关于论坛数据库的设计
数据库该如何设计,一直以来都是一个仁者见仁智者见智的问题。
对于某一种数据库设计,并不能简单的用好与不好来区分。或许真的应了那句话,没有最好,只有最适合。讨论某种数据库设计的时候,应该在某种特定的需求环境下讨论。
下面来讨论一下在项目中经常碰到的用户的联系方式储存的问题。
我在这里套用之前网络上流行“普通——文艺——二逼”的分类方式来描述我下文中提及的三种数据库设计思路,并且通过查询数据(对数据增删改,三种设计要付出的代码成本都差不多)和数据库面临需求变动两个方面来思考这三种设计各有怎样的优劣。
普通青年:
或许我们都这样设计过数据库
学生表 tb_Student:
| Name | varchar(100) | 名字 |
| Telphone | varchar(200) | 联系电话 |
| varchar(200) | 你懂的 | |
| Fax | varchar(200) | 传真 |
这应该是最容易想到的一种思路,简单、明了。
比如说我要查询某个人的联系方式,那么我只用一条语句就能实现:
select Name,Telphone,Email,Fax from 表 where 条件
在查询的时候,这种数据库设计十分清晰,没有任何思维的难度,没有任何逻辑的挑战。但是当面临需求变动的时候,那将会是一场灾难。
比如现在要新增一类用户:校长。那么我们要如何处理?
答案是:再加一张表 tb_Headmaster。
事实上,再加一张表其实修改并不大,因为我们完全不需要修改学生表的存储逻辑,换句话说,这种设计是遵循了开闭原则的
但如果学生要添加一种联系方式HomePhone的时候,灾难发生了
怎么办?
在tb_Student中加一列HomePhone?这意味着至少要修改整个Model层(或者说DAL层),这种改动是十分巨大的,而且容易造成错误。
或者再建一张表tb_Student2,来储存HomePhone,然后以ID来关联两张表?按改动规模来说,这种改动相对简单而且不容易出错,但是在今后的维护中会增加逻辑成本。当你一而再再而三的以这样的方式来应对需求变动的时候,你的程序将变得不可理解。
文艺青年:
| UserRole | int | 对应用户类型(None = 0, Student = 1, Teacher = 2, Headmaster = 4) |
| OwnerID | int | 对应用户ID |
| ContactMethod | int | 联系方式(None = 0, Email = 1, HomePhone = 8, WorkPhone = 16,MobilePhone = 32,Fax=64) |
| ContactInfo | varchar(255) | 联系信息 |
这种是一个一对多关系。当我们要查询某个用户对应的联系方式的时候,那是一场逻辑上的浩劫:
select ContactInfo from 表 where UserRole=某种用户类型 and OwnerID=某用户ID
这种写法是一次性取出某个用户所有的联系方式,包括Email,HomePhone,WorkPhone等,之后我们可以在程序中判断ContactMethod的类型,将具体的联系方式加以区分。你可以简单的想到用switch-case的写法,类似这样:
var contact = 上面的SQL语句取出来的用户所有的联系方式;foreach (var item in contact){switch (item.ContactMethod){case ContactMethod.WorkPhone:txtWorkPhone.Text = item.ContactInfo;break;case ContactMethod.Email:txtEmail.Text = item.ContactInfo;break;case ContactMethod.Fax:txtFax.Text = item.ContactInfo;break;case ContactMethod.OtherPhone:txtOtherPhone.Text = item.ContactInfo;break;case ContactMethod.MobilePhone:txtMobilePhone.Text = item.ContactInfo;break;}}
|
当然你也可以尝试下面这种写法,我个人认为这种写法更优雅
var contact = 上面的SQL语句取出来的用户所有的联系方式; txtWorkPhone.Text = (from a in contactwhere a.ContactMethod == ContactMethod.Work_Phoneselect a.ContactInfo).ToString();//后面以此类推,你懂的 |
注意,请不要试图使用类似下面这类语句来查询某用户的联系方式:
select ContactInfo from 表 where UserRole=某种用户类型 and OwnerID=某用户ID and ContactMethod=1 //取出某用户的Email select ContactInfo from 表 where UserRole=某种用户类型 and OwnerID=某用户ID and ContactMethod=8 //取出某用户的HomePhone |
相信我,这种做法非常愚蠢:每当你要取出这个用户的一种联系方式,就要和数据库建立一次连接,打开/关闭一次数据库;这种做法代价是十分巨大的,即使有数据库连接池,即使有数据库缓存,都应该避免这种愚蠢的做法
唔,用了那么多的代码,终于查出了某个用户的联系信息了。反正我个人觉得这种设计方式在查询的时候,是逻辑上的浩劫。什么?你说你很享受?好吧,看来是我脑容量不够…
不过当我们面临需求变动的时候,那就非常愉快了
什么,要加一类用户?简单,UserRole加一个枚举就好了。
什么,要加一种联系方式?ContactMethod加一个枚举就OK。
使用了这种表设计的时候,相信你会微笑着面对需求变动的
二逼青年
昨天和同事也探讨了下这个问题,按他的说法就是:哪个表要联系方式,我就扔个字段进去,存json
| Contact | varchar(8000) | 用于储存json |
举例来说,有这么一个用户:
| ID:1 | Name:张三 | Telphone:1234 | Email:123@123.com | Fax:5678 |
那么数据库中就这样存:
[{"ID":1,"Name":"张三","Telphone":"1234","Email":"123@123.com","Fax":"5678"}]
当我听到这种设计思路的时候,虎躯微微一震:靠,这都行。按这种设计,我整张表都放进一个json里面一股脑的存进去就算了。不过震惊之后仔细想一想,其实这种设计也是有可取之处
首先,从查询来说,和普通青年一样,只需一句SQL:
select Contact from 表 where 条件
查询之后,就可以通过json处理函数将想要的数据取出来,在此就不赘述了
那么当面临需求变动的时候会发生什么:
加一类用户的时候,要添加一张表。也是符合开闭原则,原有代码没有改动
加一种联系方式,只用存json的时候多存一点东西
不过这种设计如果要更新某条数据的话要稍微麻烦一点:先查询一条数据,重组json之后再Update
最近公司要开发新系统,基本决定使用ORM(高层还在犹豫,担心效率问题)。既然使用了ORM,那么自然而然的就想到了用面向对象的思想来设计数据库
本篇文章旨在讨论如何抽象(以用户作为抽象的例子),并提出一些解耦的思路
我也是第一次在实际项目中使用面向对象的思想来设计数据库,写下这篇博客,也是希望与大家多多交流
正文开始
首先来需求分析
我们的系统有前台和后台,前台用户有:Man,Woman,SuperMan,SpiderMan与IronMan。后台用户为Administrator
前台用户都要填写联系方式与地址,然后SuperMan,SpiderMan与IronMan都有Ability
需求很简单。那么按照这个需求,我们来随手画一个继承关系图。其中V代表抽象类(应该是abstract,画图的时候脑抽想着是virtual就用V开头了,懒得改图了大家凑合着看吧),I代表Interface。如下图:
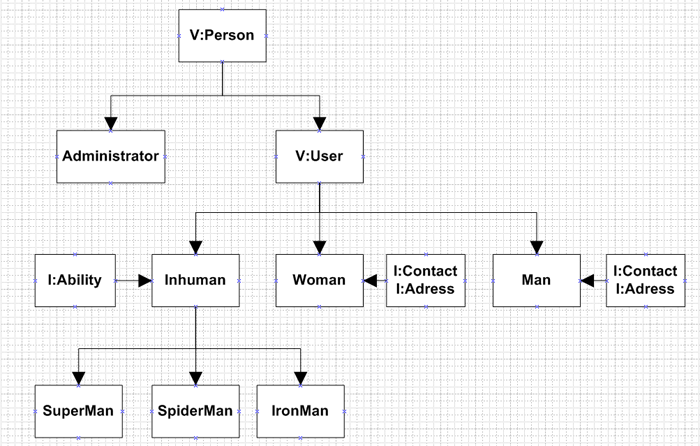
从图中可以看出,由抽象类Person派生出Administration与抽象类User。类Man与类Womam实现了接口Address与接口Contact,Inhumans则实现了Ability接口
然后抽象类代码:
View Code public abstract class Person{public string Username { get; set; }public string Password { get; set; }}public abstract class User : Person{public string Name { get; set; }}
|
接口代码:
View Code public interface IAddress{string Address { get; set; }}public interface IContact{string Email{get;set;}string WorkPhone { get; set; }string MobilePhone { get; set; }string Fax { get; set; }}
|
最后是Man类和Woman类:
View Code public class Man : User, IContact, IAddress{public string Address { get; set; }public string Email { get; set; }public string WorkPhone { get; set; }public string MobilePhone { get; set; }public string Fax { get; set; }public bool HasCar { get; set; } //如果这三项都为false的话public bool HasHouse { get; set; } //这辈子就甭想结婚了public bool HasMoney { get; set; } //T T我泪涌}
|
View Code class Woman : User, IAddress, IContact{public string Address { get; set; }public string Email { get; set; }public string WorkPhone { get; set; }public string MobilePhone { get; set; }public string Fax { get; set; }public bool IsBeauty { get; set; } //这个为true,一辈子不愁吃喝}
|
代码非常简单。其他几个类限于篇幅就不说那么细了
那么按照这个model,使用EF Model First来建立数据库,得到的Woman表如下:
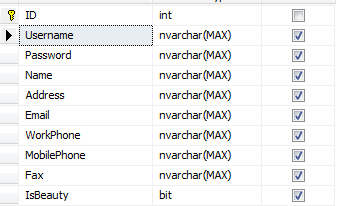
那么接下来就是重点了:为什么不把Contact和Address分表储存。这样与Man表、Woman表写在一起的话,出现改动(如新增一种联系方式),会不会非常痛苦
如果不是使用ORM,那么这个改动的确是很痛苦;但是如果使用了(这里默认使用的ORM可以从Model生成/改动数据库),那么这个改动是没什么大不了的了,只需要修改一下接口定义,然后根据报错去改就好了。至于数据库的变动,就交给ORM去做就OK了
这样有一个好处,可以在有限的范围内实现解耦,部分减少了关系——若将Contact和Address分表的话,取Woman要Join两次,这看起来没什么大不了的,但是如果放大了看,如果是join十次呢?这样弄出来的东西很难去维护(现在公司老系统就是这样,动不动就join十次二十次的,改动起来十分费力)
具体怎么去解耦,这个问题相当相当的深奥,就不敢在这班门弄斧了
在上面,园友Jacklondon Chen提出了一些问题,大致如下:
“man/woman应该设计在同一张表中。 用户表大多都设计成一个表。连分 administrator 和 user 都不应该。”
我想还是因为我举例太随意,因为博文中Man和Woman只有4个差异属性:HasCar\HasHouse\HasMoney,以及IsBeauty
其实对于这个问题我无力吐槽什么,简单的说说吧:假设为Man用户实现的是一个征婚系统,而Woman用户实现的是一个选美系统。这么说应该能理解Man和Woman的不能并同一张表的原因了吧
废话说完,正文开始
/*=============================================================*/
现在有一个系统,我们暂时假设为学校选课系统。有两类用户Teacher和Student,还有一张Curriculum表是课程总表,来储存学校一共有哪些课程,每门课的学分什么的。然后一个老师,一门课程和多名学生,就可以开始上课了
表结构如下图:
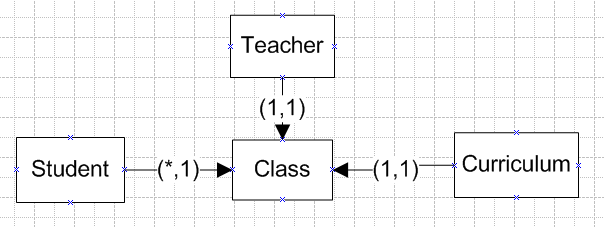
逻辑很简单,一目了然
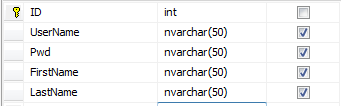
但是问题在于,我们的系统要按学校来卖。每个学校的选课逻辑都是一样的,而表中的数据有共性,但是也有差异性。比如说基本的Teacher表结构是这样的:

现在把系统卖给A学校。A学校除了的Teacher表除了用户名和密码之外,还要储存老师的FirstName和LastName,那么表结构变化如下:
现在B学校也买了我们的系统。他们的Teacher表不要FirstName和LastName,但是要储存教师的工号“Number”,表结构如下:

好,现在我们的问题出来了:怎么去解决这种差异性
最简单的思路莫过于表中加冗余字段。比如说将表设计成这样:
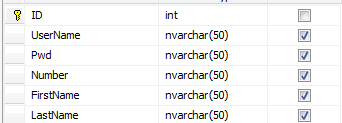
如果我们的系统只卖两三个学校,这样是可行的。但是打个比方,我们的系统卖了30所学校,每个学校有一个自己的差异字段,那么这个表就要有30个冗余字段来应对这种差异性。且不说每次加冗余都要改动系统,且不说冗余多了浪费空间降低传输效率,光说怎么维护这些冗余,我就已经觉得是灾难了:Teacher表有差异字段,其他表也会有。假设一个中型系统,60张表,其中30张实体表30张关系表不算过分吧。那么总共要维护 30(表数量)*30(冗余数量) = 900 个差异字段
第二个想法是建立一张冗余表来储存差异。这种其实和表中加冗余异曲同工,就不多加分析了,留给大家自己思考
第三个想法是建立不同的数据库。其实本来每个学校的数据库就是不同的,唔……怎么说呢,A学校自己的数据库中的表,存的是A学校自己的特有字段,B学校存B学校的特有字段。两者之间并无关系,然后Model用l继承的思路来设计(详见上一篇文章),通过配置文件来选择恰当的数据库和其对应的Model
是的,这种方法挺好的,唯一的不足可能就是比较依赖于ORM——使用ORM来生成数据库,以及T-SQL语句
如果您是一个关系型数据库的重度爱好者,那么这篇文章到这就结束了,下面的东西不会对您胃口的
/*=============================================================*/
众所周知,因为大量使用了反射,ORM的效率不是那么的高,而且本身关系型数据库的可拓展性也不是那么的好
作为一个激进的开发者,我一直希望在项目中尝试NoSql
一、一个简单的论坛系统
1:包含下列信息:
2:每天论坛访问量300万左右,更新帖子10万左右。
请给出数据库表结构设计,并结合范式简要说明设计思路。
一. 发帖主题和回复信息存放在一张表,并在这个表中增加user_name字段
对数据库的操作而言,检索数据的性能基本不会对数据造成很大的影响(精确查找的情况下),而对表与表之间的连接却会产生巨大的影响, 特别在有巨量数据的表之间;因此对问题的定位基本可以确定:在显示和检索数据时,尽量减少数据库的连接以及表与表之间的连接;
引用
1: user:用户基本信息表
字段有:user_id,user_name,email,homepage,tel,add...
2: forum_item:主题和回复混合表
字段有:id,parent_id,user_id,user_name,title,content,....
parent_id=0或者null表示是主题,否则=n表示是id=n那条帖子的回复
UserName字段是冗余的,因此在用户修改UserName的时候就会产生同步数据的问题,这个需要程序来进行弥补
二. 主题表和主题回复分开保存
引用
1: user:用户基本信息表
字段有:user_id,user_name,email,homepage,tel,add...
2: forum_topic:主题表
字段有:id,user_id,title,content,....
3: forum_topic_back:主题回复表
字段有:id,topic_id,user_id,title,content,....
三. 主题表的内容单独设计成一个表
引用
1: user:用户基本信息表
字段有:user_id,user_name,email,homepage,tel,add...
2: forum_topic:主题表
字段有:id,user_id,title,....
3: forum_topic_content:主题内容表
字段有:id,topic_id,content
4: forum_topic_back:主题回复表
字段有:id,topic_id,user_id,title,content,....
四.用户信息分2个表保存,并对相关表进行分表处理
引用
1: 简单用户表 tb_user:
id , username
2: 用户详细信息表 tb_userinfo
id,userid , email , homepage , phone , address ...
3: 论坛主题表 tb_bbs
id , userid , title , ip , repleycount , replyuserid , createtime , lastreplytime
4: 论坛内容标 tb_bbs_content (此表可按照bbsid进行分表存储)
id,bbsid , content;
5: 论坛回复表 tb_bbs_reply (此表可按照bbsid进行分表存储)
id , bbsid , userid , content , replytime , ip
五.增加一个主题缓存表,取每个区的前面100条记录
引用
1: 简单用户表 tb_user:
字段有:id , username
2: 用户详细信息表 tb_userinfo
字段有:id,userid , email , homepage , phone , address ...
3: 论坛主题表 tb_bbs
字段有:id , userid , title , ip , repleycount , replyuserid , createtime , lastreplytime
4: 论坛内容标 tb_bbs_content (此表可按照bbsid进行分表存储)
字段有:id,bbsid , content;
5: 论坛回复表 tb_bbs_reply (此表可按照bbsid进行分表存储)
字段有:id , bbsid , userid , content , replytime , ip
6: 主题缓存表 tb_bbs_cache
字段有:id , userid , title , ip , repleycount , replyuserid , createtime , lastreplytime
------------------------------------------------------------------------------
下面是针对上面的方案展开的讨论:
1:方案一表面上看起来好像少查了一张表,但由于冗余,因为帖子数量极大,会占用大量的空间。这种数据量大,但是对实时和数据绝对安全性要求较低的应用,大量使用缓存的话可以极大提高处理能力。
2:方案一你这么设计的话,索引怎么建比较好呢,还有就是会不会造成这个表过热,还有…… 我觉得像论坛这样的系统,使用缓存可以大大降低数据库的负载
3:大家的意思是分成主题表、回复表等多个表? 还是合成一个表然后做物理分区? 哪种更好呢?
4:再这么高插入更新的频率下 索引就有些不实用了,创建索引会降低插入更新的速度而且访问量这么大的情况下,索引不建议采用
5:就这样的一个论坛,实时在更新、发帖、回帖。我觉得在数据库上建立索引不太好,但是如果不建立索引如何来提高查询等方面性能呢?
6:都是分布式数据库了。放在多个表中,直接关联一点都没问题。重要是横向切分
7:认同分表,分库,缓存的做法
引用
问题分析:
每天论坛访问量300万左右,更新帖子10万左右。
1. 读写比例在30:1左右, 应向读取效率方面倾斜. 索引建立需参考常用读取的主关键字.
2. 每月数据在10W*30=300W. 可按月分表
3. 每年帖子在300W*12=3600W, 推算数据不会小于30T. 可按年分库
结构:
用户信息:独立表,userid主键
发帖、回帖:按月表存储,帖子唯一ID主键,日期索引。
帖子内容明细:按月存储,帖子唯一ID主键
8:拿一张500万的表来说事
引用
更新的时候如果没有索引的话
更新时间大概需要30秒左右 指的是全表更新~~
而查询某单行记录 却需要10秒左右~~
而加入索引的话
更新时间差不多慢了一倍有余
而查询记录则缩减到毫秒级~~
快了百倍有余~~
孰重孰轻 自己选
9:自己的一点经验:
引用
1.分表存储;
2.建立索引;SQL按所以查询的速度还是很快的;
3.避免整表扫描;先读取主题,在按照主题ID读取回复;再按照用户ID读取用户;而不要使用关联;
4.使用缓存;
10:需要分3张表,且建立索引。。。
理由如下:
引用
1:建立3张表可以避免冗余数据,维护起来方便。。。
2:每天论坛访问量300万左右,可见主要的压力来自于查询,sql查询的效率在于避免全表扫描,可见建立索引是必须的。。。
3:关于创建索引会降低插入更新的速度这个问题是不存在的。。。 因为,索引之所以会降低更新的速度的速度,是因为在更新完对应字段后还需要更新对应字段的索引。
4:看到更新帖子10万左右,这句话是说,我们可能对发帖标题,发帖内容,回复标题,回复内容这4个字段做更新。。。需要注意的是,这四个字段并不是用来建立表连接的字段,为了优化查询速度我们不会在这四个字段上建立索引,所以从这道题目出发,我们建立的索引不会影响更新帖子的性能。。。
所以,我认为最后的答案是建立3张表,在连接用到的字段上建立索引。。。
11:
引用
兩個表然後建一個視圖是否可行呢?
视图也是很慢的。
12:每天就更新10万个帖子,每天访问那么多,肯定是不能把所有的主贴放在一个表里,大表分小表,建立常用字段的索引,然后配置缓存。级联关系最好不要配置,等需要的时候再查询。
13:虽然题目中没有说明,但实际应用中,查阅帖子通常只会分页显示,而一页最多也就显示几十个帖子,那么实际上只要SQL语句构造得好,T_USER表其实只是跟一个只有几十行结果集的的子查询进行连接,应该基本不用担心出现性能问题。
而且实际上,一个万行级的表简单关联百万行级的表(其实镇魂歌数量级在我看来其实也算不上很大的表),在数据库方面完全有很多优化方式,甚至可以通过提高硬件配置来改善性能,实在没有很大必要进行结构上的冗余。一旦结构有冗余,为了保证数据一致性,往往你还要消耗更多的资源,反而得不偿失。
14:分表有垂直和水平分表
引用
1:无论你拿多少记录(甚至是1条),如果两个大表关联都可能会产生非常大的中间值,如果你排序(排序字段没有用到索引),你都可能导致数据库采用各种各样的方式来计算。
2:索引会导致插入、更新记录很慢,大家都是知道的。
3:水平分表可以解决这个问题,只要你能保证每个表只存适合的记录数(例如100W一个表) (水平分区也可以解决IO的一些问题)
4:还有就读写分离,master是写,slave是读 (再加上cache,一般问题都还好了)
上面都是比较大的工作量,最好是保证你的数据库设计是合理的(范式是第一步,然后考虑反范式),基本上也能满足很多问题了。
15:方案四 把内容与其它信息分开的好处就是可以让每个表的文件最小化,对数据库操作压力会减小,操作速度会快,还可以搭配缓存,把内容根据情况进行缓存,可以尽量很少访问表数据。
引用
1:对于上述分表方式也可以适用于分库操作,这样就降低了数据库单库的压力,把压力分散到各个机器
2:我的做法就是尽量避免表关联
3:再就是对于sql语句尽量都保证索引有效,不能索引的sql,尽量采用能索引的高效方式解决
16:外围的方案:
引用
1 读方面,生成静态页,或者缓存最新最热的帖子。
2 写方面,估计主要是INSERT吧,这个可以异步操作的。所有的写贴操作放到一个队列然后批量执行插入数据库操作。
17:方案四比较靠谱,再加上定期转储,海量的cache,大型论坛就此搞定。
18:我觉得应该还是使用3张表比较合适。
引用
1:业务上说,很可能主贴跟回复贴拥有不同的扩展,比如附件什么的,都放在一张表里面,假如主贴跟回复存在个性需求,怎么办?无限加字段么?
2:主贴跟回复在同一张表里,会增大锁表的几率。
3:索引的确会降低表更新的速度,但是带来的查询效率提升也是很可观的,因此我觉得,索引不能不用,但是要少用。
4:建立表时,确实可以通过楼上某位仁兄回复所言,用水平分表的方式,其实原理就是用先算再查嘛。
5:在前端表现上,可以使用ajax等方式,分步骤取数据,比如主贴的内容先取出来,然后再逐步加载回复信息等。
19:提高速度的关键:
引用
1.建立索引并在查询时充分利用;
2.避免使用关联,这样避免整表扫描;使用关联不如多次使用主键查询来的快;
3.一些处理的功能尽可能放到内存中来做,比如组织主题和回复;
4.使用静态页面也是个不错的做法;
20:方案三是延续了hibernate二级缓存的思想, 对于经常更新的数据都设计成单独表,这样可以最大程度的利用hibernate缓存
21:没有fast=true的设置,有人说or比in 好,exists比in 好,索引比全表扫描好,分区能提高查询效率,但是分区要降低插入效率
我要说的是,没有fast=true的选项, 如果能找到一步,或者几步公式化的方法能提高效率,那么优化器自己就会做了,根本不用用户担心。
假设 or比in好,数据库优化器把in语法和or语法走的执行计划一样就可以了,何必折磨用户呢。
说点实际的,很多人张嘴就说,SQL优化就是避免全表扫描,不知道大家有没有了解过索引查找的原理.索引查找数据,有两步要做,第一步是索引中快速查询,索引里只存储了对应表数据的rowid, 所以还有第二步,根据rowid去得到全部的数据, 所以需要一次磁盘i/o, 不要小看磁盘I/O,通过索引查询出的结果比较多的时候,磁盘i/o的时间是非常大的,这个时候比全表扫描慢得多, 实际上,oracle 10g基于成本的优化器(CBO),选择性不高的索引,优化器根本不会使用,而自动采用全表扫描的方式来做.
22:这个量级的bbs我设计过,当时是这样做的(方案五):
引用
共四个表:
1. 用户表
2. 主题表(包含最后回复信息,最后回复人,最后回复id等)
3. 回复表
4. 主题缓存表(这个取每个区的前面100条记录),一般来说负载最大的就是主题的第一页,所以缓存表是个小表。
共3台app集群,1台web,2台oracle一主一备,运行下来速度还是可接受的。
23:不建议进行表的设计冗余,感觉就想重复代码一样,有坏味道
引用
1:缓存常用的页面和数据
2:读写表或库分开(基于垂直分隔)
3:数据库可以进行垂直分隔(字段分到多个表中),再进行水平分隔(数据分到多个表中)
4:论坛功能可以进行分隔,不同的服务器负责不同的功能,如图片服务器,web服务器,邮件服务器等
总之,就是要细化分工
24:支持方案三的设计
读取的操作:
引用
1:显示帖子列表界面,如果主贴内容放在forum_topic表,那么这就是冗余的,假设都要获取100个帖子,一行的数据长度越大,数据库需要扫描的数据块就越多,性能也越差。
2:在打开一个帖子时,读操作通过索引关联到两张表(forum_topic和forum_topic_content)性能消耗对整个数据库来说不多。
写帖子的操作:
引用
发表帖子,对标题表和内容表分别作一个插入
更新非索引列不会引起索引更新:
引用
只要被索引的列(例如回复表的标题ID)不被频繁更新,即使索引所在地行的其它列被频繁update,索引也不会被更新从而产生性能消耗,一张表一天30万次的索引更新,因它引起的性能消耗小到即使数据库安装在奔腾3单核CPU下都能轻松承担下来, 为什么会有人对索引有这么大的误解呢?。对一个论坛(或者绝大部分的系统)来说,检索(SELECT)数据耗费的系统资源远远高于更新数据(INSERT/UPDATE)本身,而索引是专门为检索数据服务的,难道就为了节省更新数据的小小的性能消耗,付出检索100条数据时需要数据库扫描几千万上亿条数据进行数据匹配的代价?如果是这样的话,即使是有32核顶级CPU的数据库作并行查询都未必顶得住。
做数据库设计,还是多了解数据库的原理才好。
25:数据库切分是必须的。
引用
1:垂直切分:用户表、用户信息表、主题表、主题内容表、回复表
2:水平切分:主题1、主题2、主题3、...、主题n
3:缓存:缓存路由表
4:再配合数据库读写分离和集群吧
另:其实论坛修改标题、内容的概率是很小的。大部分都是新增
二、以铁路的售票系统来说明分库分表对架构的影响。
一、问题:铁路的售票系统的数据量是海量吗?
不是。因为数据量不大,真不大。
每一个车次与车次间是独立的,每车次不超过2000张票,一天发车不超过50万车次;
以预售期15天来讲,15*0.1亿张不超过1.5亿笔的热线数据,称不上海量数据的。
再加上可以按线路分库,更是不到千万级的单表容量。已经发车完成的进入归档分析。
即数据库按路线使用不同的服务器,不同的车次放在不同的表中。并发量锁真不大。
当然,如果不分库分表,再加上不归档处理,铁路的售票系统的数据量看起来是海量的;
关键是这海量的数据没有意义。
二、如何分库分表?
2.1 分库,考虑数据间没有直接关系和服务器如何部署
铁路的售票系统为例来说,按路线分库,再按车次分表是合理的。
设路线有1万条,按每1000条需要两台服务器(一台热机沉余),不到20台服务器
如果使用SAN存储,则使用SAN作为存储,本机作为热机沉余,只需要10台。
当然使用mySQL这种经济型数据库,服务器需要更多来防灾;
即可以采用双写或多写的方式来保证数据的绝对安全。
2.2分表,考虑数据间不存在重叠,即数据满足二分原则
铁路的售票系统的任意两个车次是没有关系的,所以可以分表。
电信的某个用户的通话和其它用户的通话记录,也是没有关系,所以可以分表处理
(实际上电信的系统,分库分表后也是不大的,难在后台的计费、结算等规则)
三、数据库访问接口
1. 元数据:如何识别到当前要处理的数量在哪张表?
铁路的售票系统会有一个车次管理系统,例2012年2月12日 D3206 车次,
按预先设计的在哪台服务器的哪个库,建哪个表。
2.建立元数据的规则:即具体如何分库分表的规则
这个就是数据库的访问接口。
3.数据库访问接口的透明程度
即哪个层知道哪些元数据信息。
例,是否让窗口售票的客户端来解析元数据的规则然后缓存,还是通过中间件来解析缓存的
具体各层使用怎样透明程度,和业务性质、节点和数据中心的拓扑等有关。
四、历史数据归档与分析
1.使用分库分表后,数据需要归档,分析处理的程序变得复杂,但使联机交易变得简单
2.分析:要注意是针对热线数据分析、归档数据分析、混合分析有关,
通过分库分表和归档,更方便使用分布式的统计方案。
具体可以参考,淘宝的开放平台架构师写的文章:
Beatles小记-分布式数据流分析框架(一) http://www.blogjava.net/cenwenchu/archive/2011/12/07/365776.html
结论:分库分表跟不分库分表,整个架构是完全不一样的。
像铁票的售票系统、淘宝、电信、银行等,绝对要采用分库分表的数据存储方案,
来解决数据量的增长而不影响性能的问题。
像淘宝等互联网应用还要解决带宽即CDN问题。
三、如何构建千万用户级别后台数据库架构设计的思路
关于如何构建千万级别用户的后台数据库架构话题,在ITPUB及CSDN论坛都有不少网友提问,新型问答网站知乎上也有人提问,并且顺带梳理了下思路,方便更多的技术朋友有章可循,整理一篇抛砖引玉性的文章。
一、技术朋友给出的背景资料:
(1). 网站型应用,主要指:SNS社交网站、新闻门户型网站、邮件系统、SNS Game社交游戏、电子商务网站、即时通信IM等类型系统;
(2). 注册用户为千万级别,也即1KW注册用户以内;
二、要求
构建千万级别用户的后台数据库架构分析思路,对数据层架构设计的有章可循,必须考虑数据量的大小,以及数据库提供服务的性能和系统的可靠性,适当地考虑用户量超过,以及需要使用的服务器资源等信息。
三、构建千万级别用户的后台数据库架构的分析思路
曾经发过一篇文章,关于千万级别用户应用架构设计的歌谣,供大家参考 千万级架构设计诀窍,接下来我们针对如何构建千万级别用户的后台数据库架构,给出通用性分析思路的建议,未必完全靠谱,但求基本靠谱(注:毕竟很多事情需要看具体业务而定的):
(1). 一定要区分业务类型,可能达到千万用户级别的应用业务场景,可归类描述为: SNS社交平台、SNS社交游戏、即时通信IM系统、电子商务、邮件系统、新闻门户网站等,这些不同类型的业务场景做法会不一样,主要是由他们业务性质决定,后续分析项中逐一描述;
(2). 应用业务的核心KPI数值,产品每天的日活跃用户量大概多少?若是网站类型应用,还需要加入其他参数PV,UV等数据辅助决策,即时通信IM的消息量,邮件系统的新增邮件数,SNS社交平台的Feeds量等核心数据;
(3). 系统中每个用户可能产生的数据量大概多大,分固定部分,以及动态部分的方式统计分析,对非固定部分以参考值和结合实践跨度(注释:1年为硬性指标,2年为预期,3年可选,再长的时间段不考虑)的方式进行分析,然后预测出整个系统的用户锁产生的数据条数和数据容量大概的估值;
(4). 注册用户并不等于活跃用户,为此需要预估日活跃用户量大概多少?周活跃用户量大概?月活跃用户量大概多少?系统设计的最高并发量为多少?这数字还是非常有必要,不管是对数据量预估,还是对技术实现方案的选择都有帮助;
(5). 根据应用业务的特点,以及系统不同模块的功能特点,初期必须判断出可能负载最大的系统模块,对于可以静态化模块或功能,尽量要Cache起来,以降低系统的负载和提高前端响应速度;若是非Cache技术能解决的,是否可以考虑独立或通过整体水平扩展方式解决系统的负载和性能问题;
(6). 针对系统中各个模块的功能或业务特点,大致那些用户数据会累计比较大,以及那些数据操作频率比较高;
(7). 不同的业务其对数据操纵不一样,要大致明白自己的应用:读写比如关系,也即:SELECT:UPDATE:DELETE:UPDATE=?;
(8). 系统的整体架构中,必须考虑系统的稳定性、负载均衡和响应速度,为此必须考虑一些模块借助Cache、异步、消息队列等技术,进行一些特殊处理或折中做法,以达到目标;
(9). 若使用MySQL数据库产品作为后台数据库提供数据服务,建议尽量使简洁的SQL语句,并不是说不用JOIN,而是要考虑MySQL对JOIN的实现算法,符合Nested loop join优缺点中的优点;
(10). 数据库结构设计
既然说是构建千万级别用户的后台数据库架构,前面讲清楚如何熟悉和理解业务模型,清楚系统可能存在的瓶颈、技术难度,以及一些技术实现方案,现在必须回归到数据库设计阶段。
开始讨论如何收集、分析和设计数据库结构之前,我们先简单地对数据库,什么情况下要考虑进行水平拆分?尤其针对互联网行业流行的数据库产品MySQL来讨论,各大数据库技术论坛或个人博客型技术网站,有不少名言式的基调:数据量超过100W,就需要分表,MySQL无法支持大数据量的服务等等?
以前的MySQL(主要指:MySQL5.0以前版本)版本确实存在诸多问题,以及当时跑MySQL的服务器一般都是超低配置,还依然记得当时我们的数据库服务器最高也就8G内存,一般都是2G内存,硬盘都是单盘且转速是10K,甚至7500转的,而当时大多主流数据库产品Oracle跑的服务器配置却很少这么差。我们大家要一时俱进,技术人员尤其DBA或架构师,要学会以数据说话,以其中一测试用例,DELL 2950 4*15K*146G RAID1+0 ,16G内存,E5410 CPU*2 ,一张分31个分区的区表业务模型只有INSERT+SELECT,且以50个INSERT+10个SELECT线程并发执行,总记录写入数据量6KW行左右,单表数据容量超过100G,并发从最高的9100 TPS/S下降到8700 TPS/S之后就稳定在此值。
上面论述MySQL支持大表并没有太大的性能方面的下降,但是并不表示笔者建议大家这么做,至少有二点MySQL的备份和数据库结构变更非常麻烦,尤其数据库结构变更其特殊的做法,使其成为一大瓶颈,也不知道要牺牲我们多少DBA的睡眠,但是对于新闻内容的存储需求,可以把新闻主题内容单独放到一张表中,以子表的方式存在,提供数据服务器,且该数据很少做变更,一般情况下是INSERT之后就只有读为主,那么就不会是任何问题,阿里巴巴旺旺弹出的新闻页面的内容就是采用此方式存储,当时单表容量接近1T,早高峰的时候也不会出现服务器性能问题,以及系统负载都非常稳定。
我们继续回到构建千万级别用户的后台数据库架构的话题上,具体建议或做法如下所示:
10.1> 数据库的设计开始之前,必须优先进行业务的数据流梳理(注释:必须尽量考虑应用所有可能的功能模块),以及对业务优先进行优化和规划,然后根据数据流和功能 考虑数据库的结构设计和优化;
10.2> 千万级别用户量,若是非游戏行业的产品(SNS游戏除外),建议考虑用户数据拆分架构设计,以及考虑后续未来1-2年的承受量,若是SNS平台必须考虑拆分,除非考虑上SSD、Fusion-io、存储等更高端的设备,用金钱换时间的方式支持技术改造;
10.3> 数据拆分的核心与难处:同一个用户的数据尽量放一起(拆分规则要尽量简单可执行),拆分之后用户关系的数据如何保存的抉择有多种(存2份或存1份放一个地方),难处数据的分页,统计合并等;
10.4> 要考虑一些冗余的方式解决SQL性能问题,但是又不能过多引入冗余而造成IO开销增加太多,冗余字段要尽量整型字段;
10.5> 数据库表对象的字段属性,要尽量考虑数字化,尤其游戏行业;
10.6> 数据库设计过程中,对于索引组织结构要偏向共同操作最优先,其次应用外部用户级别的操作性能优先,最后内部用户的操作,硬尽量隔离,例如:搜索引擎Build操作、内部编辑团队审核等操作;
10.7> 数据库要从设计角度规避一些无法通过其他技术手段解决的模糊查询,类似全文索引的模糊查询,要走搜索引擎的模式,再通过数据库读具体的数据,一些必要的计数类型的数据,适当地考虑缓存;
10.8> 重点解决数据库级别的数据分页问题,要学会从前端应用用户的体验不降低的情况下,达到更高效的数据分页做法,类如论坛中帖子分楼的做法;
10.9> 数据库的设计必须考虑使用什么类型配置的物理服务器,核心参数:内存、CPU、硬盘(这个是关键:硬盘类型(注: SATA、SAS、SSD)、多少块盘、转速、容量,以及做RAID几),RAID卡内存及RAID写模式也需要考虑进去,必须结合数据量和读写能力要求进行一个预算规划,不一定超准确,但是要八九不离十;
【结束】
主要是想通过回答网友的提问“如何构建千万用户级别后台数据库”,把对于此类用户级别通用性分析和设计的思路描述清楚,实在不善于文字描述,可能很多地方没有讲述到位,还请各位一起补充完毕和纠正。
关于论坛数据库的设计相关推荐
- 论坛系统mysql数据库设计_BBS论坛系统的设计与实现(MySQL)
BBS论坛系统的设计与实现(MySQL)(任务书,开题报告,中期检查表,文献综述,外文翻译,毕业论文12000字,程序代码,MySQL数据库) 论文主要介绍了BBS论坛系统的设计和实现.设计包括数据库 ...
- 基于php留言本毕业设计,基于PHP校园学生论坛留言本设计与实现(MySQL)(含录像)
基于PHP校园学生论坛留言本设计与实现(MySQL)(含录像)(毕业论文12000字,程序代码,MySQL数据库) 摘 要 本课题所实现的网络留言本是基于PHP语言开发实现,使用的数据库是MySql数 ...
- 学生论坛管理系统的设计与实现
学生论坛管理系统的设计与实现 一.问题定义 二.可行性分析 三.开发计划书 四.系统设计 五.系统完成后截图 六.源码地址: 一.问题定义 1.项目背景 随着网络的不断发展,网上论坛信息越来越多,发帖 ...
- Java、JSP+BBS论坛系统的设计与实现
技术:Java.JSP等 摘要: BBS即Bulletin Board System("电子公告版"),一般可以分为:教学型论坛.推广型论坛.地方型论坛.交流型论坛.技术型论坛等. ...
- asp.net976-校园论坛系统的设计与实现#毕业设计
项目编号: asp.net976-校园论坛系统的设计与实现#毕业设计 运行环境:VS+SQL 开发工具:VS2010及以上版本 数据库:SQL2008及以上版本 使用技术:HTML+JS+HTML 开 ...
- SQL Server 进阶 01 数据库的设计
SQL Server 进阶 01 数据库的设计 本篇目录 课程内容回顾及介绍 为什么需要规范的数据库设计 设计数据库的步骤 绘制E-R(实体-关系)图 实体-关系模型 如何将E-R图转换为表 数据规范 ...
- 大工21春《SQL数据库课程设计》模板及要求
远程与继续教育学院 <SQL数据库课程设计>大作业 ...
- 分析论坛数据库设计分析
1,数据库设计 论坛数据库设计还是挺有意思的,按照业务逻辑进行拆分的数据库设计. 首先,如果是一个博客就一个post表记可以了.然后考虑到论坛数据量比较大,所以在设计上有优化. 论坛把数据库分成3个数 ...
- 如何构建千万用户级别 后台数据库架构设计的思路
关于如何构建千万级别用户的后台数据库架构话题,在ITPUB及CSDN论坛都有不少网友提问,新型问答网站知乎上也有人提问,并且顺带梳理了下思路,方便更多的技术朋友有章可循,整理一篇抛砖引玉性的文章. 一 ...
- 基于WEB的考研论坛网站的设计与实现
基于WEB的考研论坛网站的设计与实现 研究的背景与意义 选题依据:这次我们所设计的课题是考研论坛与学习生活之间的紧密关系的体现,现今的社会,越来越多的人开始使用论坛,考研论坛已经成为人与人之间交流的一 ...
最新文章
- flash build 4.6 不能debug 报错 C:\WINDOWS\system32\...
- flask 学习笔记 mvc ,sqlalchemy(insert,update)
- 国外学python的软件_全球开发者调查报告:IT人最想学习 Go 和 Python、美国开发者收入最高...
- python 计算机基础
- java题-如何递归遍历一个文件夹下的所有文件
- C语言对结构体何时用- , 何时用.
- android intent sender,Android7.0以上调PendingIntent.getIntent()报错
- SQL Server学习之路(六):“增删改查”之“查”
- USACO Section 1.2 Name That Number
- 彭国伦Fortran95学习笔记(一)第八章至第十六章
- vnc远程控制软件下载,四款神级能够下载的vnc远程控制软件
- 怎样用计算机编码出文字,计算机汉字编码主要有哪些方式
- 基于android的影音设计,基于Android的车载影音导航系统软件设计与实现
- 99乘法表,读写文件,函数
- 瓜大NPUCTF-Misc、Crypto Write Up
- vue 白边 项目_GitHub - Hobby0/Vue-mmPlayer: 基于 Vue 的在线音乐播放器(PC) Online music player...
- 【成长经历】----陪女朋友拔智齿
- 【维修】如何成功做网线?
- Java集合、IO、多线程的一些知识
- 十个富有特色的猎奇网站
热门文章
- 福利 | 启迪之星2018首期AI创业加速营免费名额
- 高通与NVIDIA在物联网芯片交锋,争相引入AI
- java实现批量注册_Java写的批量域名注册查询程序
- Could not fetch URL https://pypi.org/simple/selenium/: There was a problem confirming the ssl cer...
- 输入数据求熵值法matlab代码,熵值法matlab程序
- golang 实现微信授权
- 【51 Nod1378】夹克老爷的愤怒
- html5 06携程网案例、 全屏插件的使用
- BZOJ1189 [HNOI2007]紧急疏散evacuate
- CSAPP ArchLab