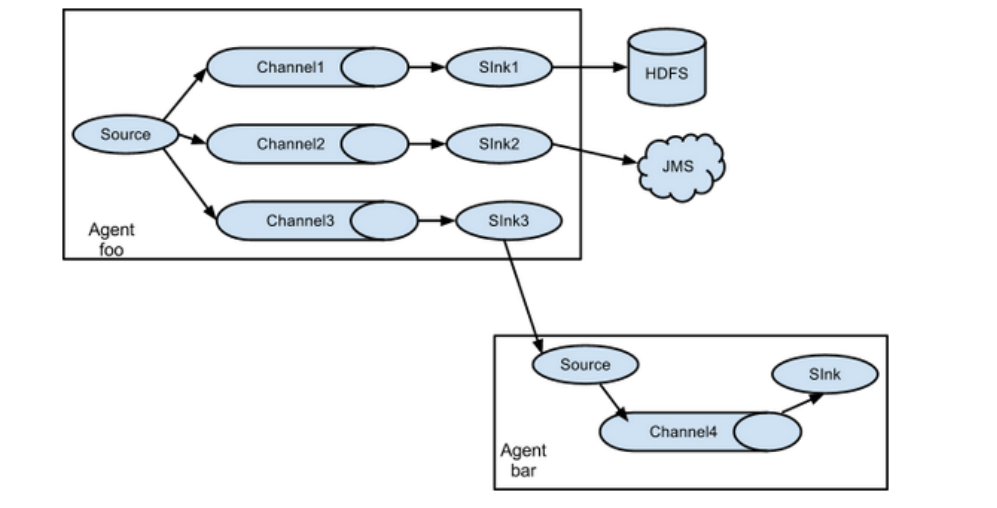
Flume 支持将事件流向一个或者多个目的地。这种模式将数据源复制到多个 channel 中,每个 channel 都有相同的数据,sink 可以选择传送的不同的目的地
第三种结构
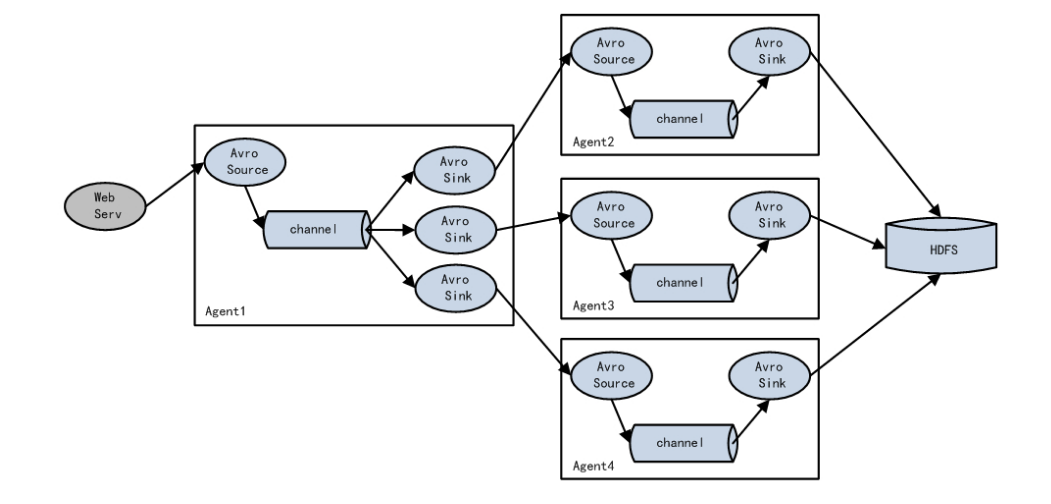
Flume 支持使用将多个 sink 逻辑上分到一个 sink 组,Flume 将数据发送到不同的 sink,主要解决负载均衡和故障转移问题
第四种结构
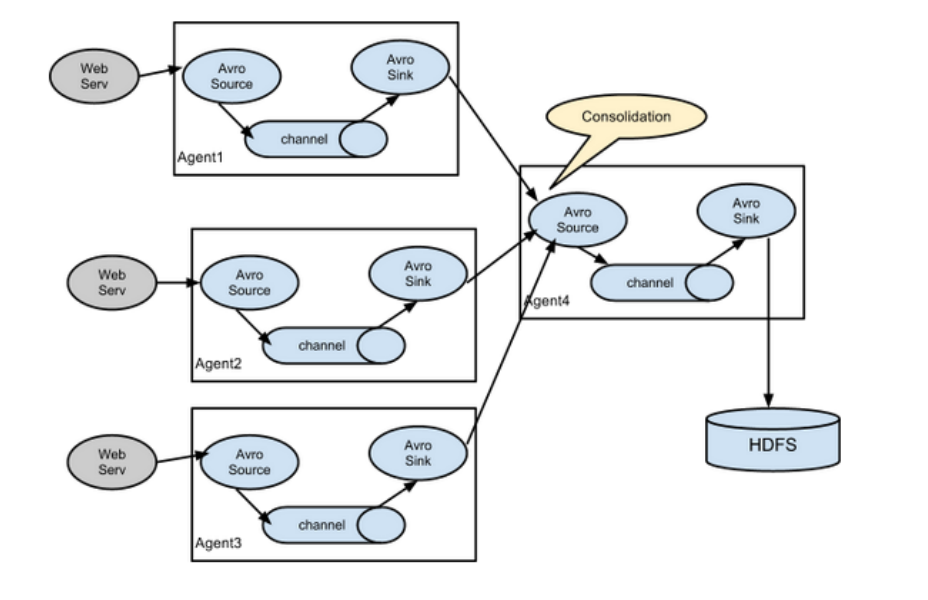
这种模式是我们最常见的,也非常实用,日常 web 应用通常分布在上百个服务器,大者甚至上千个、上万个服务器。产生的日志,处理起来也非常麻烦。用 flume 的这种组合方式能很好的解决这一问题,每台服务器部署一个 flume 采集日志,传送到一个集中收集日志的 flume,再由此 Flume 上传到 HDFS、Hive、HBase、jms 等,进行日志分析
1.5 Flume Agent 内部原理解析
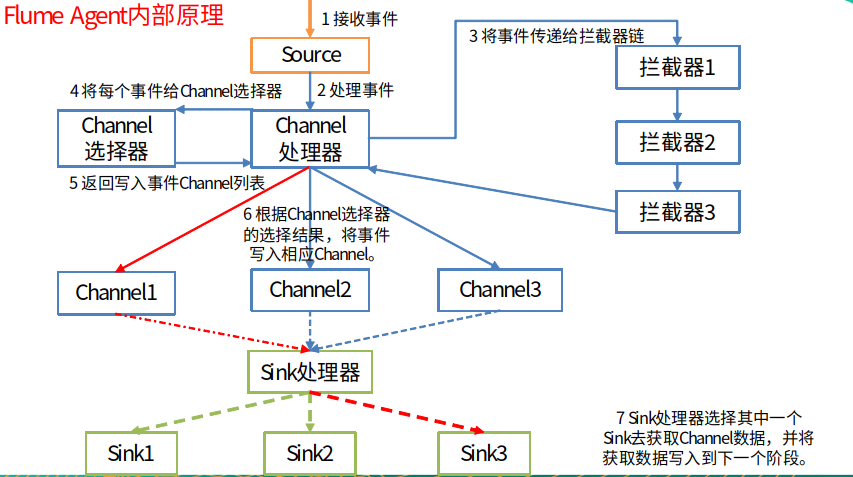
2. Flume 快速上手
2.1 Flume 官方文档
Flume官网地址
http://flume.apache.org/
文档查看地址
http://flume.apache.org/FlumeUserGuide.html
下载地址
http://archive.apache.org/dist/flume/
2.2 安装部署
将
apache-flume-1.7.0-bin.tar.gz上传到linux的/opt/software目录下解压
apache-flume-1.7.0-bin.tar.gz到/opt/module/目录下修改
apache-flume-1.7.0-bin 的名称为flume将
flume/conf下的flume-env.sh.template文件备份后改名为flume-env.sh,并配置flume-env.sh文件vim flume-env.sh# 添加一句代码即可 export JAVA_HOME=/opt/module/jdk1.8.0_172验证安装

2.3 配置 Flume 的环境变量(推荐)
直接在 /etc/profile 目录下配置 FLUME_HOME 即可,这里不再赘述~
3. Flume 实战(重点)
3.1 监控端口数据官方案例
① 案例需求
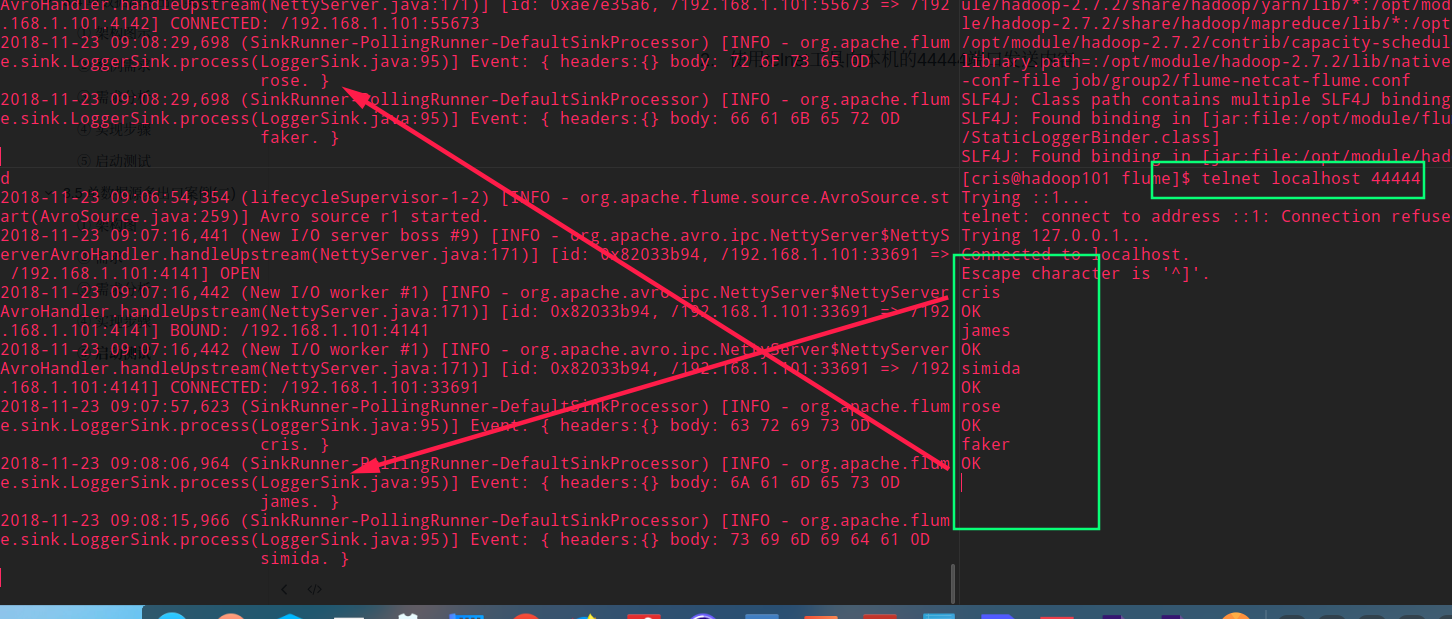
首先,Flume 监控本机 44444 端口,然后通过 telnet 工具向本机 44444 端口发送消息,最后 Flume 将监听的数据实时显示在控制台
② 需求分析

③ 实现步骤
安装
telnet工具
执行安装命令
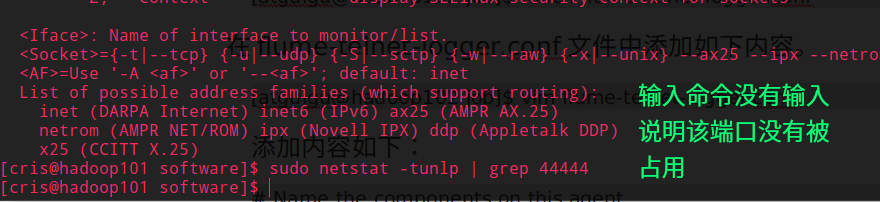
$ sudo rpm -ivh xinetd-2.3.14-40.el6.x86_64.rpm $ sudo rpm -ivh telnet-0.17-48.el6.x86_64.rpm $ sudo rpm -ivh telnet-server-0.17-48.el6.x86_64.rpm判断
44444端口是否被占用$ sudo netstat -tunlp | grep 44444功能描述:
netstat命令是一个监控TCP/IP网络的非常有用的工具,它可以显示路由表、实际的网络连接以及每一个网络接口设备的状态信息基本语法:netstat [选项]
选项参数:
-t或–tcp:显示TCP传输协议的连线状况;
-u或–udp:显示UDP传输协议的连线状况;
-n或–numeric:直接使用ip地址,而不通过域名服务器;
-l或–listening:显示监控中的服务器的Socket;
-p或–programs:显示正在使用Socket的程序识别码和程序名称;
创建
Flume Agent配置文件flume-telnet-logger.conf在
Flume目录下创建job文件夹并进入job文件夹在
job文件夹下创建Flume Agent配置文件flume-telnet-logger.conf在
flume-telnet-logger.conf文件中添加如下内容# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1# Describe/configure the source #使用nc打开并监听本机的44444的端口号,并将数据传给channel a1.sources.r1.type = netcat #bing本机及端口号 a1.sources.r1.bind = localhost a1.sources.r1.port = 44444# Describe the sink # 将channel传来的数据通过日志打印到控制台 a1.sinks.k1.type = logger# Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100# Bind the source and sink to the channel # 将设置的sink和source与channel进行绑定 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1注:配置文件来源于官方手册http://flume.apache.org/FlumeUserGuide.html
配置文件详解

首先开启
Flume监听端口
flume-ng agent -c /opt/module/flume/conf/ -n a1 -f /opt/module/flume/job/flume-telnet-logger.conf -Dflume.root.logger=INFO,console参数说明:
--conf :表示配置文件存储在conf/目录
--name :表示给agent起名为a1
--conf-file :flume本次启动读取的配置文件是在job文件夹下的flume-telnet.conf文件。
-Dflume.root.logger==INFO,console :-D表示flume运行时动态修改flume.root.logger参数属性值(默认flume.root.logger=INFO,LOGFILE,打印到日志文件,可查看flume配置文件log4j.properties),并将控制台日志打印级别设置为INFO级别。日志级别包括:log、info、warn、error
使用
telnet工具向本机的44444端口发送内容telnet localhost 44444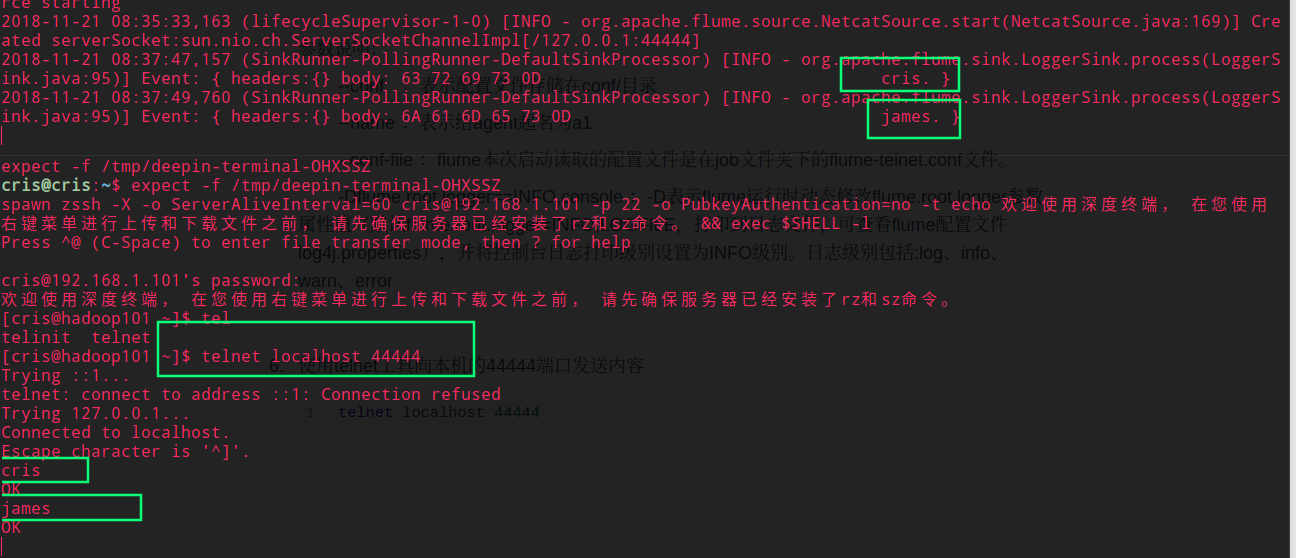
注意:如果此时使用 telent hadoop101 44444 的命令 Flume 是无法接受到消息的,因为之前的 Flume 配置文件配置的是 localhost,就只能以 localhost 开启端口
3.2 实时读取本地文件到HDFS案例
① 案例需求
实时监控Hive日志,并上传到HDFS中
② 案例分析图
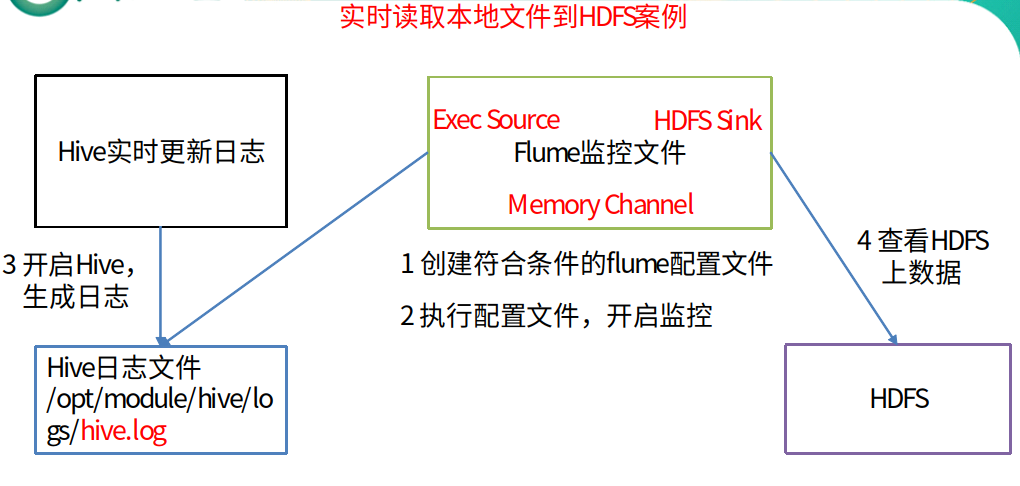
③ 实现步骤
Flume 要想将数据输出到 HDFS,必须持有 Hadoop 相关 jar 包;或者当前节点已经安装了 Hadoop 并在 /etc/profile 配置了 Hadoop 环境变量(这里 Cris 小哥哥的虚拟机集群已经配置好了)
创建
Flume Agent配置文件flume-file-hdfs.conf注:要想读取Linux系统中的文件,就得按照Linux命令的规则执行命令。由于hive日志在Linux系统中所以读取文件的类型选择:exec即execute执行的意思。表示执行Linux命令来读取文件

# Name the components on this agent a2.sources = r2 a2.sinks = k2 a2.channels = c2# Describe/configure the source a2.sources.r2.type = exec a2.sources.r2.command = tail -F /opt/module/hive-1.2.1/logs/hive.log#指定shell解释器,-c即为"command string" a2.sources.r2.shell = /bin/bash -c# Describe the sink a2.sinks.k2.type = hdfs a2.sinks.k2.hdfs.path = hdfs://hadoop101:9000/flume/%Y%m%d/%H#上传文件的前缀 a2.sinks.k2.hdfs.filePrefix = logs-#是否按照时间滚动文件夹 a2.sinks.k2.hdfs.round = true#多少时间单位创建一个新的文件夹 a2.sinks.k2.hdfs.roundValue = 1#重新定义时间单位 a2.sinks.k2.hdfs.roundUnit = hour#是否使用本地时间戳 a2.sinks.k2.hdfs.useLocalTimeStamp = true#积攒多少个Event才flush到HDFS一次 a2.sinks.k2.hdfs.batchSize = 1000#设置文件类型,可支持压缩 a2.sinks.k2.hdfs.fileType = DataStream#多久生成一个新的文件 a2.sinks.k2.hdfs.rollInterval = 600#设置每个文件的滚动大小 a2.sinks.k2.hdfs.rollSize = 134217700#文件的滚动与Event数量无关 a2.sinks.k2.hdfs.rollCount = 0#最小冗余数 a2.sinks.k2.hdfs.minBlockReplicas = 1# Use a channel which buffers events in memory a2.channels.c2.type = memory a2.channels.c2.capacity = 1000 a2.channels.c2.transactionCapacity = 100# Bind the source and sink to the channel a2.sources.r2.channels = c2 a2.sinks.k2.channel = c2
对于所有与时间相关的转义序列,Event Header中必须存在以 “timestamp”的key(除非hdfs.useLocalTimeStamp设置为true,此方法会使用TimestampInterceptor自动添加timestamp)
配置详解:

更加详细的配置介绍,请参考这篇文章
如果还不满足,就请参考官网文档
④ 执行监控
flume-ng agent -c conf/ -n a2 -f job/flume-file-hdfs.conf
如下图:

⑤ 开启hadoop和hive并操作hive产生日志
startall
这里使用 Cris 写的群起脚本,启动 101,102,103 节点的所有 Hadoop 集群和 YARN 集群
然后直接输入 hive 命令,此时 hive 会往 /opt/module/hive-1.2.1/logs/hive.log 写日志,由于 Flume 的监控,可以发现 HDFS 上已经生成了对应的文件
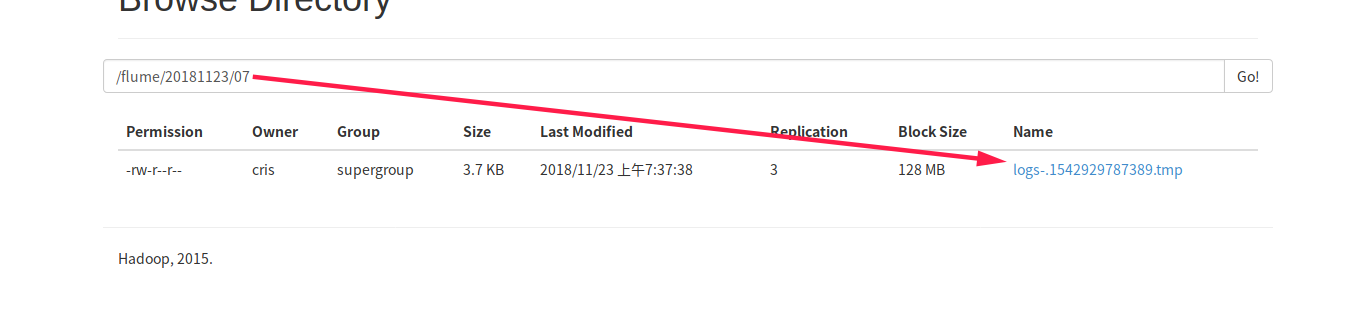
然后静静的等待十分钟,发现临时文件已经生产永久文件了

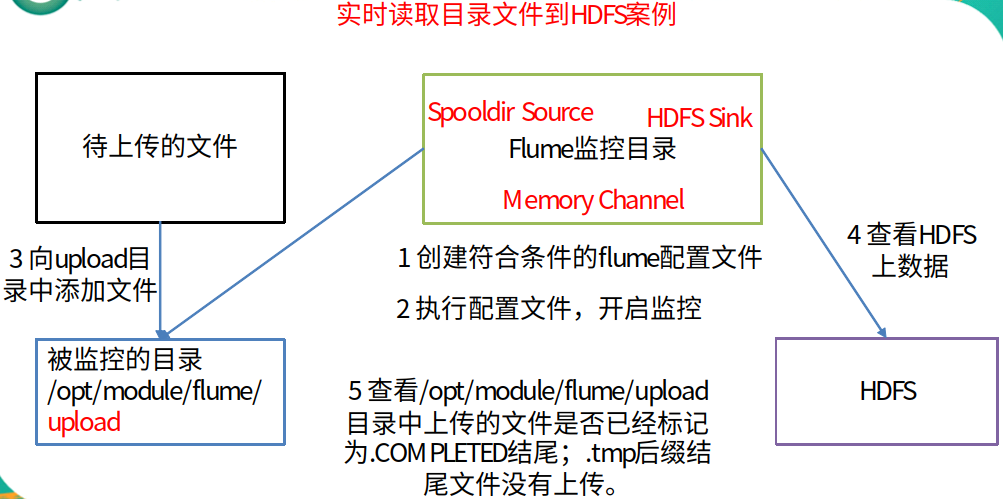
3.3 实时读取目录文件到HDFS案例(重点)
① 案例需求
使用flume监听整个目录的文件
② 需求分析
③ 实现步骤
创建配置文件 flume-dir-hdfs.conf
具体添加内容如下:
a3.sources = r3 a3.sinks = k3 a3.channels = c3# Describe/configure the source a3.sources.r3.type = spooldir a3.sources.r3.spoolDir = /opt/module/flume/upload #将文件传给channel后,将文件名修改为.COMPLETED结尾 a3.sources.r3.fileSuffix = .COMPLETED #是否在event的Header中添加文件的绝对路径 a3.sources.r3.fileHeader = true #忽略所有以.tmp结尾的文件,不上传 a3.sources.r3.ignorePattern = ([^ ]*\.tmp)# Describe the sink a3.sinks.k3.type = hdfs a3.sinks.k3.hdfs.path = hdfs://hadoop101:9000/flume/upload/%Y%m%d/%H #上传文件的前缀 a3.sinks.k3.hdfs.filePrefix = upload- #是否按照时间滚动文件夹 a3.sinks.k3.hdfs.round = true #多少时间单位创建一个新的文件夹 a3.sinks.k3.hdfs.roundValue = 1 #重新定义时间单位 a3.sinks.k3.hdfs.roundUnit = hour #是否使用本地时间戳 a3.sinks.k3.hdfs.useLocalTimeStamp = true #积攒多少个Event才flush到HDFS一次 a3.sinks.k3.hdfs.batchSize = 100 #设置文件类型,可支持压缩 a3.sinks.k3.hdfs.fileType = DataStream #多久生成一个新的文件(秒) a3.sinks.k3.hdfs.rollInterval = 600 #设置每个文件的滚动大小大概是128M a3.sinks.k3.hdfs.rollSize = 134217700 #文件的滚动与Event数量无关 a3.sinks.k3.hdfs.rollCount = 0 #最小冗余数 a3.sinks.k3.hdfs.minBlockReplicas = 1# Use a channel which buffers events in memory a3.channels.c3.type = memory a3.channels.c3.capacity = 1000 a3.channels.c3.transactionCapacity = 100# Bind the source and sink to the channel a3.sources.r3.channels = c3 a3.sinks.k3.channel = c3
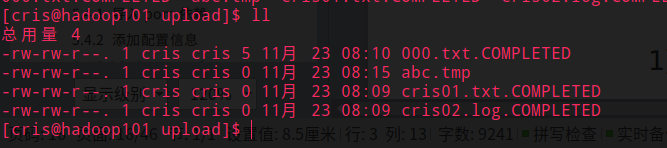
说明: 在使用Spooling Directory Source时
不要在监控目录中创建并持续修改文件
上传完成的文件会以.COMPLETED结尾
被监控文件夹每500毫秒扫描一次文件变动
④ 开启监控测试
[cris@hadoop101 flume]$ flume-ng agent -c conf/ -n a3 -f job/flume-dir-hdfs.conf

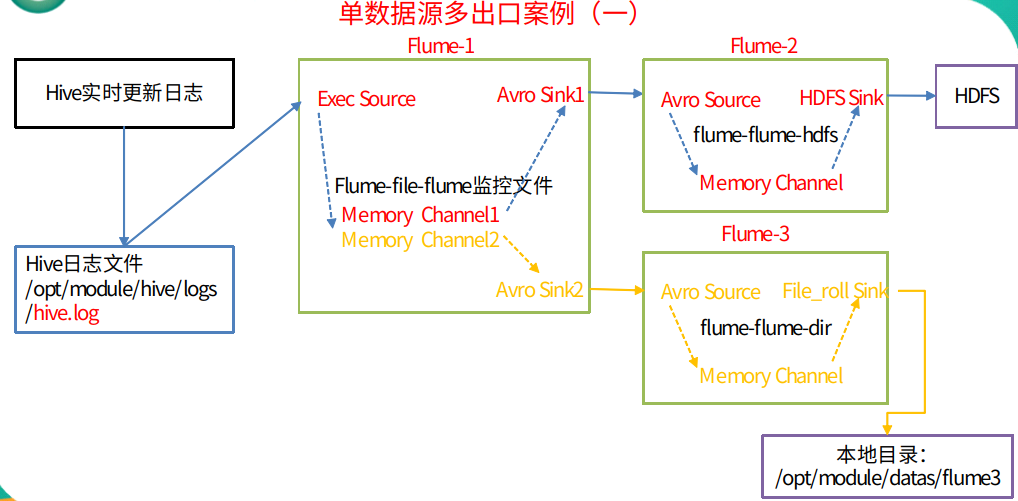
3.4 单数据源多出口案例(一)
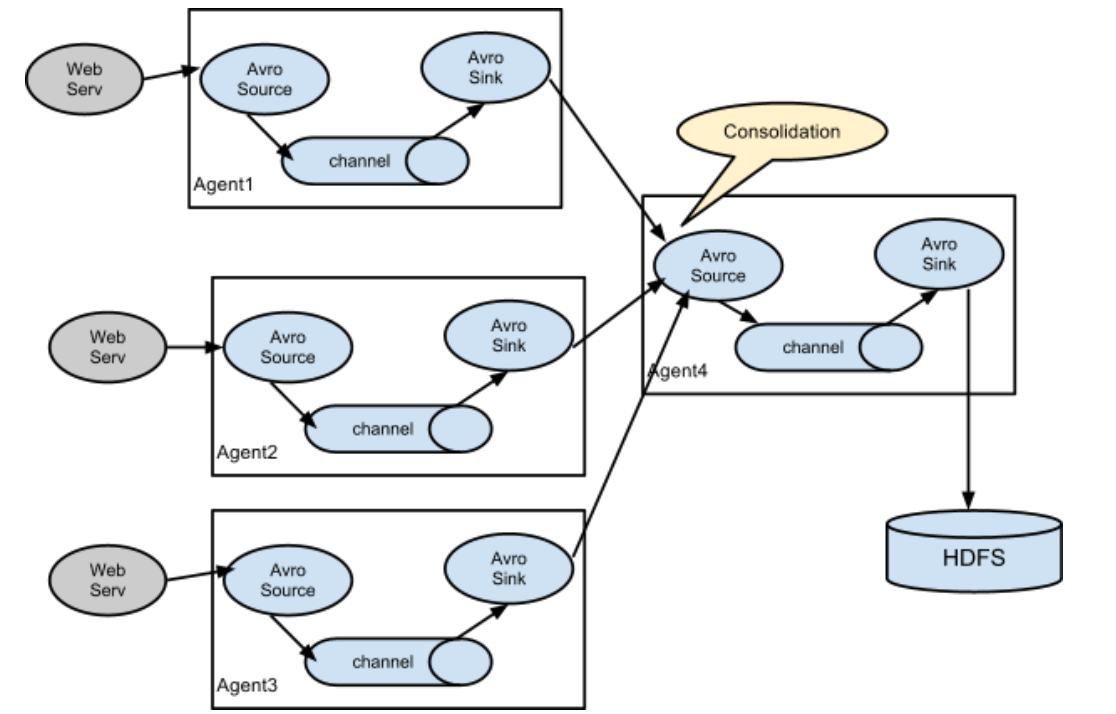
① 架构图示
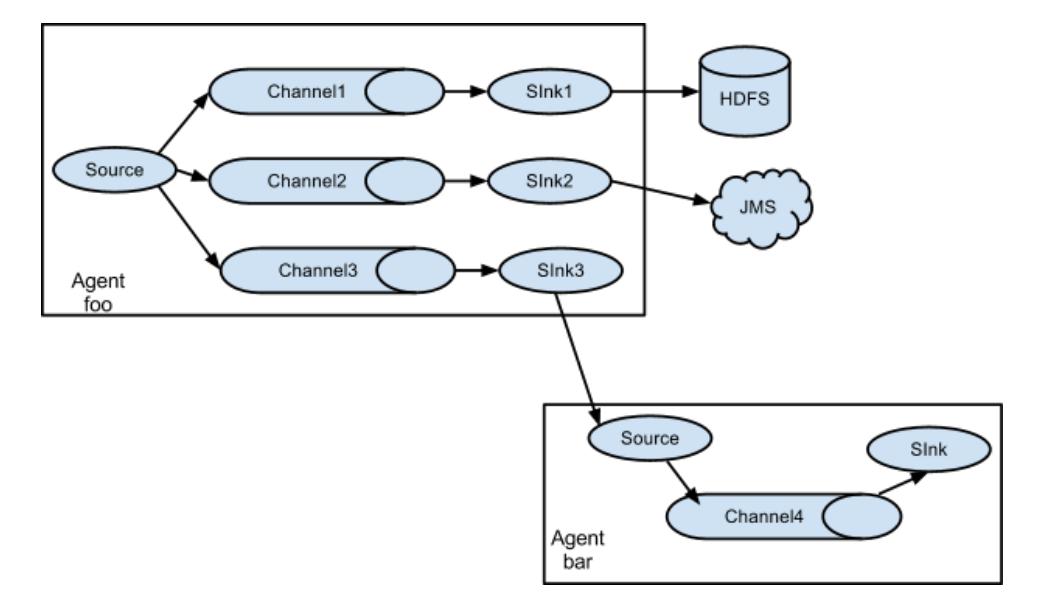
② 案例需求
使用flume-1监控文件变动,flume-1将变动内容传递给flume-2,flume-2负责存储到HDFS。同时flume-1将变动内容传递给flume-3,flume-3负责输出到local filesystem
③ 需求分析
④ 实现步骤
在/opt/module/flume/job目录下创建group1文件夹
在/opt/module/datas/目录下创建flume3文件夹
创建flume-file-flume.conf
配置1个接收日志文件的source和两个channel、两个sink,分别输送给flume-flume-hdfs和flume-flume-dir
在配置文件中输入以下内容:
# Name the components on this agent a1.sources = r1 a1.sinks = k1 k2 a1.channels = c1 c2 # 将数据流复制给多个channel a1.sources.r1.selector.type = replicating# Describe/configure the source a1.sources.r1.type = exec a1.sources.r1.command = tail -F /opt/module/hive-1.2.1/logs/hive.log a1.sources.r1.shell = /bin/bash -c# Describe the sink #sink端的avro是一个数据发送者 a1.sinks.k1.type = avro a1.sinks.k1.hostname = hadoop101 a1.sinks.k1.port = 4141a1.sinks.k2.type = avro a1.sinks.k2.hostname = hadoop101 a1.sinks.k2.port = 4142# Describe the channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100a1.channels.c2.type = memory a1.channels.c2.capacity = 1000 a1.channels.c2.transactionCapacity = 100# Bind the source and sink to the channel a1.sources.r1.channels = c1 c2 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c2注:Avro是由Hadoop创始人Doug Cutting创建的一种语言无关的数据序列化和RPC框架
创建flume-flume-hdfs.conf
配置上级flume输出的source,输出是到hdfs的sink
在配置文件输入:
# Name the components on this agent a2.sources = r1 a2.sinks = k1 a2.channels = c1# Describe/configure the source ##source端的avro是一个数据接收服务 a2.sources.r1.type = avro a2.sources.r1.bind = hadoop101 a2.sources.r1.port = 4141# Describe the sink a2.sinks.k1.type = hdfs a2.sinks.k1.hdfs.path = hdfs://hadoop101:9000/flume2/%Y%m%d/%H #上传文件的前缀 a2.sinks.k1.hdfs.filePrefix = flume2- #是否按照时间滚动文件夹 a2.sinks.k1.hdfs.round = true #多少时间单位创建一个新的文件夹 a2.sinks.k1.hdfs.roundValue = 1 #重新定义时间单位 a2.sinks.k1.hdfs.roundUnit = hour #是否使用本地时间戳 a2.sinks.k1.hdfs.useLocalTimeStamp = true #积攒多少个Event才flush到HDFS一次 a2.sinks.k1.hdfs.batchSize = 100 #设置文件类型,可支持压缩 a2.sinks.k1.hdfs.fileType = DataStream #多久生成一个新的文件 a2.sinks.k1.hdfs.rollInterval = 600 #设置每个文件的滚动大小大概是128M a2.sinks.k1.hdfs.rollSize = 134217700 #文件的滚动与Event数量无关 a2.sinks.k1.hdfs.rollCount = 0 #最小冗余数 a2.sinks.k1.hdfs.minBlockReplicas = 1# Describe the channel a2.channels.c1.type = memory a2.channels.c1.capacity = 1000 a2.channels.c1.transactionCapacity = 100# Bind the source and sink to the channel a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1创建flume-flume-dir.conf
配置上级flume输出的source,输出是到本地目录的sink
往配置文件输入以下内容:
# Name the components on this agent a3.sources = r1 a3.sinks = k1 a3.channels = c2# Describe/configure the source a3.sources.r1.type = avro a3.sources.r1.bind = hadoop101 a3.sources.r1.port = 4142# Describe the sink # 本地文件系统滚动存储日志 a3.sinks.k1.type = file_roll # 将数据存放的目录 a3.sinks.k1.sink.directory = /opt/module/datas/flume3# Describe the channel a3.channels.c2.type = memory a3.channels.c2.capacity = 1000 a3.channels.c2.transactionCapacity = 100# Bind the source and sink to the channel a3.sources.r1.channels = c2 a3.sinks.k1.channel = c2提示:输出的本地目录必须是已经存在的目录,如果该目录不存在,并不会创建新的目录
⑤ 启动测试
分别开启对应配置文件:flume-flume-dir,flume-flume-hdfs,flume-file-flume
注意:flume启动顺序,先起a2和a3,再启a1,a2和a3相当于server端,a1启动后要进行连接


然后开启 Hive
查看 HDFS 和本地

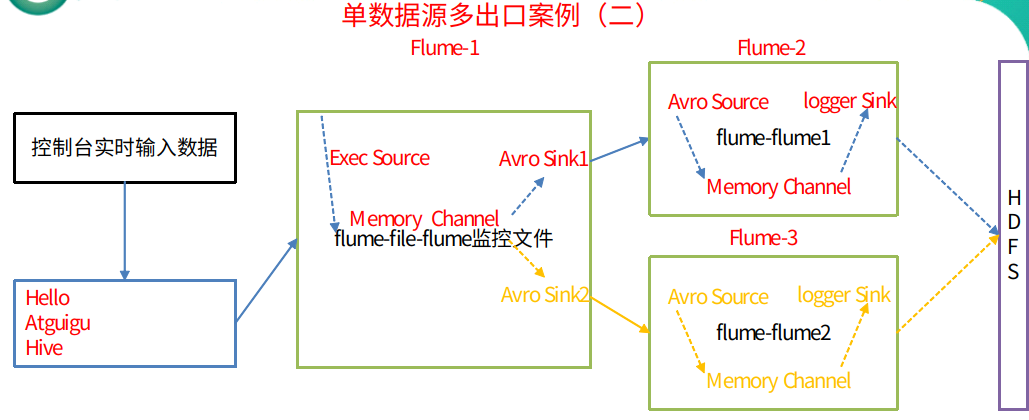
3.5 单数据源多出口案例(二)
① 架构图
② 需求
使用flume-1监控文件变动,flume-1将变动内容传递给flume-2,flume-2负责存储到HDFS。同时flume-1将变动内容传递给flume-3,flume-3也负责存储到HDFS
注意:这里简化案例,我们的 flume-2 和 flume-3 将收到的内容输入到控制台即可
③ 需求分析
④ 实现步骤
在/opt/module/flume/job目录下创建group2文件夹
创建flume-netcat-flume.conf
配置1个接收日志文件的source和1个channel、两个sink,分别输送给flume-flume1和flume-flume2
输入以下内容:
# Name the components on this agent a1.sources = r1 a1.channels = c1 a1.sinkgroups = g1 a1.sinks = k1 k2# Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444a1.sinkgroups.g1.processor.type = load_balance a1.sinkgroups.g1.processor.backoff = true a1.sinkgroups.g1.processor.selector = round_robin a1.sinkgroups.g1.processor.selector.maxTimeOut=10000# Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.hostname = hadoop101 a1.sinks.k1.port = 4141a1.sinks.k2.type = avro a1.sinks.k2.hostname = hadoop101 a1.sinks.k2.port = 4142# Describe the channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100# Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinkgroups.g1.sinks = k1 k2 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c1创建flume-flume1.conf
配置上级flume输出的source,输出是到本地控制台
添加如下内容:
# Name the components on this agent a2.sources = r1 a2.sinks = k1 a2.channels = c1# Describe/configure the source a2.sources.r1.type = avro a2.sources.r1.bind = hadoop101 a2.sources.r1.port = 4141# Describe the sink a2.sinks.k1.type = logger# Describe the channel a2.channels.c1.type = memory a2.channels.c1.capacity = 1000 a2.channels.c1.transactionCapacity = 100# Bind the source and sink to the channel a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1创建 flume-flume2.conf
配置上级flume输出的source,输出是到本地控制台
添加如下内容:
# Name the components on this agent a3.sources = r1 a3.sinks = k1 a3.channels = c2# Describe/configure the source a3.sources.r1.type = avro a3.sources.r1.bind = hadoop101 a3.sources.r1.port = 4142# Describe the sink a3.sinks.k1.type = logger# Describe the channel a3.channels.c2.type = memory a3.channels.c2.capacity = 1000 a3.channels.c2.transactionCapacity = 100# Bind the source and sink to the channel a3.sources.r1.channels = c2 a3.sinks.k1.channel = c2
⑤ 启动测试
执行配置文件
分别前后开启对应配置文件:flume-flume2,flume-flume1,flume-netcat-flume



使用telnet工具向本机的44444端口发送内容
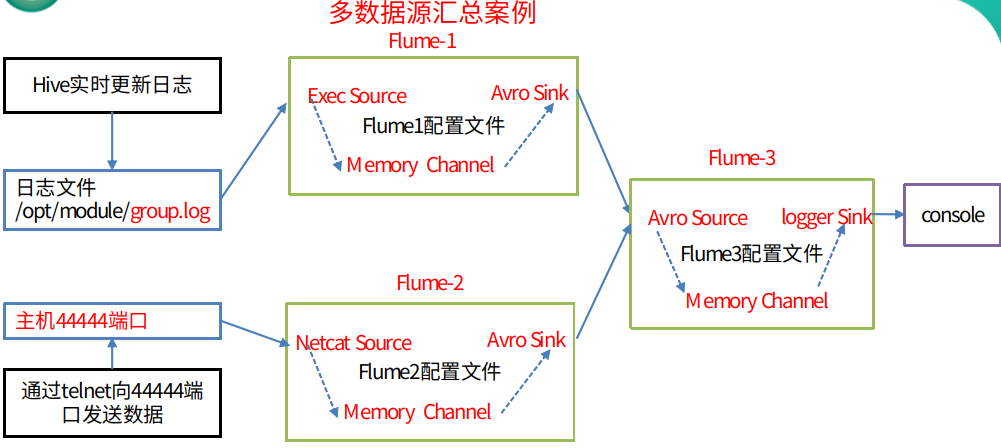
3.6 多数据源汇总案例(重点)
① 架构图
② 案例需求
hadoop102上的flume-1监控文件/opt/module/group.log,
hadoop103上的flume-2监控某一个端口的数据流,
flume-1与flume-2将数据发送给hadoop101上的flume-3,flume-3将最终数据打印到控制台
③ 案例分析
优势:
如果很多flume都直连hdfs,这样hdfs需要开启很多连接,导致hdfs的压力会很大,读写很慢,所以需要先将多个flume汇总到一个flume,再由这个flume将数据写入到hdfs
④ 实现步骤
分发flume
xsync flume/创建flume1.conf
在 hadoop102 上创建配置文件并输入
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1# Describe/configure the source a1.sources.r1.type = exec a1.sources.r1.command = tail -F /opt/module/group.log a1.sources.r1.shell = /bin/bash -c# Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.hostname = hadoop101 a1.sinks.k1.port = 4141# Describe the channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100# Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1创建flume2.conf
配置source监控端口44444数据流,配置sink数据到下一级flume
在hadoop103上创建配置文件并打开
# Name the components on this agent a2.sources = r1 a2.sinks = k1 a2.channels = c1# Describe/configure the source a2.sources.r1.type = netcat a2.sources.r1.bind = hadoop103 a2.sources.r1.port = 44444# Describe the sink a2.sinks.k1.type = avro a2.sinks.k1.hostname = hadoop101 a2.sinks.k1.port = 4141# Use a channel which buffers events in memory a2.channels.c1.type = memory a2.channels.c1.capacity = 1000 a2.channels.c1.transactionCapacity = 100# Bind the source and sink to the channel a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1创建flume3.conf
配置source用于接收flume1与flume2发送过来的数据流,最终合并后sink到控制台。
在hadoop101上创建配置文件并打开
# Name the components on this agent a3.sources = r1 a3.sinks = k1 a3.channels = c1# Describe/configure the source a3.sources.r1.type = avro a3.sources.r1.bind = hadoop101 a3.sources.r1.port = 4141# Describe the sink # Describe the sink a3.sinks.k1.type = logger# Describe the channel a3.channels.c1.type = memory a3.channels.c1.capacity = 1000 a3.channels.c1.transactionCapacity = 100# Bind the source and sink to the channel a3.sources.r1.channels = c1 a3.sinks.k1.channel = c1
⑤ 启动测试
执行配置文件
分别开启对应配置文件:flume3.conf,flume2.conf,flume1.conf
启动流程略
在hadoop102上向/opt/module目录下的group.log追加内容
echo 'hello' >> group.log在hadoop103上向44444端口发送数据
telnet hadoop104 44444检查hadoop101上数据

4. Flume 监控之 Ganglia
4.1 Ganglia 介绍,安装与部署
详细介绍请参考官网
Cris 这里一句话概况:
Ganglia is a scalable distributed monitoring system for high-performance computing systems such as clusters and Grids
Ganglia是一个可扩展的分布式监控系统,为管理高性能的计算系统,例如集群而生
安装基础环境依赖
sudo yum -y install httpd php
sudo yum -y install rrdtool perl-rrdtool rrdtool-devel
sudo yum -y install apr-devel
然后安装 Ganglia
sudo rpm -Uvh http://dl.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm
sudo yum -y install ganglia-gmetad
sudo yum -y install ganglia-web
sudo yum install -y ganglia-gmond
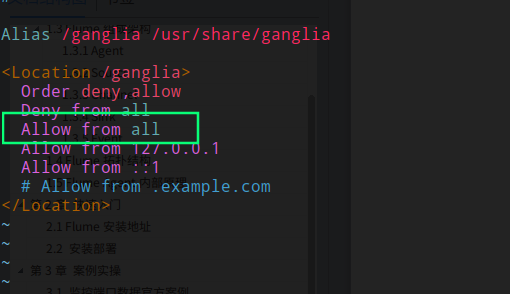
修改配置文件 ganglia.conf
sudo vim /etc/httpd/conf.d/ganglia.conf
修改配置文件gmetad.conf
sudo vim /etc/ganglia/gmetad.conf
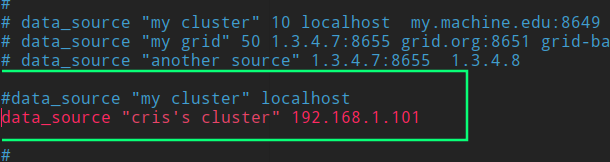
修改配置文件 gmond.conf
sudo vim /etc/ganglia/gmond.conf
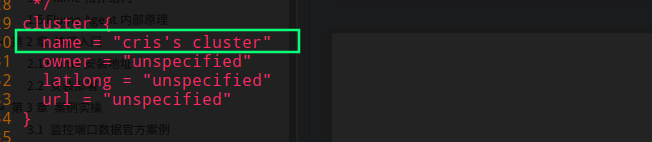
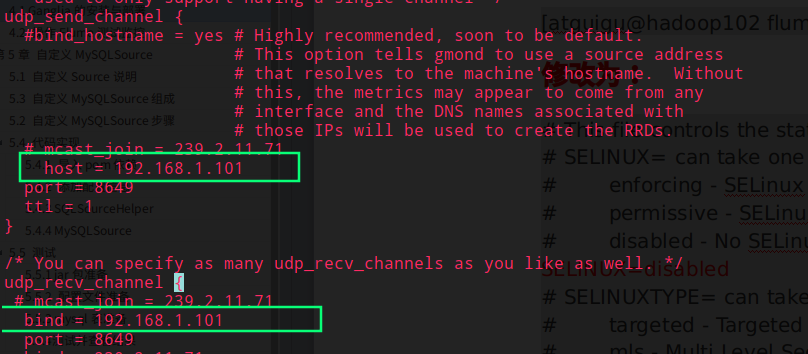
修改配置文件 config
sudo vim /etc/selinux/config
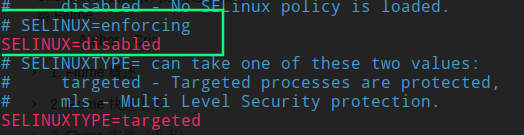
提示:selinux本次生效关闭必须重启,如果此时不想重启,可以临时生效之
sudo setenforce 0
启动ganglia
sudo service httpd start
sudo service gmetad start
sudo service gmond start
4.2 操作 Flume 测试监控
- 修改/opt/module/flume/conf目录下的flume-env.sh配置
JAVA_OPTS="-Dflume.monitoring.type=ganglia
-Dflume.monitoring.hosts=192.168.1.101:8649
-Xms100m
-Xmx200m"
- 启动flume任务
[cris@hadoop101 flume]$ flume-ng agent
--conf conf/
--name a1
--conf-file job/flume-telnet-logger.conf
-Dflume.root.logger==INFO,console
-Dflume.monitoring.type=ganglia
-Dflume.monitoring.hosts=192.168.1.101:8649
- 发送数据观察ganglia监测图
telnet localhost 44444
打开监控台
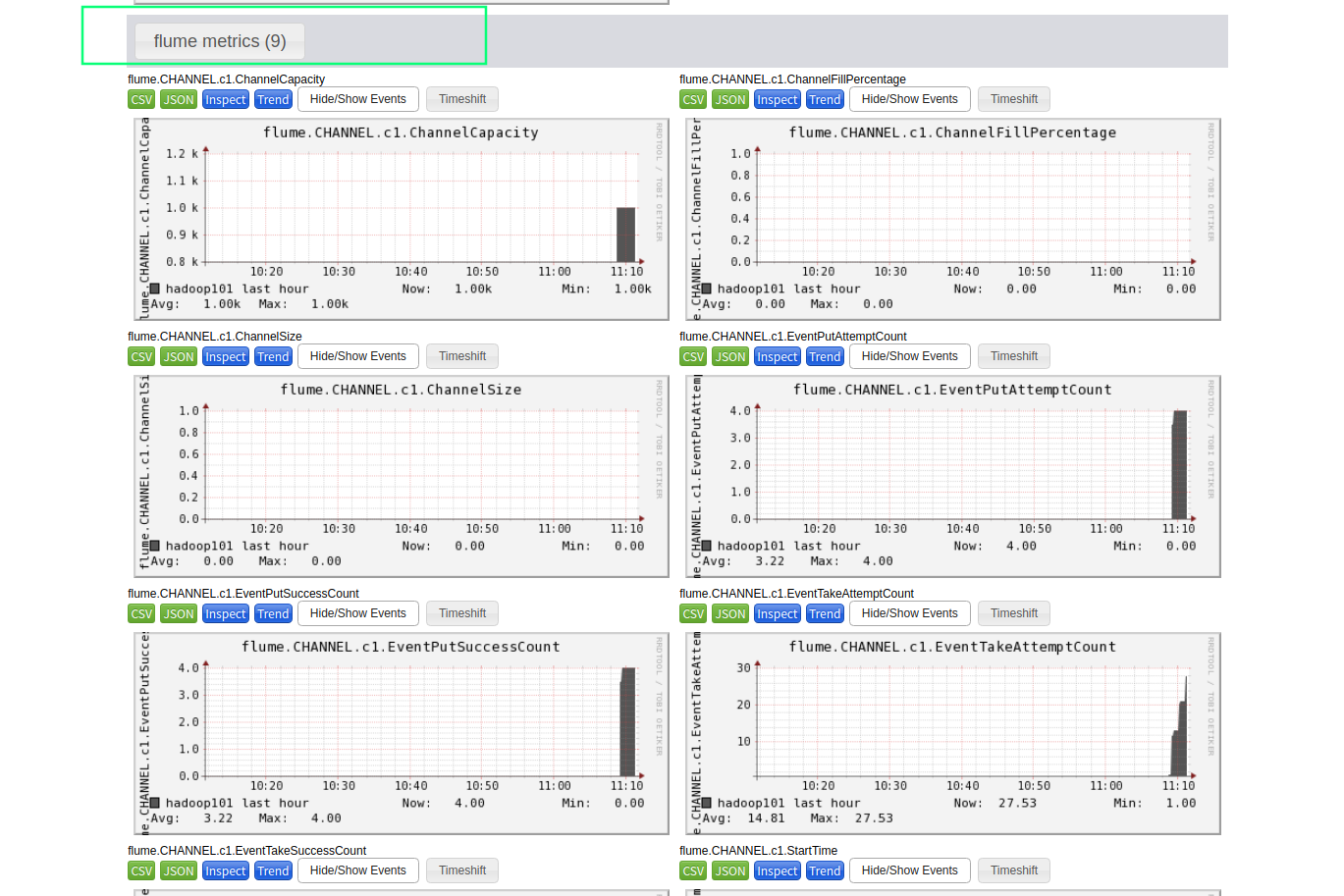
4.3 Ganglia 图表参数说明
| 字段(图表名称) | 字段含义 |
|---|---|
| EventPutAttemptCount | source尝试写入channel的事件总数量 |
| EventPutSuccessCount | 成功写入channel且提交的事件总数量 |
| EventTakeAttemptCount | sink尝试从channel拉取事件的总数量。这不意味着每次事件都被返回,因为sink拉取的时候channel可能没有任何数据。 |
| EventTakeSuccessCount | sink成功读取的事件的总数量 |
| StartTime | channel启动的时间(毫秒) |
| StopTime | channel停止的时间(毫秒) |
| ChannelSize | 目前channel中事件的总数量 |
| ChannelFillPercentage | channel占用百分比 |
| ChannelCapacity | channel的容量 |
5. 自定义 Source 组件(深度)
5.1 定义 Source 组件的目的
Source是负责接收数据到Flume Agent的组件。Source组件可以处理各种类型、各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy。官方提供的source类型已经很多,但是有时候并不能满足实际开发当中的需求,此时我们就需要根据实际需求自定义某些source
如:实时监控MySQL,从MySQL中获取数据传输到HDFS或者其他存储框架,所以此时需要我们自己实现MySQLSource。
官方也提供了自定义source的接口:
官网说明
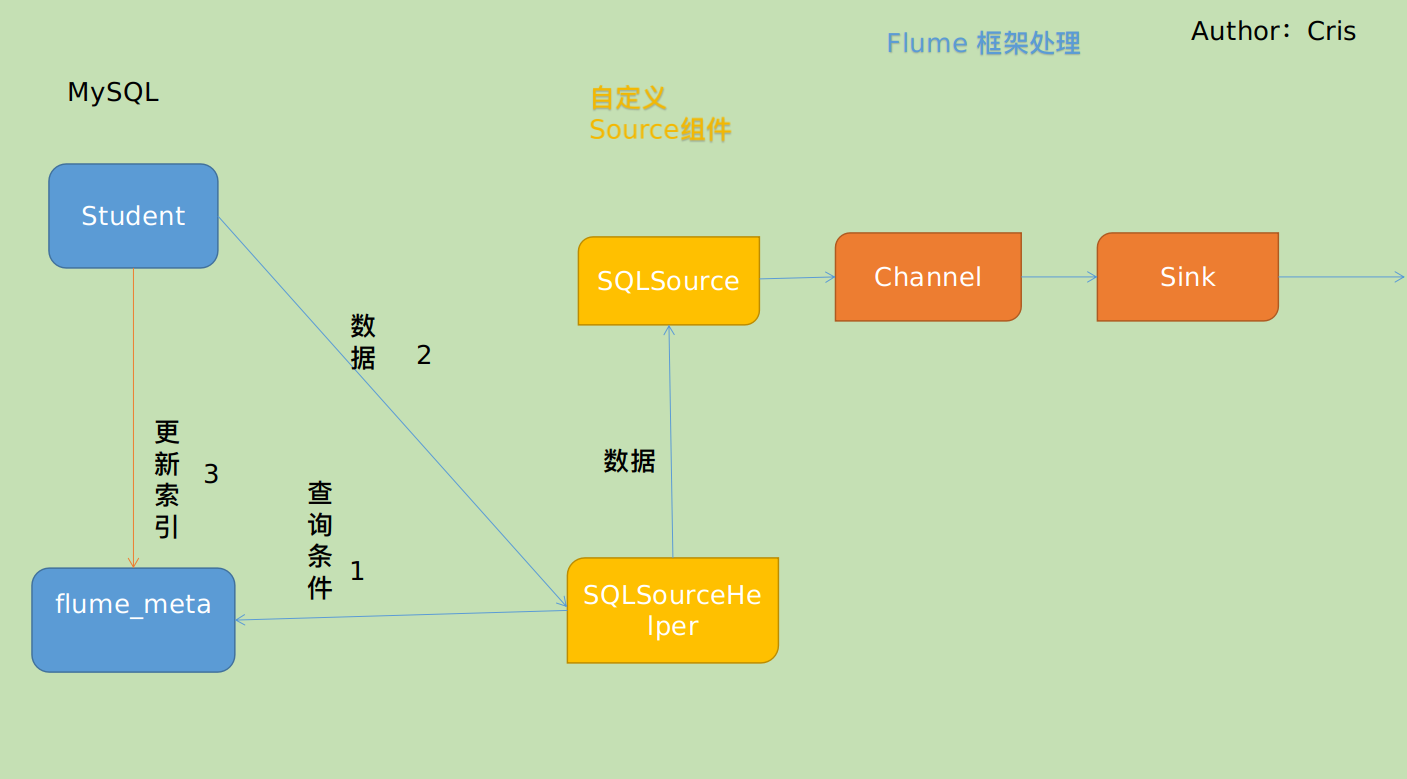
5.2 自定义 Source 组件的图示
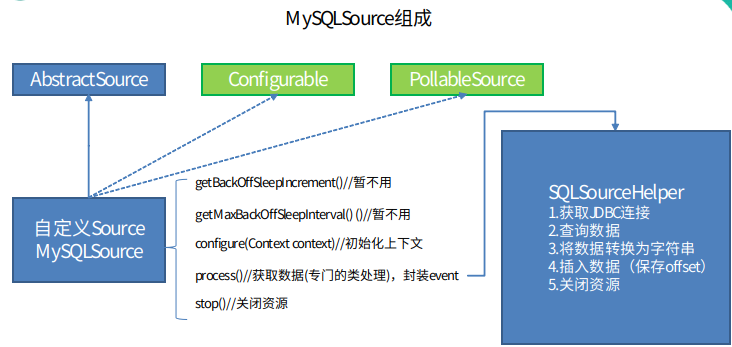
5.3 自定义MySQLSource步骤
根据官方说明自定义mysqlsource需要继承AbstractSource类并实现Configurable和PollableSource接口。
实现相应方法:
getBackOffSleepIncrement()//暂不用
getMaxBackOffSleepInterval()//暂不用
configure(Context context)//初始化context
process()//获取数据(从mysql获取数据,业务处理比较复杂,所以我们定义一个专门的类——SQLSourceHelper来处理跟mysql的交互),封装成event并写入channel,这个方法被循环调用
stop()//关闭相关的资源
PollableSource:从source中提取数据,将其发送到channel。
Configurable:实现了Configurable的任何类都含有一个context,使用context获取配置信息。
① 创建 Maven 工程
打开 IDEA ,创建 Maven 工程专门用来写我们自定义的用来监视 MySQL 的 Source,创建流程这里就不再赘述,直接上 pom.xml 以及项目视图
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.crsi</groupId><artifactId>MySQLSource</artifactId><version>1.0-SNAPSHOT</version><dependencies><dependency><groupId>org.apache.flume</groupId><artifactId>flume-ng-core</artifactId><version>1.7.0</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.27</version></dependency><!-- https://mvnrepository.com/artifact/org.projectlombok/lombok --><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.2</version><scope>provided</scope></dependency></dependencies>
</project>
然后是项目视图
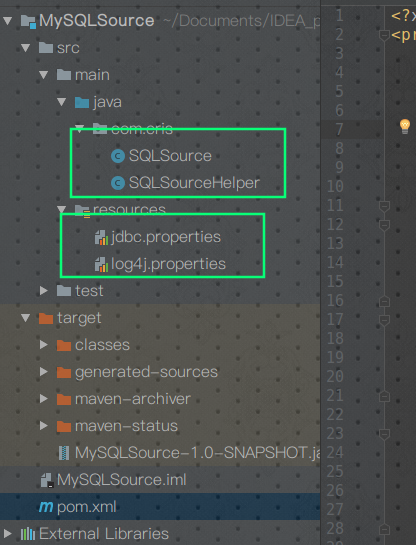
看看我们的配置文件
jdbc.properties
dbDriver=com.mysql.jdbc.Driver
dbUrl=jdbc:mysql://hadoop101:3306/mysqlsource?useUnicode=true&characterEncoding=utf-8
dbUser=root
dbPassword=123456
然后是 log4j.properties
#--------console-----------
log4j.rootLogger=info,myconsole,myfile
log4j.appender.myconsole=org.apache.log4j.ConsoleAppender
log4j.appender.myconsole.layout=org.apache.log4j.SimpleLayout
#log4j.appender.myconsole.layout.ConversionPattern =%d [%t] %-5p [%c] - %m%n#log4j.rootLogger=error,myfile
log4j.appender.myfile=org.apache.log4j.DailyRollingFileAppender
log4j.appender.myfile.File=/tmp/flume.log
log4j.appender.myfile.layout=org.apache.log4j.PatternLayout
log4j.appender.myfile.layout.ConversionPattern =%d [%t] %-5p [%c] - %m%n
② 自定义 Source 以及辅助类
先看看自定义的 Source 类
package com.cris;import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.PollableSource;
import org.apache.flume.conf.Configurable;
import org.apache.flume.event.SimpleEvent;
import org.apache.flume.source.AbstractSource;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;/*** TODO** @author cris* @version 1.0**/
public class SQLSource extends AbstractSource implements Configurable, PollableSource {/*** 打印日志**/private static final Logger LOG = LoggerFactory.getLogger(SQLSource.class);/*** 定义sqlHelper**/private SQLSourceHelper sqlSourceHelper;@Overridepublic long getBackOffSleepIncrement() {return 0;}@Overridepublic long getMaxBackOffSleepInterval() {return 0;}@Overridepublic void configure(Context context) {//初始化sqlSourceHelper = new SQLSourceHelper(context);}/*** Source 的核心逻辑,将数据从 mysql 数据库放入到 channel 中** @return*/@Overridepublic Status process() {try {//查询数据表List<List<Object>> result = sqlSourceHelper.executeQuery();//存放event的集合List<Event> events = new ArrayList<>();//存放event头集合HashMap<String, String> header = new HashMap<>();//如果有返回数据,则将数据封装为eventif (!result.isEmpty()) {List<String> allRows = sqlSourceHelper.getAllRows(result);Event event = null;for (String row : allRows) {event = new SimpleEvent();event.setBody(row.getBytes());event.setHeaders(header);events.add(event);}//将event写入channelthis.getChannelProcessor().processEventBatch(events);//更新数据表中的offset信息sqlSourceHelper.updateOffset2DB(result.size());}//等待时长Thread.sleep(sqlSourceHelper.getRunQueryDelay());return Status.READY;} catch (InterruptedException e) {LOG.error("Error procesing row", e);return Status.BACKOFF;}}@Overridepublic synchronized void stop() {LOG.info("Stopping sql source {} ...");try {//关闭资源sqlSourceHelper.close();} finally {super.stop();}}
}
然后再来看看辅助类(整体的 MySQL 监视具体逻辑都是这个类完成,因为要和 MySQL 交互)
属性介绍
| 属性 | 说明(括号中为默认值) |
|---|---|
| runQueryDelay | 查询时间间隔(10000) |
| batchSize | 缓存大小(100) |
| startFrom | 查询语句开始id(0) |
| currentIndex | 查询语句当前id,每次查询之前需要查元数据表 |
| recordSixe | 查询返回条数 |
| table | 监控的表名 |
| columnsToSelect | 查询字段(*) |
| customQuery | 用户传入的查询语句 |
| query | 查询语句 |
| defaultCharsetResultSet | 编码格式(UTF-8) |
方法介绍
| 方法 | 说明 |
|---|---|
| SQLSourceHelper(Context context) | 构造方法,初始化属性及获取JDBC连接 |
| InitConnection(String url, String user, String pw) | 获取JDBC连接 |
| checkMandatoryProperties() | 校验相关属性是否设置(实际开发中可增加内容) |
| buildQuery() | 根据实际情况构建sql语句,返回值String |
| executeQuery() | 执行sql语句的查询操作,返回值List<List> |
| getAllRows(List<List> queryResult) | 将查询结果转换为String,方便后续操作 |
| updateOffset2DB(int size) | 根据每次查询结果将offset写入元数据表 |
| execSql(String sql) | 具体执行sql语句方法 |
| getStatusDBIndex(int startFrom) | 获取元数据表中的offset |
| queryOne(String sql) | 获取元数据表中的offset实际sql语句执行方法 |
| close() | 关闭资源 |
具体代码如下
package com.cris;import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.experimental.Accessors;
import org.apache.flume.Context;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;import javax.naming.ConfigurationException;
import java.io.IOException;
import java.sql.*;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;/*** TODO** @author cris* @version 1.0**/
@SuppressWarnings("JavaDoc")
@Data
@AllArgsConstructor
@NoArgsConstructor
@Accessors(chain = true)
public class SQLSourceHelper {private static final Logger LOG = LoggerFactory.getLogger(SQLSourceHelper.class);private int runQueryDelay, //两次查询的时间间隔startFrom, //开始idcurrentIndex, //当前idrecordSixe = 0, //每次查询返回结果的条数maxRow; //每次查询的最大条数private String table, //要操作的表columnsToSelect, //用户传入的查询的列customQuery, //用户传入的查询语句query, //构建的查询语句defaultCharsetResultSet;//编码集//上下文,用来获取配置文件private Context context;//为定义的变量赋值(默认值),可在flume任务的配置文件中修改private static final int DEFAULT_QUERY_DELAY = 10000;private static final int DEFAULT_START_VALUE = 0;private static final int DEFAULT_MAX_ROWS = 2000;private static final String DEFAULT_COLUMNS_SELECT = "*";private static final String DEFAULT_CHARSET_RESULTSET = "UTF-8";private static Connection conn = null;private static PreparedStatement ps = null;private static String connectionURL, connectionUserName, connectionPassword;//加载静态资源static {Properties p = new Properties();try {p.load(SQLSourceHelper.class.getClassLoader().getResourceAsStream("jdbc.properties"));connectionURL = p.getProperty("dbUrl");connectionUserName = p.getProperty("dbUser");connectionPassword = p.getProperty("dbPassword");Class.forName(p.getProperty("dbDriver"));} catch (IOException | ClassNotFoundException e) {LOG.error(e.toString());}}/*** 获取JDBC连接** @param url* @param user* @param pw* @return JDBC 连接*/private static Connection initConnection(String url, String user, String pw) {try {Connection conn = DriverManager.getConnection(url, user, pw);if (conn == null)throw new SQLException();return conn;} catch (SQLException e) {e.printStackTrace();}return null;}/*** 构造方法里初始化配置(通过读取 Flume 任务配置文件的参数)以及调用参数校验方法** @param context*/@SuppressWarnings("unused")SQLSourceHelper(Context context) {//初始化上下文this.context = context;//有默认值参数:获取flume任务配置文件中的参数,读不到的采用默认值this.columnsToSelect = context.getString("columns.to.select", DEFAULT_COLUMNS_SELECT);this.runQueryDelay = context.getInteger("run.query.delay", DEFAULT_QUERY_DELAY);this.startFrom = context.getInteger("start.from", DEFAULT_START_VALUE);this.defaultCharsetResultSet = context.getString("default.charset.resultset", DEFAULT_CHARSET_RESULTSET);//无默认值参数:获取flume任务配置文件中的参数,如果Flume 配置文件中没有配置的参数,那么就参考static 代码快读取的jdbc.properties 的配置this.table = context.getString("table");this.customQuery = context.getString("custom.query");connectionURL = context.getString("connection.url");connectionUserName = context.getString("connection.user");connectionPassword = context.getString("connection.password");conn = initConnection(connectionURL, connectionUserName, connectionPassword);//校验相应的配置信息,如果没有默认值的参数也没赋值,抛出异常try {checkMandatoryProperties();} catch (ConfigurationException e) {e.printStackTrace();}//获取当前表数据保存到 flume_data 表的idcurrentIndex = getStatusDBIndex(startFrom);//构建查询语句,需要去对应的表根据 id 查询数据query = buildQuery();}/*** 校验相应的配置信息(表,查询语句以及数据库连接的参数)** @throws ConfigurationException*/private void checkMandatoryProperties() throws ConfigurationException {if (table == null) {throw new ConfigurationException("property table not set");}if (connectionURL == null) {throw new ConfigurationException("connection.url property not set");}if (connectionUserName == null) {throw new ConfigurationException("connection.user property not set");}if (connectionPassword == null) {throw new ConfigurationException("connection.password property not set");}}/*** 构建sql语句:从 flume_meta 表获取指定表的 offset,然后构建 sql 从指定表去查新插入的数据** @return 去指定表查询数据的 sql 语句*/private String buildQuery() {String sql;StringBuilder execSql = new StringBuilder();//获取当前idcurrentIndex = getStatusDBIndex(startFrom);LOG.info(currentIndex + "what is the currentIndex?");if (customQuery == null) {// 如果 customerQuery 为null,就以 offsest 作为 idsql = "SELECT " + columnsToSelect + " FROM " + table;execSql.append(sql).append(" where ").append("id").append(">").append(currentIndex);} else {/*如果 customQuery 不为 null,那么就要将其最后已存在的 offset 替换掉新查询出的 offset(!!!)*/sql = customQuery.substring(0, customQuery.indexOf(">") + 1) + currentIndex;execSql.append(sql);}return execSql.toString();}/*** 执行查询:从指定的表去查询数据** @return 数据集*/List<List<Object>> executeQuery() {try {//每次执行查询时都要重新生成sql,因为id不同customQuery = buildQuery();//存放结果的集合List<List<Object>> results = new ArrayList<>();if (ps == null) {ps = conn.prepareStatement(customQuery);}ResultSet result = ps.executeQuery(customQuery);while (result.next()) {//存放一条数据的集合(多个列)List<Object> row = new ArrayList<>();//将返回结果放入集合for (int i = 1; i <= result.getMetaData().getColumnCount(); i++) {row.add(result.getObject(i));}results.add(row);}LOG.info("execSql:" + customQuery + "\nresultSize:" + results.size());return results;} catch (SQLException e) {LOG.error(e.toString());// 重新连接conn = initConnection(connectionURL, connectionUserName, connectionPassword);}return null;}/*** 将结果集转化为字符串,每一条数据是一个list集合,将每一个小的list集合转化为字符串** @param queryResult 结果集* @return 查询的结果集转换后的字符串*/List<String> getAllRows(List<List<Object>> queryResult) {List<String> allRows = new ArrayList<>();if (queryResult == null || queryResult.isEmpty())return allRows;StringBuilder row = new StringBuilder();for (List<Object> rawRow : queryResult) {Object value;for (Object aRawRow : rawRow) {value = aRawRow;if (value == null) {row.append(",");} else {row.append(aRawRow.toString()).append(",");}}allRows.add(row.toString());row = new StringBuilder();}return allRows;}/*** 更新offset元数据状态,每次返回结果集后调用。必须记录每次查询的offset值,为程序每次查询使用,以id为offset** @param size 新的 offset*/void updateOffset2DB(int size) {//以source_tab做为KEY,(on duplicate key update 函数)如果 offset 不存在则插入,存在则更新(每个源表对应一条记录,记录当前表的 offset)String sql = "insert into flume_meta(source_tab,currentIndex) VALUES('"+ this.table+ "','" + (recordSixe += size)+ "') on DUPLICATE key update source_tab=values(source_tab),currentIndex=values(currentIndex)";LOG.info("updateStatus Sql:" + sql);execSql(sql);}/*** 执行sql语句:新增或者更新 flume_meta 表的数据** @param sql*/private void execSql(String sql) {try {ps = conn.prepareStatement(sql);LOG.info("exec::" + sql);ps.execute();} catch (SQLException e) {e.printStackTrace();}}/*** 获取当前 source_tab 的 offset 是多少, sql 语句中的 flume_meta 表写死了,实际上可以提取出来作为 Flume 的任务配置文件参数** @param startFrom* @return offset*/private Integer getStatusDBIndex(int startFrom) {//从flume_meta表中查询出当前表对应的 id 是多少,拿到这个 id 就可以去对应的表根据 id 查询数据并写入到 Flume 的 channel 里去String dbIndex = queryOne("select currentIndex from flume_meta where source_tab='" + table + "'");LOG.info("currentIndex = " + dbIndex);if (dbIndex != null) {return Integer.parseInt(dbIndex);}//如果没有数据,则说明是第一次查询或者数据表中还没有存入数据,返回最初传入的值即可return startFrom;}/*** 具体查询 flume_meta 对应数据表的 offset 的方法** @param sql* @return offset*/private String queryOne(String sql) {ResultSet result;try {ps = conn.prepareStatement(sql);LOG.info("sql = " + sql);result = ps.executeQuery();if (result.next()) {return result.getString(1);}} catch (SQLException e) {e.printStackTrace();}return null;}/*** 关闭相关资源*/void close() {try {ps.close();conn.close();} catch (SQLException e) {e.printStackTrace();}}
}
③ 打包运行
使用 Maven 打包项目,然后放到服务器的 Flume 文件夹的 lib 目录下

将 mysql 驱动包放入 flume 的 lib 目录下

书写 job 配置文件
[cris@hadoop101 job]$ vim mysql.conf写入以下内容
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1# Describe/configure the source a1.sources.r1.type = com.cris.SQLSource a1.sources.r1.connection.url = jdbc:mysql://192.168.1.101:3306/mysqlsource a1.sources.r1.connection.user = root a1.sources.r1.connection.password =123456 a1.sources.r1.table = student a1.sources.r1.columns.to.select = * #a1.sources.r1.incremental.column.name = id #a1.sources.r1.incremental.value = 0 a1.sources.r1.run.query.delay=5000# Describe the sink a1.sinks.k1.type = logger# Describe the channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100# Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
④ 创建 MySQL 对应表
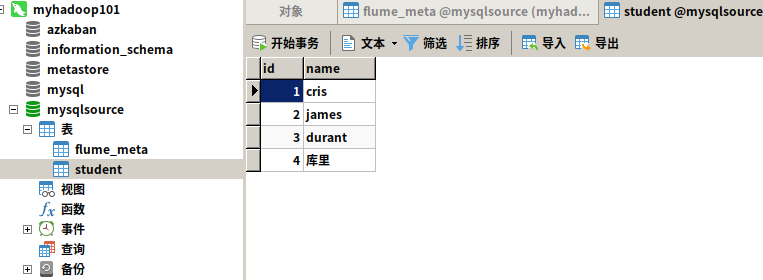
打开 Navicat Premium 12,建表及数据如下:
值得一提的是,Cris 这里使用的是 Linux 版本的 Navicat Premium 12,实质上还是 Windows 版本的,但是这也太丑了吧?,?
具体的 sql 语句如下:
CREATE DATABASE mysqlsource;CREATE TABLE `student` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
PRIMARY KEY (`id`)
);CREATE TABLE `flume_meta` (
`source_tab` varchar(255) NOT NULL,
`currentIndex` varchar(255) NOT NULL,
PRIMARY KEY (`source_tab`)
);
⑤ 测试(并使用 IDEA 远程 Debug)
首先要开启 mysql 服务~~~
因为 Cris 写这些代码的时候,还是调试了不少时间的,所以这里写出 Cris 如何 Debug 的流程
参考博客
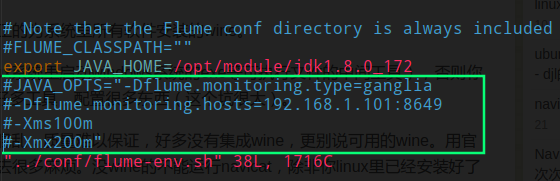
首先如果要开启 Flume 的远程 Debug 模式,需要注释掉我们之前在 Flume 配置文件中配置的 Ganglia 信息
然后修改 bin目录下的 flume-ng 文件

紧接着修改我们的 IDEA 程序配置文件
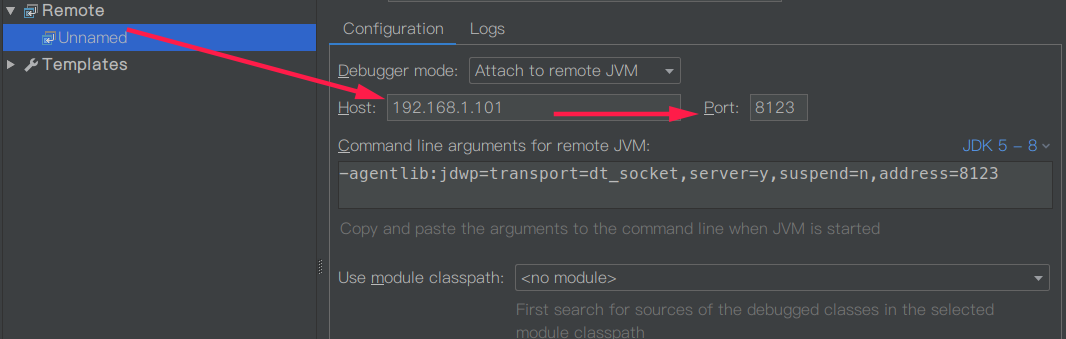
然后随意打个断点
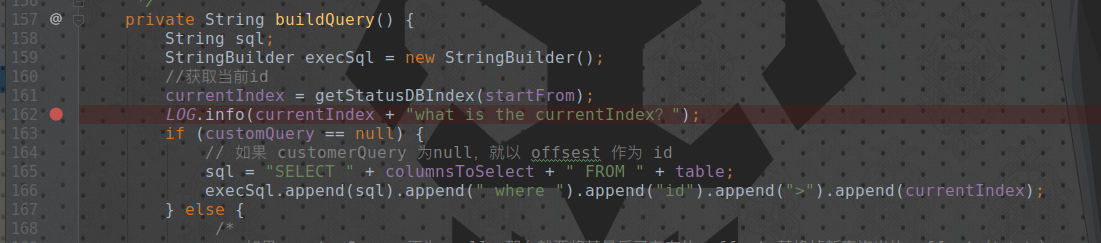
启动 Flume ~
[cris@hadoop101 flume]$ flume-ng agent -c conf/ -n a1 -f job/mysql.conf -Dflume.root.logger=INFO,console发现服务启动停滞了~
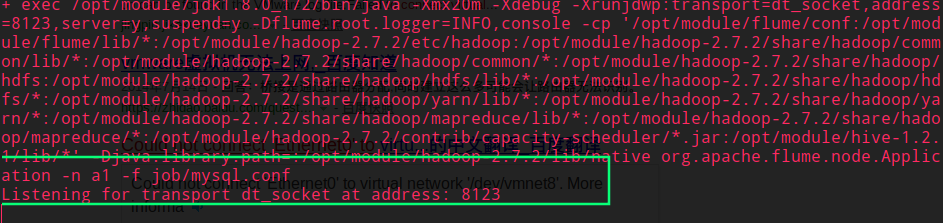
不要慌,此时 IDEA 以 Debug 模式运行代码
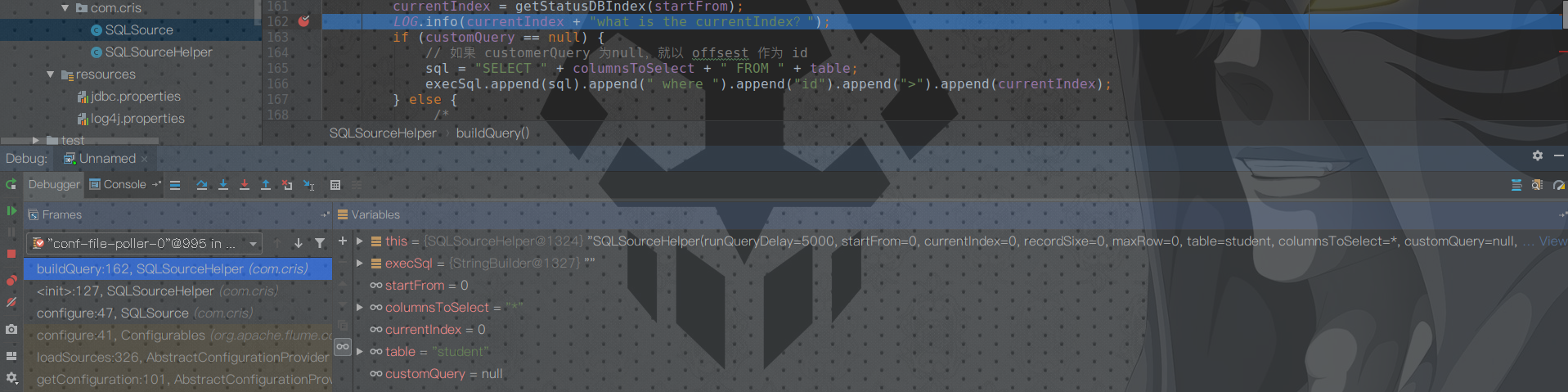
然后往下执行,发现远程服务器日志跟着输出

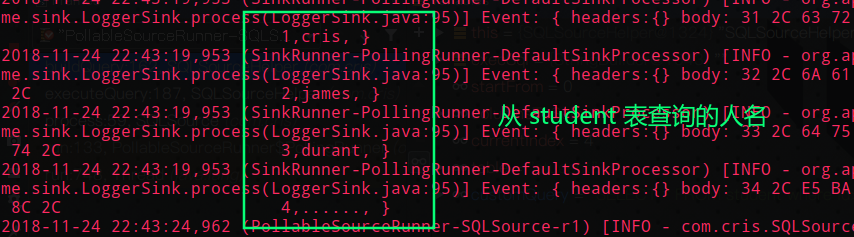
我们执行断点多次,可以发现远程服务器日志输出如下
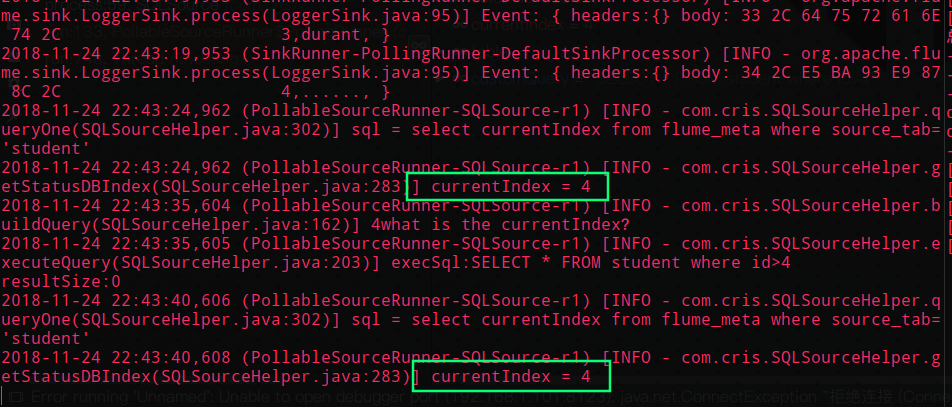
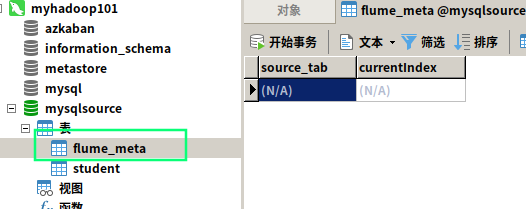
证明程序持续从 flume_meta 表中读取索引,但是因为 student 表中并没有新的数据插入,所以并没有打印新的人名(执行的 sql 语句一直是 SELECT * FROM student where id>4 )
再看看数据表
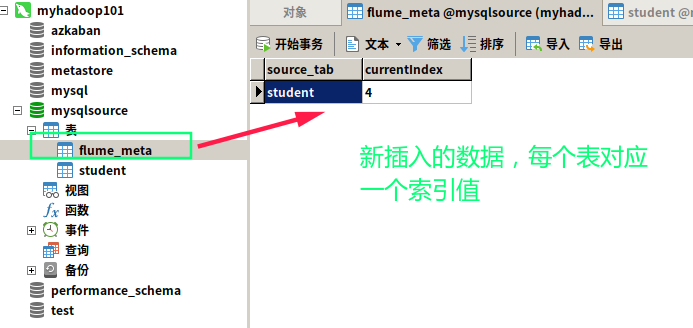
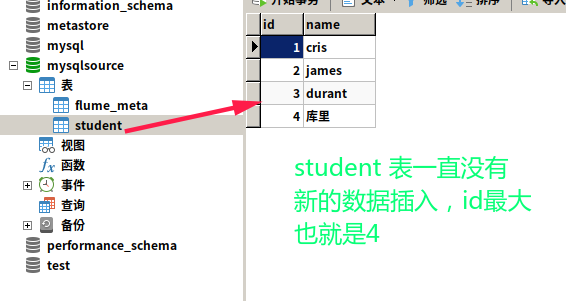
到此,自定义 MySQLSource 就完成了:happy:
5.4 总结
总体来说,Flume 还是比较容易上手的,目前作为大数据领域最流行的日志采集和聚合框架,熟悉 Flume 还是很有必要的
同时自定义 Flume 的 Source 组件没有很复杂,跟着官网的教程一步一步走即可,Cris 写完还是费了一番功夫调试的,特别是 IDEA 的远程 Debug 模式,真的很方便!!!
上面自定义的 Source 组件还有一个关键点:student 表的 id 一定要设置为自增 +1,并且从 1 开始的,想想为什么???此外强烈建议将 自增+1 的操作放到 Java 代码里去执行,减少数据库负担
对这个 demo 感兴趣的同学可以参考
最后附上 Cris 做的简单图示
6. 简单的正则
| 元字符 | 描述 |
|---|---|
| ^ | 匹配输入字符串的开始位置。如果设置了RegExp对象的Multiline属性,^也匹配“\n”或“\r”之后的位置。 |
| $ | 匹配输入字符串的结束位置。如果设置了RegExp对象的Multiline属性,$也匹配“\n”或“\r”之前的位置。 |
| * | 匹配前面的子表达式任意次。例如,zo*能匹配“z”,“zo”以及“zoo”。*等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次(大于等于1次)。例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{1,}。 |
| [a-z] | 字符范围。匹配指定范围内的任意字符。例如,“[a-z]”可以匹配“a”到“z”范围内的任意小写字母字符。注意:只有连字符在字符组内部时,并且出现在两个字符之间时,才能表示字符的范围; 如果出字符组的开头,则只能表示连字符本身. |
Cris 玩转大数据系列之日志收集神器 Flume相关推荐
- Cris 玩转大数据系列之消息队列神器 Kafka
Cris 玩转大数据系列之消息队列神器 Kafka Author:Cris 文章目录 Cris 玩转大数据系列之消息队列神器 Kafka Author:Cris 1. Kafka 概述 1.1 消息队 ...
- Cris 玩转大数据系列之任务流神器 Azkaban
Cris 玩转大数据系列之任务流神器 Azkaban Author:Cris 文章目录 Cris 玩转大数据系列之任务流神器 Azkaban Author:Cris 1. 概述 1.1 为什么需要工作 ...
- Cris 玩转大数据系列之 Hadoop HA 实现
文章目录 零.序 1. Hadoop 实现 HA 原理 1.1 什么是 HA? 1.2 HA 工作机制 2. HDFS-HA 手动故障转移(了解) 2.1 要点 2.2 环境准备 2.3 测试集群规划 ...
- Cris 玩转大数据之分布式服务协调神器 ZooKeeper
文章目录 0.什么是ZooKeeper? 1.安装 ZooKeeper Ⅰ. 解压 Ⅱ.配置环境变量(可选) ⅲ.修改配置文件以及同步 Ⅳ.ZooKeeper集群搭建以及集群脚本编写 2.客户端操作 ...
- 玩转大数据系列之三:数据报表与展示
为什么80%的码农都做不了架构师?>>> 经过了数据采集与数据同步.数据分析和处理,我们应该考虑将处理好的数据做成报表或者大屏展示给老板们看,以便老板们可以更加精准地做出战略决 ...
- 大数据系列(五)之 Flume 数据传输
目录 一.Flume简介 二.Flume架构 2.1 Flume基本组件 2.2 Flume常见数据流模型 三.Source,Channel,Sink 详解 3.1 Source 3.2 Channe ...
- 大数据系列之日志数据实时分析计算
日志数据实时分析计算基于Spark Streaming和Kafka实现,本文主要介绍其中采集模块.数据清洗模块.指标计算模块.数据存储模块. 1.日志实时分析系统架构 实时日志分析系统通过Logsta ...
- 大数据——Logstash(日志收集)
Logstash(日志收集) ELK Stack Logstash简介 安装Logstash Logstash如何工作 Logstash配置语法(一) Logstash配置语法(二) 输入插件 编解码 ...
- 大数据系列 之 学习准备
在学习大数据的过程中,需要具备的能力或者知识,在这里简单的罗列一下: 语言基础:需要会使用shell脚本.java和scala(这俩语言主要是用于日常代码和阅读源代码) 工具:IDE如eclipse或 ...
最新文章
- 19日零时起降低成品油价格 燃油税元旦起开征
- Spring Boot与数据访问
- 数据结构与算法:Python语言描述
- 中小型园区网络的基本部署之动手划分vlan
- 43 WM配置-作业-库存盘点-定义每种存储类型的类型
- Ubuntu文件夹有锁标志
- mysql单张表数据量极限_极限数据量范围的安全测试
- Flutter实战之Android混合开发初探
- p1口实验_【正点原子FPGA连载】第二章 实验平台简介-摘自【正点原子】开拓者 FPGA 开发指南...
- 软件系统服务器改造方案,并实施系统软件国产化改造方案 审计署.doc
- 2018最佳GAN论文回顾
- PDF文件如何旋转文件
- 协议软件服务器吗,使用开源协议软件搭建即时通讯服务器.doc
- QQ勋章墙工具-支持所有版本完成QQ等级加速
- 分享109个PHP源码,总有一款适合您
- 用通俗易懂的大白话彻底搞明白mysql的数据类型以及mysql中的int(11),这个11到底是啥?
- python实现:将一个四位数反向输出
- 很好的励志文章(特别针对刚刚进入职场的毕业生而写)
- 人群计数:人群计数研究综述(2018.11)
- 根据字体的中文名 获取 字体的路径 和 英文名
热门文章
- iOS英语背单词神器-背轻松-单词卡APP系列推荐
- 逃离天坑之后——谈谈技术路线该怎么走
- 美团团队---客户端自动化测试研究
- JIL Widget模拟器上网技巧
- 使用API绘制轮船,并实现按下键盘上的W,A,S,D键进行上下左右移动,按下+,-键实现放大和缩小功能
- Hi3519AV100 arm-himix200-linux-gcc 编译失败
- IDEA创建新的类(Java文件)时,自动添加作者创建时间(文件注释)等信息的设置方法
- python公众号开发框架_Python的WeRoBot框架开发公众号-Go语言中文社区
- 当事情推动不了时,投诉或许是一种好的解决方案 | 每天成就更大成功
- 叔贵的减脂训练课,臀部+马甲线+肩颈