Log4j2架构分析与实战
为什么80%的码农都做不了架构师?>>> 
1 系列目录
2种日志接口框架,4种日志实现框架
jdk-logging、log4j、logback日志介绍及原理
jcl与jul、log4j1、log4j2、logback的集成原理
slf4j与jul、log4j1、log4j2、logback的集成原理
slf4j、jcl、jul、log4j1、log4j2、logback大总结
slf4j + log4j原理实现及源码分析
Apache Log4j
Log4j架构分析与实战
Log4J配置文件详解
Apache Commons Logging
Commons Logging 架构分析
JDK Logging
JDK Logging 深入分析
Logback
从Log4j迁移到LogBack的理由
Logback 深入分析
Apache Log4j2
Log4j2架构分析与实战
Log4j2配置文件详解
2 Log4j2介绍
Log4j2是Log4j的升级版,与之前的版本Log4j 1.x相比、有重大的改进,在修正了Logback固有的架构问题的同时,改进了许多Logback所具有的功能。
2.1 Log4j2的特性及改进
API分离:
Log4j2将API与实现分离开来。开发人员现在可以很清楚地知道能够使用哪些没有兼容问题的类和方法,同时又允许通过自己实现来增强功能。改进的性能:
Log4j2的性能在某些关键领域比Log4j 1.x更快,而且大多数情况下与Logback相当。多个API支持:Log4j2提供最棒的性能的同时,还
支持SLF4J和公共日志记录API。自动配置加载:像Logback一样,一旦配置发生改变,
Log4j2可以自动载入这些更改后的配置信息,又与Logback不同,配置发生改变时不会丢失任何日志事件。高级过滤功能:与Logback类似,
Log4j2可以支持基于上下文数据、标记,正则表达式以及日志事件中的其他组件的过滤。Log4j2能够专门指定适用于所有的事件,无论这些事件在传入Loggers之前还是正在传给appenders。另外,过滤器还可以与Loggers关联起来。与Logback不同的是,Filter公共类可以用于任何情况。插件架构:
所有可以配置的组件都以Log4j插件的形式来定义。同样地,不需要修改任何Log4j代码就可以创建新的Appender、Layout、Pattern Convert 等等。Log4j自动识别预定义的插件,如果在配置中引用到这些插件,Log4j就自动载入使用。属性支持:
属性可以在配置文件中引用,也可以直接替代或传入潜在的组件,属性在这些组件中能够动态解析。属性可以是配置文件,系统属性,环境变量,线程上下文映射以及事件中的数据中定义的值。用户可以通过增加自己的Lookup插件来定制自己的属性。
更为先进的API(Modern API) 在这之前,程序员们以如下方式进行日志记录:
123if(logger.isDebugEnabled()) {logger.debug("Hi, "+ u.getA() + “ “ + u.getB());}许多人都会抱怨上述代码的可读性太差了。
如果有人忘记写if语句,程序输出中会多出很多不必要的字符串。现在,Java虚拟机(JVM)也许对字符串的打印和输出进行了很多优化,但是难道我们仅仅依靠JVM优化来解决上述问题?log4j 2.0开发团队鉴于以上需要对API进行了完善。现在你可以这样写代码:1logger.debug("Hi, {} {}", u.getA(), u.getB());和其它一些流行的日志框架一样,
新的API也支持变量参数的占位符功能。log4j 2.0还支持其它一些很棒的功能,
像Markers和flow tracing:12345678privateLogger logger = LogManager.getLogger(MyApp.class.getName());privatestaticfinalMarker QUERY_MARKER = MarkerManager.getMarker("SQL");...publicString doQuery(String table) {logger.entry(param);logger.debug(QUERY_MARKER,"SELECT * FROM {}", table);returnlogger.exit();}Markers可以帮助你很快地找到具体的日志项(Log Entries)。而在某个方法的开头和结尾调用Flow Traces中的一些方法,你可以在日志文件中看到很多新的跟踪层次的日志项,也就是说,你的程序工作流(Program Flow)被记录下来了。下面是Flow Traces的一些例子:1219:08:07.056TRACE com.test.TestService19retrieveMessage - entry19:08:07.060TRACE com.test.TestService46getKey - entry插件式的架构:
log4j 2.0支持插件式的架构。你可以根据需要自行扩展log4j 2.0,这非常简单。首先,你要为你的扩展建立好命名空间,然后告诉log4j 2.0在哪能够找到它。1<configuration … packages="de.grobmeier.examples.log4j2.plugins">根据上述配置,
log4j 2将会在de.grobmeier.examples.log4j2.plugins包中找寻你的扩展插件。如果你建立了多个命名空间,没关系,用逗号分隔就可以了。下面是一个简单的扩展插件:
123456789101112131415161718@Plugin(name ="Sandbox", type ="Core", elementType ="appender")publicclassSandboxAppenderextendsAppenderBase {privateSandboxAppender(String name, Filter filter) {super(name, filter,null);}publicvoidappend(LogEvent event) {System.out.println(event.getMessage().getFormattedMessage());}@PluginFactorypublicstaticSandboxAppender createAppender(@PluginAttr("name") String name,@PluginElement("filters") Filter filter) {returnnewSandboxAppender(name, filter);}}上面标有
@PluginFactory注解的方法是一个工厂,它的两个参数直接从配置文件读取。我用@PluginAttr和@PluginElement进行了实现。剩下的就非常简单了。
由于我写的是一个Appender,因此得继承AppenderBase这个类。该类必须实现append()方法,从而进行实际的逻辑处理。除了Appender,你甚至可以实现自己的Logger和Filter。强大的配置功能(Powerful Configuration) log4j 2的配置变得非常简单。如果你习惯了之前的配置方式,也不用担心,你只要花很少的时间就可以从之前的方式转换到新的方式。请看下面的配置:
12345678910111213141516<?xml version="1.0"encoding="UTF-8"?><configuration status="OFF"><appenders><Console name="Console"target="SYSTEM_OUT"><PatternLayout pattern="%d{HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n"/></Console></appenders><loggers><logger name="com.foo.Bar"level="trace"additivity="false"><appender-ref ref="Console"/></logger><root level="error"><appender-ref ref="Console"/></root></loggers></configuration>上面说的只是一部分改进,你还可以自动重新加载配置文件:
1234<?xml version="1.0"encoding="UTF-8"?><configuration monitorInterval="30">...</configuration>监控的时间间隔单位为秒,最小值是5。这意味着,log4j 2在配置改变的情况下可以重新配置日志记录行为。如果值设置为0或负数,log4j 2不会对配置变更进行监测。
最为称道的一点是:不像其它日志框架, log4j 2.0在重新配置的时候不会丢失之前的日志记录。还有一个非常不错的改进,那就是:同XML相比,如果你更加喜欢JSON,你可以自由地进行基于JSON的配置了:
12345678910111213141516171819202122232425262728{"configuration": {"appenders": {"Console": {"name":"STDOUT","PatternLayout": {"pattern":"%m%n"}}},"loggers": {"logger": {"name":"EventLogger","level":"info","additivity":"false","appender-ref": {"ref":"Routing"}},"root": {"level":"error","appender-ref": {"ref":"STDOUT"}}}}}Java 5 并发性(Concurrency)有一段文档是这样描述的:
“log4j 2利用Java 5中的并发特性支持,尽可能地执行最低层次的加锁...”。Apache log4j 2.0解决了许多在log4j 1.x中仍然存留的死锁问题。如果你的程序仍然饱受内存泄漏的折磨,请毫不犹豫地试一下log4j 2.0。
2.2 程序中如何使用
在你的程序中使用Log4j之前必须确保API和Core jars 在程序的classpath中。使用Maven将下面的依赖加入pom.xml。
|
1
2
3
4
5
6
7
8
9
10
11
12
|
<dependencies>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version> 2.0 -beta3</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version> 2.0 -beta3</version>
</dependency>
</dependecies>
|
与日志门面接口commons-logging,slf4j集成使用,具体详情参见slf4j与log4j2集成,commons-logging与log4j2集成。
这里随便写个类,调用就是这么简单,log4j的核心在配置文件上,配置文件详解,请参见Log4j2配置文件详解。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
public class Log4j2Hello {
private static Logger logger = LogManager.getLogger(Hello. class .getName());
public boolean hello() {
logger.entry(); //trace级别的信息,单独列出来是希望你在某个方法或者程序逻辑开始的时候调用,和logger.trace("entry")基本一个意思
logger.error( "Did it again!" ); //error级别的信息,参数就是你输出的信息
logger.info( "我是info信息" ); //info级别的信息
logger.debug( "我是debug信息" );
logger.warn( "我是warn信息" );
logger.fatal( "我是fatal信息" );
logger.log(Level.DEBUG, "我是debug信息" ); //这个就是制定Level类型的调用:谁闲着没事调用这个,也不一定哦!
logger.exit(); //和entry()对应的结束方法,和logger.trace("exit");一个意思
return false ;
}
}
|
3 Log4j2日志级别
在log4j2中,一共有五种log level,分别为TRACE, DEBUG,INFO, WARN, ERROR 以及FATAL。详细描述如下:
FATAL:用在极端的情形中,即
必须马上获得注意的情况。这个程度的错误通常需要触发运维工程师的寻呼机。ERROR:显示一个错误,或一个通用的错误情况,但还
不至于会将系统挂起。这种程度的错误一般会触发邮件的发送,将消息发送到alert list中,运维人员可以在文档中记录这个bug并提交。WARN:不一定是一个bug,但是有人可能会想要知道这一情况。
如果有人在读log文件,他们通常会希望读到系统出现的任何警告。INFO:用于
基本的、高层次的诊断信息。在长时间运行的代码段开始运行及结束运行时应该产生消息,以便知道现在系统在干什么。但是这样的信息不宜太过频繁。DEBUG:用于
协助低层次的调试。TRACE:用于
展现程序执行的轨迹。
4 Log4j2类图
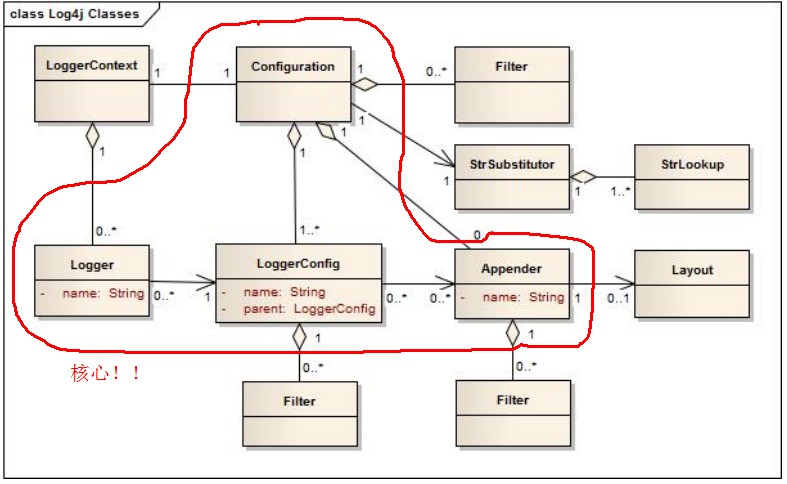
通过类图可以看到:
每一个log上下文对应一个configuration,configuration中详细描述了log系统的各个LoggerConfig、Appender(输出目的地)、EventLog过滤器等。每一个Logger又与一个LoggerConfig相关联。另外,可以看到Filter的种类很多,有聚合在Configuration中的filter、有聚合在LoggerConfig中的filter也有聚合在Appender中的filter。不同的filter在过滤LogEvent时的行为和判断依据是不同的,具体可参加本文后面给出的文档。
应用程序通过调用log4j2的API并传入一个特定的名称来向LogManager请求一个Logger实例。LogManager会定位到适当的 LoggerContext 然后通过它获得一个Logger。如果LogManager不得不新建一个Logger,那么这个被新建的Logger将与LoggerConfig相关联,这个LoggerConfig的名称中包含如下信息中的一种:①与Logger名称相同的②父logger的名称③ root 。当一个LoggerConfig的名称与一个Logger的名称可以完全匹配时,Logger将会选择这个LoggerConfig作为自己的配置。如果不能完全匹配,那么Logger将按照最长匹配串来选择自己所对应的LoggerConfig。LoggerConfig对象是根据配置文件来创建的。LoggerConfig会与Appenders相关联,Appenders用来决定一个log request将被打印到那个目的地中,可选的打印目的地很多,如console、文件、远程socket server等。LogEvent是由Appenders来实际传递到最终输出目的地的,而在LogEvent到达最终被处理之前,还需要经过若干filter的过滤,用来判断该EventLog应该在何处被转发、何处被驳回、何处被执行。
5 Log4j2概念介绍
5.1 Logger层次关系
相比于纯粹的System.out.println方式,使用logging API的最首要以及最重要的优势是可以在禁用一些log语句块的同时允许其他的语句块的输出。这一能力建立在一种假设之上,即所有在应用中可能出现的logging语句可以按照开发者定义的标准分成不同的类型。
在Log4j 1.x版本时,Logger的层次是靠Logger类之间的关系来维护的。但在Log4j2中, Logger的层次则是靠LoggerConfig对象之间的关系来维护的。
Logger和LoggerConfig均是有名称的实体。Logger的命名是大小写敏感的,并且服从如下的分层命名规则。(与java包的层级关系类似)。例如:com.foo是com.foo.Bar的父级;java是java.util的父级,是java.util.vector的祖先。
root LoggerConfig位于LoggerConfig层级关系的最顶层。它将永远存在与任何LoggerConfig层次中。任何一个希望与root LoggerConfig相关联的Logger可以通过如下方式获得:
|
1
|
Logger logger = LogManager.getLogger(LogManager.ROOT_LOGGER_NAME);
|
其他的Logger实例可以调用LogManager.getLogger 静态方法并传入想要得到的Logger的名称来获得。
5.2 LoggerContext
LoggerContext在Logging System中扮演了锚点的角色。根据情况的不同,一个应用可能同时存在于多个有效的LoggerContext中。在同一LoggerContext下,log system是互通的。如:Standalone Application、Web Applications、Java EE Applications、”Shared” Web Applications 和REST Service Containers,就是不同广度范围的log上下文环境。
5.3 Configuration
每一个LoggerContext都有一个有效的Configuration。Configuration包含了所有的Appenders、上下文范围内的过滤器、LoggerConfigs以及StrSubstitutor.的引用。在重配置期间,新与旧的Configuration将同时存在。当所有的Logger对象都被重定向到新的Configuration对象后,旧的Configuration对象将被停用和丢弃。
5.4 Logger
如前面所述, Loggers 是通过调用LogManager.getLogger方法获得的。Logger对象本身并不实行任何实际的动作。它只是拥有一个name 以及与一个LoggerConfig相关联。它继承了AbstractLogger类并实现了所需的方法。当Configuration改变时,Logger将会与另外的LoggerConfig相关联,从而改变这个Logger的行为。
获得Logger,使用相同的名称参数来调用getLogger方法将获得来自同一个Logger的引用。如:
|
1
2
3
|
Logger x = Logger.getLogger( "wombat" );
Logger y = Logger.getLogger( "wombat" ); // x和y指向的是同一个Logger对象。
|
log4j环境的配置是在应用的启动阶段完成的。优先进行的方式是通过读取配置文件来完成。
log4j使采用类名(包括完整路径)来定义Logger 名变得很容易。这是一个很有用且很直接的Logger命名方式。使用这种方式命名可以很容易的定位这个log message产生的类的位置。当然,log4j也支持任意string的命名方式以满足开发者的需要。不过,使用类名来定义Logger名仍然是最为推崇的一种Logger命名方式。
5.5 LoggerConfig
当Logger在configuration中被描述时,LoggerConfig对象将被创建。LoggerConfig包含了一组过滤器。LogEvent在被传往Appender之前将先经过这些过滤器。过滤器中包含了一组Appender的引用。Appender则是用来处理这些LogEvent的。
每一个LoggerConfig会被指定一个Log级别。可用的Log级别包括TRACE, DEBUG,INFO, WARN, ERROR 以及FATAL。需要注意的是,在log4j2中,Log的级别是一个Enum型变量,是不能继承或者修改的。如果希望获得更多的分割粒度,可用使用Markers来替代。
在Log4j 1.x 和Logback 中都有“层次继承”这么个概念。但是在log4j2中,由于Logger和LoggerConfig是两种不同的对象,因此“层次继承”的概念实现起来跟Log4j 1.x 和Logback不同。具体情况下面的五个例子:
例子一:

可用看到,应用中的LoggerConfig只有root这一种。因此,对于所有的Logger而言,都只能与该LoggerConfig相关联而没有别的选择。
例子二:

在例子二中可以看到,有5种不同的LoggerConfig存在于应用中,而每一个Logger都被与最匹配的LoggerConfig相关联着,并且拥有不同的Log Level。
例子三:

可以看到Logger root、X、X.Y.Z都找到了与各种名称相同的LoggerConfig。而LoggerX.Y没有与其名称相完全相同的LoggerConfig。怎么办呢?它最后选择了X作为它的LoggerConfig,
因为X LoggerConfig拥有与其最长的匹配度。例子四:

可以看到,现在应用中有两个配置好的LoggerConfig:root和X。而Logger有四个:root、X、X.Y、X.Y.Z。其中,root和X都能找到完全匹配的LoggerConfig,而X.Y和X.Y.Z则没有完全匹配的LoggerConfig,那么它们将选择哪个LoggerConfig作为自己的LoggerConfig呢?由图上可知,它们都选择了X而不是root作为自己的LoggerConfig,
因为在名称上,X拥有最长的匹配度。例子五:

可以看到,现在应用中有三个配置好的LoggerConfig,分别为:root、X、X.Y。同时,有四个Logger,分别为:root、X、X.Y以及X.YZ。其中,名字能完全匹配的是root、X、X.Y。那么剩下的X.YZ应该匹配X还是匹配X.Y呢?结果是X。
因为匹配是按照标记点(即“.”)来进行的,只有两个标记点之间的字串完全匹配才算,否则将取上一段完全匹配的字串的长度作为最终匹配长度。
5.6 Filter
与防火墙过滤的规则相似,log4j2的过滤器也将返回三类状态:Accept(接受), Deny(拒绝) 或Neutral(中立)。其中,Accept意味着不用再调用其他过滤器了,这个LogEvent将被执行;Deny意味着马上忽略这个event,并将此event的控制权交还给过滤器的调用者;Neutral则意味着这个event应该传递给别的过滤器,如果再没有别的过滤器可以传递了,那么就由现在这个过滤器来处理。
5.7 Appender
由logger的不同来决定一个logging request是被禁用还是启用只是log4j2的情景之一。log4j2还允许将logging request中log信息打印到不同的目的地中。在log4j2的世界里,不同的输出位置被称为Appender。目前,Appender可以是console、文件、远程socket服务器、Apache Flume、JMS以及远程 UNIX 系统日志守护进程。一个Logger可以绑定多个不同的Appender。
可以调用当前Configuration的addLoggerAppender函数来为一个Logger增加。如果不存在一个与Logger名称相对应的LoggerConfig,那么相应的LoggerConfig将被创建,并且新增加的Appender将被添加到此新建的LoggerConfig中。尔后,所有的Loggers将会被通知更新自己的LoggerConfig引用(PS:一个Logger的LoggerConfig引用是根据名称的匹配长度来决定的,当新的LoggerConfig被创建后,会引发一轮配对洗牌)。
在某一个Logger中被启用的logging request将被转发到该Logger相关联的的所有Appenders上,并且还会被转发到LoggerConfig的父级的Appenders上。
这样会产生一连串的遗传效应。例如,对LoggerConfig B来说,它的父级为A,A的父级为root。如果在root中定义了一个Appender为console,那么所有启用了的logging request都会在console中打印出来。另外,如果LoggerConfig A定义了一个文件作为Appender,那么使用LoggerConfig A和LoggerConfig B的logger 的logging request都会在该文件中打印,并且同时在console中打印。
如果想避免这种遗传效应的话,可以在configuration文件中做如下设置:
|
1
|
additivity= "false" // 默认为true
|
这样,就可以关闭Appender的遗传效应了。
5.8 Layout
通常,用户不止希望能定义log输出的位置,还希望可以定义输出的格式。这就可以通过将Appender与一个layout相关联来实现。Log4j中定义了一种类似C语言printf函数的打印格式,如”%r [%t] %-5p %c – %m%n” 格式在真实环境下会打印类似如下的信息:
|
1
|
176 [main] INFO org.foo.Bar - Located nearest gas station.
|
其中,各个字段的含义分别是:
|
1
2
3
4
5
|
%r 指的是程序运行至输出这句话所经过的时间(以毫秒为单位);
%t 指的是发起这一log request的线程;
%c 指的是log的level;
%m 指的是log request语句携带的message;
%n 为换行符;
|
6 Log4j2的LogEvent分析
6.1 如何产生LogEvent
在调用Logger对象的info、error、trace等函数时,就会产生LogEvent。LogEvent跟LoggerConfig一样,也是由Level的。LogEvent的Level主要是用在Event传递时,判断在哪里停下。
|
1
2
3
4
5
6
7
8
9
10
|
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
public class Test {
private static Logger logger = LogManager.getLogger( "HelloWorld" );
public static void main(String[] args){
Test.logger.info( "hello,world" );
Test.logger.error( "There is a error here" );
}
}
|
如代码中所示,这样就产生了两个LogEvent。
6.2 LogEvent的传递是怎样的
我们在IDE中运行一下这个程序,看看会有什么输出。如下:

发现,只有ERROR的语句输出了,那么INFO的语句呢?不着急,先来看看工程目录结构:

可以看到,工程中没有写入任何的配置文件。所以,application应该是使用了默认的LoggerConfig Level。那么默认的Level是多少呢?默认的输出地是console,默认的级别是ERROR级别。
那么,为什么默认ERROR级别会导致INFO级别的信息被拦截呢?看如下表格:

左边竖栏是Event的Level,右边横栏是LoggerConfig的Level。Yes的意思就是这个event可以通过filter,no的意思就是不能通过filter。
可以看到,INFO级别的Event是无法被ERROR级别的LoggerConfig的filter接受的。所以,INFO信息不会被输出。
7 Log4j2的配置文件重定位
如果想要改变默认的配置,那么就需要configuration file。Log4j的配置是写在log4j.properties文件里面,但是Log4j2就可以写在XML和JSON文件里了。
(1)放在classpath(src)下,以log4j2.xml命名:使用Log4j2的一般都约定俗成的写一个log4j2.xml放在src目录下使用。这一点没有争议。
(2)将配置文件放到别处:在系统工程里面,将log4j2的配置文件放到src目录底下很不方便。如果能把工程中用到的所有配置文件都放在一个文件夹里面,当然就更整齐更好管理了。但是想要实现这一点,前提就是Log4j2的配置文件能重新定位到别处去,而不是放在classpath底下。
如果没有设置”log4j.configurationFile” system property的话,application将在classpath中按照如下查找顺序来找配置文件:
|
1
2
3
4
5
6
7
|
log4j2-test.json 或log4j2-test.jsn文件
log4j2-test.xml文件
log4j2.json 或log4j2.jsn文件
log4j2.xml文件
|
这就是为什么在src目录底下放log4j2.xml文件可以被识别的原因了。如果想将配置文件重命名并放到别处,就需要设置系统属性log4j.configurationFile。设置的方式是在VM arguments中写入该属性的key和value:
|
1
|
-Dlog4j.configurationFile= "D:\learning\blog\20130115\config\LogConfig.xml"
|
测试的java程序如上文,在此不再重复。运行,console输出如下:

期待已久的INFO语句出现了。
转载于:https://my.oschina.net/yu120/blog/669024
Log4j2架构分析与实战相关推荐
- 转:秒杀系统架构分析与实战
原文出处: 陶邦仁 欢迎分享原创到伯乐头条 0 系列目录 秒杀系统架构 秒杀系统架构分析与实战 1 秒杀业务分析 正常电子商务流程 (1)查询商品:(2)创建订单:(3)扣减库存:(4)更新订单: ...
- 【转】秒杀系统架构分析与实战
0 系列目录 秒杀系统架构 秒杀系统架构分析与实战 1 秒杀业务分析 正常电子商务流程 (1)查询商品:(2)创建订单:(3)扣减库存:(4)更新订单:(5)付款:(6)卖家发货 秒杀业务的特性 (1 ...
- 秒杀系统架构分析与实战 for java
秒杀系统架构分析与实战 for java 标签: 系统架构架构设计数据库 2016-01-18 16:35 2435人阅读 评论(0) 收藏 举报 目录(?)[+] 目录[-] 0 系列目录 1 秒杀 ...
- [转]秒杀系统架构分析与实战
原文出处: 陶邦仁 欢迎分享原创到 伯乐头条 0 系列目录 秒杀系统架构 秒杀系统架构分析与实战 1 秒杀业务分析 正常电子商务流程(1)查询商品:(2)创建订单:(3)扣减库存:(4)更新订单 ...
- 秒杀系统架构分析与实战,一文带你搞懂秒杀架构!
作者丨猿码道 jianshu.com/p/df4fbecb1a4b 1.秒杀业务分析 正常电子商务流程 (1)查询商品: (2)创建订单: (3)扣减库存: (4)更新订单: (5)付款: (6)卖家 ...
- 不错的秒杀系统架构分析与实战!
点击上方蓝色"程序猿DD",选择"设为星标" 回复"资源"获取独家整理的学习资料! 作者 | 猿码架构 来源 | https://urlif ...
- 热点推荐:秒杀系统架构分析与实战--转载
原文地址:http://developer.51cto.com/art/201601/503511.htm 互联网正在高速发展,使用互联网服务的用户越多,高并发的场景也变得越来越多.电商秒杀和抢购,是 ...
- 限时抢购秒杀系统架构分析与实战
1 秒杀业务分析 正常电子商务流程 (1)查询商品:(2)创建订单:(3)扣减库存:(4)更新订单:(5)付款:(6)卖家发货 秒杀业务的特性 (1)低廉价格:(2)大幅推广:(3)瞬时售空:(4)一 ...
- 万字好文,电商秒杀系统架构分析与实战
点击上方"朱小厮的博客",选择"设为星标" 后台回复"书",获取 后台回复"k8s",可领取k8s资料 1 秒杀业务分析 ...
最新文章
- 【进阶玩法】Angular用emit()实现类似Vue.js的v-model双向绑定[(ngModel)]功能
- BZOJ 4422 Cow Confinement (线段树、DP、扫描线、差分)
- Dorado 7.1.20 发布,Ajax的Web开发平台
- 在Spring中使用Netflix Hystrix批注
- hdu 4961 Boring Sum(高效)
- oracle如何自定义类型,Oracle 自定义类型
- LintCode 137. 克隆图
- IM设计思考:XMPP资源绑定
- 5s硬件测试软件,生产现场管理5S推行工具
- kotlin插件禁用导致的Android studio无法打开-mac
- 路由器 三层交换机 网关有什么区别
- Autovue 集成
- linux发行版本号列举,查看Linux发行版的名称及其版本号
- Electron:WARNING Too many active WebGL contexts. Oldest context will be lost.
- 青龙扩展--九章头条
- latex行间距调整
- 号称下一代监控系统,到底有多牛逼!
- 【转】搜狗开源内部项目管理平台Cynthia意欲何为
- 老生常谈:让软件留下临终遗言并优雅地关闭
- 树莓派局域网测速方法