序列到序列网络seq2seq与注意力机制attention浅析
序列到序列网络
序列到序列网络(Sequence to Sequence network),也叫做seq2seq网络, 又或者是编码器解码器网络(Encoder Decoder network), 是一个由两个称为编码器解码器的RNN组成的模型。在这里进行介绍的作用是确定变量的名称,为接下来讲注意力机制做铺垫。
自编码器也是seq2seq模型中的一种。在自编码器中,解码器的工作是将编码器产生的向量还原成为原序列。经过压缩之后不可避免的会出现信息的损失,我们需要尽量将这种损失降低(方法是设置合理的中间向量大小和经过多次训练迭代的编码-解码器)。相关理论本身在这里讲得不是很清楚,有兴趣了解更多的同学可以移步数学专题中的信息论。
编码器
把一个不定长的输入序列变换成一个定长的背景变量ccc,并在该背景变量中编码输入序列信息。编码器可以使用循环神经网络。
在时间步ttt,循环神经网络将输入的特征向量xtx_txt和上个时间步的隐藏状态ht−1h_{t−1}ht−1变换为当前时间步的隐藏状态hth_tht。
ht=f(xt,ht−1)h_t = f(x_t, h_{t-1}) ht=f(xt,ht−1)
接下来,编码器通过自定义函数qqq将各个时间步的隐藏状态变换为背景变量
c=q(h1,...,hT)c=q(h_1,...,h_T) c=q(h1,...,hT)
例如,我们可以将背景变量设置成为输入序列最终时间步的隐藏状态hTh_ThT。
以上描述的编码器是一个单向的循环神经网络,每个时间步的隐藏状态只取决于该时间步及之前的输入子序列。我们也可以使用双向循环神经网络构造编码器。在这种情况下,编码器每个时间步的隐藏状态同时取决于该时间步之前和之后的子序列(包括当前时间步的输入),并编码了整个序列的信息。
解码器
对每个时间步t′t′t′,解码器输出yt′y_{t′}yt′的条件概率将基于之前的输出序列y1,...,yt′−1y_1,...,y_{t′−1}y1,...,yt′−1和背景变量ccc(所有时间步共用),即P(yt′∣y1,...,yt′−1,c)P(y_{t′}∣y_1,...,y_{t′−1},c)P(yt′∣y1,...,yt′−1,c)。同时还要考虑上一时间步的隐藏状态st′−1s_{t′−1}st′−1。
st′=g(yt′−1,c,st′−1)s_{t'} = g(y_{t′−1}, c, s_{t'-1}) st′=g(yt′−1,c,st′−1)
注意力机制
动机
普通的seq2seq模型到底有什么问题?我们再来回顾一下输出流程。
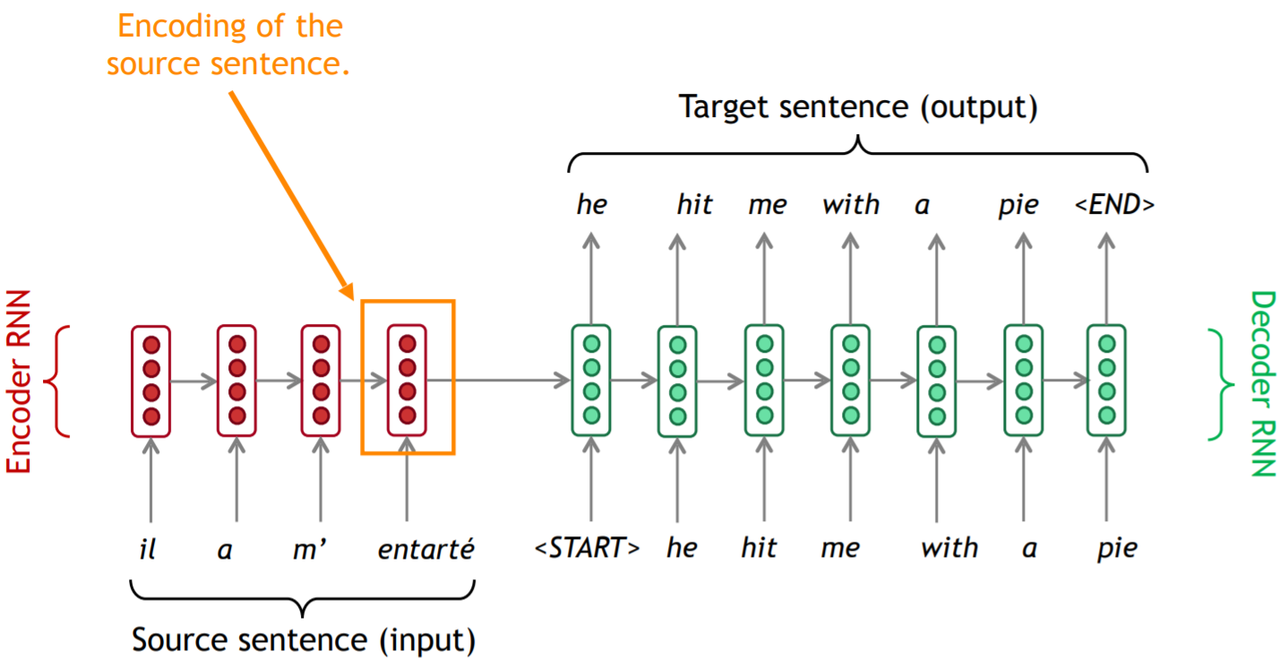
我们发现,解码器过分依赖于编码器在最后时间步生成的向量。这个向量需要包括源序列所有的信息,否则解码器将难以产生准确的输出。这个要求对于最后时间步生成的向量而言实在太高了。这个问题被称为信息瓶颈(information bottleneck)。
实际上,解码器在生成输出序列中的每一个词时可能只需利用输入序列某一部分的信息。为了让模型在不同时间步能够根据信息的有用程度分配权重,我们引入注意力机制。注意力机制的核心思想是解码器在每个时间步上使用直连接通向编码器以便其专注于源序列的部分内容。
过程
我们先通过图片形式展示过程。
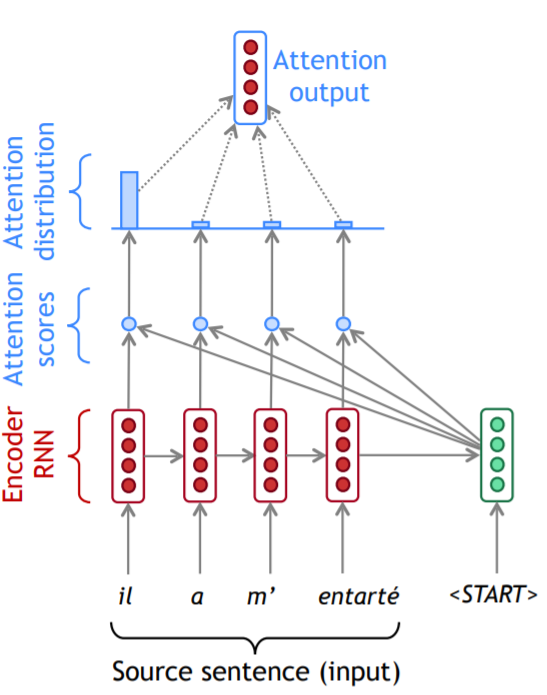
在注意力得分(attention scores)那个区域的小圆圈代表向量点乘,使用softmax函数将注意力得分转换成注意力分布(attention distribution)。我们可以看到,在第一步,大部分注意力被分配给了源序列的第一个单词。通过加权相加的方法得到了编码器的一个隐状态。将编码器产生的隐状态和解码器的隐状态进行叠加,就可以产生解码器在该时间步的输出。

有时,我们将注意力在上一步的输出当成输入,与当前的解码器隐状态一起进行训练,产生当前时间步的输出。例如这里的"he"就是上一步解码器的输出。
从另一个角度理解,对于普通的解码器,我们每一个时间步可以使用相同的背景变量。而在引入注意力机制之后,我们必须给每一个时间步不同的背景变量。
st′=g(yt′−1,ct′,st′−1)s_{t'} = g(y_{t′−1}, c_{t'}, s_{t'-1}) st′=g(yt′−1,ct′,st′−1)

我们用h1,...,hN∈Rhh_1, ..., h_N \in R^{h}h1,...,hN∈Rh来表示编码器的隐状态(hidden states),用st′∈Rhs_{t'} \in R^{h}st′∈Rh来表示解码器在时间步t′t't′的隐状态。我们可以计算注意力得分(attention scores)
et′=[st′Thi,...,st′ThN]∈RNe_{t'} = [s_{t'}^Th_i,...,s_{t'}^Th_N] \in R^N et′=[st′Thi,...,st′ThN]∈RN
使用softmax得到在时间步t′t't′的注意力分布(attention distribution)
αt′=softmax(et′)∈RN\alpha_{t'} = softmax(e_{t'}) \in R^N αt′=softmax(et′)∈RN
利用分布计算加权总合得到注意力输出向量(attention output) aaa,有时候也叫做上下文向量(context vector) ccc,
at′=ct′=∑i=1Nαi,t′hi∈Rha_{t'} = c_{t'} = \sum_{i=1}^N \alpha_{i,t'}h_i \in R^{h} at′=ct′=i=1∑Nαi,t′hi∈Rh
最后,我们将该向量与解码器当前的隐状态进行拼接
[at′;st′]∈R2h[a_{t'}; s_{t'}] \in R^{2h} [at′;st′]∈R2h
拓展
优点
- 解决了信息瓶颈的问题
- 缓解了梯度消失的问题
- 在一定程度上提供了可解释性
- 解决了软对齐问题(模型自己学习的,不需要人工调控)
注意力机制不光应用在机器翻译,还在很多其他领域有用武之地。
注意力机制的更通用的定义:给定一组值向量(values)和一个查询向量(query),注意力是一种根据查询向量对值向量计算加权和的技术。我们有时候会说查询关注这些值(query attends to the values)。例如,在seq2seq+attention模型中,每一个解码器的隐状态(query)都会关注所有编码器的隐状态(values)。
我们用h1,...,hN∈Rd1h_1, ..., h_N \in R^{d_1}h1,...,hN∈Rd1来表示values,用s∈Rd2s \in R^{d_2}s∈Rd2来表示query。注意力的计算过程如下:
- 计算注意力得分(attention scores),e∈RNe \in R^Ne∈RN
- 进行softmax操作,将得分转换成注意力分布,α=softmax(e)∈RN\alpha = softmax(e) \in R^Nα=softmax(e)∈RN
- 利用分布计算加权总合得到输出向量(attention output) aaa,有时候也叫做上下文向量(context vector),a=∑i=1Nαihi∈Rd1a = \sum_{i=1}^N \alpha_ih_i \in R^{d_1}a=∑i=1Nαihi∈Rd1
计算注意力得分的方法
计算注意力得分的方式有很多种。
点乘注意力
英文是basic dot-product attention。使用前提是d1=d2d_1 = d_2d1=d2。
ei=sThie_i = s^Th_i ei=sThi
乘法注意力
英文是multiplicative attention。权重矩阵W∈Rd2∗d1W \in R^{d_2*d_1}W∈Rd2∗d1。
ei=sTWhie_i = s^TWh_i ei=sTWhi
加法注意力
英文是additive attention。权重矩阵W1∈Rd3∗d1W_1 \in R^{d_3*d_1}W1∈Rd3∗d1,W2∈Rd2∗d1W_2 \in R^{d_2*d_1}W2∈Rd2∗d1,权重向量v∈Rd3v \in R^{d_3}v∈Rd3。我们用d3d_3d3表示注意力维度(attention dimensionality),这是一个超参数。
ei=vTtanh(W1hi+W2s)e_i = v^Ttanh(W_1h_i + W_2s) ei=vTtanh(W1hi+W2s)
矢量化计算
可以对注意力机制采用更高效的矢量化计算。我们再引入与值项一一对应的键项(key) KKK。
我们考虑编码器和解码器的隐藏单元个数均为hhh的情况。假设我们希望根据解码器单个隐藏状态st′−1∈Rhs_{t′−1} \in R^hst′−1∈Rh和编码器所有隐藏状态[h1,...,hN]∈Rh[h_1, ..., h_N] \in R^{h}[h1,...,hN]∈Rh来计算背景向量ct′∈Rhc_{t′} \in R^hct′∈Rh。 我们可以将查询项矩阵Q∈R1×hQ \in R^{1×h}Q∈R1×h设为st′−1Ts_{t′−1}^Tst′−1T,并令键项矩阵K∈RT×hK \in R^{T×h}K∈RT×h和值项矩阵V∈RT×hV \in R^{T×h}V∈RT×h相同且第ttt行均为htTh_t^ThtT。此时,我们只需要通过矢量化计算
softmax(QKT)Vsoftmax(QK^T)V softmax(QKT)V
即可算出转置后的背景向量ct′Tc_{t′}^Tct′T。当查询项矩阵QQQ的行数为nnn时,上式将得到nnn行的输出矩阵。输出矩阵与查询项矩阵在相同行上一一对应。
Reference
Dive Into Deep Learning,第10章
Natural Language Processing with Deep Learning, Stanford CS244n, 2019 winter, Chris Manning
序列到序列网络seq2seq与注意力机制attention浅析相关推荐
- 深度学习与自然语言处理教程(6) - 神经机器翻译、seq2seq与注意力机制(NLP通关指南·完结)
作者:韩信子@ShowMeAI 教程地址:https://www.showmeai.tech/tutorials/36 本文地址:https://www.showmeai.tech/article-d ...
- 注意力机制Attention详解
注意力机制Attention详解 一.前言 2018年谷歌提出的NLP语言模型Bert一提出,便在NLP领域引起热议,之所以Bert模型能够火出圈,是由于Bert模型在NLP的多项任务中取得了之前所有 ...
- 注意力机制(Attention)最新综述论文及相关源码
来源:专知 注意力机制(Attention)起源于模仿人类的思维方式,后被广泛应用于机器翻译.情感分类.自动摘要.自动问答等.依存分析等机器学习应用中.专知编辑整理了Arxiv上一篇关于注意力机制在N ...
- 注意力机制Attention Mechanism及论文
注意力机制Attention Mechanism Q,K,V 注意力分数 seq2seq中注意力机制的应用 注意力机制源于对人类视觉的研究.在认知科学中,由于信息处理的瓶颈,人类会选择性地关注所有信息 ...
- 图像处理注意力机制Attention汇总(附代码)
原文链接: 图像处理注意力机制Attention汇总(附代码,SE.SK.ECA.CBAM.DA.CA等) 1. 介绍 注意力机制(Attention Mechanism)是机器学习中的一种数据处理方 ...
- 论文浅尝 | 具有图卷积网络和顺序注意力机制的应用于目标导向的对话系统
论文笔记整理:吴涵,天津大学硕士,研究方向:自然语言处理. 来源:2019 Association for Computational Linguistics 论文链接:https://www.mit ...
- 深度残差收缩网络:借助注意力机制实现特征的软阈值化
作者 | 哈尔滨工业大学(威海)讲师 赵明航 本文解读了一种新的深度注意力算法,即深度残差收缩网络(Deep Residual Shrinkage Network). 从功能上讲,深度残差收缩网络是一 ...
- 在yolov5的网络结构中添加注意力机制模块
知足知不足,有为有不为 目录 前言 一.模块添加步骤 二.相应注意力机制介绍及其代码 1.SE注意力 2.CBAM注意力
- 翻译: 详细图解Transformer多头自注意力机制 Attention Is All You Need
1. 前言 The Transformer--一个使用注意力来提高这些模型的训练速度的模型.Transformer 在特定任务中的表现优于谷歌神经机器翻译模型.然而,最大的好处来自于 The Tran ...
最新文章
- Python画出心目中的自己
- 设置为true有什么区别_腻子粉和腻子膏到底有什么区别,腻子粉厂家来为你讲解...
- InnoDB Double write
- boost::type_erasure::dereferenceable相关的测试程序
- 华为8lite支持云闪付吗_鸿蒙系统适配机型表曝光,部分华为旗舰机未支持,你是其中之一吗...
- Cocos2d-x V3.2+Cocos Studio1.6 实现一个简单的uibutton点击功能
- CCF CSP201912-1 报数
- 【TensorFlow-windows】(一)实现Softmax Regression进行手写数字识别(mnist)
- hdu 1856 并查集 求最大的子树含有元素的个数
- 如何设置Mac允许远程电脑SSH登录?
- mysql exporter怎么配置_prometheus mysqld_exporter监控mysql-5.7
- 201521123045 《Java程序设计》第7周学习总结
- 2、喷淋塔填料(PP多面空心球)是喷淋塔的核心-喷淋塔填料的基本要求
- cst时间(utc和cst时间)
- linux信号函数signal(SIGCHLD, SIG_IGN)
- 生鲜配送管理系统_升鲜宝 V2.0 小程序辅助系统工具矩阵系列相关说明
- 第五周学习总结-HTML5
- 【Linux】基础常见指令
- 红领巾小创客机器人活动计划_环市西路小学:红领巾小创客社团活动总结
- html + vue + axios能获取数据但是无法渲染