计量经济学复习笔记(一):一元线性回归(上)
计量经济学复习笔记(一):一元线性回归(上)
在本文中,我们将对回归的基本概念作出解释,介绍相关分析与因果分析之间的差异;辨析总体回归函数、总体回归模型、样本回归函数、样本回归模型之间的关系,了解我们的工作是从样本推断总体,用样本回归函数来预测总体回归函数。最后,对回归中最简单的一元线性回归模型作出介绍,并给出参数估计的方法。
文章目录
- 计量经济学复习笔记(一):一元线性回归(上)
- 1、什么是回归
- 2、回归的基本概念
- 3、一元线性回归模型
- 4、一元线性回归模型参数估计
1、什么是回归
在数学上,回归指的是研究一组随机变量和另一组随机变量之间关系的统计方法,这句话包含的意义有两个。一是回归的研究主体是两组随机变量,在实际生活中,研究的对象往往来自于某个总体中的样本;我们知道,样本具有两重性,在观测之前是一个服从总体分布的随机变量,观测之后就是一个定值,因此我们的回归对象往往是一堆观测记录。二是回归揭示的是关系,这种关系可能是确定的函数关系,也可能是不确定的相关关系,且往往是不确定的;不论是哪种关系,回归总蕴含着某种“因果”,即一个变量的变化会是影响另一个变量变化的原因。
关于如何看待这样的因果关系,我们来作一个假设。现在我们得到了某个关系式:
Y = f ( X ) + μ . Y=f(X)+\mu. Y=f(X)+μ.
这里 Y Y Y是一个随机变量, X X X是一个随机向量, f f f是已知且确定的随机向量函数, μ \mu μ是模型所包含的不可控误差。如果我们想让 Y Y Y提升,如果因果关系成立,我们就会通过改变 X X X的取值以增加 f ( X ) f(X) f(X)的值,也就是说 X X X是关系到 Y Y Y变动的成因。但如果因果关系不成立,我们改变了 X X X的值就不会对 Y Y Y的值造成影响,而是推翻这个关系式。
典型的例子是夏季儿童溺死数与雪糕售卖数的关系,夏季儿童溺死数会与雪糕售卖数同步增加,但我们能不能为了减少儿童溺死数而控制雪糕的销量?显然是不可以的,如果我们强行减少了雪糕售卖数,儿童溺死数也不可能减少,这样的关系会被打破。
因此,为了使我们得到的模型不仅具有预测能力,还具有解释能力,我们都要求回归分析的变量之间存在一定的依赖关系。这时候,因变量 Y Y Y又被称为被解释变量,自变量 X X X被称为解释变量。
在 Y Y Y与 X X X之间存在的关系往往多种多样,这也导致回归函数是多种多样的,但由于我们不可能找到世界上所有的回归函数形式,我们只能找一些常用的函数类,通过改变它们的参数来达到合适的回归效果。常用的回归函数有线性回归、多项式回归、指数回归、对数回归、Logistic回归等,其中以线性回归的形式最为简单,因此我们从线性回归开始讨论起是合适的。
2、回归的基本概念
在第一节中,我们提到,回归的研究对象是某个总体,这个总体往往非常非常大,以至于我们只能从其中抽取样本进行研究,从样本推测总体性质。但是,由于我们希望获得的是能反映总体的变量间关系式,我们需要假定这样的关系式是存在的。
现在我们假设一个有一个总体,其中的每一个个体 ω \omega ω都具有两个具有因果关系的属性 ( Y , X ) (Y,X) (Y,X),这里 X X X是 Y Y Y的影响因素。我们想探究的是如何通过变化 X X X来影响 Y Y Y,自然要找到 Y , X Y,X Y,X之间的一个回归关系,如果给定 X X X,我们会认为 Y Y Y的什么值最有可能出现?概率论知识告诉我们——条件期望就是给定 X X X情况下的最佳预测,即
f ( X ) = E ( Y ∣ X ) . f(X)=\mathbb E(Y|X). f(X)=E(Y∣X).
如果我们能找到每一个给定 X X X水平下 Y Y Y的条件期望,就找到了 Y Y Y关于 X X X的一个最佳联系式,我们称这样的 f ( X ) f(X) f(X)为总体回归函数。由于随机性,每一个具有相同 X X X水平的个体也不可能有同样的 Y Y Y,因此,称
μ = Y − E ( Y ∣ X ) \mu=Y-\mathbb E(Y|X) μ=Y−E(Y∣X)
为观察值 Y Y Y围绕其期望值的离差,也被称为随机误差项或随机干扰项。
但,由于总体往往大到无法遍历,我们自然不会知道总体的分布函数,也就求不了条件期望,即直接获得总体回归函数是不可能的。无法获得总体回归函数,自然也不可能得到 μ \mu μ的观测值,因此离差 μ \mu μ是一个不可观测的随机变量。习惯上,我们称 E ( Y ∣ X ) \mathbb E(Y|X) E(Y∣X)是 Y Y Y的系统性部分, μ \mu μ是 Y Y Y的随机性部分,这就构成了总体回归模型:
Y = E ( Y ∣ X ) + μ . Y=\mathbb E(Y|X)+\mu. Y=E(Y∣X)+μ.
既然总体回归函数和误差都不可观测,我们就只能利用数理统计的知识,通过样本估计总体。通过从总体中抽取某些样本,观察它围绕在哪一个函数附近,这个函数就称作样本回归函数,记作
Y ^ = f ^ ( X ) . \hat Y=\hat f(X). Y^=f^(X).
有没有发现这里的 Y Y Y上面加上了一顶帽子?这表明,通过这个式子 f ^ \hat f f^算出来的值并不是给定 X X X后真正的 Y Y Y值,而是通过样本观测得到的函数,近似认为给定 X X X的情况下 Y Y Y离这个值比较近而已。当然,不管多近, Y Y Y与 Y ^ \hat Y Y^之间总有差距,这个差距 μ ^ = e = Y − Y ^ \hat\mu=e=Y-\hat Y μ^=e=Y−Y^就称为残差,加上残差以后,就得到了样本回归模型:
Y = f ^ ( X ) + μ ^ . Y=\hat f(X)+\hat \mu. Y=f^(X)+μ^.
会不会感觉有点绕?其实只要区分以下六个概念就好了:
- 总体回归函数(population regression function)、总体回归模型(population regression model)、随机误差(stochastic error);
- 样本回归函数(sample regression function)、样本回归模型(sample regression model)、残差(residual)。
如何区分呢?首先,区分总体与样本的关键,就在于这个东西是基于总体计算的还是基于样本计算的,由于总体不可观测,总体回归函数、总体回归模型只是“理论上”存在的,但我们不可能直接观测它是什么样的,而是只能通过样本估计总体,而基于样本计算出的,就是样本回归函数或样本回归模型了。其次,区分函数与模型,关键就在于随机误差/残差,即实际的总体往往不表现为确定的函数关系,不可能代入 X X X就能得到精准的 Y Y Y,回归模型中允许了这样的误差存在,而回归函数就是用于计算预测值的工具。
现在就留下了一个问题——如何通过抽取的样本来计算样本回归函数呢?直接凭感觉画一条线拟合,既主观又难以测量,而且不精准,所以我们需要基于数学推导,给出通过样本估计总体的方式。
3、一元线性回归模型
现在我们要转向样本回归函数(SRF)的计算上了。之前我们提到过,回归函数的形式多种多样,我们总要依赖于一些函数类,通过调整参数得到样本回归函数,而线性回归函数就是最简单的一种回归函数类。特别当我们只有一个被解释变量 Y Y Y和一个解释变量 X X X的情况下,SRF是一元线性回归函数,对应的回归模型是一元线性回归模型。一元线性回归模型总可以用这样的形式表示:
Y = β 0 + β 1 X + μ . Y=\beta_0+\beta_1X+\mu. Y=β0+β1X+μ.
注意,这是总体回归模型,也就是说我们假定总体满足 E ( Y ∣ X ) = β 0 + β 1 X \mathbb E(Y|X)=\beta_0+\beta_1X E(Y∣X)=β0+β1X,这样处理的好处就是,我们从茫然地估计总体,简化成了估计两个待估参数 β 0 , β 1 \beta_0,\beta_1 β0,β1,问题得到大大简化。
对参数进行点估计就成了数理统计中的问题,但如果不对模型加以约束,我们就不知道有关于分布的任何信息,从而无从下手。这里,我们暂时搁置对一元线性回归的基本假设问题,我们将在多元线性回归中详细讨论它,所以现在我们只提出必要的、关于分布的假设。
假设从总体中抽取的总体为 ( X i , Y i ) , i = 1 , ⋯ , n (X_i,Y_i),i=1,\cdots,n (Xi,Yi),i=1,⋯,n,随机误差项为 μ i \mu_i μi,则我们一般不考虑 X X X的分布信息,只作如下的要求:
- E ( μ i ∣ X ) = 0 , D ( μ i ∣ X ) = σ 2 \mathbb E(\mu_i|X)=0,\mathbb D(\mu_i|X)=\sigma^2 E(μi∣X)=0,D(μi∣X)=σ2,这表明在任何 X X X的水平下,随机误差项都是一个零均值、同分布序列。这条性质也暗含了 E μ i = 0 , D μ i = σ 2 \mathbb E\mu_i=0,\mathbb D\mu_i=\sigma^2 Eμi=0,Dμi=σ2。
- C o v ( μ i , μ j ∣ X ) = 0 {\rm Cov}(\mu_i,\mu_j|X)=0 Cov(μi,μj∣X)=0如果 i ≠ j i\ne j i=j,这表明在任何 X X X的水平下,随机误差项序列不相关。这条性质也暗含了 C o v ( μ i , μ j ) = 0 {\rm Cov}(\mu_i,\mu_j)=0 Cov(μi,μj)=0。
- C o v ( μ i , X ) {\rm Cov}(\mu_i,X) Cov(μi,X),这表明随机误差项与自变量不存在任何形式的相关性。
- μ i ∣ X ∼ N ( 0 , σ 2 ) \mu_i|X\sim N(0,\sigma^2) μi∣X∼N(0,σ2),这表明在任何 X X X的水平下, μ i \mu_i μi都服从正态分布。
实际上,正态分布的要求是为了更好的区间估计而提出的,这也说明随机误差项总体 μ ∼ N ( 0 , σ 2 ) \mu\sim N(0,\sigma^2) μ∼N(0,σ2),每一次观测都可以视为从这个总体抽取独立同分布 (i.i.d.) \text{(i.i.d.)} (i.i.d.)样本,因此,总体 Y Y Y在给定 X X X的情况下可以确定分布:
Y ∣ X ∼ N ( β 0 + β 1 X , σ 2 ) . Y|X\sim N(\beta_0+\beta_1X,\sigma^2). Y∣X∼N(β0+β1X,σ2).
我们的任务依然是根据样本的情况估计参数,此时需要估计的参数就是 β 0 , β 1 , σ 2 \beta_0,\beta_1,\sigma^2 β0,β1,σ2,从而确定 Y Y Y在给定 X X X的水平时的分布。
4、一元线性回归模型参数估计
最典型的参数估计方法是普通最小二乘法(OLS),我们也只介绍这种方法而不考虑矩法估计、极大似然估计。
最小二乘法的思想在高中就已经接触过,我们需要找到一个拟合函数,使得所有点到拟合函数的误差平方和尽可能小,利用微积分的方法可以很容易地得到这个拟合函数的形态。假设符合要求的拟合函数是
Y ^ = β ^ 0 + β ^ 1 X , \hat Y=\hat\beta_0+\hat\beta_1X, Y^=β^0+β^1X,
则点 i i i到 Y ^ i \hat Y_i Y^i的误差平方是
( Y i − Y ^ i ) 2 = [ Y i − ( β ^ 0 + β ^ 1 X i ) ] 2 , (Y_i-\hat Y_i)^2=[Y_i-(\hat\beta_0+\hat\beta_1X_i)]^2, (Yi−Y^i)2=[Yi−(β^0+β^1Xi)]2,
所有点的误差平方和就是
Q = ∑ i = 1 n [ Y i − ( β ^ 0 + β ^ 1 X i ) ] 2 . Q=\sum_{i=1}^n[Y_i-(\hat\beta_0+\hat\beta_1X_i)]^2. Q=i=1∑n[Yi−(β^0+β^1Xi)]2.
我们的目标是找到一组参数 β ^ 0 , β ^ 1 \hat\beta_0,\hat\beta_1 β^0,β^1使得 Q Q Q最小,由多元函数求极值的方法,只要让偏导数为零即可,也就是
∂ Q ∂ β ^ 0 = ∑ i = 1 n ( − 2 ) ⋅ [ Y i − ( β ^ 0 + β ^ 1 X i ) ] = 0 , ∂ Q ∂ β ^ 1 = ∑ i = 1 n ( − 2 X i ) ⋅ [ Y i − ( β ^ 0 + β ^ 1 X i ) ] = 0. \frac{\partial Q}{\partial\hat\beta_0}=\sum_{i=1}^n(-2)\cdot[Y_i-(\hat\beta_0+\hat\beta_1X_i)]=0,\\ \frac{\partial Q}{\partial \hat\beta_1}=\sum_{i=1}^n(-2X_i)\cdot[Y_i-(\hat\beta_0+\hat\beta_1X_i)]=0. ∂β^0∂Q=i=1∑n(−2)⋅[Yi−(β^0+β^1Xi)]=0,∂β^1∂Q=i=1∑n(−2Xi)⋅[Yi−(β^0+β^1Xi)]=0.
也就是
( n ∑ i = 1 n X i ∑ i = 1 n X i ∑ i = 1 n X i 2 ) ( β ^ 0 β ^ 1 ) = ( ∑ i = 1 n Y i ∑ i = 1 n X i Y i ) , \begin{pmatrix} n & \sum\limits_{i=1}^nX_i\\ \sum\limits_{i=1}^nX_i & \sum\limits_{i=1}^nX_i^2 \end{pmatrix}\begin{pmatrix} \hat\beta_0 \\ \hat\beta_1 \end{pmatrix}=\begin{pmatrix} \sum\limits_{i=1}^n Y_i \\ \sum\limits_{i=1}^nX_iY_i \end{pmatrix}, ⎝⎜⎛ni=1∑nXii=1∑nXii=1∑nXi2⎠⎟⎞(β^0β^1)=⎝⎜⎛i=1∑nYii=1∑nXiYi⎠⎟⎞,
解得
β ^ 0 = ∑ i = 1 n Y i ∑ i = 1 n X i 2 − ∑ i = 1 n X i ∑ i = 1 n X i Y i n ∑ i = 1 n X i 2 − ( ∑ i = 1 n X i ) 2 , β ^ 1 = n ∑ i = 1 n X i Y i − ∑ i = 1 n X i ∑ i = 1 n Y i n ∑ i = 1 n X i 2 − ( ∑ i = 1 n X i ) 2 . \hat\beta_0=\frac{\sum\limits_{i=1}^nY_i\sum\limits_{i=1}^nX_i^2-\sum\limits_{i=1}^nX_i\sum\limits_{i=1}^nX_iY_i}{n\sum\limits_{i=1}^nX_i^2-\left(\sum\limits_{i=1}^nX_i \right)^2}, \hat\beta_1=\frac{n\sum\limits_{i=1}^nX_iY_i-\sum\limits_{i=1}^nX_i\sum\limits_{i=1}^nY_i}{n\sum\limits_{i=1}^nX_i^2-\left(\sum\limits_{i=1}^nX_i \right)^2}. β^0=ni=1∑nXi2−(i=1∑nXi)2i=1∑nYii=1∑nXi2−i=1∑nXii=1∑nXiYi,β^1=ni=1∑nXi2−(i=1∑nXi)2ni=1∑nXiYi−i=1∑nXii=1∑nYi.
这个式子看起来十分麻烦,为了化简这个式子,引入中心化这个概念。以下记 X ˉ \bar X Xˉ为 X i X_i Xi的样本均值, Y ˉ \bar Y Yˉ为 Y i Y_i Yi的样本均值, x i = X i − X ˉ , y i = Y i − Y ˉ x_i=X_i-\bar X,y_i=Y_i-\bar Y xi=Xi−Xˉ,yi=Yi−Yˉ,这样, β ^ 1 \hat\beta_1 β^1可以被改写成
β ^ 1 = n ∑ i = 1 n X i Y i − ∑ i = 1 n X i ∑ i = 1 n Y i n ∑ i = 1 n X i 2 − ( ∑ i = 1 n X i ) 2 = n ∑ i = 1 n ( X i − X ˉ ) ( Y i − Y ˉ ) + n 2 X ˉ Y ˉ − n 2 X ˉ Y ˉ n ∑ i = 1 n ( X i − X ˉ ) 2 + n 2 X ˉ 2 − n 2 X ˉ 2 = ∑ i = 1 n x i y i ∑ i = 1 n x i 2 = d e f ∑ x i y i ∑ x i 2 . \begin{aligned} \hat\beta_1=&\frac{n\sum\limits_{i=1}^nX_iY_i-\sum\limits_{i=1}^nX_i\sum\limits_{i=1}^nY_i}{n\sum\limits_{i=1}^nX_i^2-\left(\sum\limits_{i=1}^nX_i \right)^2}\\ =&\frac{n\sum\limits_{i=1}^n(X_i-\bar X)(Y_i-\bar Y)+n^2\bar X\bar Y-n^2\bar X\bar Y}{n\sum\limits_{i=1}^n(X_i-\bar X)^2+n^2\bar X^2-n^2\bar X^2}\\ =&\frac{\sum\limits_{i=1}^nx_iy_i}{\sum\limits_{i=1}^n x_i^2}\xlongequal{\rm def}\frac{\sum x_iy_i}{\sum x_i^2}. \end{aligned} β^1===ni=1∑nXi2−(i=1∑nXi)2ni=1∑nXiYi−i=1∑nXii=1∑nYini=1∑n(Xi−Xˉ)2+n2Xˉ2−n2Xˉ2ni=1∑n(Xi−Xˉ)(Yi−Yˉ)+n2XˉYˉ−n2XˉYˉi=1∑nxi2i=1∑nxiyidef ∑xi2∑xiyi.
很神奇地, β ^ 1 \hat\beta_1 β^1被简化了很多。而
Y i = β ^ 0 + β ^ 1 X i + e i , ∑ i = 1 n Y i = n β ^ 0 + β ^ 1 ∑ i = 1 n X i + ∑ i = 1 n e i , ⇓ n Y ˉ = n β ^ 0 + n β ^ 1 X ˉ + ∑ i = 1 n e i . Y_i=\hat\beta_0+\hat\beta_1X_i+e_i,\\ \sum_{i=1}^nY_i=n\hat\beta_0+\hat\beta_1\sum_{i=1}^nX_i+\sum_{i=1}^ne_i,\\ \Downarrow \\ n\bar Y=n\hat\beta_0+n\hat\beta_1\bar X+\sum_{i=1}^ne_i. Yi=β^0+β^1Xi+ei,i=1∑nYi=nβ^0+β^1i=1∑nXi+i=1∑nei,⇓nYˉ=nβ^0+nβ^1Xˉ+i=1∑nei.
注意到 ∑ i = 1 n e i = ∑ i = 1 n [ Y i − ( β ^ 0 + β ^ 1 X i ) ] \sum_{i=1}^n e_i=\sum_{i=1}^n[Y_i-(\hat\beta_0+\hat\beta_1X_i)] ∑i=1nei=∑i=1n[Yi−(β^0+β^1Xi)]恰好是OLS过程中的第一个式子,所以
n Y ˉ = n β ^ 0 + n β ^ 1 X ˉ , β ^ 0 = Y ˉ − β ^ 1 X ˉ . n\bar Y=n\hat\beta_0+n\hat\beta_1\bar X,\\ \hat\beta_0=\bar Y-\hat\beta_1\bar X. nYˉ=nβ^0+nβ^1Xˉ,β^0=Yˉ−β^1Xˉ.
这样我们就得到了运用中心化数据,求参数估计的简化方法。
由本节的推导内容,我们知道了如何由一系列数据建立回归方程,现在就举个例子试试。下表是中国某地区部分男性的身高体重数据,尝试建立线性回归模型。
| 身高 X i X_i Xi(cm) | 体重 Y i Y_i Yi(kg) | |
|---|---|---|
| 1 | 163 | 60 |
| 2 | 164 | 56 |
| 3 | 165 | 60 |
| 4 | 167 | 55 |
| 5 | 168 | 60 |
| 6 | 169 | 54 |
| 7 | 170 | 79 |
| 8 | 170 | 64 |
第一步,求出身高和体重的均值:这里 X ˉ = 167 , Y ˉ = 61 \bar X=167,\bar Y=61 Xˉ=167,Yˉ=61。
第二步,求出离差相关数据,并计算求和
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | ∑ \sum ∑ | |
|---|---|---|---|---|---|---|---|---|---|
| ( X i − X ˉ ) 2 (X_i-\bar X)^2 (Xi−Xˉ)2 | 16 | 9 | 4 | 0 | 1 | 4 | 9 | 9 | 52 |
| ( X i − X ˉ ) ( Y i − Y ˉ ) (X_i-\bar X)(Y_i-\bar Y) (Xi−Xˉ)(Yi−Yˉ) | 4 | 15 | 2 | 0 | -1 | -14 | 54 | 9 | 69 |
第三步,计算参数估计值,得到
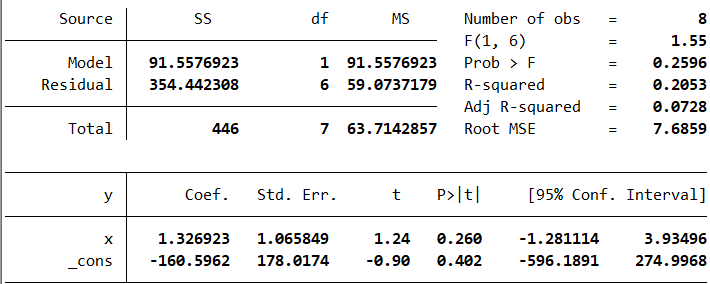
β ^ 1 = 1.3269 , β ^ 0 = − 160.5923. Y ^ = − 160.5923 + 1.3269 X . \hat\beta_1=1.3269,\quad \hat\beta_0=-160.5923.\\ \hat Y=-160.5923+1.3269X. β^1=1.3269,β^0=−160.5923.Y^=−160.5923+1.3269X.
通过软件验算,这是正确的回归结果(观察x和_cons的值)。
本文的内容就到此为止了,但是还有许多需要解决的问题,比如:我们需要估计的参数是三个——两个回归系数以及一个方差,但是方差应该如何估计呢?在我们的推导过程中,似乎没有用到随机误差项的正态假定,这个假定对我们的工作有什么贡献?软件计算给出的结果中,除了能够直接阅读的回归系数,其他参数又是什么意思?
在之后的学习中,我们将对这些问题一一作出回答。
计量经济学复习笔记(一):一元线性回归(上)相关推荐
- 《计量经济学》学习笔记之一元线性回归模型
注意:本笔记以文字概括为主,公式为辅,问为啥,因为贴图片和打公式对于我来说,太烦啦~所以,就只把每个章节里觉得重要的一些概念记下来. 书籍:<计量经济学(第三版)>–李子奈 导航 下一章: ...
- 计量经济学复习笔记(四)updated2.0!
终于进入回归了regression! 回归就是探究因变量和自变量的相关关系 因变量,就是y,又被称为被解释变量,回归子,相应变量 自变量,就是x,又被称为解释变量,回归元,控制变量 根据变量个数可以将 ...
- 计量经济学复习笔记(六)updated
接下来就可以很快地把Chapitre4过掉了 先是多变量线性回归模型的栗子,看课件就好了,没什么重要的. 必须强调,类似于柯布道格拉斯生产函数的非线性函数我们也可以将其对数化弄成参数线性的. 然后是偏 ...
- java 一元线性回归_算法笔记:一元线性回归及Java实现
这是voidAlex原创的第四篇博文. 源码在我的GitHub 回归问题 回归问题是研究自变量和因变量之间关系的一种预测模型技术.例如我们可以通过回归模型去预测房价与房子面积之间的关系,一个人每周花在 ...
- 计量经济学复习笔记(1)
考研炸了,期末考不能炸!!!对付拖延症的最好方法就是找一个push的压力 每天两更!4天攻下计量! 首先我们首先要明白几个公式 假设A和B均为独立变量则有 E(X+Y)=E(X)+E(Y) E(X+ ...
- 一元线性回归决定系数_回归分析|笔记整理(1)——引入,一元线性回归(上)...
大家好! 新学期开始了,不知道大家又是否能够适应新的一学期呢?先祝所有大学生和中小学生开学快乐! 本学期我的专业课是概率论,回归分析,偏微分方程,数值代数,数值逼近,金融时间序列分析,应用金融计量学和 ...
- 《计量经济学》学习笔记之多元线性回归模型
导航 上一章:一元线性回归模型 下一章:放宽基本假定的模型 文章目录 导航 3.1多元线性回归模型 一.多元线性回归模型 二.多元线性回归的基本假设 3.2多元线性回归模型的参数估计 四.参数统计量的 ...
- 二、简单线性回归模型(计量经济学学习笔记)
研究经济变量之间相互数量关系最基本的方法之一是回归分析. ①回归分析与回归函数 1.1相关分析与回归分析 1.1.1函数关系与相关关系 经济变量之间的相互依存关系有两种:1.确定性的函数关系 2.不确 ...
- 机器学习公开课笔记(1):机器学习简介及一元线性回归
初步介绍 监督式学习: 给定数据集并且知道其正确的输出应该是怎么样的,即有反馈(feedback),分为 回归 (Regressioin): map输入到连续的输出值. 分类 (Classificat ...
最新文章
- 关于float的说明
- ADO.NET 中的表达式
- sql server 2005 T-SQL CEILING (Transact-SQL)
- char data[0]用法总结
- mysql增加sort_buffer_MySQL数据库之MySQL中的sort_buffer_size参数大小的设置问题
- Cent OS 重置root密码
- 【渝粤教育】国家开放大学2018年春季 8662-22T特色课(1) 参考试题
- 用报表工具Style Report制作排名前N名的分组报表
- Java:日期类Date与Calendar
- VMP2.0版本带壳调试教程
- python-机器学习的两种传统算法-knn,k-means
- 准确生成电信、联通、移动IP地址段
- ASU计算机科学专业大学排名,2013美国大学排名_计算机科学专业研究生排名
- 如何快速融入一个研发团队?
- Ubuntu12.04软件安装指南
- STM32工程文件的建立以及Keil软件的基本设置和修改
- python简易版爬虫
- ajax瀑布流加载重叠,使用瀑布流插件masonry,图片未加载完就会出现重叠现象,怎么解决?...
- 数字孪生地铁设备管理系统方案
- 1 spss基本使用