自然语言处理工具hanlp自定义词汇添加图解
过程分析
1.添加新词需要确定无缓存文件,否则无法使用成功,因为词典会优先加载缓存文件
2.再确认缓存文件不在时,打开本地词典按照格式添加自定义词汇。
3.调用分词函数重新生成缓存文件,这时会报一个找不到缓存文件的异常,不用管,因为加载词典进入内存是会优先加载缓存,缓存不在当然会报异常,然后加载词典生成缓存文件,最后处理字符进行分词就会发现新添加的词汇可以进行分词了。
操作过程图解:
1、有缓存文件的情况下:
1 System.out.println(HanLP.segment("张三丰在一起我也不知道你好一个心眼儿啊,一半天欢迎使用HanLP汉语处理包!" +"接下来请从其他Demo中体验HanLP丰富的功能~"))
2
3 //首次编译运行时,HanLP会自动构建词典缓存,请稍候……
4 //[张/q, 三丰/nz, 在/p, 一起/s, 我/rr, 也/d, 不/d, 知道/v, 你好/vl, 一个心眼儿/nz, 啊/y, ,/w, 一半天/nz, 欢迎/v, 使用/v, HanLP/nx, 汉语/gi, 处理/vn, 包/v, !/w, 接下来/vl, 请/v, 从/p, 其他/rzv, Demo/nx, 中/f, 体验/v, HanLP/nx, 丰富/a, 的/ude1, 功能/n, ~/nx]
5
6
1. 打开用户词典–添加 ‘张三丰在一起’ 为一个 nz词性的新词
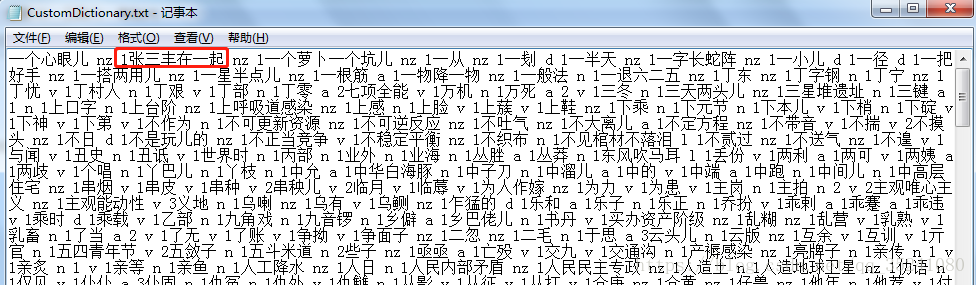
2.2 原始缓存文件下运行–会发现不成功,没有把 ‘张三丰在一起’ 分词一个nz词汇
1 System.out.println(HanLP.segment("张三丰在一起我也不知道你好一个心眼儿啊,一半天欢迎使用HanLP汉语处理包!" +"接下来请从其他Demo中体验HanLP丰富的功能~"))
2
3 //首次编译运行时,HanLP会自动构建词典缓存,请稍候……
4 //[张/q, 三丰/nz, 在/p, 一起/s, 我/rr, 也/d, 不/d, 知道/v, 你好/vl, 一个心眼儿/nz, 啊/y, ,/w, 一半天/nz, 欢迎/v, 使用/v, HanLP/nx, 汉语/gi, 处理/vn, 包/v, !/w, 接下来/vl, 请/v, 从/p, 其他/rzv, Demo/nx, 中/f, 体验/v, HanLP/nx, 丰富/a, 的/ude1, 功能/n, ~/nx]
5
3.1 删除缓存文件 bin
3.2 再次运行程序,此时会报错—无法找到缓存文件
1 System.out.println(HanLP.segment("张三丰在一起我也不知道你好一个心眼儿啊,一半天欢迎使用HanLP汉语处理包!" +"接下来请从其他Demo中体验HanLP丰富的功能~"));
2
3 /**首次编译运行时,HanLP会自动构建词典缓存,请稍候……
4 十月 19, 2018 6:12:49 下午 com.hankcs.hanlp.corpus.io.IOUtil readBytes
5 WARNING: 读取D:/datacjy/hanlp/data/dictionary/custom/CustomDictionary.txt.bin时发生异常java.io.FileNotFoundException: D:\datacjy\hanlp\data\dictionary\custom\CustomDictionary.txt.bin (系统找不到指定的文件。) 找不到缓存文件
6
7
8 [张三丰在一起/nz, 我/rr, 也/d, 不/d, 知道/v, 你好/vl, 一个心眼儿/nz, 啊/y, ,/w, 一半天/nz, 欢迎/v, 使用/v, HanLP/nx, 汉语/gi, 处理/vn, 包/v, !/w, 接下来/vl, 请/v, 从/p, 其他/rzv, Demo/nx, 中/f, 体验/v, HanLP/nx, 丰富/a, 的/ude1, 功能/n, ~/nx]
9
10 */
自然语言处理工具hanlp自定义词汇添加图解相关推荐
- 自然语言处理工具HanLP被收录中国大数据产业发展的创新技术新书《数据之翼》...
在12月20日由中国电子信息产业发展研究院主办的2018中国软件大会上,大快搜索获评"2018中国大数据基础软件领域领军企业",并成功入选中国数字化转型TOP100服务商. 在本届 ...
- 自然语言处理工具HanLP被收录中国大数据产业发展的创新技术新书《数据之翼》
在12月20日由中国电子信息产业发展研究院主办的2018中国软件大会上,大快搜索获评"2018中国大数据基础软件领域领军企业",并成功入选中国数字化转型TOP100服务商. 在本届 ...
- hanlp中文语言处理--词典加载源码过程分析及自定义用户词汇添加
一.hanlp本地词典加载源码分析 hanlp在调用提供的函数处理文本时会先初始化本地词典,加载词典进入内存中 以中文分词接口为例子 1.调用分词函数入口 public class DemoAtFir ...
- Python自然语言处理工具
Python 自然语言处理(NLP)工具汇总 NLTK 简介: NLTK 在使用 Python 处理自然语言的工具中处于领先的地位.它提供了 WordNet 这种方便处理词汇资源的接口,以及分类.分词 ...
- python自然语言处理库_Python自然语言处理工具库(含中文处理)
自然语言处理(Natural Language Processing,简称 NLP),是研究计算机处理人类语言的一门技术.随着深度学习在图像识别.语音识别领域的大放异彩,人们对深度学习在 NLP 的价 ...
- 开源的自然语言处理工具
2019独角兽企业重金招聘Python工程师标准>>> 学习自然语言这一段时间以来接触和听说了好多开源的自然语言处理工具,在这里做一下汇总方便自己以后学习,其中有自己使用过的也有了解 ...
- 视图添加字段_使用ExploreByTouchHelper辅助类为自定义视图添加虚拟视图
在安卓开发过程中,为了视觉和功能的需要开发者经常会使用自定义视图 大多数的自定义视图是组合现有的控件来完成特定的功能 但是,有一种自定义视图是通过画笔在画布上画出自定义的子视图的,例如日期控件,颜色选 ...
- 这个自然语言处理“工具”,玩得停不下来
今天推荐一个有趣的自然语言处理公众号「AINLP」,关注后玩得根本停不下来!AINLP的维护者是我爱自然语言处理(52nlp)博主,他之前在腾讯从事NLP相关的研发工作,目前在一家创业公司带技术团队. ...
- HanLP自定义词典注意事项
对于词典,直接加载文本会很慢,所以HanLP对于文本文件做了一些预处理,生成了后缀名为.txt.bin的二进制文件. 这些二进制文件相当于缓存,避免了每次加载去读取多个文件. 通过这种txt和bin结 ...
最新文章
- 做ML项目,任务繁多琐碎怎么办?这份自查清单帮你理清思路
- ×××论坛应该为访问者更大的价值
- DDD理论学习系列(6)-- 实体
- XSS挑战之旅闯关笔记
- Spring Cloud Alibaba到底坑不坑?
- 服务器忘记linux系统密码,linux系统服务器忘记密码怎么办
- 鸿蒙os即将升级,央视爆料鸿蒙OS即将升级,荣耀智慧屏强大自研开启国货新时代...
- mysql目录权限设置_MySQL文件及目录权限设置分析-爱可生
- mybatis中的xml中拼接sql中参数与字符串的方法
- C++总结8——shared_ptr和weak_ptr智能指针
- 采用推理的方法认知单词、CBOW模型
- python内置模块大全_python知识汇总(异常、内置模块和打包)
- 致命车祸进展:Uber无人车检测到了行人,但选择了忽略
- c++ 虚函数实现原理
- plecs matlab 联合仿真,利用MATLAB/Simulink图形环境和PLECS模块库仿真太阳光电(PV)换流器...
- oracle查看数据库文件大小
- Python:火山小视频-无水印视频-多线程-批量采集实现和完整代码
- 查看自己电脑连接过的WiFi密码
- Android so 文件全部报错:Duplicate resources
- 杂记:Atmel sama5d3 DMA Controller (DMAC)