python爬取电影和美食数据实战
from multiprocessing import Pool
from requests.exceptions import RequestException
import re
import json
def get_one_page(url):
try:
headers = {
"user-agent": 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'}
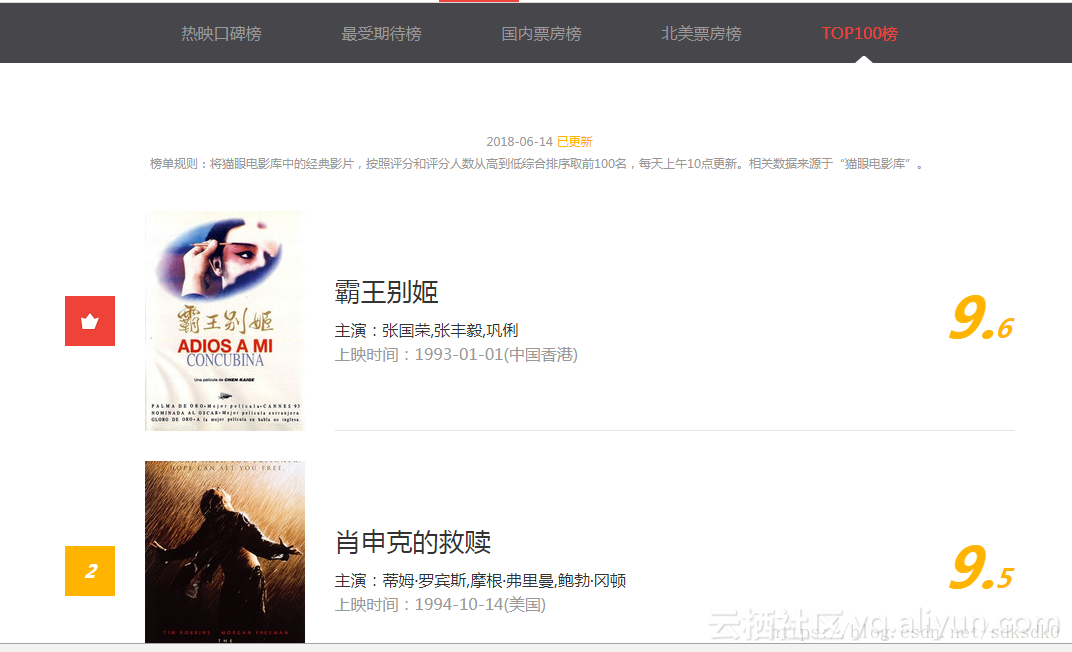
11
response = requests.get(url, headers=headers)
if response.status_code ==200:
return response.text
return None
except RequestException:
return None
def parse_one_page(html):
pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a'
+ '.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>'
+ '.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>', re.S)
items =re.findall(pattern,html)
for item in items:
yield {
'index':item[0],
'image':item[1],
'title':item[2],
'actor':item[3].strip()[3:],
'time': item[4].strip()[5:],
'score': item[5] + item[6]
}
def write_to_file(content):
with open('result.txt', 'a', encoding='utf-8') as f:
f.write(json.dumps(content, ensure_ascii=False) + '\n')
f.close()
def main(offset):
url ='http://maoyan.com/board/4?offset='+str(offset)
html = get_one_page(url)
for item in parse_one_page(html):
#print(item)
write_to_file(item)
if __name__ == '__main__':
#for i in range(10):
# main(i*10)
pool = Pool()
pool.map(main,[i*10 for i in range(10)])

from requests.exceptions import RequestException
import re
import json
def get_one_page(url):
try:
headers = {
"user-agent": 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'}
11
response = requests.get(url, headers=headers)
if response.status_code ==200:
return response.text
return None
except RequestException:
return None
def parse_one_page(html):
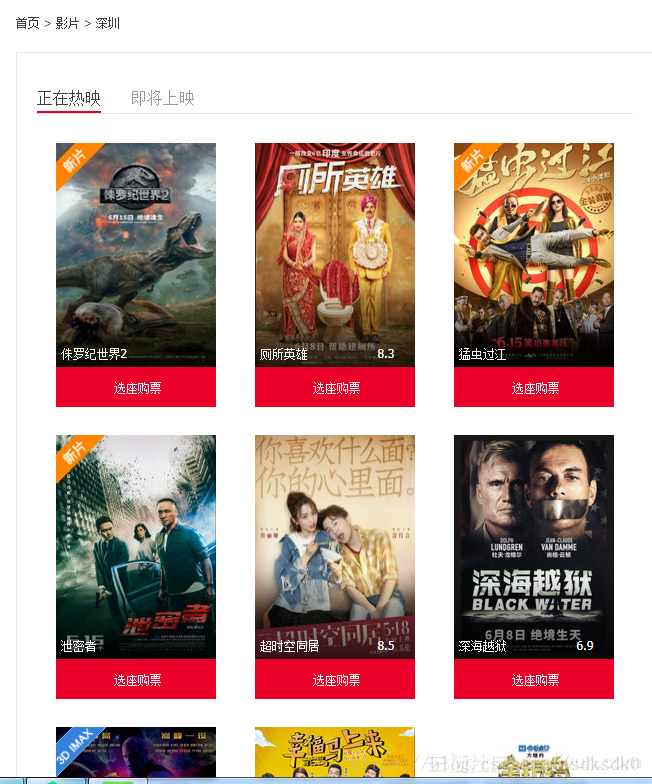
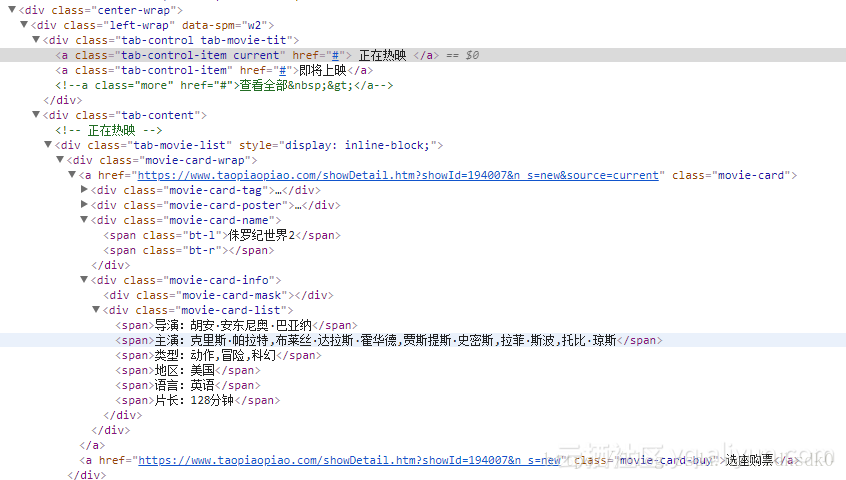
pattern = re.compile('<div class="movie-card-poster">.*?data-src="(.*?)".*?<span class="bt-l">(.*?)</span>.*?<span class="bt-r">(.*?)</span>.*?<div class="movie-card-list">.*?<span>(.*?)</span>'
+'.*?<span>(.*?)</span>.*?<span>(.*?)</span>.*?<span>(.*?)</span>.*?<span>(.*?)</span>.*?<span>(.*?)</span>',re.S)
items = re.findall(pattern, html)
for item in items:
yield {
'image': item[0],
'title': item[1],
'score': item[2],
'director': item[3].strip()[3:],
'actor': item[4].strip()[3:],
'type': item[5].strip()[3:],
'area': item[6].strip()[3:],
'language': item[7].strip()[3:],
'time': item[8].strip()[3:]
}
def write_to_file(content):
with open('movie-hot.txt', 'a', encoding='utf-8') as f:
f.write(json.dumps(content, ensure_ascii=False) + '\n')
f.close()
def main():
url ='https://www.taopiaopiao.com/showList.htm'
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_file(item)
if __name__ == '__main__':
main()
from multiprocessing import Pool
from requests.exceptions import RequestException
import re
import json
"""
author 朱培
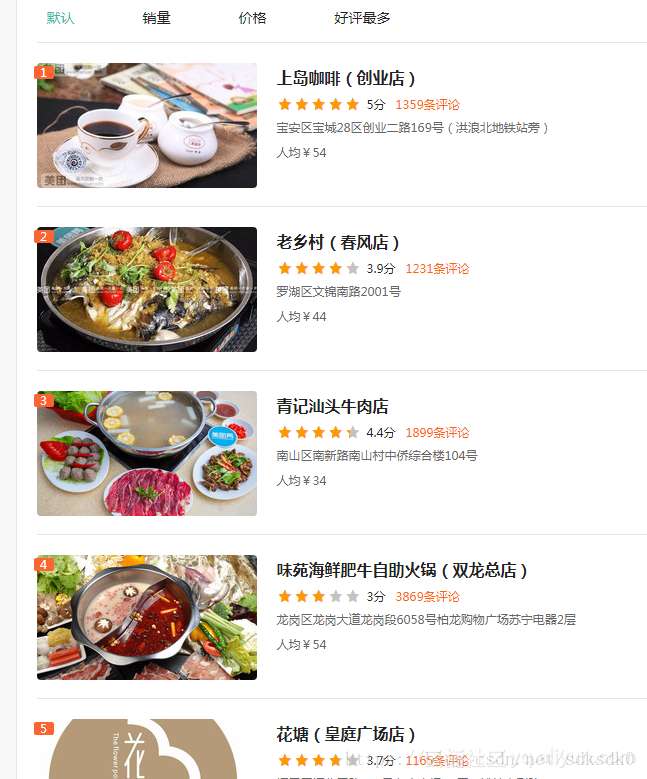
title 爬取美团(深圳)美食店铺信息,评分大于4.0分的店铺
"""
def get_one_page(url):
try:
headers = {
"user-agent": 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'}
response = requests.get(url, headers=headers)
if response.status_code ==200:
return response.text
return None
except RequestException:
return None
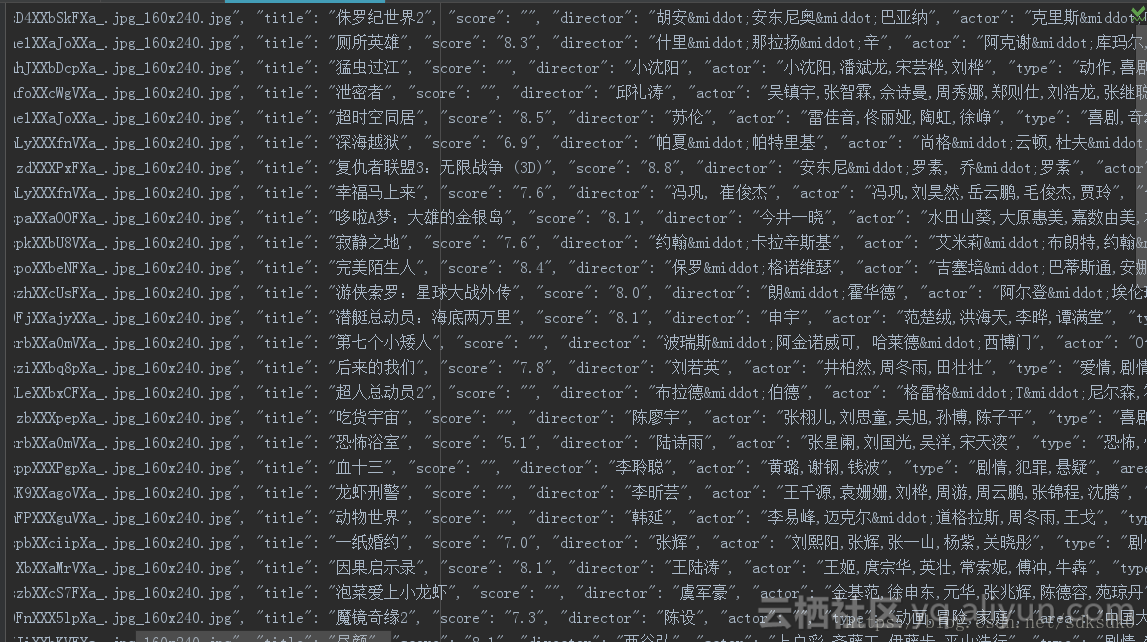
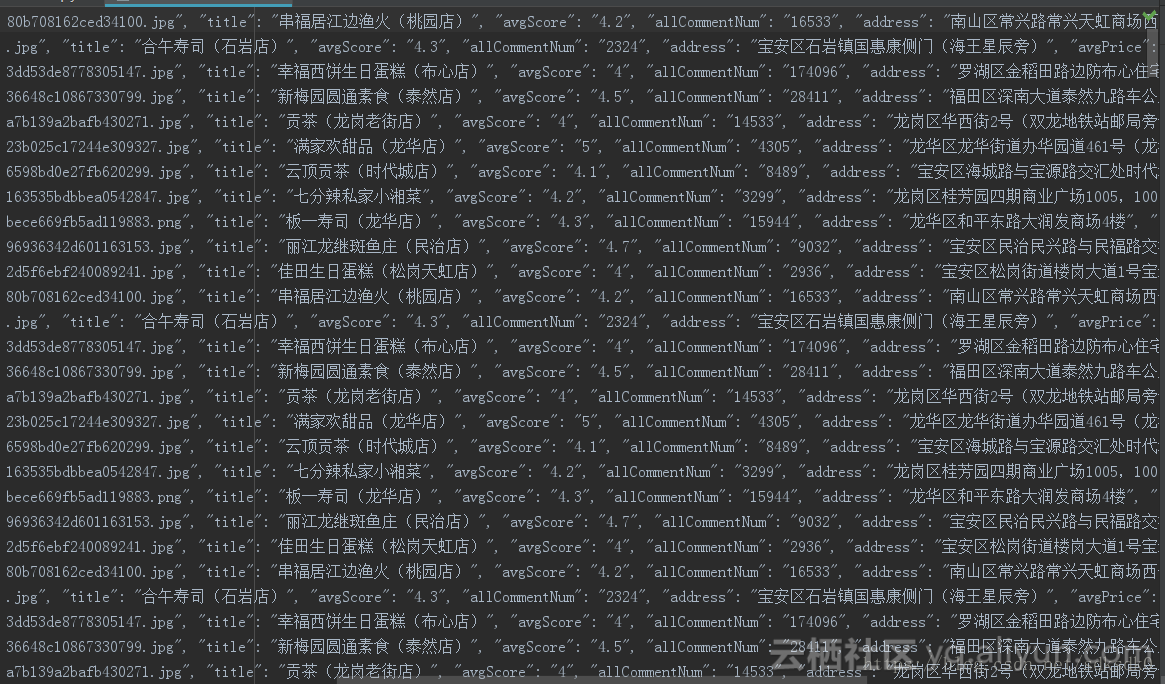
def parse_one_page(html):
pattern = re.compile('"poiId":(.*?),"frontImg":"(.*?)","title":"(.*?)","avgScore":(.*?),"allCommentNum":(.*?)'
+',"address":"(.*?)","avgPrice":(.*?),', re.S)
items = re.findall(pattern, html)
for item in items:
if float(item[3]) >= 4.0:
yield {
'poiId': item[0],
'frontImg': item[1],
'title': item[2],
'avgScore': item[3],
'allCommentNum':item[4],
'address': item[5],
'avgPrice': item[6]
}
def write_to_file(content):
with open('food-meituan.txt', 'a', encoding='utf-8') as f:
f.write(json.dumps(content, ensure_ascii=False) + '\n')
f.close()
def main(n):
url ='http://sz.meituan.com/meishi/pn'+str(n)+'/'
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_file(item)
if __name__ == '__main__':
#for i in range(32):
# main(i)
pool = Pool()
pool.map(main, [ 1 for i in range(32)])
python爬取电影和美食数据实战相关推荐
- Python爬取京东任意商品数据实战总结
利用Python爬取京东任意商品数据 今天给大家展示爬取京东商品数据 首先呢还是要分思路的,我分为以下几个步骤: 第一步:得到搜索指定商的url 第二步:获得搜索商品列表信息 第三步:对得到的商品数据 ...
- python实战|python爬取58同城租房数据并以Excel文件格式保存到本地
python实战|python爬取58同城租房数据并以Excel文件格式保存到本地 一.分析目标网站url 目标网站:https://cq.58.com/minsuduanzu/ 让我们看看网站长啥样 ...
- python爬取电影评分_用Python爬取猫眼上的top100评分电影
代码如下: # 注意encoding = 'utf-8'和ensure_ascii = False,不写的话不能输出汉字 import requests from requests.exception ...
- python爬取电影天堂的下载链接
python爬取电影天堂dytt8的下载链接 电影天堂下载链接都是magnet的,搞下来想下就下没有广告 建一个main.py 一个一个挨着去爬肯定慢啊,建一个多线程的去爬 mui.py 多线程有可能 ...
- python爬取微博热搜数据并保存!
主要用到requests和bf4两个库将获得的信息保存在d://hotsearch.txt下importrequests;importbs4mylist=[]r=requests.get(ur- 很多 ...
- python 爬取24小时天气数据
python 爬取24小时天气数据 1.引入相关库 # -*- coding: utf-8 -*- import requests import numpy as np 关于爬虫,就是在网页上找到自己 ...
- Python 爬取电影天堂top最新电影
Python爬虫有他无可比拟的优势:语法简单,经常几十行代码就能轻松解决问题,相比于JAVA,C,PHP;第三方库丰富,Python强大而又丰富的第三方库使他几乎可以无所不能.今天我们就来用用Pyth ...
- 用python爬取基金网信息数据,保存到表格,并做成四种简单可视化。(爬虫之路,永无止境!)
用python爬取基金网信息数据,保存到表格,并做成四种简单可视化.(爬虫之路,永无止境!) 上次 2021-07-07写的用python爬取腾讯招聘网岗位信息保存到表格,并做成简单可视化. 有的人留 ...
- python爬淘宝app数据_一篇文章教会你用Python爬取淘宝评论数据(写在记事本)
[一.项目简介] 本文主要目标是采集淘宝的评价,找出客户所需要的功能.统计客户评价上面夸哪个功能多,比如防水,容量大,好看等等. [二.项目准备工作] 准备Pycharm,下载安装等,可以参考这篇文章 ...
最新文章
- [YTU]_2622(B 虚拟继承(虚基类)-沙发床(改错题))
- LeetCode5-最长回文子串原理及Python实现
- 动态规划-时间规整算法
- MySql中添加用户/删除用户
- Navicat 编辑器自动完成代码功能讲解
- php 逗号 分割字符串
- 基于FPGA实现DAC8811接口(正弦波)
- 哪些手机支持双wifi?
- 1000个摄像头的网络怎么搭建?为什么500个就卡的不行?
- ssma迁移助手_如何使用SQL Server迁移助手(SSMA)和SSIS将MySQL表迁移到SQL Server
- WEB自动化(Python+selenium)的API
- 【HDU2050】折线分割平面
- 让部署到服务器上的springboot项目持续运行(nohup)
- html字体样式(有中文兼英文实例)
- c语言 | 求1000-2000年之间的闰年
- 教你一步解决添加和修改环境变量问题
- 为什么买入不了创业版_为什么我买不了创业板?创业板开户有什么条件
- Linux宝塔面板命令大全,快速学会
- PMSM电机学习记录--矢量控制之滞环电流控制(Bang-Bang控制)
- MFC之文档/视图结构应用程序