Scrapy爬取豆瓣影评
爬虫爬取了500条豆瓣网站的影评网页,25部电影,每部20条。每个网页中提取了影评的电影名称、影评作者、评论时间、影评标题、网页的url和影评的具体内容。爬虫的实现使用了Scrapy框架。Scrapy框架是一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化数据。
爬虫的项目文件目录如下图所示。(movie被不小心敲成了moview 捂脸。。)
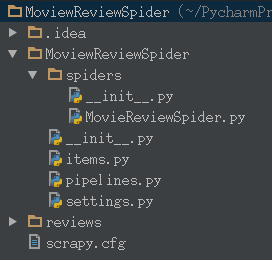
其中scrapy.cfg是项目的配置文件,MovieReviewSpider文件夹是项目的Python模块,代码会从这个文件夹中导入。这个文件夹中的spiders文件夹是放置Spider的目录,items.py是项目的Items文件,pipeline.py是项目的管道文件,settings.py是项目的配置文件。
爬虫的实现步骤如下:
1、定义Item类,Item是将要抓取的数据的容器,工作方式像Python中的字典。在本项目中,需要定义MoviewreviewspiderItem类继承自scrapy.Item类,类中包含movie、writer、time、title、url、content六个属性,用来存储网页上要爬取的电影名称、影评作者、评论时间、影评标题、网页的url和影评的具体内容
2、定义Spider类,Spider包含三部分内容:下载的URL的初步列表、如何跟踪链接和如何解析这些网页的内容用于提取items。在本项目中定义了name属性、allowed_domains属性、start_urls属性、headers属性、start_requests方法、parse_link方法和parse_review方法。
- 设置name属性为moviereview。name是爬虫的识别名,必须是唯一的,不同的爬虫中必须定义不同的名字。
- 设置start_urls属性,在里面放起始的25个电影的网址。start_urls是爬虫开始爬的一个URL列表,爬虫从这里开始抓取数据。
- 设置headers属性,设置本机浏览器访问豆瓣网站时给我们添加的头信息。在浏览器中手动访问豆瓣网站时,浏览器会自动为我们添加很多信息,而现在在程序访问网站,如果不加上头信息,豆瓣网站就会拒绝程序对它的访问。
- 定义start_request方法,在这个方法中实现循环访问每一个start_urls中的URL,并设置访问URL后的回调函数为parse_link方法。
- 定义parde_link方法,在这个方法中用xpath选择器提取访问的URL页面中的影评链接,这些影评链接是要进一步爬取的网页。设置回调函数为parse_review方法,进一步访问该网页中影评链接所指向的网页。
- 定义parse_review方法,在这个方法中用xpath提取网页中的电影名称、影评作者、评论时间、影评标题、网页的url和影评的具体内容信息,并用这些信息来实例化MoviewreviewspiderItem对象。
- 在提取具体内容信息时,需要用re模块中的sub方法来清洗影评的内容。因为这些内容中可能含有单引号和双引号,本程序最后要把这些信息以json形式存储。如果不清洗,引号会破坏json数据的格式。
- 最后yield item对象,scrapy框架会在pipeline中处理这些item对象。
3、定义Itme Pipeline类,将爬下来的数据存储成utf-8编码的json文件。当Item在Spider中收集之后,它会被传递到Item Pipeline,这个类中必须定义process_item()方法。
- 定义__init()__方法,在这个里面写一个global型的全局变量,用记录item对象的个数,并用它来作为json的文件。
- 定义process_item()方法,在这个方法中调用codecs模块的open方法以utf-8编码打开reviews文件夹中的文件,文件名用global变量做为文件名,然后将item中的内容写到文件中,再将global变量的值加1。
- 定义spider_close方法,在这个方法中关闭打开的文件。
4、在settings.py文件中配置Item Pipeline。
最后在终端中进入项目的根目录,运行命令scrapy crawl moviereview即可执行爬虫,在reviews文件夹中可以得到json文件。
转载于:https://my.oschina.net/u/3041591/blog/793625
Scrapy爬取豆瓣影评相关推荐
- python爬取豆瓣影评生成词云的课程设计报告_Python爬取豆瓣影评,生成词云图,只要简单一步即可实现。...
最近看了一部电影<绣春刀>,里面的剧情感觉还不错,本文爬取的是绣春刀电影的豆瓣影评,1000个用户的短评,共5W多字.用jieba分词,对词语的出现频率进行统计,再通过wordcloud生 ...
- 爬虫实战2(上):爬取豆瓣影评
这次我们将主要尝试利用python+requsets模拟登录豆瓣爬取复仇者联盟4影评,首先让我们了解一些模拟登录相关知识补充.本文结构如下: request模块介绍与安装 get与post方式介 ...
- python爬取豆瓣电影top250_【Python3爬虫教程】Scrapy爬取豆瓣电影TOP250
今天要实现的就是使用是scrapy爬取豆瓣电影TOP250榜单上的电影信息. 步骤如下: 一.爬取单页信息 首先是建立一个scrapy项目,在文件夹中按住shift然后点击鼠标右键,选择在此处打开命令 ...
- python爬取豆瓣影评_【python爬虫实战】爬取豆瓣影评数据
概述: 爬取豆瓣影评数据步骤: 1.获取网页请求 2.解析获取的网页 3.提速数据 4.保存文件 源代码: # 1.导入需要的库 import urllib.request from bs4 impo ...
- #私藏项目实操分享#Python爬虫实战,requests+xpath模块,Python实现爬取豆瓣影评
前言 利用利用requests+xpath爬取豆瓣影评,废话不多说. 让我们愉快地开始吧~ 开发工具 Python版本:3.6.4 相关模块: requests模块: jieba模块: pandas模 ...
- Python爬虫实战,requests+xpath模块,Python实现爬取豆瓣影评
前言 利用利用requests+xpath爬取豆瓣影评,废话不多说. 让我们愉快地开始吧~ 开发工具 **Python版本:**3.6.4 相关模块: requests模块: jieba模块: pan ...
- 朴素贝叶斯情感分析评分python_「豆瓣影评」从爬取豆瓣影评到基于朴素贝叶斯的电影评论情感分析(上) - seo实验室...
豆瓣影评 一.爬取豆瓣影评 基本思路:先获取每个电影的评论区链接,然后依次进入其评论区爬取评论.选取10部电影,每部200条评论. 用到的包为:BeautifulSoup,urllib 这里选取的链接 ...
- 从爬取豆瓣影评到基于朴素贝叶斯的电影评论情感分析(上)
一.爬取豆瓣影评 基本思路:先获取每个电影的评论区链接,然后依次进入其评论区爬取评论.选取10部电影,每部200条评论. 用到的包为:BeautifulSoup,urllib 这里选取的链接为:豆瓣电 ...
- 用python爬取豆瓣影评及影片信息(评论时间、用户ID、评论内容)
爬虫入门:python爬取豆瓣影评及影片信息:影片评分.评论时间.用户ID.评论内容 思路分析 元素定位 完整代码 豆瓣网作为比较官方的电影评价网站,有很多对新上映影片的评价,不多说,直接进入正题. ...
最新文章
- 钉钉日志范文100篇_看图写话范文328:暑假旅行(4篇)
- LINUX DHCP搭建
- 话里话外:项目部如何不再形同虚设
- Spring MVC原理学习之how is return type handled
- Sublime Text官方文档 中英文版本
- Java之递归遍历目录,修改指定文件的指定内容
- 进程控制块PCB(进程描述符)
- 【BZOJ1085】骑士精神
- SVN1.6.5详细配置
- Android做的第一个小程序
- 【转】Windows Phone在隔离存储里存取图片文件
- ccf中文期刊目录_37本!中国计算机学会CCF首次发布推荐中文科技期刊目录
- python无限弹窗1.0
- 《生命》第五集:Birds (鸟类)
- ipad文献管理软件_ipad和电脑双向同步文献的奥秘
- 线性代数:如何求特征值和特征向量
- 小红书数据平台:2022年5月彩妆行业数据洞察报告
- pip命令卸载所有库
- NOIP2012 提高组初赛试题讲解
- 物联网开发笔记(64)- 使用Micropython开发ESP32开发板之控制ILI9341 3.2寸TFT-LCD触摸屏进行LVGL图形化编程:控件显示
热门文章
- 基于tensorflow、keras利用emnist数据集构建CNN卷积神经网络进行手写字母识别
- nrf51822微信---AES加密
- [收集]什么是父表和子表
- 论书法艺术在包装设计中的运用
- oracle 判断高水位,修正ORACLE表的高水位线HWM
- F28335第五篇——EALLOW和EDIS
- 非科班、无实习、拿到腾讯华为提前批offer,C++学习路线及项目分享
- Springboot 分布式会话 io.lettuce.core.RedisCommandExecutionException: NOAUTH Authentication required
- create-react-app项目打包后遇到问题
- Cadence每日一学_04 | 使用OrCAD创建简单元器件(原理图)库