架构师的 36 项修炼第02讲:架构核心技术之分布式缓存(上)
本课时的主题是分布式缓存。
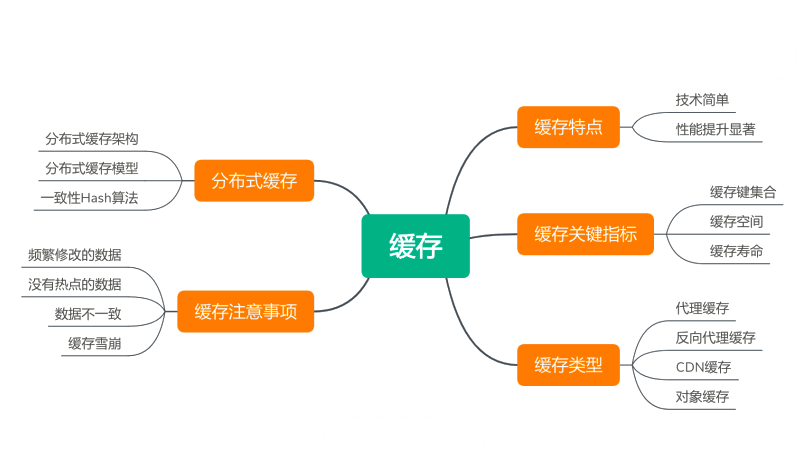
缓存是架构设计中一个重要的手段。缓存的主要特点是技术比较简单,同时对性能提升的效果又很显著,所以缓存在很多地方都会被用到。使用缓存需要注意几个关键指标:缓存键集合大小、缓存空间的大小以及缓存的使用寿命。这三个指标决定了缓存的有效性、缓存的使用效率、缓存实现的效果。缓存的类型主要有代理缓存、反向代理缓存、 CDN 缓存和对象缓存几种。缓存知识图谱如下图所示。
不是所有的数据都适合使用缓存,使用缓存的时候需要注意以下几点。
数据频繁修改,这类数据使用缓存效果比较差。
数据没有热点,这类数据缓存的命中率比较差。
数据不一致,因为缓存的数据和数据库的数据是不同步的,可能存在数据不一致的情况,如果业务场景对数据一致性要求非常高,这个时候使用缓存也要注意。
缓存雪崩,当缓存崩溃的时候,可能会导致整个系统的崩溃,这也是使用缓存中要注意的一个事项。
在架构中使用最多的,也是关注最多的是分布式缓存。分布式缓存最重要的几个技术点是:分布式对象缓存的架构、分布式对象缓存的访问模型,以及分布式缓存中一个重要的算法——一致性哈希算法。
缓存的特点
缓存的主要特点:
技术简单
性能提升显著
应用场景多
缓存可以被很容易地添加到现有的应用中,不需要复杂的架构技术。在现有的系统中使用缓存,该系统所受到的影响和要做出的调整是非常小的,但是使用缓存以后性能提升却非常明显。因此,使用缓存的场景非常多。不仅在系统架构中,在计算机的整个体系结构中缓存几乎是无处不在的。
比如,CPU 中就有缓存,在 CPU 固件里就有 cache,当 CPU 进行计算的时候,它并不总是每次都去内存中读取数据,而是预加载一部分指令和数据到 cache 里面,也就是 CPU 的缓存里面,CPU 核心计算取的数据其实大多数是 CPU 缓存中的数据。
再比如,操作系统的文件缓存。操作系统对磁盘进行操作的时候,它也会对数据进行缓存,以加快操作系统访问磁盘文件数据的速度。
还有就是数据库的查询缓存,数据库本身也会对一些数据表进行缓存。比如对索引的结构 B+ 树进行缓存,对一些热点的数据记录也要进行缓存,以加快应用程序的访问速度。
在外部应用系统中,比较常用的有 DNS 客户端缓存、HTTP 浏览器缓存、HTTP 代理和反向代理缓存、CDN 缓存,以及各种类型的对象缓存,对象缓存常用的比如 Redis、Memcached 等等。
缓存提高性能的优势
缓存是架构性能优化的最重要的手段,使用缓存来提升系统性能主要有三方面优势。
第一个方面是缓存的数据来自于内存,访问速度更快。我们知道数据从内存中读取要比磁盘上读取速度会更快,所以使用缓存从内存中读取数据会使系统获得更快的响应性能,系统的访问速度会更快,处理速度也会更快。
第二个方面是缓存中存储的数据形态通常是最终的结果形态,减少资源消耗。比如说,我们缓存一个网页、一个对象,这些数据通常是我们计算过的结果。从缓存中读取数据跟从磁盘中或者数据库中直接读取数据不同,从数据库中读取的数据要进行加工处理,生成我们最终的结果,而从缓存中读取的数据通常都是直接的最终结果。因此,使用缓存中的数据可以减少 CPU 的资源消耗,不需要进行中间的计算,可以进一步提高响应的特性。
第三个方面是使用缓存可以降低数据库磁盘或者网络的负载压力。不需要从外部的 IO 设备中去读取数据,这些数据直接从本地缓存或内存中读取,减少 IO 设备的访问压力。我们知道 IO 设备是最容易出现瓶颈的地方,减少这些设备的访问压力、负载压力,可以更好地提升整个系统的处理能力。
缓存数据存储(Hash 表)
缓存是存储在内存中的,那么如何从内存中快速获取一个数据呢?
缓存使用的数据结构主要是哈希(Hash)表。我们看一下哈希表实现的机制。哈希表最终的存储形式通常是一个顺序表,也就是一个数组结构。数组结构的特点是在内存中连续存储分配。那么,当我们要在哈希表中存储一个数据的时候,哈希表通常是以 key、value 这样的数据结构进行存储的。当我们把一个 key、value 数据结构存储在一个哈希表中的时候,主要的存储过程大致如下图所示。

首先,我们拿到 key、value 数据结构,在上图的例子中,key 是字符串 abc,value 是字符串 hello,我们先计算 key 的哈希值,比如字符串 abc 的 hashcode 算出来是 101 这样一个整型值。往下,计算哈希值 101 对应的 hash 表索引就要对 8 取模。此处 8 指什么?哈希表真正的物理存储是一个数组,我们建的哈希表长度是 8,如上图所示。101 对 8 取模余 5,这个 5 就是数组下标的索引值,我们就可以把 abc hello 这样一个 key、value 值存储在下标为 5 的数组记录中。这一步是最关键的,通常我们所谓的哈希算法也就是指这一步,即如何把一个哈希值转换成在数组中对应的位置。这个例子我们使用的是余数哈希,实践中最常用的也是余数哈希。
将来,当我们要进行数据读取的时候,只要给定 key abc,还是用这样一个算法过程,先求取它的 hash code 101,然后再对 8 取模。因为数组的长度不变,对 8 取模以后依然是余 5,那么我们到数字下标中去找 5 的这个位置,就可以找到前面存储进去的 abc 对应的 value 值。
通过哈希表可以使整个数据存储或检索效率时间复杂都是 O(1)。所以即使存储非常大的几百万上千万的数据量,通过哈希表也可以非常快地进行数据的查找和读写。通过这种手段缓存可以获得较快的读写访问特性,比数据库中的读写速度要快得多。
缓存的关键指标——命中率
影响缓存特性的一个关键指标是缓存的命中率。缓存的主要特点是一次写入多次读出,通过这种手段减少对数据库的使用,尽快从缓存中读取数据,提高性能。所以缓存是否有效,主要就是看它一次写进去的缓存能不能够多次去读出来响应业务的请求,这个判断指标就叫作缓存的命中率。
缓存命中率怎么算呢?查询得到正确缓存结果除以总的查询次数,得到的比值就是缓存命中率,比如说十次查询九次都能够得到缓存的正确结果,命中率就是 90%。
影响缓存命中率的主要因素有三个,分别是:
缓存键集合大小
内存空间大小
缓存的寿命
缓存键集合大小
缓存中的每个对象都是通过缓存键进行识别的。刚才 abc hello 这个例子里 abc 就是一个缓存的键,键是缓存中唯一的识别符,定位一个对象的唯一方式就是对缓存键进行精确的匹配。
比如说我们想缓存每个商品的在线商品信息,就需要使用商品 ID 作为缓存键。换句话说,缓存键空间是你的应用能够生成的所有键的数量。从统计数字上看,应用生成的唯一键越多,重用的机会越小。比如说根据 IP 地址缓存天气数据,可能需要 40 多亿个键。但是如果基于国家缓存天气数据,那么只需要几百个缓存键就够了,全世界也不过就几百个国家。
所以要尽可能减少缓存键的数量,键的数量越少,缓存的效率越高。设计缓存的时候要关注缓存键是如何进行设计的,它的整个的集合范围,限定在一个既能够高效使用,又可以减少它的数量,这个时候缓存的性能是最好的。
缓存内存空间大小
缓存可以使用的内存空间决定了缓存对象平均大小和缓存对象的数量。因为缓存通常是存储在内存中的,缓存对象可用的内存空间相对来说比较昂贵,而且受到严格限制。
如果想缓存更多的对象,就需要先删除老的对象,再添加新的对象。而这些老的对象被删除掉,就会影响到缓存的命中率。所以物理上缓存的空间越大,缓存的对象越多,缓存的命中率也就越高。
缓存对象生存时间(缓存寿命)
缓存对象的生存时间称为 TTL。对象缓存的时间越长,被重用的可能性就越高。使缓存失效的方法有两种:一种是超时失效;一种是清除失效,也就是实时清除。如下图所示。

所谓的超时失效是在构建缓存,即写缓存的时候,每个缓存对象都设置一个超时时间,在超时之前访问缓存就会返回缓存的数据,而一旦超时,缓存就失效了,这时候再访问缓存,就会返回空。
而实时清除是说,当有缓存对象更新的时候,直接通知缓存将已经被更新了的数据进行清除。清除了以后,应用程序下一次访问这个缓存对象键的时候,就不得不到数据库中去查找读取,这个时候就会得到最新的数据,因为更新总是更新在数据库里的。
还有一种,虽然时间上还没有失效但是新的对象要写入缓存,而内存空间不够了,这个时候就需要将一些老的缓存对象清理掉,为新的缓存对象腾出空间。
内存空间清除主要使用的算法是 LRU 算法,LRU 算法就是最近最久未用算法,也就是说清除那些最近最久没有被访问过的对象。这个算法使用链表结构实现的,所有的缓存对象都放在同一个链表上。当一个对象被访问的时候,就把这个对象移到整个链表的头部。当需要通过 LRU 算法清除那些最近最久未用对象的时候,只需要从队列的尾部进行查找,越是在队列尾部的,越是最近最久没有被访问过的,也就是优先清除的,腾出的内存空间让新对象加入进来。
缓存的主要类型
代理缓存
代理缓存是在应用程序—端的代理,缓存在客户端—端的,代理客户端访问互联网。它的主要作用是互联网访问代理。但是同时因为他代理了所有的客户端 HTTP 请求,所以它可以进行页面缓存,如果有一些其他的客户端已经访问过这个网页,那么当新的客户端连接的时候,就可以通过代理缓存中的数据直接返回,避免对数据中心的访问。

代理缓存是存在客户端一端的缓存,我们无法进行管理。所以代理缓存虽然存在,但是通常不作为我们系统架构中的一部分,我们能够管理的是反向代理缓存。
反向代理缓存

代理缓存是代理用户上网的,而反向代理则是代理数据中心输出的,是反向代理的。所以反向代理缓存是存在于系统数据中心里的,它是数据中心的统一入口,代理整个数据中心其他服务器的应用处理。
用户通过互联网连接到数据中心的时候,连接的通常是一个反向代理服务器,反向代理服务器根据用户的请求,在本地的反向代理缓存中查找是否有用户请求的数据,如果有就直接返回这个数据,如果没有再把这个请求向下继续转发,请求后面的应用服务器去处理生成数据。
反向代理缓存可以多层反向代理缓存的形式出现。因为我们的应用服务器也是经过分层的,在处理的前端通常是一个前端服务器,后面有 Web 服务器,之后有应用服务器,再后还有其他的各类服务器。在这样一个分层的服务器结构里,我们可以对每一层的服务器都进行反向代理缓存。
如下图所示,前端 Web 服务器和 Web 服务器分为两层,用户请求接入的时候,先接入前端 Web 服务器,其上可以加一层反向代理服务器来代理前端 Web 服务器的 HTTP 请求。如果用户请求的数据已经包含在这个反向代理服务器中,就可以直接返回;如果没有,就再把 HTTP 请求提交给前端 Web 服务器,前端 Web 服务器会把请求发给后面的 Web 服务器。在 Web 服务器和前端 Web 服务器之间还可以再加一层反向代理服务器。如果前端 Web 服务器的请求在这一层的反向代理服务器中存在,那么这一层反向代理服务器可以直接将数据返还;如果不存在,再将请求下发给 Web 服务器。

通过这样的方式,极大地减少了前端 Web 服务器或者是 Web 服务器的访问压力,同时提高了系统的响应性能。
内容分发网络 CDN 缓存
所谓的 CDN 是指在用户请求的前端(尽量前的前端)为用户提供数据服务。CDN 并不存在于我们的数据中心,也不存在于用户的访问系统一端,它介于两者之间,作为网络服务商的缓存服务。用户进行互联网访问的时候,需要通过互联网网络服务商提供的网络链接才能够连接到数据中心,那么网络服务商就可以在自己提供的网络服务的机房里进行一次缓存操作,提供一次缓存服务。如下图所示。

客户端第一次访问 example.com 的时候,访问数据中心,数据中心返回 HTML 页面以后,客户端解析 HTML,HTML 里面还各种 js 文件、css 文件、图片等,这些静态资源访问的就是 CDN 服务器。CDN 服务器检查自己是否有需要的静态资源,如果有,就立即返回给客户端;如果没有,就自己访问数据中心,获得需要的静态资源后,缓存在 CDN 服务器上后,再返回客户端。
所以 CDN 缓存也叫作网络访问的“第一跳”,用户请求先到达的是互联网网络服务商的机房。在机房里面部署 CDN 服务器,提供缓存服务。如果 CDN 中存在用户请求的 Web 响应内容,那么就可以直接通过 CDN 进行返回;如果 CDN 中不存在,那么 CDN 会把这个请求通过后面的网络连接,把它发到系统的数据中心去。数据中心返回的结果依然是先通过 CDN 服务器,CDN 服务器就可以把数据缓存在自己的本地,供后面的用户请求操作响应。
精选评论
**璋:
老师好,初入架构学习,想请问一下
1、CDN服务是运营商机房的,那进行缓存访问这些操作是需要跟运营商支付费用的吗?想去访问CDN服务器是怎么操作的能简要介绍一下吗2、反向代理服务器是不是需要部署在不同的区域? 比如公司总服务器在上海,但新疆用户多,访问的时候为了提高速度,是不是就需要在新疆部署一台反向代理服务器?感谢架构师的 36 项修炼第02讲:架构核心技术之分布式缓存(上)相关推荐
- 架构师的 36 项修炼第10讲:架构实战案例分析
本课时的主题是架构案例分享,通过案例分析来加深对前面所学内容的理解.下面将分析三种不同的系统架构案例. 分析初创互联网公司的架构演化案例,看一个小的系统架构是如何演化成一个较为成熟的.能够承受百万级订 ...
- 架构师的 36 项修炼第04讲:架构核心技术之分布式消息队列
本课时的主题是分布式消息队列,分布式消息队列的知识结构如下图. 本课时主要介绍以下内容. 同步架构和异步架构的区别.异步架构的主要组成部分:消息生产者.消息消费者.分布式消息队列.异步架构的两种主要模 ...
- 架构师的 36 项修炼第07讲:高性能系统架构设计
本课时讲解大家常听到的高性能系统架构. 高性能系统架构,主要包括两部分内容,性能测试与性能优化.性能优化又可以细分为硬件优化.中间件优化.架构优化及代码优化,知识架构图如下. 性能测试 先看系统的性能 ...
- 架构师的 36 项修炼1 开篇词:7分钟Get技术人进阶技巧
你好,欢迎来到我的架构课.可能很多人认识我是因为<大型网站技术架构:核心原理与案例分析>这本书,写书的时候我在阿里巴巴担任技术专家,期间设计开发了阿里巴巴分布式存储系统Doris.阿里巴巴 ...
- 运维高手的36项修炼_职业经理人36项修炼
职业经理人 36 项修炼 一 . 要有一个正确的方向 二 . 两个统一原则 1. 把个人发展利益与团队整体发展利益相统一的原则 . 2. 把现实发展利益和未来发展利益想统一原则 . 三 . 三个学习的 ...
- 运维高手的36项修炼_从大学生到经理人的36项修炼
从大学生到经理人的 36 项修炼 1 .管理者的核心能力是: ---- D .策划 + 计划 2 .团队的基因.企业做大的秘诀在于: ------ 没有分工,就没有协作.就没有团队.也就 谈不上企业化 ...
- 程序员晋升架构师的十项必备技能
1.卓越的程序员 Fred George先生说:"不编程的架构师的职业生涯是短暂的".他说这句话的背景主要是针对有些架构师的设计与实现有断层的问题而言的,因为如果架构师不去实践,只 ...
- Java架构师成长之道之浅谈计算机系统架构
Java架构师成长之道之浅谈计算机系统架构 Java架构师成长之旅 1.1 信息技术发展趋势 目前信息技术主要经历了互联网.移动互联网以及以大数据.云计算.人工智能和区块链为代表的新兴技术三个阶段.而 ...
- 阿里P7架构师要求:Web核心+开源框架+大型网站架构!含面试题目!
阿里P7技能(一):数据结构和算法: 常用数据结构:链表.堆与栈.哈希表等,常用的排序等. 掌握:精通 阿里P7技能(二):java高级 java相关的高级特性:JVM.多线程高并发.网络等. 掌握: ...
最新文章
- Leetcode 215. 数组中的第K个最大元素 解题思路及C++实现
- SAP HR系统如何处理员工月中调动问题
- 将一个文件夹的文件复制到另一个文件夹
- Port already in use: 1099;
- php图片旋转显示不出来的,php – 我服务的图像不正确,它们都显示为旋转90度
- 在用到select2时,临时抱佛脚学习了一下
- php 表别名,MySQL和PHP – 不是唯一的表/别名
- zmq是基于tcp实现的吗_zmq消息传输基本功能的实现、传输模式
- Apache IoTDB 物联网数据库引擎
- 2020-12-26
- react做h5 例子_从零搭建 React 开发 H5 模板
- 【SSH密钥生成与使用】
- vulnhub--ALFA: 1
- php删除文件还能修复吗,删除文件恢复
- ZT android -- 蓝牙 bluetooth (二) 打开蓝牙
- AR/VR/MR三者之间的区别和联系
- 数据挖掘之Spark学习
- 东西归置20210815
- 单线激光雷达的外参标定方法
- 5款免费分区工具,快给你的磁盘洗洗澡吧
热门文章