cs61b学习记录(四)Trie、KDTree、Prim、Dijkstra、Kruskul
cs61b学习记录(四)
Lecture21、Prefix Operations and Tries
- Balanced Search Tree:
contains(x): Θ(logN)add(x): Θ(logN)
- Resizing Separate Chaining Hash Table:
contains(x): Θ(1) (assuming even spread)add(x): Θ(1) (assuming even spread and amortized)
We can see that the implementations for operations associated with Sets and Maps are extremely fast.
But if we knew a special characteristic of the keys,we can do better.
For example if we always know our keys are ASCII characters then instead of using a general-purpose HashMap, simply use an array where each character is a different index in our array

By knowing the range of our keys as well as what types of values they will be we have a simple and efficient data structure. Now we have created something for characters, what about strings?
Trie
Tries are a very useful data structure used in cases where keys can be broken into “characters” and share prefixes with other keys (e.g. strings)
当我们存储一些可以被切分成“字符”的键时(比如string),由于很多键的前缀相同,如果像之前的map或BST一样,每个键单独存储,会存储很多重复的字符,造成空间的浪费和查找缓慢。所以,如果这些键可以共享前缀,我们就针对string这个数据类型的BST结构做出了改进,创造出了另一个针对string的高效的数据结构:Tire
Suppose we had a set containing “sam”, “sad”, “sap”, “same”, “a”, and "awls“.An important observation to make is that most of these words share the same prefixes, therefore we can utilize these similarly structured strings for our structure. In other words we don’t store the same prefixes (e.g. “sa-”) multiple times.

Tries work by storing each ‘character’ of our keys as a node. Keys that share common prefixes share the same nodes. To check if the trie contains a key, walk down the tree from the root along the correct nodes.
Since we are going to share nodes, we must figure out some way to represent which strings belong in our set and which don’t. We will solve this problem through marking the color of the last character of each string to be blue.
To search, we will traverse our trie and compare to each character of the string as we go down. Thus, there are only two cases when we wouldn’t be able to find a string
- the final node is white
- we fall off the tree.

我们通常可以通过指定数据类型,添加约束条件来改进通用的数据结构。比如,当我们限制键的类型为character时,就可以对hashmap进行改进,从而创造一个非常高效的数据结构。
综上,Trie的规则是:
- 每个string对象的字符单独存储,共享相同的前缀,重复的前缀只存储一次
- 每个string的末尾的字符标记为特殊颜色,以区分该string是否包含于当前的set
- 搜索时从根节点向下,比较每一个经过的字符节点,直到最终的节点为白色,或者没有符合条件的节点。


Trie的查找操作:
单词查找树中的每个结点都包含了下一个可能出现的所有字符的链接。从根结点开始,首先经过的是键的首字母所对应的链接;在下一个结点中沿着第二个字符所对应的链接继续前进;在第二个结点中沿着第三个字符所对应的链接向前,如此这般直到到达键的最后一个字母所指向的结点或是遇到了一条空链接。这时可能会出现以下3种情况:
- 键的尾字符所对应的结点中的值非空。这是一次命中的查找,键所对应的值就是键的尾字符所对应的结点中保存的值。
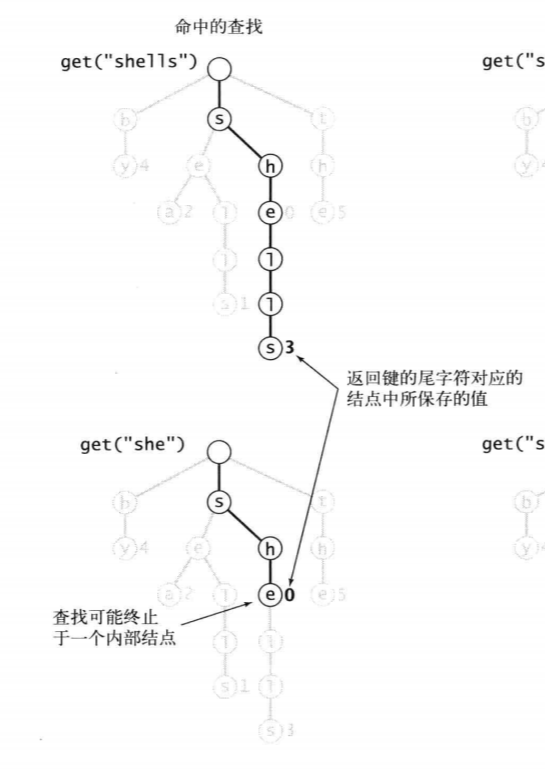
- 键的尾字符所对应的结点中的值为空。这是一次未命中的查找,符号表中不存在被查找的键。

查找结束于一条空链接。这也是一次未命中的查找。

对于DataIndexedCharMap的实现来说,查找实际分为两种情况:
- 没有遇到空链接,将对应的节点的值直接返回,如果是null就说明查找失败,否则查找成功
- 遇到空链接,查找失败,直接返回
插入操作:
和二叉查找树一样,在插入之前要进行一次查找,在单词查找树中意味着沿着被查找的键的所有字符到达树中
- 表示尾字符的结点
- 或者一个空链接
此时可能会出现以下两种情况:
- 在到达键的尾字符之前就遇到了一个空链接。在这种情况下,字符查找树中不存在与键的尾字符对应的结点,因此需要为键中还未被检查的每个字符创建一个对应的结点并将键的值保存到最后一个字符的结点中。
- 在遇到空链接之前就到达了键的尾字符。在这种情况下,和关联性数组样, 将该结点的值设为键所对应的值(无论该值是否为空)
对于DataIndexedCharMap的实现来说,插入实际是如下的过程:
沿着Trie向下找
如果没有遇到空链接,将要查找的字符串与每个节点一一对比,不需要进行对比,直接沿着树向下找
如果遇到空链接,就将字符串剩下的字符转换成节点,插入到Trie的后面
直到要查找的字符串到达末尾,将要插入的值直接赋给当前节点的value属性
Implementation
我们为单词查找树所绘出的图像和在程序中构造的数据结构并不完全一致,因为我们没有画出空链接。将空链接考虑进来将会突出单词查找树的以下重要性质:
- 每个结点都含有R个链接,对应着每个可能出现的字符;
- 字符和键均隐式地保存在数据结构中。
我们可以知道,Trie中每个节点都连接了多个字符节点,现在的问题是,我们该如何存储这些字符节点?如何确保查找指定字符节点的速度?
对于BST,它每个节点最多只有两个子节点,它的查找只需要和当前节点判断大小即可。而对于Tire来说,每个节点可能至多有128个子节点!我们如果要一个一个地查找,效率将会非常低下。既然我们知道每个节点都是字符,那么我们可以使用 DataIndexedCharMap 来存储子节点。

R是 DataIndexedCharMap中的数组大小,也就是数组中可能存储的字符的范围。如果是存的是ASCII字符集,R就是128。

The DataIndexedCharMap object, will have mostly null links if nodes in our tree have relatively few children. This means that we are wasting a lot of excess space
![]()
这个数据结构不会保存任何字符串或字符,它保存了链接数组和值。因为参数R的重要性,所以将基于含有R个字符的字母表的Tire称为R向单词查找树。
public class Trie<Value> {private static int R = 256;private Node root;private static class Node {private Object val;private Node[] next = new Node[R];}public Value get(String key) {Node x = get(key, root, 0);if (x==null) return null;return (Value) x.val;}private Node get(String key, Node x,int index) {if (x == null) return null;//index是字符串中下一个要比较的下标,也就是说,当前要比较的下标就是字符串的末尾//此时字符串除了最后一个字符,其他的都已经比较完了//现在,这个字符存在两种状态:是或不是//如果是,就返回该字符对应的值,如果不是,就返回null,所以不需要进行判断if (index == key.length()) {return x;}return get(key, x.next[key.charAt(index)], index + 1);}public void put(String key, Value value) {root = put(key, value, root, 0);}//put先查找,如果沿途中的字符与key中的字符一一对应,那么把value赋值给最后一个节点//如果在查找时遇到了空节点,那么将key中剩下的字符继续接下去,然后再将value赋值给最后一个节点private Node put(String key, Value value, Node x, int index) {if (x==null) x = new Node();if (index == key.length()) {x.val = value;return x;}char c=key.charAt(index);x.next[c] = put(key, value, x.next[c], index + 1);return x;}
Alternate child tracking strategy



Tries will especially thrive with some special operations.
Trie String Operations
Recall all of the comparisons that we’ve made between Tries and other data structures. We can see that Tries offer us constant time lookup and insertion theoretically, but they don’t actually perform better than BSTs or Hash Tables。 For every string we have to traverse through every character, whereas in BSTs we have access to the entire string immediately.
所以Tire的真正作用是一些BST和hashMap无法执行的字符串操作。
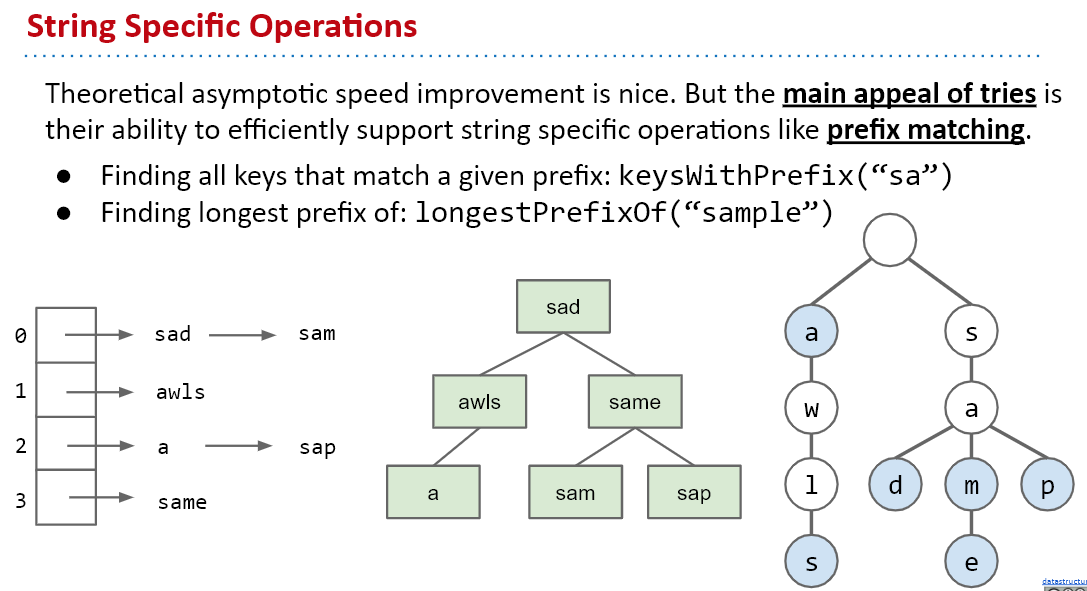
DataIndexedCharMap实现:
查找所有键:
我们将所有字符串键保存在一个队列( Queue)里。我们用一个类似于size()的私有递归方法collect()来完成这个任务,它维护了一个字符串用来保存从根结点出发的路径上的一系列字符。每当我们在collect()调用中访问一个结点时,方法的第一个参数就是该结点,第二个参数则是和该结点相关联的字符串(从根结点到该结点的路径上的所有字符)。
- 在访问一个结点时,如果它的值非空,我们就将和它相关联的字符串加入队列之中,然后( 递归地)访问它的链接数组所指向的所有可能的字符结点。
- 如果它的值为空,那么不将字符串加入队列,然后继续访问它的链接数组所指向的所有可能的字符节点
- 如果某一个字符节点为空,那么结束对这条路的访问。
在每次调用之前,都将链接对应的字符附加到当前键的末尾作为调用的参数键。
API中的keys()和keysWithPrefix()方法使用这个collect()方法收集符号表中所有的键。
- 要实现keysWithPrefix()方法,可以先调用get()找出给定前缀所对应的单词查找树(如果不存在则返回null),再使用collect()方法完成任务。
- 要实现keys()方法,可以以空字符串作为参数调用keysWithPrefix()方法。
![]()
public Iterable<String> keys() {return keyWithPrefix("");}public Iterable<String> keyWithPrefix(String s) {Queue<String> queue = new LinkedList<>();collect(get(s, root, 0), s, queue);return queue;}private void collect(Node x, String pre, Queue<String> queue) {if (x == null) return;if (x.val != null) queue.offer(pre);for (int i = 0; i < R; i++) {collect(x.next[i], pre + (char) i, queue);}}
最长前缀:
为了找到给定字符串的最长键前缀,就需要使用一个类似于get()的递归方法。它会记录查找路径上所找到的最长键的长度(将它作为递归方法的参数在遇到值非空的结点时更新它)。查找会在被查找的字符串结束或是遇到空链接时终止。
public String longestPrefixOf(String s) {int length = search(root, s, 0, 0);return s.substring(0, length);}private int search(Node x, String s, int index, int length) {if (x == null ) return length;if (x.val != null) length = index;if (index == length) return length;return search(x.next[s.charAt(index)], s, index + 1, length);}
删除操作:
从一棵单词查找树中删去一个键值对的第一步是, 找到键所对应的结点并将它的值设为空null。如果该结点含有一个非空的链接指向某个子结点,那么就不需要在进行其他操作了。如果它的所有链接均为空,那就需要从数据结构中删去这个结点。如果删去它使得它的父结点的所有链接也均为空,就需要继续删除它的父结点,依此类推。根据标准递归流程,这项操作所需的代码极少:在递归删除了某个结点x之后,如果该结点的值和所有的链接均为空则返回null,否则返回x。
public void delete(String key) {root = delete(root, key, 0);}private Node delete(Node x, String key, int index) {if (x==null) return null;//index实际上是下一次的下标if (index == key.length()) {x.val = null;}else{char c = key.charAt(index);x.next[c] = delete(x.next[c], key, index + 1);}//如果本身是非空节点,则不需要再删除,直接返回自己if (x.val != null)return x;//如果本身是空节点,那么如果是树的末尾的话需要将该节点删除//也就是说,如果该节点有非空链接,就可以不用删除//如果该节点全部都是空链接,就需要删除for (Node n : x.next)if (n != null) return x;return null;}
不要使用该算法处理来自于大型字母表的大量长键。它所构造的单词查找树所需要的空间与R和所有键的字符总数之积成正比。但是,如果你能够负担得起这么庞大的空间,单词查找树的性能是无可匹敌的。
HashTable实现:
public class Trie<Value> {private static int R = 256;private Node root;private static class Node {private Object val;private Map<Character, Node> next = new HashMap<>();}public Value get(String key) {Node x = get(key, root, 0);if (x==null) return null;return (Value) x.val;}private Node get(String key, Node x,int index) {if (x == null) return null;//index是字符串中下一个要比较的下标,也就是说,当前要比较的下标就是字符串的末尾//此时字符串除了最后一个字符,其他的都已经比较完了//现在,这个字符存在两种状态:是或不是//如果是,就返回该字符对应的值,如果不是,就返回null,所以不需要进行判断if (index == key.length()) {return x;}return get(key, x.next.get(key.charAt(index)), index + 1);}public void put(String key, Value value) {root = put(key, value, root, 0);}//put先查找,如果沿途中的字符与key中的字符一一对应,那么把value赋值给最后一个节点//如果在查找时遇到了空节点,那么将key中剩下的字符继续接下去,然后再将value赋值给最后一个节点private Node put(String key, Value value, Node x, int index) {if (x==null) x = new Node();if (index == key.length()) {x.val = value;return x;}char c=key.charAt(index);x.next.put(c, put(key, value, x.next.get(c), index + 1));return x;}public Iterable<String> keys() {return keyWithPrefix("");}public Iterable<String> keyWithPrefix(String s) {Queue<String> queue = new LinkedList<>();collect(get(s, root, 0), s, queue);return queue;}private void collect(Node x, String pre, Queue<String> queue) {if (x == null) return;if (x.val != null) queue.offer(pre);for (Map.Entry<Character, Node> entry : x.next.entrySet()) {collect(entry.getValue(), pre + entry.getKey(), queue);}}public String longestPrefixOf(String s) {int length = search(root, s, 0, 0);return s.substring(0, length);}private int search(Node x, String s, int index, int length) {if (x == null ) return length;if (x.val != null) length = index;if (index == s.length()) return length;return search(x.next.get(s.charAt(index)), s, index + 1, length);}public void delete(String key) {root = delete(root, key, 0);}private Node delete(Node x, String key, int index) {if (x==null) return null;//index实际上是下一次的下标,也就是字符串到了最后一个字符,查找到了所在位置,将值置为空if (index == key.length()) {x.val = null;}//如果字符串还没有匹配完,继续对下一个字符进行匹配else{//index指向下一次要匹配的字符下标char c = key.charAt(index);//将链接重置x.next.put(c, delete(x.next.get(c), key, index + 1));}//匹配完成,将当前节点的值置为null之后,对多余的节点进行删除//要求:树的叶结点的val必须存在//如果本身的val非空,则不需要再删除,直接返回自己if (x.val != null)return x;//如果本身的val为空,那么是否需要删除则取决于是不是叶结点//也就是说,如果该节点有非空链接,就可以不用删除//如果该节点全部都是空链接,就需要删除if (!x.next.isEmpty()) return x;return null;}
}
Lecture22、Range Searching and Multi-Dimensional Data
KDtree:
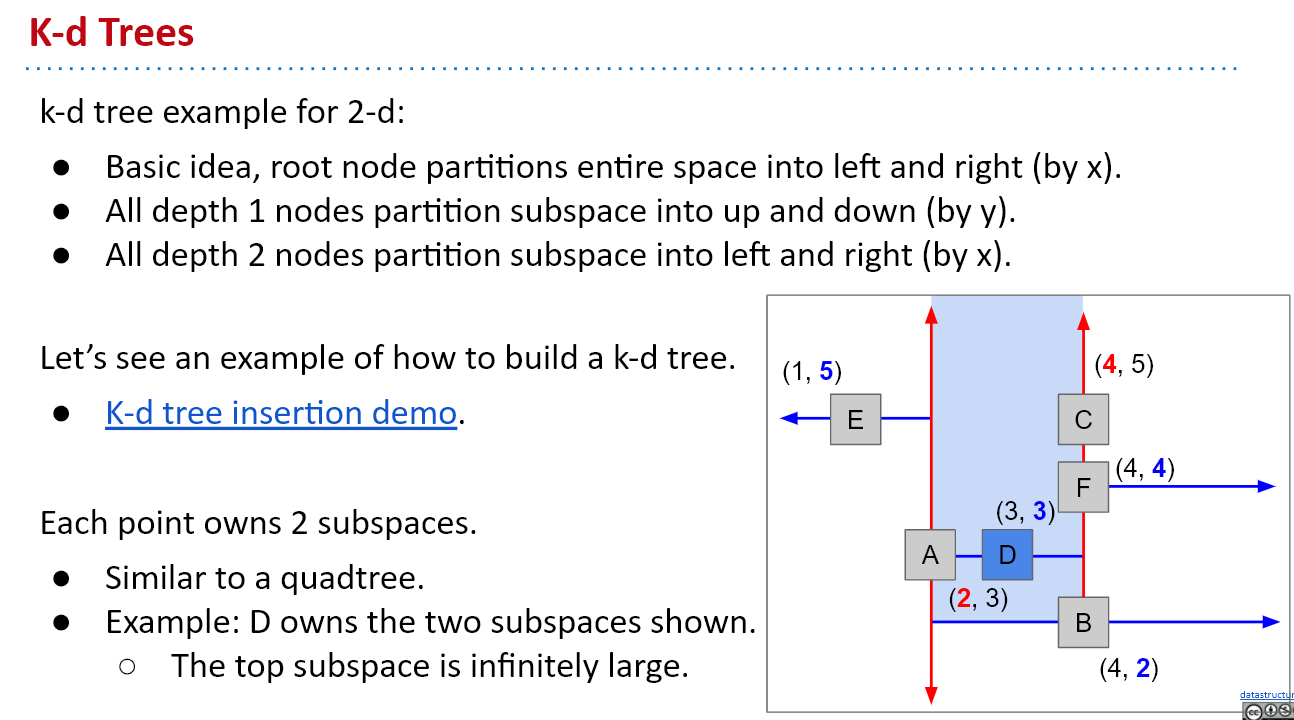
类似BST,KDtree的每个节点的属性分为左节点和右节点,左边是小于当前节点的点,右边是大于当前节点的点。对于2维及以上的KDtree,树的每一层的比较规则都不同。比如对于2维的KDtree,根节点的使用x比较,深度为1的节点使用y比较,深度为2的节点使用x比较,以此类推。我们规定等于的点属于右节点。
KDtree Insertion Demo
Nearest Neighbor:
对于每一个点,首先朝着它的good side搜索,并且动态更新距目标点的最优距离以及记录最近的节点。一直探索到某一点的good side为空时,开始回溯,根据每一点的bad side范围中距离目标点最近的距离与当前的最优距离的对比情况决定是否对bad side进行探索。如果小于最优距离,则需要探索。如果大于最优距离,则不需要探索,继续回溯。如此直到回到根节点,探索完毕。
K-d tree nearest demo

当在递归函数中需要使用动态变化的值时,比如像上图的best,在每一次递归调用中都有可能被修改,同时下一次递归调用还需要该变量。一种做法是将它设置为全局变量,每次使用时进行修改,需要时直接拿来用,但是这样太丑了。我们可以选择在函数参数中传递该变量,这样,下一次递归调用就能使用到该变量。对于同时还需要在递归回溯时使用的变量,我们还需要将该变量作为函数的返回值,每一次函数调用以
def func(var1,var2,x)if(...)return x...some operations to x....x=func(var1,var2,x)return x
的形式进行。这样,我们在每一个函数调用中对变量的改变,下一次函数调用都能收到,并且在该函数中对变量的值进行更新。
Lecture23、Tree and Graph Traversals
What is a tree:
- A set of nodes (or vertices). We use both terms interchangeably.
- A set of edges that connect those nodes.
- Constraint: There is exactly one path between any two nodes.
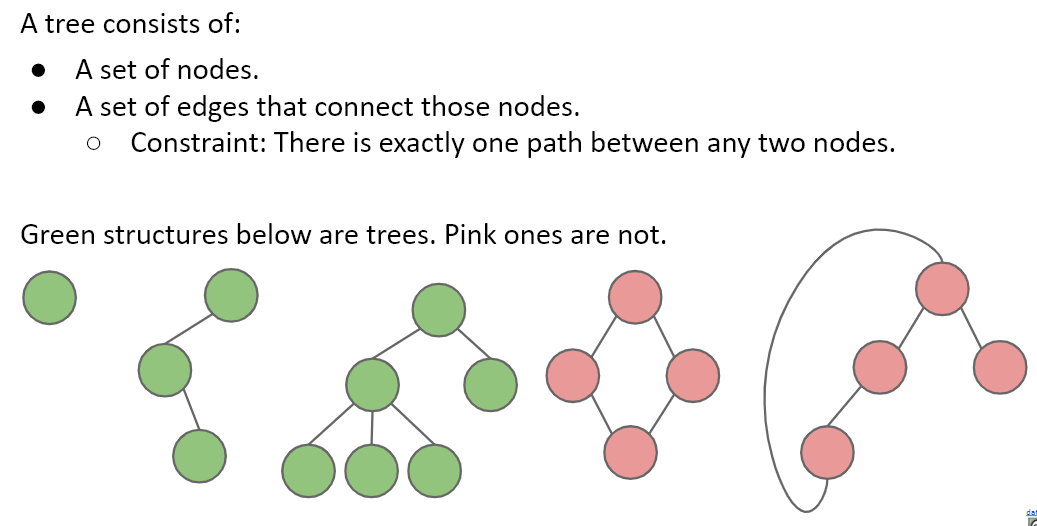
Tree Iteration Traversal
everyone calls iteration through trees 'traversals‘,So what are some natural ways to ‘traverse’ through a tree?
Level order traversal:
Visit top-to-bottom, left-to-right
Depth-First traversals:
- pre-order
- in-order
- post-order.


先序遍历的应用:
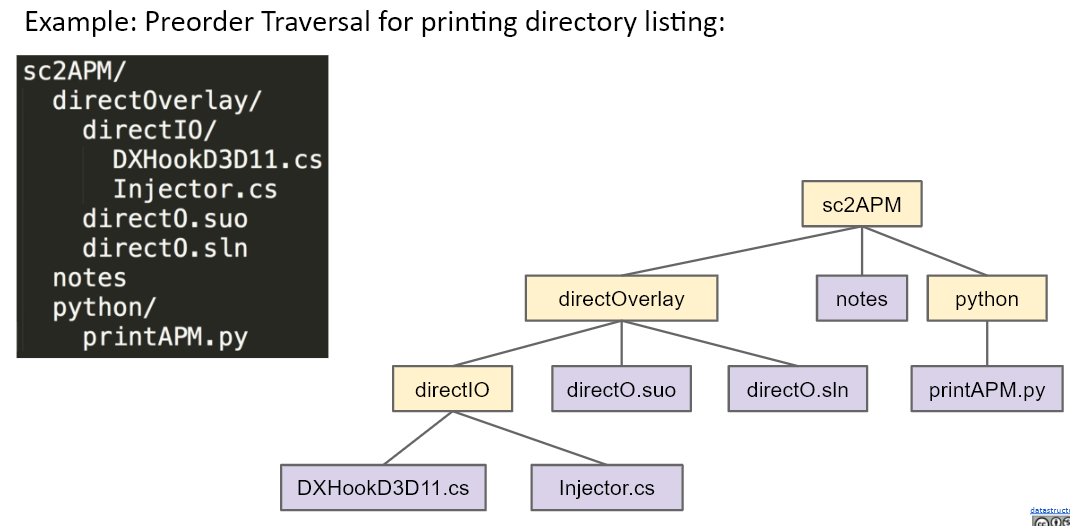
后序遍历的应用:求出文件的大小,我们需要先获得子节点的大小,才能算出父节点的大小。所以使用先访问所有子节点,再访问父节点的后序遍历。
Graphs
![]()
我们使用邻接表来表示图:
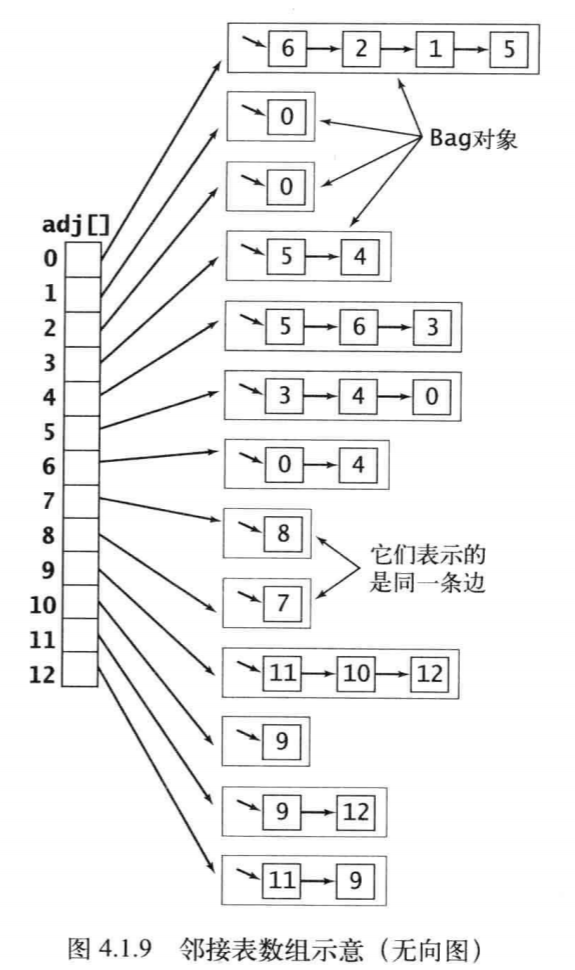
非稠密图的标准表示为邻接表,它将每个顶点的所有相邻顶点都保存在该顶点对应的元素所指向的一张链表中。我们使用这个数组就是为了快速访问给定顶点的邻接顶点列表。对于无向图,要添加一条连接v与w的边,我们将w添加到v的邻接表中并把v添加到w的邻接表中。因此,在这个数据结构中每条边都会出现两次。
Graph:
public class Graph {private int V;private int E;private List<Integer>[]adj;public Graph(int v){this.V=v;this.E=0;adj=(List<Integer>[])new ArrayList[V];//一共V个点,序号是0~V-1for (int i=0;i<V;i++){adj[i]=new ArrayList<>();}}public Graph(){Scanner input=new Scanner(System.in);int n=input.nextInt();for (int i=0;i<n;i++){int x=input.nextInt();int y=input.nextInt();addEdge(x,y);}}public void addEdge(int v,int W){//无向图,增加两次adj[v].add(W);adj[W].add(v);E++;}public int V(){return V;}public int E(){return E;}public Iterable<Integer>adj(int V){return adj[V];} }
In general, note that all trees are also graphs, but not all graphs are trees.
simple graph:

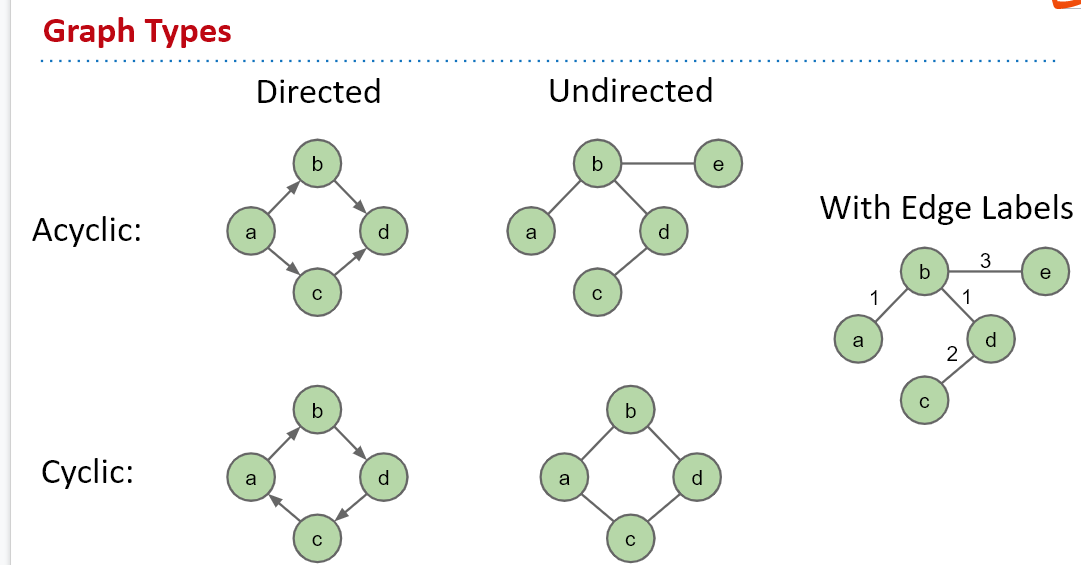
- s-t Path: Is there a path between vertices s and t?
- Connectivity: Is the graph connected, i.e. is there a path between all vertices?
- Biconnectivity: Is there a vertex whose removal disconnects the graph?
- Shortest s-t Path: What is the shortest path between vertices s and t?
- Cycle Detection: Does the graph contain any cycles?
- Euler Tour: Is there a cycle that uses every edge exactly once?
- Hamilton Tour: Is there a cycle that uses every vertex exactly once?
- Planarity: Can you draw the graph on paper with no crossing edges?
- Isomorphism: Are two graphs isomorphic (the same graph in disguise)?
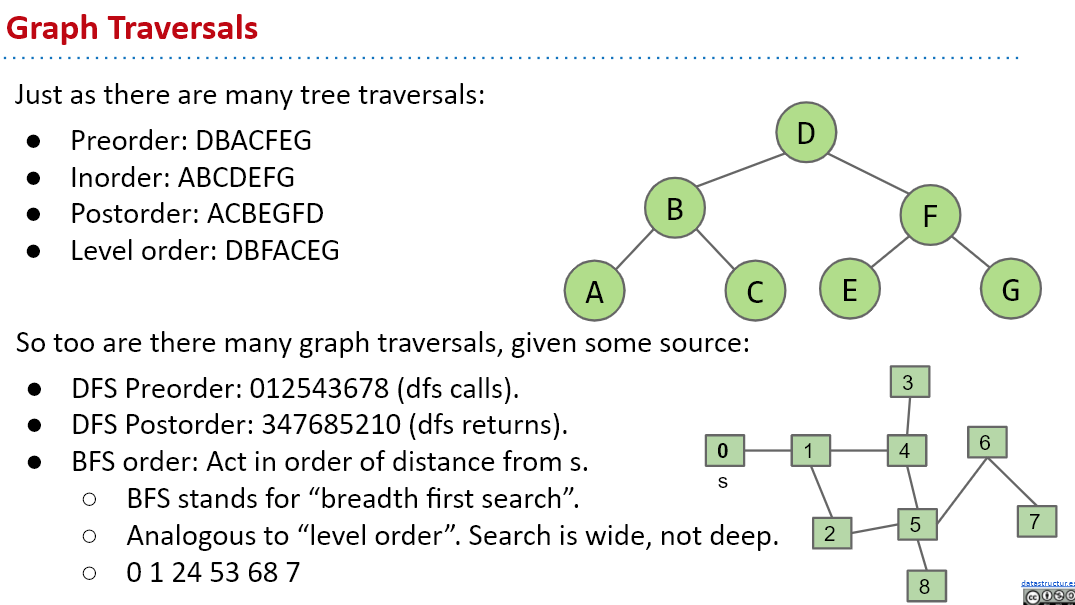
DFS:
public class DepthFirstPaths {private boolean[]marked;private int[]edgeTo;private int s;public DepthFirstPaths(Graph G,int s){marked=new boolean[G.V()];edgeTo=new int[G.V()];this.s=s;dfs(G,s);}private void dfs(Graph G,int v){marked[v]=true;for (int w:G.adj(v)){if (marked[w]!=true){edgeTo[w]=v;dfs(G,w);}}}public boolean hasPathTo(int v){//如果这个点被经过了,就说明该点可达return marked[v];}public Iterable<Integer>pathTo(int v){if (!hasPathTo(v))return null;Stack<Integer>path=new Stack<>();for (int x=v;x!=s;x=edgeTo[x])path.push(x);path.push(s);return path;} }BFS:
public class BreadthFirstPaths {private boolean[]marked;private int[]edgeTo;private int s;public BreadthFirstPaths(Graph G,int s){marked=new boolean[G.V()];edgeTo=new int[G.V()];this.s=s;}private void bfs(Graph G,int s){Queue<Integer>queue=new LinkedList<>();queue.offer(s);marked[s]=true;while (!queue.isEmpty()){int v=queue.poll();for (int w:G.adj(v)){if (marked[w]!=true){queue.offer(w);marked[w]=true;edgeTo[w]=v;}}}}public boolean hasPathTo(int v){return marked[v];}public Iterable<Integer>pathTo(int v){if (!hasPathTo(v))return null;Stack<Integer> path=new Stack<>();for (int x=v;x!=s;x=edgeTo[x])path.push(x);path.push(s);return path;} }
深度优先搜索可以用来寻找两点之间的路径,广度优先搜索可以用来寻找两点之间的最短路径。
DFS还可以用来寻找一幅图的所有连通分量,这是并查集做不到的,并查集只能判断两点之间是否连接,也无法获取两点之间的连接关系。
寻找连通分量,还可以判断任意两点是否连接(connected),给出任意一点的连通分量的序号(id):
public class connectedComponent {private boolean[]marked;private int[]id;private int count;public connectedComponent(Graph G){marked=new boolean[G.V()];id=new int[G.V()];for (int s=0;s<G.V();s++){if (marked[s]!=true){dfs(G,s);count++;}}}private void dfs(Graph G,int v){marked[v]=true;id[v]=count;for (int w:G.adj(v)){if (marked[w]!=true){id[w]=v;dfs(G,w);}}}public boolean connected(int v,int w){return id[v]==id[w];}public int id(int v){return id[v];}public int count(){return count;} }
CC中基于深度优先搜索来解决图连通性问题的方法与union-find算法相比孰优孰劣?理论上,深度优先搜索比union-find法快,因为它能保证所需的时间是常数而union-find算法不行;但在实际应用中,这点差异微不足道。union-find 算法其实更快,因为它不需要完整地构造并表示一幅图。更重要的是,union-find 算法是一种动态算法 (我们在任何时候都能用接近常数的时间检查两个顶点是否连通,甚至是在添加一条边的时候),但深度优先搜索则必须要对图进行预处理。因此,我们在完成只需要判断连通性或是需要完成有大量连通性查询和插入操作混合等类似的任务时,更倾向使用union-find 算法,而深度优先搜索则更适合实现图的抽象数据类型,因为它
能更有效地利用已有的数据结构。
SymbolGraph
二分图是一种能够将所有结点分为两部分的图,其中图的每条边所连接的两个顶点都分别属于不同的部分。其中红色的结点是一个集合,黑色的结点是另一个集合。
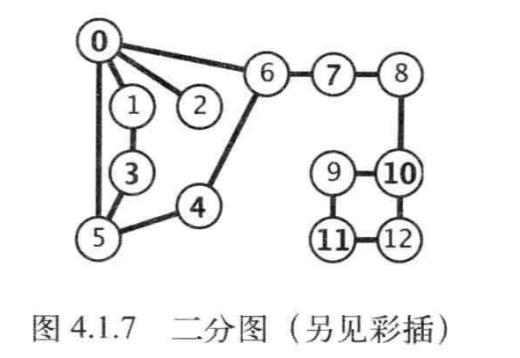
在典型应用中,图是通过文件或网页定义的,使用的是字符串而不是整数来指代顶点。我们称这种图为符号图。
应用一:一个小型运输系统的模型,其中表示每个顶点的是美国机场的代码,连接它们的边则表示顶点之间
的航线。文件只是一组边的列表。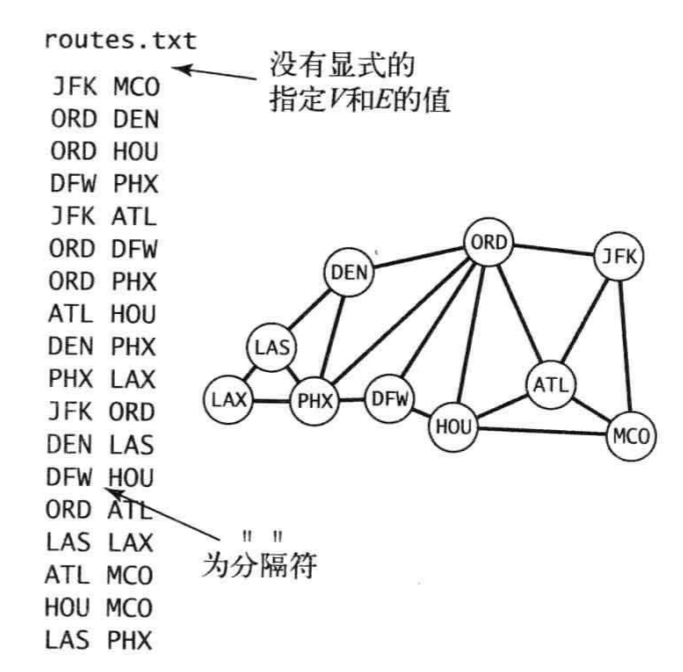
你可以输入一个机场的代码来查找能从该机场直飞到达的城市,但这些信息并不是直接就能从文件中得到的。
SymbolGraph的完整实现用到了以下3种数据结构
- 一个符号表st,键的类型为String (顶点名),值的类型为int (索引) ;
- 一个数组keys[], 用作反向索引,保存每个顶点索引所对应的顶点名;
- 一个Graph对象G,它使用索引来引用图中顶点。
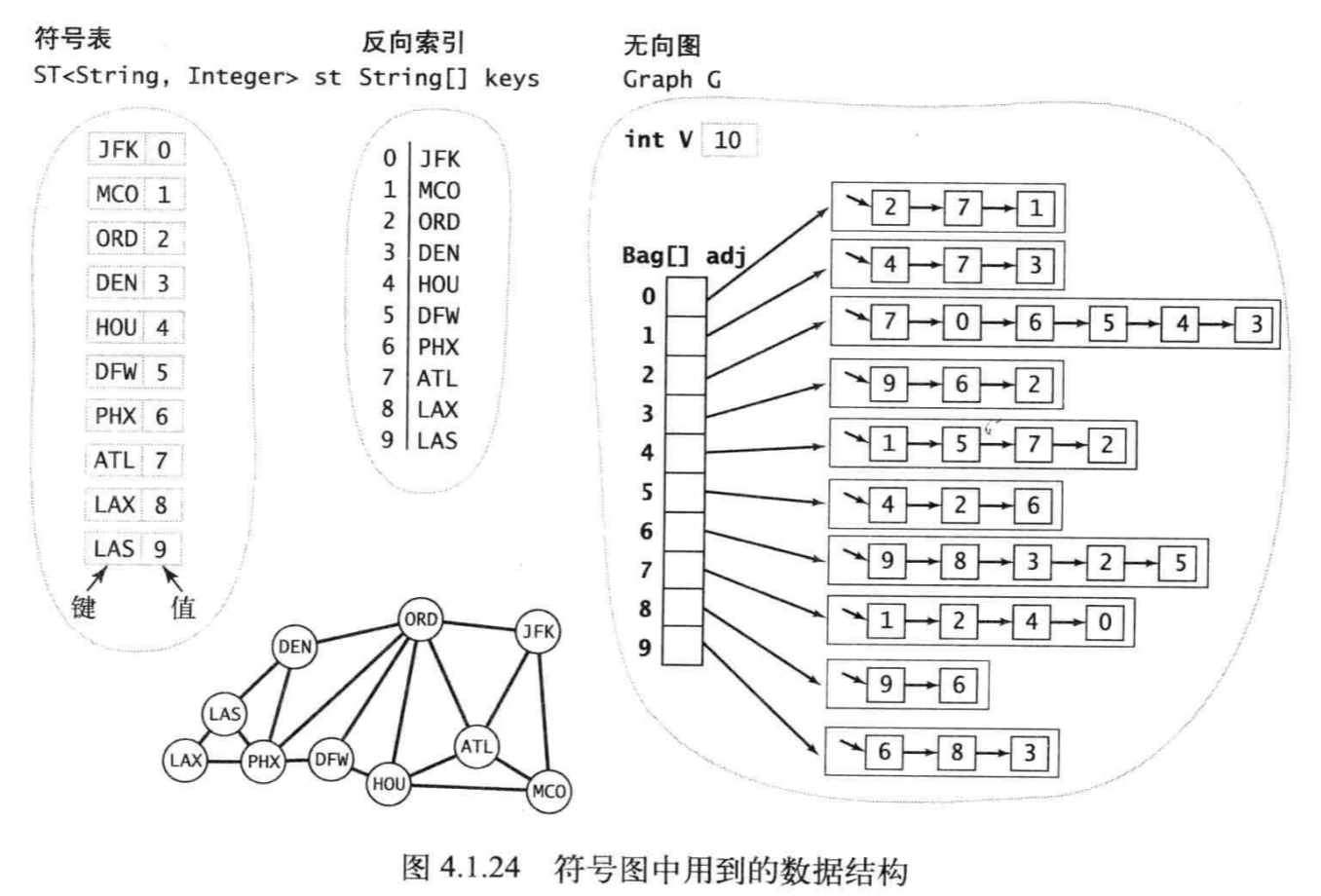
用例可以使用index( )将顶点名转化为索引并在图处理算法中使用,然后将处理结果用name()转化为顶点名以便在实际应用中使用。
public class SymbolGraph {private HashMap<String,Integer>SymbolToIndex;private String[]keys;//索引到符号名private Graph G;public SymbolGraph(){SymbolToIndex=new HashMap<>();Scanner input=new Scanner(System.in);String sp=" ";while (input.hasNextLine()){String stream=input.nextLine();String[]a=stream.split(sp);for (int i=0;i<a.length;i++){if (!SymbolToIndex.containsKey(a[i])){int index=SymbolToIndex.size();SymbolToIndex.put(a[i],index);//符号到索引keys[index]=a[i];//索引到符号}}//将每一行的顶点和其他点相连。for (int i=1;i<a.length;i++){G.addEdge(SymbolToIndex.get(a[0]),SymbolToIndex.get(a[i]));}}}public boolean contains(String s){return SymbolToIndex.containsKey(s);}public int index(String s){return SymbolToIndex.get(s);}public String name(int index){return keys[index];}public Graph G(){return G;} }图处理的一个经典问题就是,找到一个社交网络之中两个人间隔的度数。为了弄清楚概念,我们用一个名为KevinBacon的游戏来说明这个问题。这个游戏用到了刚才讨论的“电影-演员”图。Kevin Bacon是一个活跃的演员,曾出演过许多电影。我们为图中的每个演员赋一个KevinBacon数:Bacon本人为0,所有KevinBacon出演过同一.部电影的人的值为1,所有(除了KevinBacon)和KevinBacon数为1的演员出演过同一部电影的其他演员的值为2,依次类推。
这是一个二分图,有两种不同的节点:电影和演员。每条路径上都会交叉出现电影和演员的顶点。我们要利用BFS来寻找任意一个演员与Kevin bacon的间隔度数(即他们之间的最短路径,间隔多少电影顶点)
Lecture25、Shortest Paths
BFS适用于无权边的图寻找最短路径,我们使用Dijkstra来对有权图(无负权边)来寻找最短路径,使用Bellman-ford对有负权边的图寻找最短路径。
Dijkstra本质上是一种贪心算法,利用优先队列,存储图中的点和离源点的距离,从源点开始,优先访问距离源点最近的点,然后对周围没有访问过的点进行松弛,更新被松弛的点和源点的距离。

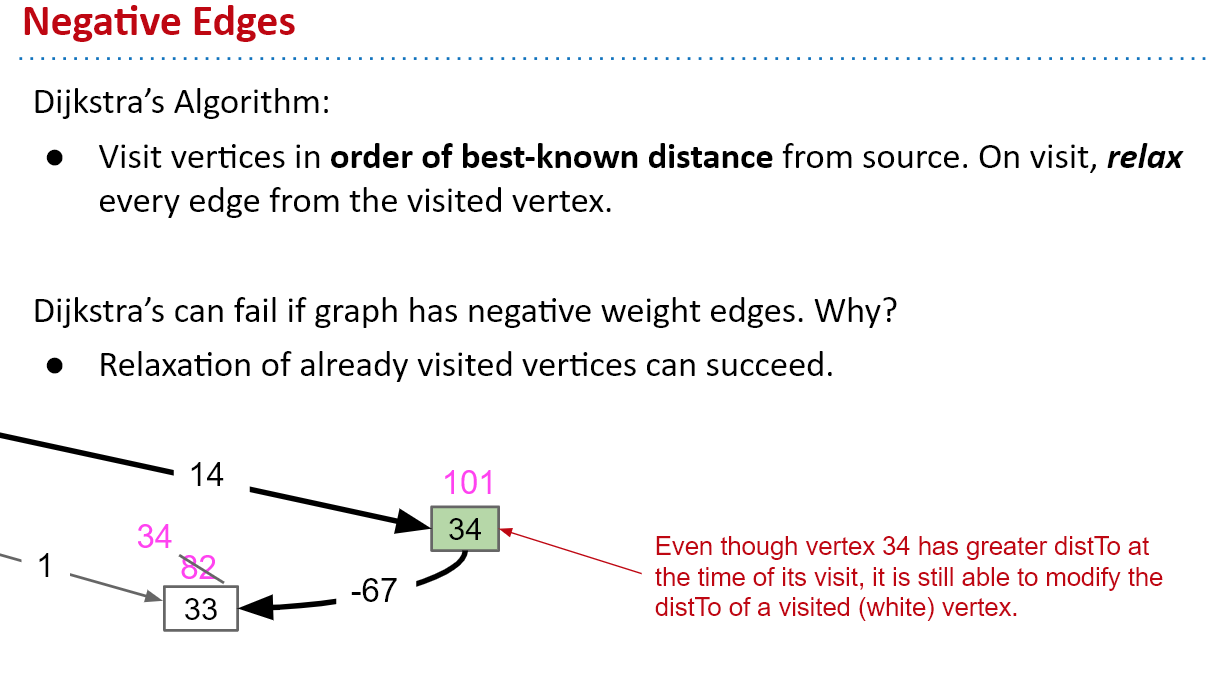
Dijkstra的正确性来源于它的访问顺序是从距离最近的点到最远的点,所有已经经过的点的距离已经是最优的了,才能在这个点的基础上对周围的边进行松弛。如果有负权边,那么无法保证已经过的点的距离是最优的,还有可能更短,所以无法对负权边使用Dijkstra。
Lecture26、Minimum Spanning Trees

一个图的生成树:
- 连通的
- 没有回路
- 包含所有的点
最小生成树:总权值最小的生成树。
最短路径和最小生成树的关系:
- A shortest paths tree depends on the start vertex:Because it tells you how to get from a source to EVERYTHING.
- There is no source for a MST.
Nonetheless, the MST sometimes happens to be an SPT for a specific vertex.
所以Dijkstra算法对于最小生成树无法使用,只有对于特殊的节点,该点的最短路径才有可能同时是最小生成树。
Dijkstra:https://docs.google.com/presentation/d/1_bw2z1ggUkquPdhl7gwdVBoTaoJmaZdpkV6MoAgxlJc/pub?start=false&loop=false&delayms=3000&slide=id.g771336078_0_655
切分定理:在一幅加权图中,给定任意的切分,它的横切边中的权重最小者必然属于图的最小生成树。
图的一种切分是将图的所有顶点分为两个非空且不重复的两个集合。横切边是一条连接两个属于不同集合的顶点的边。切分定理的这条性质将会把加权图中的所有顶点分为两个集合、检查横跨两个集合的所有边并识别哪条边应属于图的最小生成树。
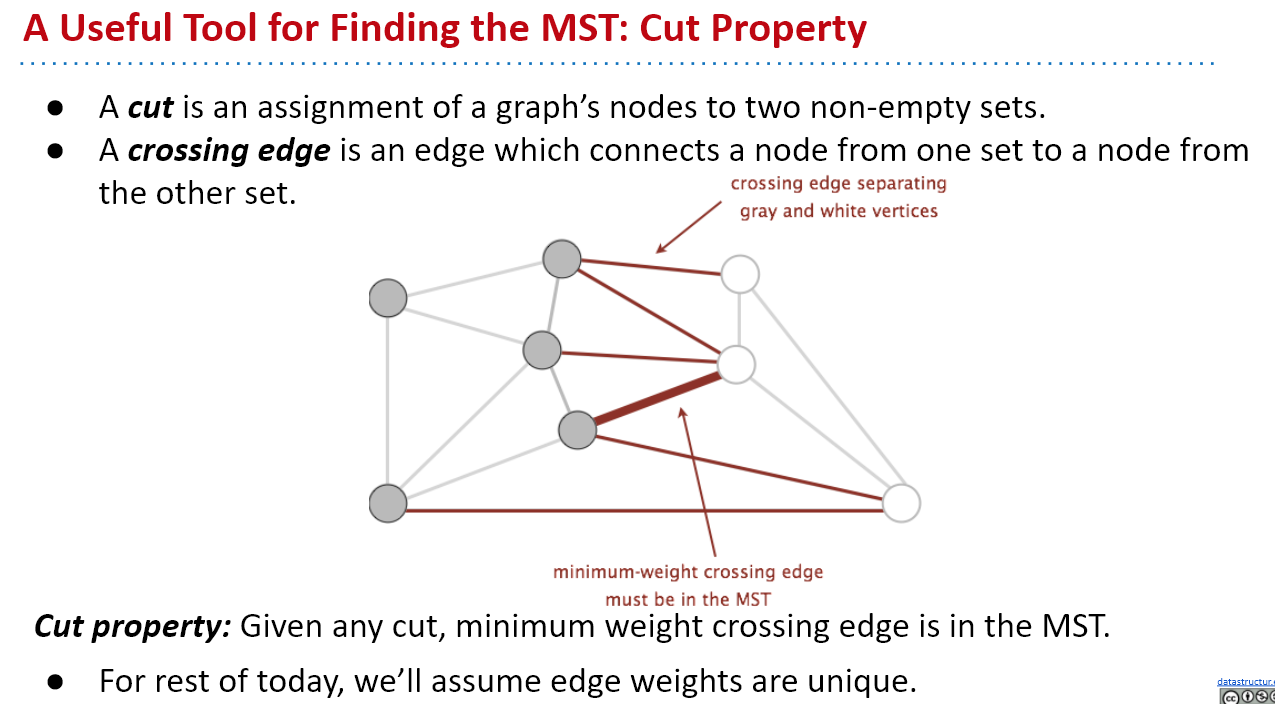
切分定理是解决最小生成树问题的所有算法的基础。更确切的说,这些算法都是一种贪心算法的特殊情况:使用切分定理找到最小生成树的一条边,不断重复直到找到最小生成树的所有边。
prim:
我们使用了一个私有方法visit()来为树添加一个顶点、将它标记为“已访问”并将与它关联的所有未失效的边(即这条边的另一个点没有被访问过,如果另一个点也被访问过的话,就会构成回路)加入优先队列,以保证队列含有所有连接树顶点和非树顶点的边(也可能含有一些已经失效的边)。代码的内循环是算法的具体实现:我们从优先队列中取出权重最小的一条边并将它添加到树中**(如果它还没有失效的话)**(即这条边的两个点中有一个没有被访问过),再把这条边的另一个顶点也添加到树中,然后用新顶点作为参数调用visit()方法来更新横切边的集合。
两个重点:
- 不要将已经另一个端点已经访问的边加入优先队列,因为这样的边已经被访问过了,如果这样的边在优先队列中,它也是失效的边,不能添加到生成树中
- 不要将优先队列中失效的边添加到生成树中(即两个端点都被访问过的边)
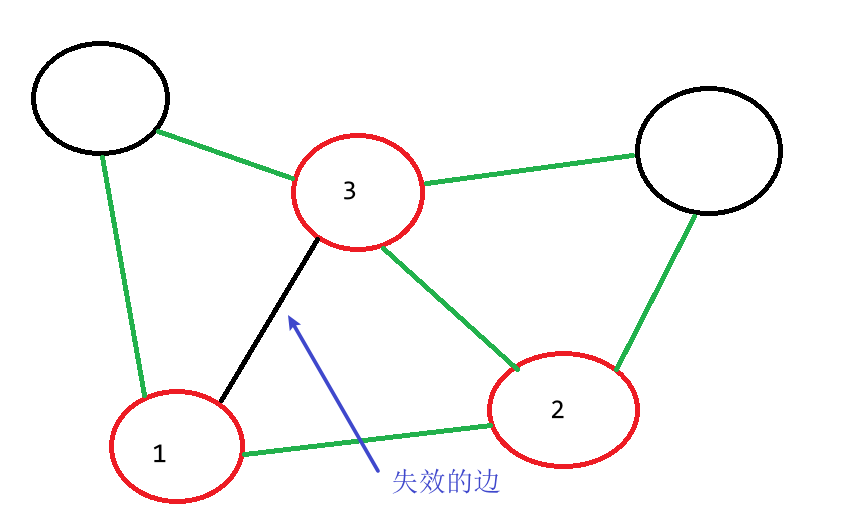
总而言之:两端都访问过的边不能加入优先队列,如果已经加入了,不能加入生成树。
也就是说:
- 在将边加入优先队列前,需要判断该边的另一个点是否访问过。
- 在从优先队列中获取最短的边加入生成树前,需要判断该边是否已经失效,即两个边是否都被访问过。
对于Dijkstra来说:只需要在松弛某一个点之前,判断该点是否访问过即可,即在优先队列中更新起点到某一点的距离之前,判断该点是否访问过,已访问过的点不需要更新距离。
因为Dijkstra和Prim的主要区别在于:Dijkstra在优先队列中存储的是每一点到起点的距离,而Prim在优先队列中存储的是所有的边。而优先队列中的边会失效的本质就是:从某一点到另外一点已经确定了另外的路线,其他的直接路线就失去了继续探索的意义。每次从一点到另外一点的路线确定了新的路线时,Prim只会直接将这个边加入优先队列,而Dijkstra则是直接更新优先队列,用新路线取代原来的旧路线,所以不需要考虑边失效的情况。
public class prim {private boolean[]marked;private Queue<Edge>mst=new LinkedList<>();private PriorityQueue<Edge>pq=new PriorityQueue<>();public prim(EdgeWeightedGraph G){marked=new boolean[G.V()];visit(G,0);while (!pq.isEmpty()){//从优先队列中获取离生成树最近的点Edge e=pq.poll();int v=e.either(),w=e.other(v);if (marked[v]&&marked[w])continue;mst.add(e);//以没有经过的点为中心将周围的边加入优先队列if (!marked[v])visit(G,v);if (!marked[w])visit(G,w);}}private void visit(EdgeWeightedGraph G,int v){//将访问过的点进行标记marked[v]=true;for (Edge e:G.adj(v))if (!marked[e.other(v)])pq.offer(e);} }kruskul
该算法的关键是:
- 将所有的边按权重从小到大排序
- 选出最小的边
- 如果该边在生成树中构成回路,就丢弃该边,重新选择最小的边
- 如果不构成回路,直接加入最小生成树
- 重复第二步
class UF{private int[]rank;private int[]parent;public UF(int n){parent=new int[n];rank=new int[n];for (int i=0;i<n;i++){parent[i]=i;rank[i]=1;}}private int find(int p){if (parent[p]!=p)parent[p]=find(parent[p]);return parent[p];}public boolean connected(int p,int q){return find(p)==find(q);}public void union(int p,int q){int pRoot=find(p);int qRoot=find(q);if (rank[pRoot]<rank[qRoot])parent[pRoot]=qRoot;else if (rank[pRoot]>rank[qRoot])parent[qRoot]=pRoot;else {parent[qRoot]=pRoot;rank[qRoot]++;}} } public class Kruskul {private Queue<Edge>mst=new LinkedList<>();private PriorityQueue<Edge>pq=new PriorityQueue<>();public Kruskul(EdgeWeightedGraph G){for (Edge e:G.Edges())pq.offer(e);UF uf=new UF(G.V());while (!pq.isEmpty()&&mst.size()<G.V()-1){Edge e=pq.poll();int v=e.either(),w=e.other(v);if (uf.connected(v,w))continue;uf.union(v,w);mst.offer(e);}}public Iterable<Edge>edges(){return mst;} }
cs61b学习记录(四)Trie、KDTree、Prim、Dijkstra、Kruskul相关推荐
- leveldb 学习记录(四)Log文件
前文记录 leveldb 学习记录(一) skiplist leveldb 学习记录(二) Slice leveldb 学习记录(三) MemTable 与 Immutable Memtable le ...
- MySQL学习记录 (四) ----- SQL数据管理语句(DML)
相关文章: <MySQL学习记录 (一) ----- 有关数据库的基本概念和MySQL常用命令> <MySQL学习记录 (二) ----- SQL数据查询语句(DQL)> &l ...
- Kafka学习记录(四)——消费者
Kafka学习记录(四)--消费者 目录 Kafka学习记录(四)--消费者 对应课程 Kafka消费者工作流程 消费方式和流程 消费者组原理 消费者组初始化流程 消费者组详细消费流程 重要参数 ka ...
- 【故障诊断发展学习记录四——数字孪生与控制系统健康管理(DT PHM)】
数字数字 目录 1. 数字孪生的起源 1.1 数字工程 1.2 模型贯穿决策 1.3 数字工程路线图 1.4 数字工程战略目标 2. 美军数字工程 2.1 生态系统全视图 2.2 支持采办的的完整视 ...
- gRPC学习记录(四)--官方Demo
了解proto3后,接下来看官方Demo作为训练,这里建议看一遍之后自己动手搭建出来,一方面巩固之前的知识,一方面是对整个流程更加熟悉. 官方Demo地址: https://github.com/gr ...
- grpc简单使用 java_gRPC学习记录(四)-官方Demo - Java 技术驿站-Java 技术驿站
了解proto3后,接下来看官方Demo作为训练,这里建议看一遍之后自己动手搭建出来,一方面巩固之前的知识,一方面是对整个流程更加熟悉. 官方Demo地址: https://github.com/gr ...
- 《你好,放大器》----学习记录(四)
4 使用放大器的共性问题 4.1 放大器的封装 选择运放的封装,对整体电路板尺寸.焊接工艺和散热有影响,对电路性能也有影响 4.1.1 关于封装的一些基本概念 关于封装,主要关心两个参数: 管脚间距 ...
- python3.10官方文档学习记录四__赋值、比较运算
1 先来个例子: Python 还可以完成比二加二更复杂的任务. 例如,可以编写 斐波那契数列 的初始子序列,如下所示: >>> # 斐波那契级数: ... # 两个元素的和定义了下 ...
- Linux 学习记录 四(Bash 和 Shell scirpt).
一.什么是 Shell? 狭义的shell指的是指令列方面的软件,包括基本的Linux操作窗口Bash等,广义的shell则包括 图形接口的软件,因为图形接口其实也可以操作各种驱动程序来呼叫核心进行工 ...
最新文章
- python必背内容-初学Python必背手册
- 公众号服务器配置url证书问题,公众号服务器配置url,验证token一直出错,为什么?...
- 百度机器阅读理解比赛赛后总结
- 4-输出基本数据类型
- 编译和使用APUE的源码
- jQuery源码研究分析学习笔记-静态方法和属性(10)
- 编写代码的软件用什么编写的_如果您编写代码,这就是您的黄金时代
- M6315模块连接阿里云物联网MQTT通讯
- 20h2是04服务器操作系统吗,爆料:微软 Win10 20H2 将是小更新
- springcloud 分布式配置中心 config server config client
- 20多行 Python 代码优雅搞定 PDF 转换成图片
- 利用Hownet进行语义相似度计算的类(
- 现代通信原理思维导图--第三章 随机过程
- 漫画分销系统服务器配置,漫画分销平台哪个好?月流水30万的老手来谈谈!
- 嵌入式开发之交叉编译工具链制作
- win10桌面管理文件收纳_win10系统关闭桌面文件收纳盒的详细方法介绍
- js是什么、html、css
- 36氪独家|「秦汉胡同」完成1亿元A轮融资,将发力线上内容产品和女性生活学习服务社群...
- iOS基础:【屏幕成像与卡顿】屏幕撕裂 Screen Tearing、 掉帧 Jank、三缓冲 Triple Buffering
- Unity任意方向拉伸物体