Spark 数据挖掘 - 利用决策树预测森林覆盖类型
Spark 数据挖掘—利用决策树预测森林覆盖类型
1 前言
预测问题记住一点:最垃圾的预测就是使用平均值,如果你的预测连比直接给出平均值效果都要差,那就省省吧!
统计学诞生一个多世纪之后,随着现在机器学习和数据科学的产生,我们依旧使用回归的思想来进行预测,尽管回归 就是用平均值向后不断回滚来预测。回归的技术和分类的技术紧密相关。通常情况下,当目标变量是连续数值时指的是回归,例如预测 身高和体重。当预测的目标变量是名义或者说是类别变量时,指的就是分类,例如预测邮件是否是垃圾邮件。
无论是分类还是回归,都需要给定已知信息去预测未知信息,所以它们都需要从输入输出来学习。它们需要包括问题和答案。这类算法因此也称为监督学习的方法。
回归和分类是使用年代最近研究的最充分的预测分析技术。很多算法开源包都包含通用的这些方法。比如:支持向量机,逻辑回归,朴素贝叶斯,神经网络和深度学习。
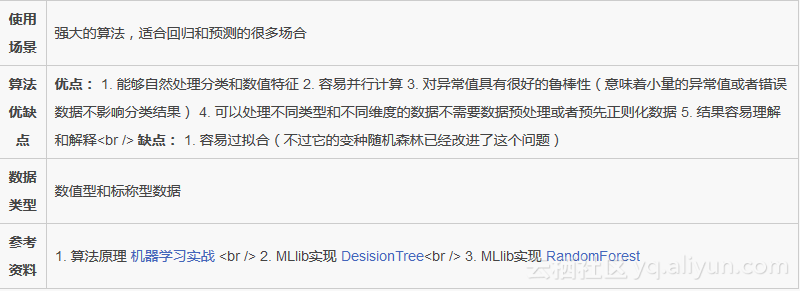
本文的重点是讨论:决策树和它的扩展随机森林。决策树是通用而且灵活的分类回归算法。
2 一些基本概念
注意:特别小心分类变量(尤其是那些用数字表示的分类变量,不要随便放到算法中去训练)和数值变量
注意:不是所有的算法都能处理分类变量,或者都能处理回归分类问题,但是放心决策树都可以
3 算法简介
决策树

4 数据集
本文将使用著名的 Covtype 数据集合,可以在 http://bit.ly/1KiJRfg 这里下载。下载之后是一个压缩的 csv 文件, linux 用户可以用命令:tar -xzvf 解压缩,windows用户可以使用 .7-zip 解压缩,同时下载数据集的描述文件 covtype.info 数据集记录的是美国 Colorado 植被覆盖类型数据,也是唯一一个关心真实森林的数据。每条记录都包含很多指标描述每一块土地。 例如:高度、坡度、到水的距离、树荫下的面积、土壤的类型等等。森林的覆盖类型是需要根据其他54个特征进行预测的特征。 这是一个有趣的数据集,它包含分类和数值特征。总共有581012条记录。每条记录有55列,其中一列是土壤的类型,其他54列是输入特征。 虽然这个数据集还不能算得上真正的大数据,但是也能说明很多问题。很幸运,这个数据集已经是csv文件,所以不需要太多的数据清洗或者其他的准备就可以给 Spark Mllib 使用。 数据集可上传到 HDFS,当然也可以先放到本地进行这个有趣的测试。不管哪种方式,Spark 都只需要改变一两个参数。 这里不得不再次提醒一个问题,分类变量如何编码,下面是编码的方式:
一个合适的编码方式是:one-hot 或者 1 of n 编码 一个分类变量:编码为 n(分类特征个数)个变量
另一种编码方式:就是给每个值一个固定的数字,例如: 1, 2, 3, ..., n
当算法中把编码当作数字的时候只能使用第一种编码,第二种编码会得出滑稽的结果。具体原因是没有大小的东西被强制成有大小之分。
Covtype 数据集中有很多类型的特征,不过很幸运,它已经帮我们转换成 one-hot 形势,具体来说:
11到14列,其实表示的是 Wilderness_Area,Wilderness_Area 本身有 4 个类别
15到54列,其实表示的是 Soil_Type,Soil_Type 本身有 40个属性值
55列是表示目标值,当然它不需要表示成为 one-hot形式。
这个数据集每一列的变量单位都不一定相同,有的表示距离,有的表示度数等等
5 Spark 决策树模型
下面给出一个初步的利用Spark MLlib 实验的决策树模型,具体的意图,代码都有详细的注释:
//本地测试val rootDir = "your sample data directory"def main(args: Array[String]) {val conf = new SparkConf().setAppName("SparkInAction").setMaster("local[4]")val sc = new SparkContext(conf)val covTypeData = sc.textFile(rootDir + "/covtype.data")val data = dataPrepare(covTypeData)//选择测试集合和训练集合val Array(train, cvData, test) =data.randomSplit(Array(0.8, 0.1, 0.1))train.cache()cvData.cache()test.cache()val model = buildDecisionTree(train, cvData)}/*** Spark MLlib 表示特征向量的对象是 LabeledPoint* 这个对象由表示特征的向量和目标变量组成*/def dataPrepare(data: RDD[String]) = {val sample = data.map{line =>//全部数据转化为 doubleval array = line.split(",").map(_.toDouble)//前面54列是特征向量,后面一列是目标变量 labelval featureVector = Vectors.dense(array.init)//决策树目标变量必须从0开始,按照1递增LabeledPoint(array.last - 1, featureVector)}sample}/*** 决策树模型建立,这里很容易改进为十择交叉验证。* 对每一份数据建立模型时,都需要随机选出部分数据来调整模型参数到最优。* 通过交叉验证的方式调整参数。* @param train* @param cvData*/def buildDecisionTree(train: RDD[LabeledPoint], cvData: RDD[LabeledPoint]) = {def getMetrics(model: DecisionTreeModel, data: RDD[LabeledPoint]) = {val predictionsAndLabels = data.map {example =>(model.predict(example.features), example.label)}new MulticlassMetrics(predictionsAndLabels)}val model = DecisionTree.trainClassifier(train, 7, Map[Int, Int](), "gini", 4, 100)val matrics = getMetrics(model, cvData)println(matrics.confusionMatrix)(0 until 7).map(cat => (matrics.precision(cat), matrics.recall(cat))).foreach(println)}这个是初步的运行结果:
#整体的准确率和召回率
(0.7012384971978136,0.7012384971978136)
#每一个类别的准确率和召回率
(0.685108051158916,0.6668097486526446)
(0.7255299659774928,0.7930627570177007)
(0.6194455768446799,0.8685338668190912)
(0.3771043771043771,0.39436619718309857)
(0.55,0.011727078891257996)
(0.0,0.0)
(0.7174657534246576,0.4134188455846078)70%的准确率和召回率似乎效果还不错,但是我们现在不能盲目的认为我们的效果就真的不错了,有时候瞎猜效果也会不错。 例如:70%的数据属于类别1,每次都猜测类别是1,那么效果也能达到70%的准确率,下面我们确定一下瞎猜的准确率: 回答瞎猜猜对的概率,这个问题也不是简单的,回到概率论课堂上,在训练样本每类概率已知的情况下,测试样本瞎猜对的概率有多大呢? 随机给出一个样本:猜测类A的概率是由训练样本决定的,同时猜对的概率是由测试样本决定的,所以瞎猜猜对的概率是训练样本每类的概率分别 乘以测试样本对应类的概率之和
/*** 获取模型瞎猜的概率* @param train 测试数据集* @param cvData 验证数据集*/def guessProb(train: RDD[LabeledPoint], cvData: RDD[LabeledPoint]) {/*** 返回数据集合中,每一个类别的概率* @param data 训练数据集*/def labelProb(data: RDD[LabeledPoint]): Array[Double] = {val labelCnt = data.map(_.label).countByValue()val labelProb = labelCnt.toArray.sortBy(_._1).map(_._2)labelProb.map(_.toDouble/labelProb.sum)}val trainProb = labelProb(train)val cvProb = labelProb(cvData)val prob = trainProb.zip(cvProb).map {case (a, b) => a * b}.sumprintln(prob)}可以看到瞎猜的结果只有:0.3771281350885772 的准确率。说明70%的准确率效果确实不错,但是请注意,我们还没有优化参数, 说明我们的模型还有优化的空间。
6 决策树参数选择
主要的参数有下面几个:
- Maximum Depth: 决策树树的最大深度,控制深度防止过拟合
- 决策树训练算法迭代最大次数
- 纯度测量算法 Gini Entropy (Gini纯度和熵) 通过反复查看不同参数模型评估效果,下面给出测试代码:
/*** 模型评估* @param trainData 训练数据* @param cvData 交叉验证数据*/def evaluate(trainData: RDD[LabeledPoint], cvData: RDD[LabeledPoint]): Unit = {val evaluations =for (impurity <- Array("gini", "entropy");depth <- Array(1, 20);bins <- Array(10, 300))yield {val model = DecisionTree.trainClassifier(trainData, 7, Map[Int,Int](), impurity, depth, bins)val predictionsAndLabels = cvData.map(example =>(model.predict(example.features), example.label))val accuracy =new MulticlassMetrics(predictionsAndLabels).precision((impurity, depth, bins), accuracy)}evaluations.sortBy(_._2).reverse.foreach(println)}文章转载自 开源中国社区[https://www.oschina.net]
Spark 数据挖掘 - 利用决策树预测森林覆盖类型相关推荐
- 徒手写代码之《机器学习实战》-----决策树算法(2)(使用决策树预测隐形眼镜类型)
使用决策树预测隐形眼镜类型 说明: 将数据集文件 'lenses.txt' 放在当前文件夹 from math import log import operator 熵的定义 "" ...
- 决策树(四):使用决策树预测隐形眼镜类型
使用决策树预测隐形眼镜类型 介绍 代码部分 总结 介绍 本节我们将通过一个例子讲解决策树如何预测患者需要佩戴的隐形眼镜类型.使用小数据集 ,我们就可以利用决策树学到很多知识:眼科医生是如何判断患者需要 ...
- ID3构造决策树预测隐形眼镜类型(代码笔记)
决策树可以从数据集合中提取出一系列规则,从而分类样本.它的优势是理解数据蕴含信息. 思想:利用信息增益(information gain)[度量数据集信息的方式-香农熵(entropy)]计算得出最好 ...
- 《机器学习实战》学习笔记:绘制树形图使用决策树预测隐形眼镜类型
上一节实现了决策树,但只是使用包含树结构信息的嵌套字典来实现,其表示形式较难理解,显然,绘制直观的二叉树图是十分必要的.Python没有提供自带的绘制树工具,需要自己编写函数,结合Matplotlib ...
- 03_使用决策树预测隐形眼镜类型
使用决策树预测隐形眼镜类型 1.实验描述 使用Python编程,输入为隐形眼镜数据集,计算所有可能的特征的信息增益,选择最优的特征值划分数据集,进而递归地构建决策树.其中为了更加直观地呈现决策树,使用 ...
- matlab隐形眼镜类型预测,【实现】利用决策树推荐隐形眼镜类型
背景介绍:根据患者眼部状况的观察条件,利用决策树来向患者推荐隐形眼镜的类型. 1. 收集数据 数据集来自于UCI数据库的隐形眼镜数据集. 数据格式 2. 准备数据 解析tab键分割的数据行.def r ...
- Educoder 机器学习 决策树使用之使用决策树预测隐形眼镜类型
任务描述 相关知识 如何处理隐形眼镜数据集 编程要求 测试说明 任务描述 本关任务:编写一个例子讲解决策树如何预测患者需要佩戴的隐形眼镜类型.使用小数据集,我们就可以利用决策树学到很多知识:眼科医生是 ...
- 机器学习实战ch03: 使用决策树预测隐形眼镜类型
决策树的一般流程 1.收集数据 2.准备数据:树构造算法只适用标称型数据,因此数据值型数据必须离散化 3.分析数据 4.训练算法 5.测试数据 6.使用算法 决策树的优点 1.数据形式非常容易理解 2 ...
- 【python和机器学习入门2】决策树3——使用决策树预测隐形眼镜类型
参考博客:决策树实战篇之为自己配个隐形眼镜 (po主Jack-Cui,<--大部分内容转载自 参考书籍:<机器学习实战>--第三章3.4 <--决策树基础知识见前两篇 , 摘要 ...
最新文章
- apache日志设置方法:按时间、按大小记录
- 利用递归、迭代解决斐波那契数列问题与汉诺塔难题
- npm ERR! code ELIFECYCLE
- qt 二维数组初始化_第十九章、C语言学习之数组3
- 美国本科计算机科学,美国本科计算机科学就业情况分析
- 被冻结的钱,银行可以私自处理吗?
- Windows Server Version 1709 管理之入门篇 1
- springboot yml对于list列表配置方式
- Maven常用命令汇总
- HBase 数据模型(Data Model)
- Codeforces - F. Dominant Indices
- VirusTotal智能搜索安卓样本示例
- 2018年腾讯实习生招聘模拟笔试:硬币组合-个人思路及代码
- 计算机文件只读模式,电脑文件只读模式如何修改 – 手机爱问
- Deep Graph Kernels
- Windows显卡切换
- 今日头条搜索应该怎么做?头条搜索SEO排名和信息流排名课程
- JavaScript DOM加强(佟刚)
- FC金手指代码大全·持续更新-亲测可用-FC 经典游戏完整可用的金手指大全---持续更新,偶尔玩玩经典回味无穷,小时候不能通关的现在通通通关一遍
- 不可错过的年度AI学术盛会 2021新一代人工智能院士高峰论坛暨启智开发者大会议程惊喜发布~