ai人工智能将替代人类_AI和人类如何优化空气污染监测
ai人工智能将替代人类
空气污染监测 (Air-pollution monitoring)
Air pollution is responsible for 4.2 million deaths per year according to the World Health Organization (WHO). No wonder we should dedicate resources to understand and monitor air quality in our cities and neighbourhoods. This should help authorities in urban planning as they can decide where to plant trees, build green spaces and manage traffic. Also, it can make us all aware of the impact of air pollution in our everyday life, which is critical to our health.
根据世界卫生组织(WHO)的数据,空气污染每年导致420万人死亡。 难怪我们应该投入资源来理解和监测我们城市和社区的空气质量。 这应该有助于当局进行城市规划,因为他们可以决定在哪里种树,建造绿地和管理交通。 此外,它还可以使我们所有人意识到空气污染对我们的健康至关重要的日常生活的影响。
In this article, we approach air pollution from a different angle. We want to introduce and discuss the concept of crowdsourcing air quality monitoring. For those unfamiliar with the concept of crowdsourcing, it is about engaging the public to achieve a common goal. We can achieve this by dividing the work among participants in small tasks; in this case, collect air quality measurements. Our aim is to use crowdsourcing in a smart way to build up an accurate air pollution heatmap with the use of Artificial Intelligence (AI).
在本文中,我们从另一个角度处理空气污染。 我们想介绍和讨论众包空气质量监测的概念。 对于那些不熟悉众包概念的人们,这是为了让公众参与以实现一个共同的目标。 我们可以通过在小任务的参与者之间分配工作来实现这一目标; 在这种情况下,请收集空气质量测量值。 我们的目标是通过人工智能(AI)以智能方式使用众包,以建立准确的空气污染热图。
We argue that crowdsourcing can potentially be a better approach than the static air quality sensors placed in cities at the moment. First of all, not every city or town has one, and when they do, they are typically placed in a way to capture the average air quality of that area. This means they do not necessarily reflect the pollutants we will breathe in when we are walking in the city centre, for example. Also, we need to consider the cost of acquiring, maintaining and using those static air quality sensors.
我们认为,与目前放置在城市中的静态空气质量传感器相比,众包可能是一种更好的方法。 首先,并非每个城市或城镇都有一个,而通常每个城市或城镇都有一个这样的位置,以捕获该地区的平均空气质量。 例如,这意味着它们不一定反映我们在市中心行走时吸入的污染物。 另外,我们需要考虑购买,维护和使用这些静态空气质量传感器的成本。
On the contrary, the crowdsourcing proposal relies on our willingness to participate. This, however, would also require the use of low-cost mobile air quality devices to take readings in our whereabouts.
相反,众包提案取决于我们的参与意愿。 但是,这还需要使用低成本的移动空气质量设备来获取我们的下落读数。
Importantly, we do not want to actively be taking measurements everywhere at all times. This relates to practical reasons as well as data privacy ones. For starters, the sensor would have to operate continuously. It would also have to track our location and taking timestamped air quality measurements. That is even if we are indoors or it is in our bag or pocket. As a consequence, the battery life would be easily depleted. To top it all, that this tiny sensor would know more about your movements than your significant other. Not very good.
重要的是,我们不想一直在任何地方积极进行测量。 这与实际原因以及数据隐私性原因有关。 对于启动器,传感器将必须连续运行。 它还必须跟踪我们的位置并进行带有时间戳的空气质量测量。 即使我们在室内,也可以放在包里或口袋里。 结果,电池寿命将很容易耗尽。 最重要的是,这个微小的传感器比其他重要传感器更能了解您的运动。 不是很好。
Thus, the challenge is to
因此,挑战在于
identify when and where air-quality measurements should be taken to efficiently monitor our city.
确定应何时何地进行空气质量测量以有效监控我们的城市。
Hopefully, the optimisation problem here is starting to become clearer by now. Given constraints about how often we are willing to actually contribute and how much battery the device has available, we want to identify the best places to take measurements such that those measurements are most useful to facilitate an efficient environment exploration and consequently improve our understanding of it.
希望这里的优化问题现在已经开始变得清晰。 给定关于我们愿意实际贡献频率和设备可用电池数量的限制,我们希望确定进行测量的最佳位置,以使这些测量对促进高效的环境探索最有用,从而增进我们对其的理解。 。
To solve the problem, we need to answer some key questions first. Specifically, how is our environment represented? How much each measurement contributes to the overall picture? How do different measurements impact our understanding of air quality?
要解决该问题,我们需要首先回答一些关键问题。 具体来说,我们的环境如何表现? 每种测量对整体情况有多大贡献? 不同的测量结果如何影响我们对空气质量的了解?
In essence, we need a model for the environment. This will help us quantify the information entailed in each of the readings. It can also help us understand how each measurement affects the overall information collected over time.
本质上,我们需要一个环境模型。 这将有助于我们量化每个读数中包含的信息。 它还可以帮助我们了解每次测量如何影响随时间推移收集的总体信息。
A good candidate approach is the use of Gaussian Processes. For the more technical readers, a Gaussian Process is a regression technique that naturally provides a predictive mean and variance over its estimates. In practice, this means we can use this technique to interpolate air quality over the environment over time, given that some measurements are taken. Or put differently, we can predict the air quality at unobserved locations (locations where no measurements are taken) as well as predict the state of the environment in the future. Importantly, however, a Gaussian Process can also be used to provide how certain we are about air-quality in each location (by utilising predictive variance).
一个很好的候选方法是使用高斯过程。 对于更多的技术读者,高斯过程是一种回归技术,自然可以在其估计值上提供预测性均值和方差。 在实践中,这意味着只要进行了一些测量,我们就可以使用该技术随时间对环境中的空气质量进行插值。 或者换句话说,我们可以预测未观测位置(未进行任何测量的位置)的空气质量,并预测未来的环境状况。 但是重要的是,高斯过程也可以用来提供我们对每个位置的空气质量的确定性(通过利用预测方差)。

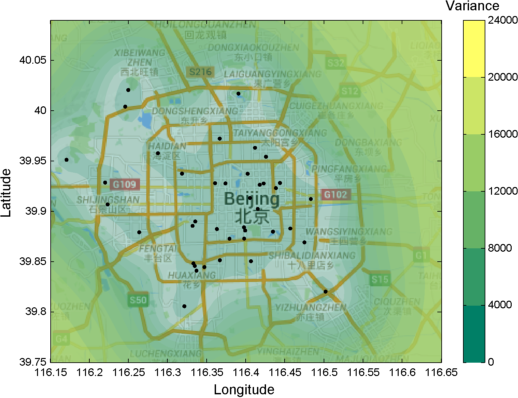
In statistics and information theory, the variance is a measure of uncertainty. Our goal is to eliminate uncertainty from our heatmap. We want to know (be sure if we can) of the air quality in our area. To help us understand visually what we mean by interpolation, have a look at the figure above. In that figure, we can see the application of a Gaussian Process as a regression technique. Specifically, it interpolates the air quality in the city of Beijing.
在统计和信息理论中, 方差是不确定性的量度。 我们的目标是消除热图的不确定性。 我们想知道(确保可以)我们所在地区的空气质量。 为了帮助我们直观地理解插值的含义,请看上图。 在该图中,我们可以看到高斯过程作为回归技术的应用。 具体来说,它可对北京城市的空气质量进行插值。

As we claimed, however, importantly, Gaussian Process provides you with an understanding of the uncertainty in the area. The figure above shows that uncertainty around the static sensors is low while in between those starts to rise. Further away from the sensors, the uncertainty is very high.
正如我们所声称的那样,重要的是,高斯过程使您对该地区的不确定性有了了解。 上图显示,静态传感器周围的不确定性很低,而静态传感器之间的不确定性则开始上升。 远离传感器,不确定性非常高。
Now, back to our crowdsourcing approach. How does this modelling approach even help us?
现在,回到我们的众包方法。 这种建模方法对我们有何帮助?
Let’s think about it for a moment. How the equivalent figures look like where instead of the static sensors we are modelling measurements taken by volunteers. As we said, it’s tough to be taking measurements at all times. We are more likely to take measurements when we are outside or when we just feel like it. Probabilistically, however, more people are clustered to the city centre and perhaps near popular attractions. No need to overthink this part. Here is an example of the setup below. There are literally some people in the city centre and some near the Summer Palace.
让我们考虑一下。 等效图形看起来如何,而不是静态传感器,我们正在对志愿者进行的测量建模。 正如我们所说,很难一直进行测量。 当我们在外面或只是喜欢时,我们更有可能进行测量。 然而,从概率上讲,更多的人聚集在市中心甚至附近的热门景点。 无需过多考虑这一部分。 这是下面的设置示例。 从字面上看,有些人在市中心,有些人在颐和园附近。

What we can tell from this figure, however, is that maybe the static sensor setup was not that bad after all. This is because the variance or uncertainty about the environment is high in all areas (as seen with yellowish in the figure). On the bright side, people in the city centre or popular attractions can be confident that they know what air quality is like where they are. But this is not very useful for urban planning.
但是,从该图我们可以看出,也许静态传感器的设置毕竟还算不错。 这是因为在所有区域中,环境的变化或不确定性都很高(如图中的黄色所示)。 从好的方面来说,市中心或热门景点的人们可以确信他们知道自己所在的地方的空气质量。 但这对于城市规划不是很有用。
We can do better. We haven’t really solved the problem yet as we haven’t guided or alerted people when and where to take the readings. It was merely a possible default setup given how people move or where they are more likely to be willing to take measurements.
我们可以做得更好。 我们还没有真正解决问题,因为我们没有指导或提醒人们何时何地读取这些数据。 考虑到人们的移动方式或他们更愿意进行测量的地方,这仅仅是一种可能的默认设置。
Nevertheless, we have managed to evolve our understanding. We can now formulate the problem in the context of our modelling method. Specifically, we need to take a set of measurements such that the information, as measured by the use of Gaussian Process, is maximised.
尽管如此,我们已经设法发展了我们的理解。 现在,我们可以在我们的建模方法的背景下提出问题。 具体来说,我们需要进行一组测量,以使通过使用高斯过程测得的信息最大化。
A solution to this problem requires the use of algorithms from the broad area of Artificial Intelligence. Specifically, we need an intelligent system to decide when and where measurements should be taken to maximise information gained about the air quality, while at the same time minimise the number of readings needed. The system can employ greedy search techniques combined with meta-heuristics such as stochastic local search, unsupervised learning (clustering) and random simulations. These are just some example potential techniques and I am not going to expand further on them but rather give an overview of how an algorithm may look like.
要解决此问题,就需要使用人工智能领域的算法。 具体来说,我们需要一个智能系统来决定何时和何处进行测量,以使获取的有关空气质量的信息最大化,同时使所需的读数数量降至最低。 该系统可以采用贪婪搜索技术,并结合元启发式技术,例如随机局部搜索,无监督学习(聚类)和随机模拟。 这些只是一些潜在的示例技术,我将不进一步扩展它们,而是概述算法的外观。
The main idea is to simulate the environment over time, asking what-if kind of questions. What if I take a measurement now versus one in the night. Which one would give me the best possible outcome? Are both necessary? What if I take a measurement downtown or what if I take it near my home?
主要思想是随着时间的流逝模拟环境,询问假设问题。 如果我现在进行测量而不是晚上进行测量,该怎么办? 哪一个会给我最好的结果? 两者都是必要的吗? 如果我在市中心进行测量,或者在我家附近进行测量该怎么办?
Think about all the possible what-if questions we can ask. That is a what-if for each person, at every moment. This problem is very hard to solve even for the most powerful computer. It would require to run many millions of simulations to cover all possible scenarios for each of our volunteer. Fortunately, we have more algorithmic approaches in our pocket as mentioned above. Clustering, for instance, can be used to group people in the same location and essentially treat them as being a single entity. So the intelligent system does not need to consider different simulations for each one of the volunteers but rather for each for the entities. Not only we can group people in space but also in time. People who took measurements at a similar location at a similar time can also be seen as a single entity.
考虑所有可能提出的假设问题。 那是每个人在每时每刻的假设。 即使对于功能最强大的计算机,此问题也很难解决。 这将需要运行数百万个模拟,以涵盖我们每个志愿者的所有可能情况。 幸运的是,如上所述,我们口袋里有更多的算法方法。 例如,聚类可用于将同一地点的人员分组,并从本质上将其视为单个实体。 因此,智能系统无需为每个志愿者考虑不同的模拟,而为每个实体考虑模拟。 我们不仅可以在太空中分组人员,而且可以在时间上分组。 在相似的时间在相似的位置进行测量的人也可以看作是一个实体。
Now that we reduced the simulations required, we can use meta-heuristic approaches that basically evaluate each combination in an order such that we progressively get closer to a better configuration but not necessarily the best one. One that is better than the above might be useful for both the participants and urban planning. For instance, a greedy algorithm will firstly iterate over all the possible entities over time and evaluate how the information collected varies if a single measurement is taken by any one of those entities. In the same fashion, progressively the algorithm can keep selecting the best places without actually having to evaluate all the possible setups.
现在我们减少了所需的仿真,我们可以使用元启发式方法,该方法基本上按顺序评估每个组合,以便我们逐渐接近更好的配置,但不一定接近最佳配置。 一个比以上更好的方法可能对参与者和城市规划都有用。 例如,贪婪算法将首先对所有可能的实体随时间进行迭代,并评估如果其中任何一个实体进行一次测量,则收集到的信息将如何变化。 以相同的方式,该算法可以逐步选择最佳位置,而无需实际评估所有可能的设置。
Finally, given the algorithmic process above, the intelligent system gives us a good possible solution. These means we have a recommended set of locations to take air-quality readings. As we can observe in the figure above, it is a much better setup than what we previously had. Also, it is comparable to the static sensor placement we discussed earlier. Just imagine having more volunteers though. This can only get better and make the map above greener. Overall, air quality monitoring can become easier and more efficient with the use of AI algorithms and crowdsourcing.
最后,鉴于上述算法过程,智能系统为我们提供了一个很好的解决方案。 这意味着我们建议使用一组位置来获取空气质量读数。 正如我们在上图中所观察到的,它是一个比以前更好的设置。 而且,它与我们之前讨论的静态传感器放置相当。 试想一下,尽管有更多的志愿者。 这样只会变得更好,并使上面的地图更绿色。 总体而言,通过使用AI算法和众包,空气质量监测可以变得更加容易和高效。
This article and figures are based on a published journal: Zenonos, Alexandros, Sebastian Stein, and Nicholas R. Jennings. “Coordinating measurements in uncertain participatory sensing settings.” Journal of Artificial Intelligence Research 61 (2018): 433–474.
本文和数据均基于已出版的期刊:Zenonos,Alexandros,Sebastian Stein和Nicholas R. Jennings。 “在不确定的参与感测设置中协调测量。” 人工智能研究杂志 61(2018):433–474。
翻译自: https://towardsdatascience.com/how-ai-and-humans-can-optimise-air-pollution-monitoring-bcc7807c7566
ai人工智能将替代人类
http://www.taodudu.cc/news/show-4170295.html
相关文章:
- Python 绘图大全之使用 Python Folium 制作生成热图的详细指南
- 使用seaborn绘制热图
- 【HigherHRNet】 HigherHRNet 详解之 HigherHRNet的热图回归代码
- 怎么让热图显示基因名_如何将 qPCR 数据做成热图
- python人工智能之:多边形矩阵热图程序实战篇(二)
- 学习1010种热图绘制方法
- Centernet 生成高斯热图
- python人工智能之:六边形矩阵热图程序实战篇(一)
- 线上课第一周总结
- 第一周(二)
- java 给一个开学日期,计算当天是开学第几周星期几或者开学第几周星期几为哪一天
- 第一周算法学习博客
- 大二下学期第十三周
- 一学期c语言的学习总结
- 第一学期ACM之旅总结篇
- 2018上期Android学期总结
- 第一周C++学习总结
- 移动端VUE实现一周课程表
- java 周次_JAVA计算学校学期周次
- 第16周—学期总结
- Python第一周学习总结
- 2021第一学期学习笔记01
- c语言输出行末不得有多余空格,2019年春季学期第四周作业
- 根据指定时间范围取得对应(第几)周信息,以及一年当中所有周时间范围列表信息(可用于学期第几周,年第几周)
- php计算一年多少周,同时计算出这一周的开始时间和结束时间(可选返回时间戳或日期)
- 第一学期第一周
- 大一下学期第十一周及以前学习总结
- 小学计算机应用技术学院官网,成都信息技术学院官网
- 计算机学院工作总结报告,计算机学院学生会中期工作总结大会
- 商丘学院计算机考研,商丘学院院校简介_商丘学院研究生院 - 中国考研网
ai人工智能将替代人类_AI和人类如何优化空气污染监测相关推荐
- ai人工智能将替代人类_AI再次击败人类
ai人工智能将替代人类 内容丰富 (Informative) Let's take a stroll down memory lane and take a look at the times whe ...
- ai人工智能将替代人类_只有人工智能才能将我们从假货世界中拯救出来(人工智能也在创造世界)...
ai人工智能将替代人类 真相就在那里. 小时候,我和弟弟用纸碟,锡纸和大理石制成不明飞行物. 然后,我们将飞船悬挂在鱼线上,并用妈妈的塑料110摄像机上了楼顶,这毫无疑问地证明了我们并不孤单. [内部 ...
- ai人工智能将替代人类_教AI学习人类如何有效计划
ai人工智能将替代人类 Human planning is hierarchical. Whether planning something simple like cooking dinner or ...
- ai人工智能将替代人类_在人工智能时代成为人类意味着什么
ai人工智能将替代人类 身临其境的体验 (IMMERSIVE EXPERIENCE) FrankensteinAI is an immersive, interactive experience de ...
- ai人工智能将替代人类_急于将AI推向极限
ai人工智能将替代人类 Earlier this year, Apple announced its US$200 million acquisition of Seattle-based edge- ...
- 【大数据AI人工智能】创造意义的是人类,不是机器
选自西班牙艺术家霍尔迪· 艾森(Jordi Isern)的系列作品"星座" (Constellations,2014 年). 在"人工智能"这个词中," ...
- ai人工智能的数据服务_AI和数据科学的傻瓜与同学聊天
ai人工智能的数据服务 These are my answers to questions about AI and its business practice, discussed among ~2 ...
- ai人工智能的数据服务_AI如何帮助提高企业数据质量
ai人工智能的数据服务 Hardly anyone relying on data can say their data is perfect. There is always that differ ...
- 五节课从零起步(无需数学和Python基础)编码实现AI人工智能框架电子书V1
五节课从零起步 (无需数学和Python 基础) 编码实现AI 人工智能框架 王 家 林 2018/4/15 ...
最新文章
- php文章列表样式,css列表样式有哪些?css设置列表样式的方法
- webpack4 系列教程: 前言
- 如何在Linux上找到包含特定文本的所有文件?
- 聊聊前后端分离的接口规范
- Spirng MVC +Velocity 表单绑定命令对象
- 运维基础(2)实用工具篇
- canoe开发从入门到精通pdf_阿里技术官手写801页PDF《精通Java Web整合开发》
- 使用POI技术简单的将数据库中的数据读取出为Excel文件
- ai的预览模式切换_AI字体制作,用AI制作创意阶梯式文字
- getCacheDir()和getFilesDir()方法区别
- 《Xcode实战开发》——1.1节下载
- 《微服务设计》(一)---- 微服务
- Android基础入门教程——4.4.2 ContentProvider再探——Ducument Provider
- jQuery 身份证验证
- 简述用决策表设计测试用例的步骤_软件测试(14)--黑盒测试案例设计技术--基于决策表的测试...
- flex 分类模块布局 (双排盒子布局 等比例 等间距)Vue绑定数据
- 微信小程序---倒计时
- Arcgis js featureLayer加载完成之后,对其加载的要素重新定义样式
- Android 系统电量统计
- 成为一名大数据工程师,需要具备什么技能?