MySQL Binlog实现流式实时分析架构
数据分析特别是实时数据分析,已经越来越多的成为各行各业的分析要求与标准 – 例如,(新)零售行业可能希望通过线下POS数据与实时门店客流流量的进行实时结合与分析,实现商品销售,销量,总类等等的实时预测; 在线广告平台期望通过广告(Impression)总类,数据量以及基于时间的点击(Click)量,计算实时的广告转化率(Conversion Rate);物联网的用户想通过实时分析线下的状态设备与设备采集的数据,进行后台的计算与预判 – 例如做一些设备维修的提前预警(Predicative Failure Analysis)与线下用户的使用习惯;电商平台或者是在线媒体需要给终端用户提供个性化的实时推荐等等。
纵观这些业务系统,从数据流的角度看,往往数据架构可以分为前后端两个部分 – 前端的业务数据与日志收集系统(其中业务数据系统一般都是利用关系型数据库实现 – 例如 MySQL,PostgreSQL)与后端的数据分析与处理系统 (例如ElasticSearch 搜索引擎,Redshift数据仓库,基于S3的Hadoop系统 等等,或者基于Spark Stream的实时分析后端)。
“巧妇难为无米炊”,实时数据分析的首要条件是实现实时数据同步,即从上述前端系统到后端系统的数据同步。具体来讲包含两个要求(根据业务场景的不同,实时性会有差异)- 1) 实时 2) 异构数据源的增量同步。实时的要求容易理解 – 无非是前后端系统的实时数据ETL的过程,需要根据业务需求,越快越好。所谓异构数据源的增量同步是指,前端产生的增量数据(例如新增数据,删除数据,更新数据 – 主要是基于业务数据库的场景,日志相对简单,主要是随时间的增量数据)可以无缝的同步到后端的数据系统 – 例如ElasticSearch,S3或者Redshift等。 显然,这里的挑战主要是来自于异构数据源的数据ETL – 直白一点,就是怎么把MySQL(或者其他RDBMS)实时的同步到后端的各类异构数据系统。因为,MySQL的表结构的存储不能简单的通过复制操作实现数据同步。 业界典型的做法大概可以归纳为两类 – 1)通过应用程序双写的架构 (application dual-writes) 2) 利用流式架构实现数据同步,即基于流式数据的Change Data Caputre (CDC) 。 双写架构实现简单,利用应用逻辑实现,但是要保证数据一致性相对复杂(需要通过二阶段提交实现 – two phase commit),而且,架构扩展相对比较困难 – 例如增加新的数据源,数据库等。 利用流式数据重构数据,越来越成为很多用户与公司的实时数据处理的架构演化方向。 MySQL的Binlog,以日志方式记录数据变化,使这种异构数据源的实时同步成为可能。 今天,我们主要讨论的是如何利用MySQL的binlog实现流式数据同步。
MySQL Binlog数据同步原理
讲了这么多,大家看张图。 我们先了解一下MySQL Binlog的基本原理。 MySQL的主库(Master)对数据库的任何变化(创建表,更新数据库,对行数据进行增删改),都以二进制文件的方式记录与主库的Binary Log(即binlog)日志文件中。从库的IO Thread异步地同步Binlog文件并写入到本地的Replay文件。SQL Thread再抽取Replay文件中的SQL语句在从库进行执行,实现数据更新。 需要注意的是,MySQL Binlog 支持多种数据更新格式 – 包括Row,Statement,或者mix(Row和Statement的混合)。我们建议使用Row这种Binlog格式(MySQL5.7之后的默认支持版本),可以更方便更加实时的反映行级别的数据变化。

如前所述,MySQL Binlog是MySQL主备库数据同步的基础,因为Binlog以日志文件的方式,记录了数据库的实时变化,所以我们可以考虑类似的方法 – 利用一些客户端工具,把它们伪装成为MySQL的Slave(备库)进行同步。
基于Binlog的流式日志抽取的架构与原理
在我们这个场景中, 我们需要利用一些客户端工具“佯装”成MySQL Slave,抽取出Binlog的日志文件,并把数据变化注入到实时的流式数据管道中。我们在管道后端对Binlog的变化日志,进行消费与必要的数据处理(例如利用AWS的Lambda服务实现无服务器的代码部署),同步到多种异构数据源中 – 例如 Redshift, ElasticSearch, S3 (EMR) 等等。具体的架构如下图所示。

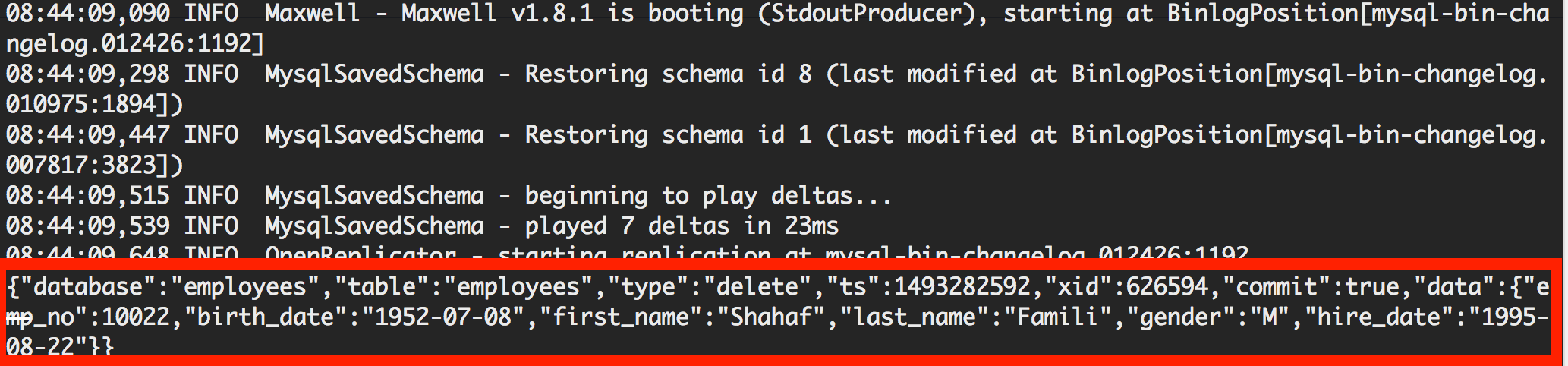
这里需要给大家介绍一个比较好的MySQL的Binlog的抽取工具 Maxwell’s Daemon。这款由Zendesk开发的开源免费(http://maxwells-daemon.io/) Binlog抽取工具可以方便的抽取出MySQL (包括AWS RDS)的变化数据,方便的把变化数据以JSON的格式注入到后端的Kafka或者Amazon Kinesis Stream中。我们把RDS MySQL中的Binlog输出到控制台如下图所示 – 下图表示从employees数据库的employees数据表中,删除对应的一行数据。
在上述架构中,我们利用Lambda实时读取Amazon Kinesis Stream中的MySQL Binlog日志,通过Kinesis Firehose实时地把MySQL binlog的结构数据自动化地同步到S3和Redshift当中。值得注意的是,整个架构基于高可用和自动扩展的理念 – Kinesis Stream( 高可用),Lambda(Serverless与自动扩展),Kinesis Firehose(兼具高可用与自动扩展)。Kinesis Stream作为统一的一个数据管道,可以通过Lambda把数据分发到更多的数据终点 – 例如,ElasticSearch或者DynamoDB中。
原文:https://aws.amazon.com/cn/blogs/china/mysql-binlog-architecture/
发表评论 取消回复

电子邮件地址不会被公开。
近期文章
- Maven deploy部署jar到远程私服仓库
- java动态代理实现与原理
- git 常用命令
- java中观察者模式Observable和Observer
- Netty解决TCP粘包和拆包问题的四种方案
近期评论
- 马化腾发表在《Nginx的一些基本功能》
- geyang发表在《世界,您好!》
- 一位WordPress评论者发表在《世界,您好!》
分类目录
- Big Data (5)
- Java (27)
- MicroServices (13)
- GateWay (2)
- REST (2)
- Plus (38)
- Spring (9)
- Spring Boot (5)
- Spring Data (4)
- 中间件/框架 (5)
- Kafka (3)
- 数据库 (11)
- Hbase (5)
- MongoDb (2)
- Mysql (3)
标签
联系我
yangge177@gmail.com
友情链接
- aisanger
MySQL Binlog实现流式实时分析架构相关推荐
- 流式数据架构理论 ◆ 基本概念
基本概念 流 流是一种为无界数据集设计的数据处理引擎,这种引擎具备以下特征: (1)具备强一致性,即支持 exactly-once 语义 (2)提供丰富的时间工具,如事件时间.处理时间.窗口 (3)保 ...
- mysql binlog限流问题总结
业务场景: 新建slave连到master,执行start slave时master险些被"搞死". 分析:新建slave连到master时,会将主库上大量的binlog(几百G) ...
- 大数据读书笔记(2)-流式计算
早期和当前的"流式计算"系统分别称为"连续查询处理类"和"可扩展数据流平台类"计算系统. 流式计算系统的特点: 1)低延迟 2)极佳的系统容 ...
- 流式计算strom,Strom解决的问题,实现实时计算系统要解决那些问题,离线计算是什么,流式计算什么,离线和实时计算区别,strom应用场景,Strorm架构图和编程模型(来自学习资料)
1.背景-流式计算与storm 2011年在海量数据处理领域,Hadoop是人们津津乐道的技术,Hadoop不仅可以用来存储海量数据,还以用来计算海量数据.因为其高吞吐.高可靠等特点,很多互联网公司都 ...
- mysqlbinlog查看日志_一个分布式 MySQL Binlog 存储系统的架构设计
1. kingbus简介 1.1 kingbus是什么? kingbus是一个基于raft强一致协议实现的分布式MySQL binlog 存储系统.它能够充当一个MySQL Slave从真正的Mast ...
- 智能湖仓架构实践:利用 Amazon Redshift 的流式摄取构建实时数仓
Amazon Redshift 是一种快速.可扩展.安全且完全托管的云数据仓库,可以帮助用户通过标准 SQL 语言简单.经济地分析各类数据.相比其他任何云数据仓库,Amazon Redshift 可实 ...
- jdbc mysql 返回游标_使用JdbcTemplate流式(游标)读取数据库
前言 生产环境中经常使用数据库分页的方式来控制一次获取的数据量,而数据处理中经常会有另外一种场景: 从一个数据库表中读取所有数据进行处理并将结果保存在其他数据库或文件或NoSql数据库中. 这时候也可 ...
- 流式视频处理架构设计
在LiveVideoStack线上交流分享中,新浪微博视频平台架构师曾诚分享了微博大规模视频处理如何应对多业务场景,大流量,高并发的挑战.包括利用工作流式计算引擎实现场景动态配置,以及采用流式上传协议 ...
- 大数据架构中的流式架构和Kappa架构
关于大数据的架构有很多,比如说传统的大数据架构,当然,还有很多经典的大数据架构,比如说流式架构和Kappa架构.流式架构和Kappa架构在大数据中的应用还是很多的,在这篇文章中我们就给大家介绍一下关于 ...
最新文章
- javascript操作对象的方法
- WEB初学者简介,web入门
- httpd四之CGI、HTTPS、压缩配置
- C#调C++生成的dll报0x800736B1错误
- 前端学习(2993):vue+element今日头条管理--加入git管理
- Optional的巧用
- 推流中转服务器,视频推流服务器EasyRTMPLive拉转推过程当中遇到复杂目的地址解决方法?...
- CSS position属性---absolute与relative
- Hierarchical clustering
- 请千万不要在 JDK 7+ 中使用这个 JSON 包了!切记
- 动态贝叶斯网络DBN
- 高通Camera驱动(1)--Camx架构介绍
- 二、循环神经网络(RNN与LSTM)
- 苹果服务器维护2017.12,2017年12月28日维护公告
- 批发进销存管理软件,商品分类管理,对商品分类批量价格管理,商品分类导入导出的操作
- 使用rest_framework的routers模块添加路由
- 快速查询快递单号物流标记代收单号
- vvebo源码学习(一)
- Whale帷幄 - 智慧化门店 智慧化运营
- 【科普】72名图灵奖获得者的成就
热门文章
- Cassandra - A Decentralized Structured Storage System
- 如何将微信昵称设置成蓝色字体,让别人一秒就找到你!
- DT时代,小数据时代的未来发展
- 通过 Flick 看数据库集群
- 亚马逊(脚本)自动化软件开发案例过程
- msys 和 Cygwin
- VMware该虚拟机似乎正在使用中。如果该虚拟机未在使用,请按“获取所有权(T)”按钮获取它的所有权........
- 关于学Linux的时候安装vmtools时遇到的坑
- 最小二乘、加权最小二乘(WLS)、迭代加权最小二乘(迭代重加全最小二乘)(IRLS)
- 第9章第6节:完成目录页的制作并创建幻灯片切换效果 [PowerPoint精美幻灯片实战教程]