SLS:海量日志数据管理利器
原文链接:http://click.aliyun.com/m/13917/
SLS:海量日志数据管理利器
日志是大规模集群管理系统中非常关键的部分,服务器上的各种日志数据(如访问日志、应用日志等)可以帮助我们回答如运维、开发、运营、客服、安全等各种问题,例如:
运维:服务是否正常,流量和QPS是多少;
开发:线上有没有异常和错误发生;
运营:多少账号开通了服务,其中开通失败原因是什么;
客服:系统登录不上了,是客户的问题还是系统的问题;
安全:谁访问了不该访问的数据。
然而要想从日志中获取这些信息,通常需要开发大量脚本和工 具,从头到底搭建端对端系统,并且为了保证服务可靠性和稳 定性,要做大量维护开发工作。阿里云自主研发的针对日志数 据的实时、大规模集中式管理服务SLS(Simple Log Service,简 单日志服务),能够提供一个从日志采集、过滤、处理、聚合到 在线查询的完整的海量日志处理平台,满足各种类型的日志处 理分析需求,减轻广大开发者的负担。
应用价值
SLS从2012年开始主要服务于阿里巴巴内部用户。后来随着外部用户对日志服务的需求越来越强烈,我们在2014年4月开始对外开放SLS的试用。为何用户对SLS有如此之高的需求,我们认为出于以下几方面的原因。
要基于数据分析结果做运营。根据日志数据,分析每个用户的行为轨迹(如何使用产品,在哪些使用场景下会遇到哪些问题等),对于改善产品设计思路和运营方向都很重要。
要定位细小问题。互联网化使得任何小问题被放大的概率大大增加。例如,有万分之五的失败率不足为奇,但在大促销等时间段内这个影响就会非常之大。日志服务有助于在较短时间内精准定位到一些细小的问题。
要快速响应用户需求。在用户反馈订单失败,或遇到错误,客服借助日志服务能马上找出问题,并尽快解决,这将极大提升用户满意度,以及对产品和服务的认可程度。
要降低研发成本。虽然可以通过开发信息系统(例如客服系统、运营记录系统)来满足运营和运维需求,但开发系统本身的时间、成本、维护负担等,都会影响企业的核心业务。而使用SLS,用户可以投入很少的研发成本,就能得到很好的日志服务。
为了便于理解,我们来看看用户是如何使用SLS的。小A创业开发了一个应用,有10台ECS,分别运行了App、Web服务器等。由于团队人数有限,他需要身兼运维、开发、运营等多种岗位职责于一身。于是小A借助于SLS来进行日志管理服务。
小A首先创建SLS Project,以及对应的日志类型(Category)和保存时间等选项(例如应用服务器、系统日志30天轮转,审计日志90天轮转)。
为了能收集应用日志,小A在SLS控制台上配置了描述日志路径及其格式(LogConfig),定义了每个应用的机器分组(Machine Group)。
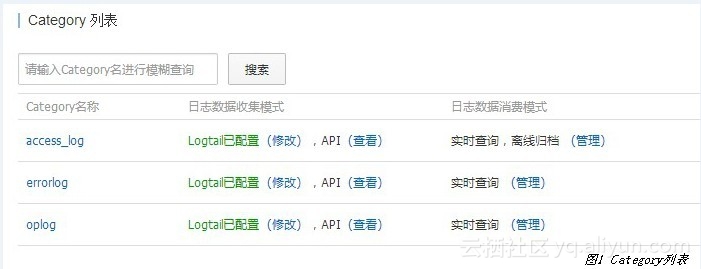
设置完成后,SLS客户端和服务端开始提供服务(小A配置了access_log、 errorlog和oplog三种日志见图1,并为access_log打开了MaxCompute的离线归档功能,以便进行离线分析)。阿里云数加大数据计算服务MaxCompute产品地址:https://www.aliyun.com/product/odps
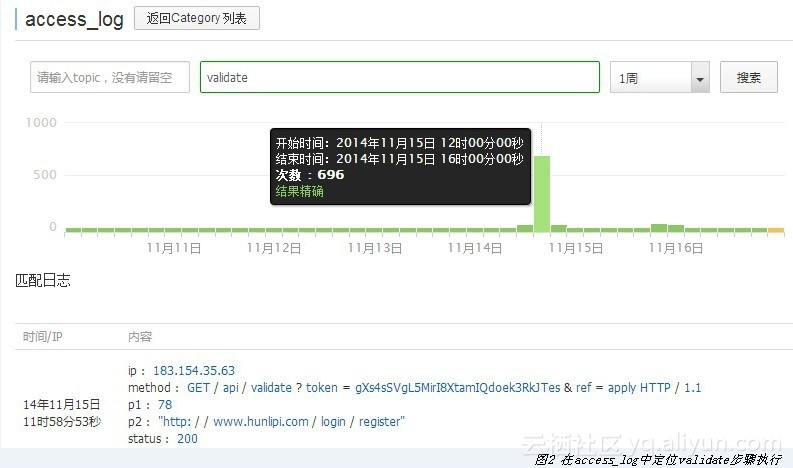
当需要查询日志时,既可以用API/SDK等方式进行调用,也可以通过SLS提供的控制台直接服务(例如在access_log中定位validate步骤执行见图2)。
小A的日志及其用途如下:
访问日志:通常在线系统的最前端都是Apache或者Nginx类的HTTP服务器,它的日志记录了不同用户在特定时间的访问行为。以下是一条常见的服务器访问日志。
213.60.233.243 - - [25/May/2004:00:17:09 +1200] "GET /internet/index.html HTTP/1.1" 200 6792 “http://www.aliyun-inc.com" "Mozilla/5.0 (X11; U; Linux i686; es-ES; rv:1.6) Gecko/20040413 Debian/1.6-5"
小A比较关心每天从www.aliyun.com过来的流量有多少。于是他在SLS中选中时间段,输入ref:“http://www.aliyun-inc.com”,控制台就能马上筛选出对应的访问日志和次数。
分析请求处理是否正常:在经过前端服务器处理后,请求会交由具体的后端服务进行处理。以下是Java应用服务的异常日志。
[2013-10-25 00:00:29 Production Mode] - GET /search_checked_form.htm/i25587486i ERROR c.a.c.w.impl.WebxRootControllerImpl - Full stack trace of the error TemplateNotFoundException: Could not find template "/screen/search_checked_form.htm/i25587486i" com.alibaba.citrus.service.pipeline.PipelineException: Failed to invoke Valve[#3/3, level 3]
日志中包含了错误发生的页面、传递的参数、错误发生的接口和具体错误堆栈等信息。小A通过查询“Level:ERORR”及其他关键词筛选每天的错误,并找到出错的地方进行修复。但在查询过程中难免会遇到因为日志不严谨引起的误伤情况,此时除了调整日志输出外,小A也可以通过在查询中加上not来排除这些已知原因。
是否有安全隐患或漏洞:在正常提供服务的同时,小A也十分关心是否有漏洞或者安全隐患可能对存储的数据或者其他敏感信息造成泄露。以下是用户登录时的访问日志。
2014-06-03 15:47:26&@#!abcusr_base4&@#!10.128.10.147&@#!&@#!def101500219
2014-06-03 15:47:26&@#!abcusr_base2&@#!10.128.10.47&@#!&@#!def70198810
2014-06-03 15:47:26&@#!jusrabc35u&@#!10.132.161.36&@#!&@#!wfp
日志中包含某个时间点用户从何处登录特定账号的记录。小A可以通过写一个监控程序调用SLS API获悉是否有紧急的异常登录行为。一般******会删除系统中的日志,但SLS实时收集日志的机制,能杜绝这种情况的发生。
服务器是否正常:在服务器运行期间,硬件或者系统可能出现各种各样的故障,通过系统日志(类似/var/log/messages)用户可以获悉是否有异常发生。
2013 Jun 8 23:01:01 Out of memory: Kill process 9682 (mysqld) score 9 or sacrifice child
Killed process 9682, UID 27, (mysqld) total-vm:47388kB, anon-rss:3744kB, file-rss:80kB
以上日志内容表明,mysqld进程由于内存使用超过内核限制而被kill。小A升级了ECS内存后,再次查询“kill” 或“out of memory”,就可以发现问题已经解决了。其实以上只是典型的在线服务系统的一部分日志,还有数据库、网络服务、文件系统等的日志能够帮助管理人员在出现问题时及时处理。6个月之后,小A的应用非常受欢迎,不仅数据量和机器数目随之增加,SLS服务能力也随之动态扩展。 除了以上例子外,我们还可以基于SLS的API进行二次开发,支撑运维、运营和客服等系统。让我们来看一下在阿里内部使用SLS的几个典型场景:
应用监控:得益于强大的日志收集和查询能力,飞天监控系统神农底层也是基于SLS开发的,现已成为各个集群标配(图3)。
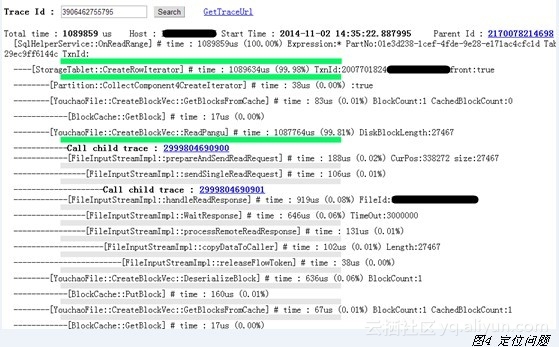
性能诊断分析:使用SLS日志收集和查询功能可以存储所有模块的请求日志,当发现服务问题时,只需输入RequestId进行查询,就能分析该请求的生命周期。例如系统记录到有一个请求超过10秒,需要快速找到最消耗的时间占据在哪台机器上、在哪个模块里、是哪个参数引起。以往需要各个应用进行调查,而现在输入RequestId,就能把问题找到(见图4)。
客服系统:基于SLS可以快速开发客服系统。CNZZ、RDS等控制台已经通过该方法向终端用户提供日志,让用户自主做查询和分析(见图5)。
SLS之所以具有如此全面的日志分析能力,和它与生俱来的基因分不开,即为解决阿里云的实践难题而生。下面就从SLS的“身世”开始,解析其背后的技术架构和核心优势。
创建初衷与研发过程
飞天系统研发初期,为了让系统顺利地运行起来,我们经常要面对“调试基本靠摸,运维基本靠人肉,解决Bug基本靠猜”的困境。为了解决这些问题,最直接的方法就是基于日志开发工具,以降低人力成本。刚开始两年中,我们开发了以下几种工具:
监控工具(神农):针对状态数据的采集和监控系统。
性能工具(Tracer):跨进程/机器跟踪请求在多台机器和进程中的执行情况和状态。
离线分析:将日志导入MaxCompute进行离线统计和分析。
虽然这些工具帮我们解决了很多问题,但每次面临新的业务场景时都需要重新搭建一套服务,重新部署一个脚本、写工具。这些工具背后用户真正的痛是什么? 我们发现,开发人员和运维人员的大部分时间和精力都耗费在定位和分析上。然而为什么开发环境(特别是分布式环境)调试会变得这么复杂呢?总体来讲,大致有以下几方面困难:
动态调度:由于计算和数据解耦,计算会被调度到不同的机器上,例如在系统中往往会有多个前端机处理各种请求,这使我们不得不查找所有机器定位特定问题。
跨模块依赖:在线系统的读取或写入,会从HTTP服务器开始,到在线系统的服务器,最后到文件系统的服务器,整个生命周期会与多个系统打交道。
分布式:数据分布在十几台机器上,查询一次失败的作业往往需要登录十几台机器。
规模与数据量:由于系统每秒钟会处理大量请求和数据,所以Log产生速度非常快。最痛苦的是问题快找到了,日志却被冲垮了,且系统盘SSD小型化使得这个问题更突出。
从以上几点看,异构系统、机器位置和数据量等都会使传统调试变得复杂,但问题的复杂性可以分解为以下几部分:
相关系统数
机器位置数
数据量
本身复杂性
要降低问题复杂度,理想的情况是将分布式和异构系统的调试降维成单机问题。那么是否可以给用户提供一种模式,让他像用单机一样来调试和诊断复杂系统呢? 于是我们开始研发SLS,解决思路是将日志集中起来,并提供一套简单而灵活的日志接口满足各类日志数据需求,优势在于:构建在飞天系统之上,天生就有扩展性;灵活易用,像瑞士×××一样适配各类日志需求。因此开发人员和运维人员只需将注意力放在具体的业务逻辑上,所有异构系统、机器等细节问题都由SLS服务解决,将所有机器上日志当成在一台机器上使用。
例如:有一个业务场景横向分布在3台机器(Machine1、Machine2和Machine3)上,纵向每台机器分别有三套服务运行(Scheduler、Executor和JobWorker)(图6)。
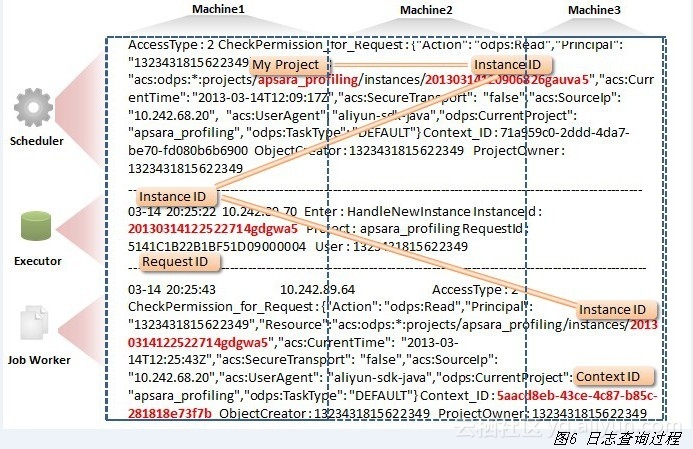
在SLS设计中,由于所有日志都已中心化存储,用户不需要再担心日志轮转、硬盘损坏等问题,也无需登录多台机器写任何脚本和处理程序。只需要输入指定查询条件(InstanceID:“2003…” and Project:“apsara_profiling”),SLS服务端会在秒级扫描指定时间段的所有日志数据,并且根据语义(and)对结果进行join,把符合条件的日志反馈给用户。此外,用户还能输入任意模块的任意条件进行查找,例如查找错误的GET请求,统计一个数据的访问行为等。
架构简析
从图7中可以清楚地看出SLS的架构思路。SLS服务端基于飞天服务模式开发,由伏羲(Fuxi)进行调度,存储基于盘古(Pangu)和OTS(开放结构化数据服务),在服务前端使用Nginx服务器进行Restful API托管。
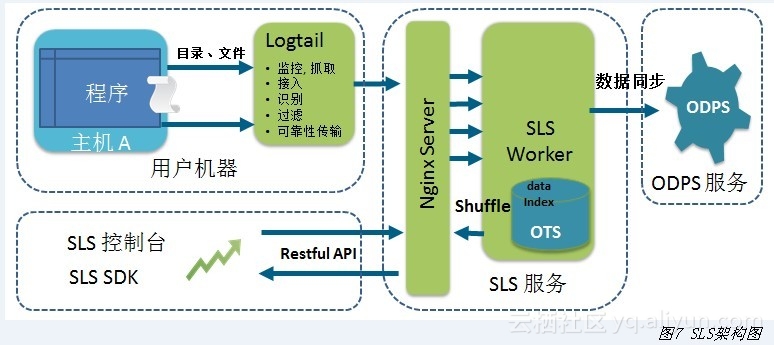
除服务端API外,SLS提供了SDK和客户端(Logtail)。Logtail对于SLS API进行了封装,将日志数据监控、抓取、过滤和可靠性传输等问题进行了处理,减少了用户收集日志的门槛。
考虑到伴随日志实时需求的同时,大部分用户会将日志用以离线分析,因此SLS服务端还提供了一种MaxCompute数据同步机制,能够将SLS中的数据定时归档到MaxCompute表中。因此对于日志而言,在线查询和离线分析的需求都能够简单地配置使用。为了服务用户这些需求,SLS有哪些挑战呢?举两个例子:
用户环境千差万别、日志多样化,如何保证日志收集稳定可靠?
例如,日志格式有几百种,如何来适配?如何从文件夹中筛选到特定模式的日志文件?日志什么时候开始写数据?日志轮转怎么处理?当网络发生闪断时,如何保证数据不丢?在用户写错程序输出大量日志后,如何保护Logtail不消耗过度的性能等?如何快速配置5000台机器的日志收集?
在过去两年中,我们花了大量时间从细节中学习,深入用户场景抽象日志变化的本质原因。在阿里内部SLS的客户端Logtail迭代了不下十几个版本,从场景覆盖和对于错误处理能力中积累了大量的经验,不断把使用体验做好,把错误处理做细。
以文件轮转为例,轮转过程中会出现边界丢少量日志的情况,同时操作系统的不同行为、日志轮转方法(按大小或时间)、轮转参数(时间命名、顺序编号、压缩等)等都会将这个问题复杂化。为此我们在操作系统文件层面之上抽象了轮转动作,定义了一套系统原语,能够追溯轮转的上下游关系和生命周期,能保证任何轮转方式都能灵活应对。
对于服务端,如何能够对一天几亿的日志进行实时存储和查询?
日志的数据量和规模通常是非常庞大的。对于一个100MB的日志文件,如果按每条100字节计算有一百万条。当这些日志被写入时,如何保证将日志产生到可以查询的时间控制在1分钟之内?当用户查询数据时,如何能在尽可能短的时间(例如2秒内)根据筛选条件在几千万数据中找到符合的日志?如何平衡性能和存储的成本?
针对这些问题,我们最主要的解决方法是采用分布式、批处理以及多级索引技术。由于日志大部分情况下是连续流格式,所以我们对相邻日志进行切块,每块数据内部通过bitmap和linkedlist进行索引存储,而块则通过倒排索引的方式建立。这样既能节省日志数据庞大的索引空间,又能在不影响索引速度的情况下保证查询质量。
核心优势
对日志研究是从20世纪80年×××始的,在各个领域内积累了丰富的经验,在安全、监控、运营分析等领域,也有不少关于日志的垂直化应用:
使用Splunk等日志服务。Splunk为日志解决方案提供较完整的解决方案,然而高昂的使用费及有限的免费数据量,加上传统软件部署方式使得其使用成本较高。而SLS在规模、性能和服务能力很不错,只是由于开发时间还不长,在查询丰富语义上还有较大提升空间,我们会不断完善SLS查询能力。
通过MySQL+Web Application搭建解决方案。MySQL在千万级以下作为存储非常理想,但超过该规模后,性能和稳定性等指标会直接下降。
开源阵营(Elastic Search+LogStash+Kibana)。利用第三方开源软件来搭建一套日志系统,维护和建设成本通常较高,并且ES依赖Lucene主要处理中长文档,面对日志这样的短文档,索引存储成本会比较高。而使用SLS可以减少开发时间及维护代价,简单地点几下配置,就能获得全面服务,并且具备弹性扩展能力。
此外,SLS在技术上还有以下亮点。
客户端
功能:支持正则表达式支持所有日志。
高性能:每秒十MB级别吞吐量(单Core)。
可靠性:处理网络中断,文件轮转,文件删除,新建日志等。
管理性:Web管理,自动推送,可部署上万台机器。
服务端
吞吐量:几十TB/天。
整体延时:日志产生后30秒可查询,最快5秒。
查询速度:1秒内过亿级别日志。
查询能力:and or not逻辑组合,支持键值以及全文两种查询模式。
可靠性:无单点,不丢失数据。
总结与展望
从2012年开始,SLS以一套标准化的接口进行支撑,逐步完善服务环节的各个功能,例如客户端管理、权限控制、增强服务的规模化管理能力。到目前为止,SLS每天接受千万级查询请求,处理百TB日志数据,可以为运维、开发、运营和安全等多个部门提供服务。例如在阿里云官网所有云产品的日志数据(ECS、RDS、OTS等)已经全部通过SLS进行管理。未来,我们会在使用体验和查询能力上不断进行优化,包括提供全套API让用户来自动化运维自己的集群,用户可以定义自己的日志模板、机器分组等信息,自动化管理所有产品的日志;提供更多的表达条件满足日志查询的需求。
转载于:https://blog.51cto.com/11778640/1907310
SLS:海量日志数据管理利器相关推荐
- Flume 海量日志收集利器
Flume 海量日志收集利器 关于日志收集 服务器日志收集 服务器日志是大数据系统中最主要的数据来源之一 服务器日志可能包含的信息 访问信息 系统信息 其他业务信息 基于服务器日志的应用 业务仪表盘: ...
- 海量日志收集利器 —— Flume
Flume 是什么? Flume是一个分布式.可靠.和高可用的海量日志聚合的系统,支持在系统中定制各类数据发送方,用于收集数据:同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的 ...
- 基于海量日志和时序数据的质量建设最佳实践
简介: 在云原生和DevOps研发模式的挑战下,一个系统从开发.测试.到上线的整个过程中,会产生大量的日志.指标.事件以及告警等数据,这也给企业质量平台建设带来了很大的挑战.本议题主要通过可观测性的角 ...
- GET日志服务如何使用让你获得建立DT时代海量日志处理能力
课程介绍 日志服务(Log Service,简称Log)是针对日志类数据一站式服务,在阿里巴巴集团经历大量大数据场景锤炼而成.用户无需开发就能快捷完成数据采集.消费.投递以及查询分析等功能,帮助提升运 ...
- 日志采集框架Flume以及Flume的安装部署(一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统)...
Flume支持众多的source和sink类型,详细手册可参考官方文档,更多source和sink组件 http://flume.apache.org/FlumeUserGuide.html Flum ...
- 海量日志数据分析与应用》场景介绍及技术点分析
摘要: 杭州云栖TI专场,大数据workshop:云数据·大计算-海量日志数据分析与应用 分享 接下来几个实验如下: 2.数据采集:日志数据上传 3.数据加工:用户画像 4.数据分析展现:可视化报表及 ...
- 容器日志采集利器Log-Pilot
容器时代越来越多的传统应用将会逐渐容器化,而日志又是应用的一个关键环节,那么在应用容器化过程中,如何方便快捷高效地来自动发现和采集应用的日志,如何与日志存储系统协同来高效存储和搜索应用日志.本文将主要 ...
- 日志分析利器splunk的搭建、使用、破解
2019独角兽企业重金招聘Python工程师标准>>> 日志分析利器splunk的搭建.使用.破解博主对splunk的了解不多,博主的使用目的是为了同步,分析日志.当初的搭建也是为了 ...
- ELK+Filebeat+Kafka+ZooKeeper 构建海量日志分析平台(elk5.2+filebeat2.11)
ELK+Filebeat+Kafka+ZooKeeper 构建海量日志分析平台 参考:http://www.tuicool.com/articles/R77fieA 我在做ELK日志平台开始之初选择为 ...
最新文章
- 读《瓦尔登湖》,寂寞的共鸣
- Python 09--多线程、进程
- JAVA的静态代理与动态代理比较--转载
- Vmware 中安装Unix
- html5大赛是什么,IE9开发大赛为HTML5打了一针兴奋剂
- 使用Java编写简单的老虎机游戏
- Linux 格式化磁盘命令mkfs
- 流批一体机器学习算法平台
- 流浪猫流浪狗H5完整运营源码下载/可封装APP
- 重磅!全球Top 1000计算机科学家h指数公布:中国53位学者上榜!
- 深信服环境SCSA环境遇到的问题(无法访问网站)
- windows上vscode 安装Fortran-language-server
- 使用MATLAB进行图像处理——显示图像的灰度直方图并进行对比度增强
- (简单有效)vivo手机怎么不root激活Xposed框架
- wireshark数据包流量分析
- 我对计算机最感兴趣作文300,电脑让我欢喜让我忧作文300字
- 一个屌丝程序猿的人生(九十一)
- 为什么亿级数据量时要使用位图?位图和布隆过滤器有什么关系?
- ChinaNet无线接入后,浏览器自动跳转到登陆界面的原理
- 征信与风控,这两者千万别搞混了