1-1 机器学习和深度学习综述-paddle
查看教师发布的版本
人工智能\机器学习和深度学习的概念及关系
人工智能、机器学习和深度学习的概念在近些年十分火热,但很多从业者也难以说清它们之间的关系,外行人更是雾里看花。学习深度学习,需要先从三个概念的正本清源开始。
三者覆盖的技术范畴是逐层递减的,人工智能是最宽泛的概念,机器学习则是实现人工智能的一种方式,也是目前较有效的方式。深度学习是机器学习算法中最热的一个分支,在近些年取得了显著的进展,并代替了多数传统机器学习算法。所以,三者的关系可用下图表示,人工智能 > 机器学习 > 深度学习。
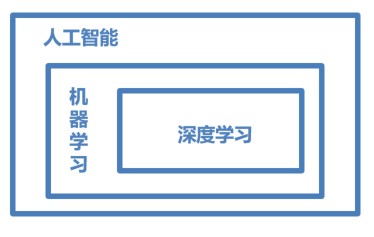
图1:人工智能、机器学习和深度学习三者之间的概念范围
如字面含义,人工智能是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的科学。由于这个定义只阐述了目标,而没限定方法。所以,实现人工智能存在的诸多方法和分支,导致其变成一个“大杂烩”式的学科。
与此不同,机器学习,尤其是监督学习则有更加明确的指代。机器学习是专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。这句话有点“云山雾罩”的感觉,让人不知所云。
机器学习的实现步骤可以分成两步,训练和预测。这两个专业名词类似于归纳和演绎的含义。归纳是从具体案例中抽象一般规律,机器学习中的“训练”亦是如此。从一定数量的样本(已知模型输入XXX和模型输出YYY)中,学习出输出YYY与输入XXX的关系(可以想象成是某种表达式)。演绎则是从一般规律推导出具体案例的结果,机器学习中的预测亦是如此。基于训练得到的YYY与XXX之间的关系,遇到新出现的输入XXX,计算出输出YYY。在多数时候,通过模型计算得到的输出,如果和真实场景中的输出一致,说明模型是有效的。
下面以“机器从牛顿第二定律实验中学习知识”为案例,让读者深入理解下机器学习(监督学习)到底是怎样的一种技术方法。机器学习的方法论和人类科研的过程有异曲同工之妙。下牛顿第二定律的常见表述:物体加速度的大小跟作用力成正比,跟物体的质量成反比,且与物体质量的倒数成正比。该定律是由艾萨克·牛顿在1687年于《自然哲学的数学原理》一书中提出的。牛顿第二运动定律和第一、第三定律共同组成了牛顿运动定律,阐述了经典力学中基本的运动规律。
在中学课本中,牛顿第二定律有两种设计实验的方法:倾斜滑动法和水平拉线法。
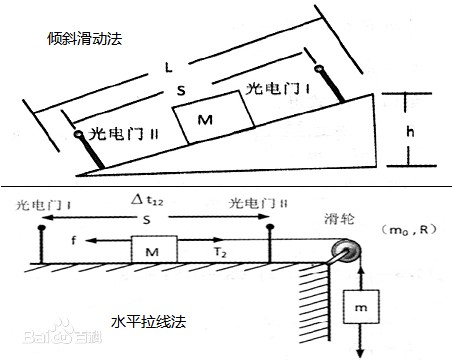
图2:牛顿第二定律实验的两种方法
相信很多读者均有摆弄滑轮和小木块做实验的青涩年代和美好回忆。基于多次实验,统计到不同的作用力下木块加速度如下表所示。
表1:实验获取的大量数据样本和作图观测结果
| 项目 | 作用力X | 加速度Y |
|---|---|---|
| 第1次 | 4 | 2 |
| 第2次 | 5 | 2.5 |
| ... | ... | ... |
| 第n次 | 6 | 3 |
观察上述实验数据,不难猜测物体的加速度aaa和作用力之间的关系应该是线性关系。所以,我们提出假设 a=w∗Fa = w * Fa=w∗F,aaa代表加速度,FFF代表作用力,www是待确定的参数。
通过大量实验数据的训练,确定参数www是物体质量的倒数(1/m)(1/m)(1/m),即得到完整的模型公式a=w∗(1/m)a = w * (1/m)a=w∗(1/m)。当已知作用到某个物体的力时,基于模型可以方便的预测物体的加速度。例如燃料对火箭的推力FFF=10,火箭的质量mmm=2,求得火箭的加速度aaa=5。
这个有趣的案例演示机器学习的基本过程,但其中有一个关键点的实现尚不清晰,即怎样确定模型的参数(w=1/m)(w=1/m)(w=1/m)?
学习确定参数的过程与科学家提出假说的方式类似,合理的假说至少能够解释所有已有观测。如果在未来观测到不符合理论假说的新数据,人们会尝试提出新的假说。如天文史上,使用大圆和小圆组合的方式计算天体运行在中世纪是可以拟合观测数据的。但随着欧洲机械工业的进步,天文观测设备逐渐强大,越来越多的观测数据无法套用已有的理论。这促进了使用椭圆计算天体运行的理论假说出现。所以,模型有效的基本条件是能够拟合已知的样本,这给我们提供了学习有效模型的实现方案。以HHH为模型的假设,它是一个关于参数θ\thetaθ和输入XXX的函数,用H(θ,X)H(\theta, X)H(θ,X) 表示。模型的优化目标是使得H(θ,X)H(\theta, X)H(θ,X)的输出与真实输入YYY尽量一致,即两者相差程度即是模型效果的评价函数(相差越小越好)。那么,学习参数的过程就是在已知的样本上,不断减小该评价函数(H(θ,X)H(\theta, X)H(θ,X) 和YYY相差)的过程,直到学习到一个参数θ\thetaθ使得评价函数的取值最小。这个衡量模型预测值和真实值差距的评价函数也被称为损失函数(损失 Loss)。上述优化参数的过程如下图公式所示。
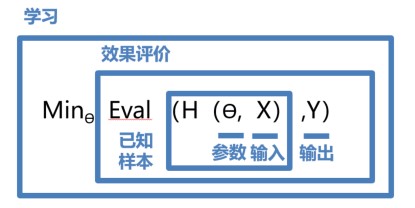
图3:学习确定参数的方法
举例类比,机器如一个机械的学生一样,只能通过尝试答对(最小化损失)大量的习题(已知样本)来学习知识(模型参数w),期望用学习到的知识w组成完整的模型H(θ,X)H(\theta, X)H(θ,X),能回答不知道答案的考试题(未知样本)。最小化损失是模型的优化目标,实现损失最小化的方法称为优化算法,也称为寻解算法(找到使得损失函数最小的参数解)。参数θ\thetaθ和输入XXX组成公式的基本结构称为假设。在牛顿第二定律的案例中,基于对数据的观测,我们提出的是线性假设,即作用力和加速度是线性关系,用线性方程表示。由此可见,模型假设,评价函数(损失/优化目标)和优化算法是构成一个模型的三个部分。
机器学习算法理论在上个世纪90年代发展成熟,在诸多领域也取得了应用效果。但平静的日子过到2010年左右,深度学习模型的异军突起,极大改变了机器学习的应用格局。在今天,多数机器学习任务均可以使用深度学习模型解决。在语音,计算机视觉和自然语言处理等领域,深度学习模型的效果比传统机器学习算法有显著提升。
那么,深度学习又怎样对机器学习的算法结构提出了改进呢?其实两者的理论结构是一致的,也存在模型假设,评价函数和优化算法,最根本的差别在于假设的复杂度上。
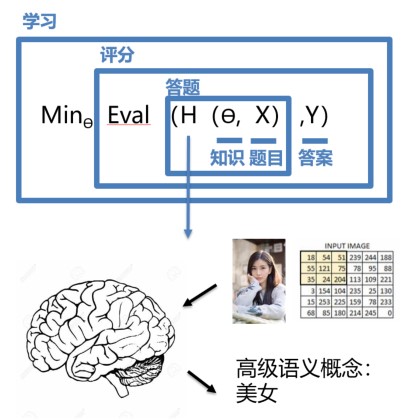
图4:从原始图片像素到高级语义概念“美女”的函数转换的复杂度难以想象!
如上图所示,不是所有的任务均如牛顿第二定律那样简单直观。对于一张图片,人脑接收到五颜六色的光学信号,计算机则接收到一个数字矩阵。人脑以极快的速度反应出这张图片是一位美女,而且是程序员喜欢的类型。这个结果是一个非常高级的语义概念,从像素到高级语义概念中间要经历怎样复杂的信息变换是难以想象的!这种变换已经复杂到无法用数学公式表达,所以研究者们借鉴了人脑神经元的结构,设计出神经网络的模型。
人工神经网络包括多个神经网络层(卷积层、全连接层、LSTM等),每一层又包括很多神经元,超过三层的非线性神经网络都可以被成为深度神经网络。通俗的讲,深度学习的模型可以视为是输入到输出的映射函数,比如中文到英文的映射,足够深的神经网络理论上可以拟合任何复杂的函数,因此,神经网络非常适合学习样本数据的内在规律和表示层次,对文字\图像和声音任务有很好的适用性,因为这几个领域的任务是人工智能的基础模块,所以深度学习被称为实现人工智能的基础也就不足为奇了
深度学习的历史和发展
究竟神经网络是怎样的设计?先不用着急,在下一章会以一个“房价预测”的案例,演示使用Python实现神经网络模型的细节。在进入实现细节之前,让我们回顾下深度学习的悠久的历史和今日的蓬勃发展。
神经网络思想的提出已经是75年前的事情了,现今的神经网络和深度学习的设计理论是一步步的完善的。在这漫长的发展岁月中,有一些取得关键突破的闪光时刻。其中有1960年代,基本网络结构设计完善后的黄金时代,也有在1969年异或问题被提出后(人们惊奇的发现神经网络模型连简单的异或问题也无法解决),神经网络模型被束之高阁的黑暗时代。虽然在1986年,新提出的多层的神经网络解决了异或问题,但随着90年代后理论更完备并且实践效果更好的SVM等机器学习模型的兴起,神经网络并未得到重视。真正的兴起是在2010年左右,基于神经网络模型改进的技术在语音和计算机视觉任务上大放异彩,也逐渐被证明在更多的任务(自然语言处理以及海量数据的任务)上有效。至此,神经网络模型重新焕发生机,并有了一个更加响亮的名字:深度学习。
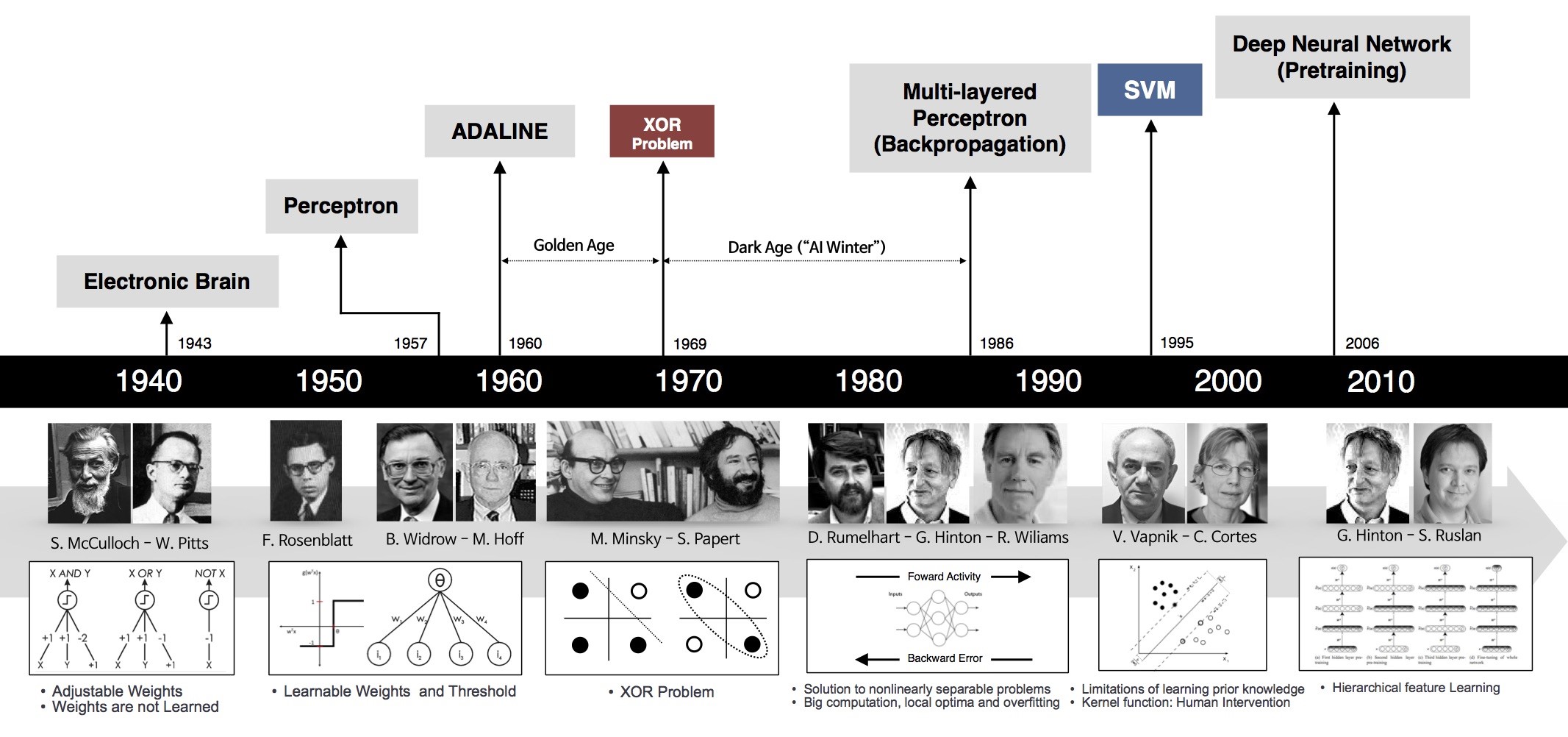
为何神经网络到2010年后才焕发生机,这与深度学习成功所依赖的先决条件有关。
- 大数据是它有效的前提。神经网络和深度学习是非常强大的模型,但也需要足够量级的训练数据。时至今日,很多传统机器学习算法和人工特征依然是足够有效的方案,原因在于很多场景下没有足够的标记数据来支撑深度学习这样强大的模型。深度学习的能力特别像科学家托罗密的豪言壮语:“给我一根足够长的杠杆,我能撬动地球!”,它也可以发出类似的豪言:“给我足够多的数据,我能够学习任何复杂的关系”。但在现实中,足够长的杠杆与足够多的数据一样,往往只能是一种美好的愿景。直到近些年,各行业IT化程度提高,累积的数据量爆发式的增长,才使得应用深度学习模型成为可能。
- 依靠硬件的发展和算法的优化。现阶段依靠更强大的计算机,GPU,Autoencoder预训练和并行计算等技术,深度网络在训练上的困难已经被逐渐克服。其中,数据量和硬件是更主要的原因。没有前两者,科学家们想优化算法都无从进行。
早在1998年,一些科学家就已经使用神经网络模型识别手写字母图像了。但深度学习在计算机视觉应用上的兴起,还是在2012年ImageNet比赛上,使用AlexNet做图像分类。如果比较下98年和12年的模型,会发现两者在网络结构上非常类似,仅在一些细节上有所优化。在这十四年间计算性能的大幅提升和数据量的爆发式增长,促使模型完成了从“简单的字母识别”到“复杂的图像分类”的跨越。
虽然历史悠久,但深度学习在今天依然在蓬勃发展,一方面基础研究快速进展,另一方面工业实践层出不穷。
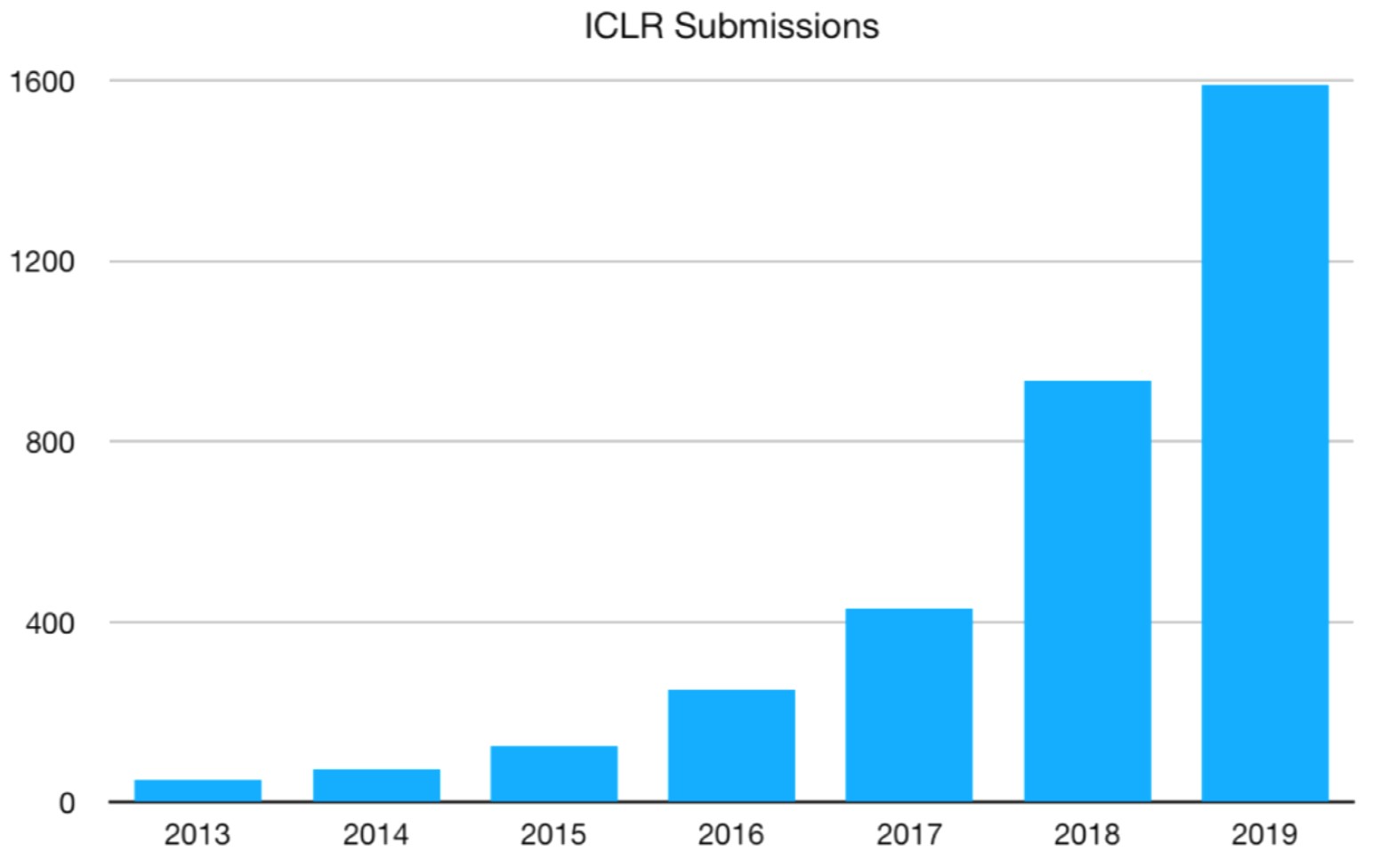
如下图所示,基于深度学习的顶级会议ICLR(international conference on learning representations)统计,深度学习相关的论文数量呈逐年递增的状态。同时,不仅仅是深度学习会议,与数据和模型技术相关的会议ICML和KDD,专注视觉的CVPR和专注自然语言处理的EMNLP等国际会议的大量论文均涉及着深度学习技术。该领域和相关领域的研究方兴未艾,技术仍在不断创新突破中。
另一方面,以深度学习为基础的人工智能技术在升级改造众多的传统行业,存在极其广阔的应用场景。下图选自艾瑞咨询的研究报告,人工智能技术不仅可在众多行业中落地应用(广度),在部分行业(如安防)已经实现了市场化变现和高速增长(深度)。

除了应用广泛的特点外,深度学习还推动人工智能进入工业大生产阶段,算法的通用性导致标准化、自动化和模块化的框架产生。此前,不同流派的机器学习算法理论和实现均不同,导致每个算法均要独立实现,例如随机森林和支撑向量机(SVM)。但在深度学习框架下的诸多算法结构有较大的通用性,例如常用与计算机视觉的卷积神经网络模型(CNN)和常用于自然语言处理的长期短期记忆模型(LSTM),均可以分为组网模块,梯度下降的优化模块,预测模块等。这使得抽象出统一的框架成为了可能,并大大降低了编写建模代码的成本。一些相对通用的模块,如网络基础算子的实现,各种优化算法等均可以由框架实现。建模者只需要关注数据处理,配置组网的方式,以及用少量代码串起训练和预测的流程即可。

图8:深度学习模型具有通用性特点,可以标准化、自动化和模块化
在深度学习框架出现之前,机器学习工程师处于手工业作坊生产的时代。为了完成建模,工程师需要储备大量数学知识,并为特征工程工作积累大量行业知识。每个模型是极其个性化的,建模者如同手工业者一样,将自己的积累形成模型的“个性化签名”。而今,“深度学习工程师”进入了工业化大生产时代。只要掌握深度学习必要但少量的理论知识,掌握Python编程即可以在深度学习框架实现极其有效的模型,甚至与该领域最领先的实现模型不相上下。建模这个被“老科学家”们长期把持的建模领域面临着颠覆,也是新入行者的机遇。
图9:深度学习工程师处于工业化大生产时代,“老科学家”长期积累的优势不再牢固

每个人的生命都是宝贵的,我们经常说要将有限的时间浪费在有价值的事情上。为何要学习深度学习技术,以及通过这本书来学习呢?一方面,深度学习的应用前景广阔,是极好的发展方向和职业选择。另一方面,本书会使用国产的深度学习框架飞桨(PaddlePaddle)来编写实践案例,基于框架的编程让深度学习变得易学易用。
下面让我们尽快开始第一个实践案例:基于Python编写完成房价预测任务的神经网络模型,并在这个过程中亲身设计一个神经网络模型。
思考题
- 类比牛顿第二定律的案例,在你的工作和生活中还有哪些问题可以用监督学习的框架来解决?模型假设和参数是什么?评价函数(损失)是什么?
- 为什么说深度学习工程师有发展前景?怎样从经济学(市场供需)的角度做出解读?
1-1 机器学习和深度学习综述-paddle相关推荐
- 【AI 学习】2.机器学习和深度学习综述
人工智能.机器学习.深度学习的关系 近些年人工智能.机器学习和深度学习的概念十分火热,但很多从业者却很难说清它们之间的关系,外行人更是雾里看花.在研究深度学习之前,我们先从三个概念的正本清源开始. 概 ...
- 1.1机器学习和深度学习综述(百度架构师手把手带你零基础实践深度学习原版笔记系列)
人工智能.机器学习.深度学习的关系 近些年人工智能.机器学习和深度学习的概念十分火热,但很多从业者却很难说清它们之间的关系,外行人更是雾里看花.在研究深度学习之前,我们先从三个概念的正本清源开始. 概 ...
- 机器学习和深度学习综述
文章目录 一:人工智能.机器学习.深度学习的关系 二:机器学习 1:机器学习的实现 2:机器学习的方法论 3:案例:牛顿第二定律 4:确定模型参数 5:模型结构介绍 三:深度学习 1:神经网络的基本概 ...
- 1.1 机器学习和深度学习综述
人工智能.机器学习.深度学习的关系 近些年人工智能.机器学习和深度学习的概念十分火热,但很多从业者却很难说清它们之间的关系,外行人更是雾里看花.在研究深度学习之前,我们先从三个概念的正本清源开始. 概 ...
- 1-1 机器学习和深度学习综述
人工智能\机器学习和深度学习的概念及关系 人工智能.机器学习和深度学习的概念在近些年十分火热,但很多从业者也难以说清它们之间的关系,外行人更是雾里看花.学习深度学习,需要先从三个概念的正本清源开始. ...
- 从起源到具体算法,这篇深度学习综述论文送给你
来源:机器之心 本文共4602字,建议阅读8分钟. 本文为大家从最基础的角度来为大家解读什么是深度学习,以及深度学习的一些前沿发展. 自 2012 年多伦多大学 Alex Krizhevsky 等人提 ...
- 2020上半年收集到的优质AI文章 – 机器学习和深度学习
2020上半年收集到的优质AI文章 – 机器学习和深度学习 一文读懂机器学习 机器学习应补充哪些数学基础? 简单梳理一下机器学习可解释性(Interpretability) 什么是CNN?机器学习入门 ...
- 《Nature》纪念人工智能60周年专题:深度学习综述
来源:网络大数据 摘要:本文是<Nature>杂志为纪念人工智能60周年而专门推出的深度学习综述,也是Hinton.LeCun和Bengio三位大神首次合写同一篇文章. 本文是<Na ...
- 深度学习综述:Hinton、Yann LeCun和Bengio经典重读
来源:人工智能头条 翻译 | kevin,刘志远 审校 | 李成华 深度学习三巨头Geoffrey Hinton.Yann LeCun和Yoshua Bengio对AI领域的贡献无人不知.无人不晓.本 ...
最新文章
- 目标检测中特征融合技术(YOLO v4)(上)
- 加强linux操作系统DNS服务安全
- simple html dom img,simple_html_dom学习过程(1)查找元素
- 蒙特卡罗模拟法 —— matlab
- 5.1.6 UPDATE更新数据
- 优秀的程序员都应当知道的11个警句
- Java后台解决跨域问题
- java.sql.SQLException: Access denied for user 'root'@'localhost'
- MongoDB 通过 Java 代码 CRUD 数据库与集合
- 五个最佳RSS新闻阅读器
- 研究生预备军:论文选题与写作
- SameTime8.5.1安装失败故障诊断
- 读书·2018(14本)
- 网页学习教程视频百度云下载,程序学习教程视频百度云下载(讲解非常的细,适合刚学习程序人员,从前端到后端都有,全看完你就是一名程序猿)
- 基于SSM实现的水果店收银系统
- 家居装修选购:挑选家用沙发的8个禁忌
- Unity3d八 Unity使用的坐标系
- window.print() 文字过多会打印不全_明天开始打印准考证,你需要注意这些!
- #9.白盒测试:数据流测试
- 如何用js源生写计时器