hdfs高可用与高拓展机制分析
一、元数据服务高可用
1.1高可用的需求
故障类型:
- 软件故障
- 硬件故障
- 人为故障
灾难:数据中心级别不可用
故障不可避免,灾难有时发生
如果HDFS不可用,业务停止的损失极大,所以高可用就至关重要
1.2高可用形式
服务高可用有
- 热备份:有另一个备份节点,发生故障时可直接切换
- 冷备份:将关键性文件切换到另外位置,发生故障时通过备份数据进行恢复。
故障恢复操作:
- 人工切换
- 自动切换
人工的反应、决策时间都更长,高可用需要让系统自动决策。
HDFS的设计中,采用了中心化的元数据管理节点NameNode。NameNode容易成为故障中的单点(single point of failure)。
1.3HDFS NameNode高可用架构
![]()
组件介绍:
- ActiveNamenode:主节点,提供服务,生产日志
- StandbyNamenode:备节点,消费日志
- ZooKeeper:为自动选主提供统一协调服务
- BookKeeper:提供日志存储服务
- ZKFC: NameNode探活、触发主备切换
- HA Client:提供了自动切换的客户端
- edit log:操作的日志
1.4理论基础:状态机复制和日志
状态机复制是实现容错的常用方法
组件:状态机以及其副本、变更日志、共识协议
![]()
1.5NameNode状态持久化
![]()
FSImage:是保存文件目录树的日志
EditLog:是保存对文件操作的日志
checkpoint机制会合并两者生成一个新的目录树日志
![]()
1.6NameNode操作日志的生产消费
Active生产,Standby (可能有多个)消费
![]()
1.7NameNode块维护
区别
- Active即接收,也发起变更·
- Standby只接收,不发起变更
![]()
1.8自动主备切换–server
ZKFailoverController:作为外部组件,驱动HDFS NameNode的主备切换
HA核心机制:Watch
![]()
1.9自动主备切换–client
核心机制-standbyexception
client自动处理
1.10BookKeeper架构
![]()
1.11Quorum机制:多副本一致性读写
场景:多副本对象存储,用版本号标识数据新旧
![]()
1.12BookKeeper Quorum
日志场景:顺序追加、只写
Write Quorum:写入副本数
Ack Quorum:响应副本数
![]()
1.13BookKeeper Ensemble
均衡加载数据
Round-Robin Load Balancer·
第一轮: 1,2,3
第二轮: 2,3,4
第三轮: 3,4,1
第四轮: 4,1,2
二、数据存储高可用
2.1单机存储–RAID
Redundant Array of Independent Disks
图:提供RAID功能的NAS设备
![]()
2.2RAID方案讲解
RAID 0:条带化-把数据按顺序依次分配在每个储存空间里
![]()
RAID 1: 冗余-把一份数据复制两份存储在每个储存空间里
![]()
RAID 3:容错校验
把数据分成多个“块”,按照一定的容错算法,存放在N+1个硬盘上,实际数据占用的有效空间为N个硬盘的空间总和,而第N+1个硬盘上存储的数据是校验容错信息,当这N+1个硬盘中的其中一个硬盘出现故障时,从其它N个硬盘中的数据也可以恢复原始数据,这样,仅使用这N个硬盘也可以带伤继续工作(如采集和回放素材),当更换一个新硬盘后,系统可以重新恢复完整的校验容错信息。
![]()
2.3HDFS多副本
HDFS版本的RAID1多副本
![]()
优点
陵与路径简单
副本修复简单高可用
Erasure Coding原理
HDFS版本的RAID2/3,常用Reed Solomon算法
算法原理
![]()
HDFS Erasure Coding
HDFS版本的RAID2
图:直接保存的EC和Stripe(条带化)后保存的EC
![]()
2.4网络架构
机架(Rack):放服务器的架子。
TOR(Top of Rack):机架顶部的交换机。
数据中心(Data Center):集中部署服务器的场所
![]()
2.5副本放置策略-机架感知
一个TOR故障导致整个机架不可用vs
降低跨rack流量
trade-off:一个本地、一个远端
三、元数据可拓展性
HDFS NameNode是个集中式服务,部署在单个机器上,内存和磁盘的容量、CPU的计算力都不能无限扩展。
拓展方法:
扩容单个服务器的能力
部署多个服务器来扩容
![]()
挑战:
- 名字空间分裂
- DataNode分裂
- 目录树结构复杂
3.1常见的Scale Out方案
![]()
图:三种数据路由方式
- 服务端侧
- 路由层
- 客户端侧
3.2社区解决方案 BlockPool
解决datenode同时服务多组NameNode的问题
文件服务分层
- Namespace
- Block Storage
用BlockPool来区分datenode的服务
- 数据块存储
- 心跳和块上报
3.3社区解决方案 viewsf
Federation架构:将多个不同集群组合起来,对外表现像一个集群一样。
图: viewfs通过在client-side的配置,指定不同的目录访问不同的NameNode。
![]()
3.4字节跳动的NNProxy
NNProxy是ByteDance自研的HDFS代理层,提供了路由服务。
NNProxy主要实现了路由管理和RPC转发·以及鉴权、限流、查询缓存等额外能力
图:NNProxy所在系统上下游
![]()
NNProxy的路由规则保存
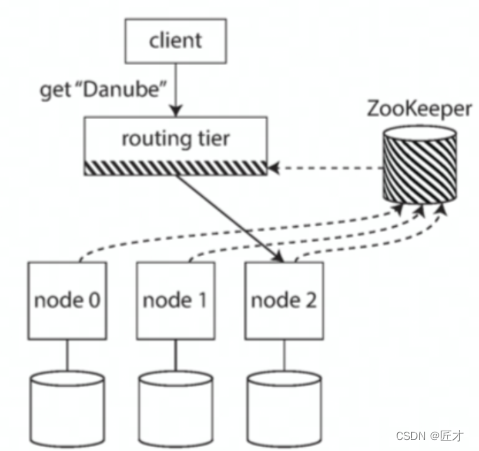
NNProxy路由转发实现
目录树视图
![]()
四、存储数据高拓展性
4.1延迟的分布与长尾延迟
延迟的分布:用百分数来表示访问的延迟的统计特征例如p95延迟为1ms,代表95%的请求延迟要低于1ms,但后5%的请求延迟会大于1ms
长尾延迟:尾部(p99/p999/p999)的延迟,衡量系统最差的请求的情况。会显著的要差于平均值
![]()
![]()
木桶原理使尾部延迟放大:访问的服务变多,尾部的请求就会越发的慢。
![]()
尾部延迟放大,整个服务被Backend 6拖累
4.2长尾问题的表现-慢节点
慢节点:读取速度过慢,导致客户端阻塞。
慢节点的发生难以避免和预测
- 共享资源、后台维护活动、请求多级排队、功率限制。
- 固定的损耗:机器损坏率
- 混沌现象
离线任务也会遇到长尾问题
- 全部任务完成时间取决于最慢的任务什么时候完成。
- 集群规模变大,任务的数据量变大。
- 只要任何数据块的读取受到长尾影响,整个任务就会因此停滞.
集群扩大10倍,问题扩大N(>10)倍
4.3超大集群下的数据可靠性
条件一:超大集群下,有一部分机器是损坏来不及修理的。
条件二:副本放置策略完全随机。
条件三:DN的容量足够大
推论:必然有部分数据全部副本在损坏的机器上,发生数据丢失。
解决方法:Copyset
将DataNode分为若干个Copyset选块在copyset内部选择
原理:减少了副本放置的组合数,从而降低副本丢失的概率。
![]()
4.4超大集群的负载均衡和数据迁移
![]()
新加入的DataNode会成为一个数据写入的热点,而老的datenode数据写入量就少了
数据的不均匀
- 节点容量不均匀
- 数据新日不均匀
- 访问类型不均匀
资源负载不均匀
![]()
典型场景
![]()
4.5数据迁移工具-跨NN迁移
DistCopy
- 基于MapReduce,通过一个个任务,将数据从一个NameNode拷
- 贝到另一个 NameNode。
- 需要拷贝数据,流量较大,速度较慢。
FastCopy
开源社区的无需拷贝数据的快速元数据迁移方案√前提条件:新旧集群的DN列表吻合
对于元数据,直接复制目录树的结构和块信息。
对于数据块,直接要求DataNode从源 BlockPool hardlink 到目标
BlookPool,没有数据拷贝。
hardlink:直接让两个路径指向同一块数据。
balancer
工具向DataNode 发起迁移命令,平衡各个DataNode的容量。
![]()
场景
- 单机房使用、多机房使用限流措施
评价标准
- 稳定性成本
- 可运维性
eNode。 - 需要拷贝数据,流量较大,速度较慢。
FastCopy
开源社区的无需拷贝数据的快速元数据迁移方案√前提条件:新旧集群的DN列表吻合
对于元数据,直接复制目录树的结构和块信息。
对于数据块,直接要求DataNode从源 BlockPool hardlink 到目标
BlookPool,没有数据拷贝。
hardlink:直接让两个路径指向同一块数据。
balancer
工具向DataNode 发起迁移命令,平衡各个DataNode的容量。
[外链图片转存中…(img-UrAfd3Lb-1660221746580)]
场景
- 单机房使用、多机房使用限流措施
评价标准
- 稳定性成本
- 可运维性
- 执行效率
要实现,一个分布式文件系统要考虑的太多了,毕竟hdfs是个代码量十多万的项目。但是要是想搭建基本框架的人可以参考这个项目
还有一个用go语言写的简易gfs
hdfs高可用与高拓展机制分析相关推荐
- oom 如何避免 高并发_微博短视频百万级高可用、高并发架构如何设计?
本文从设计及服务可用性方面,详细解析了微博短视频高可用.高并发架构设计中的问题与解决方案. 今天与大家分享的是微博短视频业务的高并发架构,具体内容分为如下三个方面: 团队介绍 微博视频业务场景 &qu ...
- 微博短视频千万级高可用、高并发架构如何设计?
作者:刘志勇,本文来自新浪微博视频平台资深架构师刘志勇在 LiveVideoStackCon 2018 讲师热身分享,并由 LiveVideoStack 整理而成. 本文从设计及服务可用性方面,详细解 ...
- 架构应用之高可用、高复用
架构应用之高可用.高复用 . 一.存储高可用 存储的高可用,主要是通过数据冗余的方式来实现高可用,复杂性主要是在如何保持数据一致性,复制延迟和网络中断都会带来数据不一致.主要考虑的就是,数据如何复制, ...
- 微博短视频百万级高可用、高并发架构如何设计?
本文从设计及服务可用性方面,详细解析了微博短视频高可用.高并发架构设计中的问题与解决方案. 今天与大家分享的是微博短视频业务的高并发架构,具体内容分为如下三个方面: 团队介绍 微博视频业务场景 &qu ...
- 抽奖活动的高可用、高并发优化
这几年工作中做过不少营销活动,这里以抽奖活动为例,讨论一下如何设计出一个高可用.高并发的营销系统. 高可用.高并发架构的核心是分流和限流.系统架构时,应根据每一种营销活动的场景与特性,制定不同的分流. ...
- 微信开源PhxQueue:高可用、高可靠、高性能的分布式队列**
消息队列概述 消息队列作为成熟的异步通信模式,对比常用的同步通信模式,有如下优势: 解耦:防止引入过多的 API 给系统的稳定性带来风险:调用方使用不当会给被调用方系统造成压力,被调用方处理不当会降低 ...
- 全面认识高并发:高性能、高可用、高扩展
Table of Contents 01 如何理解高并发? 02 高并发系统设计的目标是什么? 2.1 宏观目标 2.2 微观目标 ❇ 性能指标 ❇ 可用性指标 ❇ 可扩展性指标 03 高并发的实践方 ...
- 抖音微博等短视频千万级高可用、高并发架构如何设计?
本文从设计及服务可用性方面,详细解析了微博短视频高可用.高并发架构设计中的问题与解决方案. 作者:刘志勇,本文来自新浪微博视频平台资深架构师刘志勇在 LiveVideoStackCon 2018 讲师 ...
- MySQL高可靠_MySQL高可用与高可靠架构
前言 数据库高可用是生产环境使用数据库必要条件,MySQL数据库通常使用复制技术实现.然MySQL复制本身存在很多的"坑"容易被忽视,导致一些开发或运维人员对于MySQL复制的可靠 ...
- 高并发、高可用、高负载、分布式架构
微博短视频百万级高可用.高并发架构如何设计? 抖音微博等短视频千万级高可用.高并发架构如何设计? 从零到百亿级,揭秘科大讯飞广告平台架构演进之路 苏宁Spring Cloud微服务脚手架工具实践分享 ...
最新文章
- 【计算理论】计算复杂性 ( coNP 问题 | coNP 完全 | P、NP、coNP 相互关系 )
- Linux安装GitLib
- python运行py文件 sublime 快捷键_Sublime Text配置python以及快捷键总结
- python continue语句的用法(跳过本次循环,不是跳出整个循环,break才是跳出整个循环)
- cplex安装_Excel软件规划求解工具的安装与功能介绍
- Java笔记-JdbcTemplate批量执行insert及update
- oracle简单建库基本流程
- UIAUTOMATOR
- h3c交换机划分vlan
- RedHat7.6 Linux系统图形界面安装教程
- opencv 应用程序无法正常启动0xc000007b
- 『TensorFlow』TFR数据预处理探究以及框架搭建
- 高通平台msm8916修改开机logo 高通平台修改LK(bootloader)开机logo
- 浙江大学计算机考研信息汇总
- 使用源码部署CITA(Ubuntu18.0.4 | VMware)
- DJ13-1 汇编语言程序设计-3
- php反向引用,JavaScript 正则应用详解【模式、欲查、反向引用等】
- Codeforces869B The Eternal Immortality
- SSL证书、 der、 cer、 pem区别
- 线性代数:零空间维度等于自由变量个数的原因