机器学习案例学习【每周一例】之 Titanic: Machine Learning from Disaster
下面一文章就总结几点关键:
1、要学会观察,尤其是输入数据的特征提取时,看各输入数据和输出的关系,用绘图看!
2、训练后,看测试数据和训练数据误差,确定是否过拟合还是欠拟合;
3、欠拟合的话,说明模型不准确或者特征提取不够,对于特征提取不够问题,可以根据模型的反馈来看其和数据的相关性,如果相关系数是0,则放弃特征,如果过低,说明特征需要再次提炼!
4、用集成学习,bagging等通常可以获得更高的准确度!
5、缺失数据可以使用决策树回归进行预测!
转自:http://blog.csdn.net/han_xiaoyang/article/details/49797143
1.引言
2.背景
2.1 关于Kaggle
2.2 关于泰坦尼克号之灾
带大家去该问题页面溜达一圈吧
- 下面是问题背景页

- 下面是可下载Data的页面

- 下面是小伙伴们最爱的forum页面,你会看到各种神级人物厉(qi)害(pa)的数据处理/建模想法,你会直视『世界真奇妙』。

- 下面是问题背景页
泰坦尼克号问题之背景
就是那个大家都熟悉的『Jack and Rose』的故事,豪华游艇倒了,大家都惊恐逃生,可是救生艇的数量有限,无法人人都有,副船长发话了『lady and kid first!』,所以是否获救其实并非随机,而是基于一些背景有rank先后的。
训练和测试数据是一些乘客的个人信息以及存活状况,要尝试根据它生成合适的模型并预测其他人的存活状况。
对,这是一个二分类问题,是我们之前讨论的logistic regression所能处理的范畴。
3.说明
接触过Kaggle的同学们可能知道这个问题,也可能知道RandomForest和SVM等等算法,甚至还对多个模型做过融合,取得过非常好的结果,那maybe这篇文章并不是针对你的,你可以自行略过。
我们因为之前只介绍了Logistic Regression这一种分类算法。所以本次的问题解决过程和优化思路,都集中在这种算法上。其余的方法可能我们之后的文章里会提到。
说点个人的观点。不一定正确。
『解决一个问题的方法和思路不止一种』
『没有所谓的机器学习算法优劣,也没有绝对高性能的机器学习算法,只有在特定的场景、数据和特征下更合适的机器学习算法。』
4.怎么做?
手把手教程马上就来,先来两条我看到的,觉得很重要的经验。
印象中Andrew Ng老师似乎在coursera上说过,应用机器学习,千万不要一上来就试图做到完美,先撸一个baseline的model出来,再进行后续的分析步骤,一步步提高,所谓后续步骤可能包括『分析model现在的状态(欠/过拟合),分析我们使用的feature的作用大小,进行feature selection,以及我们模型下的bad case和产生的原因』等等。
Kaggle上的大神们,也分享过一些experience,说几条我记得的哈:
- 『对数据的认识太重要了!』
- 『数据中的特殊点/离群点的分析和处理太重要了!』
- 『特征工程(feature engineering)太重要了!在很多Kaggle的场景下,甚至比model本身还要重要』
- 『要做模型融合(model ensemble)啊啊啊!』
更多的经验分享请加讨论群,具体方式请联系作者,或者参见《“ML学分计划”说明书》
5.初探数据
先看看我们的数据,长什么样吧。在Data下我们train.csv和test.csv两个文件,分别存着官方给的训练和测试数据。
import pandas as pd #数据分析
import numpy as np #科学计算
from pandas import Series,DataFramedata_train = pd.read_csv("/Users/Hanxiaoyang/Titanic_data/Train.csv")
data_trainpandas是常用的Python数据处理包,把csv文件读入成dataframe各式,我们在ipython notebook中,看到data_train如下所示:

这就是典型的dataframe格式,如果你没接触过这种格式,完全没有关系,你就把它想象成Excel里面的列好了。
我们看到,总共有12列,其中Survived字段表示的是该乘客是否获救,其余都是乘客的个人信息,包括:
- PassengerId => 乘客ID
- Pclass => 乘客等级(1/2/3等舱位)
- Name => 乘客姓名
- Sex => 性别
- Age => 年龄
- SibSp => 堂兄弟/妹个数
- Parch => 父母与小孩个数
- Ticket => 船票信息
- Fare => 票价
- Cabin => 客舱
- Embarked => 登船港口
逐条往下看,要看完这么多条,眼睛都有一种要瞎的赶脚。好吧,我们让dataframe自己告诉我们一些信息,如下所示:
data_train.info()- 1
- 1
看到了如下的信息:

上面的数据说啥了?它告诉我们,训练数据中总共有891名乘客,但是很不幸,我们有些属性的数据不全,比如说:
- Age(年龄)属性只有714名乘客有记录
- Cabin(客舱)更是只有204名乘客是已知的
似乎信息略少啊,想再瞄一眼具体数据数值情况呢?恩,我们用下列的方法,得到数值型数据的一些分布(因为有些属性,比如姓名,是文本型;而另外一些属性,比如登船港口,是类目型。这些我们用下面的函数是看不到的):

我们从上面看到更进一步的什么信息呢?
mean字段告诉我们,大概0.383838的人最后获救了,2/3等舱的人数比1等舱要多,平均乘客年龄大概是29.7岁(计算这个时候会略掉无记录的)等等…
6.数据初步分析
每个乘客都这么多属性,那我们咋知道哪些属性更有用,而又应该怎么用它们啊?说实话这会儿我也不知道,但我们记得前面提到过
- 『对数据的认识太重要了!』
- 『对数据的认识太重要了!』
- 『对数据的认识太重要了!』
重要的事情说三遍,恩,说完了。仅仅最上面的对数据了解,依旧无法给我们提供想法和思路。我们再深入一点来看看我们的数据,看看每个/多个 属性和最后的Survived之间有着什么样的关系呢。
6.1 乘客各属性分布
脑容量太有限了…数值看花眼了。我们还是统计统计,画些图来看看属性和结果之间的关系好了,代码如下:
import matplotlib.pyplot as plt
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数plt.subplot2grid((2,3),(0,0)) # 在一张大图里分列几个小图
data_train.Survived.value_counts().plot(kind='bar')# 柱状图
plt.title(u"获救情况 (1为获救)") # 标题
plt.ylabel(u"人数") plt.subplot2grid((2,3),(0,1))
data_train.Pclass.value_counts().plot(kind="bar")
plt.ylabel(u"人数")
plt.title(u"乘客等级分布")plt.subplot2grid((2,3),(0,2))
plt.scatter(data_train.Survived, data_train.Age)
plt.ylabel(u"年龄") # 设定纵坐标名称
plt.grid(b=True, which='major', axis='y')
plt.title(u"按年龄看获救分布 (1为获救)")plt.subplot2grid((2,3),(1,0), colspan=2)
data_train.Age[data_train.Pclass == 1].plot(kind='kde')
data_train.Age[data_train.Pclass == 2].plot(kind='kde')
data_train.Age[data_train.Pclass == 3].plot(kind='kde')
plt.xlabel(u"年龄")# plots an axis lable
plt.ylabel(u"密度")
plt.title(u"各等级的乘客年龄分布")
plt.legend((u'头等舱', u'2等舱',u'3等舱'),loc='best') # sets our legend for our graph.plt.subplot2grid((2,3),(1,2))
data_train.Embarked.value_counts().plot(kind='bar')
plt.title(u"各登船口岸上船人数")
plt.ylabel(u"人数")
plt.show()
bingo,图还是比数字好看多了。所以我们在图上可以看出来,被救的人300多点,不到半数;3等舱乘客灰常多;遇难和获救的人年龄似乎跨度都很广;3个不同的舱年龄总体趋势似乎也一致,2/3等舱乘客20岁多点的人最多,1等舱40岁左右的最多(→_→似乎符合财富和年龄的分配哈,咳咳,别理我,我瞎扯的);登船港口人数按照S、C、Q递减,而且S远多于另外俩港口。
这个时候我们可能会有一些想法了:
- 不同舱位/乘客等级可能和财富/地位有关系,最后获救概率可能会不一样
- 年龄对获救概率也一定是有影响的,毕竟前面说了,副船长还说『小孩和女士先走』呢
- 和登船港口是不是有关系呢?也许登船港口不同,人的出身地位不同?
口说无凭,空想无益。老老实实再来统计统计,看看这些属性值的统计分布吧。
6.2 属性与获救结果的关联统计
#看看各乘客等级的获救情况
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数Survived_0 = data_train.Pclass[data_train.Survived == 0].value_counts()
Survived_1 = data_train.Pclass[data_train.Survived == 1].value_counts()
df=pd.DataFrame({u'获救':Survived_1, u'未获救':Survived_0})
df.plot(kind='bar', stacked=True)
plt.title(u"各乘客等级的获救情况")
plt.xlabel(u"乘客等级")
plt.ylabel(u"人数")
plt.show()
啧啧,果然,钱和地位对舱位有影响,进而对获救的可能性也有影响啊←_←
咳咳,跑题了,我想说的是,明显等级为1的乘客,获救的概率高很多。恩,这个一定是影响最后获救结果的一个特征。
#看看各性别的获救情况
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数Survived_m = data_train.Survived[data_train.Sex == 'male'].value_counts()
Survived_f = data_train.Survived[data_train.Sex == 'female'].value_counts()
df=pd.DataFrame({u'男性':Survived_m, u'女性':Survived_f})
df.plot(kind='bar', stacked=True)
plt.title(u"按性别看获救情况")
plt.xlabel(u"性别")
plt.ylabel(u"人数")
plt.show()
歪果盆友果然很尊重lady,lady first践行得不错。性别无疑也要作为重要特征加入最后的模型之中。
再来个详细版的好了。
#然后我们再来看看各种舱级别情况下各性别的获救情况
fig=plt.figure()
fig.set(alpha=0.65) # 设置图像透明度,无所谓
plt.title(u"根据舱等级和性别的获救情况")ax1=fig.add_subplot(141)
data_train.Survived[data_train.Sex == 'female'][data_train.Pclass != 3].value_counts().plot(kind='bar', label="female highclass", color='#FA2479')
ax1.set_xticklabels([u"获救", u"未获救"], rotation=0)
ax1.legend([u"女性/高级舱"], loc='best')ax2=fig.add_subplot(142, sharey=ax1)
data_train.Survived[data_train.Sex == 'female'][data_train.Pclass == 3].value_counts().plot(kind='bar', label='female, low class', color='pink')
ax2.set_xticklabels([u"未获救", u"获救"], rotation=0)
plt.legend([u"女性/低级舱"], loc='best')ax3=fig.add_subplot(143, sharey=ax1)
data_train.Survived[data_train.Sex == 'male'][data_train.Pclass != 3].value_counts().plot(kind='bar', label='male, high class',color='lightblue')
ax3.set_xticklabels([u"未获救", u"获救"], rotation=0)
plt.legend([u"男性/高级舱"], loc='best')ax4=fig.add_subplot(144, sharey=ax1)
data_train.Survived[data_train.Sex == 'male'][data_train.Pclass == 3].value_counts().plot(kind='bar', label='male low class', color='steelblue')
ax4.set_xticklabels([u"未获救", u"获救"], rotation=0)
plt.legend([u"男性/低级舱"], loc='best')plt.show()
- 1

恩,坚定了之前的判断。
我们看看各登船港口的获救情况。
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数Survived_0 = data_train.Embarked[data_train.Survived == 0].value_counts()
Survived_1 = data_train.Embarked[data_train.Survived == 1].value_counts()
df=pd.DataFrame({u'获救':Survived_1, u'未获救':Survived_0})
df.plot(kind='bar', stacked=True)
plt.title(u"各登录港口乘客的获救情况")
plt.xlabel(u"登录港口")
plt.ylabel(u"人数") plt.show()
下面我们来看看 堂兄弟/妹,孩子/父母有几人,对是否获救的影响。
g = data_train.groupby(['SibSp','Survived'])
df = pd.DataFrame(g.count()['PassengerId'])
print dfg = data_train.groupby(['SibSp','Survived'])
df = pd.DataFrame(g.count()['PassengerId'])
print df
- 1


好吧,没看出特别特别明显的规律(为自己的智商感到捉急…),先作为备选特征,放一放。
#ticket是船票编号,应该是unique的,和最后的结果没有太大的关系,先不纳入考虑的特征范畴把
#cabin只有204个乘客有值,我们先看看它的一个分布
data_train.Cabin.value_counts()
部分结果如下:

这三三两两的…如此不集中…我们猜一下,也许,前面的ABCDE是指的甲板位置、然后编号是房间号?…好吧,我瞎说的,别当真…
关键是Cabin这鬼属性,应该算作类目型的,本来缺失值就多,还如此不集中,注定是个棘手货…第一感觉,这玩意儿如果直接按照类目特征处理的话,太散了,估计每个因子化后的特征都拿不到什么权重。加上有那么多缺失值,要不我们先把Cabin缺失与否作为条件(虽然这部分信息缺失可能并非未登记,maybe只是丢失了而已,所以这样做未必妥当),先在有无Cabin信息这个粗粒度上看看Survived的情况好了。
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数Survived_cabin = data_train.Survived[pd.notnull(data_train.Cabin)].value_counts()
Survived_nocabin = data_train.Survived[pd.isnull(data_train.Cabin)].value_counts()
df=pd.DataFrame({u'有':Survived_cabin, u'无':Survived_nocabin}).transpose()
df.plot(kind='bar', stacked=True)
plt.title(u"按Cabin有无看获救情况")
plt.xlabel(u"Cabin有无")
plt.ylabel(u"人数")
plt.show()

咳咳,有Cabin记录的似乎获救概率稍高一些,先这么着放一放吧。
7.简单数据预处理
大体数据的情况看了一遍,对感兴趣的属性也有个大概的了解了。
下一步干啥?咱们该处理处理这些数据,为机器学习建模做点准备了。
对了,我这里说的数据预处理,其实就包括了很多Kaggler津津乐道的feature engineering过程,灰常灰常有必要!
『特征工程(feature engineering)太重要了!』
『特征工程(feature engineering)太重要了!』
『特征工程(feature engineering)太重要了!』
恩,重要的事情说三遍。
先从最突出的数据属性开始吧,对,Cabin和Age,有丢失数据实在是对下一步工作影响太大。
先说Cabin,暂时我们就按照刚才说的,按Cabin有无数据,将这个属性处理成Yes和No两种类型吧。
再说Age:
通常遇到缺值的情况,我们会有几种常见的处理方式
- 如果缺值的样本占总数比例极高,我们可能就直接舍弃了,作为特征加入的话,可能反倒带入noise,影响最后的结果了
- 如果缺值的样本适中,而该属性非连续值特征属性(比如说类目属性),那就把NaN作为一个新类别,加到类别特征中
- 如果缺值的样本适中,而该属性为连续值特征属性,有时候我们会考虑给定一个step(比如这里的age,我们可以考虑每隔2/3岁为一个步长),然后把它离散化,之后把NaN作为一个type加到属性类目中。
- 有些情况下,缺失的值个数并不是特别多,那我们也可以试着根据已有的值,拟合一下数据,补充上。
本例中,后两种处理方式应该都是可行的,我们先试试拟合补全吧(虽然说没有特别多的背景可供我们拟合,这不一定是一个多么好的选择)
我们这里用scikit-learn中的RandomForest来拟合一下缺失的年龄数据(注:RandomForest是一个用在原始数据中做不同采样,建立多颗DecisionTree,再进行average等等来降低过拟合现象,提高结果的机器学习算法,我们之后会介绍到)
from sklearn.ensemble import RandomForestRegressor### 使用 RandomForestClassifier 填补缺失的年龄属性
def set_missing_ages(df):# 把已有的数值型特征取出来丢进Random Forest Regressor中age_df = df[['Age','Fare', 'Parch', 'SibSp', 'Pclass']]# 乘客分成已知年龄和未知年龄两部分known_age = age_df[age_df.Age.notnull()].as_matrix()unknown_age = age_df[age_df.Age.isnull()].as_matrix()# y即目标年龄y = known_age[:, 0]# X即特征属性值X = known_age[:, 1:]# fit到RandomForestRegressor之中rfr = RandomForestRegressor(random_state=0, n_estimators=2000, n_jobs=-1)rfr.fit(X, y)# 用得到的模型进行未知年龄结果预测predictedAges = rfr.predict(unknown_age[:, 1::])# 用得到的预测结果填补原缺失数据df.loc[ (df.Age.isnull()), 'Age' ] = predictedAges return df, rfrdef set_Cabin_type(df):df.loc[ (df.Cabin.notnull()), 'Cabin' ] = "Yes"df.loc[ (df.Cabin.isnull()), 'Cabin' ] = "No"return dfdata_train, rfr = set_missing_ages(data_train)
data_train = set_Cabin_type(data_train)

恩。目的达到,OK了。
因为逻辑回归建模时,需要输入的特征都是数值型特征,我们通常会先对类目型的特征因子化。
什么叫做因子化呢?举个例子:
以Cabin为例,原本一个属性维度,因为其取值可以是[‘yes’,’no’],而将其平展开为’Cabin_yes’,’Cabin_no’两个属性
- 原本Cabin取值为yes的,在此处的”Cabin_yes”下取值为1,在”Cabin_no”下取值为0
- 原本Cabin取值为no的,在此处的”Cabin_yes”下取值为0,在”Cabin_no”下取值为1
我们使用pandas的”get_dummies”来完成这个工作,并拼接在原来的”data_train”之上,如下所示。
dummies_Cabin = pd.get_dummies(data_train['Cabin'], prefix= 'Cabin')dummies_Embarked = pd.get_dummies(data_train['Embarked'], prefix= 'Embarked')dummies_Sex = pd.get_dummies(data_train['Sex'], prefix= 'Sex')dummies_Pclass = pd.get_dummies(data_train['Pclass'], prefix= 'Pclass')df = pd.concat([data_train, dummies_Cabin, dummies_Embarked, dummies_Sex, dummies_Pclass], axis=1)
df.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True)
df

bingo,我们很成功地把这些类目属性全都转成0,1的数值属性了。
这样,看起来,是不是我们需要的属性值都有了,且它们都是数值型属性呢。
有一种临近结果的宠宠欲动感吧,莫急莫急,我们还得做一些处理,仔细看看Age和Fare两个属性,乘客的数值幅度变化,也忒大了吧!!如果大家了解逻辑回归与梯度下降的话,会知道,各属性值之间scale差距太大,将对收敛速度造成几万点伤害值!甚至不收敛! (╬▔皿▔)…所以我们先用scikit-learn里面的preprocessing模块对这俩货做一个scaling,所谓scaling,其实就是将一些变化幅度较大的特征化到[-1,1]之内。
import sklearn.preprocessing as preprocessing
scaler = preprocessing.StandardScaler()
age_scale_param = scaler.fit(df['Age'])
df['Age_scaled'] = scaler.fit_transform(df['Age'], age_scale_param)
fare_scale_param = scaler.fit(df['Fare'])
df['Fare_scaled'] = scaler.fit_transform(df['Fare'], fare_scale_param)
df
恩,好看多了,万事俱备,只欠建模。马上就要看到成效了,哈哈。我们把需要的属性值抽出来,转成scikit-learn里面LogisticRegression可以处理的格式。
8.逻辑回归建模
我们把需要的feature字段取出来,转成numpy格式,使用scikit-learn中的LogisticRegression建模。
from sklearn import linear_model# 用正则取出我们要的属性值
train_df = df.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')
train_np = train_df.as_matrix()# y即Survival结果
y = train_np[:, 0]# X即特征属性值
X = train_np[:, 1:]# fit到RandomForestRegressor之中
clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6)
clf.fit(X, y)clfgood,很顺利,我们得到了一个model,如下:

先淡定!淡定!你以为把test.csv直接丢进model里就能拿到结果啊…骚年,图样图森破啊!我们的”test_data”也要做和”train_data”一样的预处理啊!!
data_test = pd.read_csv("/Users/Hanxiaoyang/Titanic_data/test.csv")
data_test.loc[ (data_test.Fare.isnull()), 'Fare' ] = 0
# 接着我们对test_data做和train_data中一致的特征变换
# 首先用同样的RandomForestRegressor模型填上丢失的年龄
tmp_df = data_test[['Age','Fare', 'Parch', 'SibSp', 'Pclass']]
null_age = tmp_df[data_test.Age.isnull()].as_matrix()
# 根据特征属性X预测年龄并补上
X = null_age[:, 1:]
predictedAges = rfr.predict(X)
data_test.loc[ (data_test.Age.isnull()), 'Age' ] = predictedAgesdata_test = set_Cabin_type(data_test)
dummies_Cabin = pd.get_dummies(data_test['Cabin'], prefix= 'Cabin')
dummies_Embarked = pd.get_dummies(data_test['Embarked'], prefix= 'Embarked')
dummies_Sex = pd.get_dummies(data_test['Sex'], prefix= 'Sex')
dummies_Pclass = pd.get_dummies(data_test['Pclass'], prefix= 'Pclass')df_test = pd.concat([data_test, dummies_Cabin, dummies_Embarked, dummies_Sex, dummies_Pclass], axis=1)
df_test.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True)
df_test['Age_scaled'] = scaler.fit_transform(df_test['Age'], age_scale_param)
df_test['Fare_scaled'] = scaler.fit_transform(df_test['Fare'], fare_scale_param)
df_test

不错不错,数据很OK,差最后一步了。
下面就做预测取结果吧!!
test = df_test.filter(regex='Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')
predictions = clf.predict(test)
result = pd.DataFrame({'PassengerId':data_test['PassengerId'].as_matrix(), 'Survived':predictions.astype(np.int32)})
result.to_csv("/Users/Hanxiaoyang/Titanic_data/logistic_regression_predictions.csv", index=False)
啧啧,挺好,格式正确,去make a submission啦啦啦!
在Kaggle的Make a submission页面,提交上结果。如下:

0.76555,恩,结果还不错。毕竟,这只是我们简单分析处理过后出的一个baseline模型嘛。
9.逻辑回归系统优化
9.1 模型系数关联分析
亲,你以为结果提交上了,就完事了?
我不会告诉你,这只是万里长征第一步啊(泪牛满面)!!!这才刚撸完baseline model啊!!!还得优化啊!!!
看过Andrew Ng老师的machine Learning课程的同学们,知道,我们应该分析分析模型现在的状态了,是过/欠拟合?,以确定我们需要更多的特征还是更多数据,或者其他操作。我们有一条很著名的learning curves对吧。
不过在现在的场景下,先不着急做这个事情,我们这个baseline系统还有些粗糙,先再挖掘挖掘。
首先,Name和Ticket两个属性被我们完整舍弃了(好吧,其实是因为这俩属性,几乎每一条记录都是一个完全不同的值,我们并没有找到很直接的处理方式)。
然后,我们想想,年龄的拟合本身也未必是一件非常靠谱的事情,我们依据其余属性,其实并不能很好地拟合预测出未知的年龄。再一个,以我们的日常经验,小盆友和老人可能得到的照顾会多一些,这样看的话,年龄作为一个连续值,给一个固定的系数,应该和年龄是一个正相关或者负相关,似乎体现不出两头受照顾的实际情况,所以,说不定我们把年龄离散化,按区段分作类别属性会更合适一些。
上面只是我瞎想的,who knows是不是这么回事呢,老老实实先把得到的model系数和feature关联起来看看。
pd.DataFrame({"columns":list(train_df.columns)[1:], "coef":list(clf.coef_.T)})- 1

首先,大家回去前两篇文章里瞄一眼公式就知道,这些系数为正的特征,和最后结果是一个正相关,反之为负相关。
我们先看看那些权重绝对值非常大的feature,在我们的模型上:
- Sex属性,如果是female会极大提高最后获救的概率,而male会很大程度拉低这个概率。
- Pclass属性,1等舱乘客最后获救的概率会上升,而乘客等级为3会极大地拉低这个概率。
- 有Cabin值会很大程度拉升最后获救概率(这里似乎能看到了一点端倪,事实上从最上面的有无Cabin记录的Survived分布图上看出,即使有Cabin记录的乘客也有一部分遇难了,估计这个属性上我们挖掘还不够)
- Age是一个负相关,意味着在我们的模型里,年龄越小,越有获救的优先权(还得回原数据看看这个是否合理)
- 有一个登船港口S会很大程度拉低获救的概率,另外俩港口压根就没啥作用(这个实际上非常奇怪,因为我们从之前的统计图上并没有看到S港口的获救率非常低,所以也许可以考虑把登船港口这个feature去掉试试)。
- 船票Fare有小幅度的正相关(并不意味着这个feature作用不大,有可能是我们细化的程度还不够,举个例子,说不定我们得对它离散化,再分至各个乘客等级上?)
噢啦,观察完了,我们现在有一些想法了,但是怎么样才知道,哪些优化的方法是promising的呢?
因为test.csv里面并没有Survived这个字段(好吧,这是废话,这明明就是我们要预测的结果),我们无法在这份数据上评定我们算法在该场景下的效果…
而『每做一次调整就make a submission,然后根据结果来判定这次调整的好坏』其实是行不通的…
9.2 交叉验证
重点又来了:
『要做交叉验证(cross validation)!』
『要做交叉验证(cross validation)!』
『要做交叉验证(cross validation)!』
恩,重要的事情说三遍。我们通常情况下,这么做cross validation:把train.csv分成两部分,一部分用于训练我们需要的模型,另外一部分数据上看我们预测算法的效果。
我们用scikit-learn的cross_validation来帮我们完成小数据集上的这个工作。
先简单看看cross validation情况下的打分
from sklearn import cross_validation#简单看看打分情况
clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6)
all_data = df.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')
X = all_data.as_matrix()[:,1:]
y = all_data.as_matrix()[:,0]
print cross_validation.cross_val_score(clf, X, y, cv=5)- 2
结果是下面酱紫的:
[0.81564246 0.81005587 0.78651685 0.78651685 0.81355932]
似乎比Kaggle上的结果略高哈,毕竟用的是不是同一份数据集评估的。
等等,既然我们要做交叉验证,那我们干脆先把交叉验证里面的bad case拿出来看看,看看人眼审核,是否能发现什么蛛丝马迹,是我们忽略了哪些信息,使得这些乘客被判定错了。再把bad case上得到的想法和前头系数分析的合在一起,然后逐个试试。
下面我们做数据分割,并且在原始数据集上瞄一眼bad case:
# 分割数据,按照 训练数据:cv数据 = 7:3的比例
split_train, split_cv = cross_validation.train_test_split(df, test_size=0.3, random_state=0)
train_df = split_train.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')
# 生成模型
clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6)
clf.fit(train_df.as_matrix()[:,1:], train_df.as_matrix()[:,0])# 对cross validation数据进行预测cv_df = split_cv.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')
predictions = clf.predict(cv_df.as_matrix()[:,1:])origin_data_train = pd.read_csv("/Users/HanXiaoyang/Titanic_data/Train.csv")
bad_cases = origin_data_train.loc[origin_data_train['PassengerId'].isin(split_cv[predictions != cv_df.as_matrix()[:,0]]['PassengerId'].values)]
bad_cases我们判定错误的 bad case 中部分数据如下:

大家可以自己跑一遍试试,拿到bad cases之后,仔细看看。也会有一些猜测和想法。其中会有一部分可能会印证在系数分析部分的猜测,那这些优化的想法优先级可以放高一些。
现在有了”train_df” 和 “vc_df” 两个数据部分,前者用于训练model,后者用于评定和选择模型。可以开始可劲折腾了。
我们随便列一些可能可以做的优化操作:
- Age属性不使用现在的拟合方式,而是根据名称中的『Mr』『Mrs』『Miss』等的平均值进行填充。
- Age不做成一个连续值属性,而是使用一个步长进行离散化,变成离散的类目feature。
- Cabin再细化一些,对于有记录的Cabin属性,我们将其分为前面的字母部分(我猜是位置和船层之类的信息) 和 后面的数字部分(应该是房间号,有意思的事情是,如果你仔细看看原始数据,你会发现,这个值大的情况下,似乎获救的可能性高一些)。
- Pclass和Sex俩太重要了,我们试着用它们去组出一个组合属性来试试,这也是另外一种程度的细化。
- 单加一个Child字段,Age<=12的,设为1,其余为0(你去看看数据,确实小盆友优先程度很高啊)
- 如果名字里面有『Mrs』,而Parch>1的,我们猜测她可能是一个母亲,应该获救的概率也会提高,因此可以多加一个Mother字段,此种情况下设为1,其余情况下设为0
- 登船港口可以考虑先去掉试试(Q和C本来就没权重,S有点诡异)
- 把堂兄弟/兄妹 和 Parch 还有自己 个数加在一起组一个Family_size字段(考虑到大家族可能对最后的结果有影响)
- Name是一个我们一直没有触碰的属性,我们可以做一些简单的处理,比如说男性中带某些字眼的(‘Capt’, ‘Don’, ‘Major’, ‘Sir’)可以统一到一个Title,女性也一样。
大家接着往下挖掘,可能还可以想到更多可以细挖的部分。我这里先列这些了,然后我们可以使用手头上的”train_df”和”cv_df”开始试验这些feature engineering的tricks是否有效了。
试验的过程比较漫长,也需要有耐心,而且我们经常会面临很尴尬的状况,就是我们灵光一闪,想到一个feature,然后坚信它一定有效,结果试验下来,效果还不如试验之前的结果。恩,需要坚持和耐心,以及不断的挖掘。
我最好的结果是在『Survived~C(Pclass)+C(Title)+C(Sex)+C(Age_bucket)+C(Cabin_num_bucket)Mother+Fare+Family_Size』下取得的,结果如下(抱歉,博主君commit的时候手抖把页面关了,于是没截着图,下面这张图是在我得到最高分之后,用这次的结果重新make commission的,截了个图,得分是0.79426,不是目前我的最高分哈,因此排名木有变…):

9.3 learning curves
有一个很可能发生的问题是,我们不断地做feature engineering,产生的特征越来越多,用这些特征去训练模型,会对我们的训练集拟合得越来越好,同时也可能在逐步丧失泛化能力,从而在待预测的数据上,表现不佳,也就是发生过拟合问题。
从另一个角度上说,如果模型在待预测的数据上表现不佳,除掉上面说的过拟合问题,也有可能是欠拟合问题,也就是说在训练集上,其实拟合的也不是那么好。
额,这个欠拟合和过拟合怎么解释呢。这么说吧:
- 过拟合就像是你班那个学数学比较刻板的同学,老师讲过的题目,一字不漏全记下来了,于是老师再出一样的题目,分分钟精确出结果。but数学考试,因为总是碰到新题目,所以成绩不咋地。
- 欠拟合就像是,咳咳,和博主level差不多的差生。连老师讲的练习题也记不住,于是连老师出一样题目复习的周测都做不好,考试更是可想而知了。
而在机器学习的问题上,对于过拟合和欠拟合两种情形。我们优化的方式是不同的。
对过拟合而言,通常以下策略对结果优化是有用的:
- 做一下feature selection,挑出较好的feature的subset来做training
- 提供更多的数据,从而弥补原始数据的bias问题,学习到的model也会更准确
而对于欠拟合而言,我们通常需要更多的feature,更复杂的模型来提高准确度。
著名的learning curve可以帮我们判定我们的模型现在所处的状态。我们以样本数为横坐标,训练和交叉验证集上的错误率作为纵坐标,两种状态分别如下两张图所示:过拟合(overfitting/high variace),欠拟合(underfitting/high bias)


我们也可以把错误率替换成准确率(得分),得到另一种形式的learning curve(sklearn 里面是这么做的)。
回到我们的问题,我们用scikit-learn里面的learning_curve来帮我们分辨我们模型的状态。举个例子,这里我们一起画一下我们最先得到的baseline model的learning curve。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.learning_curve import learning_curve# 用sklearn的learning_curve得到training_score和cv_score,使用matplotlib画出learning curve
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None, n_jobs=1, train_sizes=np.linspace(.05, 1., 20), verbose=0, plot=True):"""画出data在某模型上的learning curve.参数解释----------estimator : 你用的分类器。title : 表格的标题。X : 输入的feature,numpy类型y : 输入的target vectorylim : tuple格式的(ymin, ymax), 设定图像中纵坐标的最低点和最高点cv : 做cross-validation的时候,数据分成的份数,其中一份作为cv集,其余n-1份作为training(默认为3份)n_jobs : 并行的的任务数(默认1)"""train_sizes, train_scores, test_scores = learning_curve(estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes, verbose=verbose)train_scores_mean = np.mean(train_scores, axis=1)train_scores_std = np.std(train_scores, axis=1)test_scores_mean = np.mean(test_scores, axis=1)test_scores_std = np.std(test_scores, axis=1)if plot:plt.figure()plt.title(title)if ylim is not None:plt.ylim(*ylim)plt.xlabel(u"训练样本数")plt.ylabel(u"得分")plt.gca().invert_yaxis()plt.grid()plt.fill_between(train_sizes, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std, alpha=0.1, color="b")plt.fill_between(train_sizes, test_scores_mean - test_scores_std, test_scores_mean + test_scores_std, alpha=0.1, color="r")plt.plot(train_sizes, train_scores_mean, 'o-', color="b", label=u"训练集上得分")plt.plot(train_sizes, test_scores_mean, 'o-', color="r", label=u"交叉验证集上得分")plt.legend(loc="best")plt.draw()plt.show()plt.gca().invert_yaxis()midpoint = ((train_scores_mean[-1] + train_scores_std[-1]) + (test_scores_mean[-1] - test_scores_std[-1])) / 2diff = (train_scores_mean[-1] + train_scores_std[-1]) - (test_scores_mean[-1] - test_scores_std[-1])return midpoint, diffplot_learning_curve(clf, u"学习曲线", X, y)
在实际数据上看,我们得到的learning curve没有理论推导的那么光滑哈,但是可以大致看出来,训练集和交叉验证集上的得分曲线走势还是符合预期的。
目前的曲线看来,我们的model并不处于overfitting的状态(overfitting的表现一般是训练集上得分高,而交叉验证集上要低很多,中间的gap比较大)。因此我们可以再做些feature engineering的工作,添加一些新产出的特征或者组合特征到模型中。
10.模型融合(model ensemble)
好了,终于到这一步了,我们要祭出机器学习/数据挖掘上通常最后会用到的大杀器了。恩,模型融合。
『强迫症患者』打算继续喊喊口号…
『模型融合(model ensemble)很重要!』
『模型融合(model ensemble)很重要!』
『模型融合(model ensemble)很重要!』
重要的事情说三遍,恩,噢啦。
先解释解释,一会儿再回到我们的问题上哈。
啥叫模型融合呢,我们还是举几个例子直观理解一下好了。
大家都看过知识问答的综艺节目中,求助现场观众时候,让观众投票,最高的答案作为自己的答案的形式吧,每个人都有一个判定结果,最后我们相信答案在大多数人手里。
再通俗一点举个例子。你和你班某数学大神关系好,每次作业都『模仿』他的,于是绝大多数情况下,他做对了,你也对了。突然某一天大神脑子犯糊涂,手一抖,写错了一个数,于是…恩,你也只能跟着错了。
我们再来看看另外一个场景,你和你班5个数学大神关系都很好,每次都把他们作业拿过来,对比一下,再『自己做』,那你想想,如果哪天某大神犯糊涂了,写错了,but另外四个写对了啊,那你肯定相信另外4人的是正确答案吧?
最简单的模型融合大概就是这么个意思,比如分类问题,当我们手头上有一堆在同一份数据集上训练得到的分类器(比如logistic regression,SVM,KNN,random forest,神经网络),那我们让他们都分别去做判定,然后对结果做投票统计,取票数最多的结果为最后结果。
bingo,问题就这么完美的解决了。
模型融合可以比较好地缓解,训练过程中产生的过拟合问题,从而对于结果的准确度提升有一定的帮助。
话说回来,回到我们现在的问题。你看,我们现在只讲了logistic regression,如果我们还想用这个融合思想去提高我们的结果,我们该怎么做呢?
既然这个时候模型没得选,那咱们就在数据上动动手脚咯。大家想想,如果模型出现过拟合现在,一定是在我们的训练上出现拟合过度造成的对吧。
那我们干脆就不要用全部的训练集,每次取训练集的一个subset,做训练,这样,我们虽然用的是同一个机器学习算法,但是得到的模型却是不一样的;同时,因为我们没有任何一份子数据集是全的,因此即使出现过拟合,也是在子训练集上出现过拟合,而不是全体数据上,这样做一个融合,可能对最后的结果有一定的帮助。对,这就是常用的Bagging。
我们用scikit-learn里面的Bagging来完成上面的思路,过程非常简单。代码如下:
from sklearn.ensemble import BaggingRegressortrain_df = df.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass.*|Mother|Child|Family|Title')
train_np = train_df.as_matrix()# y即Survival结果
y = train_np[:, 0]# X即特征属性值
X = train_np[:, 1:]# fit到BaggingRegressor之中
clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6)
bagging_clf = BaggingRegressor(clf, n_estimators=20, max_samples=0.8, max_features=1.0, bootstrap=True, bootstrap_features=False, n_jobs=-1)
bagging_clf.fit(X, y)test = df_test.filter(regex='Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass.*|Mother|Child|Family|Title')
predictions = bagging_clf.predict(test)
result = pd.DataFrame({'PassengerId':data_test['PassengerId'].as_matrix(), 'Survived':predictions.astype(np.int32)})
result.to_csv("/Users/HanXiaoyang/Titanic_data/logistic_regression_bagging_predictions.csv", index=False)然后你再Make a submission,恩,发现对结果还是有帮助的。

11.总结
文章稍微有点长,非常感谢各位耐心看到这里。
总结的部分,我就简短写几段,出现的话,很多在文中有对应的场景,大家有兴趣再回头看看。
对于任何的机器学习问题,不要一上来就追求尽善尽美,先用自己会的算法撸一个baseline的model出来,再进行后续的分析步骤,一步步提高。
在问题的结果过程中:
- 『对数据的认识太重要了!』
- 『数据中的特殊点/离群点的分析和处理太重要了!』
- 『特征工程(feature engineering)太重要了!』
- 『模型融合(model ensemble)太重要了!』
本文中用机器学习解决问题的过程大概如下图所示:

12.关于数据和代码
本文中的数据和代码已经上传至github中,欢迎大家下载和自己尝试。
下面的文章代码是R语言写的,转自:https://zhuanlan.zhihu.com/p/25185856
一些总结:
1、特征提取是非常关键的,例如从乘客姓名里去提取头衔,通过在船上的父母兄妹人数生成家庭人数,生成儿童和母亲这样的新变量!
2、缺失值的处理,对于有相同舱位等级(passenger class)和票价(Fare)的乘客也许有着相同的 登船港口位置embarkment,通过猜测来验证从而填充登录的港口数据!年龄缺失也是用的类似随机森林思路处理!
3、模型反馈:通过计算Gini系数得到相应变量的重要性排序,这个非常非常关键,对于特征提取可以说是一个结果验证!
【Kaggle实例分析】Titanic Machine Learning from Disaster
 KevinMeng
KevinMeng
你是不是也学了很久R语言的却还没有完完整整的把数据分析的整个流程走一遍。
跟着本文操作练习也许会是个不错的开始。
看完本文你将了解到:
1. 如何用R语言进行数据分析
2. 数据分析师的主要工作流程
3. 如何参加Kaggle比赛
======================
引言
本文采用Kaggle中比较知名的数据集Titanic Machine Learning from Disaster作为分析数据源。分析目的是根据训练集预测部分乘客在沉船事件中是否会存活?
当然不是问你Jack &Rose ^_^
该数据集被评为五大最适合数据分析练手项目之一。Five data science projects to learn data science
说明:本文除了细微处有所改动外,主体部分翻译借鉴自Megan L. Risdal文章。
本文的基本按照数据分析的整个流程进行:
- 数据清洗
- 特征工程
- 缺失值
- 模型设计与预测
下面具体看来
=======================
数据导入与概览
# 加载相应包
library('ggplot2') # 可视化
library('ggthemes') # 可视化
library('scales') # 可视化
library('dplyr') # 数据处理
library('mice') # 缺失值填补
library('randomForest') # 建模
加载完毕后,先将数据导入
【为了保证文章的可读性,部分代码运行结果以图片形式贴出】
train <- read.csv('train.csv', stringsAsFactors = F)
test <- read.csv('test.csv', stringsAsFactors = F)
#初步观察数据
# 检查数据
str(train)
str(test)
head(train)
head(test)
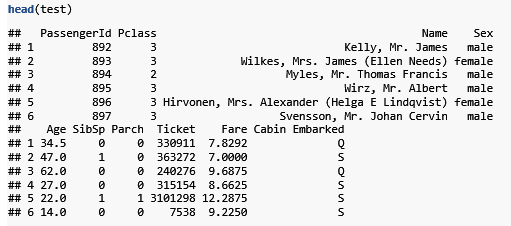
#可以看到,除了Survived字段不同外,其他字段均相同。合并训练集与测试集,为下一步数据清洗做准备
full <- bind_rows(train, test)
str(full)
summary(full)
合并后的数据除了生存情况(Survived)中缺失值NA有418个(需要预测的),年龄(Age)中缺失值有263个,船票费用(Fare)中缺失值有1个。
目前,我们已经对变量,变量类型,及其前几个取值情况有了初步的了解。 我们知道:我们有1309 个观测,其中训练集891个,测试集418个。 我们的目标是要预测生存情况(Survived)——因变量 可供使用的自变量11个
其各个变量对应的含义列示如下

-------------------------------
数据清洗
a. 观察姓名变量
首先,我注意到在乘客名字(Name)中,有一个非常显著的特点:乘客头衔每个名字当中都包含了具体的称谓或者说是头衔,将这部分信息提取出来后可以作为非常有用一个新变量,可以帮助我们预测。此外也可以用乘客的姓代替家庭,生成家庭变量。下面开始着手操作!
# 从乘客名字中提取头衔
full$Title <- gsub('(.*, )|(\\..*)', '', full$Name)# 查看按照性别划分的头衔数量?
table(full$Sex, full$Title)
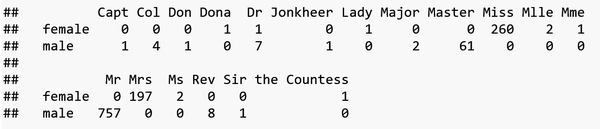
# 对于那些出现频率较低的头衔合并为一类
rare_title <- c('Dona', 'Lady', 'the Countess','Capt', 'Col', 'Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer')# 对于一些称呼进行重新指定(按含义) 如mlle, ms指小姐, mme 指女士
full$Title[full$Title =='Mlle']<- 'Miss'
full$Title[full$Title =='Ms'] <- 'Miss'
full$Title[full$Title =='Mme']<- 'Mrs'
full$Title[full$Title %in% rare_title] <- 'Rare Title'# 重新查看替换后的情况
table(full$Sex, full$Title)

# 最后从乘客姓名中,提取姓氏
full$Surname <- sapply(full$Name, function(x) strsplit(x, split = '[,.]')[[1]][1])
我们有 875 唯一姓氏. 有时间的话可以通过发掘乘客姓氏之间的联系,也许会有意外发现,这里就先不做深入探讨了.
b.家庭情况是否会影响生存结果?
目前为止我们已经处理完乘客姓名这一变量,并从其中提取了一些新的变量。 下一步考虑衍生一些家庭相关的变量 首先,生成家庭人数family size 这一变量。可以基于已有变量SubSp和Parch(具体含义参照上面)
# 生成家庭人数变量,包括自己在内
full$Fsize <- full$SibSp + full$Parch + 1# 生成一个家庭变量:以姓_家庭人数 格式
full$Family <- paste(full$Surname, full$Fsize, sep='_')# 使用 ggplot2 绘制家庭人数与生存情况之间的关系
ggplot(full[1:891,], aes(x = Fsize, fill = factor(Survived))) +geom_bar(stat='count', position='dodge') +scale_x_continuous(breaks=c(1:11)) +labs(x = 'Family Size') +theme_few()
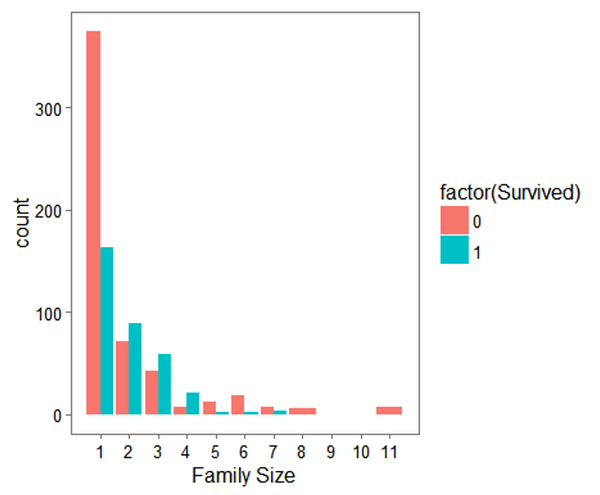 通过图形我们可以明显发现以下特点:
通过图形我们可以明显发现以下特点:
- 1 个人上船和家庭人数>4人的家庭的存活人数小于死亡人数
- 2 家庭人数size在[2:4]的存活人数要高于死亡人数
因此我们可以将家庭人数变量进行分段合并,明显的可以分为3段:个人,小家庭,大家庭,由此生成新变量.
# 离散化
full$FsizeD[full$Fsize == 1] <- 'singleton'
full$FsizeD[full$Fsize < 5 & full$Fsize > 1]<- 'small'
full$FsizeD[full$Fsize > 4] <- 'large'# 通过马赛克图(mosaic plot)查看家庭规模与生存情况之间关系
mosaicplot(table(full$FsizeD,full$Survived), main='Family Size by Survival', shade=TRUE)
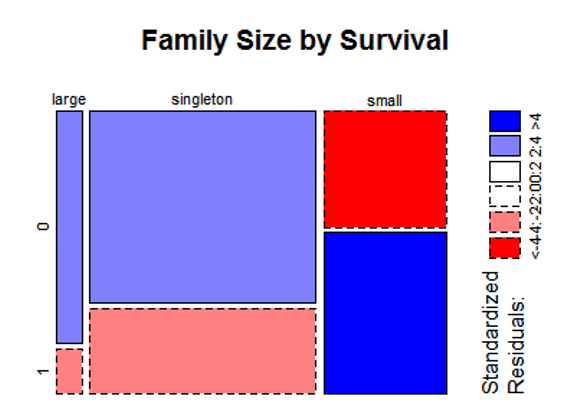
从图上也可以显而易见的观察出来,个人与大家庭不利于生存下来,而相对的小家庭当中生存率相对较高
c. 试着生成更多变量
可以发现在乘客客舱变量 passenger cabin 也存在一些有价值的信息如客舱层数 deck. .
# 可以看出这一变量有很多缺失值
full$Cabin[1:28]

# 第一个字母即为客舱层数.如:
strsplit(full$Cabin[2], NULL)[[1]]## [1]
"C" "8" "5"# 建立一个层数变量(Deck)变化取值从 A - F:
full$Deck<-factor(sapply(full$Cabin, function(x) strsplit(x, NULL)[[1]][1]))
summary(full$Deck)

这里有很多可以进一步操作的地方,如有些乘客名下包含很多间房 (e.g., row 28: "C23 C25 C27"), 但是考虑到这一变量数值的稀疏性(sparseness),有1014 个缺失值。 后面就不再进一步考虑。
------------------------
缺失值
现在我们开始对原始数据当中的缺失值进行处理(填补)。
具体做法有很多种,考虑到数据集本身较小,样本数也不多,因而不能直接整行或者整列删除缺失值样本。那么只能通过现有数据和变量对缺失值进行预估填补 例如:可以用均值中位数模型 填补缺失值,这里使用后面两种方式进行。
a. 登船港口缺失——中位数
# 乘客 62 and 830 缺少登船港口信息。
full[c(62, 830), 'Embarked']
## [1] "" ""
我估计对于有相同舱位等级(passenger class)和票价(Fare)的乘客也许有着相同的 登船港口位置embarkment .我们可以看到他们支付的票价分别为: $ 80 和 $ 80 同时他们的舱位等级分别是: 1 和 1 . 那么他们最有可能是在哪个港口登船的呢?
# 去除缺失值乘客的ID
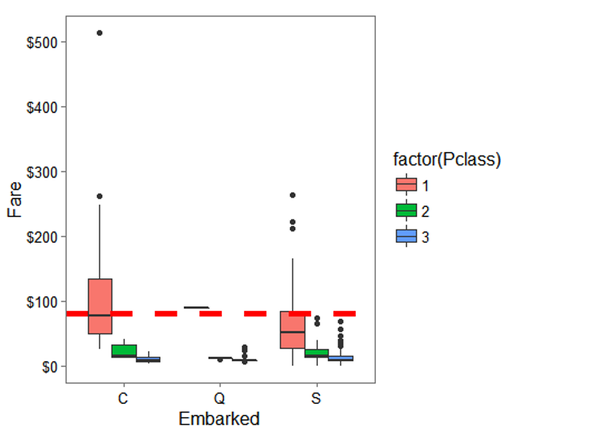
embark_fare <- full %>% filter(PassengerId != 62 & PassengerId != 830)# 用 ggplot2 绘制embarkment, passenger class, & median fare 三者关系图
ggplot(embark_fare, aes(x = Embarked, y = Fare, fill = factor(Pclass))) +geom_boxplot() +geom_hline(aes(yintercept=80), colour='red', linetype='dashed', lwd=2) +scale_y_continuous(labels=dollar_format()) +theme_few()
 很明显!
很明显!
从港口 ('C')出发的头等舱支付的票价的中位数为80。因此我们可以放心的把处于头等舱且票价在$80的乘客62和830 的出发港口缺失值替换为'C'.
# 因为他们票价为80且处于头等舱,因而他们很有可能都是从港口C登船的。
full$Embarked[c(62, 830)] <- 'C'
b. 票价缺失 ——中位数
这里发现1044行的乘客票价为空值
# 提取1044行数据
full[1044, ]

这是从港口Southampton ('S')出发的三等舱乘客。 从相同港口出发且处于相同舱位的乘客数目为 (n = 494).
ggplot(full[full$Pclass == '3' & full$Embarked == 'S', ], aes(x = Fare)) +geom_density(fill = '#99d6ff', alpha=0.4) + geom_vline(aes(xintercept=median(Fare, na.rm=T)),colour='red', linetype='dashed', lwd=1) +scale_x_continuous(labels=dollar_format()) + theme_few()
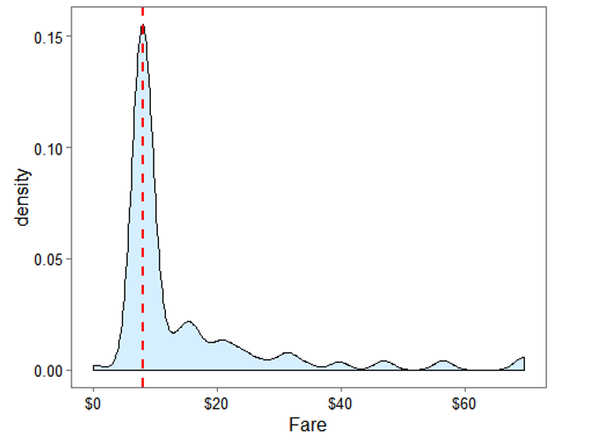
从得到的图形上看,将缺失值用中位数进行替换是合理的。替换数值为$8.05.
# 基于出发港口和客舱等级,替换票价缺失值
full$Fare[1044] <- median(full[full$Pclass == '3' & full$Embarked == 'S', ]$Fare, na.rm = TRUE)
c. 年龄缺失——预测填补
最后,正如我们之前观察到的,在用户年龄(Age) 中有大量的缺失存在。 这里我们将基于年龄和其他变量构建一个预测模型对年龄缺失值进行预测
# S统计缺失数量
sum(is.na(full$Age))
## [1] 263
通常我们会使用 rpart (recursive partitioning for regression) 包来做缺失值预测 在这里我将使用 mice 包进行处理。具体理由,你可以通过阅读关于基于链式方程 Chained Equations的多重插补法Multiple Imputation(MICE)的内容MICE (PDF). 在这之前我们先要对因子变量(factor variables)因子化,然后再进行多重插补法。
# 使因子变量因子化
factor_vars <- c('PassengerId','Pclass','Sex','Embarked','Title','Surname','Family','FsizeD')full[factor_vars] <- lapply(full[factor_vars],function(x) as.factor(x))# 设置随机种子
set.seed(129)# 执行多重插补法,剔除一些没什么用的变量:
mice_mod <- mice(full[, !names(full) %in% c('PassengerId','Name','Ticket','Cabin','Family','Surname','Survived')], method='rf') # 保存完整输出
mice_output <- complete(mice_mod)
让我们对比数据填补前与填补后的数据分布情况。确保数据分布没用发生偏移
# 绘制年龄分布图
par(mfrow=c(1,2))
hist(full$Age, freq=F, main='Age: Original Data', col='darkgreen', ylim=c(0,0.04))
hist(mice_output$Age, freq=F, main='Age: MICE Output', col='lightgreen', ylim=c(0,0.04))
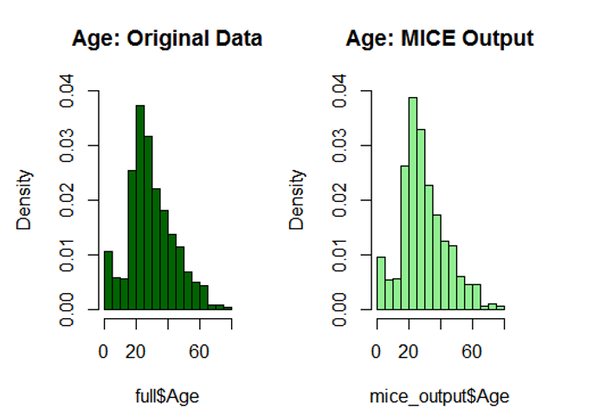
结果看起来不错,那么下面可以用mice模型的结果对原年龄数据进行替换。
# MICE模型结果替换年龄变量.
full$Age <- mice_output$Age# 检查缺失值是否被完全替换了
sum(is.na(full$Age))## [1] 0
现在,我们已经完成了对所有重要变量的缺失值的替换工作。 但是这一切还没结束,我们可以对年龄变量进一步对的划分 ..
-----------------------------------
特征工程2
现在我们知道每一位乘客的年龄,那么我们可以基于年龄生成一些变量如儿童(Child)和 母亲(Mother).
划分标准:
- 儿童 : 年龄Age < 18
- 母亲 : 1 女性; 2 年龄 > 18; 3 拥有超过1个子女 4 头衔不是'Miss'.
# 首先我们来看年龄与生存情况之间的关系
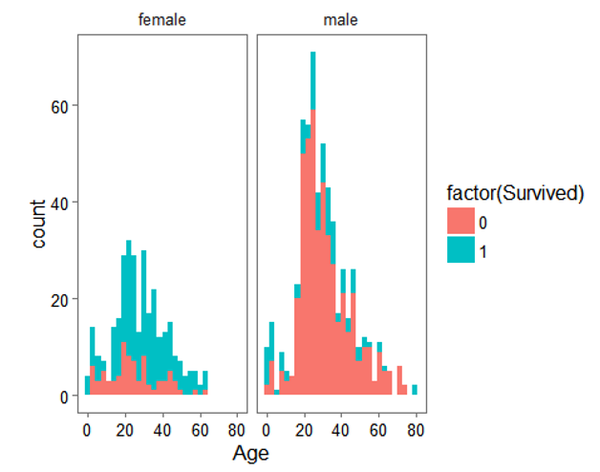
ggplot(full[1:891,], aes(Age, fill = factor(Survived))) + geom_histogram() + # 分性别来看,因为前面我们知道 性别对于生存情况有重要影响facet_grid(.~Sex) + theme_few()
# 生成儿童(child)变量, 并且基于此划分儿童child与成人adult
full$Child[full$Age < 18] <- 'Child'
full$Child[full$Age >= 18] <- 'Adult'# 展示对应人数
table(full$Child, full$Survived)
##
## 0 1
## Adult 484 274
## Child 65 68
从结果看,儿童的生存率要高于成人但是这并不意味着作为儿童就一定可以生还。正如我们当年看《泰坦尼克号》电影时,最后船员要求母亲和儿童先上船一样。
下面来生成母亲这个变量.
# 生成母亲变量
full$Mother <- 'NotMother'full$Mother[full$Sex =='female' & full$Parch > 0 & full$Age > 18 & full$Title != 'Miss'] <- 'Mother'# 统计对于数量
table(full$Mother, full$Survived)##
## 0 1
## Mother 16 39
## Not Mother 533 303# 对新生成的两个变量完成因子化。
full$Child <- factor(full$Child)
full$Mother <- factor(full$Mother)
至此,所有我们需要的变量都已经生成,并且其中没有缺失值。 为了保险起见,我们进行二次确认。
#这个起到什么作用?
md.pattern(full)
现在我们终于完成对泰坦尼克数据集(the Titanic dataset)中所有的变量缺失值的填补,并基于原有变量构建了一些新变量,希望这些可以在最终的生存情况预测时起到帮助。
----------------------
模型设定与预测
在完成上面的工作之后,我们进入到最后一步:预测泰坦尼克号上乘客的生存状况。 在这里我们使用随机森林分类算法(The RandomForest Classification Algorithm) 我们前期那么多工作都是为了这一步服务的。
a. 拆分训练集与测试集
我们第一步需要将数据变回原先的训练集与测试集.
# 将数据拆分为训练集与测试集
train <- full[1:891,]
test <- full[892:1309,]
b. 建立模型
我们利用训练集训练建立随机森林 randomForest 模型.
# 设置随机种子
set.seed(754)# 建立模型l (注意: 不是所有可用变量全部加入)
rf_model <- randomForest(factor(Survived) ~ Pclass + Sex + Age + SibSp + Sex*Parch + Fare + Embarked + Title + FsizeD + Child + Mother, data = train)# 显示模型误差
plot(rf_model, ylim=c(0,0.36))
legend('topright', colnames(rf_model$err.rate), col=1:3, fill=1:3)
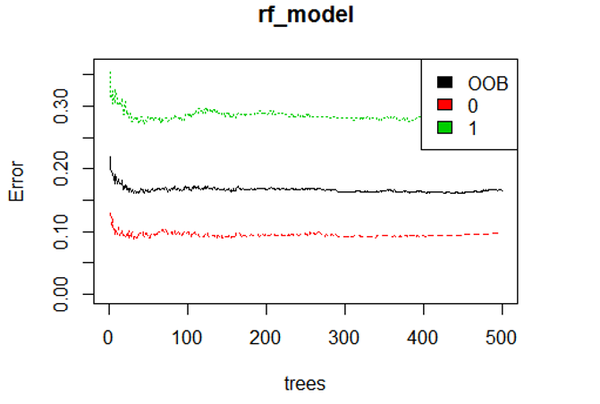
黑色那条线表示:整体误差率(the overall error rate)低于20% 红色和绿色分别表示:遇难与生还的误差率 至此相对于生还来说,我们可以更准确的预测出死亡。
c.变量重要性
通过计算Gini系数得到相应变量的重要性排序
# 获取重要性系数
importance <- importance(rf_model)
varImportance <- data.frame(Variables = row.names(importance), Importance = round(importance[ ,'MeanDecreaseGini'],2))# 基于重要性系数排列变量
rankImportance <- varImportance %>% mutate(Rank = paste0('#',dense_rank(desc(Importance))))#通过 ggplot2 绘制相关重要性变量图
ggplot(rankImportance, aes(x = reorder(Variables, Importance), y = Importance, fill = Importance)) +geom_bar(stat='identity') + geom_text(aes(x = Variables, y = 0.5, label = Rank),hjust=0, vjust=0.55, size = 4, colour= 'red') +labs(x = 'Variables') +coord_flip() + theme_few()
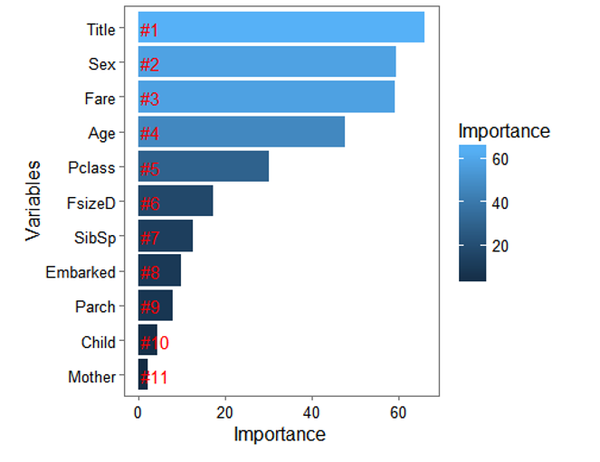
我们从图上可以看出哪些变量才是对我们预测最重要的变量 从图上看头衔和性别对于生存情况影响最大,其次是船票价格和年龄。而相应的乘客舱位排第五。 而最出乎我意料的是母亲和孩子对于生存与否的影响最小排在11和10. 这个我小时候看泰坦尼克号的印象相差甚远。
d.预测
下面到了最后一步了----预测结果! 在这里可以把刚才建立的模型直接应用在测试集上。 但为了达到最佳的预测结果,我们也可以重新构建不同的模型,或者用不同的变量进行组合。
# 基于测试集进行预测
prediction <- predict(rf_model, test)# 将结果保存为数据框,按照Kaggle提交文档的格式要求。[两列:PassengerId and Survived (prediction)]
solution <- data.frame(PassengerID = test$PassengerId, Survived = prediction)# 将结果写入文件
write.csv(solution, file = 'rf_mod_Solution1.csv', row.names = F)
得到的文件大家就可以上传Kaggle获取自己的排名情况啦~
当然前提你得有个Kaggle账号。注册kaggle
比赛页面:Titanic: Machine Learning from Disaster
Ps:Kaggle上不光可以参加比赛,还可以学习其他优秀选手分享的经验、以及一些代码等。
借此机会,好好逛逛吧~
-----------------------------
总结
本次案例讲解到这里就全部结束了。 后面大家想要继续提高排名,提高预测的准确率,则需要构建一些新的变量或是构建新的模型,大家可以自由探索和发挥。
感谢你花时间阅读这样一篇基于Kaggle 数据集的数据分析流程的介绍,希望对你有帮助~
【如果你有提高预测准确率的方法请留言或者私信告诉我~】
参考资料:
Titanic: Machine Learning from Disaster -by Megan L. Risdal
总结:
如果大家都用同样的算法库,影响最终结果的,就是三个因素(因为没法获得更多的数据):1、数据的预处理方式 2、特征工程 3、算法的参数调整。 数据的处理包括丢失数据的处理,数据类型的转换。
转自:http://blog.csdn.net/wiking__acm/article/details/42742961
在udacity上学完了intro to maching learning后,来Kaggle上实践一下。第一次做kaggle的比赛,收获非常大!开始时茫茫没头绪,就学tutorials里的代码, 大致明白了解这种题的框架是个什么样子。然后从头实现自己的代码,做出了第一个结果后,准确率偏低,不知道该从哪个方面下手提高准确率。然后去看论坛的讨论,看别人写的解题博客,还要经常查sklearn和panda的文档。
感觉在数据挖掘竞赛中,如果大家都用同样的算法库,影响最终结果的,就是三个因素(因为没法获得更多的数据):1、数据的预处理方式 2、特征工程 3、算法的参数调整。 数据的处理包括丢失数据的处理,数据类型的转换。特征工程则是最复杂的部分,有人可以利用已有的特征挖掘出更多的特征,有的特征是多余的,这个过程中有很多方法。参数调整可以利用gridsearch这样的工具,但还是乏味无聊的。毕竟第一次做比赛,经验还太少,有些体会可能也是不对的,如果有错,期待大家的批评指正。也期待有朋友可以交流这个比赛!一个完成基本任务的代码如下。
pandas as pd
import csv
from sklearn.ensemble import RandomForestClassifier
from sklearn.cross_validation import cross_val_score
from sklearn.grid_search import GridSearchCV, RandomizedSearchCV # read in the training and testing data into Pandas.DataFrame objects
input_df = pd.read_csv('train.csv', header=0)
submit_df = pd.read_csv('test.csv', header=0) # merge the two DataFrames into one
df = pd.concat([input_df, submit_df])
df = df .reset_index()
df = df.drop('index', axis=1)
df = df.reindex_axis(input_df.columns, axis=1) #print df.info()
#print df.describe() """ cope with the missing data """ # 1.'Cabin', seems useless, too much missing, two ways to handle it
# (1) drop this feature
df = df.drop('Cabin', axis=1)
# (2) assign a value represent it's missing
#df[df['Cabin'].isnull()] = 'missing' # 2. 'Age', a important feature, we can't just drop it, two ways to handle it
# (1) fill it with median
df['Age'][df['Age'].isnull()] = df['Age'].median()
# (2) use a simple model to predict it, after everything else is fixed.In this case,
# the accuracy of the experiment consequence is too low,so we give up this method. # 3. 'Fare', only one miss, just use the median
df['Fare'][df['Fare'].isnull()] = df['Fare'].median() # 4.'Embarked', two miss, use the most frequency word
df['Embarked'][df['Embarked'].isnull()] = df['Embarked'].mode().values """ feature engineering """ # 1. 'Sex', factorizing it
df['Sex'] = pd.factorize(df['Sex'])[0] # 2. 'Name', we can drag some title from the name, for simplicity, I just drop it
df = df.drop('Name', axis=1) # 3. 'Ticket', for simlicity, just drop it
df = df.drop('Ticket', axis=1) # 4. 'Embarked', factorizing it
df['Embarked'] = pd.factorize(df['Embarked'])[0] # 5. 'SibSp', 'Parch', combine them to get a new feature, 'Famliy_size'
df['Family_size'] = df['SibSp']+df['Parch'] """ train the model """ df = df.drop(['PassengerId', 'SibSp', 'Parch'], axis=1)
known_survived = df[df['Survived'].notnull()].values
unknown_survived = df[df['Survived'].isnull()].values Y = known_survived[:, 0]
X = known_survived[:, 1:] clf = RandomForestClassifier(n_estimators=1000, random_state=312, min_samples_leaf=3).fit(X, Y)
#print cross_val_score(clf, X, Y).mean()
#print df.columns
#print clf.feature_importances_ """ predict and write to csv file """ pred = clf.predict(unknown_survived[:, 1:]).astype(int)
ids = submit_df['PassengerId'] predictions_file = open("myfirstsubmission.csv", "wb")
open_file_object = csv.writer(predictions_file)
open_file_object.writerow(["PassengerId","Survived"])
open_file_object.writerows(zip(ids, pred))
predictions_file.close() print 'done.' 摘自:https://github.com/yew1eb/DM-Competition-Getting-Started/tree/master/kaggle-titanic
说句题外话,网上貌似有遇难者名单,LB上好几个score 1.0的。有坊间说,score超过90%就怀疑作弊了,不知真假,不过top300绝大多数都集中在0.808-0.818。这个题目我后面没有太多的改进想法了,求指导啊~ 数据包括数值和类别特征,并存在缺失值。类别特征这里我做了one-hot-encode,缺失值是采用均值/中位数/众数需要根据数据来定,我的做法是根据pandas打印出列数据分布来定。 模型我采用了DT/RF/GBDT/SVC,由于xgboost输出是概率,需要指定阈值确定0/1,可能我指定不恰当,效果不好0.78847。 效果最好的是RF,0.81340。这里经过筛选我使用的特征包括’Pclass’,’Gender’, ‘Cabin’,’Ticket’,’Embarked’,’Title’进行onehot编码,’Age’,’SibSp’,’Parch’,’Fare’,’class_age’,’Family’ 归一化。 我也尝试进行构建一些新特征和特征组合,比如title分割为Mr/Mrs/Miss/Master四类或者split提取第一个词,添加fare_per_person等,pipeline中也加入feature selection,但是效果都没有提高,求指导~
kaggle数据挖掘竞赛初步--Titanic
[Kaggle Titanic Competition Part I – Intro] (http://www.ultravioletanalytics.com/2014/10/30/kaggle-titanic-competition-part-i-intro/)
[Kaggle Competition | Titanic Machine Learning from Disaster] (http://nbviewer.ipython.org/github/agconti/kaggle-titanic/blob/master/Titanic.ipynb)
https://github.com/agconti/kaggle-titanic
http://www.sotoseattle.com/blog/categories/kaggle/
[Titanic: Machine Learning from Disaster - Getting Started With R] https://github.com/trevorstephens/titanic https://github.com/wehrley/wehrley.github.io/blob/master/SOUPTONUTS.md
http://mlwave.com/tutorial-titanic-machine-learning-from-distaster/ Full Titanic Example with Random Forest https://www.youtube.com/watch?v=0GrciaGYzV0
[Tutorial: Titanic dataset machine learning for Kaggle] (http://corpocrat.com/2014/08/29/tutorial-titanic-dataset-machine-learning-for-kaggle/)
[Getting Started with R: Titanic Competition in Kaggle] (http://armandruiz.com/kaggle/Titanic_Kaggle_Analysis.html)
A complete guide to getting 0.79903 in Kaggle’s Titanic Competition with Python 机器学习系列(3)_逻辑回归应用之Kaggle泰坦尼克之灾 https://www.kaggle.com/malais/titanic/kaggle-first-ipythonnotebook/notebook
下面的文章要点在上述几个里面几乎都提到了,就是再度熟悉下流程即可!
摘自:https://duyiqi17.github.io/2017/01/29/my-first-kaggle/
写在前面
这个项目中目前我所使用到的算法只有 RandomForest(随机森林算法) 这也是Kaggle官方在案例中所提到的算法,在CSDN的一篇博文上找到了很具体的介绍,具体算法的原理和过程打算单独写一篇笔记。
整个的实现过程自己先看了一下Youtube上面Step By Step的视频,整个视频的核心观点是不管三七二十一先实现一个最最最简单的模型,然后再来不断优化这个数据集里的特征和进行参数调优,感觉能够快速上手对于我来说也是一种不错的选择。
在看这个视频之前自己也百度/Google了同一例子的教程,其中对参数处理也有很多让我大开眼界的方法,于是打算结合前者的思想和后者的方法,实现一次训练,完成自己在Kaggle上的第一次提交。
了解/处理数据
使用pandas来处理数据,首先引入一些必要的库。
|
1
2
3
4
5
6
7
8
9
10
|
# 引入随机森林
from sklearn.ensemble import RandomForestRegressor
# 引入ROC/AUC Scroe
from sklearn.metrics import roc_auc_score
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('whitegrid')
%matplotlib inline
|
然后我们把数据集加载到项目中
|
1
2
3
|
#装载数据
X_train=pd.read_csv("train.csv")
X_test=pd.read_csv("test.csv")
|
随后我们使用X_train.info()来大概了解一下数据集的情况,得到的结果如下
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
|
可以看到有一些属性是由缺失的并且并不是每一个属性都是数值类型,然而sklearn的随机森林算法只能处理数值类型的值,因此我们需要对这些属性进行处理,这里的处理和可视化方法参考了这篇文章的一些方法。
处理Embarked
Embarked在数据集中是指上船的港口,从我们自己的认知角度来看,在哪个地方上船和最终能不能活下来应该是没有太多关系的,因此我在这里使用了这个参数在数据集中的众数来填充缺失的部分,然后使用seaborn把上船港口和幸存情况的分布关系显示出来
|
1
2
|
X_train.loc[X_train['Embarked'].isnull(),'Embarked']=X_train.Embarked.dropna().mode().values
sns.factorplot('Embarked','Survived', data=X_train,size=4,aspect=3)
|

于此同时,我们也把乘客上船港口的分布情况、幸存情况和平均生还的情况用图表的形式展示出来

到目前为止,我们的Embarked参数还是一个字符型的变量S、C、Q,接下来我们使用pandas的get_dummies方法将这些参数变成一个参数矩阵把它们追加到训练集和测试集上,然后我们把原有的Embarked列删除掉
|
1
2
3
4
5
6
7
8
|
#处理训练集
embark_dummies_titanic=pd.get_dummies(X_train['Embarked'])
X_train=X_train.join(embark_dummies_titanic)
X_train.drop(["Embarked"],axis=1, inplace=True)
#处理测试集
embark_dummies_titanic=pd.get_dummies(X_test['Embarked'])
X_test=X_test.join(embark_dummies_titanic)
X_test.drop(["Embarked"],axis=1, inplace=True)
|
处理过后的数据集变成了这样

处理Fare
对比训练集和测试集,我们发现只有测试集的Fare是由缺失的并且只缺失了一项,因此我们直接用这一项的中位数来填充。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 418 entries, 0 to 417
Data columns (total 13 columns):
PassengerId 418 non-null int64
Pclass 418 non-null int64
Name 418 non-null object
Sex 418 non-null object
Age 332 non-null float64
SibSp 418 non-null int64
Parch 418 non-null int64
Ticket 418 non-null object
Fare 417 non-null float64
Cabin 91 non-null object
C 418 non-null uint8
Q 418 non-null uint8
S 418 non-null uint8
dtypes: float64(2), int64(4), object(4), uint8(3)
memory usage: 34.0+ KB
|
|
1
|
X_test["Fare"].fillna(X_test["Fare"].median(), inplace=True)
|
然后,我们需要将Fare的数据类型从float型转换为int型
|
1
2
|
X_train['Fare'] = X_train['Fare'].astype(int)
X_test['Fare'] = X_test['Fare'].astype(int)
|
之后,让我们对Fare特征进行一些可视化的操作,比如将数据分为幸存和没有幸存的两类,分别查看一下对应的均值、标准差这些信息,如图。


处理年龄
对于年龄的处理应该是这道题目比较关键的一个环节了,从训练集中可以看到年龄属性的缺失是比较严重的,这里有几种考虑
- 使用随机生成的介于 (mean - std) & (mean + std) 之间的数据作为缺失值
- 用算法根据已有年龄的样本预测缺失值
这里考虑使用训练集中已有年龄的样本为依据,用一个简单的随机森林,预测缺失值。
|
1
2
3
4
5
6
7
8
9
10
11
|
# 预测缺失的年龄字段
age_df=X_train[['Age','Survived',"Pclass","Fare","Parch","SibSp","C","Q","S"]]
age_df_notnull=age_df.loc[(X_train.Age.notnull())] # 训练集
age_df_isnull=age_df.loc[(X_train.Age.isnull())] #测试集
X=age_df_notnull.values[:,1:]
Y=age_df_notnull.values[:,0]
#训练模型
age_rfr=RandomForestRegressor(n_estimators=1000,n_jobs=-1)
age_rfr.fit(X,Y)
|
然后我们用得到的模型来拟合缺失年龄的样本
|
1
2
|
pridectAges=age_rfr.predict(age_df_isnull.values[:,1:])
X_train.loc[(X_train.Age.isnull()),'Age']=pridectAges
|
现在年龄的处理差不多就算完成了,我们还需要将训练得到的模型用在测试集的缺失处理上

让我们来看一看年龄的一些分布情况
|
1
2
3
4
5
6
|
X_train['Age'] = X_train['Age'].astype(int)
# peaks for survived/not survived passengers by their age
facet = sns.FacetGrid(X_train, hue="Survived",aspect=4)
facet.map(sns.kdeplot,'Age',shade= True)
facet.set(xlim=(0, X_train['Age'].max()))
facet.add_legend()
|

|
1
2
3
4
|
# average survived passengers by age
fig, axis1 = plt.subplots(1,1,figsize=(18,4))
average_age = X_train[["Age", "Survived"]].groupby(['Age'],as_index=False).mean()
sns.barplot(x='Age', y='Survived', data=average_age)
|

处理姓名
看了一些文章,有的文章中直接把姓名这一项丢掉了,也有的文章认为姓名中的一些称谓说明了这个人的社会地位,因此对于是否能够逃生也有一定的影响。我比较认同后者的观点,所以也打算对名字进行一些处理。
对于名字中的称呼,在法语和英语中有一定的差别,具体的话网上找到的这段代码能够比较详细的解释。
|
1
2
3
4
5
6
7
8
|
import re
# 处理名字中的称谓
X_train['Title'] = X_train['Name'].map(lambda x: re.compile(",(.*?)\.").findall(x)[0])
X_train.loc[(X_train.Title==' Jonkheer'),"Title"]="Mater"
X_train.loc[(X_train.Title.isin([' Ms',' Mlle'])),"Title"]="Miss"
X_train.loc[(X_train.Title == ' Mme'),"Title"]="Mrs"
X_train.loc[(X_train.Title.isin([' Capt', ' Don', ' Major', ' Col', ' Sir'])),"Title"]= 'Sir'
X_train.loc[(X_train.Title.isin([' Dona', ' Lady', ' the Countess'])),"Title"]= 'Lady'
|
现在我们来看看训练集中不同身份的乘客的可视化分布情况

我们对测试集也做同样的处理
|
1
2
3
4
5
6
|
X_test['Title'] = X_test['Name'].map(lambda x: re.compile(",(.*?)\.").findall(x)[0])
X_test.loc[(X_test.Title==' Jonkheer'),"Title"]="Mater"
X_test.loc[(X_test.Title.isin([' Ms',' Mlle'])),"Title"]="Miss"
X_test.loc[(X_test.Title == ' Mme'),"Title"]="Mrs"
X_test.loc[(X_test.Title.isin([' Capt', ' Don', ' Major', ' Col', ' Sir'])),"Title"]= 'Sir'
X_test.loc[(X_test.Title.isin([' Dona', ' Lady', ' the Countess'])),"Title"]= 'Lady'
|
然后我们依然使用pandas提供的factorize方法来讲我们的Title属性变为数值类型的属性。
|
1
2
|
X_train['Title']=pd.factorize(X_train.Title)[0]+1
X_test['Title']=pd.factorize(X_test.Title)[0]+1
|
处理Cabin
从测试集和训练集的数据情况看,两个数据集都大量的缺失Cabin字段,因此我们在分析时考虑直接去除这个字段。
|
1
2
|
X_train.drop("Cabin",axis=1,inplace=True)
X_test.drop("Cabin",axis=1,inplace=True)
|
处理Family
原始数据中sibsp和parch分别表示了该名乘客同行的伴侣或兄弟的数量和同行的父母或子女的数量,在处理的过程中我们可以把它们看做一个变量也就是家人的数量,并且为了简化我们不关心这个乘客有几名家人我们只关心这名乘客是不是有家人。
具体的操作如下。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
#训练集
X_train['Family'] = X_train["Parch"] + X_train["SibSp"]
X_train.loc[(X_train['Family'] > 0),"Family"] = 1
X_train.loc[(X_train['Family'] == 0),"Family"] = 0
#测试集
X_test['Family'] = X_test["Parch"] + X_test["SibSp"]
X_test.loc[(X_test['Family'] > 0),"Family"] = 1
X_test.loc[(X_test['Family'] == 0),"Family"] = 0
#删除原有的两个数据
X_train = X_train.drop(['SibSp','Parch'], axis=1)
X_test = X_test.drop(['SibSp','Parch'], axis=1)
|
这样操作过后,我们就可以对是否有家人陪伴与是否幸存的关系进行一个比较直观的观察了。
|
1
2
3
4
5
6
7
8
9
10
11
|
# plot
fig, (axis1,axis2) = plt.subplots(1,2,sharex=True,figsize=(10,5))
# sns.factorplot('Family',data=titanic_df,kind='count',ax=axis1)
sns.countplot(x='Family', data=X_train, order=[1,0], ax=axis1)
# average of survived for those who had/didn't have any family member
family_perc = X_train[["Family", "Survived"]].groupby(['Family'],as_index=False).mean()
sns.barplot(x='Family', y='Survived', data=family_perc, order=[1,0], ax=axis2)
axis1.set_xticklabels(["With Family","Alone"], rotation=0)
|

处理性别
就我们自己的理解来说,儿童(小于16岁)获救的几率要比成年人要大,因此在处理性别对生还影响的时候我们将性别分为Male、Female和Child
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
def get_person(passenger):
age,sex = passenger
return 'child' if age < 16 else sex
X_train['Person'] = X_train[['Age','Sex']].apply(get_person,axis=1)
X_test['Person'] = X_test[['Age','Sex']].apply(get_person,axis=1)
# No need to use Sex column since we created Person column
X_train.drop(['Sex'],axis=1,inplace=True)
X_test.drop(['Sex'],axis=1,inplace=True)
# create dummy variables for Person column, & drop Male as it has the lowest average of survived passengers
person_dummies_train = pd.get_dummies(X_train['Person'])
person_dummies_train.columns = ['Child','Female','Male']
person_dummies_test = pd.get_dummies(X_test['Person'])
person_dummies_test.columns = ['Child','Female','Male']
|
合并这两个表格
|
1
2
|
X_train = X_train.join(person_dummies_train)
X_test = X_test.join(person_dummies_test)
|
可视化展示一下这几个类别的生还情况,男同胞牺牲很大啊。
|
1
2
3
4
5
6
7
8
9
10
|
fig, (axis1,axis2) = plt.subplots(1,2,figsize=(10,5))
sns.countplot(x='Person', data=X_train, ax=axis1)
# average of survived for each Person(male, female, or child)
person_perc = X_train[["Person", "Survived"]].groupby(['Person'],as_index=False).mean()
sns.barplot(x='Person', y='Survived', data=person_perc, ax=axis2, order=['male','female','child'])
X_train.drop(['Person'],axis=1,inplace=True)
X_test.drop(['Person'],axis=1,inplace=True)
|

处理舱位

上图是舱位和生还情况的一个分布,可以看到头等舱生还率是最高的(万恶的资本主义…),处理舱位,我们只需要用pandas的get_dummies进行处理就可以了。
|
1
2
3
4
5
6
7
8
9
10
11
|
pclass_dummies_titanic = pd.get_dummies(X_train['Pclass'])
pclass_dummies_titanic.columns = ['Class_1','Class_2','Class_3']
pclass_dummies_test = pd.get_dummies(X_test['Pclass'])
pclass_dummies_test.columns = ['Class_1','Class_2','Class_3']
X_train.drop(['Pclass'],axis=1,inplace=True)
X_test.drop(['Pclass'],axis=1,inplace=True)
X_train = X_train.join(pclass_dummies_titanic)
X_test = X_test.join(pclass_dummies_test)
|
第一次训练
完成好上边的处理,准备开始第一次训练啦。选用的方法是随机森林算法,在开始训练之前,我们还需要构造训练集,把一些没用的参数删除掉
|
1
2
3
|
X_trainsets=X_train.drop(['Name','Ticket',"PassengerId","Survived"],axis=1)
Y_trainsets=X_train.pop("Survived")
X_testsets=X_test.drop(['Name','Ticket',"PassengerId"],axis=1)
|
然后构建一棵随机森林树
|
1
2
3
4
5
6
7
|
random_forest = RandomForestRegressor(n_estimators=1000,n_jobs=-1)
random_forest.fit(X_trainsets, Y_trainsets)
Y_pred = random_forest.predict(X_testsets)
random_forest.score(X_trainsets, Y_trainsets)
|
如图所示是结果

可以看到得分大概在0.85左右,我们把第一次训练的结果保存下来,庆祝一下阶段性完工哈哈。
|
1
2
3
4
5
6
|
# 保存
submission = pd.DataFrame({
"PassengerId": X_test["PassengerId"],
"Survived": Y_pred
})
submission.to_csv('titanic.csv', index=False)
|
提交结果
完成了上面的操作过后,兴致勃勃的去提交结果,但是爆了一堆错,才注意到提交的结果生存的越策应该是0或者1,所以改了一下代码
|
1
2
3
4
5
6
7
8
9
|
# 保存
submission = pd.DataFrame({
"PassengerId": X_test["PassengerId"],
"Survived": Y_pred
})
submission.loc[(submission.Survived>0.5),"Survived"]=1
submission.loc[(submission.Survived<=0.5),"Survived"]=0
submission["Survived"]=submission["Survived"].astype(int)
submission.to_csv('titanic.csv', index=False)
|
提交结果后迫不及待的去看自己的得分和排名,果然作为萌新结果还是差强人意的…..

后记
感觉处理得不太科学的地方:
- 对于年龄的处理
- 变量的选取
- 拟合方法参数的问题
理想和现实果然还是有很大的差距,依样画葫芦完成了这样一个“实验”感觉要学的东西确实还有很多很多很多啊。前两天去听了一个国学大师的讲座,她说:
人二十岁以前的容颜是由年龄决定的,二十岁以后的容颜是由肚子里的知识和脑子里的信念决定的。
二十一岁写的第一篇博客,做完的第一个实验,想要达到自己追求的境界,显然还有很长很长的一段路,不过既然已经启程了,就不再在乎路远的事情了。
我想做一个更好的自己。
转载于:https://www.cnblogs.com/bonelee/p/7198616.html
机器学习案例学习【每周一例】之 Titanic: Machine Learning from Disaster相关推荐
- 小白的机器学习之路(1)---Kaggle竞赛:泰坦尼克之灾(Titanic Machine Learning from Disaster)
我是目录 前言 数据导入 可视化分析 Pclass Sex Age SibSp Parch Fare Cabin Embarked 特征提取 Title Family Size Companion A ...
- Kaggle | Titanic - Machine Learning from Disaster【泰坦尼克号生存预测】 | baseline及优秀notebook总结
文章目录 一.数据介绍 二.代码 三.代码优化方向 一.数据介绍 Titanic - Machine Learning from Disaster是主要针对机器学习初学者开展的比赛,数据格式比较简 ...
- 大数据第一课(满分作业)——泰坦尼克号生存者预测(Titanic - Machine Learning from Disaster)
大数据第一课(满分作业)--泰坦尼克号生存者预测(Titanic - Machine Learning from Disaster) 1 项目背景 1.1 The Challenge 1.2 What ...
- 【Kaggle】Titanic - Machine Learning from Disaster(二)
文章目录 1. 前言 2. 预备-环境配置 3. 数据集处理 3.1 读取数据集 3.2 查看pandas数据信息 3.2.1 查看总体信息 3.2.2 数据集空值统计 3.3. 相关性分析 3.3. ...
- 【kaggle入门题一】Titanic: Machine Learning from Disaster
原题: Start here if... You're new to data science and machine learning, or looking for a simple intro ...
- Kaggle——泰坦尼克号(Titanic: Machine Learning from Disaster)详细过程
一.简介 1.数据 (1)训练集(train.csv) (2)测试集(test.csv) (3)提交文件示例(gender_submission.csv) 对于训练集,我们为每位乘客提供结果.模型将基 ...
- 数据分析入门项目之 :Titanic: Machine Learning from Disaster
1.摘要: 本文详述了新手如何通过数据预览,探索式数据分析,缺失数据填补,删除关联特征以及派生新特征等数据处理方法,完成Kaggle的Titanic幸存预测要求的内容和目标. 2.背景介绍: Tita ...
- Kaggle比赛(一)Titanic: Machine Learning from Disaster
泰坦尼克号幸存预测是本小白接触的第一个Kaggle入门比赛,主要参考了以下两篇教程: https://www.cnblogs.com/star-zhao/p/9801196.html https:// ...
- Titanic: Machine Learning from Disaster-kaggle入门赛-学习笔记
Titanic: Machine Learning from Disaster 对实验用的数据的认识,数据中的特殊点/离群点的分析和处理,特征工程(feature engineering)很重要. 注 ...
最新文章
- Test Reprot
- Unity钢铁以及玻璃材质的选择
- C#中快速设置控件的相关事件
- keyshot详细安装教程
- 设计模式:装饰模式(Decorator)
- EF中Take和Skip的区别
- 低格硬盘用什么软件_迟来的评测:用了三年后的固态硬盘会变成什么样呢?
- css关键字unset
- 计算机硬盘改回基本磁盘,将动态磁盘更改回基本磁盘
- 董明珠赞同取消住房公积金 格力员工每人一套房
- iOS开发值苹果手机各种尺寸详细表以及iPhoneX、iPhoneXS、iPhoneXR、iPhoneXSMax屏幕适配
- linux 双显卡如何切换显卡,解决Ubuntu双显卡切换问题
- 门门通还是精通一门(程序员)
- 为自己选一个网络硬盘
- Abp vnext Web应用程序开发教程 5 —— 授权
- xinetd使用指南
- 重启随机游走(RWR)算法
- 认认真真做事,勤勤恳恳做人
- 赞雨林木风:从修改版到定制版
- JDBC (Java DB Connection)---Java数据库连接
热门文章
- win 2008 控制共享文件夹大小_win10如何一键网络共享
- 为提高访问速度建立本地文件服务器,html5 Application Cache——加快简历二次访问速度...
- 饥荒海难机器人怎么用_饥荒:海难是一款野外生存游戏
- fio模拟mysql写入速度_IO压力测试工具 -- FIO 使用说明
- linux 进程装入 物理内存 页表,linux进程空间一步步探究.doc
- arduinows2812灯条程序_Arduino 控制WS2812 LED灯条
- 温度 数值模拟 matlab,西安交通大学 - 温度场数值模拟(matlab)
- GCC中的分支预测(likely和unlikey)
- Keras【Deep Learning With Python】Autoencoder 自编码(看不懂你打我系列!)
- python中栈_Python中的栈