能通过一张照片(2D)得到3D的模型吗?
链接:https://www.zhihu.com/question/52934069/answer/132784366
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
<img src="https://pic2.zhimg.com/v2-72484972fcab52884c8526d43716fb71_b.png" data-rawwidth="392" data-rawheight="172" class="content_image" width="392">

[1] Chai, Menglei, et al. "High-quality hair modeling from a single portrait photo."ACM Transactions on Graphics (TOG) 34.6 (2015): 204.
这一篇的关注点是从单张图片中如何高质量的还原出头发的模型。不过整体是基于以前还原头像的工作来做的。可以看到基本上是类似于浮雕的效果,头发的还原度非常高。当然鼻子的高度之类的东西可能就很难还原了。
还有一些老文,比如99年的这篇基于可变性模型做的想过也是非常的惊艳。大致思路是给人脸建立一个参数化的模型,通过调节这个参数化的模型去拟合输入图像。
<img src="https://pic3.zhimg.com/v2-26a3eb77e5f0a3393fe12870424490d6_b.png" data-rawwidth="688" data-rawheight="168" class="origin_image zh-lightbox-thumb" width="688" data-original="https://pic3.zhimg.com/v2-26a3eb77e5f0a3393fe12870424490d6_r.png">[2]Blanz, Volker, and Thomas Vetter. "A morphable model for the synthesis of 3D faces."
[2]Blanz, Volker, and Thomas Vetter. "A morphable model for the synthesis of 3D faces."Proceedings of the 26th annual conference on Computer graphics and interactive techniques. ACM Press/Addison-Wesley Publishing Co., 1999.
对于任意的物体,这篇工作提出了一种方法,不过要求提供和被重建物体同一类的三维模型来提供先验知识
<img src="https://pic1.zhimg.com/v2-3f1cb2b865896e24202cbf5010336cd4_b.png" data-rawwidth="697" data-rawheight="212" class="origin_image zh-lightbox-thumb" width="697" data-original="https://pic1.zhimg.com/v2-3f1cb2b865896e24202cbf5010336cd4_r.png">[3] Li, Dongping, et al. "Shape Completion from a Single RGBD Image." (2016).
[3] Li, Dongping, et al. "Shape Completion from a Single RGBD Image." (2016).
不需要先验知识的也有,不过生成的就不是模型,而是点云了。比如这篇文章的工作,可以通过手机摄像头拍摄视频来获取3D 信息。可以看到有很多缺失的部分,一方面因为单目相机很难记录完整的3D 信息,另一方面因为有些部位由于遮挡拍不到。
<img src="https://pic3.zhimg.com/v2-e0cd3668a9e88a35575f0e4fb60a163a_b.png" data-rawwidth="325" data-rawheight="205" class="content_image" width="325"> <img src="https://pic1.zhimg.com/v2-0d6197a40f3f25ce489747f41bbbd7d8_b.png" data-rawwidth="347" data-rawheight="265" class="content_image" width="347">[4] Tanskanen, Petri, et al. "Live metric 3d reconstruction on mobile phones."
<img src="https://pic1.zhimg.com/v2-0d6197a40f3f25ce489747f41bbbd7d8_b.png" data-rawwidth="347" data-rawheight="265" class="content_image" width="347">[4] Tanskanen, Petri, et al. "Live metric 3d reconstruction on mobile phones." 
[4] Tanskanen, Petri, et al. "Live metric 3d reconstruction on mobile phones."Proceedings of the IEEE International Conference on Computer Vision. 2013.
其他的还有很多我就不一一例举了。
链接:https://www.zhihu.com/question/52934069/answer/132797149
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
题主的问题在计算机视觉领域里还是很前沿的。但是由于对3D模型这块描述的并不精确,其实可以理解为两种意思,但是无论哪种都是很值得深入探索的方向。
第一种。3D Scene Reconstruction / 三维场景重建
在这个领域里,最早的工作可能要在10-20年前就已经出现了。那个时候的 vision 是 pre-deep learning 时代,所以大家都是提出数学方法,相对来说比较五花八门。通常来说,single image 3D scene reconstruction 就是通过单张图片来重新估测他的深度信息,以此来得到他的结构。因此在这里没有任何填补其他未知信息的成分,跟我们普通所认为的三维重建稍稍有些不一样。(vision领域里会认为这是2.5D)
比较著名的作品有 Andrew Ng 的几个作品(cornell.edu 的页面,umich.edu 的页面)核心思想都是通过 orientation, co-planar, co-linearity 类似点线面结构关系来构造 grid-structure Markov Random Field (MRF) 来计算每个像素处在哪个平面。
<img src="https://pic4.zhimg.com/v2-6e968e4be5a5ce48ff037fb3ee21552f_b.png" data-rawwidth="704" data-rawheight="383" class="origin_image zh-lightbox-thumb" width="704" data-original="https://pic4.zhimg.com/v2-6e968e4be5a5ce48ff037fb3ee21552f_r.png">
第二种。3D Object Reconstruction / 三维物体重建
在这里的绝大部分工作相对比较新。因为学习一个物体完整的架构是需要大数据支撑的,因此基本上所有类似的工作都是有深度学习的框架在。由于传统3D模型 (3D CAD Model)是由 vertices 和 triangulation mesh 组成的。因此不一样的数据大小就造成了training的一些困难。后续,大家都用 voxelization 的方法把所有CAD model转成binary voxel (1是填补的0是空缺的)这样保证了每个模型都是equal size。
最早比较著名的工作是 3DShapeNet (princeton.edu 的页面) 作者利用 Deep Belief Network (DBN)来学习 voxel 的 probabilistic embedding 然后在给带有2.5D信息的图片后,通过 Gibbs Sampling来不断预测他的 shape class 和填补他的未知 voxel 来完成模型重建。这项工作也同时提出了比较著名的ModelNet数据集。
后续有 CMU最近的作品 TL Network(arxiv.org 的页面) 利用 auto-encoder 学习3D Model 的 embedding 然后通过 ConvNets 学习一个 deterministic function 让其 rendered image infer 到学习到的 embedding 上。因为 auto-encoder 是 generative 的, 对于新的 test image,模型就会infer 到相关的 3D model 的 embedding,再通过decoder 生成 其相应的 3D model。
<img src="https://pic1.zhimg.com/v2-033ef24a0fb6ed9f644819fde140ee10_b.png" data-rawwidth="1183" data-rawheight="315" class="origin_image zh-lightbox-thumb" width="1183" data-original="https://pic1.zhimg.com/v2-033ef24a0fb6ed9f644819fde140ee10_r.png">
最近刚出结果的 NIPS 2016, 吴家俊也做出了类似的工作 (jiajunwu.com 的页面),其中把 auto-encoder 换成 generative 能力更强的 GAN 然后把 ConvNet 换成了 VAE。
其中由于 voxel 是三维的,他的 resolution 就成了指数增长,在上述介绍的工作中一般都使用 小于等于 32^3 voxel 来防止过多占用内存。因此以下还有几个问题值得我们继续深入研究:
- 如何将voxel 的分辨率进一步提高。
- 如何利用较小的数据而保持相对不差的重建结果。
- 能否用先前学习到对三维模型的解读使得架构可以重建从来没有训练过的数据类别。
链接:https://www.zhihu.com/question/52934069/answer/132813092
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
有的答主提到一张照片可以建模,其实是通过分析光影建的一个'假3D'。
道理等同人眼,闭一只眼睛理论上看不出深度(物体前后顺序)。然而人可以根据生活经验,可以根据光影猜出深度,并不准确。计算机同理,通过算法对比高光和阴影也可以猜个一二。
硬广一个,我们是咋拍3D的<img src="https://pic2.zhimg.com/v2-0126ea160956299d85da4cf8171c8da5_b.jpg" data-rawwidth="800" data-rawheight="533" class="origin_image zh-lightbox-thumb" width="800" data-original="https://pic2.zhimg.com/v2-0126ea160956299d85da4cf8171c8da5_r.jpg">这些个角度拍3D比较够了。
这些个角度拍3D比较够了。
很常见的应用例如各种法线贴图生成工具(xnormal),一张照片生成个置换或法线贴图,闹呢。
另外研究国外(包括迪士尼)的论文要谨慎,有的是完美的实验室环境,你懂的。例如石头表面质地亚光是最理想的3d扫描材质,如果本身颜色均匀靠分析深浅也有可能建出个低模来。有的一百个案例里挑出两个最好的结果,憋问我是咋知道的...
---------------------------------
那么问题来了,为啥我们肉眼看一张照片能看出深度呢?不管一只还是两只眼。
因为照片里的光线信息已经被“烘焙”进去了,如之前所述,大脑通过分析光源阴影判断出深度。
就像长者一样见多识广,什么大风大浪没见过。
在一个完美的均匀光源下,四只眼也看不出深度。举个栗子,下面是我们矩阵三维扫描出来的。
<img src="https://pic2.zhimg.com/v2-fa296447997ed946863ff32dc1b6b5f5_b.jpg" data-rawwidth="664" data-rawheight="600" class="origin_image zh-lightbox-thumb" width="664" data-original="https://pic2.zhimg.com/v2-fa296447997ed946863ff32dc1b6b5f5_r.jpg">
如果吓到你了我很抱歉,我想拿这张图吓人已经很久了。
你看脸颊部分显得很平,可以明显看出深度的仅限鼻翼和耳朵附近,这部分把光打匀几乎不可能。
做CG特效需要这种漫反射贴图,光影是渲染器分析几何图形结合贴图合成一起才看出立体效果。
---------------------------------
不过人眼人脑是个很好玩的东西,我有个朋友有种怪病,啥都能看得出来,就是认不出来人脸。他判断人名不看脸,靠听声音加观察举止习惯,这个素材库有点大。
想想跟女朋友说:我爱的是你的内涵,literally。
有位答主举的例子:<img src="https://pic2.zhimg.com/v2-6be626c50ba555c1d789826eefad1ff1_b.png" data-rawwidth="347" data-rawheight="265" class="content_image" width="347">
这个显然不是一张照片建模,绝对是多张,具体多少张看不出来,如果有单色点云我还能猜猜。
为啥呢,你看照片并没有拍到右脸颊。
链接:https://www.zhihu.com/question/52934069/answer/132865914
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
最近一直在做有关计算机视觉与深度学习,尤其是怎么在3维与4维空间(也就是视频处理)实施,干脆把想法发到知乎,具体的算法会在arxiv详细介绍。
--------------------------------------------------------------------------
1. 单张图片的处理方法
我把图片简单分为三大类,分别是:正常图片,光场图片和人类的视觉图片
正常的图片是指用普通光学相机拍摄,图中包含,聚焦,欠焦,过焦等区域
光场相机(Light-field camera),简单来说就是除去RGB值与XY的位置外还有光线的角度信息的图片,例如lytro的相机拍摄的图片。
人类视觉的图片,人眼的广义像素有1.2亿,实际分辨率与中高端相机相当,并且转动灵活,聚焦速度超快。
1.1. 单张正常的图片的处理方法
加入深度学习,在识别出物体后可以通过估算物体的大致尺寸计算距离,准确度不高。简单说就是近大远小。
再接合透视发,就更天衣无缝了。
<img src="https://pic3.zhimg.com/v2-5695d48e0866582e41844107827e33fa_b.jpg" data-rawwidth="1920" data-rawheight="1080" class="origin_image zh-lightbox-thumb" width="1920" data-original="https://pic3.zhimg.com/v2-5695d48e0866582e41844107827e33fa_r.jpg">
简单的画画,例如大裤衩:
图片来自google
通过透视处理后,空间感觉也就出来了啊。这也就是我们看图片就可以重构出空间感的基础。
除了图片的空间重塑,还可还原ps过的照片了啊。引用一个大家都熟悉的照片。
<img src="https://pic2.zhimg.com/v2-e0b9fce24a35f7cfb411a723a180f3b5_b.png" data-rawwidth="757" data-rawheight="503" class="origin_image zh-lightbox-thumb" width="757" data-original="https://pic2.zhimg.com/v2-e0b9fce24a35f7cfb411a723a180f3b5_r.png">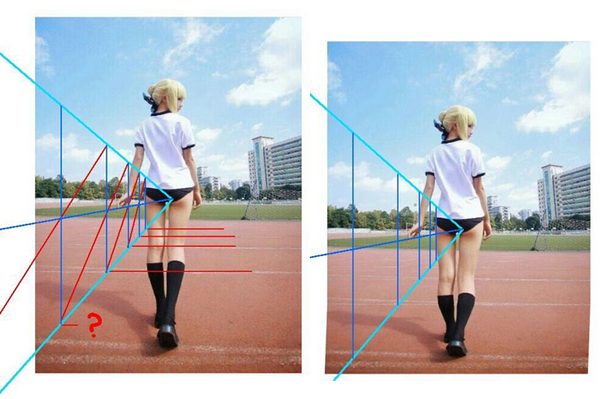
原图来自知乎的日报
谁有兴趣可以试试基于深度学习开开发一个反ps软件,过滤一下我们的眼睛。
当然在实际使用中要考虑到相机的产生,例如用鱼眼相机的话,要对图片预处理后再进行分析。
1.2. 单张光场相机图片的方法
光场相机的问题。保存了光线的角度与方向的信息。通过简单的三角函数计算也是可以得到大致的三维信息的。
1.3. 人类的眼睛,通过眼睛聚焦,两眼的视角差,可以感知深度3维的信息。
正如@xxx所说,关键是,我们都是生活在三维空间中,大脑中早已形成了空间分析的模式。一岁以下的婴儿他们的三空间认知能力就比较差。
值得一提的是普林斯顿的Jianxiong Xiao组接合深度图片(depth map)与普通RGB图片集合的深度学习(Deep Learning in N Dimensions)。但是由于depth map不能在有自然光照的室外使用,该方法还仅限于室内。接合Lidar数据后就适合室外作业了啊,不过从google self-driving car前BOSS Sebastian Thrun早在2011年的TED演讲中就可以看出他们已经开始三维的识别了啊。注意途中的小框,就是被标识的物体。
<img src="https://pic2.zhimg.com/v2-d671c0670d1fd6d58002d771f347d269_b.png" data-rawwidth="852" data-rawheight="485" class="origin_image zh-lightbox-thumb" width="852" data-original="https://pic2.zhimg.com/v2-d671c0670d1fd6d58002d771f347d269_r.png">
图片来自Thrun的TED演讲截屏
2 多张图片的问题
其实我们在日常生活中接触的都是连续的信息,不知道远近可以换个角度看,总之就是在运动中观察来得到整体的三维的信息。比如在盗梦空间中的彭罗斯阶梯(Penrose stairs),在三维空间中无法存在,但是有些特色的形状可以在某些特定的投影面中存在。
<img src="https://pic3.zhimg.com/v2-6b23b4e43fd360a5c0486208193ac3d2_b.png" data-rawwidth="372" data-rawheight="283" class="content_image" width="372">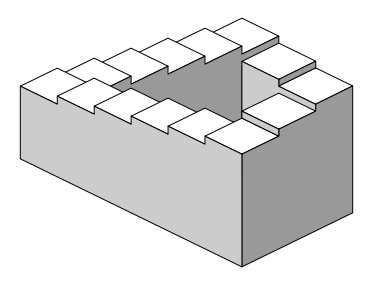
原图来自维基百科
大致三维重塑过程大致可以分为两种
一种类似人眼物体跟踪的光流法
一种更为精确的Image Cross Correlation集合的测绘方法
突然发现程序有点问题,等debug后再补充图。
[1612.00603] A Point Set Generation Network for 3D Object Reconstruction from a Single Image
作者首次利用deep learning对输入图像生成其点云:

再利用另一个6层的CNN将point set处理成连续的3D结构
 与人类相比在部分数据集上有优势:
与人类相比在部分数据集上有优势:
 point cloud相对简单,没有连接性问题,方便training
point cloud相对简单,没有连接性问题,方便training
作者基于TensorFlow设计实现了一个多层CNN,探讨了数种distance metric, 设计和选择了cost function and loss function, 并探讨了该方法的其他功能,如从RGB-depth 图像从补全缺失的3D结构(下图),及出错的情形。人工合成的dataset有220k张图片来自2000种物品。

类似工作:
https://arxiv.org/abs/1604.00449
PS:ls貌似竟然出现了这篇文章投CVPR2017的reviewer,真是藏龙卧虎啊···仰慕
能通过一张照片(2D)得到3D的模型吗?相关推荐
- 能通过一张照片(2D)得到3D的模型吗?AI自动识别户型图生成3D场景方案
参考文献: 基于形状与边缘特征的户型图识别研究_江州.caj 面向自动家装生成的户型图识别方法研究_黄文.caj 基于深度学习的青年公寓户型自动生成研究_杨柳.caj 基于结构构件识别的户型图三维重建 ...
- Rmxprt Maxwell 生成2D和3D全模型方法
使用ansys 19.2 maxwell 一键生成有限元模型功能,往往会出现2D或者3D仿真只有一部分,其实那是周期模型 要想生成全模型,可以在Rmxprt/design settings/User ...
- 证件照转数字人只需几秒钟,微软实现首个3D扩散模型高质量生成效果,换装改形象一句话搞定 | CVPR 2023...
转载自 微软亚洲研究院 量子位 | 公众号 QbitAI 一张2D证件照,几秒钟就能设计出3D游戏化身! 这是扩散模型在3D领域的最新成果.例如,只需一张法国雕塑家罗丹的旧照,就能分分钟把他" ...
- 用html5制作机柜,基于HTML5 Canvas 点击添加 2D 3D 机柜模型
今天又返回好好地消化了一下我们的数据容器 DataModel,这里给新手做一个典型的数据模型事件处理的例子作为参考.这个例子看起来很简单,实际上结合了数据模型中非常重要的三个事件处理的部分:属性变化事 ...
- 从2D地图到3D城市模型的概略路线
对包括道路和城市在内的这些密集使用的地理要素制作地图的需求一直在稳步提升.这是因为如今的城市化率需要详细的及时更新的三维地理数据.这些数据帮助城市管理者规避居住性下降,限制水.空气和噪声污染,改善公平 ...
- 基于HTML5 Canvas 点击添加 2D 3D 机柜模型
今天又返回好好地消化了一下我们的数据容器 DataModel,这里给新手做一个典型的数据模型事件处理的例子作为参考.这个例子看起来很简单,实际上结合了数据模型中非常重要的三个事件处理的部分:属性变化事 ...
- AD切换2D,3D,旋转模型
2D与3D的切换: 按住英文键盘上面的数字"3" 正反面旋转切换:快捷键"vb"或者同时按住"ctrl"和"f" 这个是 ...
- CVPR 2023 | 微软提出RODIN:首个3D扩散模型高质量生成效果,换装改形象一句话搞定!...
点击下方卡片,关注"CVer"公众号 AI/CV重磅干货,第一时间送达 点击进入->[扩散模型]微信技术交流群 转载自:微软亚洲研究院 编者按:近日,由微软亚洲研究院提出的 ...
- AutoCAD 2D与3D大师班学习教程 AutoCAD 2D and 3D Masterclass
用实例和解决问题的方法完成从基础到专业的AutoCAD课程. 你会学到什么 AutoCAD课程包含创建计划和模型的命令和不同方法的详细使用. 本课程包括对AutoCAD中使用的所有命令和工具的详细解释 ...
最新文章
- AI和大数据如何落地智能城市?京东城市这6篇论文必读 | KDD 2019
- 解决不了bug先放着,这里有40条提升编程技能小妙招
- 重整谋定电商经信研究新格局-李玉庭:人工智能精细化运营
- JVM之XX参数详解
- Mask R-CNN
- 英伟达赚钱能力创历史新高,老黄:GPU供不应求我也很急
- 【.NET】使用HtmlAgilityPack抓取网页数据
- C语言实战之猜拳游戏
- linux centos用户修改密码,centos怎么修改用户密码
- 网关是什么?工业网关是什么?
- wi7计算机桌面删除,win7系统删除桌面右键多余选项
- 后端都需要学习什么?
- 用 Pinbox 轻松收藏代码,这就是我要的收藏工具
- drawableLeft改变图片的大小
- 云计算技术 实验三 安装Hadoop系统并熟悉hadoop命令
- 【Java 常用的设计模式】
- 你唯一能控制的,是自己的脾气与努力!
- Flash 与课件制作:视频播放
- mysql report-port_mysql性能优化工具mysqlreport
- python写入文本文件的数据类型必须是_用Python读写固定格式(MODFLOW)文本文件...