虚拟化Hadoop集群的部署和管理 - 基本操作
在Big Data Extensions(BDE)上不仅可以在分钟级别非常快速地部署Hadoop集群,这点可以通过前文《大数据虚拟化零起点-6基础运维第五步-使用CLI创建Apache Hadoop集群》和《大数据虚拟化零起点-7基础运维第六步-安装Big Data Extensions Plugin》感受到。部署完成后,BDE还能够方便地管理它们,从软件定义的角度,通过简单的图形界面和直观的命令行两种方法对集群的对象进行管理。下面我们就具体展开,讨论这些日常所需的集群运行管理。
打开和关闭Hadoop集群
使用CLI方式:
1. 打开Serengeti CLI,连接Serengeti服务器
2. 输入命令行:
serengeti>cluster stop --name <cluster name>
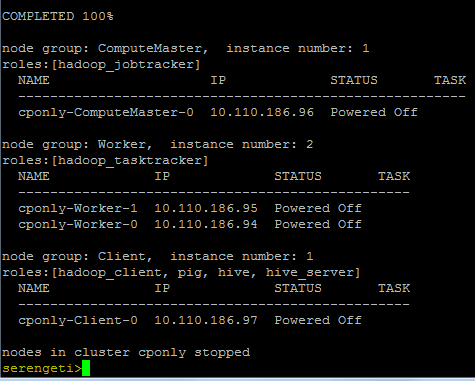
例如:serengeti>clusterstop --name cponlycluster
3. 命令行界面会显示关闭cluster的进度,直到完成。
 \
\
我们再使用GUI的方式去看同一个Hadoop集群,再试图重新开启它。
1.登录vSphere web client,进入Big Data Extensions界面
2.进入Big Data Cluster界面,可以找到刚才关闭的Hadoop集群也显示Stopped状态了。
3.现在直接在图形界面重新开启它,选中该集群,右键菜单选择Start Big Data Cluster

4.该集群开始运行,显示Starting状态,并显示进度条。直到完全启动,并显示Running状态。
这时候切换到命令行模式,查看该集群的话,它的运行状态也是Running,都应该是一致的。
删除Hadoop集群
删除集群在虚拟化环境中相当于对文件进行操作,非常简单,它利用vSphere操作虚拟机,从而回收对应的虚拟机文件夹里的文件,在1分钟即可搞定。所腾出的空间和运算资源可以立刻被其他虚拟机利用。而在物理环境下,对Hadoop集群的回收要达到同等效果,要对集群的所有物理机器进行清理和格式化,资源重新被分配的周期更是进一步拉长。
命令行的操作步骤:
serengeti>cluster delete --name<cluster name>
例如:serengeti>clusterdelete --name testcluster
用户也可以通过Big Data Extensions的Web图形界面来操作:
1.打开vSphere Web Client, 进入BigData Extension界面
2.选择所要删除的集群
3.右键菜单选择Delete Big Data Cluste

目标集群的状态会显示Deleting,直到集群被完全删除。
在下一篇文章里,我们会讨论灵活方便地扩展Hadoop集群,以及时满足业务的变化。
如有任何问题,您可以发邮件至bigdata_apac@vmware.com。
关于vSphere Big Data Extensions:
VMwarevSphere Big Data Extensions(简称BDE)基于vSphere平台支持大数据和ApacheHadoop作业。BDE以开源Serengeti项目为基础,为企业级用户提供一系列整合的管理工具,通过在vSphere上虚拟化ApacheHadoop,帮助用户在基础设施上实现灵活、弹性、安全和快捷的大数据部署、运行和管理工作。了解更多关于VMware vSphere Big Data Extensions的信息,请参见http://www.vmware.com/hadoop。
作者简介:

张君迟
VMware大数据解决方案项目经理
目前负责VMware大数据解决方案的管理和市场工作。曾担任VMware数据库管理产品vFabric Data Director产品经理,对虚拟化、云计算、关系型数据库和大数据等企业产品、技术方案和市场有深入的理解和实战经验。在此之前,就职于Microsoft从事分布式系统的产品管理和研发工作。
转载于:https://blog.51cto.com/vbigdata/1293862
虚拟化Hadoop集群的部署和管理 - 基本操作相关推荐
- 使用 xCAT 简化 AIX 集群的部署和管理
使用 xCAT 简化 AIX 集群的部署和管理 基于 IBM® Power 520 Express® (8203-E4A) 的实践 本文主要介绍了 xCAT 软件的工作原理,并且通过在 IBM® Po ...
- 在Kubernetes集群上部署和管理JFrog Artifactory
JFrog Artifactory是一个artifacts仓库管理平台,它支持所有的主流打包格式.构建工具和持续集成(CI)服务器.它将所有二进制内容保存在一个单一位置并提供一个接口,这使得用户在整个 ...
- Hadoop系列一:Hadoop集群分布式部署
1.环境准备 VirtualBox虚拟机上分布部署三套Ubuntu15.10操作系统(Linux 64位),命名为Ubuntu_Hadoop(用户名hp).Ubuntu_C(用户名c).Ubuntu_ ...
- 革命性新特性 | 单一应用跨多Kubernetes集群的部署与管理
近日,全球领先的容器管理软件供应商Rancher Labs宣布,其旗舰产品Rancher--开源的企业级Kubernetes管理平台--全面发布的最新版本Rancher 2.2 Preview 2中, ...
- Hadoop集群安装部署_分布式集群安装_02
文章目录 一.上传与 解压 1. 上传安装包 2. 解压hadoop安装包 二.修改hadoop相关配置文件 2.1. hadoop-env.sh 2.2. core-site.xml 2.3. hd ...
- Hadoop集群安装部署_分布式集群安装_01
文章目录 1. 分布式集群规划 2. 数据清理 3. 基础环境准备 4. 配置ip映射 5. 时间同步 6. SSH免密码登录完善 7. 免密登录验证 1. 分布式集群规划 伪分布集群搞定了以后我们来 ...
- Hadoop集群安装部署_伪分布式集群安装_02
文章目录 一.解压安装 1. 安装包上传 2. 解压hadoop安装包 二.修改Hadoop相关配置文件 2.1. hadoop-env.sh 2.2. core-site.xml 2.3. hdfs ...
- Hadoop集群安装部署_伪分布式集群安装_01
文章目录 一.配置基础环境 1. 设置静态ip 2. hostname 3. firewalld 4. ssh免密码登录 5. JDK 一.配置基础环境 1. 设置静态ip [root@bigdata ...
- Centos7系统、Hadoop集群上部署ntp服务器
集群情况: 三台机器分别: master:180.201.163.46 slave1:180.201.156.76 slave2:180.201.130.17 网关:255.255.192.0 在sl ...
最新文章
- centos7 nginx安装_手把手教你PHP(一) Centos7上的LEMP配置
- Maven-学习笔记06【基础-Maven工程servlet实例】
- tp3.2php开启事务,ThinkPHP 3.2.2实现事务操作的方法
- linux lspci信息 详解_Linux引导之EFI SHELL详解
- 对DataTable的一些解释
- 一致性hash算法虚拟节点_一致性Hash算法原理详解
- firefox 插件可能用得上的Firefox插件及下载
- Java并发--ConcurrentModificationException(并发修改异常)异常原因和解决方法
- Android 使用Nginx rtmp 模块
- 设计模式练习:Composite模式
- vue+express+mongodb+websocket 仿QQ即时聊天项目
- 浏览器的使用方法,如何添加书签|常用网站|扩展程序?
- 数学分析教程(科大)——2.4笔记+习题
- 运放输入偏置电流方向_运算放大器+仪表放大器:如何为偏置电流提供直流回路?...
- 软件需求分析期末试题
- 【Android 第三方SDK】breakpad在linux下编译
- 关于BUCK降压的一些学习笔记2-->滞回比较器产生三角波
- K8S二进制环境搭建苹果电脑(M1芯片)
- Matplotlib二维箭头图
- 一帮一 (15 分)