无监督学习 聚类分析②
划分聚类分析
K 均值聚类
最常见的划分方法是K均值聚类分析。从概念上讲,K均值算法如下:
- 选择K个中心点(随机选择K行);
- 把每个数据点分配到离它最近的中心点;
- 重新计算每类中的点到该类中心点距离的平均值(也就说,得到长度为p的均值向量,这
里的p是变量的个数); - 分配每个数据到它最近的中心点;
- 重复步骤(3)和步骤(4)直到所有的观测值不再被分配或是达到最大的迭代次数(R把10次
作为默认迭代次数)。
K均值聚类能处理比层次聚类更大的数据集。由于K均值聚类在开始要随机选择k个中心点,在每次调用函数时可能获得不同的方案。使用
set.seed() 函数可以保证结果是可复制的。此外,聚类方法对初始中心值的选择也很敏感。
kmeans() 函数有一个 nstart 选项尝试多种初始配置并输出最好的一个。
同样是聚类分析,上一次介绍的是层次聚类分法,这种方法输出的聚类树状图是其最大的优点,但是层次分析法的缺点就在于适合的样本数比较小,大概在150个左右。所以,当我们面临更大的数据时,划分聚类法就是更好的选择,虽然没有树状聚类图,却而代之的是圈型的聚类图。
- 代码:
setwd("E:\\Rwork")
library(rattle)
wine <- read.csv("wine.csv")
head(wine)
df <- wine[,-1]#或者wine$Type <- NULL
head(df)
df.scaled <- scale(df)
library(NbClust)
set.seed(1234)
devAskNewPage(ask = TRUE)#按回车输出图形
nc <- NbClust(df.scaled,min.nc = 2,max.nc = 15,method="kmeans")
table(nc$Best.n[1,])
*******************************************************************
* Among all indices:
* 4 proposed 2 as the best number of clusters
* 15 proposed 3 as the best number of clusters
* 1 proposed 10 as the best number of clusters
* 1 proposed 12 as the best number of clusters
* 1 proposed 14 as the best number of clusters
* 1 proposed 15 as the best number of clusters ***** Conclusion ***** * According to the majority rule, the best number of clusters is 3 ******************************************************************* barplot(table(nc$Best.n[1,]),xlab="Number of Clusters", ylab="Number of Criteria",main="Number of Clusters Chosen by 26 Criteria")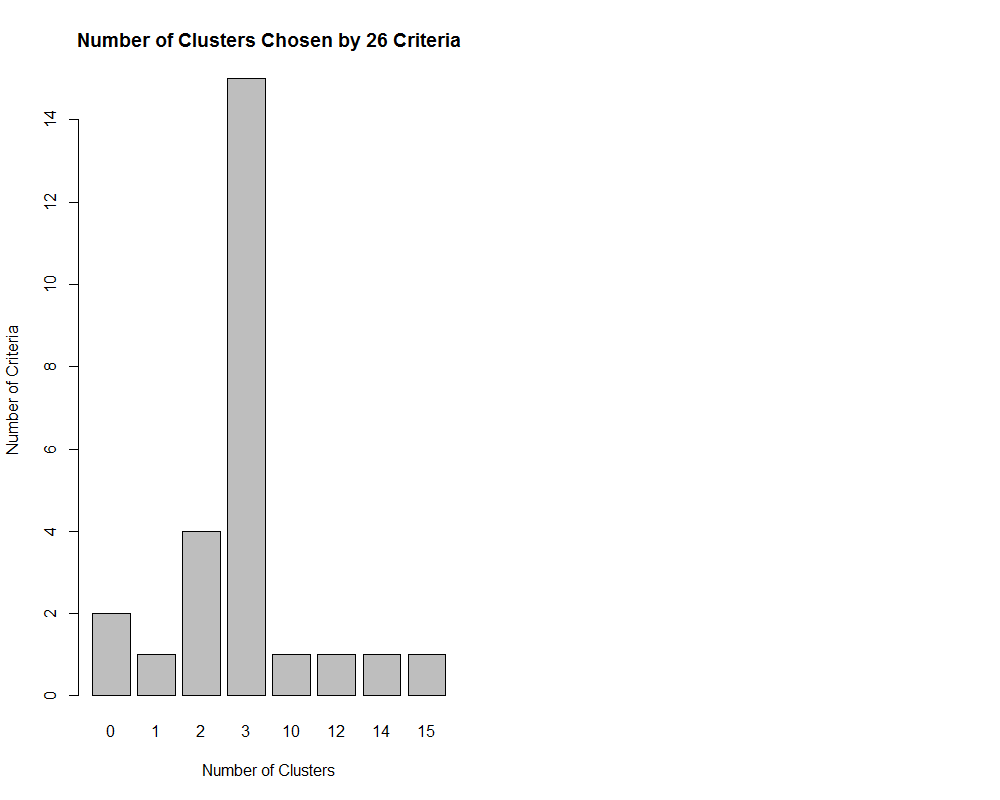
- NbClust 包中的26种指标中有15种建议使用类别数为3的聚类方案
set.seed(1234)
fit.km<- kmeans(df.scaled,3,nstart = 25)#nstart=25默认推荐值
fit.km$size #查看具体分类数量
fit.km$centers#查看具体中心点
aggregate(df,by=list(culster=fit.km$cluster),mean)
ct.km<-table(wine$Type, fit.km$cluster) #查看分类概括
ct.km1 2 31 59 0 02 3 65 33 0 0 48
- 用 flexclust 包中的兰德指数(Rand index)来量化类型变量和类之间的协议:
library(flexclust)
randIndex(ct.km)#-1是完全不同意,1是完全同意ARI
0.897495 library(cluster)
par(mfrow=c(1,1),no.readonly = FALSE)#NbCluster将图形改为(1,2)的形式,这里将其改回(1,1)的形式
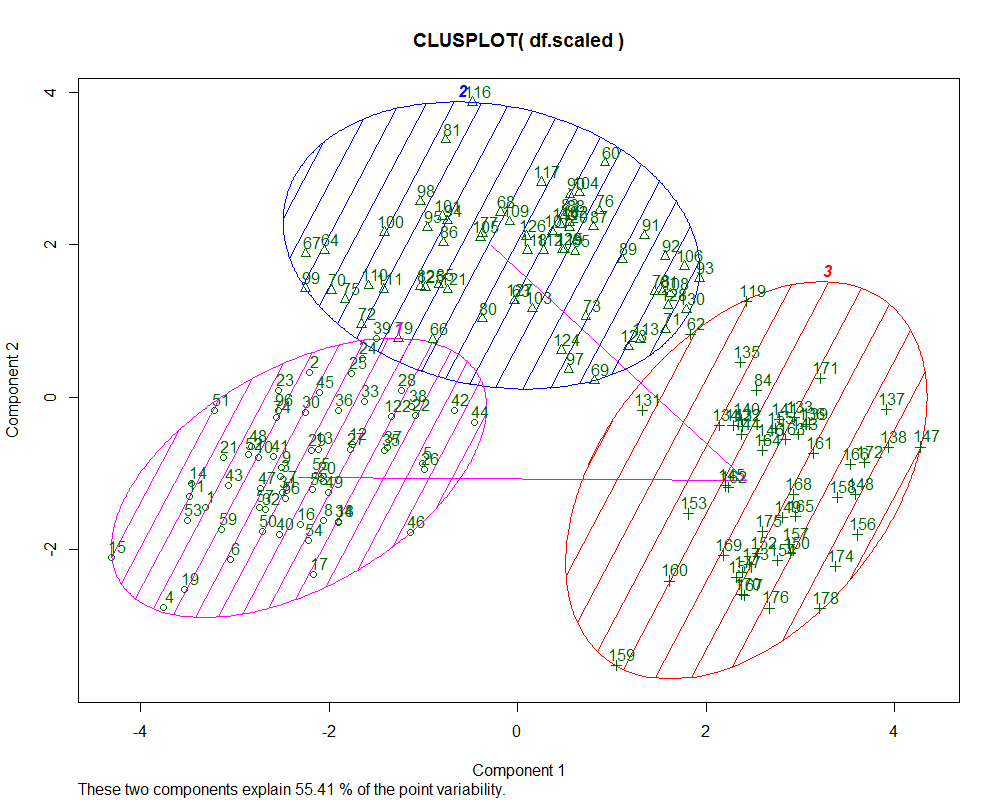
clusplot(df.scaled,fit.km$cluster,color = TRUE,shade = T,labels = 2,lines = 1)#输出聚类图
围绕中心点的划分
因为K均值聚类方法是基于均值的,所以它对异常值是敏感的。一个更稳健的方法是围绕中心点的划分(PAM)。与其用质心(变量均值向量)表示类,不如用一个最有代表性的观测值来表示(称为中心点)。K均值聚类一般使用欧几里得距离,而PAM可以使用任意的距离来计算。因此,PAM可以容纳混合数据类型,并且不仅限于连续变量。
PAM算法如下:
- 随机选择K个观测值(每个都称为中心点);
- 计算观测值到各个中心的距离/相异性;
- 把每个观测值分配到最近的中心点;
- 计算每个中心点到每个观测值的距离的总和(总成本);
- 选择一个该类中不是中心的点,并和中心点互换;
- 重新把每个点分配到距它最近的中心点;
- 再次计算总成本;
- 如果总成本比步骤(4)计算的总成本少,把新的点作为中心点;
- 重复步骤(5)~(8)直到中心点不再改变。
参数详解:可以使用 cluster 包中的 pam() 函数使用基于中心点的划分方法。格式是 pam(x, k,metric="euclidean", stand=FALSE) ,这里的 x 表示数据矩阵或数据框, k 表示聚类的个数,metric 表示使用的相似性/相异性的度量,而 stand 是一个逻辑值,表示是否有变量应该在计算该指标之前。
> library(cluster)
> set.seed(1234)
> fit.pam <- pam(wine[-1], k=3, stand=TRUE)
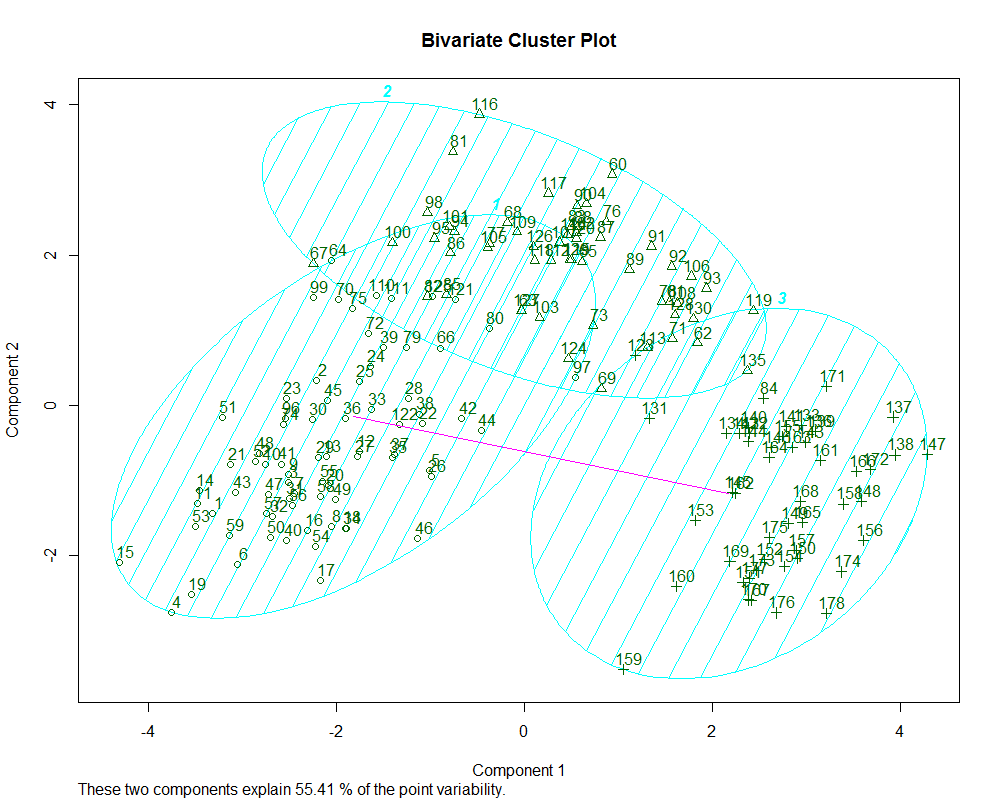
> fit.pam$medoids> clusplot(fit.pam, main="Bivariate Cluster Plot")
- 该数据中PAM法不如k-means法
ct.pam <- table(wine$Type, fit.pam$clustering)
> randIndex(ct.pam)ARI
0.6994957
无监督学习 聚类分析②相关推荐
- 机器学习(二)之无监督学习:数据变换、聚类分析
文章目录 0 本文简介 1 无监督学习概述 2 数据集变换 2.1 预处理和缩放 2.2 程序实现 2.3 降维.特征提取与流形学习 2.3.1 主成分分析 2.3.2 非负矩阵分解 2.3.3 用t ...
- 易百教程人工智能python修正-人工智能无监督学习(聚类)
无监督机器学习算法没有任何监督者提供任何指导. 这就是为什么它们与真正的人工智能紧密结合的原因. 在无人监督的学习中,没有正确的答案,也没有监督者指导. 算法需要发现用于学习的有趣数据模式. 什么是聚 ...
- 【采用】无监督学习在反欺诈中的应用
一.反欺诈技术的发展历程 反欺诈技术的的发展经历了四个阶段,第一阶段黑名单.信誉库和设备指纹:第二阶段规则系统:第三阶段有监督的机器学习:第四阶段无监督的大数据欺诈检测.目前来说,前三种还是大家应用最 ...
- [Python人工智能] 十五.无监督学习Autoencoder原理及聚类可视化案例详解
从本专栏开始,作者正式研究Python深度学习.神经网络及人工智能相关知识.前一篇文章详细讲解了循环神经网络LSTM RNN如何实现回归预测,通过sin曲线拟合实现如下图所示效果.本篇文章将分享无监督 ...
- 使用Scikit-learn,Spotify API和Tableau Public进行无监督学习
I will also walk through the OSEMN framework for this machine learning example. The acronym, OSEMN, ...
- 机器学习中的无监督学习_无监督机器学习中聚类背后的直觉
机器学习中的无监督学习 When it comes to analyzing & making sense of the data from the past and understandin ...
- 机器学习之无监督学习——聚类
机器学习之无监督学习--聚类 无监督学习 一.基于划分的聚类方法 1.基于划分的方法 简介 A.概念 B.分组 C.分组与样本 对应关系 D.硬聚类 与 软聚类 二.基于层次的聚类方法 1.基于层次的 ...
- 机器学习集群_机器学习中的多合一集群技术在无监督学习中应该了解
机器学习集群 Clustering algorithms are a powerful technique for machine learning on unsupervised data. The ...
- 技术+案例详解无监督学习Autoencoder
摘要:本篇文章将分享无监督学习Autoencoder的原理知识,然后用MNIST手写数字案例进行对比实验及聚类分析. 本文分享自华为云社区<[Python人工智能] 十五.无监督学习Autoen ...
最新文章
- 【Java基础】多线程
- redhat 5.6下网卡冗余实验
- Elastic AMP监控.NET程序性能
- scala和java像不像_关于Java和Scala同步的五件事你不知道
- Openfire插件开发
- ge linux安装apt_教你如何在 Linux 中使用 apt 命令
- 重构:如何去掉代码中的S味
- 用户如何设置浏览器主页的历史记录和管理加载项
- pythonxy官网下载_spyder安装包
- PMI-ACP敏捷项目认证练习题(四)
- python 报错“xxx is not defined”
- python里offset啥意思_深度理解Jquery 中 offset() 方法
- 服务器修复划痕,【DIY】自己动手修复屏幕划痕及建议
- 多功能运算求解器_matlab中bsxfun函数
- Stegsolve.jar工具包准备,避坑指南,教你正确启动Stegsolve
- 证明技巧I——反证法
- windows优化大师怎么用_win7系统提示未能连接一个windows服务如何解决【详解】
- WuThreat身份安全云-TVD每日漏洞情报-2023-05-30
- U盘系统盘恢复成普通U盘
- 【自然语言处理】潜在语义分析【下】概率潜在语义分析