WhereHows解读
1 系统介绍
WhereHows是linkedin开源的数据发现平台,它从各种数据源收集元数据,标准化处理,提供统一的元数据服务。WhereHows的名字与warehouse谐音。同时,还包含了两层含义:
- Where:数据在哪,即元数据收集。
- How:数据的前世今生,生产者、消费者是谁,即血缘。
在统一元数据的基础上,平台提供了一系列功能:
- 数据发现:搜索数据。
- 数据血缘:跟踪数据集和任务的上下游。
- 工作流发现:通过项目、流、子流、任务的树结构,查看任务血缘。
- 提供页面访问及后台API。
2 架构介绍
2.1 总览
官方架构图:
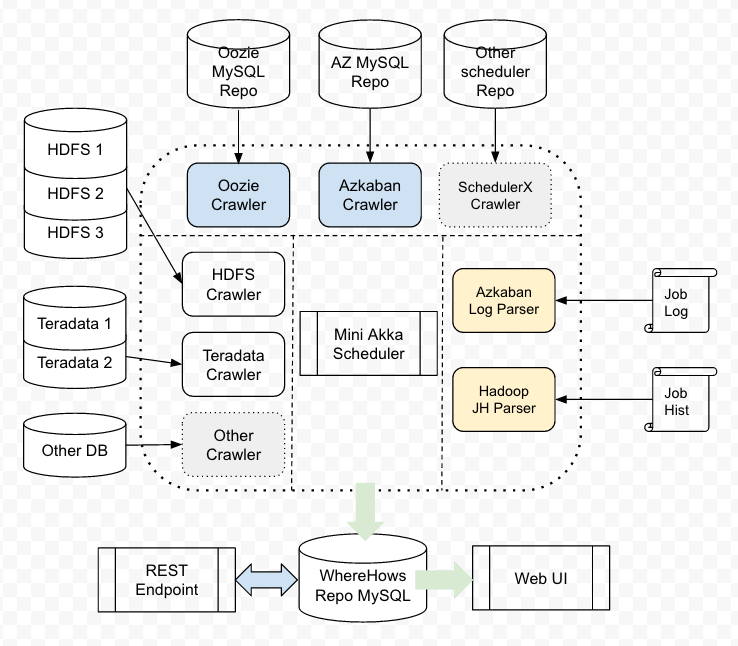
上图中,除了缺少Kafka部分外,还是比较准确的。可以看到,核心是akka分布式框架。通过akka actor执行各个存储系统和调度系统元数据的收集,并转换为统一模型存入WhereHows的mysql中。而不同存储系统和调度系统的元数据的收集、转换、存储的逻辑存在差异,所以具体的ETL逻辑是通过jython脚本编写的,这样就实现了面对不同存储和引擎的扩展性。新增存储系统或者计算调度系统,只需要对应的ETL job jython脚本。
2.2 数据模型
官方数据模型:
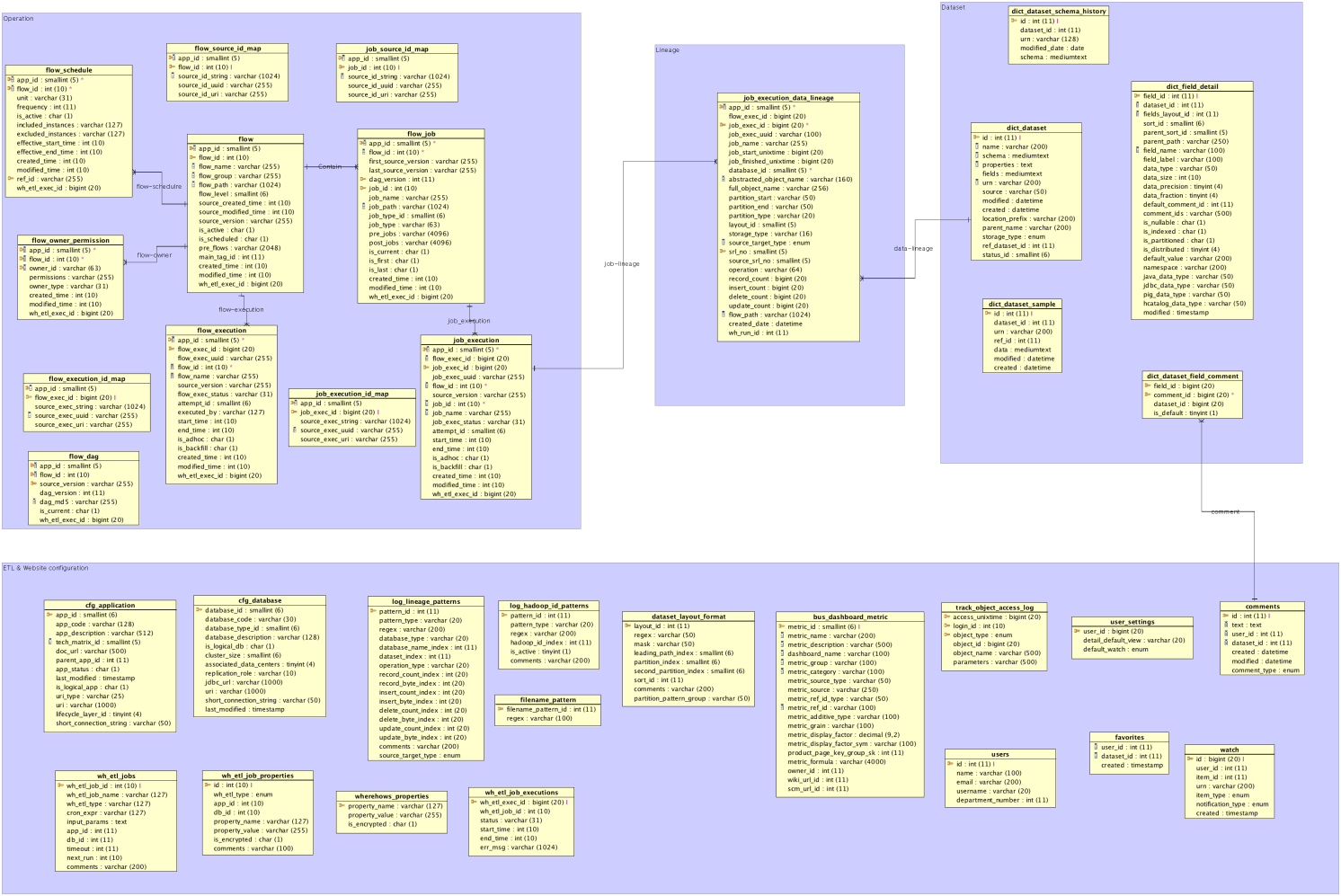
数据模型分为四部分:
- 数据集:数据集schema、备注、样本等。
- 操作数据:流组、流、任务、任务依赖、执行、ID映射表等。
- 血缘数据:任务的输入和输出、依赖、分区、位点等。
- ETL和Web服务配置。
dataset_前缀的表与数据集相关;flow_和job_前缀的表与流和任务相关;cfg_前缀开头的表与物理配置相关;wh_前缀开头的表与内部定时执行的元数据收集任务相关,负责记录定时执行的任务信息,以及任务执行状态等。
最顶层的抽象是dataset数据集的概念,以URN作为数据集唯一标识,schema抽象了不同的数据结构。除此之外还包括app应用系统信息(cfg_application)和db数据库系统信息(cfg_database)。
dataset作为顶层抽象,通过dataset_id关联到底层实际物理元数据信息(dict_dataset_instance、cfg_object_name_map、cfg_database等),包括hdfs、hive、teradata、dalids等。其中有DB模型的(hive、teradata、dalids),也有非DB模型的(hdfs)。cfg_object_name_map.sub_type区分具体的物理类型。
任务执行信息和数据集之间通过job_execution_data_lineage关联,即血缘表。数据集和操作数据是两个端点,而血缘数据就是连接两者的桥梁。用户可以从一个数据集出发,找到它的生产者任务或消费者任务;也可以从一个任务触发,找到这个任务读\写的数据集。
2.3 ETL
WhereHows使用java和jython语言。以java构建框架,定义每个ETL阶段的输入和输出;使用jython资源文件实现ETL处理过程。这使得结构更加清晰,对于需要自定义的内容一目了然。同时,提高了引入新的源系统的灵活性和扩展性。框架定义的元数据收集步骤按照ETL三阶段执行:extract、transform、load。
2.3.1 数据集ETL
数据集元数据包括:schema、path、partition、sample data、watermark、owner等等。WhereHows收集了HDFS、Teradata等数据集元数据。
HDFS:
使用具有读权限的账号,扫描白名单下的目录,并收集数据集信息。程序将schemaFetch.jar文件copy到hadoop gateway上,执行扫描,再将结果copy回本地,经过转换存储到mysql。
Teradata:
直接在jython脚本中查询库中的元数据。
2.3.2 操作数据ETL
操作数据包括:流组定义、流定义、流执行信息、任务定义、任务执行信息、owner信息、调度信息等。WhereHows的操作数据ETL定时从调度系统的数据库中爬取信息到WhereHows的数据库中。
- 痛点1:不同的调度系统具有不同的数据模型,需要将他们转换成统一的模型。例如:Azkaban的执行是在流级别,流执行具有唯一ID,但是任务执行没有唯一ID。反观Oozie,每个任务执行都具有唯一ID。为了解决这种情况,WhereHows结合流执行ID与任务在流中的顺序为Azkaban任务生成任务ID。同时,将所有的唯一ID映射为整型来适配相同的模型。每当添加调度系统,都要添加不同的映射规则将原生数据模型转换成WhereHows数据模型。
- 痛点2:很多源系统没有跟踪版本,或者版本很不直观。例如,Oozie和Azkaban这些调度系统没有流版本。在这种情况下,WhereHows收集流元数据之后,与老的DAG结构进行比较,在内部推导维护版本信息。WhereHows将这种推导的DAG版本用作所有操作数据的通用版本。
2.3.3 血缘ETL
血缘信息包括:任务和数据集之间的依赖关系,读还是写,涉及多少条记录等。
How:
基本策略是从日志和配置文件中收集血缘信息。比如:一个Pig任务有很多Hadoop任务,在Hadoop任务的配置文件中可以看到“mapreduce.input.fileinputformat.inputdir”一类的属性,可以代表Hadoop任务的血缘。WhereHows收集所有子Hadoop任务的输入和输出,将它们聚合到父级别任务,并存储下来。
When:
血缘ETL任务需要一个入口点,即任务ID信息列表,根据这个列表提取血缘信息。WhereHows作为一个元数据仓库,延迟容忍度高,5到10分钟的延迟是可以接受的,所以采用“微批拉取”的解决方案。通过一个拉取任务,检查最近30分钟(窗口可配)有哪些任务结束,然后以此作为入口点,拉取它们的日志和配置文件分析血缘。
3 代码解读
3.1 调度
WhereHows使用了akka分布式并发框架,其中三个核心的actor包括:SchedulerActor、EtlJobActor、TreeBuilderActor。这三个actor以静态变量的形式注册在ActorRegistry中:
public class ActorRegistry {public static Scheduler scheduler = actorSystem.scheduler();public static ActorRef schedulerActor = actorSystem.actorOf(Props.create(SchedulerActor.class), "SchedulerActor");public static ActorRef etlJobActor =actorSystem.actorOf(new SmallestMailboxPool(ETL_POOL_SIZE).props(Props.create(EtlJobActor.class)), "EtlJobActor");public static ActorRef treeBuilderActor =actorSystem.actorOf(Props.create(TreeBuilderActor.class), "TreeBuilderActor");
}通过SchedulerUtil启动SchedulerActor,则启动了整个调度引擎。定时向SchedulerActor发送“checking”消息触发调度检查:
public class SchedulerUtil {public static synchronized void start(Long mins) {if (schedulerRef != null) {schedulerRef.cancel();}schedulerRef = ActorRegistry.scheduler.schedule(Duration.create(0, TimeUnit.MILLISECONDS), Duration.create(mins, TimeUnit.MINUTES),ActorRegistry.schedulerActor, "checking", ActorRegistry.dispatcher, null);}}3.1.1 SchedulerActor
SchedulerActor在收到“checking”消息后,从应用配置的目录位置,读取所有需要执行的job文件:

并从DB中读取已经记录的定时调度job(包括job的下一次调度时间)。
遍历所有的job文件,将每个job的下一次调度时间更新到DB中。如果已经记录的job中存在当前job,则判断是否到了调度时间,到了就执行,没到则跳过。而触发job执行就是将对应的job信息作为消息发送给EtlJobActor。
public void onReceive(Object message) throws Exception {if (message.equals("checking")) {runDueJobs();}}private void runDueJobs() throws Exception {Map<String, Properties> enabledJobs = JobsUtil.getScheduledJobs(ETL_JOBS_DIR);Map<String, Long> scheduledJobs = getScheduledJobs();long now = System.currentTimeMillis() / 1000;for (Map.Entry<String, Properties> entry : enabledJobs.entrySet()) {String etlJobName = entry.getKey();Properties properties = entry.getValue();EtlJobMessage etlMsg = new EtlJobMessage(etlJobName, properties);// Schedule next run if a cron expr is defined.String cronExpr = etlMsg.getCronExpr();if (cronExpr != null) {EtlJobDao.updateNextRun(etlJobName, cronExpr, new Date());}if (scheduledJobs.getOrDefault(etlJobName, Long.MAX_VALUE) > now) {continue;}Long whExecId = EtlJobDao.insertNewRun(etlJobName);etlMsg.setWhEtlExecId(whExecId);if (Global.getCurrentRunningJob().contains(etlJobName)) {EtlJobDao.endRun(etlMsg.getWhEtlExecId(), JobStatus.ERROR, "Previous is still running, Aborted!");} else {Global.getCurrentRunningJob().add(etlJobName);ActorRegistry.etlJobActor.tell(etlMsg, getSelf());}}}3.1.2 EtlJobActor
EtlJobActor的任务是启动一个新的进程执行SchedulerActor发送的job。这个新的进程的执行框架在Launcher中定义。
3.1.3 Launcher
Launcher负责job的ETL的触发。ETL的实际处理class在job文件中定义,以HDFS_METADATA_ETL.job文件为例,该job用来提取HDFS数据集的元数据:
# Fetch HDFS dataset metadata
# Common ETL configs
job.class=metadata.etl.dataset.hdfs.HdfsMetadataEtl
job.cron.expr=0 0 5 ? * TUE,THU,SUN *
job.timeout=3000
job.ref.id=11
# Cluster name
hdfs.cluster=your_cluster_name
# Run job on remote machine, true/false
hdfs.remote.mode=false
# Remote Hadoop gateway machine name (could be localhost)
hdfs.remote.machine=
# Private key used to log in to the remote machine
hdfs.private_key_location=
# JAR file location on the remote machine
hdfs.remote.jar=
# User login on remote machine
hdfs.remote.user=
# Metadata JSON file location on remote machine
hdfs.remote.raw_metadata=
# Sample data CSV file location on remote machine
hdfs.remote.sample=
# Place to store field metadata file
hdfs.local.field_metadata=
# Place to store metadata CSV file
hdfs.local.metadata=hdfs_metadata.csv
# Place to store metadata JSON file
hdfs.local.raw_metadata=hdfs_raw_metadata.json
# Place to store sample file
hdfs.local.sample=hdfs_sample.dat
# The whitelist of folder to collect metadata
hdfs.white_list=
# Optional. number of threads you want to scrape the HDFS
hdfs.num_of_thread=1
# Optional. The map of file path regex and dataset source. e.g. [{"/data/tracking.":"Kafka"},{"/data/retail.":"Teradata"}]
hdfs.file_path_regex_source_map=
文件中的“job.class”属性定义了实际执行的class为“metadata.etl.dataset.hdfs.HdfsMetadataEtl”。Launcher在实例化具体的job class之后,调用其run方法触发ETL执行。
3.2 ETL
所有的ETL类都继承EtlJob。EtlJob定义了extract、transform、load三个抽象方法,分别对应着ETL的三个执行步骤,由具体的实现类实现。在EtlJob.run()方法中顺序执行三个方法:
public abstract void extract() throws Exception;public abstract void transform() throws Exception;public abstract void load() throws Exception;public void run() throws Exception {setup();extract();transform();load();close();}以实现类HdfsMetadataEtl为例:
(1)extract
将schemaFetch.jar拷贝到HDFS文件系统上,并执行。执行过程中,扫描白名单中的路径,将所有文件的元数据信息记录在HDFS文件系统的指定路径。执行结束后,将结果拷贝回本地。
(2)transform
根据名为“HdfsTransform.py”的jython脚本中的逻辑,对上一步中拷贝到本地的数据进行转换处理:
public void transform() throws Exception {InputStream inputStream = classLoader.getResourceAsStream("jython/HdfsTransform.py");interpreter.execfile(inputStream);inputStream.close();}(3)load
在名为“HdfsLoad.py”的jython脚本中,将transform转换结果存入DB:
public void load() throws Exception {InputStream inputStream = classLoader.getResourceAsStream("jython/HdfsLoad.py");interpreter.execfile(inputStream);inputStream.close();}3.3 Kafka
WhereHows集成了kafka,可以通过消息触发元数据和血缘的更新。kafka的consumer和producer同样封装为akka的actor。
3.3.1 KafkaClientMaster
KafkaClientMaster是主actor,在ApplicationStart中启动:
public static void main(String[] args) {final ActorSystem actorSystem = ActorSystem.create("KAFKA");String kafkaJobDir = config.getString("kafka.jobs.dir");actorSystem.actorOf(Props.create(KafkaClientMaster.class, kafkaJobDir), "KafkaMaster");}其中,配置属性“kafka.jobs.dir”代表kafka消费/生产配置文件的目录。
KafkaClientMaster在preStart阶段从“kafka.jobs.dir”获取所有的kafka任务文件,遍历文件,构造对应的KafkaWorker(actor)并启动。在构造KafkaWorker的过程中,根据文件中的consumer topic和consumer属性构造kafka consumer,作为KafkaWorker的数据来源;根据“kafka.processor”属性实例化处理数据的Processor class;如果processor在处理过程中需要发送消息,则根据producer topic和producer属性构造kafka producer。通过向KafkaWorker发送“WORKER_START”消息触发kafka consumer的消费。
KafkaClientMaster由于在preStart阶段已经启动了所有worker,不需要接收、处理消息。
public void preStart() throws Exception {_kafkaJobList = JobsUtil.getEnabledJobs(KAFKA_JOB_DIR);log.info("Kafka jobs: {}", _kafkaJobList.keySet());if (_kafkaJobList.size() == 0) {context().stop(getSelf());return;}log.info("Starting KafkaClientMaster...");for (Map.Entry<String, Properties> entry : _kafkaJobList.entrySet()) {// handle one kafka topicfinal String kafkaJobName = entry.getKey();final Properties props = entry.getValue();final int numberOfWorkers = Integer.parseInt(props.getProperty(Constant.KAFKA_WORKER_COUNT, "1"));log.info("Create Kafka client with config: " + props);try {// create workerfor (int i = 0; i < numberOfWorkers; i++) {ActorRef worker = makeKafkaWorker(kafkaJobName, props);_kafkaWorkers.add(worker);worker.tell(KafkaWorker.WORKER_START, getSelf());log.info("Started Kafka worker #{} for job {}", i, kafkaJobName);}} catch (Exception e) {log.error("Error starting Kafka job: " + kafkaJobName, e);}}}3.3.2 KafkaWorker
KafkaWorker收到“WORKER_START”消息后,开始不断从kafka consumer拉取数据,并传给processor处理:
public void onReceive(@Nonnull Object message) throws Exception {if (!message.equals(WORKER_START)) {log.warn("Must send WORKER_START message first!");unhandled(message);}while (RUNNING) {ConsumerRecords<String, IndexedRecord> records;try {records = _consumer.poll(POLL_TIMEOUT_MS);} catch (SerializationException e) {log.error("Serialization Error: ", e);moveOffset(extractPartition(e), 1);continue;}try {process(records);} catch (Exception e) {log.error("Unhandled processing exception: ", e);break;}}getContext().stop(getSelf());}private void process(@Nonnull ConsumerRecords<String, IndexedRecord> records) {for (ConsumerRecord<String, IndexedRecord> record : records) {_receivedRecordCount++;_processor.process(record.value());if (_receivedRecordCount % 1000 == 0) {log.info("{}: received {} messages", _topic, _receivedRecordCount);}}_consumer.commitAsync();}3.3.3 KafkaMessageProcessor
上面提到“kafka.processor”属性指定实际处理消息的class。所有处理kafka消息的class都继承抽象类KafkaMessageProcessor,并实现process抽象方法。WhereHows提供了三个KafkaMessageProcessor实现类:MetadataChangeProcessor、MetadataInventoryProcessor、MetadataLineageProcessor。
MetadataChangeProcessor
从命名可以看出来,MetadataChangeProcessor处理单个数据集元数据的变更,输入消息为MetadataChangeEvent。它解析消息内容,并将变更作用于存储中。MetadataChangeEvent的changeType字段代表操作类型,包括创建、更新、删除。
处理失败的消息再通过kafka发送出去,便于记录、跟踪和重试。
MetadataInventoryProcessor
MetadataInventoryProcessor负责某个集群的数据集的批量处理。目前WhereHows代码中,只实现了删除。MetadataInventoryProcessor处理的消息为MetadataInventoryEvent,其中包含某个集群当前所有的数据集名称(nativeNames)。MetadataInventoryProcessor先根据消息中的集群信息,查询该集群在WhereHows中已存的数据集名称,再将存量数据集名称与消息中的数据集名称列表做减法,得到需要从元数据中删除的数据集名称。最后将这些需要删除的数据集包装为MetadataChangeEvent通过kafka发送出去,由上面的MetadataChangeProcessor进行消费处理。
MetadataLineageProcessor
MetadataLineageProcessor处理的消息是MetadataLineageEvent。MetadataLineageProcessor遍历消息中的血缘列表,对每个血缘的source列表和destination列表进行去重和校验,然后将血缘列表插入到数据库中。不过入库这一步暂未实现。
4 总结
WhereHows作为一个post-hoc型数据集管理系统,可以认为是GOODS思想的一个具体实现,高扩展性是其一个优点。引入新的源系统,可以通过jython脚本动态引入ETL逻辑,但仍要写java代码实现ETL job,灵活性在这里受到了限制。
5 参考资料
[1] WhereHows官方:https://github.com/linkedin/WhereHows
WhereHows解读相关推荐
- Python Re 模块超全解读!详细
内行必看!Python Re 模块超全解读! 2019.08.08 18:59:45字数 953阅读 121 re模块下的函数 compile(pattern):创建模式对象 > import ...
- Bert系列(二)——源码解读之模型主体
本篇文章主要是解读模型主体代码modeling.py.在阅读这篇文章之前希望读者们对bert的相关理论有一定的了解,尤其是transformer的结构原理,网上的资料很多,本文内容对原理部分就不做过多 ...
- Bert系列(三)——源码解读之Pre-train
https://www.jianshu.com/p/22e462f01d8c pre-train是迁移学习的基础,虽然Google已经发布了各种预训练好的模型,而且因为资源消耗巨大,自己再预训练也不现 ...
- NLP突破性成果 BERT 模型详细解读 bert参数微调
https://zhuanlan.zhihu.com/p/46997268 NLP突破性成果 BERT 模型详细解读 章鱼小丸子 不懂算法的产品经理不是好的程序员 关注她 82 人赞了该文章 Goo ...
- 解读模拟摇杆原理及实验
解读模拟摇杆原理及实验 Interpreting Analog Sticks 当游戏支持控制器时,玩家可能会一直使用模拟摇杆.在整个体验过程中,钉住输入处理可能会对质量产生重大影响.让来看一些核心概念 ...
- 自监督学习(Self-Supervised Learning)多篇论文解读(下)
自监督学习(Self-Supervised Learning)多篇论文解读(下) 之前的研究思路主要是设计各种各样的pretext任务,比如patch相对位置预测.旋转预测.灰度图片上色.视频帧排序等 ...
- 自监督学习(Self-Supervised Learning)多篇论文解读(上)
自监督学习(Self-Supervised Learning)多篇论文解读(上) 前言 Supervised deep learning由于需要大量标注信息,同时之前大量的研究已经解决了许多问题.所以 ...
- 可视化反投射:坍塌尺寸的概率恢复:ICCV9论文解读
可视化反投射:坍塌尺寸的概率恢复:ICCV9论文解读 Visual Deprojection: Probabilistic Recovery of Collapsed Dimensions 论文链接: ...
- 从单一图像中提取文档图像:ICCV2019论文解读
从单一图像中提取文档图像:ICCV2019论文解读 DewarpNet: Single-Image Document Unwarping With Stacked 3D and 2D Regressi ...
- 点云配准的端到端深度神经网络:ICCV2019论文解读
点云配准的端到端深度神经网络:ICCV2019论文解读 DeepVCP: An End-to-End Deep Neural Network for Point Cloud Registration ...
最新文章
- Maven工程构建时报编码警告的解决办法
- 工具在软件过程改进中的重要作用
- MyEclipse 如何使用断点调试
- 2018黄河奖设计大赛获奖_宣布我们的freeCodeCamp 2018杰出贡献者奖获奖者
- python tkinter 窗口禁止编辑_python tkinter禁用文本窗口中的换行
- 图标插件java_java – Eclipse插件:标记的自定义图标
- matlab中unique的作用,matlab中的unique函数详解
- 3t硬盘 xp_如何在Windows XP SP3 32位系统下识别3T容量GPT格式硬盘
- 详细解析Photoshop10个必学的抠图技巧
- k8s的命令行管理工具
- UOJ #60 [UR #5] 怎样提高智商
- termux python turtle_如何在termux上安装Python的turtle库?
- 第二章 Dubbo框架
- c++11新特性std::is_trivial
- 2015年全部企业校园招聘情况+薪资水平!
- 借助小程序·云开发制作校园导览小程序丨实战
- Python系列英文原版电子书
- 【linux】lsb_release -a命令
- add_months()函数介绍
- Golang 从入门到放弃