以下用于数据存储领域的python第三方库是-『爬虫四步走』手把手教你使用Python抓取并存储网页数据!...
第一步:尝试请求
首先进入b站首页,点击排行榜并复制链接
https://www.bilibili.com/ranking?spm_id_from=333.851.b_7072696d61727950616765546162.3
现在启动Jupyter notebook,并运行以下代码
import requests
url = 'https://www.bilibili.com/ranking?spm_id_from=333.851.b_7072696d61727950616765546162.3'
res = requests.get('url')
print(res.status_code)
#200
在上面的代码中,我们完成了下面三件事
导入
requests
使用
get方法构造请求
使用
status_code获取网页状态码
可以看到返回值是200,表示服务器正常响应,这意味着我们可以继续进行。
第二步:解析页面
在上一步我们通过requests向网站请求数据后,成功得到一个包含服务器资源的Response对象,现在我们可以使用.text来查看其内容

可以看到返回一个字符串,里面有我们需要的热榜视频数据,但是直接从字符串中提取内容是比较复杂且低效的,因此我们需要对其进行解析,将字符串转换为网页结构化数据,这样可以很方便地查找HTML标签以及其中的属性和内容。
在Python中解析网页的方法有很多,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml,本文将基于BeautifulSoup进行讲解.
Beautiful Soup是一个可以从HTML或XML文件中提取数据的第三方库.安装也很简单,使用pip install bs4安装即可,下面让我们用一个简单的例子说明它是怎样工作的
from bs4 import BeautifulSoup
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
title = soup.title.text
print(title)
# 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
在上面的代码中,我们通过bs4中的BeautifulSoup类将上一步得到的html格式字符串转换为一个BeautifulSoup对象,注意在使用时需要制定一个解析器,这里使用的是html.parser。
接着就可以获取其中的某个结构化元素及其属性,比如使用soup.title.text获取页面标题,同样可以使用soup.body、soup.p等获取任意需要的元素。
第三步:提取内容
在上面两步中,我们分别使用requests向网页请求数据并使用bs4解析页面,现在来到最关键的步骤:如何从解析完的页面中提取需要的内容。
在Beautiful Soup中,我们可以使用find/find_all来定位元素,但我更习惯使用CSS选择器.select,因为可以像使用CSS选择元素一样向下访问DOM树。
现在我们用代码讲解如何从解析完的页面中提取B站热榜的数据,首先我们需要找到存储数据的标签,在榜单页面按下F12并按照下图指示找到
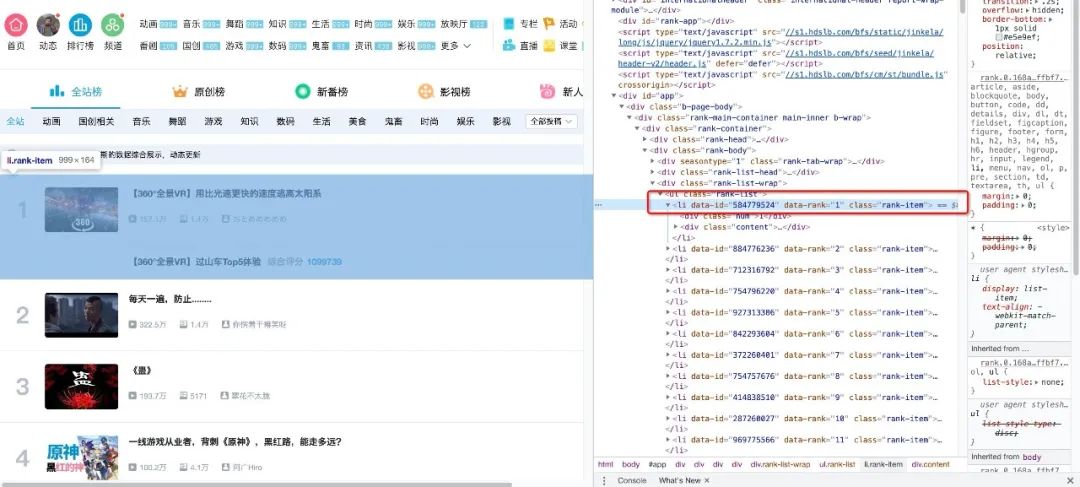
可以看到每一个视频信息都被包在class="rank-item"的li标签下,那么代码就可以这样写�
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
在上面的代码中,我们先使用soup.select('li.rank-item'),此时返回一个list包含每一个视频信息,接着遍历每一个视频信息,依旧使用CSS选择器来提取我们要的字段信息,并以字典的形式存储在开头定义好的空列表中。
可以注意到我用了多种选择方法提取去元素,这也是select方法的灵活之处,感兴趣的读者可以进一步自行研究。
第四步:存储数据
通过前面三步,我们成功的使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel中保存即可。
如果你对pandas不熟悉的话,可以使用csv模块写入,需要注意的是设置好编码encoding='utf-8-sig',否则会出现中文乱码的问题
import csv
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
如果你熟悉pandas的话,更是可以轻松将字典转换为DataFrame,一行代码即可完成
import pandas as pd
keys = all_products[0].keys()
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
小结
至此我们就成功使用Python将b站热门视频榜单数据存储至本地,大多数基于requests的爬虫基本都按照上面四步进行。
不过虽然看上去简单,但是在真实场景中每一步都没有那么轻松,从请求数据开始目标网站就有多种形式的反爬、加密,到后面解析、提取甚至存储数据都有很多需要进一步探索、学习。
本文选择B站视频热榜也正是因为它足够简单,希望通过这个案例让大家明白爬虫的基本流程,最后附上完整代码
import requests
from bs4 import BeautifulSoup
import csv
import pandas as pd
url = 'https://www.bilibili.com/ranking?spm_id_from=333.851.b_7072696d61727950616765546162.3'
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
### 使用pandas写入数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
以下用于数据存储领域的python第三方库是-『爬虫四步走』手把手教你使用Python抓取并存储网页数据!...相关推荐
- python抓取内存中的网页_『爬虫四步走』手把手教你使用Python抓取并存储网页数据!...
爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取我们想要的数据,本文将基于爬取B站视频热搜榜单数据并存储为例,详细介绍Python爬虫的基本流程.如果你还在入门爬虫 ...
- 『爬虫四步走』手把手教你使用Python抓取并存储网页数据!
爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取我们想要的数据,本文将基于爬取B站视频热搜榜单数据并存储为例,详细介绍Python爬虫的基本流程.如果你还在入门爬虫 ...
- java使用xml存储数据_『爬虫四步走』手把手教你使用Python抓取并存储网页数据!
菜鸟学Python 以下文章来源于早起Python ,作者刘早起 爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取我们想要的数据,本文将基于爬取B站视频热搜榜单数据 ...
- 『爬虫四步走』手把手教你使用 Python 抓取并存储网页数据!
爬虫是 Python 的一个重要的应用,使用 Python 爬虫我们可以轻松的从互联网中抓取我们想要的数据 本文将基于爬取 B 站视频热搜榜单数据并存储为例,详细介绍 Python 爬虫的基本流程. ...
- java使用xml存储数据_「爬虫四步走」手把手教你使用Python抓取并存储网页数据
爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取我们想要的数据,本文将基于爬取B站视频热搜榜单数据并存储为例,详细介绍Python爬虫的基本流程.如果你还在入门爬虫 ...
- python抓取pc端数据_「爬虫四步走」手把手教你使用Python抓取并存储网页数据!...
爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取我们想要的数据,本文将基于爬取B站视频热搜榜单数据并存储为例,详细介绍Python爬虫的基本流程.如果你还在入门爬虫 ...
- 手把手教你python实现量价形态选股知乎_【手把手教你】Python实现量价形态选股...
来源:雪球App,作者: Python金融量化,(https://xueqiu.com/1444657641/139331726) 01引言 在股票市场上,一切交易行为的成功皆为概率事件,交易获利的核 ...
- 手把手教你用python抢票_又没抢到票?手把手教你用python抢票回家过年…
原标题:又没抢到票?手把手教你用python抢票回家过年- 最近朋友圈刷屏:我又没抢到票!哭! 憋急,教程在此,有人愿意尝试吗? 先看看如何快速查看剩余火车票? 作者 protream 原文:http ...
- python中字典的value可以为任意对象_手把手教你学Python之字典
字典是一种无序可变的容器,字典中的元素都是"键(key):值(value)"对, "键"和"值"之间用冒号隔开,所有"键值对&qu ...
最新文章
- C语言程序设计 | 结构体内存对齐,位段
- 花式模拟【栈结构】做“日志分析”(洛谷P1165题题解,Java语言描述)
- vs2005 c# mysql_在VS2010中怎样用C#创建数据库联接并执行sql语句 最好举个例子讲一下...
- 老人为什么要去依靠曾经不喜欢的子女去为她养老?
- Python3+Selenium3+Unittest+ddt+Requests 接口自动化测试框架
- 常见的php后门,有趣的PHP后门
- Linux - vim安装 配置与使用
- java从字符串中提取数字的简单实例
- 计算机图形学(一)——数据压缩:道格拉斯普克法
- 网络编程:Socket编程从IPv4转向IPv6支持
- 微信服务号认证小程序
- 全球最牛逼的并发架构,抖音排第二,它排第一!
- 武大计算机导师蔡贤涛,CAD模型在线集成与离线集成关键技术研究
- C++编译为动态链接库并用python调用
- html-canvas-绘制简单线条
- mc服务器地皮系统权限指令,我的世界地皮指令大全
- 【转】西门子数控系统中MMC、PCU、NCU、CCU简略介绍
- LaTeX编辑中文论文,公式、图表、参考文献添加超链接
- 神经网络架构大盘点--读Fjodor Van Veen的《neural-network-zoo》
- 河北单招计算机的考试试题,河北单招试题