初学Python——文件操作第三篇
一、引言
什么?有了第二篇文件操作还不够?远远不够!而且在读完第三篇文件操作还是不够。关于文件的操作,后续的学习中将不断学习新的操作方式,使用更加合适的方法。
进入正题,上一篇讲到,Python对文件最基本的读取写入操作,都必须是字符串,所有的数据必须要转化成字符串写入,都出来的也全部都是字符串,这会给我们实际应用中造成一些困扰,上一篇文章讲述了如何使用eval()函数,但是也有局限性,比如:字符串格式稍有错误(结尾带有换行符\n)就会转换出错;写入文件之前在内存中的int型数据,写入读取仔eval后无法变回int型等。因此,我们需要更加标准、更加合理的方法来完成文件读写。
接下来将一一介绍四个模块:json, pickle, shelve, shutil
先将个概念:序列化。即将内存中各种类型的数据转成能够写入文件的格式的标准过程。反序列化是序列化的反过程。
二、json模块
json模块提供一些功能,能够处理简单的数据类型:布尔型、(长)整形、字符型、浮点型等,以及列表、字典等。将这些类型的数据通过序列化即可写入文件,读取文件时通过反序列化即可在内存中正常使用。json是可以跨平台使用的,python、java等语言都可以使用它,并进行不同语言之间的数据交互。
1、dumps() 和 loads() 方法
1 import json # 导入json模块
2
3 kwargs={
4 "name":"Alex",
5 "age":21,
6 }
7 args=[1,6,8,4]
8 acer="woshishei"
9
10 f=open("序列化","w",encoding="utf-8")
11 f.write(json.dumps(kwargs)) # 将字典序列化写入文件
12 f.write("\n")
13 f.write(json.dumps(args)) # 将列表序列化写入文件
14 f.write("\n")
15 f.write(json.dumps(acer)) # 将字符串序列化写入文件
16 f.write("\n")
17 f.close()
18 print(type(json.dumps(args))) #输出序列化后的类型
19
20 f=open("序列化","r",encoding="utf-8")
21 data=f.readlines() #读取文件
22 f.close()
23 for i,j in enumerate(data):
24 data[i]=json.loads(j) # 逐个反序列化
25 print(data[0]) # 输出
26 print(data[1])
27 print(data[2])
28 print(data[0]["age"])
29 print(data[1][1])运行结果:
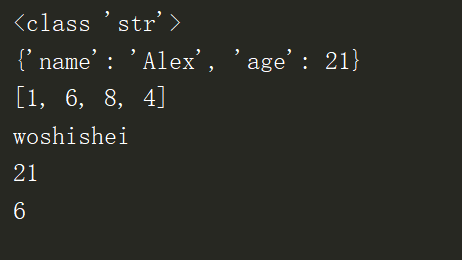
运行结果显示: json序列化就是将其转化成字符串(标准、规范的操作)
2、dump() 和 load() 方法
上面了解到,序列化的语句是 json.dumps(<被转化变量>),反序列化语句是 json.loads(<从文件读出的数据>)
同时也应该注意到,我是一行一行写读的,一个数据写一行,一行绝对不能写两个数据。
dump() 和 load() 只是写法不同,功能是一样的
f=open("序列化","w",encoding="utf-8")
json.dump(kwargs,f)
f.close()f=open("序列化","r",encoding="utf-8")
data=json.load(f) #读取文件并将其反序列化
f.close()有了json模块,可以很方便地在内存中复原数据。
三、pickle模块
pickle模块和json模块的功能基本相同。不同点是:pickle模块不能跨平台使用,是Python专用的模块,但是可以使用复杂的数据类型,函数等都可以。
1、dumps() 和 loads() 方法
import picklef=open("序列化","wb") #如果用pickle,必须用二进制文件的打开方式
f.write(pickle.dumps(kwargs)) #与json完全一样的操作
f.close()
print(type(pickle.dumps(kwargs))) #将数据类型转化成何种类型
f=open("序列化","rb")
data=pickle.loads(f.read()) # 反序列化
f.close()
print(data["age"])运行结果:

结果显示,pickle序列化后,将数据转化成bytes类型。
2、dump() 和 load() 方法
def text(name):print("hello,",name)kwargs={"name":"Alex","age":21,"function":text
}f=open("序列化","wb")
pickle.dump(kwargs,f)
f.close()f=open("序列化","rb")
data=pickle.load(f)
f.close()
data["function"]("alex")结果:
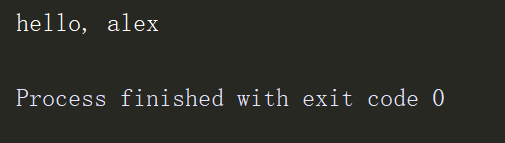
运行结果证明,函数被序列化写入文件,并成功反序列化回来,运行无误。
对于反序列化来说,如果反序列化操作在另外一个程序,读取之前写入的函数时会报错。因为序列化的程序在结束时函数已经不存在。
如果想要在反序列化的程序里正常使用,只能从原来的文件里copy函数过来。
新建一个.py文件,测试一下:
f=open("序列化","rb")
data=pickle.load(f)
f.close()
data["function"]("alex")
程序报错!
在这里强调一点:json序列化写入文件的时候,可以将多个数据分行写入;但是pickle序列化则不可以,一个数据只能写入一个文件!
四、shelve模块
shelve模块是一个将内存数据通过文件持久化的模块,可以持久化任何pickle可支持的Pyhton模块。可以理解是对pickle更高一层的封装,能够非常方便地写入和读取数据。
1 import shelve
2 import datetime
3
4 info={"age":22,"sex":"man"}
5 name=["hello","good","nice"]
6
7 # 写入文件
8 d=shelve.open("shelve_text") # 打开一个文件
9 d["name"]=name # 持久化列表
10 d["info"]=info # 持久化字典
11 d["date"]=datetime.datetime.now() # 持久化时间
12 d.close()
13
14 # 读取文件
15 d=shelve.open("shelve_text")
16 a=d.get("name")
17 b=d.get("info")
18 c=d.get("date")
19 d.close()
20
21 print(a)
22 print(b)
23 print(c)运行结果:

完美运行。可以看到,shelve模块读写文件的操作更加简洁方便。
五、shutil模块
更高级的操作来了——shutil模块。不过,它不止能对普通文件操作,还可以处理文件夹和压缩包。
1.普通文件、文件夹操作部分:
import shutilf1=open("text1","r",encoding="utf-8")
f2=open("text2","w",encoding="utf-8")
shutil.copyfileobj(f1,f2) # 将文件内容拷贝到另一个文件中(必须先打开文件才能操作)
f1.close()
f2.close()运行情况就不上图了,可以自己试一下。
还有丰富的操作手法:
1 shutil.copyfile("text1","text3") # 不需要打开文件,直接复制文件(如果有文件直接覆盖,如果没有文件则创建)
2
3 shutil.copymode("text1","text2") # 仅拷贝权限,内容、组、用户均不拷贝
4 shutil.copystat("text1","text2") # 拷贝状态的信息,不拷贝内容
5
6 shutil.copy("text1","text2") # 将文件和权限都复制过来(源代码中:copy == copyfile + copymode )
7
8 shutil.copy2("text1","text2") # 将文件和状态信息拷贝(源代码中:copy2 == copyfile + copystat )
9
10 shutil.copytree("package2","new_package2") # 递归地去拷贝文件(复制文件夹)
11
12 shutil.rmtree("new_package2") # 删除一个文件夹
13
14 shutil.move("F:\\Pythonfiles\\day5\\package2","D:\\") # 移动文件(夹)的位置( 旧路径(完整)-->新路径(父目录) )
15 shutil.move("D:\\package2","F:\\Pythonfiles\\day5")2.压缩包操作部分:
① shutil.make_archive() 方法:创建压缩包并返回路径,
参数:
base_name:压缩包名,也可以是压缩包路径。如果只是名称,默认当前路径
format:压缩包格式,"zip","tar","bztar","gztar"
root_dir:被压缩文件的路径,默认当前路径
owner:用户,默认当前用户
group:组,默认当前组
logger:用于记录日志,通常是logging.Logger对象
#res=shutil.make_archive("压缩包","zip","package2") #如果多次执行此语句,将覆盖同名压缩包
#print("路径是:",res)#res1=shutil.make_archive("压缩包2","zip","packaged")
#print("路径2是",res1)② shutil对压缩包的操作是通过 zipfile 和 tarfile 两个模块来完成的:
先说zipfile:
import zipfile#压缩文件
z=zipfile.ZipFile("压缩包.zip","a") #打开压缩包
z.write("text1")
z.write("random_module.py")
z.write("asdf.xlsx")
z.write("135456.txt")
z.close() #关闭压缩包'''
"w"方式打开并写入,会覆盖包内所有的文件
"a"方式可以追加文件,但需要注意的是,不能重复写入同名文件,否则会报错
'''#解压文件
z=zipfile.ZipFile("压缩包.zip","r")
#z.extractall() #将所有文件解压到当前路径下
z.extractall("wooo") #将所有文件解压到指定路径下
z.extract("asdf.xlsx","解压") #将指定文件解压(参数:member成员,path默认当前路径)
print(zipfile.ZipFile.namelist(z)) #输出文件列表
print(z.namelist()) #输出文件列表
z.close()
#在使用zipfile文件句柄z时,跟open打开文件不同,没有光标这种概念print(zipfile.is_zipfile("压缩包.zip")) #判断文件是不是压缩文件有兴趣可以在自己电脑上测试。
再讲tarfile:
import tarfile# 压缩
tar = tarfile.open('your.tar','w')
print(help(tar.add))
tar.add('135456.txt',arcname="bbs2") # arcname="bbs2" 为存档的文件指定别名
tar.add('asdf.xlsx',arcname="cmdb")
tar.close()# 解压
tar = tarfile.open('your.tar','r')
tar.extractall("waaa") # 可设置解压地址
tar.close()六、chardet模块
可以智能检测编码,第三方模块,需要安装。
在命令行直接输入 pip3 install chardet 即可安装
使用:


import chardetf = open("文件","rb")
data = f.read()
f.close()res = chardet.detect(data)
printf(res)View Code
结果:{'encoding': 'GB2312', 'confidence': 0.99, 'language': 'Chinese'}
confidence翻译过来是自信程度,0.99,类似于机器学习
初学Python——文件操作第三篇相关推荐
- 初学Python——文件操作第二篇
前言:为什么需要第二篇文件操作?因为第一篇的知识根本不足以支撑基本的需求.下面来一一分析. 一.Python文件操作的特点 首先来类比一下,作为高级编程语言的始祖,C语言如何对文件进行操作? 字符(串 ...
- python的难点_初学python的操作难点总结(新手必看篇)
如下所示: 1 在cmd下 盘与盘之间的切换 直接 D或d: 就好 2 查找当前盘或者文件下面的目录 直接 dir 3 想在一个盘下进去一个文件夹,用cd空格目标文件 cd p 4 写文件的第一个字母 ...
- python新手入门总结_初学python的操作难点总结(新手必看篇)
如下所示: 1 在cmd下 盘与盘之间的切换 直接 D或d: 就好 2 查找当前盘或者文件下面的目录 直接 dir 3 想在一个盘下进去一个文件夹,用cd空格目标文件 cd p 4 写文件的第一个字母 ...
- 看了这篇,你也是Python文件操作高手
Python文件操作 文本文件和二进制文件 文件操作相关模块概述 创建文件对象 open() 文本文件的写入 基本的文件写入操作 常用编码介绍 ASCII ISO8859-1 GB2312,GBK,G ...
- Python文件操作学习总结
Python读写文件 1.open 使用open打开文件后一定要记得调用文件对象的close()方法.比如可以用try/finally语句来确保最后能关闭文件. file_object = open( ...
- python文件操作实验总结,[干货分享]Python文件操作技巧总结
引言 小伙伴们,今天给大家讲解一下python程序下的文件操作完整技巧梳理,都是笔者总结的干货.通过本文阅读,不仅可以带来生产力提升,也可以开发小脚本为生活带来乐趣. 首先不知道大家对 ...
- 不是python文件操作的相关函数_从零开始学Python(七):文件存储I/O流和异常捕捉
这两天在搞小程序开发,耽搁了一下更新的进度,今天补上.一个完整的前端程序肯定离不开数据存储和网络两个模块,今天我们就先来讲讲python中的一种常见数据存储:文件存储!~! 文件存储(I/O操作) 何 ...
- 简述python文件操作的流程_Python文件操作详解
这篇文章主要介绍了Python 文件操作的详解及实例的相关资料,希望通过本文大家能够理解掌握Python 文件操作的知识,需要的朋友可以参考下 Python 文件操作的详解及实例 一.文件操作 1.对 ...
- python关闭读写的所有的文件-Python文件操作:文件的打开关闭读取写入
Python文件操作:文件的打开关闭读取写入 一.文件的打开关闭 Python能以文本和二进制两种方式处理文件,本文主要讨论在Python3中文本文件的操作. 文件操作都分为以下几个步骤: 1.打开文 ...
最新文章
- 事件控制寄存器(AFIO_EVCR) (2011-09-09 13:51:58)
- 巧断梯度:单个loss实现GAN模型(附开源代码)
- java nio 阻塞_Java NIO和传统阻塞IO
- Java日历的getMinimalDaysInFirstWeek()方法和示例
- pptx打不开,未安装该文件类型的文本转换程序~[解决方案]
- c++注释快捷键_JAVA编程中你一定要掌握的“快捷键”
- 马云欣赏你,你的创业就已成功了一半
- Ubuntu 下升级git到最新版
- android studio乱码
- Redis缓存组件开发规范
- 64.Linux/Unix 系统编程手册(下) -- 伪终端
- python cls方法_Python 中的 __new__(cls)方法详解
- Spring boot 集成Quartz,实现Job注入bean
- Centos 7.5 1804 镜像下载
- 如何让大脑更强大?打造最强大脑的5个关键要素
- linux连接小米随身wifi密码忘记了,小米路由器无线密码(wifi密码)忘记了怎么办?...
- 微信网页扫码登录与微信公众号授权登录的区别
- 在LINUX中安装Berkeley DB
- 【技能】小白耳机维修入门--各种耳机插头接线图--耳机维修汇总贴
- 好听的英文歌推荐 必备(亿买网整理)