多类SVM的损失函数
原文:Multi-class SVM Loss
作者: Adrian Rosebrock
翻译: KK4SBB 责编:何永灿
from: http://geek.csdn.net/news/detail/101547
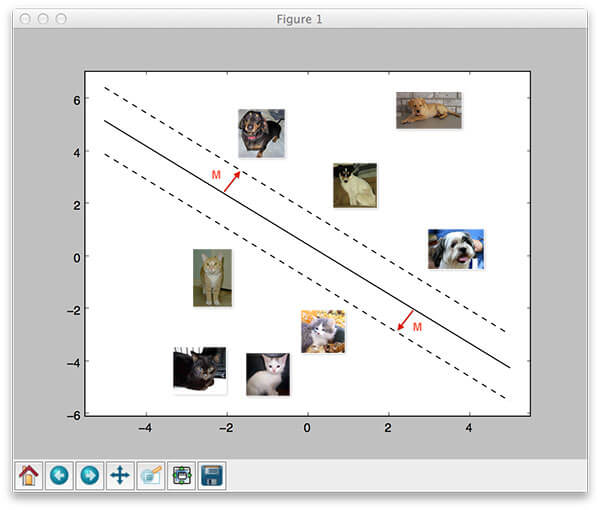
几个星期之前,我们讨论了线性分类和参数化学习的概念。这类学习方法使我们能够输入一组数据和类别标签,然后从中学到一个从输入值到预测值的映射关系,而我们只需要定义一组参数并优化这些参数。
我们本篇线性分类器教程主要关注评分函数的概念和它的用法。但是,为了真的“学会”输入值和类别标签的映射关系,我们需要讨论下面两个重要的概念:
- 损失函数
- 优化方法
在本周和下周的文章中,我们会讨论两类常见的损失函数,它们在机器学习、神经网络和深度学习算法中都被应用:
- 多类SVM损失
- 交叉熵(用于Softmax分类器/多项式逻辑回归)
接下来,我们就讨论多类SVM损失。
多类SVM损失
用最简单的方式来解释,损失函数就是用来衡量一个预测器在对输入数据进行分类预测时的质量好坏。
损失值越小,分类器的效果越好,越能反映输入数据与输出类别标签的关系(虽然我们的模型有时候会过拟合——这是由于训练数据被过度拟合,导致我们的模型失去了泛化能力)。
相反,损失值越大,我们需要花更多的精力来提升模型的准确率。就参数化学习而言,这涉及到调整参数,比如需要调节权重矩阵W或偏置向量B,以提高分类的精度。确切地说,我们如何去更新这些参数属于优化问题,我们这一系列的教程的后续篇幅将会覆盖这些话题。
多类SVM损失背后的数学问题
在阅读完Python的线性分类教程之后,你会发现我们选用的分类器是线性支持向量机(linear SVM)。
上一篇教程着重介绍了评分函数f的概念,它把我们的特征向量映射为数值型的类别标签。如其名称所示,线性SVM采用简单的线性映射:
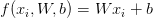
现在我们有了评分/映射函数f,我们需要确定这个函数预测的质量(给定权重矩阵W和偏置向量b)是“好”还是“坏”。
为了完成这一目标,需要定义一个损失函数。接着,我们就来给损失函数下一个定义。
基于之前的线性分类器教程,我们知道当前有一个特征向量矩阵x —— 这些特征向量可以从颜色直方图中获取,也可以是HOG特征,或者甚至是原始像素值。
无论我们如何选择量化图像,我们都能从图像数据集中抽取出一个特征矩阵x。然后,我们可以用xi获取某张图片的第i维特征,也就是x的第i个特征向量。
同样的,我们也有一个向量y,存储了每个x的类别标签。这些y值是我们的参照标签,正是我们希望评分函数能够准确预测的标签值。就像我们可以用xi得到某个特征向量,我们也可以用yi读取第i个类别标签。
为了简化,我们将评分函数简写为s:
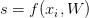
第i个数据的第j类预测得分值可以表示为:

按照上述定义,我们将它代入公式,得到了hinge损失函数:
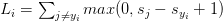
注意:我先故意略过正则化参数项。在后续的文章中,当我们理解了损失函数,我会再来介绍正则化。
那么,上面那个方程究竟有什么用途?
我很高兴你能提出这样的问题。
简单来说,hinge损失函数将预测不正确的类别( )累加,然后将我们评分函数s在第j类(不正确类别)的输出值与在第yi类的输出值比较。
)累加,然后将我们评分函数s在第j类(不正确类别)的输出值与在第yi类的输出值比较。
然后应用max函数,使得函数的输出值不小于0 —— 这一点非常重要,因而输出不会出现负值。
若Li=0,说明给定的数据xi被正确分类了(我在后续的章节中会举一个例子)。
当把损失值推广到整个训练数据集,我们对所有的Li取平均数:
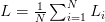
此外,常用的损失函数还有平方hinge损失:

平方项对损失值的惩罚力度更大。
至于选用何种损失函数,这需要视数据集而定。标准的hinge损失函数比较常见,但某些数据集可能使用平方项能取得更好的精度 —— 总之,这是一个需要你交叉验证的超参数。
多类SVM损失示例
现在,再来讨论hinge损失和平方hinge损失的数学原理,以下面的问题为例。
我们再一次选用Kaggle的狗vs.猫数据集,即判断指定图片里包含了猫还是狗。
这个数据集中只包含了两种可能的类别标签,因此属于二分类问题,可以用标准的二项SVM损失函数求解。也就是说,我们仍然使用多类SVM损失,所以我们可以有一个成功实践的例子。然后,我会扩展示例来处理三种类别的问题。
首先,看看下面的图片,图片是来自“狗vs.猫”数据集的两个训练样本:

图1:对图像选用hinge损失
给定任意的权重矩阵W和偏置向量b,f(x,W)=Wx+b函数的输出分数如上表所示。分数值越大,说明我们的评分函数对预测结果的置信度越高。
我们先来计算“狗”类的损失值Li。假设一个二分类问题,这就非常容易:
>>> max(0, 1.33 - 4.26 + 1)
0
>>>
请注意“狗”的损失值为啥等于零 —— 意思是正确地预测了狗的类别。快速地回顾上述图1所示的内容:“狗”的分值大于“猫”的分值。
同样的,我们对第二张图像采取相同的做法,这张图片包含了一只猫:
>>> max(0, 3.76 - (-1.2) + 1)
5.96
>>>
损失函数的输出值大于零,意味着我们的预测结果不正确。
我们计算两张图片的损失值的均值作为整体损失值:
>>> (0 + 5.96) / 2
2.98
>>
对于二分类问题,计算过程非常简单,那对于三分类问题呢?过程会变得复杂吗?
事实上,并没有复杂 —— 下图是一个三类问题的示例,我新加入了一个类别“马”:

图2:hinge损失在三类图片的分类问题上的应用。
再次计算“狗”这一类的损失值:
>>> max(0, 1.49 - (-0.39) + 1) + max(0, 4.21 - (-0.39) + 1)
8.48
>>>
请注意我们是如何将求和部分扩展到两项计算的 —— 分别计算“狗”类的预测得分与“猫”类和”马”类分值的差。
同样的,计算”猫”这一类的损失值:
>>> max(0, -4.61 - 3.28 + 1) + max(0, 1.46 - 3.28 + 1)
0
>>>
最后,计算”马”这一类的损失值:
>>> max(0, 1.03 - (-2.27) + 1) + max(0, -2.37 - (-2.27) + 1)
5.199999999999999
>>>
因此,整体损失值是:
>>> (8.48 + 0.0 + 5.2) / 3
4.56
>>>
正如你所看到的,它们都适用同样的原则 —— 只要记住在扩展类别数目的同时,求和的项数也要扩展。
测验:根据上面三类的损失值判断,哪一类是正确的预测值?
我需要动手实现多类SVM损失值计算吗?
如果你愿意,也可以动手实现hinge和平方hinge损失值 —— 但这主要还是出于学习的目的。
你几乎可以在所有的机器学习/深度学习库里找到hinge损失和平方hinge损失的实现,比如scikit-learn, Keras, Caffe等等。
总结
今天我们讨论了多类SVM损失的概念。给定一个评分函数(将输入数据映射到输出的类别标签),我们的损失函数可以用来定量评判评分函数预测正确类别标签质量的“好”与“坏”。
损失值越小,我们的预测越准确(但存在过拟合的风险,映射函数过于拟合了输入数据)。
相反,损失值越大,我们的预测结果越不准确,因此需要继续优化参数W和b —— 当我们更深入地理解损失函数之后,后续文章会介绍优化方法。
理解“损失”的概念以及它在机器学习和深度学习算法中的应用之后,我们仔细研究了两类损失函数:
- hinge损失函数
- 平方hinge损失函数
通常,hinge损失更常见 —— 但仍然需要调优分类器的超参数来判断哪种损失函数更适合你的数据集。
多类SVM的损失函数相关推荐
- 多类 SVM 的损失函数及其梯度计算
CS231n Convolutional Neural Networks for Visual Recognition -- optimization 1. 多类 SVM 的损失函数(Multicla ...
- 高斯核函数python代码_单类SVM:SVDD
话接上文(SVM的简单推导),这篇文章我们来看单类SVM:SVDD.可能大家会觉得很奇怪,我们为什么需要单分类呢?有篇博客举了一个很有意思的例子. 花果山上的老猴子,一生阅猴无数,但是从来没有见过其它 ...
- 机器学习中SVM的损失函数,向量积
SVM即支持向量机(Support Vector Machine, SVM) 是一类按监督学习(supervised learning)方式对数据进行二元分类的广义线性分类器(generalized ...
- matlab中svm testacc参数,使用Matlab进行交叉验证的多类SVM的完整示例
我目前正在混淆使用Matlab实现带有交叉验证的SVM. stackoverflow上有很多帖子提到了有关SVM及其交叉验证的信息;然而,即使使用最简单的'fisheriris'数据集也没有完整的例子 ...
- 机器学习基础(四十二)—— 常用损失函数的设计(multiclass SVM loss hinge loss)
损失函数,又叫代价函数(成本函数,cost function),是应用优化算法解决问题的关键. 1. 0-1 损失函数 误分类的概率为: P(Y≠f(X))=1−P(Y=f(X)) P(Y\neq f ...
- Python搭建SVM
目录 1.线性分类器 2.损失函数 Loss function 多类支持向量机损失(Multiclass Support Vector Machine Loss) 损失函数(Softmax分类器): ...
- 【深度学习】cs231n计算机视觉 SVM分类器
线性分类 上篇对于图像分类问题实践了 k-Nearest Neighbor (k-NN)分类器,该分类器的基本思想是通过将测试图像与训练集带标签的图像进行比较,来给测试图像打上分类标签.k-Neare ...
- 图像的线性分类器(感知机、SVM、Softmax)
本文主要内容为 CS231n 课程的学习笔记,主要参考 学习视频 和对应的 课程笔记翻译 ,感谢各位前辈对于深度学习的辛苦付出.在这里我主要记录下自己觉得重要的内容以及一些相关的想法,希望能与大家 ...
- 最优化基础:损失函数可视化、折页损失函数 梯度计算
本文主要内容为 CS231n 课程的学习笔记,主要参考 学习视频 和对应的 课程笔记翻译 ,感谢各位前辈对于深度学习的辛苦付出.在这里我主要记录下自己觉得重要的内容以及一些相关的想法,希望能与大家 ...
最新文章
- 国内首个面向工业级实战的点云处理课程
- SpringCloud Gateway配置自定义路由404坑
- 中国联通4G携号转网业务支撑的架构实践
- opencv3错误集锦(四)——Rect函数参数引发的异常中断
- 转载 Linux新人科普
- 上班要了解的一些法律条例
- 程序猿软件开发保护眼睛,win7设置窗口护眼模式?
- Cocos2d-X 3.x的具体配置详解
- 2022.06青少年软件编程(Python)等级考试试卷(四级)
- 截图并使用libjpeg库压缩BMP为JPG与将JPG转换为BMP
- 记录mysql中如何统计日周月季度年
- Self-Supervised Gait Encoding with Locality-Aware Attention for Person Re-Identification阅读
- 用ps羽化图片边缘(两种羽化图片边缘的方法)
- 芝加哥犯罪率数据集(数据分析与特征处理)
- 2021-09-23记录下wifi调试流程
- 快递管理系统项目整理
- Bugku:杂项 爆照(08067CTF)
- React从零开始搭建项目
- window.navigator详解和使用场景
- SKLEARN-3-随机森林